| 编辑推荐: |
本文阐述了钉钉审批消息链路重构的设计和解决方案。希望对你的学习有帮助。
本文来自于微信公众号阿里开发者,由火龙果软件Linda编辑、推荐。 |
|
引入消息队列可以帮助我们解耦业务逻辑,提升性能,让主链路更加清晰。但是消息链路的代码腐化和一致性问题也给业务带来了很多困扰,本文阐述了钉钉审批消息链路重构的设计和解决方案。注:Metaq
是阿里 RocketMQ 消息队列的内网版本。
概述
引入消息队列可以帮助我们解耦业务逻辑,提升性能,让主链路更加清晰。Metaq 也确实可靠,重试机制能够保障足够的一致性。
钉钉审批将审批中的关键事件,比如审批单发起,任务开始,任务结束以及审批单结束等等作为消息发布出去,将审批的主体流程和周边业务清晰地分开。
但是经过数年的产品迭代,周边业务越来越多,消息链路越来越复杂(详见 “消息链路的美好幻想与残酷现实”
章节):
1、不同的业务逻辑堆砌在一起互相影响,单个消息处理方法就能有上千行代码。
2、因为逻辑太复杂无法实现幂等,只能放弃重试,不一致问题严重。每个业务都必须额外开发复杂的对账,补偿机制才能避免客诉。
钉钉审批每分钟都会数十万条消息的发出,从监控可以看出平均每分钟都会有百条消息失败(有的时候会有千条),失败率大约
0.5%。
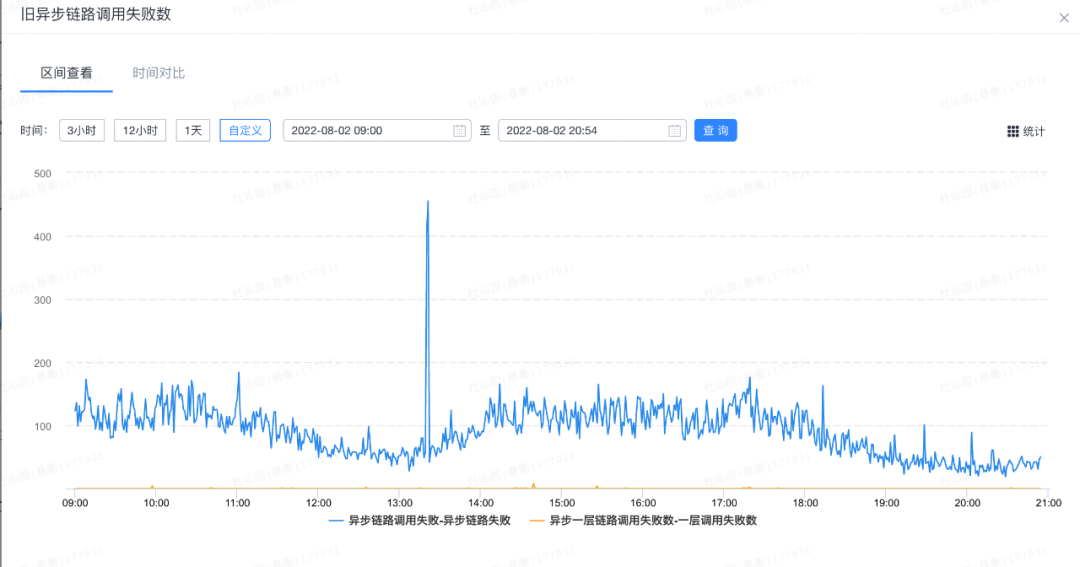
通过本文的最佳实践,将能实现:
1、将堆砌在一起的逻辑拆分成一个个业务 Listener 类(详见 “朴素的拆分想法” 章节);
2、当有业务 Listener 失败时,可以实现失败业务精准重试,而不是粗暴地全部重试(详见 “精准重试”
章节);
3、高性能地构建 Listener 的统一上下文,降低读扩散,并且避免其随着迭代腐化(详解 “统一上下文”
章节);
4、最后,本文的实践不需要额外的存储,也不需要建立额外的 Consumer,原来的基础设施可以直接复用;
通过下图监控可以看出,经过本文方案的治理,消息链路每天只有非常零星的失败(约几十个),而审批每天要发送两亿以上的消息,失败率只有约
0.000005%。
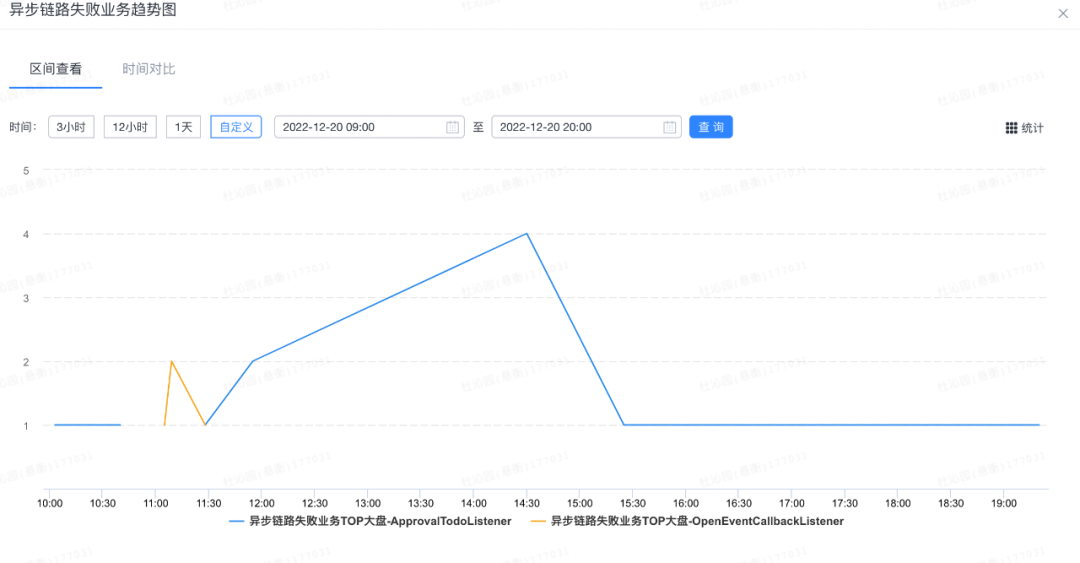
图中只有顶点处存在失败,其他都是 Sunfire 的自动连线,不存在失败。
消息链路的美好幻想与残酷现实
美好幻想
消息队列在设计之初就给业务规划好了一条康庄大道:
主业务链路作为 Producer 发出消息
数十个甚至更多 Consumer 订阅该消息,分别执行自己快速且幂等的原子逻辑
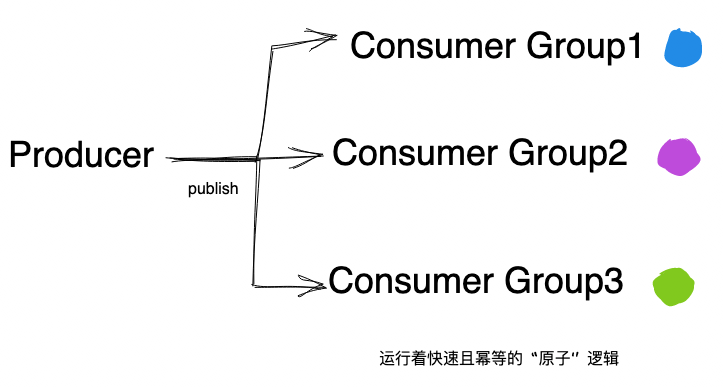
