| БрМЭЦМі: |
БОЦЊЮФеТжївЊМЏжаНщЩмдкДцДЂЮФМўЕФЛљДЁЩЯЗжБ№НщЩмInfluxDBЪЧШчКЮДІРэгУЛЇЕФаДШыЃЈЩОГ§ЃЉЧыЧѓКЭЖСШЁЧыЧѓЕФЁЃЯЃЭћЖдФњгаЫљАяжњЁЃ
БОЮФРДздhbaseflyЃЌгЩЛ№СњЙћШэМўDeloresБрМЁЂЭЦМіЁЃ |
|
InfluxDBаДШызмЬхПђМм
InfluxDBЬсЙЉСЫЖржжНгПкавщЙЉЭтВПгІгУаДШыЃЌБШШчПЩвдЪЙгУcollectedВЩМЏЪ§ОнЩЯДЋЃЌПЩвдЪЙгУopentsdbзїЮЊЪфШыЃЌвВПЩвдЪЙгУhttpавщвдМАudpавщХњСПаДШыЪ§ОнЁЃХњСПЪ§ОнНјШыЕНInfluxDBжЎКѓзмЬхЛсОЙ§Ш§ИіВНжшЕФДІРэЃЌШчЯТЭМЫљЪОЃК
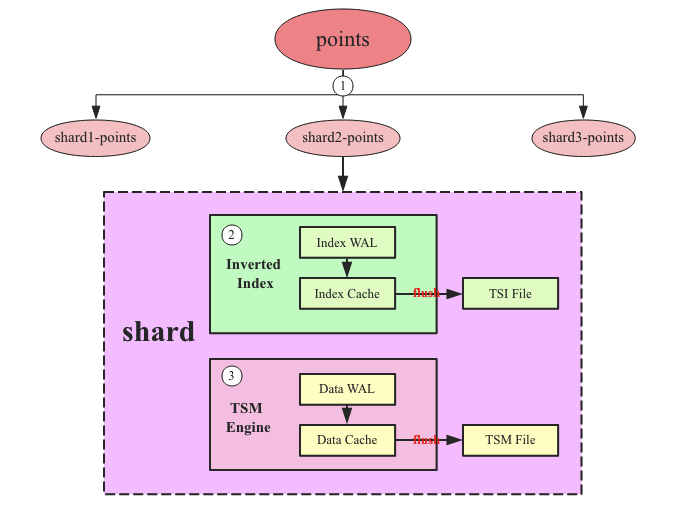
ХњСПЪБађЪ§ОнshardТЗгЩЃКInfluxDBЪзЯШЛсНЋетаЉЪ§ОнИљОнshardЕФВЛЭЌЗжГЩВЛЭЌЕФЗжзщЃЌУПИіЗжзщЕФЪБађЪ§ОнЛсЗЂЫЭЕНЖдгІЕФshardЁЃУПИіshardЯрЕБгкHBaseжаregionЕФИХФюЃЌЪЧInfluxDBжаДІРэгУЛЇЖСаДЧыЧѓЕФЕЅЛњв§ЧцЁЃ
ЕЙХХЫїв§в§ЧцЙЙНЈЕЙХХЫїв§ЃКInfluxDBжаshardгЩСНИіLSMв§ЧцЙЙГЩ ЈC ЕЙХХЫїв§в§ЧцКЭTSMв§ЧцЁЃЪБађЪ§ОнЪзЯШЛсОЙ§ЕЙХХЫїв§в§ЧцЙЙНЈЕЙХХЫїв§ЃЌЕЙХХЫїв§гУРДЪЕЯжInfluxDBЕФЖрЮЌВщбЏЁЃ
TSMв§ЧцГжОУЛЏЪБађЪ§ОнЃКЕЙХХЫїв§ЙЙНЈГЩЙІжЎКѓЪБађЪ§ОнЛсНјШыTSM EngineДІРэЁЃTMS EngineДІРэСїГЬКЭЭЈгУLSM EngineЛљБОвЛбљЃЌЯШНЋаДШыЧыЧѓзЗМгаДШыWALШежОЃЌдйаДШыcacheЃЌвЛЕЉТњзуЬиЖЈЬѕМўЛсНЋcacheжаЕФЪБађЪ§ОнжДааflushВйзїТфХЬаЮГЩTSM FileЁЃ
ХњСПЪБађЪ§ОнShardТЗгЩ
ЭЈГЃРДЫЕЪБађЪ§ОнЖМЛсвдХњСПЕФаЮЪНаДШыЪ§ОнПтЃЌКмЩйЛсЯёЙиЯЕаЭЪ§ОнПтФЧбљвЛЬѕвЛЬѕаДШыЃЌетЖдгкзЗЧѓИпЭЬЭТЕФЪБађЯЕЭГРДЫЕжСЙиживЊЁЃХњСПЪ§ОнаДШыInfluxDBжЎКѓзіЕФЕквЛМўЪТЧщЪЧЗжзщЃЌНЋЪБађЪ§ОнЕуАДееЫљЪєshardЛЎЗжЮЊЖрзщЃЈГЦЮЊShard MapЃЉЃЌУПзщЪБађЪ§ОнЕуНЋЛсЗЂЫЭИјЖдгІЕФshardв§ЧцВЂЗЂДІРэЁЃ
