| БрМЭЦМі: |
БОЦЊЮФеТжївЊМЏжаНщЩмInfluxDBЛљБОВйзїЃЌПЭЛЇЖЫУќСюааЗНЪНВйзїЃЌЪ§ОнБЃДцВпТдЃЌЯЃЭћЖдФњгаЫљАяжњЁЃ
БОЮФРДздВЉПЭдАЃЌгЩЛ№СњЙћШэМўDeloresБрМЁЂЭЦМіЁЃ |
|
InfluxDBЛљБОИХФю
1ЁЂЪ§ОнИёЪН
дк InfluxDB жаЃЌЮвУЧПЩвдДжТдЕФНЋвЊДцШыЕФвЛЬѕЪ§ОнПДзївЛИіащФтЕФ key КЭЦфЖдгІЕФ value(field value)ЁЃИёЪНШчЯТЃК
cpu_usage,host=server01,region=us-west
value=0.64 1434055562000000000 |
ащФтЕФ key АќРЈвдЯТМИИіВПЗжЃК database, retention policy, measurement, tag sets, field name, timestampЁЃ
database: Ъ§ОнПтУћЃЌдк InfluxDB жаПЩвдДДНЈЖрИіЪ§ОнПтЃЌВЛЭЌЪ§ОнПтжаЕФЪ§ОнЮФМўЪЧИєРыДцЗХЕФЃЌДцЗХдкДХХЬЩЯЕФВЛЭЌФПТМЁЃ
retention policy: ДцДЂВпТдЃЌгУгкЩшжУЪ§ОнБЃСєЕФЪБМфЃЌУПИіЪ§ОнПтИеПЊЪМЛсздЖЏДДНЈвЛИіФЌШЯЕФДцДЂВпТд autogenЃЌЪ§ОнБЃСєЪБМфЮЊгРОУЃЌжЎКѓгУЛЇПЩвдздМКЩшжУЃЌР§ШчБЃСєзюНќ2аЁЪБЕФЪ§ОнЁЃВхШыКЭВщбЏЪ§ОнЪБШчЙћВЛжИЖЈДцДЂВпТдЃЌдђЪЙгУФЌШЯДцДЂВпТдЃЌЧвФЌШЯДцДЂВпТдПЩвдаоИФЁЃInfluxDB ЛсЖЈЦкЧхГ§Й§ЦкЕФЪ§ОнЁЃ
measurement: ВтСПжИБъУћЃЌР§Шч cpu_usage БэЪО cpu ЕФЪЙгУТЪЁЃ
tag sets: tags дк InfluxDB жаЛсАДеезжЕфађХХађЃЌВЛЙмЪЧ tagk ЛЙЪЧ tagvЃЌжЛвЊВЛвЛжТОЭЗжБ№ЪєгкСНИі keyЃЌР§Шч host=server01,region=us-west КЭ host=server02,region=us-west ОЭЪЧСНИіВЛЭЌЕФ tag setЁЃ
tag--БъЧЉЃЌдкInfluxDBжаЃЌtagЪЧвЛИіЗЧГЃживЊЕФВПЗжЃЌБэУћ+tagвЛЦ№зїЮЊЪ§ОнПтЕФЫїв§ЃЌЪЧЁАkey-valueЁБЕФаЮЪНЁЃ
field name: Р§ШчЩЯУцЪ§ОнжаЕФ value ОЭЪЧ fieldNameЃЌInfluxDB жажЇГжвЛЬѕЪ§ОнжаВхШыЖрИі fieldNameЃЌетЦфЪЕЪЧвЛИігяЗЈЩЯЕФгХЛЏЃЌдкЪЕМЪЕФЕзВуДцДЂжаЃЌЪЧЕБзїЖрЬѕЪ§ОнРДДцДЂЁЃ
timestamp: УПвЛЬѕЪ§ОнЖМашвЊжИЖЈвЛИіЪБМфДСЃЌдк TSM ДцДЂв§ЧцжаЛсЬиЪтЖдД§ЃЌвдЮЊСЫгХЛЏКѓајЕФВщбЏВйзїЁЃ
