|
我们经常能在科幻影片里能看到各种机器人与人类同台出演,与人类自由的沟通交流,甚至比人类更加聪明。大家肯定想知道这样的人造机器是如何做到的,我们现在真的能造出这样的机器人吗?
开玩笑,我在这绝不可能解释好这个问题,但是从另一个角度简单来讲,与机器人交流其实这是通过语音来实现与机器交互,互动的一种操作,人与机器人的沟通其核心的一个方面便是语音的识别,就是说机器人得先听懂人说话。那此文就来浅聊下关于通过语音来实现人机交互的一些问题。
我们先看一个较简单的例子 ―― Windows语音识别程序:

Windows语音识别功能主要是使用声音命令指挥你的电脑,实现离开键盘鼠标来实现人机交互。通过声音控制窗口、启动程序、在窗口之间切换,使用菜单和单击按钮等功能。Windows语音识别功能仅仅限于
Windows系统体系内的一些常用操作和指令,并且是与监视器显示辅助来完成整个语音操作。
例如你想用语音通过主菜单打开某个程序,当你说出“开始”后,系统将会提供一个“显示编号”的区块划分功能,(编号是半透明的,使你能知道此编号下是哪个程序或文件夹)这样假如你想打开“下载”这个文件夹,你只需说出它的编号“10”,程序就会给你打开“下载”这个文件夹了。这样做的原因一是因为:如果你需要开启用户自行安装的纷繁复杂的程序,Windows的语音库里面可能没有这些程序相应的名称,会造成识别不准,甚至无法识别,二是通过显示编号,和语音识别编号,响应指令的效率更高,因此这样语音配合监视器的分模块显示大大的提高了用户使用Windows系统的效率和准确率。
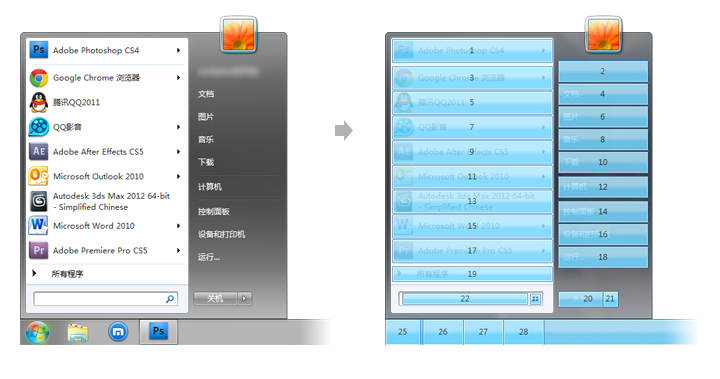
同样,如果你对桌面的快捷方式或文件进行语音操作,系统将会提供一个称之为“鼠标网络”的功能,对桌面进行以前区域的划分和自动编号,用语音+视觉来提高操作效率和识别的精准率:
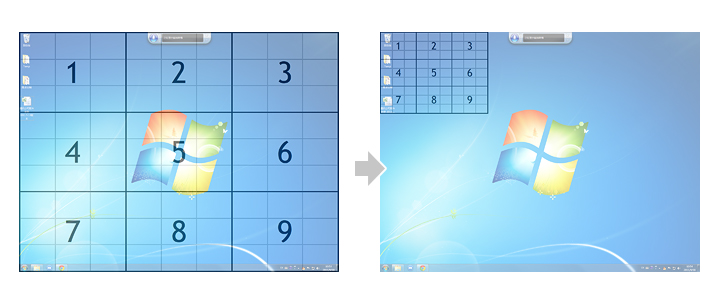
在目前Windows的语音识别程序中,除文本的语音输入(包括文字和符号)之外,还包括16个常用命令,9项常用控件命令,31项文本处理命令,15项窗口命令,5个点击屏幕任意位置命令,以及另外的几组键盘命令。用户所能语音指挥的也就是围绕这些预先准备好了的命令进行交互操作,旨在这将有可能提高使用电脑的效率,和尽可能的把双手从鼠标键盘上解放出来。
与此初衷相类似的我们还能在目前主流的移动设备上能看到语音识别功能的应用:
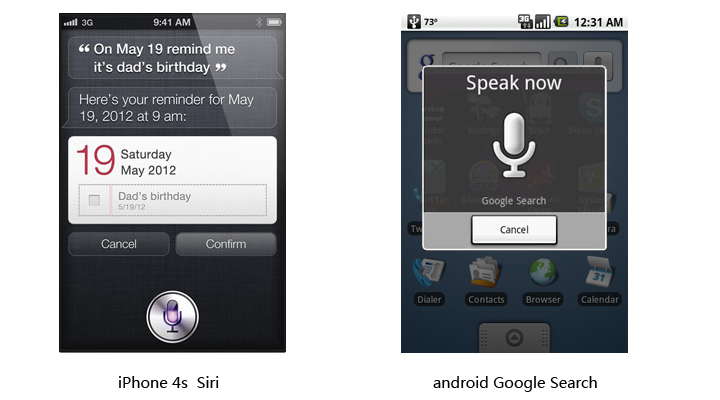
然后我们在前进一点,再想一下假如现在我们要面对的不是电脑,手机,而是一个机器人!一位拟人化,仿真化的机器人,对比上面的例子你会很容易发现它和常用的电子设备的不同之处在于,它很可能是不会有一个我们通常所见的显示屏,那以上那些通过语音指令结合屏幕可视化辅助来进行的高效的交互方式在机器人身上就收到了限制。在这种情况下你面对着机器人,你肯定会想它在听我说话吗?它能听懂我说话吗?我说什么它能听懂?我说什么它可能听不懂?等等这样一对问题会立即扑面而来。