етРяЮвУЧМђЕЅЛиЙЫЯТInfluxDBЕФShardingВпТдЃЈЯъМћЮФеТЁЖЪБађЪ§ОнПтММЪѕЬхЯЕ ЈC ГѕЪЖInfluxDBЁЗжаShardingВпТдвЛНкЃЉЁЃInfluxDBЫфЫЕЪЧЕЅЛњЪ§ОнПтЃЌЕЋЪЧУПИіБэвРШЛЛсБЛЗжЮЊЖрИіshardЁЃМђЕЅРДЫЕЃЌInfluxDBжаshardingЪєгкСНВуshardingЃКЪзЯШАДееЪБМфНјааRange ShardingЃЌМДАДЪБМфЗжЦЌЃЌБШШч7ЬьвЛИіЗжЦЌЕФЛАЃЌзюНќ7ЬьЕФЪ§ОнЛсЗжЕНвЛИіshardЃЌвЛжмЧАЕНСНжмЧАЕФЪ§ОнЛсБЛЗжЕНЩЯвЛИіshardЃЌвдДЫРрЭЦЃЛдкЪБМфЗжЦЌЕФЛљДЁЩЯЛЙПЩвддйжДааHash ShardingЃЌАДееSeriesKeyжДааHashЃЈБЃжЄЭЌвЛИіSeriesKeyЖдгІЕФЫљгаЪ§ОнЖМТфЕНЭЌвЛИіshardЃЉЃЌдйНЋЪ§ОнЗжЩЂЕНжИЖЈЕФЖрИіshardжаЁЃ
ЕБШЛЃЌОЙ§БЪепЩюНјвЛВНСЫНтЃЌЗЂЯжЕЅЛњInfluxDBжЛгаЕквЛВуshardingЃЌМДжЛгаИљОнЪБМфНјааRange ShardingЃЌВЂУЛгажДааHash ShardingЁЃHash ShardingжЛЛсдкЗжВМЪНInfluxDBжаВХЛсгУЕНЁЃ
ЕЙХХЫїв§в§ЧцЙЙНЈЕЙХХЫїв§
InfluxDBжаЕЙХХЫїв§в§ЧцЪЙгУLSMв§ЧцЙЙНЈЃЌЩЯЦЊЮФеТЁЖЪБађЪ§ОнПтММЪѕЬхЯЕ ЈC InfluxDB ЖрЮЌВщбЏжЎЕЙХХЫїв§ЁЗЦфЪЕвбОЖдв§ЧцЕФЙЄзїдРэНјааСЫЩюШыЕФНщЩмЁЃетРяжиЕуНЋећИіСїГЬзівЛИіДЎСЊЪсРэЃЌЦфжаЯИНкВПЗжВЛЛсеЙПЊРДНВЃЌгааЫШЄЕФЛАПЩвдВЮПМЩЯвЛЦЊЮФеТЁЃ
етРяЪзЯШЫМПМвЛИіЮЪЬтЃКЮЊЪВУДInfluxDBЕЙХХЫїв§ашвЊЙЙНЈГЩLSMв§ЧцЃПЦфЪЕКмМђЕЅЃЌLSMв§ЧцЬьЩњЖдаДгбКУЃЌаДЖрЖСЩйЕФЯЕЭГЕквЛбЁдёОЭЪЧLSMв§ЧцЃЌЫљвдДѓЪ§ОнЪБДњЕФИїжжЪ§ОнДцДЂЯЕЭГОЭЪЧLSMв§ЧцЕФЬьЯТЃЌHBaseЁЂKuduЁЂDruidЁЂTiKVетаЉЯЕЭГЮовЛВЛЪЧетбљЁЃInfluxDBзїЮЊвЛИіЪБађЪ§ОнПтИќЪЧаДЖрЖСЩйЕФЕфаЭЃЌЮоТлЕЙХХЫїв§в§ЧцЛЙЪЧЪБађЪ§ОнДІРэв§ЧцбЁгУLSMв§ЧцИќЪЧЮоПЩКёЗЧЁЃ
