| БрМЭЦМі: |
БОЮФжївЊНсКЯInfluxDBдДТыЖдВщбЏОлКЯЧыЧѓдкЗўЮёЦїЖЫЕФДІРэПђМмНјааСЫЯЕЭГРэТлНщЩмЕШЕШЃЌЯЃЭћЖдФњгаЫљАяжњЁЃ
БОЮФРДздhbaseflyЃЌгЩЛ№СњЙћШэМўLucaБрМЁЂЭЦМіЁЃ |
|
ШЮКЮвЛИіЪ§ОнПтЯЕЭГФкКЫЙизЂЕФжиЕуЮоЗЧЃКЪ§ОндкФкДцжаШчКЮДцДЂЁЂдкЮФМўжаШчКЮДцДЂЁЂЫїв§НсЙЙШчКЮДцДЂЁЂЪ§ОнаДШыСїГЬвдМАЪ§ОнЖСШЁСїГЬЁЃЙигкInfluxDBДцДЂФкКЫЃЌБЪепдкжЎЧАЕФЮФеТжавбОБШНЯШЋУцЕФНщЩмСЫЪ§ОнЕФЮФМўДцДЂИёЪНЁЂЕЙХХЫїв§ДцДЂЪЕЯжвдМАЪ§ОнаДШыСїГЬЃЌБОЦЊЮФеТжиЕуНщЩмInfluxDBжаЪБађЪ§ОнЕФЖСШЁСїГЬЁЃ
InfluxDBжЇГжРрSQLВщбЏЃЌГЦЮЊInfluxQLЁЃInfluxQLжЇГжЛљБОЕФDDLВйзїКЭDMLВйзїгяОфЃЌЯъМћInfluxQL_SpecЃЌБШШчSelectгяОфЃК
select_stmt =
"SELECT" fields from_clause [ into_clause
] [ where_clause ]
[ group_by_clause ] [ order_by_clause ] [ limit_clause
]
[ offset_clause ] [ slimit_clause ] [ soffset_clause
] . |
ЪЙгУInfluxQLПЩвдЗЧГЃЗНБуЁЂШЫадЛЏЕиЖдInfluxDBжаЕФЪБађЪ§ОнНјааЖрЮЌОлКЯЗжЮіЁЃФЧInfluxDBФкВПЪЧШчКЮДІРэQueryЧыЧѓЕФФиЃПНгЯТРДБЪепНсКЯдДТыЖдInfluxDBЕФВщбЏСїГЬзівЛИіЦЪЮіЁЃСэЭтЃЌШчЙћПДЙйЖддДТыетВПЗжИааЫШЄЃЌЭЦМіЯШдФЖСЙйЗНЮФЕЕЖдгІВПЗжЃКhttps://docs.influxdata.com/influxdb/v1.0
/query_language/spec/#query-engine-internals
БОЮФЦЊЗљЯрЖдНЯГЄЁЃЮЊСЫЗНБудФЖСЃЌБОЮФЗжЮЊЩЯЯТСНВПЗжЃЌЩЯАыВПЗжЛсДгдРэВуУцНщЩмInfluxDBЕФЪ§ОнЖСШЁСїГЬЃЌЯТАыВПЗжЛсОйвЛИіР§згФЃФтећИіЪ§ОнЖСШЁЕФЙ§ГЬЁЃ
