| БрМЭЦМі: |
БОНкжївЊНщЩмTsFileЕФЮФМўИХРРЁЂTsFileЕФЪ§ОнПщЯрЙиФкШн
БОЮФРДздПЊдДВЉПЭ ЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
ЩЯвЛеТСФЕНааЪНДцДЂЁЂСаЪНДцДЂЕФЛљБОИХФюЃЌВЂНщЩмСЫ TsFile ЪЧШчКЮДцДЂЪ§ОнвдМАЛљБОИХФюЁЃЯъЧщЧыМћЃК
ЪБађЪ§ОнПт Apache-IoTDB дДТыНтЮіжЎЮФМўИёЪНМђНщЃЈШ§ЃЉ
TsFileЮФМўИХРР

вЛИіЭъећЕФ TsFile ЪЧгЩЭМжаЕФМИДѓПщзщГЩЃЌЭМжаЕФЪ§ОнПщгыЫїв§ПщжЎМфЪЙгУ 1 ИізжНкЕФЗжИєЗћ
2 РДНјааЗжИєЃЌетИіЗжИєЗћЕФвтвхЪЧЕБ TsFile Ы№ЛЕЕФЪБКђЃЌЫГађЩЈУш TsFile ЪБЃЌвРШЛПЩвдХаЖЯЯТвЛИіЪЧ
MetaData ЪЧЪВУДЖЋЮїЁЃ
1. ЪЖБ№ЗћЃЈMagicЃЉ
ЯждкИїжжШэМўЮхЛЈАЫУХЃЌКмЖрШэМўЖМгЕгаздМКЕФЮФМўИёЪНгУРДДцДЂЪ§ОнФкШнЃЌЕЋЕБгВХЬЩЯЮФМўЗЧГЃЖрЕФЪБКђШчКЮгааЇЕФЪЖБ№ЪЧЗёЮЊздМКЕФЮФМўЃЌШЗШЯПЩвдДђПЊФиЃПОГЃгУ
windows ЯЕЭГЕФХѓгбПЩФмЛсЯыЕНгУРЉеЙУћЃЌЕЋМйШчЮФМўУћЖЊЪЇСЫЃЌФЧЮвУЧШчКЮжЊЕРетИіЮФМўЪЧВЛЪЧФмБЛГЬађе§ШЗЗУЮЪФиЃП
етЪБКђЭЈГЃЛсЪЙгУвЛИіЖРгаЕФзжЗћЬюГфдкЮФМўПЊЭЗКЭНсЮВЃЌетбљГЬађжЛвЊЗУЮЪ
1 ИіЙЬЖЈГЄЖШЕФзжЗћОЭжЊЕРетИіЮФМўЪЧВЛЪЧздМКФме§ГЃЗУЮЪЕФЮФМўСЫЃЌЕБШЛЃЌTsFile зїЮЊвЛИіЪ§ОнПтЮФМўЃЌПЯЖЈашвЊдкетИіЪЖБ№ЗћЩЯОЋаФДђдьвЛЗЌЃЌЫќПДЦ№РДЪЧетбљЃК
(decimal) 84
115 70 105 108 101
(hex) 54 73 46 69 6c 65
(ASCII) T s F i l e |
ЗЧГЃ cool ЁЃ
2.ЮФМўАцБОЃЈVersionЃЉ
дйОЋУюЕФЩшМЦвВФбУтВњЩњвЛаЉЮЪЬтЃЌФЧУДОЭашвЊЩ§МЖЃЌФЧУДЮФМўФкШнвВвЛбљЃЌгаЪБКђЕБФуЕФИФЖЏЬиБ№ДѓСЫЃЌОЭЛсГіЯжЭъШЋВЛМцШнЕФСНИіАцБОЃЌетИіКмКУРэНтВЛЙ§ЖрНтЪЭЁЃTsFile
жаВЩгУСЫ 6 ИізжНкРДБЃДцЮФМўАцБОаХЯЂЃЌЕБЧА 0.9.x АцБОПДЦ№РДОЭЪЧетбљЃК
(decimal) 48
48 48 48 48 50
(hex) 30 30 30 30 30 32
(ASCII) 0 0 0 0 0 2 |
3.Ъ§ОнПщ
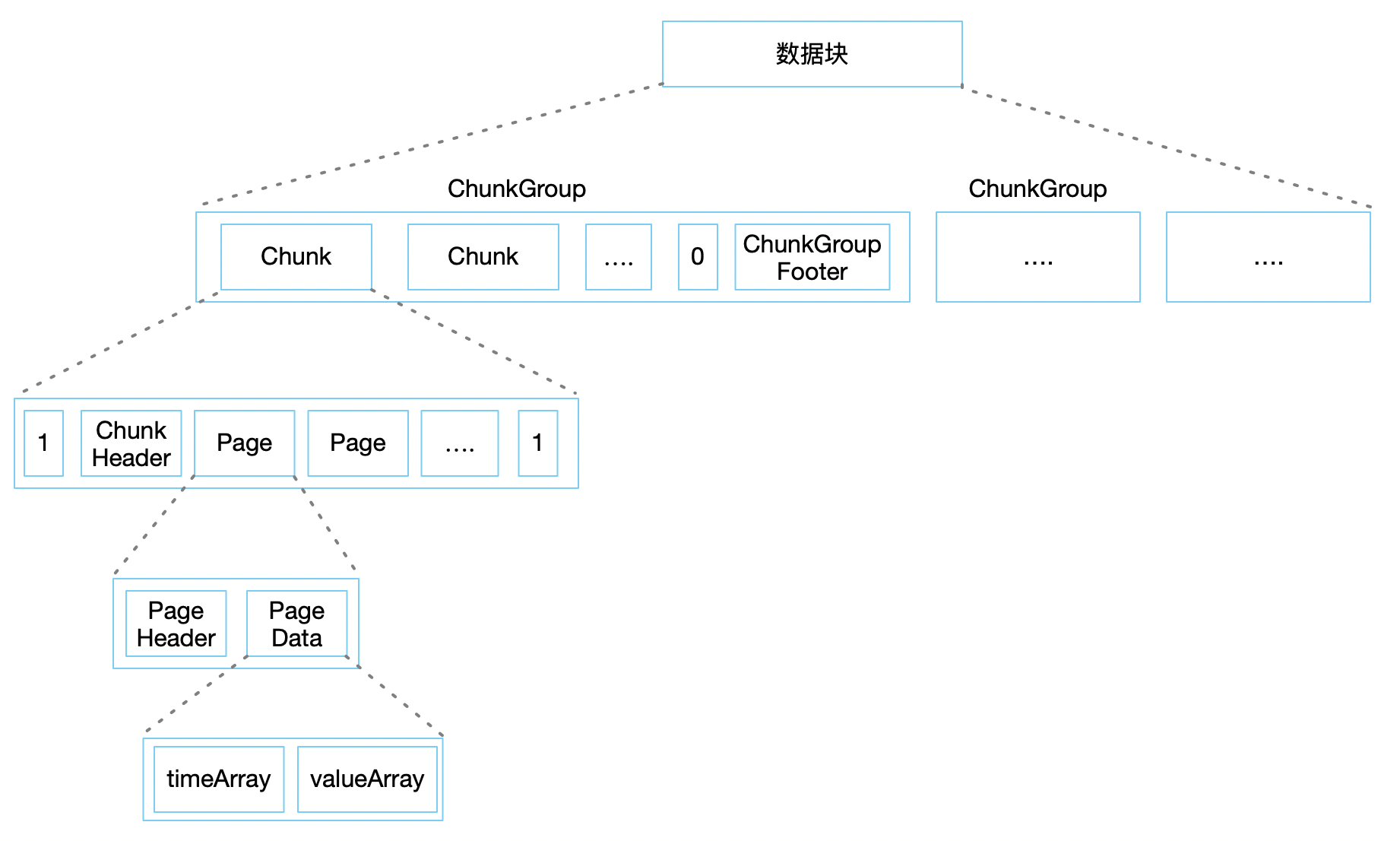
3.1 ChunkGroup