МШШЛЪЧLSMв§ЧцЃЌЙЄзїЛњжЦБиШЛЪЧетбљЕФЃКЪзЯШНЋЪ§ОнзЗМгаДШыWALдйаДШыCacheОЭПЩвдЗЕЛиИјгУЛЇаДШыГЩЙІЃЌWALПЩвдБЃжЄМДЪЙЗЂЩњвьГЃхДЛњвВПЩвдЛжИДГіРДCacheжаЖЊЪЇЕФЪ§ОнЁЃвЛЕЉТњзуЬиЖЈЬѕМўЯЕЭГЛсНЋCacheжаЕФЪБађЪ§ОнжДааflushВйзїТфХЬаЮГЩЮФМўЁЃЮФМўЪ§СПГЌЙ§вЛЖЈуажЕЯЕЭГЛсНЋетаЉЮФМўКЯВЂаЮГЩвЛИіДѓЮФМўЁЃФЧОпЬхЕНЕЙХХЫїв§в§ЧцећИіСїГЬЪЧЪВУДбљЕФЃЌМђЕЅРДПДвЛЯТЃК
1.WALзЗМгаДШыЃКInverted Index WALИёЪНКмМђЕЅЃЌгЩвЛИівЛИіLogEntryЙЙГЩЃЌШчЯТЭМЫљЪОЃК
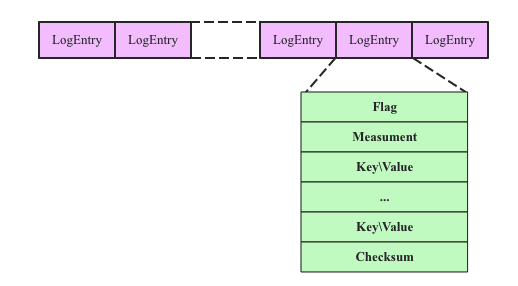
УПИіLogEntryгЩFlagЁЂMeasurementЁЂвЛЯЕСаKey\ValueвдМАChecksumзщГЩЁЃЦфжаFlagБэЪОИќаТРраЭЃЌАќРЈаДШыЁЂЩОГ§ЕШЃЌMeasurementБэЪОЪ§ОнБэЃЌKey\ValueБэЪОаДШыЕФTag SetвдМАChecksumЃЌЦфжаChecksumгУгкИљОнWALЛиЗХЪ§ОнЪБбщжЄLogEntryЕФЭъећадЁЃзЂвтЃЌLogEntryжаВЂУЛгаЪБађЪ§ОнСаЃЌжЛгаЮЌЖШСаЃЈTag SetЃЉЁЃ
2. Inverted IndexдкФкДцжаЙЙНЈ
ЃЈ1ЃЉЦДSeriesKeyЃК ЪБађЪ§ОнаДШыЕНЯЕЭГжЎКѓЯШНЋmeasurementКЭЫљгаЕФЮЌЖШжЕЦДГЩвЛИіseriesKey
ЃЈ2ЃЉШЗШЯSeriesKeyЪЧЗёвбОЙЙНЈЙ§Ыїв§ЃКдкЮФМўжаШЗШЯИУseriesKeyЪЧЗёвбОДцдкЃЌШчЙћвбОДцдкОЭКіТдЃЌВЛашвЊдйНЋЦфМгШыЕНФкДцЕЙХХЫїв§ЁЃФЧЮЪЬтзЊЛЏЮЊШчКЮдкЮФМўжаВщевФГИіseriesKeyЪЧЗёвбОДцдкЃПетОЭЪЧSeries BlockжаBloom FilterЕФКЫаФзїгУЃЌЪзЯШЪЙгУBloom FilterНјааХаЖЯЃЌШчЙћВЛДцдкЃЌПЯЖЈВЛДцдкЁЃШчЙћДцдкЃЌВЛвЛЖЈДцдкЃЌашвЊНјвЛВНХаЖЯЁЃдйНјвЛВНЪЙгУB+ЪївдМАHashIndexНјвЛВНВщевХаЖЯЁЃ