ЩЯАыВПЗжЃКInfluxDBЪ§ОнЖСШЁСїГЬдРэ
LSM(TSM)в§ЧцЖдгкЖССїГЬЕФДІРэЭЈГЃРДЫЕЖМБШНЯИДдгЃЌНЈвщБЃГжзуЙЛЕФФЭаФКЭзЈзЂСІЁЃРэТлВПЗжЛсЗжСНИіаЁФЃПщНјааНщЩмЃЌЕквЛИіФЃПщЛсДгКъЙлПђМмВуУцМђЕЅЪсРэећИіЖСШЁСїГЬЃЌЕкЖўИіФЃПщЛсДгЮЂЙлЯИНкВуУцЗжЮіTSMДцДЂв§ЧцЃЈTSDBЃЉФкВПЯъЯИЕФжДааТпМЁЃ
InfluxDBЖСШЁСїГЬПђМм
БЪепЖдеедДТыЖдећИіСїГЬзіСЫвЛИіМђЕЅЕФЪсРэЃЈЯТЭМЖСепПЩФмПДВЛЧхГўЃЌЮФФЉИНгаИУЭМЕФИпЧхАцЃЉЃК
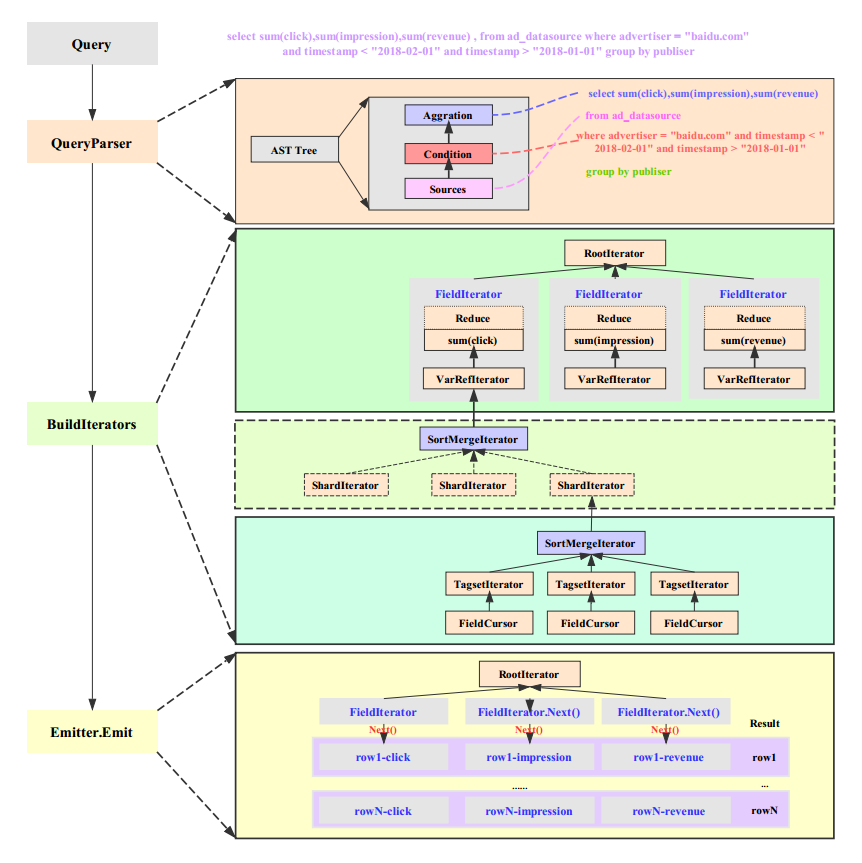
ећИіЖСШЁСїГЬДгКъЙлЩЯЗжЮЊЫФИіВПЗжЃК
1. QueryЃКInfluxQLдЪаэгУЛЇЪЙгУРрSQLгяОфжДааВщбЏЗжЮіОлКЯЃЌInfluxQLгяЗЈЯъМћЃКhttps://docs.influxdata.com/influxdb/
v1.0/query_language/spec/
2. QueryParserЃКInfluxQLНјШыЯЕЭГжЎКѓЃЌЯЕЭГЪзЯШЛсЖдInfluxQLжДааЧаДЪВЂНтЮіЮЊГщЯѓгяЗЈЪїЃЈASTЃЉЃЌГщЯѓЪїжаБъЪОГіСЫЪ§ОндДЁЂВщбЏЬѕМўЁЂВщбЏСавдМАОлКЯКЏЪ§ЕШЕШЃЌЗжБ№ЖдгІЩЯЭМжаSourceЁЂConditionвдМАAggrationЁЃInfluxQLУЛгаЪЙгУЭЈгУЕФЕкШ§ЗНASTНтЮіПтЃЌздМКЪЕЯжСЫвЛЬзНтЮіПтЃЌЖдЯИНкИааЫШЄЕФПЩвдВЮПМЃКhttps://github.com/influxdata/influxqlЁЃНгзХInfluxDBЛсНЋГщЯѓЪїзЊЛЏЮЊвЛИіQueryЪЕЬхЖдЯѓЃЌЙЉКѓајВщбЏжаЪЙгУЁЃ
3. BuildIteratorsЃКInfluxQLгяОфзЊЛЛЮЊQueryЪЕЬхЖдЯѓжЎКѓЃЌОЭНјШыЖСШЁСїГЬжазюживЊзюКЫаФЕФвЛИіЛЗНк
ЈC ЙЙНЈIteratorЬхЯЕЁЃЙЙНЈIteratorЬхЯЕЪЧвЛИіЗЧГЃИДдгЕФТпМЙ§ГЬЃЌЦфжаЯИНкЗЧГЃЗБИДЃЌБЪепОЁПЩФмЛЏЗБЮЊМђЃЌНЋЦфжаЕФжїЯпГщГіРДЁЃЮЊСЫЗНБуРэНтЃЌБЪепНЋIteratorЬхЯЕЗжЮЊШ§ИізгЬхЯЕЃКЖЅВуIteratorзгЬхЯЕЁЂжаМфВуIteratorзгЬхЯЕвдМАЕзВуIteratorзгЬхЯЕЁЃ