2ЁЂгыДЋЭГЪ§ОнПтжаЕФУћДЪзіБШНЯ
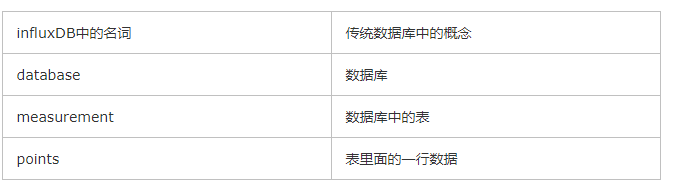
3ЁЂPoint
PointгЩЪБМфДСЃЈtimeЃЉЁЂЪ§ОнЃЈfieldЃЉЁЂБъЧЉЃЈtagsЃЉзщГЩЁЃ
PointЯрЕБгкДЋЭГЪ§ОнПтРяЕФвЛааЪ§ОнЃЌШчЯТБэЫљЪОЃК
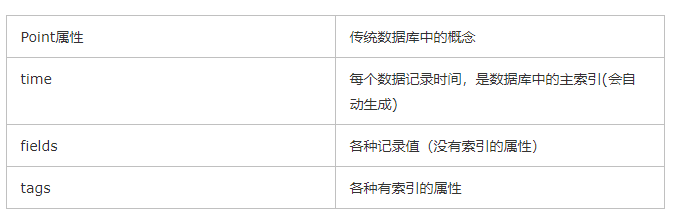
4ЁЂSeries
Series ЯрЕБгкЪЧ InfluxDB жавЛаЉЪ§ОнЕФМЏКЯЃЌдкЭЌвЛИі database жаЃЌretention policyЁЂmeasurementЁЂtag sets ЭъШЋЯрЭЌЕФЪ§ОнЭЌЪєгквЛИі seriesЃЌЭЌвЛИі series ЕФЪ§ОндкЮяРэЩЯЛсАДееЪБМфЫГађХХСаДцДЂдквЛЦ№ЁЃ
5ЁЂShard
Shard дк InfluxDB жаЪЧвЛИіБШНЯживЊЕФИХФюЃЌЫќКЭ retention policy ЯрЙиСЊЁЃУПвЛИіДцДЂВпТдЯТЛсДцдкаэЖр shardЃЌУПвЛИі shard ДцДЂвЛИіжИЖЈЪБМфЖЮФкЕФЪ§ОнЃЌВЂЧвВЛжиИДЃЌР§Шч 7Еу-8Еу ЕФЪ§ОнТфШы shard0 жаЃЌ8Еу-9ЕуЕФЪ§ОндђТфШы shard1 жаЁЃУПвЛИі shard ЖМЖдгІвЛИіЕзВуЕФ tsm ДцДЂв§ЧцЃЌгаЖРСЂЕФ cacheЁЂwalЁЂtsm fileЁЃ
6ЁЂзщМў
TSM ДцДЂв§ЧцжївЊгЩМИИіВПЗжзщГЩЃК cacheЁЂwalЁЂtsm fileЁЂcompactorЁЃ
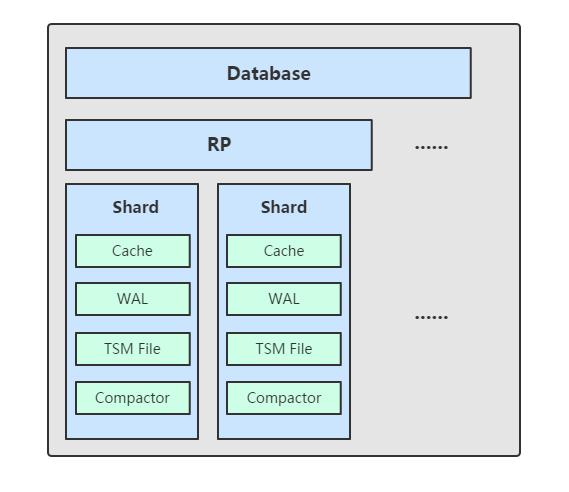
1ЃЉCacheЃКcache ЯрЕБгкЪЧ LSM Tree жаЕФ memtablЁЃВхШыЪ§ОнЪБЃЌЪЕМЪЩЯЪЧЭЌЪБЭљ cache гы wal жааДШыЪ§ОнЃЌПЩвдШЯЮЊ cache ЪЧ wal ЮФМўжаЕФЪ§ОндкФкДцжаЕФЛКДцЁЃЕБ InfluxDB ЦєЖЏЪБЃЌЛсБщРњЫљгаЕФ wal ЮФМўЃЌжиаТЙЙдь cacheЃЌетбљМДЪЙЯЕЭГГіЯжЙЪеЯЃЌвВВЛЛсЕМжТЪ§ОнЕФЖЊЪЇЁЃ
cache жаЕФЪ§ОнВЂВЛЪЧЮоЯодіГЄЕФЃЌгавЛИі maxSize ВЮЪ§гУгкПижЦЕБ cache жаЕФЪ§ОнеМгУЖрЩйФкДцКѓОЭЛсНЋЪ§ОнаДШы tsm ЮФМўЁЃШчЙћВЛХфжУЕФЛАЃЌФЌШЯЩЯЯоЮЊ 25MBЃЌУПЕБ cache жаЕФЪ§ОнДяЕНЗЇжЕКѓЃЌЛсНЋЕБЧАЕФ cache НјаавЛДЮПьееЃЌжЎКѓЧхПеЕБЧА cache жаЕФФкШнЃЌдйДДНЈвЛИіаТЕФ wal ЮФМўгУгкаДШыЃЌЪЃЯТЕФ wal ЮФМўзюКѓЛсБЛЩОГ§ЃЌПьеежаЕФЪ§ОнЛсОЙ§ХХађаДШывЛИіаТЕФ tsm ЮФМўжаЁЃ
