| Īŗľ≠Õ∆ľŲ: |
Īĺőń÷ų“™Ĺť…‹ żĺ›≤÷Ņ‚≤ķ∆∑◊ųő™∆ů“Ķ÷– żĺ›īśīĘļÕĻ‹ņŪĶńĽýī°…Ť ©£¨‘ŕÕ®Ļż∑÷≤„īśīĘľľ űņīĹĶĶÕ∆ů“ĶīśīĘ≥…Īĺ ĪĶńĻōľŁő Ő‚ļÕļň–ńľľ űĶ»ŌŗĻōńŕ»›°£
Īĺőńņī◊‘ įĘņÔľľ ű£¨”…ĽūŃķĻŻ»ŪľĢAliceĪŗľ≠°ĘÕ∆ľŲ°£ |
|
“Ľ Ī≥ĺį
ĺ›IDC∑Ę≤ľĶń°∂ żĺ› Īīķ2025°∑Ī®łśŌ‘ ĺ£¨»ę«Ú√ŅńÍ≤ķ…ķĶń żĺ›Ĺęī”2018ńÍĶń33ZB‘Ų≥§ĶĹ2025ńÍĶń175ZB£¨∆Ĺĺý√ŅŐž‘ľ≤ķ…ķ491EB żĺ›°£ňś◊Ň żĺ›ŃŅĶń≤Ľ∂Ō‘Ų≥§£¨ żĺ›īśīĘ≥…Īĺ≥…ő™∆ů“ĶIT‘§ň„Ķń÷ō“™◊ť≥…≤Ņ∑÷°£ņż»Á1PB żĺ›īśīĘ“ĽńÍ£¨»ę≤Ņ∑Ň‘ŕłŖ–‘ń‹īśīĘĹť÷ ļÕ»ę≤Ņ∑Ň‘ŕĶÕ≥…ĪĺīśīĘĹť÷ ŃĹ’Ŗ≥…Īĺ≤Óĺŗ‘ŕ“ĽłŲŃŅľ∂“‘…Ō°£”…”ŕĻōľŁ“ĶőŮ–ŤłŖ–‘ń‹∑√ő £¨“Úīň≤Ľń‹ľÚĶ•Ķńį—ňý”– żĺ›īś∑Ň‘ŕĶÕňŔ…ŤĪł£¨∆ů“Ķ–Ťłýĺ› żĺ›Ķń∑√ő ∆Ķ∂»£¨ Ļ”√≤ĽÕ¨÷÷ņŗĶńīśīĘĹť÷ ĽŮĶ√◊Ó–°ĽĮ≥…ĪĺļÕ◊ÓīůĽĮ–߬ °£“Úīň£¨į— żĺ›īśīĘ‘ŕ≤ĽÕ¨≤„ľ∂£¨≤Ęń‹ĻĽ◊‘∂Į‘ŕ≤„ľ∂ľš«®“∆ żĺ›Ķń∑÷≤„īśīĘľľ ű≥…ő™∆ů“Ķļ£ŃŅ żĺ›īśīĘĶń ◊—°°£
ĪĺőńĹť…‹ żĺ›≤÷Ņ‚≤ķ∆∑◊ųő™∆ů“Ķ÷– żĺ›īśīĘļÕĻ‹ņŪĶńĽýī°…Ť ©£¨‘ŕÕ®Ļż∑÷≤„īśīĘľľ űņīĹĶĶÕ∆ů“ĶīśīĘ≥…Īĺ ĪĶńĻōľŁő Ő‚ļÕļň–ńľľ ű°£
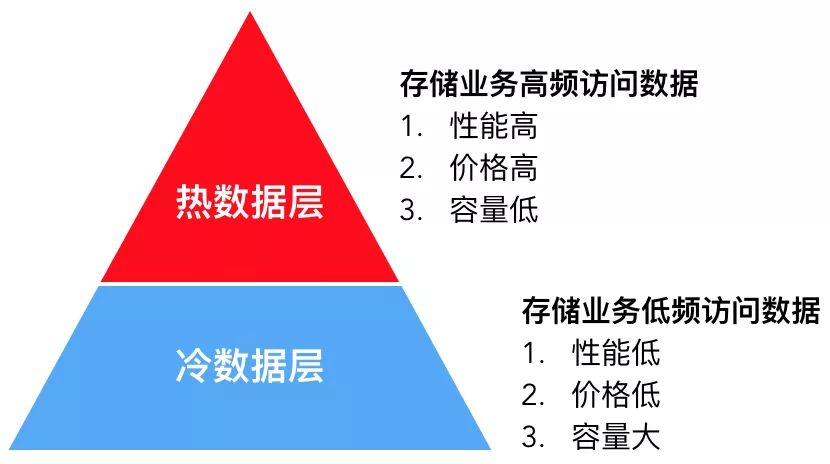
1 ≤√ī «∑÷≤„īśīĘ
∑÷≤„īśīĘĻň√Żňľ“Ś£¨ĺÕ «į— żĺ›∑÷ő™łŖ∆Ķ∑√ő Ķń»» żĺ›ļÕĶÕ∆Ķ∑√ő Ķńņš żĺ›£¨≤Ę∑÷ĪūīśīĘ‘ŕ»» żĺ›≤„ļÕņš żĺ›≤„£¨īÔĶĹ–‘ń‹”Ž≥…ĪĺĶń∆Ĺļ‚°£