在这种设计下,每个订阅者的逻辑相互隔离,互不影响;能够独立地重试,保证自己的一致性。
残酷现实
现实并不总像上面幻想的那样,随着业务发展常会出现一些 “大泥球” 消费者。
以钉钉审批为例,为了优化产品体验,在审批单发起后,还要消费审批单发起消息,异步做一系列的事情,比如发消息通知,同步搜索引擎,更新提示红点等等,这些功能随着产品迭代只会越叠越多,最后成为一个同时做十几件事情的
“大泥球” 消费者。
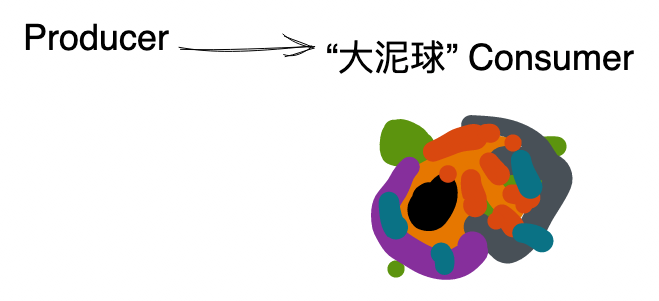
大泥球 Consumer 对系统和用户都有巨大的损害:
逻辑相互影响,修改风险高;
链路脆弱,容易中断,一个调用失败,后续所有逻辑将不会执行;
没有重试:大泥球无法做到原子和幂等,整体重试代价太大,所以直接异步执行放弃重试;
消息队列引以为傲的重试功能反而会成为故障的温床,导致雪崩。
为什么不直接把大泥球拆分成前面的多个 Consumer 呢?这确实也是一种方案,但是对于大泥球 Consumer,可能会拆出几十个
Consumer,这会导致非常严重的读扩散。举个例子,审批单发起的消息中只含有审批单的 id,内容需要从数据库反查,原本在“大泥球”中,只需要查询一次就复用,而拆分后可能要多查几十次。这还只是众多扩散问题的其中一个,如果为了治理大泥球,却加重了扩散问题,就得不偿失了。
朴素的拆分想法
最简单的想法就是把大泥球中相关的逻辑聚合到一起,不相关的逻辑隔离,拆成一个个独立的业务处理器,俗称
“高内聚低耦合”。
在一个审批单的生命周期中会有很多种类的消息发出,比如审批单发起,审批单结束,审批任务生成,审批任务完成,审批抄送等等,我们可以将这些将这些消息的处理逻辑聚合到一个业务处理器中,只需要实现这个接口的
onXxx 方法,就能将逻辑嵌入整个审批的生命周期中。这个业务处理器接口在审批中就是 ProcessEventListener:
public interface ProcessEventListener extends
EventListener {
/**
* 审批单发起事件
*/
void onProcessInstanceStart(InstanceEventContext
instanceEventContext);
/**
* 审批单结束事件
*/
void onProcessInstanceFinish(InstanceEventContext
instanceEventContext);
/**
* 审批任务生成事件
*/
void onTaskActivated(TaskEventContext taskEventContext);
// 省略其他事件
// ...