2ЃЉWALЃКwal ЮФМўЕФФкШнгыФкДцжаЕФ cache ЯрЭЌЃЌЦфзїгУОЭЪЧЮЊСЫГжОУЛЏЪ§ОнЃЌЕБЯЕЭГБРРЃКѓПЩвдЭЈЙ§ wal ЮФМўЛжИДЛЙУЛгааДШыЕН tsm ЮФМўжаЕФЪ§ОнЁЃ
3ЃЉTSM FileЃКЕЅИі tsm file ДѓаЁзюДѓЮЊ 2GBЃЌгУгкДцЗХЪ§ОнЁЃ
4ЃЉCompactorЃКcompactor зщМўдкКѓЬЈГжајдЫааЃЌУПИє 1 УыЛсМьВщвЛДЮЪЧЗёгаашвЊбЙЫѕКЯВЂЕФЪ§ОнЁЃ
жївЊНјааСНжжВйзїЃЌвЛжжЪЧ cache жаЕФЪ§ОнДѓаЁДяЕНЗЇжЕКѓЃЌНјааПьееЃЌжЎКѓзЊДцЕНвЛИіаТЕФ tsm ЮФМўжаЁЃ
СэЭтвЛжжОЭЪЧКЯВЂЕБЧАЕФ tsm ЮФМўЃЌНЋЖрИіаЁЕФ tsm ЮФМўКЯВЂГЩвЛИіЃЌЪЙУПвЛИіЮФМўОЁСПДяЕНЕЅИіЮФМўЕФзюДѓДѓаЁЃЌМѕЩйЮФМўЕФЪ§СПЃЌВЂЧввЛаЉЪ§ОнЕФЩОГ§ВйзївВЪЧдкетИіЪБКђЭъГЩЁЃ
7ЁЂФПТМгыЮФМўНсЙЙ
InfluxDB ЕФЪ§ОнДцДЂжївЊгаШ§ИіФПТМЁЃФЌШЯЧщПіЯТЪЧ meta, wal вдМА data Ш§ИіФПТМЁЃ
meta гУгкДцДЂЪ§ОнПтЕФвЛаЉдЊЪ§ОнЃЌmeta ФПТМЯТгавЛИі meta.db ЮФМўЁЃ
wal ФПТМДцЗХдЄаДШежОЮФМўЃЌвд .wal НсЮВЁЃ
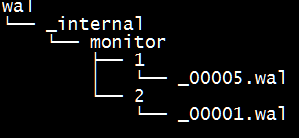
data ФПТМДцЗХЪЕМЪДцДЂЕФЪ§ОнЮФМўЃЌвд .tsm НсЮВЁЃ
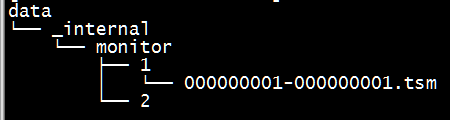
ЩЯУцМИеХЭМжаЃЌ_internalЮЊЪ§ОнПтУћЃЌmonitorЮЊДцДЂВпТдУћГЦЃЌдйЯТвЛВуФПТМжаЕФвдЪ§зжУќУћЕФФПТМЪЧ shard ЕФ ID жЕЁЃ
ДцДЂВпТдЯТгаСНИі shardЃЌID ЗжБ№ЮЊ 1 КЭ 2ЃЌshard ДцДЂСЫФГвЛИіЪБМфЖЮЗЖЮЇФкЕФЪ§ОнЁЃдйЯТвЛМЖЕФФПТМдђЮЊОпЬхЕФЮФМўЃЌЗжБ№ЪЧ .wal КЭ .tsm НсЮВЕФЮФМўЁЃ
InfluxDBЛљБОВйзї
InfluxDBЬсЙЉЖржжВйзїЗНЪНЃК
1ЃЉПЭЛЇЖЫУќСюааЗНЪН
2ЃЉHTTP APIНгПк
3ЃЉИїгябдAPIПт
4ЃЉЛљгкWEBЙмРэвГУцВйзї
ПЭЛЇЖЫУќСюааЗНЪНВйзї
НјШыУќСюаа
| influx -precision
rfc3339 |

1ЁЂInfluxDBЪ§ОнПтВйзї
ЯдЪОЪ§ОнПт
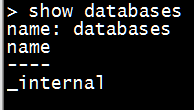
аТНЈЪ§ОнПт
| create database
shhnwangjian |