ЮФМўЕФЪ§ОнПщжаАќКЌСЫЖрИі ChunkGroup ЃЌЦфжа ChunkGroup ЕФИХФювбОдкЩЯвЛеТСФЙ§ЃЌЫќДњБэСЫЩшБИ(ТпМИХФюЩЯЕФвЛИіМЏКЯ)вЛЖЮЪБМфФкЕФЪ§ОнЃЌдк
IoTDB жаГЦЮЊ DeviceЁЃ
дкЪЕМЪЕФЮФМўжаЃЌChunkGroupЪЧгЩЖрИі Chunk КЭвЛИі ChunkGroupFooter
зщГЩЁЃЦфжазюКѓвЛИі Chunk ЕФНсЮВКЭ ChunkGroupFooter жЎМфЪЙгУ 1 ИізжНкЕФЗжИєЗћ
0 РДзіЧјЗжЃЌChunkGroupFooter УЛгаЪВУДОпЬхзїгУЃЌВЛзіЯъЯИНтЪЭЁЃ
3.2 Chunk
вЛИі ChunkGroup жаАќКЌСЫЖрИі ChunkЃЌЫќДњБэСЫВтЕуЪ§Он(ТпМИХФюЩЯЕФФГвЛРрЪ§ОнЕФМЏКЯ,ШчЬхЮТЪ§Он)ЃЌдк
IoTDB жаГЦЮЊ MeasurementЁЃ
дкЪЕМЪЮФМўжа Chunk ЪЧгЩ ChunkHeader КЭЖрИі Page зщГЩЃЌВЂБЛ 1 ИізжНкЕФЗжИєЗћ
1 АќЙќЁЃChunkHeaderжажївЊБЃДцСЫЕБЧА Chunk ЕФЪ§ОнРраЭЁЂбЙЫѕЗНЪНЁЂБрТыЗНЪНЁЂАќКЌЕФ
Pages еМгУЕФзжНкЪ§ЕШаХЯЂЁЃ
3.3 Page
вЛИі Chunk жаАќКЌЖрИі PageЃЌЫќЪЧвЛИіЪ§ОнзщжЏЗНЪНЃЌЪ§ОнДѓаЁБЛЯожЦдк 64K зѓгвЁЃ
дкЪЕМЪЮФМўжагЩ PageHeader КЭ PageData зщГЩЁЃЦфжа PageHeader РяжївЊБЃДцСЫЃЌЕБЧА
page РяЕФвЛаЉдЄОлКЯаХЯЂЃЌАќКЌСЫзюДѓжЕЁЂзюаЁжЕЁЂПЊЪМЪБМфЁЂНсЪјЪБМфЕШЁЃЫћЕФДцдкЪЧЗЧГЃгавтвхЕФЃЌвђЮЊЕБФГаЉЬиЖЈГЁОАЕФЖСЪБКђЃЌВЛБивЊНтПЊ
page ЕФЪ§ОнОЭФмЙЛЕУЕННсЙћЃЌБШШчЫЕ selece ЬхЮТ from ЭѕЮх where time >
1580950800 ЃЌ ЕБЖСЕН PageHeader ЕФЪБКђЃЌевЕН startTime КЭ endTime
ОЭФмХаЖЯЪЧЗёПЩвдЪЙгУЕБЧА pageЁЃ етИіОлКЯаХЯЂЕФНсЙЙЭЌбљГіЯждкЫїв§ПщжаЃЌЯТвЛеТдйОпЬхСФетИіОлКЯНсЙЙЁЃ
3.4 PageData
вЛИі Page жаАќКЌСЫвЛИі PageDataЃЌРяУцгаСНИіЪ§зщЃКЪБМфЪ§зщКЭжЕЪ§зщЃЌЧветСНИіЪ§зщЕФЯТБъЪЧЖдЦыЕФЃЌвВОЭЪЧЪБМфЪ§зщжаЕФЕквЛИіЖдгІжЕЪ§зщжаЕФЕквЛИіЁЃОйИіР§згЃК
timeArray: [1,2,3,4]
valueArray: ['a', 'b', 'c', 'd'] |
дкpageжаОЭЪЧетбљБЃДцЕФЪ§ОнЃЌЦфжа 1 ДњБэСЫЪБМф 1970-01-01 08:00:00 КѓЕФ
1 КСУыЃЌЖдгІЕФжЕОЭЪЧ 'a'ЁЃ
Ъ§ОнПщеЙЪО
