| ����
��Ϊһ�ֻ����ij������ݽṹ�����б��㷺Ӧ���ڸ������С�������ʱ���Կ���̡��������ͨѶ����˸��ߵ�Ҫ��������ȣ��ֲ�ʽ���б�̵����ü����������ڡ����ǣ����ֳ����Ļ����Ե������������ױ����ӣ�ʹ����������������㣺
1.ʹ�÷ֲ�ʽ���е�ʱ��û����ʶ�����Ƕ��С�
2.�о��������ʱ�������˷ֲ�ʽ���еĴ��ڡ�
�������ȴ�������������������ϸ�����ֲ�ʽ���б��ģ�͵�������Դ�����塢�ṹ�Լ���仯�����ԡ�ͨ����һ���ֵĽ��⣬������������������������ߣ�һ���棬�ṩһ��ϵͳ�Ե�˼��������ʹ�����ܹ�����������������ֲ�ʽ���б��ģ�ͣ��߱����зֲ�ʽ���мܹ�����������һ���棬ͨ��ȫ��λ�Ľ��⣬�ö����ܹ�����ʶ�����������ĸ��ֲַ�ʽ���б��ģ�͡�
���µĵڶ�����ʵսƪ������������������ʵ�ʹ������飬�����˶���ʽ����ڷֲ�ʽ�����µ�һЩ����Ӧ�á���Щ���ӵĻ���ģ�Ͳ����״γ����ڻ��������ĵ��У��������е����Ӷ��ǰ�����ս����˼���ܹ�����������н���ġ����ֽ��ⷽʽ�ܸ�����һ�������������ȥ���ֲܷ�ʽ���б�̡����ó̡�
�����µ����һ�����Ż�ƪ���棬�ص�������ڹ���ʦ�����÷ֲ�ʽ���б�̹��ܵ�ʱ���������ߡ��ֲ�ʽ�����Լ����������������ڵ�ע����Լ��Ż����顣
�ֲ�ʽ���б�̣���ģ��ƪ
ģ��ƪ�ӻ��������������ȥ˼����ʱ�Լ����ʹ�÷ֲ�ʽ���б��ģ�͡���ģ���ڷdz���Ҫ����Ϊ���и�����ʦ���ٵĶ��Ǿ�������ӵ������ĵ�һ��������ǽ�ģ��ͨ����ƪ�Ľ��⣬ϣ�������ܹ�����������ֲ�ʽ���б��ģ��֮���������
��ͨѶ
ͨѶ�����������������ͬ��Ҳ�Ǽ����������������ڹ���ʦ���ԣ��ڱ�̺ͼ���ѡ�͵�ʱ����������Եĸ�����RPC��RESTful��Ajax��Kafka������Щ����ĸ�����棬��ʵĶ����ǡ�ͨѶ�������ԣ��ֽ�ģ�ͼܹ�����Ҫ�ӡ�ͨѶ������������ʼ����ȷ��ϵͳ֮����ͨѶ�����ʱ����ʦ����Ҫ���ܶ�ľ��ߺ�ƽ�⣬��ֱ��Ӱ�칤��ʦ���Ƿ��ѡ��ֲ�ʽ���б��ģ����Ϊ�ܹ���������Ƕȳ�����Ӱ�콨ģ���������ĸ���When��Who��Where��How��
When��ͬ��VS�첽
ͨѶ��һ�����������ǣ�����ȥ����Ϣʲôʱ����Ҫ�����յ�����������������������������ͬ��ͨѶ���͡��첽ͨѶ�����������۳���ģ�ͣ�ͬ��ͨѶ���첽ͨѶ��ʵIJ��������ʱ�ӻ��Ƶ����ޡ�ͬ��ͨѶ��˫����Ҫһ��У��ʱ�ӣ��첽ͨѶ��˫������Ҫʱ�ӡ���ʵ������ǣ�û����ȫУ��ʱ�ӣ�����û�о��Ե�ͬ��ͨѶ��ͬ���������첽ͨѶ��ζ��������һ������ȥ����Ϣ�����յ���ʱ��㣬�����ĵȴ�һ����Ϣ��Ȼ����ʵ�����塣���ԣ�ʵ�ʱ�������е�ͨѶ�Ȳ��ǡ�ͬ��ͨѶ��Ҳ���ǡ��첽ͨѶ��������˵�����ǡ�ͬ��ͨѶ��Ҳ�ǡ��첽ͨѶ�����ر��Ƕ���Ӧ�ò��ͨѶ����ײ�ܹ����ܼȰ�����ͬ�����ơ�Ҳ�������첽���ơ����жϡ�ͬ�����͡��첽����Ϣ�ı�����̫������ʺϼ���չ�������������һЩ����ʽ�Ľ��飺
