| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫЮЊЪВУДашвЊЪ§ОнНЈФЃЃЌЕфаЭЕФЪ§ОнВжПтНЈФЃЗНЗЈТлАќРЈЫФжжЛљБОЕФНЈФЃЗНЗЈЃЌФПЧАжїСїЕФЪЧЃКE-RФЃаЭЁЂЮЌЖШФЃаЭЁЃ
БОЮФРДздАйЖШеЫКХЃКдУЩЯаФСщЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
вЛЁЂЮЊЪВУДашвЊЪ§ОнНЈФЃЃП
дкПЊЪМНёЬьЕФЛАЬтжЎЧАЃЌЮвУЧВЛЗСЫМПМЯТЃЌЕНЕзЮЊЪВУДашвЊНјааЪ§ОнНЈФЃЃП
ЫцзХДгITЪБДњЕНDTЪБДњЕФПчдНЃЌЪ§ОнПЊЪМГіЯжБЌЗЂЪНЕФдіГЄЃЌетЕБжаВњЩњЕФМлжЕвВЪЧВЛбдЖјгїЁЃШчКЮНЋетаЉЪ§ОнНјаагаађЁЂгаНсЙЙЕиЗжРрзщжЏДцДЂЃЌЪЧЮвУЧЫљгаЪ§ОнДгвЕепЖМвЊУцСйЕФвЛИіЬєеНЁЃ
ШчЙћАбЪ§ОнПДзїЭМЪщЙнРяЕФЪщЃЌЮвУЧЯЃЭћПДЕНЫќУЧдкЪщМмЩЯЗжУХБ№РрЕиЗХжУЃЌЖјВЛЪЧТвдудуЕФЖбЦідквЛЦ№ЁЃ
ДѓЪ§ОнЕФЪ§ВжНЈФЃе§ЪЧЭЈЙ§НЈФЃЕФЗНЗЈЃЌИќКУЕФзщжЏЁЂДцДЂЪ§ОнЃЌвдБудкадФмЁЂГЩБОЁЂаЇТЪКЭЪ§ОнжЪСПжЎМфевЕНзюМбЦНКтЕуЃЌвЛАуЮвУЧЛсДгвдЯТУцЫФЕуПМТЧЃК
адФмЃКФмЙЛПьЫйВщбЏЫљашЕФЪ§ОнЃЌМѕЩйЪ§ОнI/OЕФЭЬЭТЁЃ
ГЩБОЃКМѕЩйВЛБивЊЕФЪ§ОнШпгрЃЌЪЕЯжМЦЫуНсЙћЕФИДгУЃЌНЕЕЭДѓЪ§ОнЯЕЭГжаЕФДцДЂГЩБОКЭМЦЫуГЩБОЁЃ
аЇТЪЃКИФЩЦгУЪЙгУЪ§ОнЕФЬхбщЃЌЬсИпЪЙгУаЇТЪЁЃ
жЪСПЃКИФЩЦЪ§ОнЭГМЦПкОЖЕФВЛвЛжТадЃЌМѕЩйЪ§ОнМЦЫуДэЮѓЕФПЩФмадЃЌЬсЙЉИпжЪСПЕФЁЂвЛжТЕФЪ§ОнЗУЮЪЦНЬЈЁЃ