»» żĺ›≤„≤…”√łŖ–‘ń‹īśīĘĹť÷ £¨Ķ•őĽ≥…ĪĺłŖ£¨ő™Ņō÷∆‘§ň„“Ľį„»›ŃŅĹŌ–°£¨÷ĽīśīĘĻōľŁ“ĶőŮ żĺ›£¨ņż»ÁERP£¨CRM żĺ›£¨ĽÚ’Ŗ◊Ó–¬Ķń∂©Ķ• żĺ›Ķ»°£
ņš żĺ›≤„‘ÚīśīĘ∑«ĻōľŁ“ĶőŮ żĺ›£¨ņż»Á…ůľ∆»’÷ĺ£¨‘ň––»’÷ĺĶ»£¨ĽÚņķ ∑≥ŃĶŪ żĺ›£¨ņż»Á“ĽłŲ‘¬«įĶń∂©Ķ• żĺ›°£īň≤Ņ∑÷ żĺ›ŐŚŃŅīů£¨∑√ő ∆Ķ∂»ĶÕ£¨–‘ń‹“™«ů≤ĽłŖ£¨“Úīň≤…”√Ķ•őĽ≥…ĪĺĶÕ£¨»›ŃŅīůĶńīśīĘĹť÷ ņīĹĶĶÕ≥…Īĺ°£Õ¨ Ī£¨ňś◊Ň ĪľšŃų Ň£¨≤Ņ∑÷»» żĺ›∑√ő ∆Ķ∂»ĽŠĹĶĶÕ£®“Ľį„≥∆ő™ żĺ›ĹĶő¬£©£¨īň ĪīśīĘŌĶÕ≥ń‹ĻĽ◊‘∂Į«®“∆ł√≤Ņ∑÷ żĺ›ĶĹņš żĺ›≤„ņīĹĶĶÕ≥…Īĺ°£
2 żĺ›≤÷Ņ‚∑÷≤„īśīĘ√śŃŔĶńŐŰ’Ĺ
żĺ›≤÷Ņ‚≤ķ∆∑‘ŕ ĶŌ÷∑÷≤„īśīĘń‹Ń¶ Ī£¨√śŃŔĶńľłłŲļň–ńŐŰ’Ĺ»ÁŌ¬£ļ
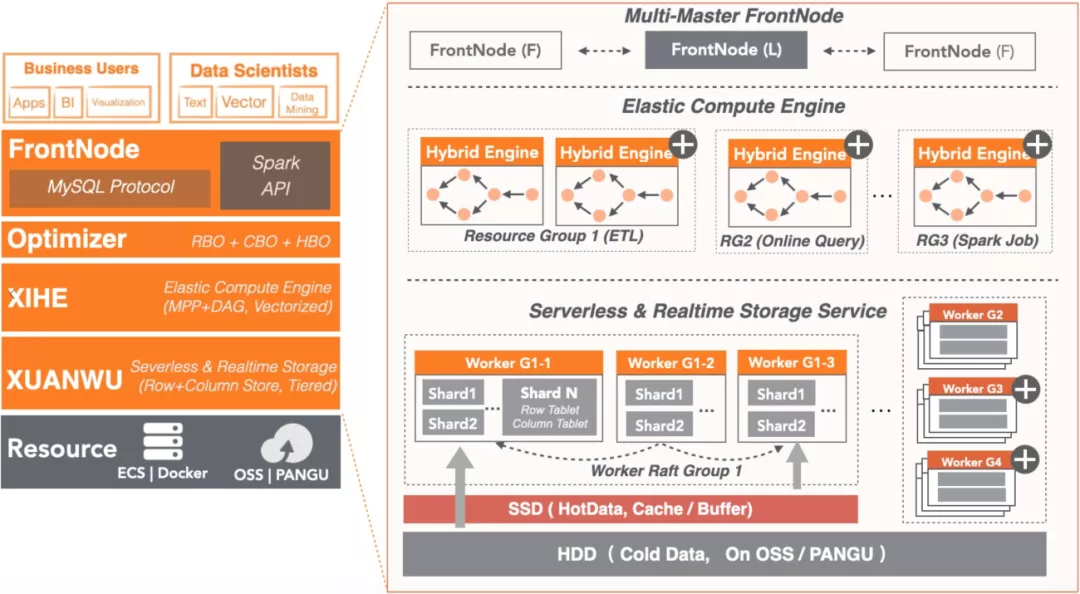
°§—°‘ŮļŌ ĶńīśīĘĹť÷ °£īśīĘĹť÷ ľ»“™¬ķ◊„–‘ń‹°Ę≥…Īĺ–Ť«ů£¨ĽĻ“™¬ķ◊„Ņ…ŅŅ–‘°ĘŅ…”√–‘°Ę»›ŃŅŅ…ņ©’Ļ°Ę‘ňő¨ľÚĶ•Ķ»–Ť«ů°£
°§“ĶőŮ…ŌĶńņš»» żĺ›£¨»Áļő‘ŕ∑÷≤„īśīĘ÷–∂®“Ś£Ņľī»Áļő√Ť Ųńń≤Ņ∑÷ «»» żĺ›£¨ńń≤Ņ∑÷ «ņš żĺ›°£
°§ņš»» żĺ›»Áļő«®“∆£Ņňś◊Ň ĪľšŃų Ň£¨“ĶőŮ…ŌĶń»» żĺ›ĹĶő¬ő™ņš żĺ›ļů£¨ żĺ›≤÷Ņ‚»Áļőł–÷™ő¬∂»ĶńĪšĽĮ≤Ę÷ī–– żĺ›«®“∆ņīĹĶĶÕīśīĘ≥…Īĺ°£