1.����ȥ����Ϣ�Ƿ���Ҫȷ�ϣ��������Ҫȷ�ϣ��������첽ͨѶ������ͨѶ��ʱ��Ҳ��Ϊ����ͨѶ��One-Way
Communication����
2.�����Ҫȷ�ϣ����Ը�����Ҫȷ�ϵ�ʱ�䳤�̽����жϡ�ʱ�䳤�ĸ������첽ͨѶ��ʱ��̵ĸ�����ͬ��ͨѶ����Ȼʱ�䳤�̵ĸ����Ǵ�������۸�����ǿ۱���
3.����ȥ����Ϣ�Ƿ�������һ��ָ���ִ�У����������������ͬ�������������첽��
������Σ�����ʦ�Dz��������ڻ���֮�У�����������������ľ�����������һ��ͨѶ������߽���ͨѶ���ܵ�ʱ����ʦ�DZ���������ͬ�������ǡ��첽���ľ����������ߵĽ����ǡ��첽ͨѶ����ʱ�ֲ�ʽ���б��ģ�;���һ����ѡ�
Who�������߽����߽���
�ڽ���ͨѶ���������ʱ����Ҫ�ش������һ�����������ǣ���Ϣ�ķ��ͷ��Ƿ����˭��������Ϣ�����߷���������Ϣ���շ��Ƿ����˭��������Ϣ���������ʦ�Ľ����ǣ���Ϣ�ķ��ͷ��ͽ��շ������ĶԷ���˭���Լ�������ֲ�ʽ���б��ģ�;���һ����ѡ���Ϊ�����ֳ����£��ֲ�ʽ���мܹ��������Ľ����ܸ�ϵͳ�ܹ�������Щ�ô���
1.�����Ƿ��ͷ����ǽ��շ���ֻ��Ҫ����Ϣ�м��ͨѶ���ӿ�ͳһ��ͳһ��ζ�Ž��Ϳ����ɱ���
2.�ڲ�Ӱ�����ܵ�ǰ���£�ͬһ����Ϣ�м�����𣬿��Ա���ͬҵ������������ζ�Ž�����ά�ɱ���
3.���ͷ����߽��շ�������IJ������˵ı仯��Ӱ���Ӧ����һ������ź��ζ�����Ϳ���չ��
Where����Ϣ�ݴ����
�ڽ���ͨѶ���ͷ���Ƶ�ʱ�����ʦ�ǿ��յ������ǣ������Ϣ����Ѹ�ٴ������������ѻ���ô�졢�ܷ�ֱ������������������������ȷ�ϴ�����Ϣ���棬������Ϣ��Ӧ�ñ���������Ӧ�ÿ��Ƿֲ�ʽ���б��ģ���ܣ���Ϊ���п����ݴ���Ϣ��
How������
��ͨѶ������мܹ���һϵ�еĻ�����ս��ӭ��������������
1.�����ԣ���α���ͨѶ�ĸ߿��á�
2.�ɿ��ԣ���α�֤��Ϣ���ɿ��ش��ݡ�
3.�־û�����α�֤��Ϣ���ᶪʧ��
4.����������Ӧʱ�䡣
5.��ƽ̨�����ԡ�
���ǹ���ʦ�����������㹻����Ȥ�������г����ʱ�䣬����һ���������ָ��ķֲ�ʽ���б��ģ�;���һ����ѡ��
�ֲ�ʽ���б�̶���
���Ѹ����ֲ�ʽ���б��ģ�͵ľ�ȷ���壬���ڱ���ƫ����Ӧ�ã����߲���������ȫ����ij������ģ�͡�������ԣ��ֲ�ʽ���б��ģ�Ͱ��������ɫ�������ߣ�Sender�����ֲ�ʽ���У�Queue���������ߣ�Receiver���������ߺͽ����߷ֱ�ָ����������Ϣ�ͽ�����Ϣ��Ӧ�ó�������
��Ҫ�ص���ȷ�ĸ����Ƿֲ�ʽ���У������ṩ���¹��ܵ�Ӧ�ó�������1. ���ա������ߡ���������Ϣʵ�壻2.