вђДЫЃЌЮугЙжУвЩЃЌДѓЪ§ОнЯЕЭГЁЂЪ§ОнЦНЬЈЖМашвЊЪ§ОнФЃаЭЗНЗЈРДАяжњИќКУЕФзщжЏКЭДцДЂЪ§ОнЃЌЪ§ОнНЈФЃЕФЙЄзїЃЌвВе§ЪЧЮЇШЦЩЯЪіЫФИіжИБъШЁЕУзюМбЕФЦНКтЖјХЌСІЁЃ
ЖўЁЂДг OLTP КЭ OLAP ЯЕЭГЕФЧјБ№ПДФЃаЭЗНЗЈТлЕФбЁдё
OLTPЯЕЭГЭЈГЃУцЯђЕФжївЊЪ§ОнВйзїЪЧЫцЛњЖСаДЃЌжївЊВЩгУ3NFЕФЪЕЬхЙиЯЕФЃаЭДцДЂЪ§ОнЃЌДгЖјдкЪТЮёДІРэжаНтОіЪ§ОнЕФШпгрКЭвЛжТадЮЪЬтЁЃ
OLAPЯЕЭГУцЯђЕФжївЊЪ§ОнВйзїЪЧХњСПЖСаДЃЌЪТЮёДІРэжаЕФвЛжТадВЛЪЧOLAPЫљЙизЂЕФЃЌЦфжївЊЙизЂЪ§ОнЕФећКЯЃЌвдМАдквЛДЮадЕФИДдгДѓЪ§ОнВщбЏКЭДІРэЕФадФмЃЌвђДЫЫќашвЊВЩгУВЛЭЌЕФНЈФЃЗНЗЈЃЌР§ШчЮЌЖШНЈФЃЁЃ
ШчЙћДѓМвЯыНјвЛВНСЫНт OLAPЯЕЭГЃЌПЩвдбЇЯАетЦЊЮФеТЃКЙигкOLAPЪ§ВжЃЌетДѓИХЪЧЪЗЩЯзюШЋУцЕФзмНсЃЁ
Ш§ЁЂЕфаЭЕФЪ§ОнВжПтНЈФЃЗНЗЈТл
Ъ§ОнВжПтБОжЪЪЧДгЪ§ОнПтбмЩњГіРДЕФЃЌЫљвдЪ§ОнВжПтЕФНЈФЃвВЪЧВЛЖЯбмЩњЗЂеЙЕФЁЃ
ДгзюдчЕФНшМјЙиЯЕаЭЪ§ОнПтРэТлЕФЗЖЪННЈФЃЃЌЕНж№НЅЬсГіЮЌЖШНЈФЃЕШЕШЃЌдНЭљКѓНЈФЃЕФвЊЧѓдНИпЃЌдНашТњзу3NFЁЂ4NFЕШЁЃЕЋЪЧЖдгкЪ§ОнВжПтРДЫЕЃЌФПЧАжїСїЛЙЪЧЮЌЖШНЈФЃЃЌЛсМадгзХЗЖЪННЈФЃЁЃ
Ъ§ОнВжПтНЈФЃЗНЗЈТлПЩЗжЮЊЃКE-RФЃаЭЁЂЮЌЖШФЃаЭЁЂData VaultФЃаЭЁЂAnchorФЃаЭЁЃ
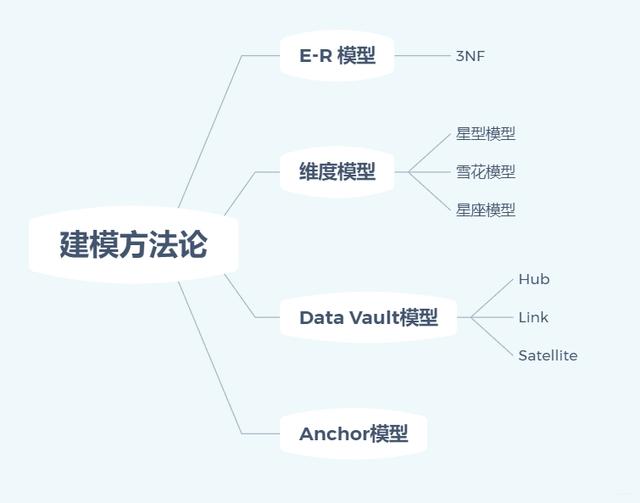
3.1 E-RФЃаЭ
НЋЪТЮяГщЯѓЮЊЁАЪЕЬхЁБЁЂЁАЪєадЁБЁЂЁАЙиЯЕЁБРДБэЪОЪ§ОнЙиСЊКЭЪТЮяУшЪіЃЌетжжЖдЪ§ОнЕФГщЯѓНЈФЃЭЈГЃБЛГЦЮЊE-RЪЕЬхЙиЯЕФЃаЭЁЃ
