| 编辑推荐: |
本文讲述Smart
Data Market 是 TalkingData 作为数据行业的先行者推出的智能数据服务商城。Smart
Data Market 以下简称(SDMK)提供多种形式的数据服务,包括 API
服务、人群数据服务、异步服务等,TalkingData 希望通过这些数据服务降低
数据应用场景的难度,希望对您有所帮助
本文来自于微信号阿里云云栖号,由火龙果软件Delores编辑、推荐。 |
|
API 服务的一个重要功能是将用户对 API 接口的调用进行准确计量,在此基础上才能进行用户对服务的访问控制、计费计量等。今天要给大家分享的就是我们一步步构建并完善计量系统的过程。
首先 SDMK 上 API 服务的调用中与计量相关的有以下几个关键流程(与本次分享内容无关的流程未画出):
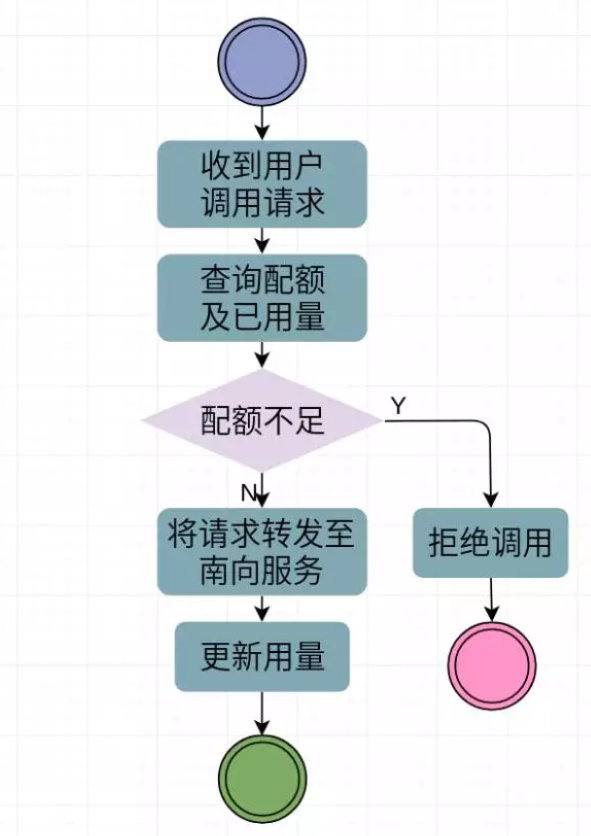
SDMK 收到用户的调用请求后,会查询该用户对该服务的配额,然后查询已用量,计算余量是否大于零来决定是否允许此次调用。如果允许,则将请求转发至具体的南向服务并更新用量。后续分享的内容均围绕着我们是如何实现计算已用量这个非常简单的流程,并一步步改进架构,提高其性能、健壮性和可扩展性。
早期实现 -
简单快速实现功能
在 SDMK 最早期开发阶段,可预期的时间内业务量不会很大,快速实现功能是最基本的需求。当时计量系统的实现如下:
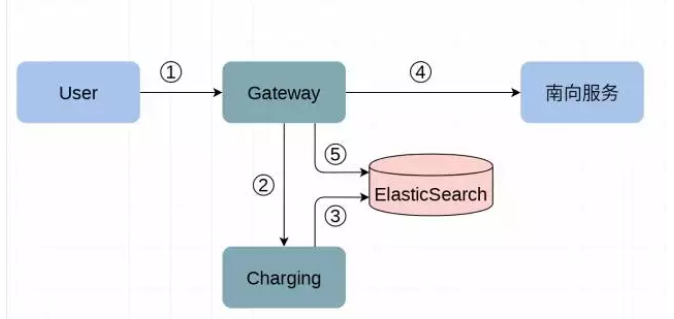
用户调用 SDMK 上的 API 服务,由 Gateway 模块接收用户的调用请求;
Gateway 询问 Charging 模块该用户对该服务的配额是否允许;
Charging 模块在 Mysql 中维护有用户-服务的配额,同时从 ES 中查询用户对该服务的已用量;
Gateway 根据 Charging 的返回结果决定是否向南向服务发起请求或直接拒绝用户请求;
Gateway 异步地将此次调用的信息写入 ElasticSearch;
这种简单架构中,Gateway 模块作为调用网关,分发处理所有用户对南向服务的调用;采用 ElasticSearch(以下简称 ES)存储所有调用日志,Gateway 异步地将调用日志写入 ES 中,Charging 模块负责配额管理和从 ES 中查询用量。在系统构建之初使用这个架构能够非常方便快速的开发出满足功能需求的计量系统,在早期也确实能够满足 SDMK 的业务需求。
但随着 SDMK 的业务量随时间激增,这种架构的缺点也非常明显的暴露出来:
每次调用都需要的已用量计算严重依赖于对 ES 的查询,而随着调用数据的积累和随业务发展的调用量急速增高,从 ES 查询已用量的时延不断升高。从早期的数十毫秒,到后来的上千毫秒,已经到了不可接受的程度;
每条调用记录入 ES 的时延也越来越高,影响计量的实时性。;