���䡢�ݴ��ʵ�壻3. Ϊ�������ߡ��ṩ��ȡ����Ϣʵ��Ĺ��ܡ����ض��ij����£�����Ȼ������Kafka��RabbitMQ����Ϣ�м����������չ����ʽ�������ڴˣ����磺
1.���п�����һ�����ݿ�ı��������߽���Ϣд����������ߴ����ݱ������Ϣ��
2.���һ�����������д��Redis���ڴ�Cache���棬��һ�������Cache�����ȡ���������������һ�ֲַ�ʽ���С�
3.��ʽ�������ĵ�����������Ҳ��һ�ֶ��С�
4.���͵�MVC��Model�Cview�Ccontroller�����ģʽ���棬���Model�ı仯��Ҫ����View�ı仯��Ҳ����ͨ�����н��д��䡣����ķֲ�ʽ���п��������ݿ⣬Ҳ������ij̨�������ϵ�һ���ڴ档
����ģ��
������ķֲ�ʽ���б�̳���ģ���ǵ�Ե�ģ�ͣ���������ģ�;��ڸĻ���ģ���ϸ���ɫ�������ͽ����仯�����µIJ�ͬ����ͼ��������ԣ���ͬ�����ķ����ߡ��ֲ�ʽ�����Լ�����������γ��˲�ͬ�ķֲ�ʽ���б��ģ�͡���ס��������͵ij���ģ�ͽṹ����������ͽ�ģ����������Ҫ��ͬʱҲ��������ѧϰ���������Դ����Լ����˵Ĵ��롣
��Ե�ģ�ͣ�Point-to-point��
����ģ���У�ֻ��һ�������ߡ�һ�������ߺ�һ���ֲ�ʽ���С�����ͼ��ʾ��

������������ģ�ͣ�Producer�Cconsumer��
��������ߺͽ����߶������ж������ʵ����������ͬ�����ͣ����ǹ���ͬһ�����У���ͱ���˱���������������ģ�͡��ڸ�ģ�ͣ�������ɫһ���֮Ϊ�����ߣ�Producer�����ֲ�ʽ���У�Queue���������ߣ�Consumer����
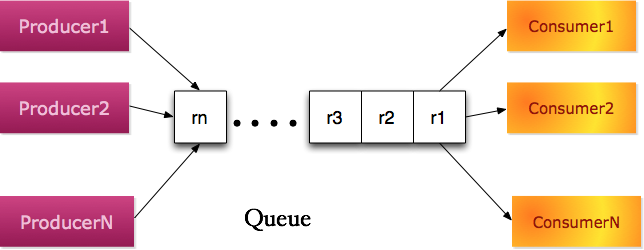
��������ģ�ͣ�PubSub��
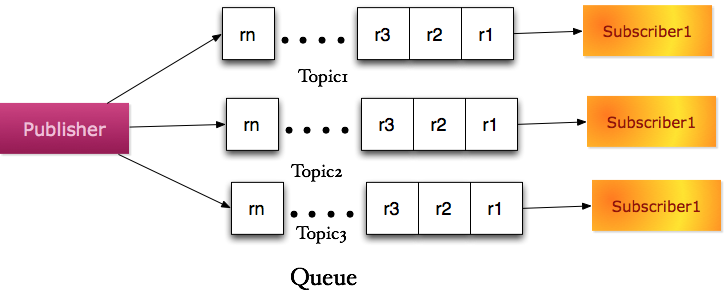
���ֻ��һ����ߣ������߽���������Ϣʵ�尴�ղ�ͬ�����⣨Topic���ַ�����ͬ�������С�ÿ��������ж�Ӧ��һ������ߡ���ͱ���˵��͵ķ�������ģ�͡��ڸ�ģ�ͣ�������ɫһ���֮Ϊ�����ߣ�Publisher�����ֲ�ʽ���У�Queue���������ߣ�Subscriber����
MVCģ��
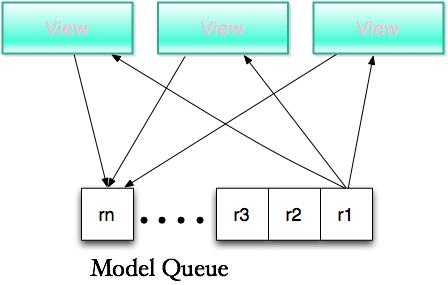
��������ߺͽ����ߴ�����ͬһ��ʵ���У����ǹ���һ���ֲ�ʽ���С���ͺ����MVCģ�͡�
���ģ��
Ϊ���ö��߸��õ�����ֲ�ʽ���б��ģʽ������ォ����һЩ�������ĸ�����һЩ�Ա�
��
�ֲ�ʽ����ģ�ͱ�̺��첽���
�ֲ�ʽ���б��ģ�͵�ͨѶ����һ���Dz����첽���ƣ�������������ͬ���첽��̡�
���ȣ��������е��첽��̶���Ҫ������еĸ�����磺�ֵIJ���ϵͳ�첽I/O��������ͨ��Ӳ���жϣ�
Hardware Interrupts����ʵ�ֵġ�
��Σ��첽��̲���һ����Ҫ����̣�������Ӧ�ó�������һ���Ƿֲ�ʽ������
��ֲ�ʽ���б��ģ��ǿ�������ߡ������ߺͷֲ�ʽ������������ɫ��ͬ��ɵļܹ��������ֽ�ɫ���첽���û��̫�������
�ֲ�ʽ����ģʽ��̺���ʽ���
����Spark Streaming��Apache Storm����ʽ��ܵĹ㷺Ӧ�ã���ʽ��̳��˵�ǰ�dz����еı��ģʽ�����DZ����������ķֲ�ʽ���б��ģ�ͺ���ʽ��̲���ͬһ���
���ȣ����ĵĶ��б��ģʽ���������κο�ܣ�����ʽ������ھ������ʽ����ڵı�̡�
��Σ��ֲ�ʽ���б��ģ����һ����������������ע��θ���ʵ��������зֲ�ʽ���б�̽�ģ����ʽ������������һ�㶼ͨ�����д��ݣ���������ʽ��̵Ĺ�ע��ȽϾ۽�������ע��δ���ʽ������ȡ��Ϣ��������map��reduce��
join��ת�ͣ�Transformation�������������µ������������ս��л��ܡ�ͳ�ơ�
�ֲ�ʽ���б�̣���ʵսƪ
�������е���Ŀ����������������������ʵ������ʵսƪ�Ĺ�ע����ѵ����ģ˼·��������Щ���Ӷ�������ս����˼���ܹ�����������н��⡣�����ڱ�����Ҫ����Щϸ�ڲ�δ����������Щϸ�ڲ���Ӱ�콲��������ԡ���һ���棬�ر����������������˷ѽ⣬Ϊ��ʹ�������˳��������Ҳ�����һЩ��ͨ���������ӡ�ͨ����ƪ�Ľ��⣬ϣ���Ͷ���һ��ȥʵ������δ��������ȥ���ֲܷ�ʽ���б��ģ�͡���
��Ҫ�������ǣ�����Ľ�������������������������ŷ��������ǣ��κ�һ�������ӵ����⣬��û�����Ž����������̸����Ψһ�Ľ��������ʵ���ϣ�����ʦÿ����Ѱ��ֻ��������һ��Լ�������µĿ��з�������Ȼ��ͬ��Լ���ᵼ�²�ͬ�ķ�����Լ�����ɳڶȾ����˹���ʦ�Ŀ�ѡ�����Ŀ���ȡ�
��Ϣ�ɼ�����
��Ϣ�ɼ�����Ӧ�ù㷺�����磺���Ʒѡ��û���Ϊ�ռ��ȡ����������ľ�����Ŀ��Ϊ���ϵͳ���һ�߿��õIJɼ��Ʒ�ϵͳ��
���͵Ĺ��CPC��CPM�Ʒ�ԭ���ǣ��ռ��û��ڿͻ��˻�����ҳ�ϵĵ���������Ϊ�����յ����������мƷѡ��Ʒ�ҵ�������µ���������
1.�ɼ��ߺʹ����߽���ɼ������ڿͻ��ˣ����Ʒѷ����ڷ���ˡ�
2.�Ʒ���ǮϢϢ��ء�
3.�ظ��Ʒ���ζ�����ѡ�
4.�Ʒ��Ƕ�̬ʵʱ��Ϊ����Ҫ����Ԥ��Լ����������ij���Ԥ�㣬����Ͷ����Ҫֹͣ��
5.�û�������͵�����dz���
��ս
�Ʒ�ҵ��ĵ������������Ǵ�����������ս��
1.��������������������͵�����dz���������Ҫ���һ�����������IJɼ��ܹ���
2.�߿����ԣ����Ʒ���Ϣ�Ķ�ʧ��ζ��ֱ�ӵĽ�Ǯ��ʧ���κδ����������ı�����Ӧ�õ���ϵͳ�����á�
3.��һ����Ҫ���Ʒ���һ��ʵʱ��̬�������̣���Ҫ�ܵ�Ԥ���Լ�����ռ���������͵����Ϊ������ܿ��ٴ��������ܵ���Ԥ�㻨�������ߵ����Ԥ����ȷ�����Բɼ�������ϢӦ������̵�ʱ���ڴ��䵽�Ʒ����Ľ��мƷѡ�
4.������Լ����������������������û���Ϊ�����ظ��Ʒѵȡ���Ҫ��Ʒ���һ��������Ϊ���Ƿֲ�ʽ��Ϊ��
5.�־û�Ҫ���Ʒ���Ϣ��Ҫ�־û���������Ϊ���������������ռ��������ݲ�����ʧ��
��˼
�ɼ��ĸ߿�������ζ��������Ҫ��̨������ͬʱ�ɼ���Ϊ�˱��ⵥIDC���ϣ��ɼ���������Ҫ�����ڶ�IDC���档
ʵ��һ���߿��á�������������һ���Ե���Ϣ����ϵͳ��Ȼ��һ����ս��Ϊ�˿�����Ŀ�����ɱ������ÿ�Դ����Ϣ�м��������Ϣ����ͳ��˱�Ȼѡ��
������Լ��Ҫ���н��мƷѣ����ԼƷ�ϵͳ�����ں���IDC��
�Ʒѷ������IJɼ���������ɼ�����Ҳ��������˭���мƷѡ�
�������Ϲ�˼��������Ϊ�ɼ��Ʒѷ��ϵ��͵ġ�������������ģ�͡���
�ܹ�
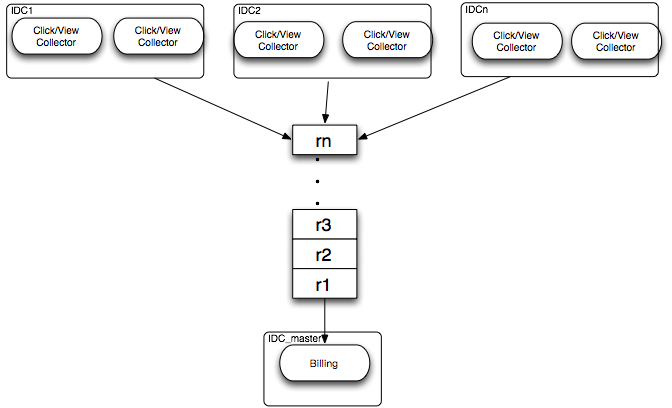
�ɼ��Ʒ�ϵͳ�ܹ�ͼ���£�
1.�û��������ռ�����Click/View Collector����Ϊ�����߲����ڶ�������������ռ���������ԡ�
2.ÿ��������ɼ���������ͨ����Ϣ�����м�����͵����Ļ���IDC_Master��
3.Billing������Ϊ�����߲����ں��Ļ������мƷѡ�
���ô˼ܹ������ǿ��������·�������һ���Ż���
1.��߿���չ�ԣ����һ��Billing����ʵ����������������Ҫ���ԶԲɼ������ݽ������������Topic
Partition���Ʒѣ������÷�������ģʽ����߿���չ�ԣ�Scalability����
2.ȫ�����غͷ����ס����ü��мƷѼܹ�����˵��������ص����⣬��һ���棬��Ҳ���������ṩ��ȫ����Ϣ��
3.��Ʒ�ϵͳ�Ŀ����ԡ��������ĵ��������Ż����ԣ��ڱ��ϼƷ�ϵͳ�����Ե�ͬʱ����Ʒ�ϵͳ�����ԡ�
�ֲ�ʽ������£�Distributed Cache Replacement��
������һ���dz������ĸ������������ϵͳ�����㼶�����͵Ļ�������������£�
1.���յ�������ȶ�ȡ���棬��������ؽ����
2.������治���У���ȡDB�������־ò�����»��沢���ؽ����
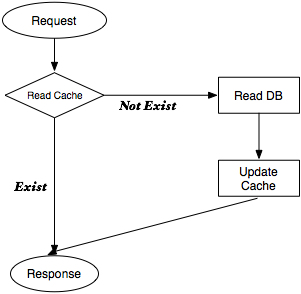
�����Ѿ����뻺������ݣ������ʱ������Ƶ����һ���������⣬��������»��ƣ�Cache
Replacement Algorithms �������͵Ļ�����»��ư�������������ʹ���㷨��LRU���������ʹ���㷨��LFU���������ֻ�����»��Ƶĵ���ʵ���ǣ�����һ����̨���̣������������û��ʹ�õģ�������һ��ʱ��������ʹ�õ����ݡ����ڴ��ڻ���������ƣ���һ��������û�����л���ʱ��ҵ�����Ҫ�ӳ־ò��л�ȡ��Ϣ�����»��棬���һ���ԡ�
��ս
�ֲ�ʽ�����������»��ƴ������µ����⣺
1.����һ���Ե͡��ֲ�ʽ�����м�ֵ�����Ӷ�����LRU����LFU�㷨�������ںܳ����ڷֲ�ʽ�����У���LRU�㷨�����������������Ϊÿ��Keyֵ����һ������ʱ�䣨TTL��������ʱ�䵽�ںü�ֵ�ӻ����������ȥ�����ǵ��ֲ�ʽ�������Ӵ�ļ�ֵ����������ʱ�����������õıȽϳ�����͵��»���ͳ־ò����ݲ�һ��ʱ��ܳ����������ʱ�����ù��̣��������������л��汻�ȶ�ȡ�־ò㣬ϵͳ��Ӧʱ��ἱ���
2.�����ݲ����á��ںܶೡ���£����ڷֲ�ʽ����ͳ־ò�ķ����������̫���ڻ��治���е�����£�һЩӦ�ò���᳢�Զ�ȡ�־ò㣬��ֱ�ӷ��ؿս���������Ļ������������ζ�������ݵĿ����Ծͱ������ˡ���ͳ�ƵĽǶ��������¼�ֵ��Ҫ�ȴ�����������ڲŻ���á�
��˼
��������ķ������ֲ�ʽ������Ҫ����������ǣ��ڱ�֤��ȡ���ܵ�ǰ���£������ܵ���������ݵ�һ���Ժ������ݵĿ����ԡ������Ȼ�ٶ���������ʵļ�ֵ���п��ܱ��ٴη��ʣ�����LRU����LFU������ǰ�ᣩ����ֵÿ�α����ʺ�һ���첽���¾�����߿����Ժ�һ���������ʱ���������Ǹ�����Ҫ����ҵ����Ҫ���ȡ�ͻ�����·ֿ�����������Ӧ�ù���һ�������ļ��еĻ�����·����н��л�����µ�����һ���ô�������Ƶ�ʿ��ơ�������һ��ʱ���ڣ��ܶ����ͷ��ʼ�ֵ�����������˹�ֲ�����ʱ�����ظ���ͬһ����ֵ���и���Cache������������Եĺô���������ɻ������ܵ��½���ͨ������ͬһ��ֵ�ĸ���Ƶ�ʿ��Դ������⣬ͬʱ����������������ݵ�һ���ԣ��μ��������Ż�����
����������ҵ����ʷ���Ҫ�������ֵ���ٴ����������·�������֮�䲻���ĶԷ���ҵ��Ҫ���١������ܵ�ʵ�ִ��������ֵ��Ϣ�Ĵ��䣬�����ֲܷ�ʽ��Ϣ�м������һ����ѡ�������һ�������һ�����͵ķֲ�ʽ���б��ģ�͡�
�ܹ�
����ͼ�����е�ҵ��������Ϊ�����ߣ��ڷ���ҵ����봦��֮ǰ�������ֵд������ܶ��С�Cache
Updater��Ϊ�����ߴӶ����ж�ȡ�����ֵ�����־ò������ݸ��µ������С�
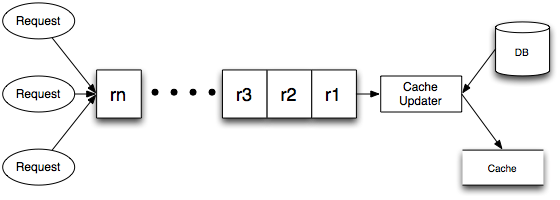
���ô˼ܹ������ǿ��������·�������һ���Ż���
1.��߿���չ�ԣ����һ��Cache Updater��������������Ҫ���ԶԼ�ֵ�������������Topic
Partition�����в��л�����£������÷�������ģʽ����߿���չ�ԣ�Scalability����
2.����Ƶ�ʿ��ơ�������¶����д��������ڷ�������ģʽ��ͬһ�����⣨Topic���ļ�ֵ���д�����Cache
Updater���Կ��ƶ�ͬһ��ֵ���ڶ����ڵĸ���Ƶ�ʣ��μ����������Ż�����
��̨������
���͵ĺ�̨������Ӧ�ð���������������ƱԤ��ϵͳ����Ʊѡ���ȡ���������Ե�������Ϊ��Ӫ��Ա����������һ�ο���Ϊ�����Ӫ��Ա����������������Ӧ�ó����ͻ�Ʊ����dz����ơ����������˵���ӳ������ԣ����Ļ��ϻ�Ʊ�������Ӫ��Ա�������������ֳ���ͬʱ���⡣���͵Ĺ�������Ҫ���������Σ�����ɸѡ�Ρ����������Ρ����磬�ڻ�ƱԤ������������ɸѡ���û�ѡ���ض�ʱ�䡢�ض����͵Ļ����ڹ��������Σ��û��µ������Ʊ��
��ս
������������������������ս��
1.����һ�������⡣�Ի�ƱԤ��Ϊ�����û�ɸѡ��Ʊ�����չ���֮��������һ����ʱ�ӣ���ζ����������֮�������Dz�һ�µġ���ɸѡ�Σ�����ʦ��������Ƿ���г�Ʊ�����������������������֤��Ʊ�ɹ�����֮�������ɸѡ��ʱ��������Ʊ�������ϵͳЧ�ʺͳ�Ʊ��������
2.Լ�����⡣����������Ҫ����ܶ�Լ������Ҫ�����������ͣ���̬Լ����������ߵIJ�����Ϊ�йأ����繺���Ż�Ʊ�ľ�������������ɸѡ���Ρ�����Լ��������Լ������ͨ���������չʾ������һ���û�������5�Ż�Ʊ����ЩƱӦ������ͬһ��������ٽ�λ�á���
3.�Ż����⡣��������������Լ���µ��Ż������ǵ��͵�ͳ���Ż����⣬��ͳ���Ż�������Ҫ�Ƚϳ���ʱ�䡣