Ъ§ОнВжПтжЎИИ Bill Inmon ЬсГіЕФНЈФЃЗНЗЈЃЌДгШЋЦѓвЕЕФИпЖШЩшМЦвЛИі3NFФЃаЭЃЌгУЪЕЬхЙиЯЕЃЈEntity
RelationshipЃЉФЃаЭРДУшЪіЦѓвЕвЕЮёЃЌТњзу3NFЁЃ
Ъ§ОнВжПтЕФ3NFгыOLTPЯЕЭГжаЕФ3NFЕФЧјБ№дкгкЃЌЫќЪЧеОдкЦѓвЕНЧЖШУцЯђжїЬтЕФГщЯѓЃЌЖјВЛЪЧеыЖдФГИіОпЬхЕФвЕЮёСїГЬЁЃ
ВЩгУ E-RФЃаЭНЈЩшЪ§ОнВжПтФЃаЭЕФГіЗЂЕуЪЧећКЯЪ§ОнЃЌЖдИїИіЯЕЭГЕФЪ§ОнвдећИіЦѓвЕНЧЖШАДжїЬтНјааЯрЫЦЕФзщКЯКЭКЯВЂЃЌВЂНјаавЛжТадДІРэЃЌЮЊЪ§ОнЗжЮіОіВпЗўЮёЃЌЕЋЪЧВЂВЛФмжБНггУгкЗжЮіОіВпЁЃ
зїЮЊвЛжжБъзМЕФЪ§ОнНЈФЃЗНАИЃЌЫќЕФЪЕЪЉжмЦкЗЧГЃГЄЃЌвЛжТадКЭРЉеЙадБШНЯКУЃЌФмОЕУЦ№ЪБМфЕФПМбщЁЃЕЋЪЧЫцзХЦѓвЕЪ§ОнЕФИпЫйдіГЄЁЂИДдгЛЏЃЌЪ§ВжШчЙћШЋВПЪЙгУE-RФЃаЭНјааНЈФЃОЭЯдЕУдНРДдНВЛЪЪКЯЯжДњЛЏИДдгЁЂЖрБфЕФвЕЮёзщжЏЃЌвђДЫвЛАужЛгадкЪ§ВжЕзВуODSЁЂDWDЛсВЩгУE-RЙиЯЕФЃаЭНјааЩшМЦЁЃ
E-RНЈФЃВНжшЗжЮЊШ§ИіНзЖЮЃК
ИпВуФЃаЭЃКвЛИіИпЖШГщЯѓЕФФЃаЭЃЌУшЪіжївЊЕФжїЬтвдМАжїЬтМфЕФЙиЯЕЃЌгУгкУшЪіЦѓвЕЕФвЕЮёзмЬхИХПіЁЃ
жаВуФЃаЭЃКдкИпВуФЃаЭЕФЛљДЁЩЯЃЌЯИЛЏжїЬтЕФЪ§ОнЯюЁЃ
ЮяРэФЃаЭЃЈЕзВуФЃаЭЃЉЃКдкжаВуФЃаЭЕФЛљДЁЩЯЃЌПМТЧЮяРэДцДЂЃЌЭЌЪБЛљгкадФмКЭЦНЬЈЬиЕуНјааЮяРэЪєадЕФЩшМЦЃЌвВПЩФмзівЛаЉБэЕФКЯВЂЁЂЗжЧјЕФЩшМЦЕШЁЃ
E-RФЃаЭдкЪЕМљжазюЕфаЭЕФДњБэЪЧ Teradata ЙЋЫОЛљгкН№ШквЕЮёЗЂВМЕФ FS-LDM (Financial