} |
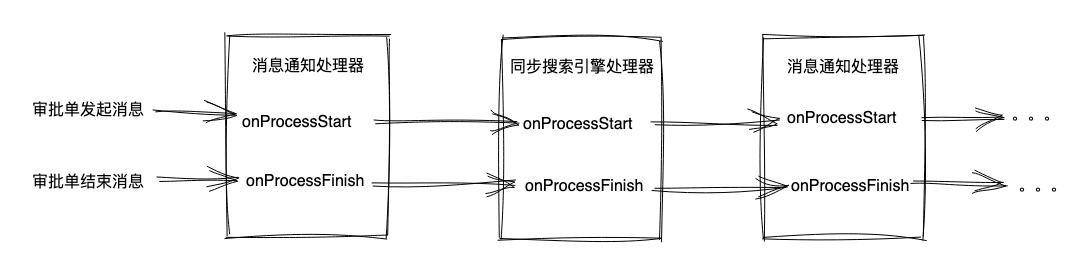
通过在框架层面 catch 异常就能够避免链路因为单个业务的失败而折断,用伪代码表述如下:
// 接到审批单发起消息
InstanceEventContext instanceEventContext = buildContext();
for (handler : handlers) {
try {
handler.onProcessInstanceStart(instanceEventContext);
} catch (Exception e) {
// 打印监控日志等等
// ...
}
} |
现在虽然逻辑内聚了,链路更加健壮了,但是还有很多技术上的问题没有解决:
某个处理器因为网络超时失败了,如何重试?:我们仅仅是将逻辑拆开了,执行的时候还是一串 “大泥球”,如果仅仅依靠消息队列本身机制,要重试只能一起重试,这显然无法满足诉求;
如何高性能地构建庞大的统一上下文(即Context 参数):为了满足众多处理器对数据查询的诉求,需要提供庞大的上下文,除了性能风险外,也是代码腐败的温床
我们先来看看第一个问题。
精准重试
当处理器因为超时等意外情况失败时,如果业务重要的话,都需要补偿重试。但是不同处理器对重试的诉求可能不同,为此我们在上一节朴素想法的基础上,还实现了多种重试策略,并且支持单独指定最大重试次数:
Ignore:非重要业务,失败就算了,不需要重试;
Concurrent:在另外线程池中并发执行,也不会重试。适合一些容易影响后续执行的长耗时的处理器;
Retry Now:立即重试。会将任务放到本地的一个延迟队列中,100~500ms 后重试。适合时效性比较强的处理器;
Retry Later:重投消息,精确重试失败的处理器,遵从 Metaq 的重投延迟,前三次重试分别是1s
5s 10s,因此不适合时效性强的处理器;
为了方便使用,我们将这些策略做成了注解的形式,比如审批抄送时效性没这么强,可以使用 Retry Later
策略:
public class
CcListener implements ProcessEventListener {
// Retry Later 策略, 最多重试两次
@Policy(value = PolicyType.RETRY_LATER, retry
= 2)
@Override
public void onProcessInstanceStart(InstanceEventContext
instanceEventContext) {
//... 逻辑省略
}
} |
再比如审批待办同步,是时效性比较强的,间隔太久容易有时效性问题,可以使用 Retry Now 策略:
public class SyncTodoTaskListener implements ProcessEventListener