°§»Áļőľ”ňŔņš żĺ›Ķń∑√ő £Ņņš żĺ›»‘»ĽĽŠĪĽ∑√ő £¨Ī»»Á“Ú∑®Ļś’Ģ≤Ŗ“™«ů£¨”√Ľß–Ť∂‘»żłŲ‘¬«į żĺ›ĹÝ–––ř∂©£¨ĽÚ’Ŗ–Ť“™∂‘Ļż»•“ĽńÍĶń żĺ›ĹÝ––Õ≥ľ∆∑÷őŲņīĹÝ––ņķ ∑ĽōĻňļÕ«ų ∆∑÷őŲ°£”…”ŕņš żĺ›ŐŚŃŅīů£¨≤ť—Į…śľįĶń żĺ›∂ŗ£¨īśīĘĹť÷ –‘ń‹ĶÕ£¨»ÁĻŻ≤ĽĹÝ––”ŇĽĮ£¨∂‘ņš żĺ›Ķń‘™–ŇŌĘ£¨ńŕ»›∑√ő Ņ…ń‹≥ŲŌ÷∆ŅĺĪ”įŌž“ĶőŮ Ļ”√°£
∂Ģ żĺ›≤÷Ņ‚∑÷≤„īśīĘĻōľŁľľ űĹ‚őŲ
Īĺ’¬Ĺę“‘įĘņÔ‘∆ żĺ›≤÷Ņ‚AnalyticDB MySQLįś£®Ō¬őńľÚ≥∆ADB£©ő™‘≠–ÕĹť…‹»Áļő‘ŕ żĺ›≤÷Ņ‚≤ķ∆∑÷– ĶŌ÷∑÷≤„īśīĘ£¨≤ĘĹ‚ĺŲ∆šļň–ńŐŰ’Ĺ°£ADBĶń’ŻŐŚľ‹ĻĻ∑÷ő™»ż≤„£ļ
°§Ķŕ“Ľ≤„ «Ĺ”»Ž≤„£ļ”…∂ŗłŲ«į∂ňĹŕĶ„ĻĻ≥…£¨÷ų“™łļ‘ūĹ”»Ž”√Ľß≤ť—Į£¨ĹÝ––SQLĹ‚őŲ°Ę”ŇĽĮ°ĘĶų∂»°£
°§Ķŕ∂Ģ≤„ «ľ∆ň„“ż«ś≤„£ļ”…∂ŗłŲľ∆ň„ĹŕĶ„◊ť≥…£¨łļ‘ū÷ī––”√Ľß≤ť—Į°£
°§Ķ໿≤„ «īśīĘ“ż«ś≤„£ļ”…∂ŗłŲīśīĘĹŕĶ„◊ť≥…£¨”√Ľß żĺ›įīShard«–∆¨īśīĘ£¨√ŅłŲShard”–∂ŗłŲłĪĪĺĪ£÷§łŖŅ…ŅŅļÕłŖŅ…”√°£
1 ņš»» żĺ›īśīĘĹť÷ Ķń—°‘Ů
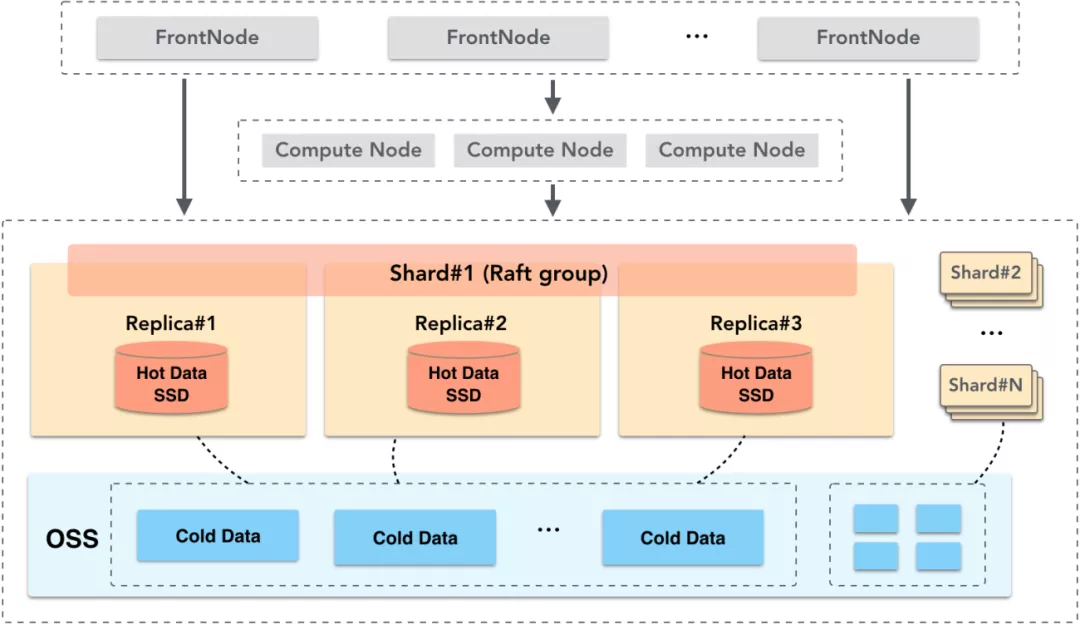
∂‘”ŕ“ĶőŮ…ŌĶń»» żĺ›£¨–Ť≤…”√łŖ–‘ń‹īśīĘĹť÷ ¬ķ◊„∆šŅžňŔ≤ť—Į–Ť«ů°£SSDŌŗ∂‘HDDņīňĶ£¨≥…ĪĺĹŌłŖ£¨Ķę∆šĺŖ”–łŖIOPSļÕłŖīÝŅŪĶńŐō–‘£¨“ÚīňADBį—»» żĺ›≤„Ĺ®ŃĘ‘ŕSSD…Ō£¨≤Ę Ļ”√ żĺ›∂ŗłĪĪĺĽķ÷∆£¨≥ŲŌ÷īśīĘĹŕĶ„“ž≥£ Ī£¨Õ®Ļż«–ĽĽ∑ĢőŮĹŕĶ„ņīĪ£÷§łŖŅ…ŅŅļÕłŖŅ…”√°£