ЃЈ1ЃЉЖЅВуIteratorзгЬхЯЕ
InfluxDBЛсЮЊInfluxQLжаЫљгаВщбЏfieldЙЙдьвЛИіFieldIteratorЃЌFieldIteratorБэЪОУПИіВщбЏСаЖМЛсДДНЈвЛИіIteratorЃЈГЦЮЊExprIteratorЃЉЃЌетЪЧвђЮЊInfluxDBЪЧСаЪНДцДЂЯЕЭГЃЌЫљгаЕФСаЖМЪЧЖРСЂДцДЂЕФЃЌвђДЫЛљгкСаЗжБ№ЙЙНЈIteratorЗНБужДааВщбЏОлКЯВйзїЁЃБШШчsum(click)ЃЌsum(impressions)КЭsum(revenue)Ш§ИіВщбЏСаОЭЗжБ№ЖдгІвЛИіExprIteratorЁЃ
ExprIteratorИљОнВщбЏСажЕЪЧЗёашвЊОлКЯПЩвдЗжЮЊVarRefIteratorКЭCallIteratorЃЌЧАепБэЪОСажЕПЩвджБНгВщбЏЗЕЛиЃЌВЛашвЊОлКЯЃЛКѓепБэЪОВщбЏСаашвЊжДааФГаЉОлКЯВйзїЁЃЪОР§жаВщбЏsum(click)ОЭЪЧЕфаЭЕФCallIteratorЃЌCallIteratorЪЕМЪЪЕЯжЗжЮЊСНВНЃЌЪзЯШЭЈЙ§VarRefIteratorАбЖдгІЕФСажЕВщбЏЕНЃЌдйЭЈЙ§ЖдгІЕФReduceКЏЪ§жДааЯргІОлКЯЁЃБШШчsum(click)етИіCallIteratorОЭашвЊЙЭгЖвЛИіVarRefIteratorАбТњзуЬѕМўЕФclickСажЕФУЩЯРДЃЌдйжДааReduceКЏЪ§sumжДааОлКЯВйзїЁЃ
ЃЈ2ЃЉжаМфВуIteratorзгЬхЯЕ
InfluxDBжавЛИіВщбЏСаЕФжЕПЩФмЗжВМдкВЛЭЌЕФShardЩЯЃЌашвЊИљОнTimeRangeОіЖЈИјЖЈЪБМфЖЮдкФФаЉshardЩЯЃЌВЂЮЊУПИіShardЙЙНЈвЛИіIteratorЃЌЙЭгЖетИіТпМIteratorИКд№ВщбЏетИіshardЩЯЖдгІСаЕФСажЕЁЃФПЧАЕЅЛњАцЫљгаshardЖМдкЭЌвЛИіInfluxDBЪЕР§ЩЯЃЌШчЙћЪЕЯжЗжВМЪНЙмРэЃЌашвЊдкетвЛВузіДІРэЁЃ
ЃЈ3ЃЉЕзВуIteratorзгЬхЯЕ