{
// Retry Now 策略, 最多重试三次
@Policy(value = PolicyType.RETRY_NOW, retry =
3)
@Override
public void onProcessInstanceStart(InstanceEventContext
instanceEventContext) {
//... 逻辑省略
}
} |
前三种策略都比较好理解,就不多说了。下文重点讨论最后一种策略是如何实现的。
要想实现精准重试,只需要记下每个处理器的执行状态,比如重试到第几次,是否成功等等。这种流水数据使用关系数据库记会比较重,因此我们利用
Metaq 提供的 UserProperty,将各个业务处理器的执行状态以 json 的形式存储在
RETRY_STORE 这个 UserProperty 中,然后重投到另一个专门的重试 topic
中。
处理器的执行状态存储格式如下:
{
// 总体重试次数, 第一次重试(第 0 次代表正常执行)
"globalCnt":
1,
// 每个处理器的执行状态
"cntMap": {
// handler1 第 1 次重试, 读取该属性可以判断 handler1 是否还有重试机会
"handler1": 1,
// -1 表示 handler2 已经执行成功, 不需要再执行
"handler2":
-1,
// -2 表示 handler3 已经彻底执行失败(一般是超过了设置的最大重试次数), 不需要再执行
"handler3": -2
}
} |
正常执行结束后,如果存在失败的处理器,并且没有达到最大重试次数,会生成上面这种格式的执行报告,存放到
RETRY_STORE 这个 UserProperty 中再重投消息,简化代码如下:
Message message = new Message();
// 重投到专门的重试主题
message.setTopic("my-retry-topic");
// 消息体保持不变
message.setBody(preBody);
// nextCnt 是重试的次数
// 设置 DelayTimeLevel 能够让重投有一定的延时
message.setDelayTimeLevel(nextCnt);
// 将本次执行状态存储到 user property 中
message.putUserProperty("RETRY_STORE",
"{\"globalCnt\":1,\"cntMap\":{\"handler1\":1,\"handler2\":-1,\"handler3\":-2}}");
// 发送消息
mqPublishService.send(message); |
虽然我们另起了一个专门重试用的 topic,但是消费者的逻辑跟原 topic 是完全一样的,理论上直接重投原来的