ЃЈ3ЃЉШчЙћseriesKeyдкЮФМўжаВЛДцдкЃЌашвЊНЋЦфаДШыФкДцЁЃЕЙХХЫїв§ФкДцНсЙЙжївЊАќКЌСНИіMapЃК< measurement, List< tagKey>> КЭ < tagKey, < tagValue, List< SeriesKey >>>ЃЌЧАепБэЪОЪБађБэгыЖдгІЮЌЖШМЏКЯЕФгГЩфЃЌМДетИіБэжагаЖрЩйЮЌЖШСаЁЃКѓепБэЪОУПИіЮЌЖШСаЖМгаФФаЉПЩУЖОйЕФжЕЃЌвдМАетаЉжЕЖМЖдгІФФаЉSeriesKeyЁЃInfluxDBжаSeriesKeyОЭЪЧвЛАбдПГзЃЌжЛгаФУЕНетАбдПГзВХФмевЕНетИіSeriesKeyЖдгІЕФЪ§ОнЁЃЖјЕЙХХЫїв§ОЭЪЧИљОнвЛаЉЯпЫїШЅеветАбдПГзЁЃ
3. Inverted Index Cache FlushСїГЬ
ЃЈ1ЃЉДЅЗЂЪБЛњЃКЕБInverted Index WALШежОЕФДѓаЁГЌЙ§уажЕЃЈФЌШЯ5MЃЉЃЌОЭЛсжДааflushВйзїНЋЛКДцжаЕФСНИіMapаДГЩЮФМў
ЃЈ2ЃЉЛљБОСїГЬЃК
ЛКДцMapХХађЃК< measurement, List< tagKey >>вдМА< tagKey, < tagValue, List< SeriesKey >>ЖМашвЊОЙ§ХХађДІРэЃЌХХађЕФвтвхдкгкгаађЪ§ОнПЩвдНсКЯHash IndexЪЕЯжЗЖЮЇВщбЏЃЌСэЭтSeries BlockжаB+ЪїЕФЙЙНЈвВашвЊSeriesKeyХХађЁЃ
ЙЙНЈВЂГжОУЛЏSeries BlockЃКдкХХађЕФЛљДЁЩЯЪзЯШГжОУЛЏ< tagKey, tagValue, List< SeriesKey >>НсЙЙжаЫљгаЕФSeriesKeyЃЌвВОЭЪЧЯШЙЙНЈSeries BlockЁЃвРДЮГжОУЛЏSeriesKeyЕНSeriesKeyChunkЃЌЕБChunkТњСЫжЎКѓЃЌИљОнChunkжазюаЁЕФSeriesKeyЙЙНЈB+ЪїжаЕФIndex EntryНкЕуЁЃЕБШЛЃЌHash IndexвдМАBloom FilterЪЧашвЊЪЕЪБЙЙНЈЕФЁЃашвЊзЂвтЕФЪЧЃЌSeries BlockдкЙЙНЈЕФЭЌЪБашвЊМЧТМЯТSeriesKeyгыИУKeyдкЮФМўжаЦЋвЦСПЕФЖдгІЙиЯЕЃЌМД< SeriesKey, SeriesKeyOffset >ЃЌетвЛЕужСЙиживЊЁЃ
ФкДцжаНЋSeriesKeyгГЩфЮЊSeriesIdЃКНЋ< tagKey, < tagValue, List< SeriesKey >>НсЙЙжаЫљгаЕФSeriesKeyгЩЩЯвЛВНжаЕУЕНЕФ< SeriesKey, SeriesKeyOffset >жаЕФSeriesKeyOffsetДњЬцЁЃаЮГЩаТЕФНсЙЙЃК< tagKey, < tagValue, List< SeriesKeyOffset >>ЃЌМД< tagKey, < tagValue, List< SeriesKeyId >>>ЃЌЦфжаSeriesKeyIdОЭЪЧSeriesKeyOffsetЁЃ