ЕзВуIteratorзгЬхЯЕИКд№ЕЅИіshard(engine)ЩЯТњзуЬѕМўЕФФГвЛСажЕЕФВщевЛђепЕЅЛњОлКЯЃЌЪЧIteratorЬхЯЕжаЪЕМЪИЩЛюЕФIteratorЁЃБШШчТњзуwhere
advertiser = ЁАbaidu.comЁБ етИіЬѕМўОЭашвЊЯШдкЕЙХХЫїв§жаИљОнadvertiser
= ЁАbaidu.comЁБВщЕНАќКЌИУtagЕФЫљгаseriesЃЌдйЮЊУПИіseriesЙЙНЈвЛИіTagsetIteratorШЅВщевЖдгІЕФСажЕЃЌTagsetIteratorЛсНЋВщевжИеыжУгкзюаЁЕФСажЕДІЁЃ
знЙлећИіIteratorЬхЯЕЕФЙЙНЈЃЌећЬхТпМЛЙЪЧКмЧхЮњЕФЁЃзмНсЦ№РДОЭЪЧЃЌВщбЏАДееВщбЏСаЙЙНЈзюЖЅВуFieldIteratorЃЌУПИіFieldIteratorЛсИљОнTimeRangeЙЭгЖЖрИіShardIteratorШЅДІРэЕЅИіShardЩЯУцЖдгІСажЕЕФВщевЃЌЖдВщевЕНЕФжЕвЊУДжБНгЗЕЛивЊУДжДааReduceКЏЪ§НјааОлКЯВйзїЁЃУПИіShardФкВПЪзЯШЛсИљОнВщбЏЬѕМўРћгУЕЙХХЫїв§ЖЈЮЛЕНЫљгаТњзуЬѕМўЕФseriesЃЌдйЮЊУПИіseriesЙЙНЈвЛИіTagsetIteratorгУРДВщевОпЬхЕФСажЕЪ§ОнЁЃвђДЫЃЌTagsetIteratorЪЧећИіЬхЯЕжаЮЈвЛИЩЛюЕФIteratorЃЌЫљгаЦфЫћЩЯВуIteratorЖМЪЧТпМIteratorЁЃ
СэвЛИіЗЧГЃживЊЕФЕуЪЧЃЌЭЌвЛИіShardФкЕФЫљгаTagsetIteratorдкЙЙНЈЭъГЩЛсКЯВЂГЩвЛИіShardIteratorЃЌетИіКЯВЂЙ§ГЬЪЧЖдетаЉTagsetIteratorНјааХХађЕФЙ§ГЬЃЌХХађЙцдђЪЧАДееseriesгЩаЁЕНДѓХХађЛђепгЩДѓЕНаЁХХађЃЈгЩгУЛЇSQLЖдВщбЏНсЙћЪЧгЩаЁЕНДѓХХађЛЙЪЧгЩДѓЕНаЁХХађОіЖЈЃЉЁЃЭЌРэЃЌвЛИіСажЕЖдгІЕФЖрИіShardIteratorЙЙНЈЭъГЩжЎКѓЛсКЯВЂГЩвЛИіFieldIteratorЃЌКЯВЂЙ§ГЬврЪЧвЛИіХХађЙ§ГЬЃЌВЛЙ§ХХађЪЧеыЖдЫљгаShardжаЕФTagsetIteratorНјааЕФЃЌХХађЙцдђЪЧЯШБШНЯseriesЃЌдйБШНЯЪБМфЁЃПЩМћЃЌвЛИіFieldIteratorзюжеЪЧгЩвЛЯЕСаХХађЙ§ЕФTagsetIteratorЙЙГЩЕФЁЃ