topic 也是可以的,但还是分离开更加安全。
总体思路如图:
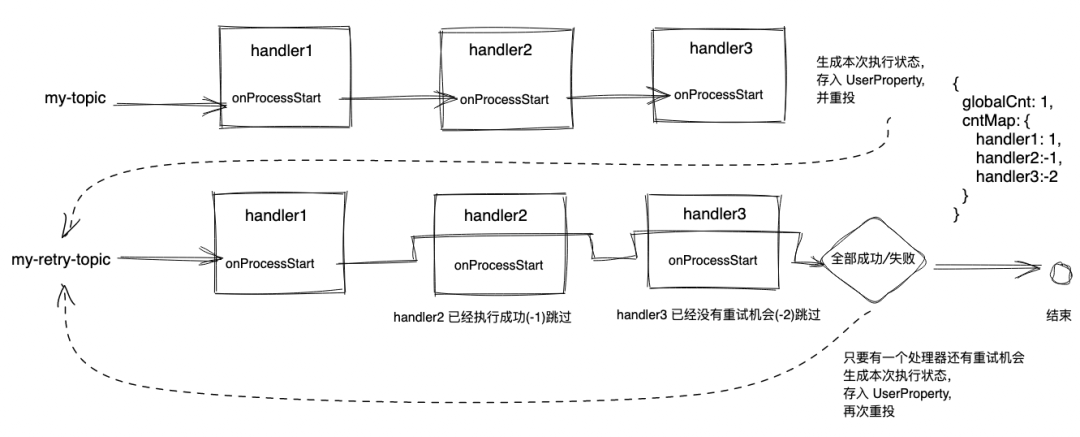
图中的重投都是指往 topic 再发一遍消息,而不是 Metaq 自身的重投机制。
其中有一些细节问题需要注意,比如某次发布中上线了一个新的处理器,而发布机器刚好接到了一个重试消息,如何才能避免新处理器被意外执行呢?我们之前记录的执行状态
cntMap 中的所有 key 就相当于首次执行时的处理器快照,我们重试时只执行 cntMap 中存在的
key 就好了。
另外 Metaq 的 UserProperty 大小也不是没有限制,它最多能存储 30KB 的数据,粗略计算一下大约可以存储
1500 个处理器的状态,这对大多业务来说都是绰绰有余的了。
统一上下文
另一个问题则是由于我们的编码结构导致的,每个处理器都接收相同的上下文参数(XxxContext)处理业务,这种
"上下文 + 处理器" 的结构在业务系统上很常见,但是它存在几个问题:
为了满足所有处理器的需求,上下文往往会很庞大,因此构建性能差。
外部无法感知处理器内部需要使用上下文的哪些字段,只能一股脑地将所有字段都填充好,传递进去,而且内部很有可能一个字段都不使用,白白损耗了性能。
上下文中存在一些幽灵字段,在某个处理器中设置进去,又在某几个处理器中读取,也就是它有时候为 null,有时候又有值,维护难度巨大,从中取个值都要战战兢兢。
读扩散问题:每个处理器都去读相同的数据,导致链路数十倍的读扩散。
懒加载
前两个问题可以通过引入懒加载机制解决,对于上下文中性能损耗比较大的字段,在读取时再进行加载。这样上下文的构建就非常快了
,也不会去额外加载处理器中用不到的字段。
懒加载的思路非常简单,就是第一次读取字段时再通过远程调用,SQL 等性能消耗较大的方式获取字段值,获取之后在内存缓存起来,后续直接从内存返回。但是在编码设计上有一些小技巧,可以让它用起来跟普通字段一样,为此我们开发了一个
Lazy 框架,用来将这部分懒加载逻辑封装起来,举个例子,我们将 User 实体的部门属性懒加载化:
public class User {
// 用户 id
private Long uid;
// 用户的部门,为了保持示例简单,这里就用普通的字符串
// 需要远程调用 通讯录系统 获得
private final Lazy<String> department;
public User(Long uid, Lazy<String> department)
{
this.uid = uid;
this.department = department;
}
public Long getUid() {
return uid;
}
public String getDepartment() {