其实在我们现有的技术水平和条件下,特别是面向大众商用的机器人,想做到像电影里面那种人和机器人自由交流的情景几乎是不可能。当然我们做一个产品,当然会有功能定位和市场需求等等很多方面要考虑的,那我在这里讨论的是一台为用户提供各种咨询和能进行简单语音逻辑“聊天”的机器人,需要如何处理语音交互方面的问题,这里以Qrobot为例,尽可能不依赖电脑屏幕,而直接来与人互动和提供各种咨询的机器人。
人是上帝创造的,而机器人是由人创造的,在现有知识和技术条件下,在人类赋予他特定的能力之前,机器人是什么也做不了的。下面我将分几点来讨论要想实现与机器人交互沟通需要做哪些工作:
一,给机器人提供一个“大脑”―― 思想的材料:知识、语言库。像Qrobot这样提供各种海量咨询和交流操作功能的机器人,如果把所有的这些“原材料”堆在一堆,一旦你有求于它的时候,它可能会慌了手脚,不知所云。(机器人无法根据对话的前后关系以及语境来判断某一个词在当前情境下恰当的含义)因此我们先会把机器人的语音知识库进行分类,把不同类型和专业的词语库分开来,以提高机器人的工作效率和服务的准确度。那这样用户如需要获得哪方面的信息和功能,就要先让机器人“思维”进入相应的语言库中。比如你通过机器人来了解“音乐”方面的信息的时候,你需要让机器人进入音乐相关的“语库思维”中,那在这个情况下它会把你说的任何话当作“音乐”相关的内容或指令了。
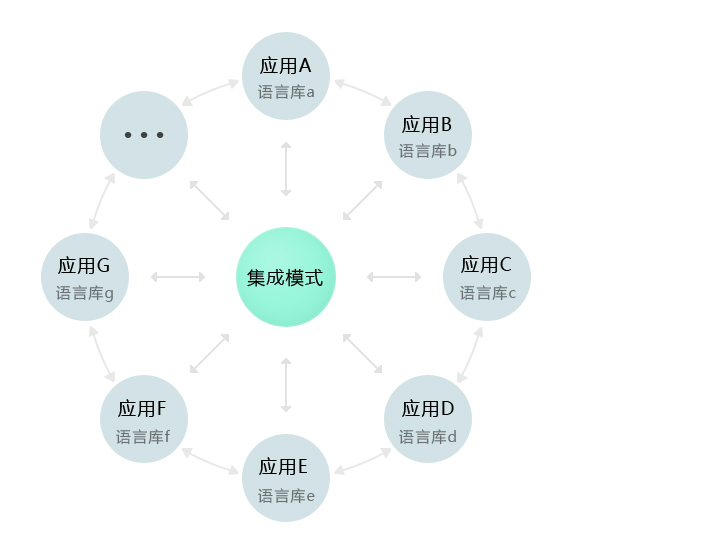
这里对比下苹果最近发布的iPhone 4s 的Siri,根据资料分析来看Siri是一个集中统一的语音分析处理中心,它通过监听用户语音,然后提取关键词来理解用户意图,(当然用户事先要知道iPhone能帮他做些什么)然后可能经过跟你确认,再触发相应的功能和服务。因此它最终提供功能咨询和服务来自于整个iPhone系统不论是本地Apps或是云端(网络APIs)已经准备整合好了的咨询信息及功能。这样的处理方式能使产品看起来更加的聪明和易用。
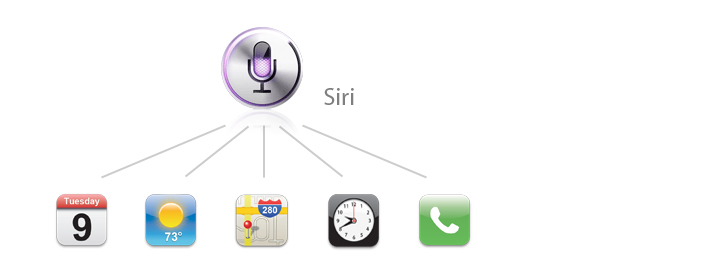
当然除了被分区的专业语库外,机器人还得有个“正常人”的思维,即识别专业语言库以外的各种指令和普通对话,(上图的集成模式)否则的话它将只能是“机器”而无“人”了。
二,Qrobot各分区之间的的转换以及从语音库分区回到“集成模式”除语音指令外,还需要假如非语音方式的的中间干预,这就涉及到触发监听和监听时机控制问题。
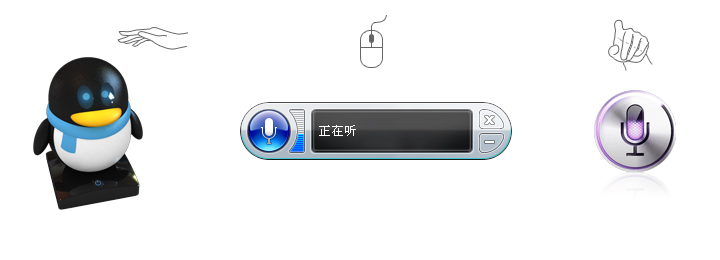
从上图可以看到Windows的语音识别程序是通过一个浮动控制器开关来使机器听取你的指令与否。这里可以通过语音来让程序进取关闭状态,但是处于关闭状态则无法用语音来命令它重新启动了,这时候需要回到鼠标操作。