4. Emitter.EmitЃКIteratorЬхЯЕЙЙНЈЭъГЩжЎКѓОЭЭъГЩСЫВщбЏОлКЯЧАЕФзМБИЙЄзїЃЌНгЯТРДОЭПЊЪМИЩЛюСЫЁЃИЩЛюТпММђЕЅРДНВЪЧБщРњЫљгаFieldIteratorЃЌЖдУПИіFieldIteratorжДаавЛДЮNextКЏЪ§ЃЌОЭЛсЗЕЛиУПИіВщбЏСаЕФНсЙћжЕЃЌзщзАЕНвЛЦ№ОЭЪЧвЛааЪ§ОнЁЃFieldIteratorжДааNext()КЏЪ§ЛсДЋЕнЕНзюЕзВуЕФTagsetIteratorЃЌTagsetIteratorжДааNextКЏЪ§ЪЕМЪЗЕЛиецЪЕЕФЪБађЪ§ОнЁЃ
TSDBДцДЂв§ЧцжДааТпМ
TSDBДцДЂв§ЧцЃЈЪЕМЪЩЯОЭЪЧвЛИіShardЃЉИљОнгУЛЇЕФВщбЏЧыЧѓжДаадЪМЪ§ОнЕФВщбЏОЭЪЧЩЯЮФжаЬсЕНЕФЕзВуIteratorзгЬхЯЕЕФЙЙНЈЁЃВщбЏЙ§ГЬЗжЮЊСНИіВПЗжЃКЕЙХХЫїв§ВщбЏЙ§ТЫвдМАTSMЪ§ОнВуВщбЏЃЌЧАепЭЈЙ§QueryжаЕФwhereЬѕМўНсКЯЕЙХХЫїв§Й§ТЫЕєВЛТњзуЬѕМўЕФSeriesKeyЃЛКѓепИљОнСєЯТЕФSeriesKeyвдМАwhereЬѕМўжаЪБМфЖЮаХЯЂЃЈTimeRangeЃЉдкTSMFileжавдМАФкДцжаВщГізюжеТњзуЬѕМўЕФЪ§жЕСаЁЃTSDBДцДЂв§ЧцЛсНЋВщбЏЕНЕФЫљгаТњзуЬѕМўЕФдЪМЪ§жЕСаЗЕЛиИјЩЯВуЃЌЩЯВуИљОнОлКЯКЏЪ§ЖддЪМЪ§ОнНјааОлКЯВЂНЋОлКЯНсЙћЗЕЛиИјгУЛЇЁЃећИіЙ§ГЬШчЯТЭМЫљЪОЃК
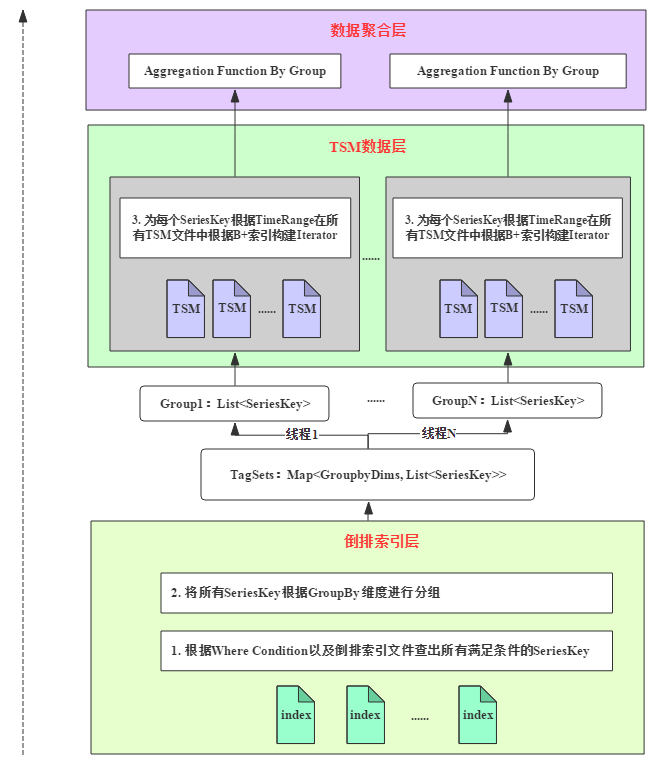
ЩЯЭМашвЊДгЕзВПЯђЩЯфЏРРЃЌећИіСїГЬПЩвдећРэЮЊШчЯТЃК
1. ИљОнwhere conditionвдМАЫљгаЕЙХХЫїв§ЮФМўВщДІЫљгаТњзуЬѕМўЕФSeriesKey
2. НЋТњзуЬѕМўЕФSeriesKeyИљОнGroupByЮЌЖШСаНјааЗжзщЃЌВЛЭЌЗжзщКѓајЕФЫљгаВйзїЖМПЩвдЖРСЂВЂЗЂжДааЃЌвђДЫПЩвдЖрЯпГЬДІРэ
