| 编辑推荐: |
本节主要介绍
行式存储、列式存储的区别,TsFile 的格式。
本文来自开源博客 ,由火龙果软件Anna编辑、推荐。 |
|
上一章聊到在车联网或物联网中对数据库的需求,以及 IoTDB 的整体架构,详情请见:
时序数据库
Apache-IoTDB 源码解析之前言(二)
行式与列式存储的区别
假如我们的逻辑上的数据表格式及数据为:
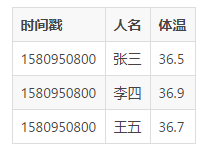
那么他出现在硬盘格式就是:
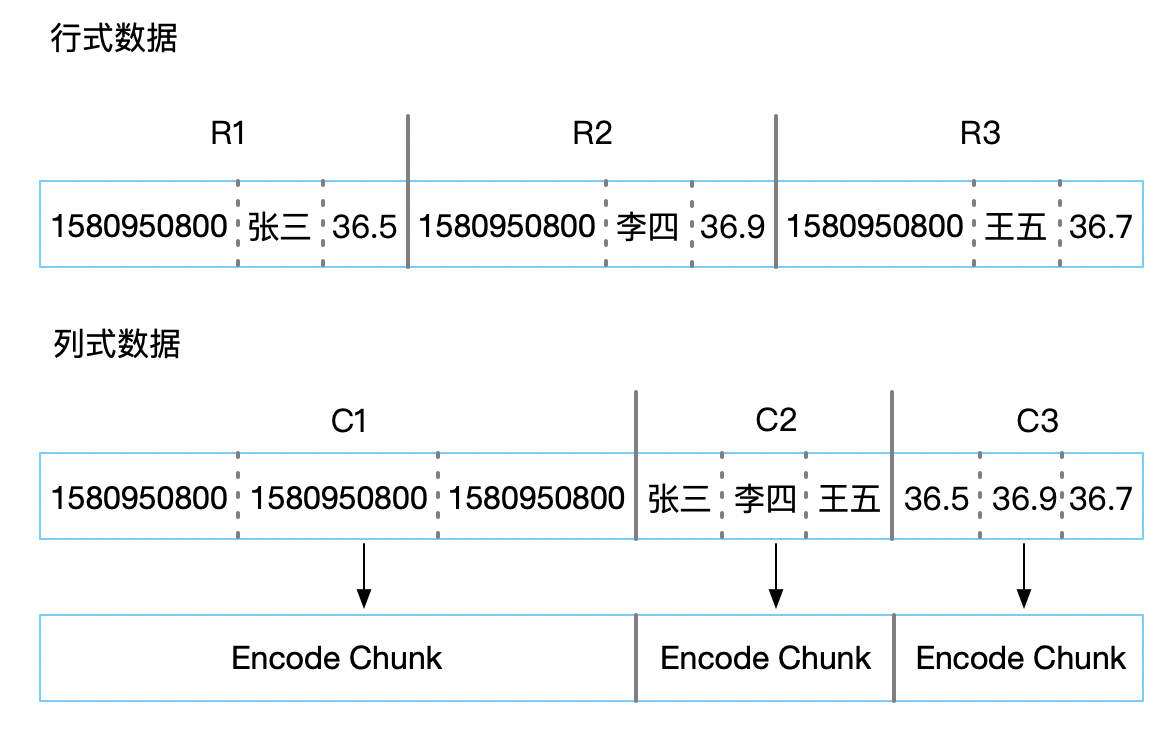
行式数据
在我理解上,行式数据是把逻辑相关的数据在硬盘上放到一起,比如上面的例子,我们可以称之为体温表,所以在逻辑上:时间、人、体温,就成为了逻辑上紧密相关的数据。
所以把相关的数据的硬盘上的组织方式也变成连续的,假如我需要取 张三 的数据,那么当你读出 R1 文件块的时候,就是读出了所有
张三 相关的数据。
列式数据
列式数据在我理解是将物理相关的数据放到一起,比如时间是一类(long 类型)、名字是一类(string
类型)、体温是一类(float 类型)。当然这种硬盘的组织方式,相比起行式数据库,在取拼回体温表的结构的时候,速度就慢了很多,因为你要分别取
C1、C2、C3 文件块,然后还要写个容器往里 Set()。那么列式数据存储方式相比于行式存储优势在哪里呢?