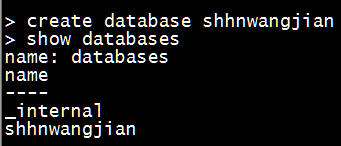
ЩОГ§Ъ§ОнПт
| drop database
shhnwangjian |
ЪЙгУжИЖЈЪ§ОнПт

2ЁЂInfluxDBЪ§ОнБэВйзї
дкInfluxDBЕБжаЃЌВЂУЛгаБэЃЈtableЃЉетИіИХФюЃЌШЁЖјДњжЎЕФЪЧMEASUREMENTSЃЌMEASUREMENTSЕФЙІФмгыДЋЭГЪ§ОнПтжаЕФБэвЛжТЃЌвђДЫЮвУЧвВПЩвдНЋMEASUREMENTSГЦЮЊInfluxDBжаЕФБэЁЃ
ЯдЪОЫљгаБэ
аТНЈБэ
InfluxDBжаУЛгаЯдЪНЕФаТНЈБэЕФгяОфЃЌжЛФмЭЈЙ§insertЪ§ОнЕФЗНЪНРДНЈСЂаТБэ
insert disk_free,hostname=server01
value=442221834240i |
Цфжа disk_free ОЭЪЧБэУћЃЌhostnameЪЧЫїв§ЃЈtagЃЉЃЌvalue=xxЪЧМЧТМжЕЃЈfieldЃЉЃЌМЧТМжЕПЩвдгаЖрИіЃЌЯЕЭГздДјзЗМгЪБМфДС

ЛђепЬэМгЪ§ОнЪБЃЌздМКаДШыЪБМфДС
insert disk_free,hostname=server01
value=442221834240i 1435362189575692182 |

ЩОГ§Бэ
| drop measurement
disk_free |
3ЁЂЪ§ОнБЃДцВпТдЃЈRetention PoliciesЃЉ
influxDBЪЧУЛгаЬсЙЉжБНгЩОГ§Ъ§ОнМЧТМЕФЗНЗЈЃЌЕЋЪЧЬсЙЉЪ§ОнБЃДцВпТдЃЌжївЊгУгкжИЖЈЪ§ОнБЃСєЪБМфЃЌГЌЙ§жИЖЈЪБМфЃЌОЭЩОГ§етВПЗжЪ§ОнЁЃ
ВщПДЕБЧАЪ§ОнПтRetention Policies
| show retention
policies on "db_name" |

ДДНЈаТЕФRetention Policies
create retention
policy "rp_name" on
"db_name"
duration 3w replication 1 default |
rp_nameЃКВпТдУћЃЛ
db_nameЃКОпЬхЕФЪ§ОнПтУћЃЛ
3wЃКБЃДц3жмЃЌ3жмжЎЧАЕФЪ§ОнНЋБЛЩОГ§ЃЌinfluxdbОпгаИїжжЪТМўВЮЪ§ЃЌБШШчЃКhЃЈаЁЪБЃЉЃЌdЃЈЬьЃЉЃЌwЃЈаЧЦкЃЉЃЛ
replication 1ЃКИББОИіЪ§ЃЌвЛАуЮЊ1ОЭПЩвдСЫЃЛ
defaultЃКЩшжУЮЊФЌШЯВпТд
аоИФRetention Policies
alter retention
policy "rp_name" on
"db_name"
duration 30d default |
ЩОГ§Retention Policies
| drop retention
policy "rp_name" on "db_name" |
4ЁЂСЌајВщбЏЃЈContinuous QueriesЃЉ