Services Logical Data Model ЃЉЃЌЫќЭЈЙ§ЖдН№ШквЕЮёЕФИпЖШГщЯѓКЭзмНсЃЌНЋН№ШквЕЮёЛЎЗжЮЊ10ДѓжїЬтЃЌЦѓвЕЛљгкДЫФЃаЭЪЪЕБЕїећКЭРЉеЙОЭФмПьЫйЪЕЪЉТфЕиЁЃ
3.2 ЮЌЖШФЃаЭ
ЮЌЖШФЃаЭЪЧЪ§ОнВжПтСьгђ Ralph Kimball ДѓЪІГЋЕМЕФЃЌЪЧЪ§ОнВжПтЙЄГЬСьгђзюСїааЕФЪ§ВжНЈФЃОЕфЁЃ
ЮЌЖШНЈФЃвдЗжЮіОіВпЕФашЧѓГіЗЂЙЙНЈФЃаЭЃЌЙЙНЈЕФЪ§ОнФЃаЭЮЊЗжЮіашЧѓЗўЮёЃЌвђДЫЫќжиЕуНтОігУЛЇШчКЮИќПьЫйЭъГЩЗжЮіашЧѓЃЌЭЌЪБЛЙгаНЯКУЕФДѓЙцФЃИДдгВщбЏЕФЯьгІадФмЁЃ
ЦфжаЕфаЭЕФДњБэОЭЪЧЪЙгУаЧаЭФЃаЭЃЌвдМАдквЛаЉЬиЪтГЁОАЯТЪЙгУЕФбЉЛЈФЃаЭЁЃ
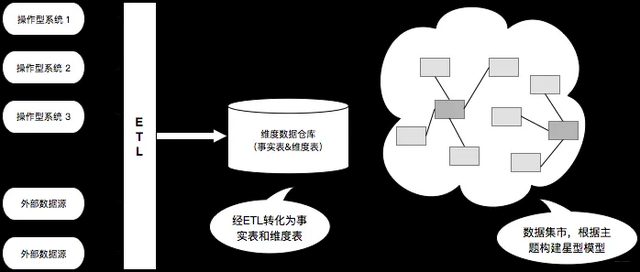
ЦфЩшМЦжївЊЗжЮЊвдЯТМИИіВНжшЃК
бЁдёашвЊНјааЗжЮіОіВпЕФвЕЮёЙ§ГЬЁЃвЕЮёЙ§ГЬПЩвдЪЧЕЅИівЕЮёЪТМўЃЌБШШчНЛвзЕФжЇИЖЁЂЭЫПюЕШЃЛвВПЩвдЪЧФГИіЪТМўЕФзДЬЌЃЌБШШчЕБЧАеЫЛЇЕФгрЖюЃЛЛЙгаОЭЪЧвЛЯЕСаЯрЙивЕЮёЪТМўзщГЩЕФвЕЮёСїГЬЃЌОпЬхашвЊЮвУЧЗжЮіЕФЪЧФГаЉЪТМўЗЂЩњЕФЧщПіЃЌЛЙЪЧЕБЧАзДЬЌЃЌЛђЪЧЪТМўСїзЊаЇТЪЁЃ
бЁдёСЃЖШЁЃдкЪТМўЗжЮіжаЃЌЮвУЧвЊдЄХаЫљгаЗжЮіашвЊЯИЗжЕФГЬЖШЃЌДгЖјОіЖЈбЁдёЕФСЃЖШЁЃСЃЖШЪЧЮЌЖШЕФвЛИізщКЯЁЃ
ЪЖБ№ЮЌБэЁЃбЁдёКУСЃЖШжЎКѓЃЌОЭашвЊЛљгкетИіСЃЖШРДЩшМЦЮЌБэЃЌАќРЈЮЌЖШЪєадЃЌгУгкЗжЮіЪБНјааЗжзщКЭЩИбЁЁЃ
бЁдёЪТЪЕЁЃШЗЖЈЗжЮіашвЊКтСПЕФжИБъЁЃ