iPhone的语音控制功能是通过触摸屏幕启动Siri程序后进入一个语音模式,在这个环境下用户才能使用语音操作手机和使用服务,如果退出Siri手机将不能听懂你任何声音。
同样你不会让Qrobot机器人一直听你说话,或是你需要它提供某特定信息的时候如何让它迅速的进入相应的语音区域,高效准确的提供信息。机器人不可能用一只鼠标去操作,这里我们给机器人设计一个响应区和相应手势:
1,用触摸响应区域来控制机器人听或不听指令
2,用触摸响应区域+配合语音指令的复合方式来切换机器人的语音库
或使用特定规范的词语句来激发机器人进入或切换语音区来高效准确的获取信息。(同样也分以上两类指令)
另外在不同的情况下,机器人听用户指令的状态也是不一样的,比如在“对话”状态下,机器人需要连续语音识别,这既基于情境需要同时也基于语音技术,而比如在功能操作或者咨询获取的以及机器人自己说话的时候并不需要连续语音识别,而是设置一个适当的语音监听时长,一旦超出这个监听时间,机器人则不进行识别,也不会造成误听和误操作。
三,同一个话题的表达可能会有很多种表述方式,同样任何问题的答案也都不是单一的,因此第二个工作是需要让机器人能尽可能的听懂关于一件事情的各种不同表述方式,和让机器人响应你的请求或问题时每次会以不同的方式甚至情绪来表现出来(这样能让机器人显得更加的聪明和人性化)。
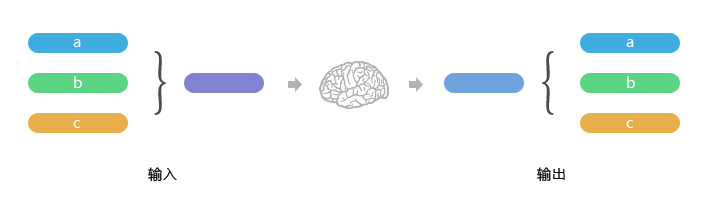
如上图,由于语言的灵活性和丰富度,在语音库的配置上面就需要在输入和输出两方面做大量的工作,这包括本地(机器人内置存储空间)和云端两块。
对一个指令的意思需要在语库中准备和配置好多种的语言表述方式,和可能的关键字词,以便在用户使用的各种表述方式的情况下都能准确的判断出指令的意图,来提供准确的反馈和服务。
另一方面,当机器人理解了指令然后经过“大脑”处理之后把结果反馈给用户的时候,如上文所说,设计者不可能只有一份准备,如何既能让用户得到准确的信息,又能体现出机器人的“人情味”来,同样也需要做大量技术算法的储备和语句、关键字词准备配置工作等等,使每次输出既恰如其分,又灵活生动。
由于目前我们日常能接触到的和能使用的语音交互产品不是很多,技术水平也还不能尽如人意。以上文字只从几个基础的方面浅浅的触碰了以语音识别为基础的交互及产品,那目前来说语音交互对使用者的价值可能体现在以下种情况:
1. 用户有视觉方面的损伤和缺陷
2. 用户肢体处于忙碌状态
3. 用户的眼睛被其它事情占用时
4. 需要灵活反应时
5. 在某些场合不方便使用键盘、鼠标等其它输入形式时
但是语音交互形式相对于其它交互形式还是有其不足,比如与手指交互比,语音交互增加用户认知负担;语音交互容易受到外部噪音的干扰;还有遇到用户、环境等变化语音识别将会变的不稳定等等。我这里只是借Qrobot项目中涉及到的一些语音交互方面的问题,以简明直截了当的语言进行一下梳理和讨论,也非常欢迎对这领域有兴趣的同学来指点和讨论。 | 