“ĶőŮ…ŌĶńņš żĺ›£¨“Ľį„ «ņķ ∑≥ŃĶŪĶń“ĶőŮ żĺ›ĽÚ»’÷ĺ żĺ›£¨’‚–© żĺ›ŐŚŃŅīů£¨∑√ő ∆Ķ∂»ĶÕ£¨“Úīň»›ŃŅīů°Ę≥…ĪĺĶÕ «īśīĘĹť÷ Ķń÷ų“™—°‘Ů“Úňō°£∂‘”ŕņš żĺ›≤„£¨ADB—°‘ŮĹ®ŃĘ‘ŕįĘņÔ‘∆OSS…Ō°£įĘņÔ‘∆∂‘ŌůīśīĘ∑ĢőŮOSS◊ųő™įĘņÔ‘∆ŐŠĻ©Ķńļ£ŃŅ°ĘĶÕ≥…Īĺ°ĘłŖ≥÷ĺ√–‘Ķń‘∆īśīĘ∑ĢőŮ£¨∆š żĺ›…Ťľ∆≥÷ĺ√–‘≤ĽĶÕ”ŕ99.9999999999%£¨∑ĢőŮŅ…”√–‘≤ĽĶÕ”ŕ99.995%°£OSSŐŠĻ©Ķń’‚–©Őō–‘¬ķ◊„Ńňņš żĺ›≤„∂‘≥…ĪĺļÕŅ…ŅŅ–‘Ķń–Ť«ů£¨Õ¨ ĪŌŗ∂‘”ŕ◊‘ľļő¨Ľ§HDDīŇŇŐ£¨OSS◊‘…ŪĺŖ”–»›ŃŅőřŌřņ©’Ļń‹Ń¶£¨¬ķ◊„ļ£ŃŅ żĺ›īśīĘ–Ť«ů°£≤Ę«“OSSŅ…“‘‘∂≥Ő∑√ő £¨“ÚīňīśīĘĹŕĶ„ĶńłĪĪĺľšŅ…“‘Ļ≤ŌŪ żĺ›ņīĹÝ“Ľ≤ĹĹĶĶÕ≥…Īĺ°£
2 ņš»» żĺ›∂®“Śő Ő‚
“ĶőŮ◊‘…Ū∂‘ņš»» żĺ›Ķń∂®“ŚĪ»ĹŌ√ų»∑°£Ī»»Á∆ů“Ķ÷–“Ľ–©–Ť“™łŖ∆Ķ∑√ő ĶńCRM°ĘERP żĺ›ĺýő™»» żĺ›°£∂Ý∂‘”ŕ…ůľ∆»’÷ĺ£¨ĽÚ żŐž«įĶń∂©Ķ• żĺ›£¨∆š∑√ő ∆Ķ∂»ĶÕ£¨‘ÚŅ…∂®“Śő™ņš żĺ›°£ļň–ńő Ő‚ «£¨“ĶőŮ…ŌĶń’‚–© żĺ›£¨»Áļő‘ŕ∑÷≤„īśīĘ÷–√Ť Ų∆šņš»» Ű–‘≤ĘĪ£÷§īśīĘőĽ÷√Ķń◊ľ»∑–‘°£ņż»Á∆ů“ĶīŔŌķĽÓ∂Į£¨īůŃŅ”√Ľß’ż‘ŕŌŖ…ŌĹÝ––“ĶőŮĹĽĽ•£¨īň Ī»ÁĻŻ∑÷≤„īśīĘīŪőůĶńį—ŅÕĽß–ŇŌĘ°Ę…Ő∆∑–ŇŌĘĶ»ĻōľŁ żĺ›«®“∆ĶĹņš«Ý£¨‘ÚĽŠ“ż∆ūŌŗĻō≤ť—Į–‘ń‹ ‹ňū£¨◊Ó÷’≥ŲŌ÷ŅÕĽßĶ«¬ľ ‹◊Ť£¨ŅÕĽßĶ„Ľų ßį‹Ķ»“ĶőŮ“ž≥££¨Ķľ÷¬∆ů“Ķ ‹ňū°£ADBĹ‚ĺŲ’‚łŲő Ő‚Ķń∑Ĺ∑® «‘ŕ”√ĽßĹ®ĪŪ Ī÷ł∂®īśīĘ≤Ŗ¬‘£®storage_policy£©ņīĺę»∑ĻōŃ™“ĶőŮ…ŌĶńņš»» żĺ›ļÕ∑÷≤„īśīĘ÷–Ķńņš»»īśīĘ£¨Ō¬√ś « ĺņż°£