ЙЙНЈВЂГжОУЛЏTag BlockЃКдкаТНсЙЙ< tagKey, < tagValue, List< SeriesKeyId >>>ЕФЛљДЁЩЯЪзЯШГжОУЛЏtagValueЃЌНЋЭЌвЛИіtagKeyЯТЕФЫљгаtagValueГжОУЛЏдквЛЦ№ВЂЩњГЩЖдгІHash IndexаДШыЮФМўЃЌНгзХГжОУЛЏЯТвЛИіtagKeyЕФЫљгаtagValueЁЃЫљгаtagValueЖМГжОУЛАЭъГЩжЎКѓдйвРДЮГжОУЛЏЫљгаЕФtagKeyЃЌаЮГЩTag BlockЁЃ
ЙЙНЈВЂГжОУЛЏMeasurement BlockЃКзюКѓГжОУЛЏmeasurementаЮГЩMeasurement BlockЁЃ
ЪБађЪ§ОнаДШыСїГЬ
ЪБађЪ§ОнЕФЮЌЖШаХЯЂОЙ§ЕЙХХЫїв§в§ЧцЙЙНЈЭъГЩжЎКѓЃЌНгзХОЭашвЊНЋЪ§ОнаДШыЯЕЭГЁЃКЭЕЙХХЫїв§в§ЧцвЛбљЃЌЪ§ОнаДШыв§ЧцвВЪЧвЛИіLSMв§ЧцЃЌЛљБОСїГЬвВЪЧЯШаДWALЃЌдйаДCacheЃЌзюКѓТњзувЛЖЈуажЕЬѕМўжЎКѓНЋCacheжаЕФЪ§ОнflushЕНЮФМўЁЃ
1. WALзЗМгаДШыЃКЪБМфЯпЪ§ОнЪ§ОнЛсОЙ§СНжиДІРэЃЌЪзЯШИёЪНЛЏЮЊWriteWALEntryЖдЯѓЃЌИУЖдЯѓзжЖЮдЊЫиШчЯТЭМЫљЪОЁЃШЛКѓОЙ§snappyбЙЫѕКѓаДШыWALВЂГжОУЛАЕНЮФМўЁЃ
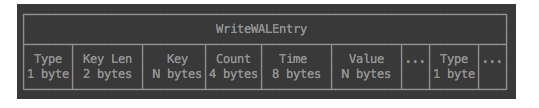
2. ЪБађЪ§ОнаДШыФкДцНсЙЙ
ЃЈ1ЃЉЪБађЪ§ОнЕуИёЪНЛЏЃКНЋЫљгаЪБМфађСаЪ§ОнЕуАДЪБМфЯпзщжЏаЮГЩвЛИіMapЃК< SeriesKey+FieldKey, List< Value >>ЃЌМДНЋЯрЭЌKey(SeriesKey+FieldKey)ЕФЪБађЪ§ОнМЏжаЗХдквЛИіListжаЁЃ
ЃЈ2ЃЉЪБађЪ§ОнЕуаДШыCacheЃКInfluxDBжаCacheЪЧвЛИіcrude hash ringЃЌетИіringгЩ256ИіpartitionЙЙГЩЃЌУПИіpartitionИКд№ДцДЂвЛВПЗжЪБађЪ§ОнKeyЖдгІЕФжЕЁЃОЭЯрЕБгкЪ§ОнаДШыCacheЕФЪБКђгжИљОнKey HashСЫвЛДЮЃЌИљОнHashНсЙћгГЩфЕНВЛЭЌЕФpartitionЁЃЮЊЪВУДвЊетУДДІРэЃПИіШЫШЯЮЊгаЕуЯёJavaжаConcurrentHashMapЕФЫМТЗЃЌНЋвЛИіДѓHashMapЧаЗжГЩЖрИіаЁHashMapЃЌУПИіHashMapФкВПдкаДЕФЪБКђашвЊМгЫјЁЃетбљДІРэПЩвдМѕаЁЫјСЃЖШЃЌЬсИпаДадФмЁЃ