4.��Ӧʱ�����⡣���ڶ�������һ��������ζ�Ŷ�������������Щ����Ĵ���������Ҫ��ѭ������ԭ��All
or Nothing�������ݲ��棬����ζ�Ź���֮����Ҫ���㴮�л�����Serializability�������������Ĵ��л�������ζ������ͻ�ӳ�����ʧ�ܡ��������ӳٻ��������µij�ʱ�ӣ����Ǹߴ���ʧ���ʣ��������˺��û����顣
��˼
������û�ɸѡ�����չ�����Ϊ��Ϣ�洢��������������������ϵͳ����ʱ����������ϵͳ���߱��������������ȫ����Ϣ���߱����������Լ���������½���ͳ���Ż���������������������β��õ�ʵ�����𣬾Ϳ��Ա��������������⣬ͬʱҲ��ζ��û������ͻ������Ҳ�����������������ӳ����⡣
��������˼·���ڶ������ϵͳ��ģ���У�ɸѡ�εĹ���ϵͳ���䵱�����߽�ɫ����������ϵͳ���䵱�����߽�ɫ��ɸѡ������Ϊ��Ϣ������֮����д��ݡ�����ǵ��͵ķֲ�ʽ���б�̼ܹ������ݹ����������IJ�ͬ�����Բ������ݿ��Դ�ķֲ�ʽ��Ϣ�м����Ϊ�ֲ�ʽ���С�
�ܹ�
�üܹ���������ͼ��
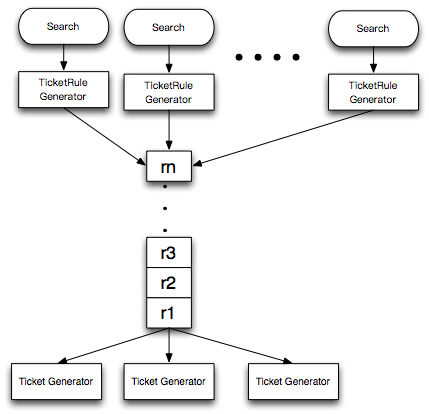
1.�û���ѡ���й��������������Ҫ��һЩ����ɸѡ������
2.�û��������������TicketRule Generator�������е�ɸѡ����װ�ɹ�����Ϣ�����͵���������ȥ��
3.Ticket Generator��Ϊһ�������ߣ�ʵʱ�Ӷ����ж�ȡ������������ʼ��������������
���øüܹ��������������������˳��Ż���ԭ�������ⶼ�ܵõ��ȽϺóɹ���
1.���������Ƴٵ����������Σ����Լ�������������Χ�����̶ȵĽ������������������߲�����Ӱ�췶Χ��
2.�����Ҫ����ͳ���Ż������Խ�Ticket Generator�Ե���ģʽ���в��𣨲μ����������Ż�����������Ticket
Generator���Զ�ȡһ��ʱ���ڵĹ���������ȫ���Ż������磬�����ǵ���Ŀ�У���ij�������£���Ӫ��Ա��Ҫ����ּ���ƽԭ����ͬ�������Ӫ��Ա�Ĺ�������Ӧ�ýӽ�����ͬ�������Ӫ��Ա��������Ӧ���������֡���������н���ͳ���Ż���ʵ�������Ż���������ѡ�
3.������Լ�������ԡ����磬�����ǵij������棬ÿ����Ӫ��Աÿ���ܹ������Ĺ��������������Ƶģ�������ò��д����ķ�ʽ������������Լ���������ʵʩ�� |