»ę»»ĪŪ
ňý”– żĺ›īśīĘ‘ŕSSD≤Ę«“≤ĽĽŠĹĶő¬£¨ ”√”ŕ»ęĪŪ żĺ›ĪĽ∆Ķ∑Ī∑√ő £¨«“∂‘∑√ő –‘ń‹”–ĹŌłŖ“™«ůĶń≥°ĺį£¨Ī»»ÁCRM°ĘERP żĺ›°£
Create table t1(
id int,
dt datetime
) distribute by hash(id)
storage_policy = 'HOT'; |
»ęņšĪŪ
ňý”– żĺ›īśīĘ‘ŕOSS£¨ ”√”ŕŐŚŃŅīů£¨∑√ő ∆Ķ∂»ĶÕ£¨–Ť“™ľű…ŔīśīĘ≥…ĪĺĶń≥°ĺį£¨Ī»»Á…ůľ∆»’÷ĺ żĺ›°£
Create table t2(
id int,
dt datetime
) distribute by hash(id)
storage_policy = 'COLD'; |
ņš»»ĽžļŌĪŪ
”√”ŕ żĺ›ņš»»”–√ųŌ‘ ĪľšīįŅŕĶń≥°ĺį°£ņż»Á◊ÓĹŁ7ŐžĶń”őŌ∑»’÷ĺ żĺ›£¨Ļ„łśĶ„Ľų żĺ›Ķ»–ŤłŖ∆Ķ∑√ő £¨◊ųő™»» żĺ›īśīĘ£¨∂Ý7Őž«įĶń żĺ›Ņ…ĹĶő¬ő™ņš żĺ›£¨ĶÕ≥…ĪĺīśīĘ°£
◊Ę£ļņš»»ĽžļŌĪŪ–ŤŇšļŌĪŪĶń∑÷«Ý Ļ”√°£≥żstorage_policyÕ‚£¨ĽĻ–Ť÷ł∂®hot_partition_count Ű–‘°£hot_partition_count÷łįī∑÷«Ý÷ĶĶĻ–Ú£¨»°◊ÓīůNłŲ∑÷«Ýő™»»∑÷«Ý£¨∆š”ŗő™ņš∑÷«Ý°£Ō¬ņż÷–£¨ĪŪįīŐž∑÷«Ý£¨hot_partition_count
= 7ĪŪ ĺ∑÷«Ý÷Ķ◊ÓīůĶń7łŲ∑÷«Ý£¨“≤ĺÕ «◊ÓĹŁ7ŐžĶń żĺ›ő™»» żĺ›°£
Create table t3(
id int,
dt datetime
) distribute by hash(id)
partition by value(date_format(dt, '%Y%m%d'))
lifecycle 365
storage_policy = 'MIXED' hot_partition_count =
7; |