InfluxDBЕФСЌајВщбЏЪЧдкЪ§ОнПтжаздЖЏЖЈЪБЦєЖЏЕФвЛзщгяОфЃЌгяОфжаБиаыАќКЌ SELECT ЙиМќДЪКЭ GROUP BY time() ЙиМќДЪЁЃ
InfluxDBЛсНЋВщбЏНсЙћЗХдкжИЖЈЕФЪ§ОнБэжаЁЃ
ФПЕФЃКЪЙгУСЌајВщбЏЪЧзюгХЕФНЕЕЭВЩбљТЪЕФЗНЪНЃЌСЌајВщбЏКЭДцДЂВпТдДюХфЪЙгУНЋЛсДѓДѓНЕЕЭInfluxDBЕФЯЕЭГеМгУСПЁЃЖјЧвЪЙгУСЌајВщбЏКѓЃЌЪ§ОнЛсДцЗХЕНжИЖЈЕФЪ§ОнБэжаЃЌетбљОЭЮЊвдКѓЭГМЦВЛЭЌОЋЖШЕФЪ§ОнЬсЙЉСЫЗНБуЁЃ
аТНЈСЌајВщбЏ
CREATE CONTINUOUS
QUERY <cq_name>
ON <database_name>
[RESAMPLE [EVERY <interval>]
[FOR <interval>]]
BEGIN SELECT <function>(<stuff>)
[,<function>(<stuff>)]
INTO
<different_measurement>
FROM <current_measurement>
[WHERE <stuff>]
GROUP BY time
(<interval>)[,<stuff>]
END |
бљР§ЃК
CREATE CONTINUOUS
QUERY wj_30m ON
shhnwangjian BEGIN SELECT mean
(connected_clients),
MEDIAN
(connected_clients), MAX(connected_clients),
MIN(connected_clients) INTO redis_clients_30m
FROM redis_clients GROUP BY ip,port,
time(30m)
END |
дкshhnwangjianПтжааТНЈСЫвЛИіУћЮЊ wj_30m ЕФСЌајВщбЏЃЌУПШ§ЪЎЗжжгШЁвЛИіconnected_clientsзжЖЮЕФЦНОљжЕЁЂжаЮЛжЕЁЂзюДѓжЕЁЂзюаЁжЕ redis_clients_30m БэжаЁЃЪЙгУЕФЪ§ОнБЃСєВпТдЖМЪЧ defaultЁЃ
ВЛЭЌdatabaseбљР§ЃК
CREATE CONTINUOUS
QUERY wj_30m ON
shhnwangjian_30 BEGIN SELECT mean
(connected_clients),
MEDIAN(connected_clients),
MAX(connected_clients),
MIN(connected_clients) INTO
shhnwangjian_30.autogen.redis
_clients_30m
FROM shhnwangjian.autogen.
redis_clients GROUP
BY ip,port,time(30m) END |
ЯдЪОЫљгавбДцдкЕФСЌајВщбЏ

ЩОГ§Continuous Queries
DROP CONTINUOUS
QUERY <cq_name>
ON <database_name> |
| 