ЮвУЧМЬајЪЙгУЩЯвЛеТСФЕНЕФЪОР§Ъ§ОнРДеЙЪОеце§ЕФTsFileжаЪЧШчКЮБЃДцЕФЁЃ
| ЪБМфДС |
ШЫУћ |
ЬхЮТ |
аФТЪ |
| 1580950800 |
ЭѕЮх |
36.7 |
100 |
| 1580950911 |
ЭѕЮх |
36.6 |
90 |
ЕБЪ§ОнБЛаДШы TsFile жаЃЌДѓИХОЭЪЧЯТУцвЛИіеЙЪОЕФЧщПіЃЌетРяЪЁТдСЫЫїв§ВПЗжЁЃ
POSITION| CONTENT
-------- -------
0| [magic head] TsFile
6| [version number] 000002
// вђЮЊ 6ИізжНкЕФmagic + 6ИізжНкЕФ version Ыљвд chunkGroup
Дг 12 ПЊЪМ
||||||||||||||||||||| [Chunk Group] of wangwu
begins at pos 12, ends at pos 253, version:0,
num of Chunks:2
// етРяеЙЪОЕФЪЧ ChunkHeader жаБЃДцЕФаХЯЂ
12| [Chunk] of xinlv, numOfPoints: 1, time range:
[1580950800,1580950800], tsDataType:INT32,
[minValue:100,maxValue: 100,firstValue: 100,lastValue:100,sumValue:100.0]
| [marker] 1 // chunk ЕФеце§ПЊЪМЪЧДгетИіЗжИєЗћ 1 ПЊЪМЕФ
| [ChunkHeader] // header ЕФЪ§ОндкЩЯУцеЙЪОСЫ
| 1 pages //етРяБЃДцЕФОпЬхЪ§Он
| time:1580950800; value:100
// ЯТвЛИі chunk
121| [Chunk] of tiwen, numOfPoints:1, time range:
[1580950800,1580950800], tsDataType:FLOAT,
[minValue: 36.7,maxValue: 36.7,firstValue: 36.7,lastValue:36.7,
sumValue:36.70000076293945]
| [marker] 1
| [ChunkHeader]
| 1 pages
| time:1580950800; value:36.7
230| [Chunk Group Footer]
| [marker] 0 // chunkFooter КЭ chunk ЪЙгУ 0 зїЮЊЗжИє
| [deviceID] wangwu
| [dataSize] 218
| [num of chunks] 2
||||||||||||||||||||| [Chunk Group] of wangwu
ends |
ЛиЯыЮвУЧЕФВщбЏгяОф select ЬхЮТ from ЭѕЮх , ЕБОРњЙ§Ыїв§жЎКѓЛсЕУЕН offset ЕФжЕЕШгк
121 ЃЌетЪБКђЮвУЧжЛашвЊЕїгУreader.seek(121)ЃЌДгетРяПЊЪМОЭЪЧЫљгаЬхЮТЪ§ОнЕФПЊЪМЕуЃЌДгетРявЛжБЖСЕН