3. Data Cache FlushСїГЬ(ВЮПМengine.compactCache)
ЃЈ1ЃЉДЅЗЂЪБЛњЃКCacheжДааflushВйзїгаСНИіЛљБОДЅЗЂЬѕМўЃЌЦфвЛЪЧЕБcacheДѓаЁГЌЙ§вЛЖЈуажЕЃЌПЩвдЭЈЙ§ВЮЪ§ЁЏcache-snapshot-memory-sizeЁЏХфжУЃЌФЌШЯЪЧ25MДѓаЁЃЛЦфЖўЪЧГЌЙ§вЛЖЈЪБМфуажЕУЛгаЪБађЪ§ОнаДШыWALвВЛсДЅЗЂflushЃЌФЌШЯЪБМфуажЕЮЊ10ЗжжгЃЌПЩвдЭЈЙ§ВЮЪ§ЁЏcache-snapshot-write-cold-durationЁЏХфжУЁЃ
ЃЈ2ЃЉЛљБОСїГЬЃКдкСЫНтСЫTSMЮФМўЕФЛљБОНсЙЙжЎКѓЃЌЮвУЧдйМђЕЅПДПДЪБађЪ§ОнЪЧШчКЮДгФкДцжаЕФMapГжОУЛЏГЩTSMЮФМўЕФЃЌећИіЙ§ГЬПЩвдБэЪіЮЊЃК
ФкДцжаЙЙНЈSeries Data BlockЃКЫГађБщРњФкДцMapжаЕФЪБађЪ§ОнЃЌЗжБ№ЖдЪБађЪ§ОнЕФЪБМфСаКЭЪ§жЕСаНјааЯргІЕФБрТыЃЌАДееSeries Data BlockЕФИёЪННјаазщжЏЃЌЕБBlockДѓаЁГЌЙ§вЛЖЈуажЕОЭЙЙНЈГЩЙІЁЃВЂМЧТМетИіBlockФкЪБМфСаЕФзюаЁЪБМфMinTimeвдМАзюДѓЪБМфMaxTimeЁЃ
НЋЙЙНЈКУЕФSeries Data BlockаДШыЮФМўЃКЪЙгУЪфГіСїНЋФкДцжаЪ§ОнЪфГіЕНЮФМўЃЌВЂЗЕЛиИУBlockдкЮФМўжаЕФЦЋвЦСПOffsetвдМАзмДѓаЁSizeЁЃ
ЙЙНЈЮФМўМЖБ№B+Ыїв§ЃКдкФкДцжаЮЊИУSeries Data BlockЙЙНЈвЛИіЫїв§НкЕуIndex EntryЃЌЪЙгУЪ§ОнBlockдкЮФМўжаЕФЦЋвЦСПOffsetЁЂзмДѓаЁSizeвдМАMinTimeЁЂMaxTimeЙЙНЈвЛИіIndex EntryЖдЯѓЃЌаДШыЕНФкДцSeries Index BlockЖдЯѓЁЃ
етбљЃЌУПЙЙНЈвЛИіSeries Data BlockВЂаДШыЮФМўжЎКѓЖМЛсдкФкДцжаЫГађЙЙНЈвЛИіIndex EntryЃЌаДШыФкДцSeries Index BlockЖдЯѓЁЃвЛЕЉвЛИіKeyЖдгІЕФЫљгаЪБађЪ§ОнЖМГжОУЛЏЭъГЩЃЌвЛИіSeries Index BlockОЭЙЙНЈЭъГЩЃЌЙЙНЈЭъГЩжЎКѓЬюГфIndex Block MetaаХЯЂЁЃНгзХаТНЈвЛИіаТЕФSeries Index BlockПЊЪМЙЙНЈЯТвЛИіKeyЖдгІЕФЪ§ОнЫїв§аХЯЂЁЃ