return department.get();
}
}
// 构建 User 实体
Long uid = 1L;
User user = new User(uid, Lazy.of(() -> departmentService.getDepartment(uid)));
// 使用 User 实体,部门属性用起来和普通属性一样
user.getDepartment(); |
Lazy 框架的具体实现可以参考另一篇文章 利用惰性写出高性能且抽象的代码。
朴素的懒加载思想在依赖服务正常的情况下能够大大减少读扩散和提升性能,但是在依赖服务大规模异常时,还是会造成读扩散,进一步加大依赖服务的压力:
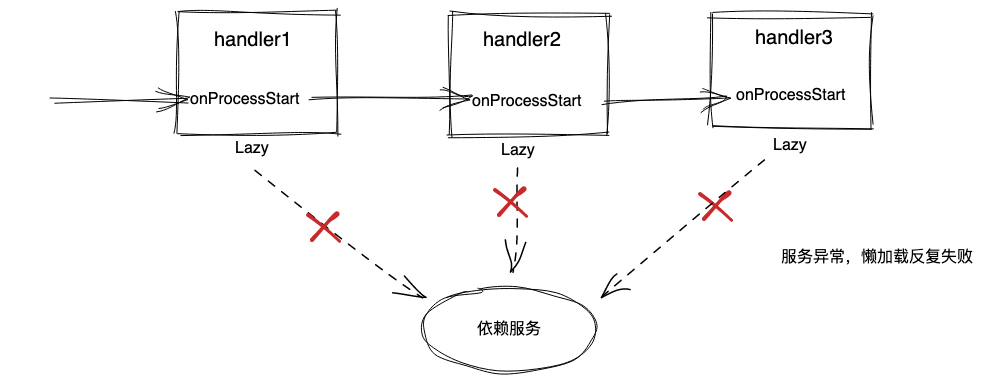
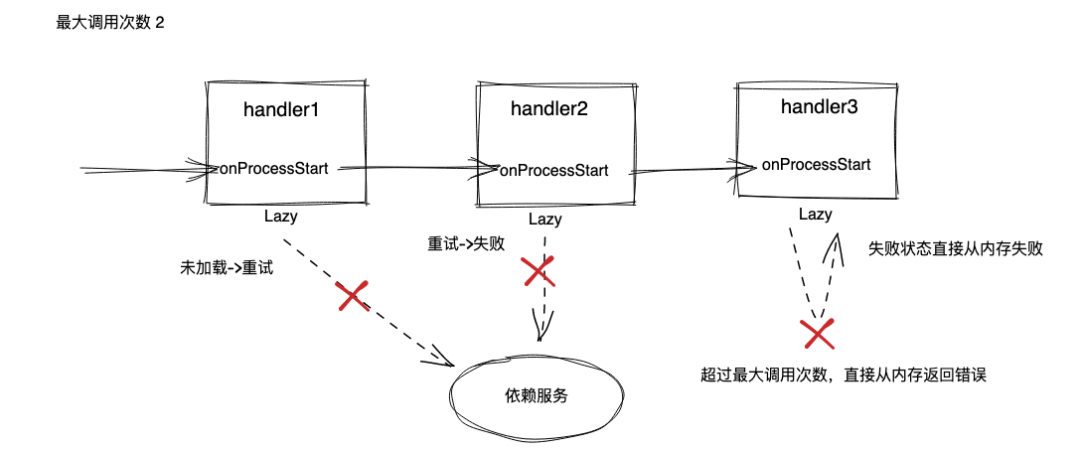
因此我们对懒加载机制进行了优化,支持设置最大调用次数。超过调用次数,直接从内存返回失败,避免在依赖服务大规模失败时还对其制造压力。
我们给 Lazy 框架添加一个状态机机制,每次 get 调用,Lazy 都会根据当前状态进行一次状态转移,在
“已加载” 状态时直接从内存返回数据,处于 “失败” 状态时,则直接从内存返回失败:
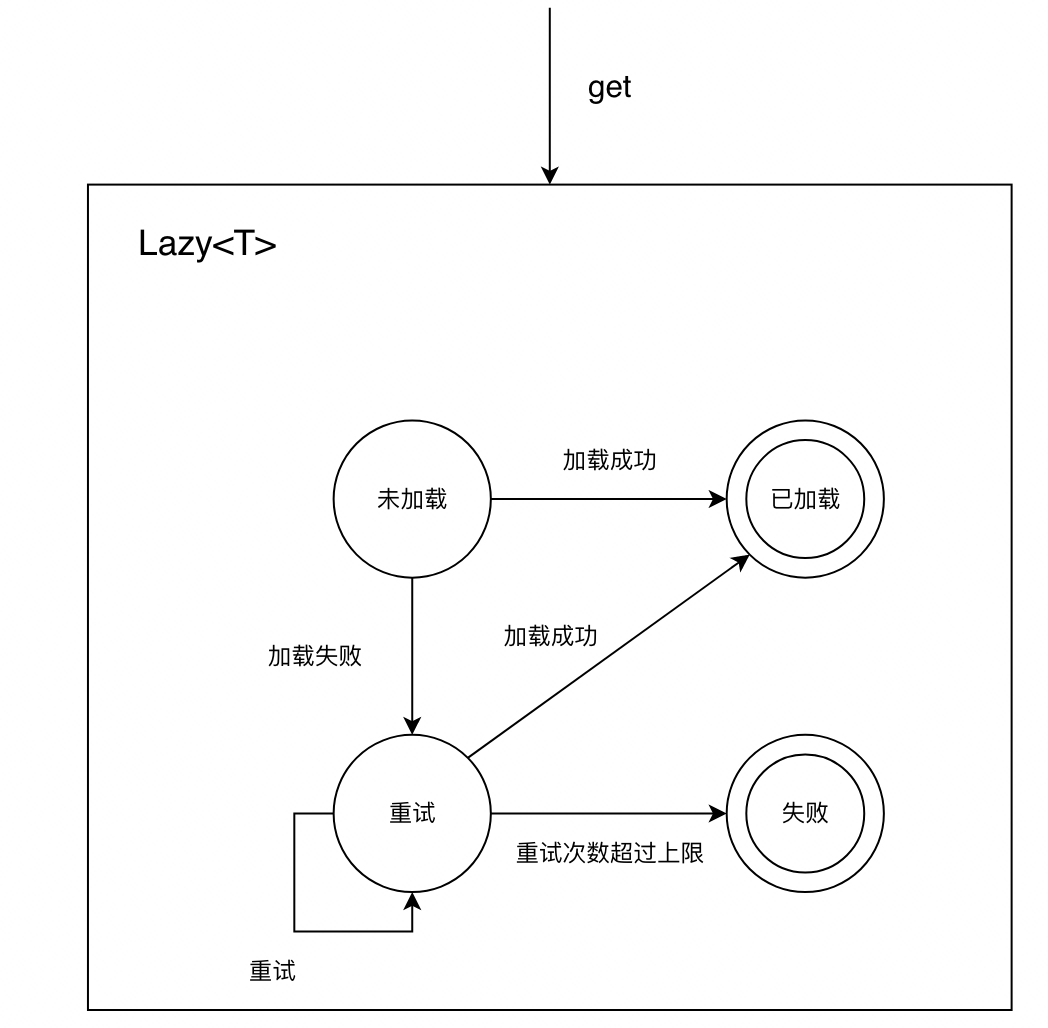
在新的机制下,如果依赖服务大规模异常,则可以避免大量的读扩散:
最后,我们可以通过一个懒加载字段计算出另一个懒加载字段,比如用户实体中,部门是懒加载的,而用户的主管又是要通过部门计算出的,产生了
用户 -> 部门 -> 主管 这样的层次加载结构,如下:
// 通过用户获得部门
Lazy<String> departmentLazy = Lazy.of(()
-> departmentService.getDepartment(uid));
// 通过部门获得主管
// department -> supervisor
Lazy<Long> supervisorLazy = departmentLazy.map(
department -> SupervisorService.getSupervisor(department)
); |
在层次加载结构中,一旦某个节点被求值,路径上所有的属性都会被缓存,因为这种对象能够自动地优化性能。以
利用惰性写出高性能且抽象的代码 这篇文章中 User 实体为例:
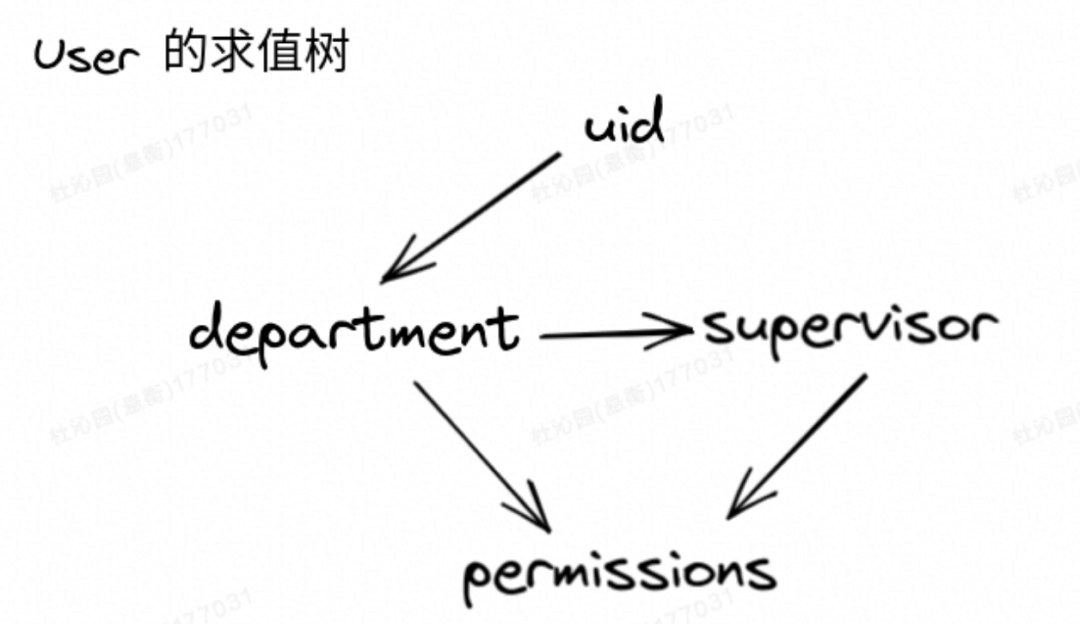
下文中我们会发现,审批的业务特点就是层次结构鲜明,因而非常适合这种设计。
基于业务的上下文设计
我们常常出于技术性能而不是业务去设计上下文中的字段,这是上下文腐化的根本原因。
什么叫 “基于技术” 设计字段?举个例子,之前审批也有类似的 上下文 + 处理器 的架构。但是因为不知道处理器中会用哪些字段,为了优化上下文的性能,在上下文中只放置了一个审批单