дк Ralph Kimball ЬсГіЖдЪ§ОнВжПтЮЌЖШНЈФЃЃЌЮвУЧНЋЪ§ОнВжПтжаЕФБэЛЎЗжЮЊЪТЪЕБэЁЂЮЌЖШБэСНжжРраЭЁЃ
еыЖдЮЌЖШНЈФЃжаЪТЪЕБэКЭЮЌЖШБэЕФЩшМЦЃЌжЎЧАгаЯъЯИНщЩмЙ§ЃЌИааЫШЄЕФЭЌбЇПЩвдПДЃКЮЌЖШНЈФЃММЪѕЪЕМљЁЊЁЊЩюШыЪТЪЕБэ
ЁЂЮЌЖШНЈФЃЕФСщЛъЫљдкЁЊЁЊЮЌЖШБэЩшМЦЁЃ
дкетРяЃЌЮвОЭвдГЃМћЕФЕчЩЬГЁОАЮЊР§ЃКдквЛДЮЙКТђЕФЪТМўжаЃЌЩцМАжїЬхАќРЈПЭЛЇЁЂЩЬЦЗЁЂЩЬМвЃЌВњЩњЕФПЩЖШСПжЕЛсАќРЈЩЬЦЗЪ§СПЁЂН№ЖюЁЂМўЪ§ЕШЁЃ
ЪТЪЕБэИљОнСЃЖШЕФНЧЩЋЛЎЗжВЛЭЌЃЌПЩЗжЮЊЪТЮёЪТЪЕБэЁЂжмЦкПьееЪТЪЕБэЁЂРлЛ§ПьееЪТЪЕБэЕШЁЃ
ЪТЮёЪТЪЕБэЃКгУгкГадиЪТЮёЪ§ОнЃЌШЮКЮРраЭЕФЪТМўЖМПЩвдБЛРэНтЮЊвЛжжЪТЮёЃЌБШШчЩЬМвдкНЛвзЙ§ГЬжаЕФГЃМћЖЉЕЅЁЂТђМвИЖПюЃЌЮяСїЙ§ГЬжаЕФРПЛѕЁЂЗЂЛѕЁЂЧЉЪеЃЌЭЫПюжаЕФЩъЧыЭЫПюЁЃ
жмЦкПьееЪТЪЕБэЃКПьееЪТЪЕБэвддЄЖЈЕФМфИєВЩбљзДЬЌЖШСПЃЌБШШчздШЛФъжСНёЛђепРњЪЗжСНёЕФЯТЕЅН№ЖюЁЂжЇИЖН№ЖюЁЂжЇИЖТђМвЪ§ЁЂжЇИЖЩЬЦЗМўЪ§ЕШЕШзДЬЌЖШСПЁЃ
РлМЦПьееЪТЪЕБэЃКЪ§ОнВЛЖЯИќаТЃЌбЁШЁЖрвЕЮёЙ§ГЬШеЦкЁЃгУРДМЧТМОпгаЪБМфПчЖШЕФвЕЮёДІРэЙ§ГЬЕФећИіЙ§ГЬЕФаХЯЂЃЌУПИіЩњУќжмЦквЛааЃЌЭЈГЃетРрЪТЪЕБэБШНЯЩйМћЁЃ
ЮвУЧМЬајОЭЩЯЪіЕФЕчЩЬГЁОАЃЌСФСФдкЮЌБэЩшМЦЪБашвЊЙизЂЕФвЛаЉЖЋЮїЃК
ЛКТ§БфЛЏЮЌЖШЃКР§ШчЛсдББэЕФЪжЛњКХЁЂЕижЗЁЂЩњШеЕШЪєадЁЃ
ЭЫЛЏЮЌЖШ ЃКЖЉЛѕЕЅБэЕФЖЉЕЅБрКХЁЂЮяСїБэЕФЮяСїБрКХЕШЁЃ