InfluxDBЪ§ОнЩОГ§ВйзїЃЈDropMeasurementЃЌDropTagKeyЃЉ
вЛАуLSMв§ЧцДІРэЩОГ§ЭЈГЃЖМВЩгУTagБъМЧЕФЗНЪНЃЌМДЩОГ§ВйзїКЭаДШыВйзїСїГЬЛљБОвЛжТЃЌжЛЪЧЪ§ОнЩЯЛсЖрвЛИіTagБъМЧ ЈC deletedЃЌБэЪОИУжЕвбОБЛdeletedЁЃетжжДІРэЗНАИПЩвдзюаЁЛЏЩОГ§ДњМлЃЌЕЋЭђЮягаЕУБигаЪЇЃЌМѕаЁСЫаДШыДњМлБиШЛЛсдіМгЖСШЁДњМлЃЌTagБъЧЉЗНАИдкЖСШЁЕФЪБКђашвЊЖдБъМЧгаdeletedЕФЪ§жЕНјааЬиЪтДІРэЃЌетИіДњМлЛЙЪЧКмДѓЕФЁЃHBaseжаЩОГ§ВйзїОЭЪЧВЩгУTagБъМЧЗНАИЁЃ
InfluxDBБШНЯЦцнтЃЌЖдгкЩОГ§ВйзїДІРэЕФБШНЯвьРрЃЌЭЈГЃInfluxDBВЛЛсЩОГ§вЛЬѕМЧТМЃЌЖјЪЧЛсЩОГ§ФГЖЮЪБМфФкЛђепФГИіЮЌЖШЯТЕФЫљгаМЧТМЃЌЩѕжСвЛеХБэЕФЫљгаМЧТМЃЌетКЭЭЈГЃЕФЪ§ОнПтгаЫљВЛЭЌЁЃБШШчЃК
DROP SERIES FROM
h2o_feet WHERE
location = ЁЎsanta_monica'
DELETE FROM "cpu" DELETE FROM "cpu"
WHERE time < '2000-01-01T00:00:00Z'
DELETE
WHERE time < '2000-01-01T00:00:00Z' |
ЩЯЮФЮвУЧжЊЕРInfluxDBжавЛИіshardгаСНИіLSMв§ЧцЃЌвЛИіЪЧЕЙХХЫїв§в§ЧцЃЈДцДЂЮЌЖШСаЕНSeriesKeyЕФгГЩфЙиЯЕЃЌЗНБуЖрЮЌВщевЃЉЃЌвЛИіЪЧTSM EngineЃЌгУРДДцДЂЪЕМЪЕФЪБађЪ§ОнЁЃШчЙћЪЧЩОГ§вЛЬѕМЧТМЃЌЭЈГЃжЛашвЊTSM EngineжДааЩОГ§ОЭПЩвдЃЌЕЙХХЫїв§в§ЧцЪЧВЛашвЊжДааЩОГ§ЕФЁЃЖјШчЙћЪЧDrop MeasurementетбљЕФВйзїЃЌФЧУДСНИіLSMв§ЧцЖМашвЊжДааЯргІЕФЩОГ§ЁЃЮЪЬтЪЧЃЌетСНИів§ЧцЕФЩОГ§ВпТдЭъШЋВЛЭЌЃЌTSM EngineВЩгУСЫвЛжжЭЌВНЩОГ§ВпТдЃЌInverted Index EngineВЩгУСЫБъМЧЩОГ§ВпТдЁЃШчЯТЭМЫљЪОЃК
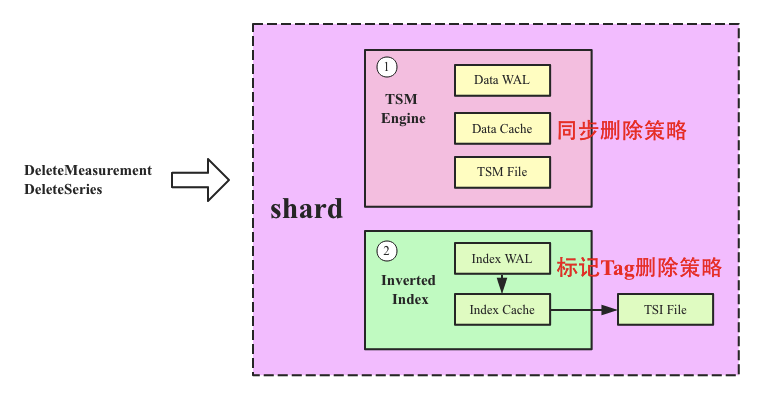
1. TSM EngineЭЌВНЩОГ§ВпТдЃЌећИіЩОçѿГЬПЩвдЗжЮЊШчЯТЫФВНЃК