id,所有数据都需要在处理器中额外查询,造成了严重的读扩散。为了优化性能还容易引入幽灵字段,幽灵字段在上下文中的初始值为
null,处理器在需要时才将其设置进去。
通过字段懒加载机制,业务不再需要妥协于技术,可以将字段放在它业务上 “应该在” 的地方。字段放在实体中的原因,不是为了方便取用,也不是为优化性能,而是业务上它就应该在那里。这也是
DDD 的核心思想。
审批业务的特点就是层次鲜明,一个审批单由多个活动组成,而一个活动由多个任务组成。

根据这个特点,我们针对不同的审批事件消息设计了三种上下文:
审批单实例上下文
审批单发起消息
审批单结束消息
审批单撤销消息
...
活动上下文
活动开始消息
活动结束消息
...
任务上下文
任务开始消息
任务结束消息
任务取消消息
...
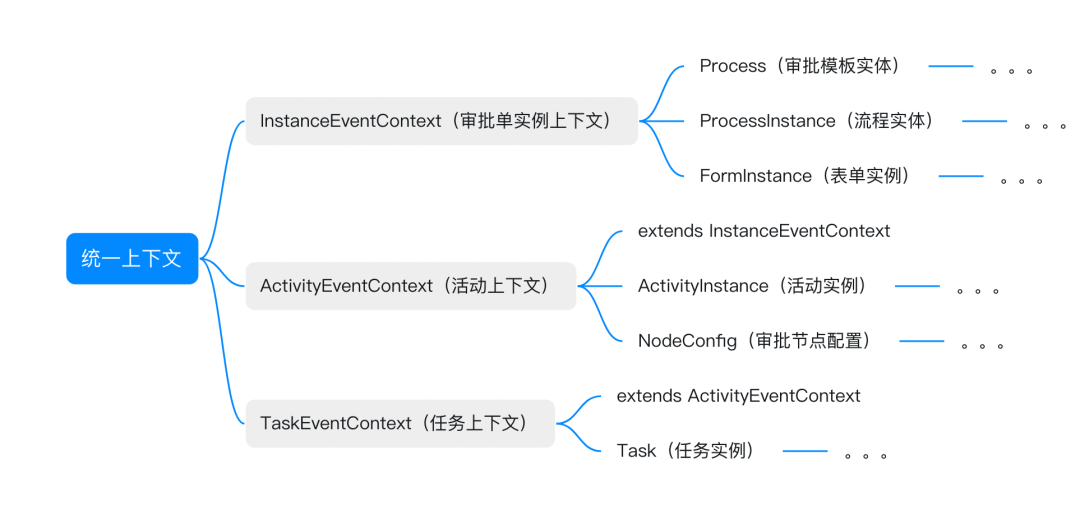
上下文全部设计成不可变的,不允许一个处理器设置字段,另一个处理器又去读取字段的情况,如果实在需要,说明这两个处理器是耦合的,那么合并成一个处理器更加合适。
至此,我们将字段都放在业务上应该在地方,开发者只要根据自己对业务的理解就可以一层层地找到字段,并且肯定能获取到,不会有的时候存在,有的时候又不存在。
如何防止雪崩
在消息链路执行这么一大串处理器,如果发生雪崩还是挺危险的。好在本方案不依赖 Metaq 自身的重试机制,直接不处理任何重复/重试的消息,就能够规避无限重试的问题。
根据踩坑的经验,Metaq 发生雪崩的主要原因在于特定场景下的无限重试:
rebalance 导致重试次数归 0;
消费者执行超时,重试次数从 3 开始继续重投;
所以我们只要不处理重复消息,也不处理重试消息,同时做好 Metaq优雅上下线,就能避免雪崩。
不处理重复消息:通过 ${msgId}_${reconsumeTimes} 设置一个 tair 分布式锁,遇到重复消息就直接返回,不进行处理。根据消息量设置过期时间长短,太长可能会占用很多的
tair 空间,但是防止雪崩的效果会更好。这个地方也可以使用布隆过滤器进行优化。
private boolean isDuplicateMessage(Message msg)
{
try {
Integer consumedCount = ltairManager
.incr("dingflow_mq_consume_" + msg.getMsgId()
+ "_" + msg.getReconsumeTimes(), 1,
30);
if (consumedCount != null && consumedCount
> 1) {
return true;
}
} catch (Throwable throwable) {
// 打印错误日志
// ...