бЉЛЈЮЌЖШЃКТњзуЕкШ§ЗЖЪНЕФЮЌЖШЙиЯЕНсЙЙЁЃ
ЗЧЙцЗЖЛЏБтЦНЮЌЖШЃКЩЬЦЗЮЌБэжаВњЦЗЁЂЦЗХЦЁЂРрФПЁЂЦЗРрЕШЁЃ
ЖрВуДЮЮЌЖШЃКЕиЧјЮЌЖШЕФЪЁЁЂЪаЁЂЧјЯиЃЌЩЬЦЗЕФРрФПВуМЖЁЃ
НЧЩЋЮЌЖШЃКШеЦкЮЌЖШдкЮяСїжаАчбнЗЂЛѕШеЦкЁЂЫЭЛѕШеЦкЁЂЪеЛёШеЦкЕШВЛЭЌНЧЩЋЁЃ
НгЯТРДОЭЪЧеыЖдЮЌЖШНЈФЃАДееЪ§ОнЕФзщжЏРраЭЃЌПЩвдЛЎЗжЮЊаЧаЭФЃаЭЁЂбЉЛЈФЃаЭЁЂаЧзљФЃаЭЁЃ
аЧаЭФЃаЭЃКаЧаЭФЃаЭжївЊЪЧЮЌБэКЭЪТЪЕБэЃЌвдЪТЪЕБэЮЊжааФЃЌЫљгаЮЌЖШжБНгЙиСЊдкЪТЪЕБэЩЯЃЌГЪаЧаЭЗжВМЁЃ
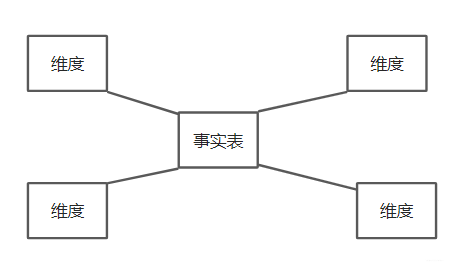
бЉЛЈФЃаЭЃКдкаЧаЭФЃаЭЕФЛљДЁЩЯЃЌЮЌЖШБэЩЯгжЙиСЊСЫЦфЫћЮЌЖШБэЁЃетжжФЃаЭЮЌЛЄГЩБОИпЃЌадФмЗНУцЛсВювЛаЉЁЃ
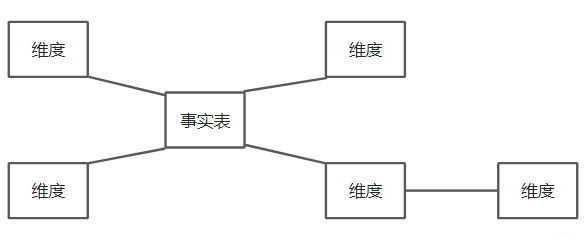
аЧзљФЃаЭЃКЪЧЖдаЧаЭФЃаЭЕФРЉеЙбгЩьЃЌЖреХЪТЪЕБэЙВЯэЮЌЖШБэЁЃЪЕМЪЩЯЪ§ВжФЃаЭНЈЩшКѓЦкЃЌДѓВПЗжЮЌЖШНЈФЃЖМЪЧаЧзљФЃаЭЁЃ
МђЕЅзмНсЯТОЭЪЧЃК
аЧаЭФЃаЭКЭбЉЛЈФЃаЭжївЊЧјБ№ОЭЪЧЖдЮЌЖШБэЕФВ№ЗжЁЃ
ЖдгкбЉЛЈФЃаЭЃЌЮЌЖШБэЕФЩшМЦИќМгЙцЗЖЃЌвЛАуЗћКЯ3NFЃЌгааЇНЕЕЭЪ§ОнШпгрЃЌЮЌЖШБэжЎМфВЛЛсЯрЛЅЙиСЊЁЃ
аЧаЭФЃаЭЃЌвЛАуВЩгУНЕЮЌЕФВйзїЃЌЗДЙцЗЖЛЏЃЌВЛЗћКЯ3NFЃЌЭЈЙ§РћгУШпгрРДБмУтФЃаЭЙ§гкИДдгЃЌЬсИпвзгУадКЭЗжЮіаЇТЪЃЌаЇТЪЯрЖдНЯИпЁЃ
3.3 DataVault ФЃаЭ
Data Vault ЪЧ Dan Linstedt ЗЂЦ№ДДНЈЕФвЛжжФЃаЭЃЌЫќЪЧ E-R ФЃаЭЕФбмЩњЃЌЦфЩшМЦЕФГіЗЂЕувВЪЧЮЊСЫЪЕЯжЪ§ОнЕФећКЯЃЌЕЋВЛФмжБНггУгкЪ§ОнЗжЮіОіВпЁЃ