3. еыЖдФГИіЗжзщЕФSeriesKeyМЏКЯвдМАД§ВщбЏСаЃЌИљОнжИЖЈВщбЏЪБМфЖЮЃЈTimeRangeЃЉдкЫљгаTSMFileжаИљОнB+ЪїЫїв§ЙЙНЈВщбЏiterator
4. НЋТњзуЬѕМўЕФдЪМЪ§ОнЗЕЛиИјЩЯВуНјааОлКЯдЫЫуЃЌВЂНЋОлКЯдЫЫуЕФНсЙћЗЕЛиИјгУЛЇ
ЪЕМЪжДааЕФЙ§ГЬПЩФмБШНЯГщЯѓЃЌЮЊСЫИќКУЕФРэНтЃЌБЪепдкЯТАыВПЗжОйСЫвЛИіЪОР§ЁЃУЛгаРэНтЩЯУцЕФТпМУЛЙиЯЕЃЌПЩвдЯШПДЯТУцЕФЪОР§ЃЌПДЭъжЎКѓдйПДЩЯУцЕФРэТлТпМЯраХЛсИќМгШнвзРэНтЁЃ
ЯТАыВПЗжЃКInfluxDBВщбЏСїГЬЪОР§
ЮФеТЩЯАыВПЗжДгРэТлВуУцЖдInfluxDBВщбЏСїГЬНјааСЫНщЩмЁЃЮЊСЫЗНБуРэНтTSDBДцДЂв§ЧцДІРэВщбЏСїГЬЕФТпМЃЌБЪепЭЈЙ§ШчЯТвЛИіецЪЕЪОР§НЋЦфжаЕФКЫаФВНжшНјааЫЕУїЁЃЯТБэЮЊдЪМЪБађЪ§ОнБэЃЌБэжага3ИіЮЌЖШСаЃКpublisherЁЂadvertiserвдМАgenderЃЌ3ИіЪ§жЕСаЃКimpressionЁЂclickвдМАrevenueЃК
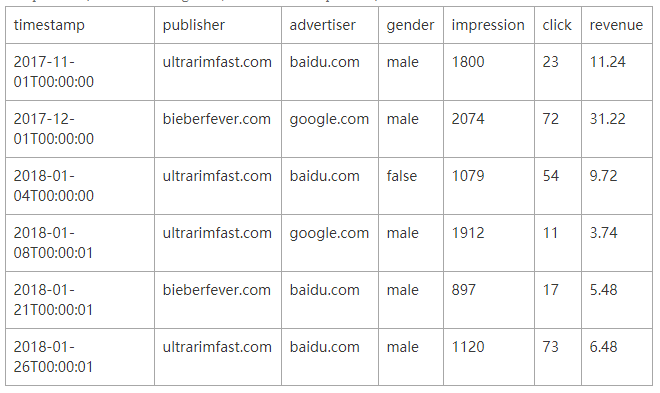
ЯждкгУЛЇЯыВщбЏ2018Фъ1дТЗнЗЂВМдкbaidu.comЦНЬЈЩЯЕФВЛЭЌЙуИцЩЬЕФЦиЙтСПЁЂЕуЛїСПвдМАзмЪеШыЃЌSQLШчЯТЫљЪОЃК
| select sum(click),sum(impression),sum(revenue)
from table group by publisher where advertiser
= "baidu.com" and timestamp > "2018-01-01"
and timestamp < "2018-02-01" |
ВНжшвЛЃКЕЙХХЫїв§Й§ТЫ+groupbyЗжзщ
дЪМВщбЏгяОфЃКselect Ё. from ad_datasource where advertiser
= ЁАbaidu.comЁБ ЁЁ ЁЃЕЙХХЫїв§МДИљОнЬѕМўadvertiser=ЁБbaidu.comЁБдкЫљгаIndex
FileжаБщРњВщбЏАќКЌИУtagЕФЫљгаSeriesKeyЃЌОпЬхдРэЃЈЯъМћЁЖЪБађЪ§ОнПтММЪѕЬхЯЕ ЈC InfluxDB