–řłńņš»»≤Ŗ¬‘
ňś“ĶőŮĶńĪšĽĮ£¨ĪŪĶń∑√ő Őō–‘Ņ…ń‹∑Ę…ķĪšĽĮ£¨∆ů“ĶŅ…“‘ňś Ī–řłńĪŪĶńīśīĘ≤Ŗ¬‘ņī ”¶–¬ĶńīśīĘ–Ť«ů°£
£®1£©”…»»ĪŪ–řłńő™ņšĪŪ£ļ
Alter table t1 storage_policy = 'COLD'; |
£®2£©–řłń»»∑÷«ÝĶńłŲ ż£¨–řłńő™◊ÓĹŁ14ŐžĶń żĺ›ő™»» żĺ›£ļ
Alter table t3 storage_policy = 'MIXED' hot_partition_count
= 14; |
3 ņš»» żĺ›◊‘∂Į«®“∆ő Ő‚
ňś ĪľšŃų Ň£¨»» żĺ›Ķń∑√ő ∆Ķ∂»ĹĶĶÕ£¨ĹĶő¬ő™ņš żĺ›°£Ī»»Á“Ľ–©»’÷ĺ żĺ›£¨‘ŕ żŐžļůĺÕļ‹…Ŕ‘Ŕ∑√ő £¨∑÷≤„īśīĘ–Ťį—’‚≤Ņ∑÷ żĺ›”…»» żĺ›≤„«®“∆ĶĹņš żĺ›≤„ņīĹĶĶÕ≥…Īĺ°£’‚ņÔĶńļň–ńő Ő‚ «»Áļő÷™Ķņńń≤Ņ∑÷ żĺ›Ķńő¬∂»ĹĶĶÕŃň–Ť“™«®“∆£ŅŌ¬√śÕ®Ļż“ĽłŲņš»»ĽžļŌĪŪ£¨ņīňĶ√ųADBĹ‚ĺŲł√ő Ő‚Ķń∑Ĺ∑®°£»ÁŌ¬ «“Ľ’Ň»’÷ĺĪŪ£¨◊ÓĹŁ»żŐž żĺ›ő™»» żĺ›£¨¬ķ◊„łŖ–‘ń‹‘ŕŌŖ≤ť—Į–Ť«ů£¨»żŐž«į żĺ›ő™ņš żĺ›£¨ĶÕ≥…ĪĺīśīĘ≤ʬķ◊„ĶÕ∆Ķ∑√ő –Ť«ů°£
Create table Event_log (
event_id bigint,
dt datetime,
event varchar
) distribute by hash(event_id)
partition by value(date_format(dt, '%Y%m%d'))
lifecycle 365
storage_policy = 'MIXED' hot_partition_count =
3; |
‘ŕĪĺņż÷–£¨ĪŪ ◊Ō»įīŐž∑÷«Ý°£
| partition by value(date_format(dt, '%Y%m%d'))
lifecycle 365 |