ЫќЧПЕїНЈСЂвЛИіПЩЩѓМЦЕФЛљДЁЪ§ОнВуЃЌвВОЭЪЧЧПЕїЪ§ОнЕФРњЪЗадЁЂПЩзЗЫнадКЭдзгадЃЌЖјВЛвЊЧѓЖдЪ§ОнНјааЙ§ЖШЕФвЛжТадДІРэКЭећКЯЁЃ
ЭЌЪБЫќЛљгкжїЬтИХФюНЋЦѓвЕЪ§ОнНјааНсЙЙЛЏзщжЏЃЌВЂв§ШыСЫИќНјвЛВНЕФЗЖЪНДІРэРДгХЛЏФЃаЭЃЌвдгІЖддДЯЕЭГБфИќЕФРЉеЙадЁЃData
Vault ФЃаЭгЩвдЯТМИВПЗжзщГЩЃК
Hub - жааФБэЃКЪЧЦѓвЕЕФКЫаФвЕЮёЪЕЬхЃЌгЩЪЕЬх KeyЁЂЪ§ВжађСаДњРэМќЁЂзАдиЪБМфЁЂЪ§ОнРДдДзщГЩЃЌВЛАќКЌЗЧМќжЕвдЭтЕФвЕЮёЪ§ОнЪєадБОЩэЁЃ
Link - СДНгБэЃКДњБэ Hub жЎМфЕФЙиЯЕЁЃетРягы ER ФЃаЭзюДѓЕФЧјБ№ЪЧНЋЙиЯЕзїЮЊвЛИіЖРСЂЕФЕЅдЊГщЯѓЃЌПЩвдЬсЩ§ФЃаЭЕФРЉеЙадЁЃЫќПЩвджБНгУшЪі
1:1ЁЂ1:2КЭn:nЕФЙиЯЕЃЌЖјВЛашвЊзіШЮКЮБфИќЁЃЫќгЩ HubЕФДњРэМќЁЂзАдиЪБМфЁЂЪ§ОнРДдДзщГЩЁЃ
Satellite - ЮРаЧБэЃКЪ§ВжжаЪ§ОнЕФжївЊдиЬхЃЌАќРЈЖдСДНгБэЁЂжааФБэЕФЪ§ОнУшЪіЁЂЪ§жЕЖШСПЕШаХЯЂЁЃ
Data Vault ФЃаЭБШ E-R ФЃаЭИќШнвзЩшМЦКЭВњГіЃЌЫќЕФ ETL МгЙЄПЩЪЕЯжХфжУЛЏЁЃЮвУЧПЩвдНЋ
Hub ЯыЯѓГЩШЫЕФЙЧМмЃЌФЧУД Link ОЭЪЧСЌНгЙЧМмЕФШЭДјЃЌЖј SateIIite ОЭЪЧЙЧМмЩЯУцЕФбЊШтЁЃ
3.4 Anchor ФЃаЭ
Anchor Жд Data Vault ФЃаЭзіСЫНјвЛВНЕФЙцЗЖЛЏДІРэЃЌЫќЕФКЫаФЫМЯыЪЧЫљгаЕФРЉеЙжЛЪЧЬэМгЖјВЛЪЧаоИФЃЌвђДЫНЋФЃаЭЙцЗЖЕН6NFЃЌЛљБОБфГЩСЫ