ElasticSearch-2.3.x 索引不支持调整分片数,不方便水平扩展;
性能优化 -
使用Lambda架构的重构
面对早期版本的问题,我们不得重构计量系统。经过讨论,我们决定保留调用日志入 ES 的路径,并使用 ES 中的数据作为基础数据计算< 用户,服务 >的按天用量;同时将调用信息推入 Kafka 中,增加一个实时处理流程来计算近两天的用量。最终形成了如下的已用量计算方案:
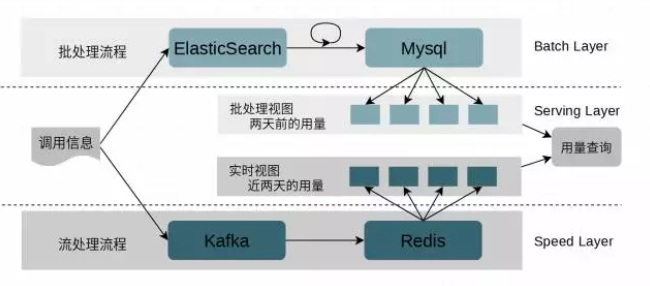
这是一个典型的 Lambda 架构系统。对用量的计算分为两个部分,批处理部分(批处理层)和实时流处理部分(速度层),最后由查询服务(服务层)聚合批处理层和快速层的数据提供查询服务。
批处理层
为了尽量少的改动,我们选择保留调用信息->ES 的流程,并把它作为 Lambda 架构的不变层。批处理流程为调用日志写入 ES,每天有一个定时任务从 ES 里计算前一天的所有<用户,服务>调用用量,然后将聚合后结果写入 Mysql 中。批处理的 Mysql 库中存储了两天前的所有<用户,服务>的按天调用计量信息。
相较于早期实现的版本,ES 不再为每次用量查询提供服务,这样 ES 的查询压力变得非常小,而更多的是调用日志入 ES 的操作。同时由于实时的计量数据不再通过批处理流程计算,因此数据入 ES 的延迟不再重要。此时 ES 的查询服务主要提供给报表和用量数据的批处理使用,不再为高频的 API 服务调用带来的用量查询所累。而且在可预见的未来,在当前每天一个的批处理间隔下,每次批处理任务是完全能够在一个批处理间隔内完成的。
这样还有一个重要的好处:批处理视图数据的重算变得非常容易。系统难免会因为业务需求、程序错误甚至故障而需要重算某些用量数据。这时候由于 ES 中存储了所有原始的调用数据,而且重算只需要在批处理间隔内完成就不会造成影响。这样对系统维护、业务演进都带来了极大的便利。
速度层
速度层为 调用数据->Kafka->Redis 的实时流处理过程。该流程为调用信息写入 Kafka,由消费者从 Kafka 中消费调用信息,然后将调用信息在 Redis 中进行增量计算。Redis 中存储了当天和昨天的所有< 用户,服务 >的按天调用计量数据。Redis 中的 key 由 用户-服务-时间区间起点组成,并且每个 key 在更新后都会更新 TTL 为两天。这样超期的 key(两天前的用量数据)会自动被删除,以达到 Redis 中只存储当天和昨天用量数据的目的。
经测试,Redis 可以达到非常高的读写性能,完全能够满足我们 API 调用的并发需求。而我们使用的 Kafka 集群的吞吐也完全能够满足业务需求。更重要的是,Kafka 的 topic 分区数可以调整,在业务量继续增长的时候完全可以通过横向扩展 Kafka 集群、增加 topic 分区数来扩展系统的容量。后继的消费者也可以通过增加节点来方便的扩展消费能力,从而使调用数据尽量不在 Kafka 内淤积,以此来保证计量的实时性。