≤Ę∂®“Śņš»»≤Ŗ¬‘ő™ĽžļŌń£ Ĺ£¨◊Ó–¬3ŐžĶń żĺ› «»» żĺ›°£
| storage_policy = 'MIXED' hot_partition_count
= 3 |
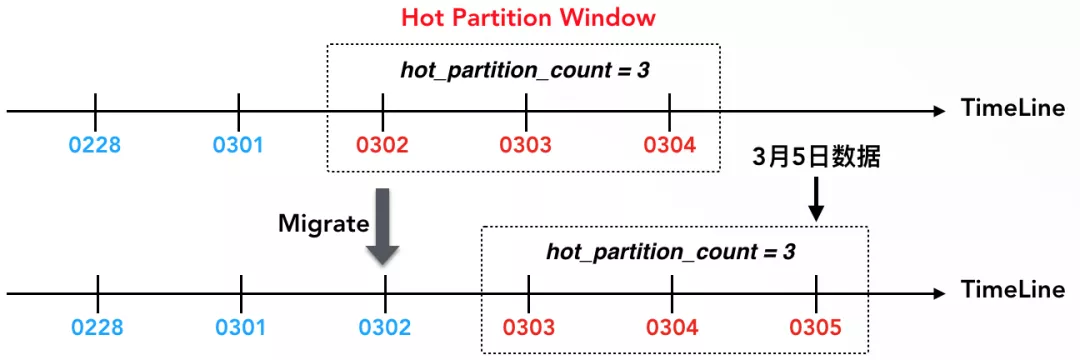
‘ŕADB÷–£¨ņš»» żĺ›“‘∑÷«Ýő™◊Ó–°Ń£∂»£¨ľī“ĽłŲ∑÷«Ý“™√ī‘ŕ»»«Ý£¨“™√ī‘ŕņš«Ý£¨»ĽļůÕ®Ļż»»∑÷«ÝīįŅŕņīŇ–∂®ń≥łŲ∑÷«Ý «∑Ůő™»»∑÷«Ý£®ĪŪ Ű–‘÷–Ķńhot_partition_count∂®“ŚŃň»»∑÷«ÝīįŅŕĶńīů–°£©°£‘ŕĪĺņż÷–£¨ľŔ∂®ĶĪ«į»’∆ŕ «3‘¬4»’£¨‘Ú3‘¬2»’°Ę3»’°Ę4»’’‚»żŐžĶń żĺ›ī¶”ŕ»»∑÷«ÝīįŅŕ÷–£¨“Úīň «»»∑÷«Ý°£ĶĪ–ī»Ž3‘¬5»’Ķń żĺ›ļů£¨‘Ú3‘¬3»’°Ę4»’°Ę5»’’‚»żŐž żĺ›◊ť≥…Ńň–¬Ķń»»∑÷«ÝīįŅŕ£¨3‘¬2»’ żĺ›ĹĶő¬ő™ņš żĺ›£¨ļůŐ®ĽŠ◊‘∂Į÷ī––»»ņš«®“∆£¨į—3‘¬2»’Ķń żĺ›”…»»«Ý«®“∆ĶĹņš«Ý°£Õ®Ļż»»∑÷«ÝīįŅŕ£¨ŅÕĽßłý囓ĶőŮ≥°ĺįŅ…“‘√ų»∑∂®“Śņš»»ĪŖĹÁ£¨“ĽĶ© żĺ›ĹĶő¬‘Ú◊‘∂Į«®“∆°£
4 ņš żĺ›∑√ő –‘ń‹ő Ő‚
ņš żĺ›īśīĘ‘ŕOSS…Ō£¨OSS «‘∂≥ŐīśīĘŌĶÕ≥≤ĘÕ®ĻżÕݬÁ∑√ő £¨—”≥ŔĹŌłŖ°£ņż»ÁŇ–∂ŌőńľĢ «∑Ůīś‘ŕ£¨ĽŮ»°őńľĢ≥§∂»Ķ»‘™–ŇŌĘ≤Ŕ◊ų£¨Ķ•īőĹĽĽ•Ķń∑√ő —”≥Ŕ‘ŕļŃ√Žľ∂Īū°£Õ¨ Ī£¨OSSīÝŅŪ”–Ōř£¨“ĽłŲ’ňļŇŌ¬’ŻŐŚ÷Ľ”–GBľ∂ĪūīÝŅŪ£¨ŐŠĻ©Ķń’ŻŐŚQPS“≤÷Ľ”– ż ģÕÚ£¨≥¨ĻżļůOSSĺÕĽŠŌřŃų°£ żĺ›≤÷Ņ‚ńŕ≤ŅīśīĘ◊ŇīůŃŅőńľĢ£¨»ÁĻŻ≤Ľ∂‘OSS∑√ő ◊Ų”ŇĽĮ£¨‘ÚĽŠ≥ŲŌ÷≤ť—Į“ž≥£°£ņż»Á≤ť—ĮŅ…ń‹…śľį