ЖрЮЌВщбЏжЎЕЙХХЫїв§ЁЗЃЉШчЯТЃК
1. ИљОнIndex FileжаMeasurement BlockИљОнЁБad_datasourceЁБНјааЙ§ТЫЃЌПЩвджБНгЖЈЮЛЕНИјЖЈsourceЖдгІЕФЫљгаTagKeyЫљдкЕФЮФМўoffset|sizeЁЃ
2. МгдиГіЖдгІTagKeyЧјгђЕФHash IndexЃЌЪЙгУИјЖЈTagKeyЃЈЁБadvertiserЁБЃЉНјааhashПЩвджБНгЖЈЮЛЕНИУTagKeyЖдгІЕФTagValueЕФЮФМўoffset|sizeЁЃ
3. МгдиГіTagKeyЖдгІTagValueЧјгђЕФHash IndexЃЌЪЙгУЙ§ТЫЬѕМўTagValueЃЈЁБbaidu.comЁБЃЉНјааhashПЩвджБНгЖЈЮЛЕНИУTagValueЖдгІЕФЫљгаSeriesIDЁЃ
4. SeriesIDОЭЪЧЖдгІSeriesKeyдкЫїв§ЮФМўжаЕФoffsetЃЌжБНгИљОнSeriesIDПЩвдМгдиГіЖдгІЕФSeriesKeyЁЃ
ТњзуЬѕМўЕФЫљгаSeriesKeyШчЯТБэЫљЪОЃЌЙВга3ИіЃК
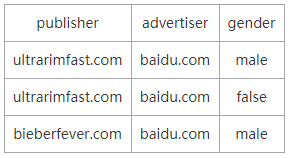
ИљОнЕЙХХЫїв§ВщбЏЕУЕНЫљгаЕФSeriesKeyжЎКѓЃЌетРягавЛИіЗЧГЃживЊЕФВНжшЃКИљОнgroupbyЬѕМўЖдSeriesKeyНјааЗжзщЃЌЗжзщЫуЗЈЮЊhashЁЃЪОР§ВщбЏжаОлКЯЬѕМўЮЊgroup
by publisherЃЌвђДЫашвЊНЋЩЯУцЕУЕНЕФ3ИіSeriesKeyАДееpublisherЕФВЛЭЌЗжГЩШчЯТСНзщЃК
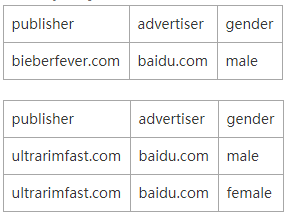
дкЕЙХХЫїв§жЎКѓжДааЗжзщвтвхЗЧГЃжиДѓЃЌЗжзщКѓВЛЭЌgroupЕФSeriesKeyЪЧПЩвдВЂааЖРСЂжДааВщбЏВЂзюжежДааОлКЯЕФЃЌвђДЫКѓајЕФЫљгаВйзїЖМПЩвдЪЙгУЖрИіЯпГЬВЂЗЂжДааЃЌМЋДѓЬсЩ§ећИіВщбЏадФмЁЃ
ВНжшЖўЃКTSMЮФМўЪ§ОнМьЫї
ЕНетвЛВНЃЌЮвУЧвбОАДееgroupbyЕУЕНЗжзщКѓЕФSeriesKeyМЏКЯЁЃНгЯТРДашвЊИљОнSeriesKeyвдМАTimeRangeдкTSMЪ§ОнЮФМўжаВщевТњзуЬѕМўЕФД§ВщбЏСаЁЃдкTSMЪ§ОнЮФМўжаИљОнSeriesKeyвдМАTimeRangeВщбЏfieldЕФОпЬхЙ§ГЬШчЯТЃК