1.1 取数据方式
有一种叫法是只读投影列,避免查询无关列的读取。列式存储的优势在于查询的列数远小于总属性数量,就能少读很多数据。可能读起来非常绕口,举个例子:比如我需要查体温大于
36 度的体温值,sql : select 体温 FROM table WHERE 体温 >
36 。这时候如果是列式存储只需要读出 C3 数据块就可以一次性查到所有数据。而行式数据库中,则需要读出
R1、 R2、 R3。在第二章中介绍到物联网中的时序数据的特点:存量数据非常大,如果遍历几百亿数据,时间差距明显就拉开了。
1.2 数据编码和压缩
因为物理相关的数据他们类型相同,可以使用多种多样的编码方式,比如 IoTDB 中就提供了 8 种编码方式,这个不具体聊,等后面章节再说。
我们继续拿时间列举例子,我们可以把时间列改造为差值存储: 比如 C1 文件块中先存储基础值 1580950800
那么他后面的数据值只需要存储 0 就可以,存储的数字小了,那么占用的存储空间肯定也就小了,当数字特别大且差值比较小的时候,这用编码方式就非常有意义。当然还有很多好玩儿的编码方式,欢迎持续关注。
TsFile 文件格式
为什么叫 TsFile ?我听意思应该是作为 TimeSeriresFile
的缩写,也就是时序数据文件的意思。
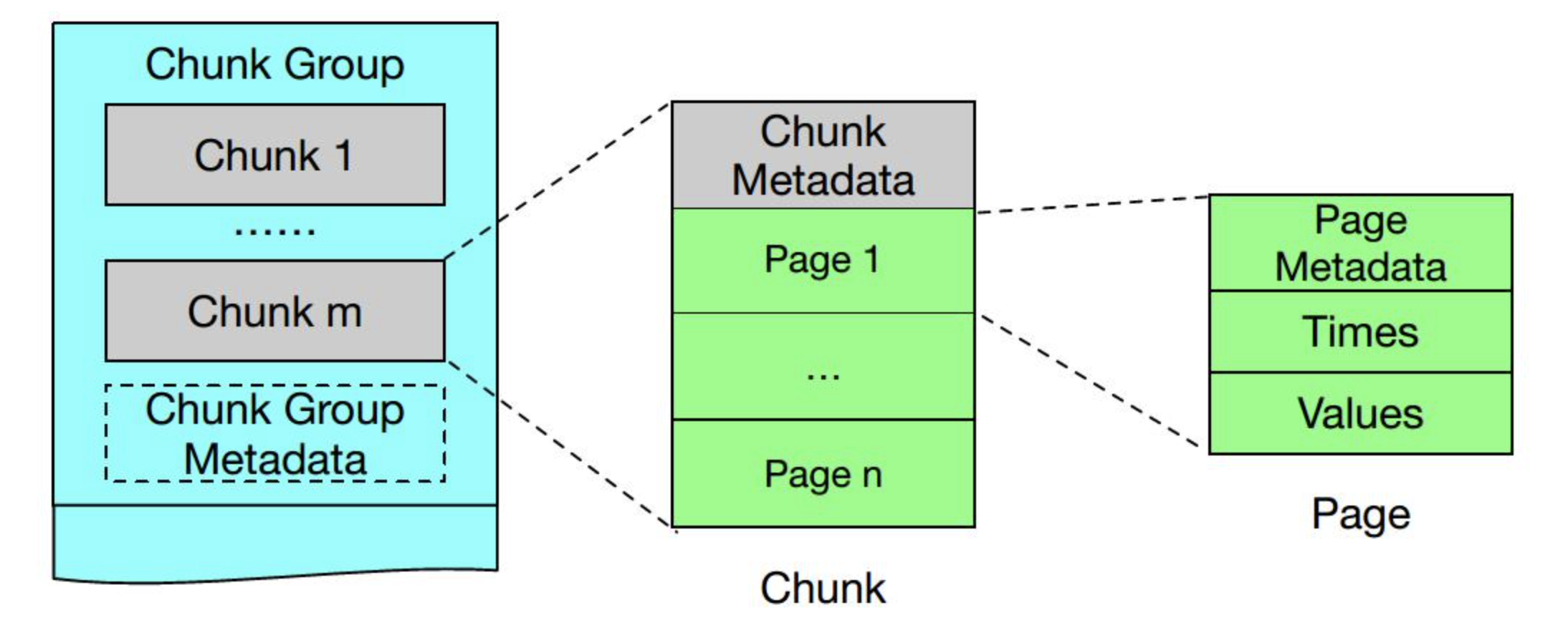
chunk数据格式
这是一个数据被刷入磁盘后的缩减版 TsFile 格式,我们还拿上面的数据举例,用来直观的解释
TsFile 中出现的一些名词,假如我的数据为:
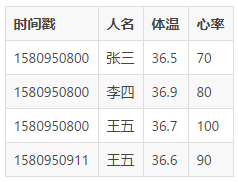
上面的数据刷新到磁盘上后会对应关系如下:
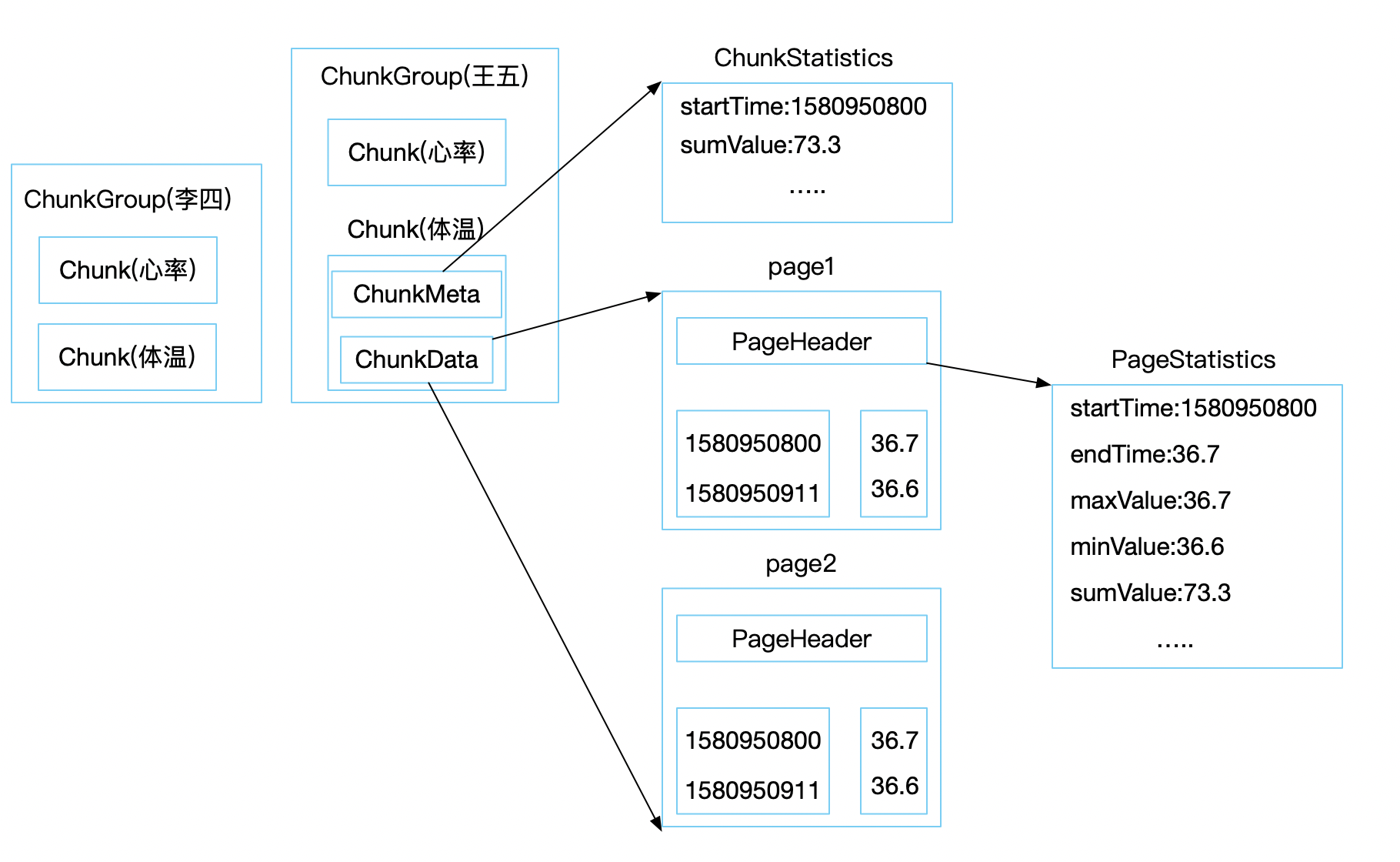
数据及名词对应关系
看到这里应该能理解每个英文名词的意思:
ChunkGroup 代表了设备(逻辑概念上的一个集合)一段时间内的数据,在 IoTDB 中称为
Device。
Chunk 代表了测点数据(逻辑概念上的某一类数据的集合,如体温数据),在 IoTDB 中称为 Measurement。
Page 中存储的是具体数据,包含一个时间序列、一个值序列。
PageStatistics 是保存的是Page当中数据的预聚合信息。
ChunkStatistics 是保存的是Chunk当中数据的预聚合信息。
ChunkGroup 中包含多个 Chunk,Chunk 中包含多个 Page ,Page 中 包含多个
时间点和数据项
回想上面提到的 SQL : select 体温 FROM 王五 WHERE 体温 > 36
, 在 TsFile 中,只要在文件中找到 王五 的 ChunkGroup ,并在 ChunkGroup
中找到 体温 的 Chunk,然后从第一个 Page 开始遍历就完成了。
介绍完了 Chunk 和 ChunkGroup 的概念,那么如果 Chunk 和 ChunkGroup
非常多的时候,TsFile 怎么来设计才能快速的定位并找到合适的 ChunkGroup 的呢?TsFile
怎样才能做到损坏时的检测或者保证传递过程的完整性呢?欢迎持续关注。。。
| 