}
return false;
} |
不处理重试消息:reconsumeTimes 大于 0 直接返回,不处理重试消息。因为我们不依赖 Metaq
层面的重试机制。
Show Me The Code: 框架编码设计
框架的整体设计遵循 代码重构:面向单元测试 中的原则,将副作用和核心逻辑完全抽离。框架的主体部分完全与消息队列无关,而是抽象出了一个通用的
RemoteRetryStore,用于持久化地存储处理器重试状态。这样我们不仅仅可以基于消息队列重试,也可以基于数据库进行重试,只要传递不同的
RemoteRetryStore 即可。框架在本地就可以模拟各种异常情况进行单元测试,文中就不大段罗列代码了。
监控与感知
有了上面的实践,监控与感知方式基本是不言自明的,只需要在框架层面 catch 异常,在有剩余重试机会时打印重试日志,无重试机会时打印失败日志。结合
Sunfire 的 Top 监控,即可看到每个处理器的失败情况。
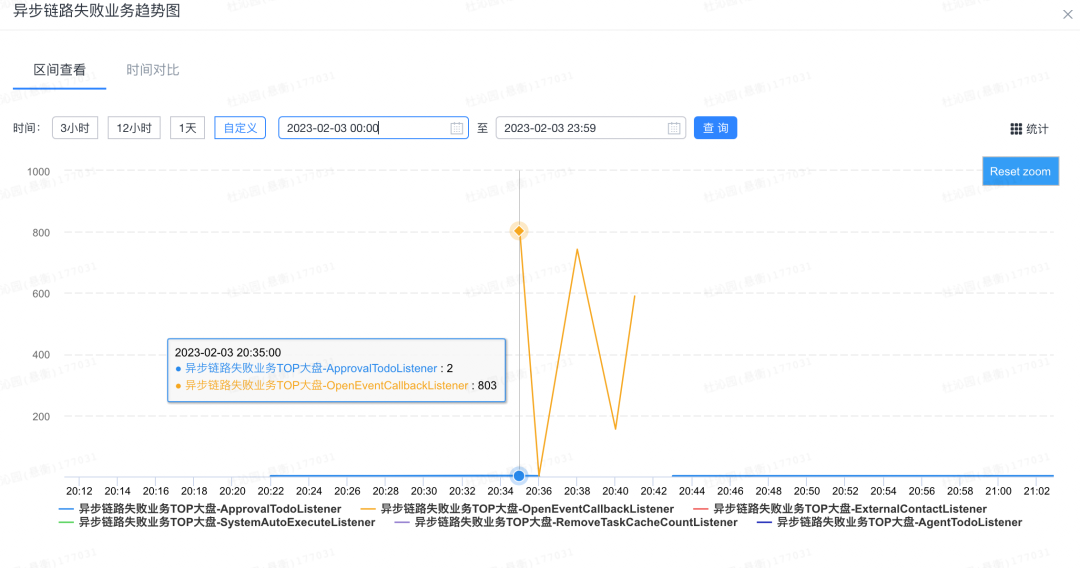
如图,OpenEventCallbackListener 处理器因为 NPE 问题,失败量突然大幅度增加。
总结
虽然这篇文章写了很多,但是总体思路非常简单,概括起来只有三点:
将消息链路拆分成多个处理器;
利用 Metaq 的 UserProperty 存储每次处理器的执行状态,精准重试失败的处理器;
用懒加载机制构建统一上下文,提升构建性能,降低读扩散,最终设计出最符合业务的上下文;
我一直坚信好的设计一定是简单而深刻的,编码过程中必然会遇到大量设计中没有的细节问题,因此只有简单的设计才能起到指导编码的作用,不然要么难以编码,要么一堆
bug; 也只有对问题的深刻理解,才能找到隐藏在背后的简洁模型。这和我另一篇 批判设计不足的文章 并不矛盾,它批判的是“只有简单”,而“没有对问题深刻理解”的设计,比如前文中的“大泥球
Consumer” ,那就是设计不足了。
|







 订阅
订阅