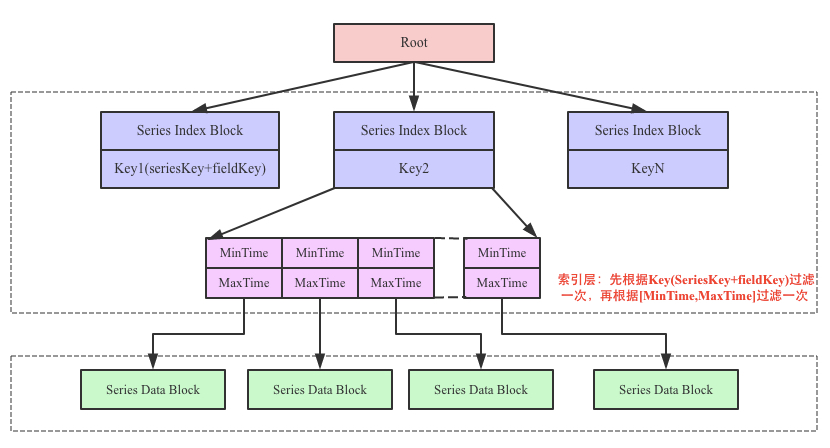
ЩЯЭМжажаМфВПЗжЮЊЫїв§ВуЃЌTSMдкЦєЖЏжЎКѓОЭЛсНЋTSMЮФМўЕФЫїв§ВПЗжМгдиЕНФкДцЃЌЪ§ОнВПЗжвђЮЊЬЋДѓВЂВЛЛсжБНгМгдиЕНФкДцЁЃгУЛЇВщбЏПЩвдЗжЮЊШ§ВНЃК
1. ЪзЯШИљОнKeyЃЈSeriesKey+fieldKeyЃЉевЕНЖдгІЕФSeriesIndex BlockЃЌвђЮЊKeyЪЧгаађЕФЃЌЫљвдПЩвдЪЙгУЖўЗжВщевРДОпЬхЪЕЯж
2. евЕНSeriesIndex BlockжЎКѓдйИљОнВщевЕФЪБМфЗЖЮЇЃЌЪЙгУ[MinTime, MaxTime]Ыїв§ЖЈЮЛЕНПЩФмЕФSeries
Data BlockСаБэ
3. НЋТњзуЬѕМўЕФSeries Data BlockМгдиЕНФкДцжаНтбЙНјвЛВНЪЙгУЖўЗжВщевЫуЗЈВщевМДПЩевЕН
дкTSMжаВщбЏТњзуTimeRangeЬѕМўЕФSeriesKeyЖдгІЕФД§ВщбЏСажЕЃЌвђЮЊInfluxDBЛсИљОнВЛЭЌЕФВщбЏСаЩшжУЖРСЂЕФFieldIteratorЃЌвђДЫВщбЏСагаЖрЩйОЭгаЖрЩйИіFieldIteratorЃЌШчЯТЫљЪОЃК
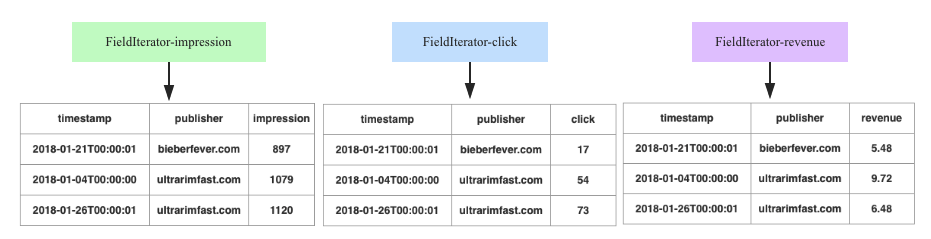
ВНжшШ§ЃКдЪМЪ§ОнОлКЯ
ВщбЏЕНТњзуЬѕМўЕФЫљгадЪМЪ§ОнжЎКѓЃЌInfluxDBЛсИљОнВщбЏОлКЯКЏЪ§ЖддЪМЪ§ОнНјааОлКЯЃЌШчЯТЭМЫљЪОЃК

ЮФеТзмНс
БОЮФжївЊНсКЯInfluxDBдДТыЖдВщбЏОлКЯЧыЧѓдкЗўЮёЦїЖЫЕФДІРэПђМмНјааСЫЯЕЭГРэТлНщЩмЃЌЭЌЪБЩюШыНщЩмСЫInfluxDB
Shard EngineЪЧШчКЮРћгУЕЙХХЫїв§ЁЂЪБађЪ§ОнДцДЂЮФМўЃЈTSMFileЃЉДІРэгУЛЇЕФВщбЏЧыЧѓЁЃзюКѓЃЌОйСЫвЛИіЪОР§ЖдShard
EngineЕФжДааСїГЬНјааСЫаЮЯѓЛЏЫЕУїЁЃећИіЖСШЁЕФЪОвтЭМИНМўЃК
InfluxDBзюаТАц(1.6)ВщбЏОлКЯПђМм | 