服务层
服务层提供用量查询接口,用量查询时,从批处理视图中查出< 用户,服务 >两天前的所有用量数据;同时从实时视图中查出当天和昨天的用量数据;聚合到一起,就是该用户对该服务的总的用量数据。可见,查询操作会读一次 Mysql,两次 Redis,相较于之前从 ES 中扫一遍所有调用信息计算用量的方式快了上百倍(之前的方案到改进时耗时已经超过 1 秒,改进后方案耗时稳定在 10 毫秒左右)。
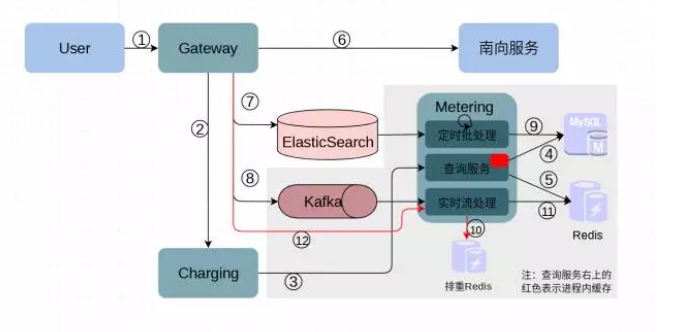
将上面的用量计算方案映射到实际的模块上,就形成了如下所示重构后计量系统的样子:
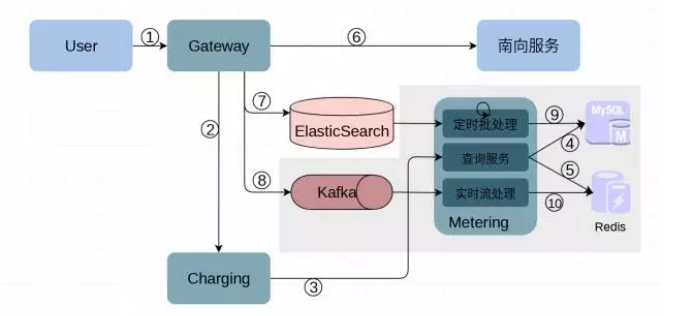
① 用户调用 SDMK 上的 API 服务,由 Gateway 模块接收用户的调用请求
② Gateway 询问 Charging 模块该用户对该服务的配额是否允许;
③ Charging 自己维护了配额,并到 Metering 查询服务用量;
④、⑤ Metering 查询服务到 Mysql 和 Redis 中聚合用量数据;
⑥ Gateway 根据 Charging 的返回结果决定是否向南向服务发起请求或直接拒绝用户请求;
⑦、⑧ Gateway 异步地将此次调用的信息写入 ElasticSearch 和 Kafka;
⑨ Metering 批处理部分定时将 ES 中的数据按天聚合到 Mysql 中;
⑩ Metering 实时流处理部分持续地从 Kafka 中消费调用消息在 Redis 中做增量计算;
图中灰色的部分就是重构时引入的部分:增加调用信息入 Kafka、增加 Metering 模块将计量查询功能从 Charging 中分离出来。Metering 分为三个部分,分别是定时批处理、实时流处理和查询服务。同时增加存储批处理结果的 Mysql 和存储实时计量数据的 Redis。
至此,计量系统经过 Lambda 架构的重构,性能得到了非常大的提高。而且在可以预见的时间内应该都能够通过简单方便的扩容来满足业务增长。
持续改进 -
在采坑中完善
1. 解决 Kafka 消费模式带来的用量重复计量
本以为可以放松一段时间,却没想到很快就遇到了计量重构后的第一个问题:实时视图中的用量数据会非常小概率的多算。虽然这发生的非常少,而且超算的量也非常少,并且超算的这部分也会在两天内被批处理视图内数据冲掉。但总归是一个缺陷。
经过排查,发现是我们使用的 Kafka 组消费模式带来的问题。所有的调用日志会被推送到 Kafka 的一个 topic 内,用来计算实时用量的消费者在同一个组内订阅这个 topic。
Kafka 组消费模式:
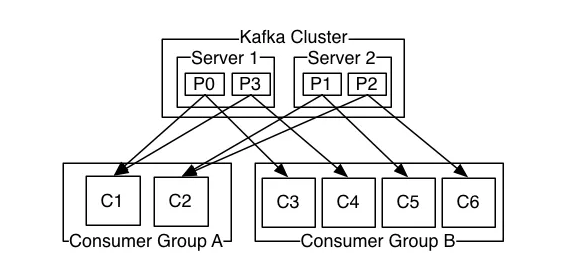