k-v НсЙЙЛЏФЃаЭЁЃ
Anchors ЃКРрЫЦгк Data Vault ЕФ Hub ЃЌДњБэвЕЮёЪЕЬхЃЌЧвжЛгажїМќЁЃ
Attributes ЃКЙІФмРрЫЦгк Data Vault ЕФ SatelliteЃЌЕЋЪЧЫќИќМгЙцЗЖЛЏЃЌНЋЦфШЋВП
k-v НсЙЙЛЏЃЌ вЛИіБэжЛгавЛИі Anchors ЕФЪєадУшЪіЁЃ
Ties ЃКОЭЪЧ Anchors жЎМфЕФЙиЯЕЃЌЕЅЖРгУБэРДУшЪіЃЌРрЫЦгк Data Vault ЕФ Link
ЃЌПЩвдЬсЩ§ећЬхФЃаЭЙиЯЕЕФРЉеЙФмСІЁЃ
Knots ЃКДњБэФЧаЉПЩФмЛсдк Anchors жаЙЋгУЕФЪєадЕФЬсСЖЃЌБШШчадБ№ЁЂзДЬЌЕШетжжУЖОйРраЭЧвБЛЙЋгУЕФЪєадЁЃ
гЩгкЙ§ЖШЙцЗЖЛЏЃЌЪЙгУжаЧЃЩцЕНЬЋЖрЕФJoinВйзїЃЌетРяЮвУЧОЭНізїСЫНтЁЃ
ЫФЁЂзмНс
еыЖдвдЩЯЫФжжЛљБОЕФНЈФЃЗНЗЈЃЌФПЧАжїСїЕФЪЧЃКE-RФЃаЭЁЂЮЌЖШФЃаЭЁЃ
E-RФЃаЭЭЈГЃгУгкOLTPЪ§ОнПтНЈФЃЃЌгІгУЕНЙЙНЈЪ§ВжЪБОЭИќЦЋЯђгкЪ§ОнећКЯЃЌеОдкЦѓвЕећЬхПМТЧЃЌНЋИїИіЯЕЭГЕФЪ§ОнАДЯрЫЦадвЛжТадЁЂКЯВЂДІРэЃЌЮЊЪ§ОнЗжЮіЁЂОіВпЗўЮёЃЌЕЋВЂВЛБугкжБНггУРДжЇГжЗжЮіЁЃ
ЮЌЖШНЈФЃЪЧУцЯђЗжЮіГЁОАЖјЩњЃЌеыЖдЗжЮіГЁОАЙЙНЈЪ§ВжФЃаЭЃЛжиЕуЙизЂПьЫйЁЂСщЛюЕФНтОіЗжЮіашЧѓЃЌЭЌЪБФмЙЛЬсЙЉДѓЙцФЃЪ§ОнЕФПьЫйЯьгІадФмЁЃеыЖдадЧПЃЌжївЊгІгУгкЪ§ОнВжПтЙЙНЈКЭOLAPв§ЧцЕЭВуЪ§ОнФЃаЭЁЃ
Ъ§ОнВжПтФЃаЭЕФЩшМЦЪЧСщЛюЕФЃЌВЛЛсОжЯогкФГвЛжжФЃаЭЃЌашвЊвдЪЕМЪЕФашЧѓГЁОАЮЊЕМЯђЃЌашвЊМцЙЫСщЛюадЁЂПЩРЉеЙадвдМАММЪѕПЩППадМАЪЕЯжГЩБОЁЃ |