230 ЕФ ChunkGroupFooter НсЙЙЕФЪБКђЃЌОЭПЩвдЗЕЛиИјгУЛЇЪ§ОнСЫЁЃ
гааЫШЄздМКЪЕбщЕФХѓгбПЩвдЃЌв§Шы TsFile ЕФАќЃЌздааЪЕбщЃЌЯТУцИјГіВтЪдДњТыЃК
<dependency>
<groupId>org.apache.iotdb</groupId>
<artifactId>tsfile</artifactId>
<version>0.9.1</version>
</dependency> |
public static
void main(String[] args) throws IOException, WriteProcessException
{
MeasurementSchema chunk1 = new MeasurementSchema("tiwen",
TSDataType.FLOAT, TSEncoding.PLAIN);
MeasurementSchema chunk2 = new MeasurementSchema("xinlv",
TSDataType.INT32, TSEncoding.PLAIN);
Schema chunks = new Schema();
chunks.registerMeasurement(chunk1);
chunks.registerMeasurement (chunk2);
TsFileWriter writer = new TsFileWriter(new File("test"),
chunks);
RowBatch chunkGroup = chunks.createRowBatch("wangwu");
long[] timestamps = chunkGroup.timestamps;
Object[] values = chunkGroup.values;
timestamps[0] = 1580950800;
float[] tiwen = (float[]) values[0];
int[] xinlv = (int[]) values[1];
// аДШыЭѕЮхЕФЬхЮТ
tiwen[0] = 36.7f;
//аДШыЭѕЮхЕФаФТЪ
xinlv[0] = 100;
chunkGroup.batchSize++;
timestamps[1] = 1580950800;
// аДШыЕкЖўЬѕЭѕЮхЕФЬхЮТ
tiwen[1] = 36.6f;
//аДШыЕкЖўЬѕЭѕЮхЕФаФТЪ
xinlv[1] = 90;
chunkGroup.batchSize++;
writer.write(chunkGroup);
writer.close();
} |
жДааЭъГЩжЎКѓФуПЩвдЪЙгУ IoTDB жаЕФ TsFileSketchTool РДВщПДЮФМўНсЙЙЃЌЕУЕНЮФжаЪОР§ЕФеЙЪОНсЙћЃЛЛђепЪЙгУ
od ЕШЙЄОпВщПДЃЌзЃЭцЖљЕФПЊаФЁЃIoTDB 0.9.1 АцБОЯТди
етвЛеТСФЕНСЫ TsFile ЗжЮЊСЫ Ъ§ОнПщ КЭ Ыїв§ПщЃЌВЂЧвНщЩмСЫЪ§ОнПщЕФОпЬхзщГЩВПЗжКЭВщбЏТпМЁЃФЧУДЫїв§ПщЪЧЪВУДНсЙЙЃЌдѕбљЭъГЩСЫдкДѓСПЛьдгЕФЪ§ОнжаЫбЫїЕНЕФЯывЊЕФЪ§ОнЃЌЧыГжајЙизЂЁЃ
|