在我们使用的组消费模式下,每一条消息会被该 topic 的每个消费者组中的消费者至少消费一次。这种消息传递语义保证每一条消息会被每一个组消费,但有可能会被同一个组消费多次,这样在计算用量的时候就有可能会重复计算。
解决的方式也很简单,在 consumer 端消费到调用日志后进行排重。当然可能有声音说 Kafka 的后续版本实现了精确一次的消息传递语义,我们虽然没有调研是不是真的这样,但在 consumer 端进行排重仍然是很有意义的。因为这样就允许调用日志在发送端被重复发送,和消费者的重新消费。这种宽容可以带来很多好处,例如方便故障恢复后的快速处理可能丢失的消息等。
我们具体实现消息排重时又一次使用了 Redis。每一条调用日志都会有一个唯一的 traceId,每拿到一条调用消息,要到排重库里去看一下这个 traceId 是否已经出现过,同时将这个 traceId 写进排重库。Redis 的 GETSET 可以原子的完成这两个操作,避免了并发时可能会带来的问题。同时,由于 Redis 里只需要计算近两天内的用量数据,因此可以给排重库里的每个 traceId 设置两天的 TTL。这样排重库就不会慢慢被撑爆,而且可以根据平台上所有 API 调用的平均频度来预估排重库需要的内存。
2. 查询服务进程内缓存批处理结果进一步提高性能
上面的流程中大家会发现,存储批处理结果的 Mysql 内的数据每一个批处理完成后才会有所更新,而这个时间长达一天,但 SDMK 上每秒数千次的 API 调用背后却都会有查询服务从 Mysql 中查询历史用量的过程。虽然这个查询过程很快 (几毫秒到几十毫秒),但对于对并发和时延要求很高的 Gateway 来说也值得优化。一个简单明了的方式是在 Metering 的查询服务进程内缓存 Mysql 中的历史用量数据,我们也确实是这么做的。由于用户对 API 服务的调用多为一段时间内连续的调用,因此只需要很小的缓存空间就可以达到非常高的缓存命中率,效果十分理想。这一改进后,查询两天前用量数据数据的时间消耗从数毫秒到数十毫秒减少到平均不到一毫秒。
3. 实时计算流程的降级处理
生产环境中曾经遇到过 Kafka 集群的故障导致调用日志无法写入 Kafka 中,进而导致实时用量没有算上。使我们意识到需要有一个 Failover 的通路。我们选择了一个简单实现:Metering 的流计算部分增加一个 HTTP 接口,用做除 Kafka 消费者外另一个调用日志的来源。Gateway 在将调用日志写 Kafka 失败后调用该接口向流处理部分传递该条调用日志。这样如果再次发生 Kafka 故障,不至于影响计量的实时性。
经过这次改造,形成了计量系统目前的样子:
结 语
历经一次重构和多次小的改进,SDMK 的计量系统一步步在性能、健壮性、可扩展性上不断提高,支撑了 SDMK 平台不断的业务增长。不断完善系统是痛苦并快乐的,这种快乐只有研发的同学亲身经历才能体会的到
|