ЃЈ1ЃЉЩОГ§ЫљгаTSM FileжаТњзуЬѕМўЕФseriesЃЌЯЕЭГЛсБщРњЕБЧАshardжаЫљгаTSM FileЃЌМьВщИУFileжаЪЧЗёДцдкТњзуЩОГ§ЬѕМўЕФFileЃЌШчЙћгаЛсжДааШчЯТСНИіВйзїЃК
TSM File IndexЯрЙиДІРэЃКдкФкДцжаЩОГ§ТњзуЬѕМўЕФIndex EntryЃЌЭЈГЃЩОГ§ЛсДјгаTime RangeвдМАKey RangeЃЌЖјЧвTSM File IndexЛсдкв§ЧцЦєЖЏжЎКѓМгдиЕНФкДцЁЃвђДЫЩОГ§ВйзїЛсНЋТњзуЬѕМўЕФIndex EntryДгФкДцжаЩОГ§ЁЃ
ЩњГЩtombstonerЮФМўЃКtombstonerЮФМўЛсМЧТМЕБЧАTSM FileжаЫљгаБЛЩОГ§ЕФЪБађЪ§ОнЃЌЪБађЪ§ОнгУ[key, min, max]Ш§ИізжЖЮБэЪОЃЌЦфжаkeyМДSeriesKey+FieldKeyЃЌЃлmin, maxЃнБэЪОвЊЩОГ§ЕФЪБМфЖЮЁЃШчЯТЭМЫљЪОЃК
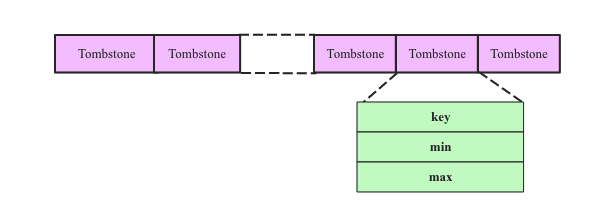
ЃЈ2ЃЉЩОГ§CacheжаТњзуЬѕМўЕФseries
ЃЈ3ЃЉдкWALжаЩњГЩвЛЬѕЩОГ§seriesЕФМЧТМВЂГжОУЛЏЕНгВХЬ
2. Inverted Index Engine БъМЧTagЩОГ§ВпТдЃЌБъМЧTagЩОГ§ЗЧГЃМђЕЅЃЌКЭвЛДЮаДШыСїГЬЛљБОЯрЭЌЃК
ЃЈ1ЃЉдкWALжаЩњГЩвЛЬѕflagЮЊdeletedЕФLogEntryВЂГжОУЛЏЕНгВХЬ
ЃЈ2ЃЉНЋвЊЩОГ§ЕФЮЌЖШаХЯЂаДШыCacheЃЌашвЊБъМЧdeletedЃЈЩшжУtype=deletedЃЉ
ЃЈ3ЃЉЕБWALДѓаЁГЌЙ§уажЕжЎКѓБъМЧЮЊdeletedЕФЮЌЖШаХЯЂЛсЫцCache FlushЕНЕЙХХЫїв§ЮФМў
ЃЈ4ЃЉКЭHBaseвЛбљЃЌInverted Index EngineжаЫїв§аХЯЂеце§БЛЩОГ§ЗЂЩњдкcompactНзЖЮ
змНс
InfluxDBвђЮЊЦфЬигаЕФЫЋLSMв§ЧцЖјЯдЕУФкВПНсЙЙИќМгИДдгЃЌаДШыСїГЬЯрБШЦфЫћЪ§ОнПтРДЫЕИќМгЗБЫіЁЃЕЋжЛвЊРэНтСЫЫќЕФЪ§ОнЮФМўФкВПзщжЏИёЪНвдМАЕЙХХЫїв§ЮФМўФкВПзщжЏИёЪНЃЌЯраХЖдгкећЬхЕФАбЮевВВЂВЛЪЧКмФбЁЃетЦЊЮФеТНЋжЎЧАНВЙ§ЕФЯрЙижЊЪЖЕуЭЈЙ§аДШыСїГЬЯЕЭГЕиДЎСЊСЫЦ№РДЃЌЯЃЭћПДЙйФмЙЛНшДЫЩюШыРэНтInfluxDBЕФЙЄзїдРэЁЃ
| 