żįŔÕÚłŲőńľĢ£¨ĹŲĹŲĽŮ»°’‚–©őńľĢĶń‘™–ŇŌĘĺÕĽŠīÔĶĹOSSĶńQPS…ŌŌř£¨◊Ó÷’Ķľ÷¬≤ť—Į≥¨ ĪĶ»“ž≥££¨“Úīň–Ť∂‘OSSĶń∑√ő ĹÝ––”ŇĽĮņīĪ£÷§“ĶőŮĶńŅ…”√–‘≤ĘŐŠłŖ≤ť—Į–‘ń‹°£»ÁŌ¬∂‘‘™–ŇŌĘ∑√ő ”ŇĽĮļÕ żĺ›∑√ő ”ŇĽĮ∑÷ĪūĹť…‹°£
‘™–ŇŌĘ∑√ő ”ŇĽĮ
ADB◊ųő™ żĺ›≤÷Ņ‚£¨Ķ◊≤„īśīĘŃňīůŃŅĶń żĺ›őńľĢļÕňų“żőńľĢ°£ADB”ŇĽĮ‘™–ŇŌĘ∑√ő Ķń∑Ĺ∑® «∂‘őńľĢĹÝ––ĻťĶĶ£¨ľīį—“ĽłŲ∑÷«ÝńŕĶńňý”–őńľĢīÚįŁ‘ŕ“ĽłŲĻťĶĶőńľĢ÷–£¨≤ĘŐŠĻ©“Ľ≤„ņŗPOSIXĶńőńľĢ∑√ő Ĺ”Ņŕ£¨Õ®Ļż’‚łŲĹ”Ņ໕∂Ń»°őńľĢńŕ»›°£
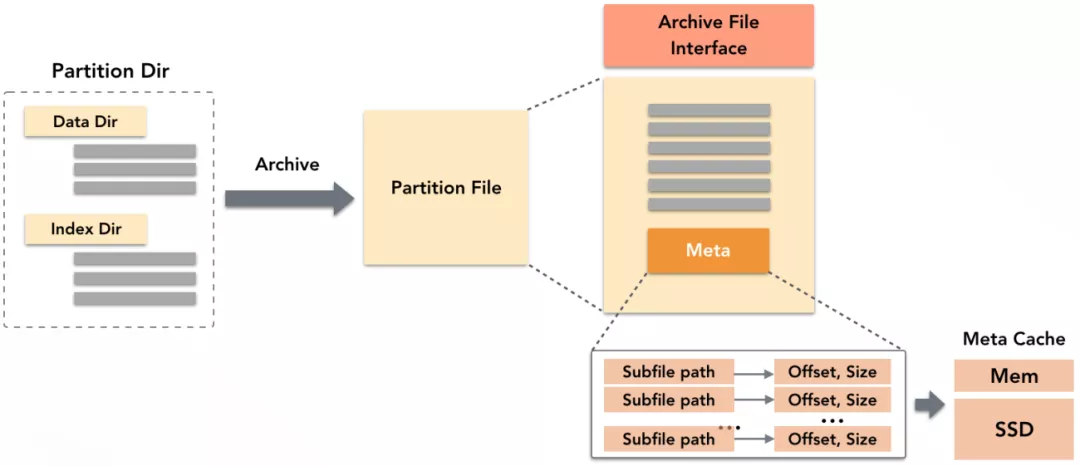
ĻťĶĶőńľĢĶńMetaņÔńŕīśīĘŃň√ŅłŲ◊”őńľĢĶń∆ę“∆ļÕ≥§∂»Ķ»‘™–ŇŌĘ°£∂Ń»° Ī£¨Ō»ľ”‘ōĻťĶĶőńľĢĶńMeta£¨÷Ľ–Ť“™“ĽīőĹĽĽ•ľīŅ…ń√ĶĹňý”–◊”őńľĢ‘™–ŇŌĘ£¨ĹĽĽ•īő żĹĶĶÕ żįŔĪ∂°£ő™ĹÝ“Ľ≤Ĺľ”ňŔ£¨ADB‘ŕīśīĘĹŕĶ„ĶńńŕīśļÕSSD…Ō∑÷ĪūŅ™ĪŔŃň“Ľ–°ŅťŅ’ľšĽļīśĻťĶĶőńľĢĶńMeta£¨ľ”‘ōĻżľīőř–Ť‘Ŕ∑√ő OSSĽŮ»°‘™–ŇŌĘ°£Õ¨ Ī£¨ĻťĶĶļů÷Ľ–Ť“ĽłŲ š»ŽŃųĪ„Ņ…∂Ń»°ňý”–◊”őńľĢ żĺ›ńŕ»›£¨Ī‹√‚ő™√ŅłŲ◊”őńľĢĶ•∂ņŅ™∆Ű š»ŽŃųĶńŅ™Ōķ°£
żĺ›∑√ő ”ŇĽĮ
≤ť—Į÷–£¨őř¬Ř «…®√Ťňų“ż£¨ĽĻ «∂Ń»° żĺ›Ņť£¨∂ľ–Ť“™∂Ń»°OSS…ŌőńľĢĶńńŕ»›£¨∂ÝOSSőř¬Ř∑√ő –‘ń‹ĽĻ «∑√ő īÝŅŪ∂ľ”–Ōř°£ő™ľ”ňŔőńľĢńŕ»›Ķń∂Ń»°£¨ADBīśīĘĹŕĶ„ĽŠ◊‘∂ĮņŻ”√SSD…ŌĶń“ĽŅťŅ’ľš◊Ų żĺ›Cache£¨«“CacheĶń…Ō≤„ŐŠĻ©ŃňņŗPOSIXĶńőńľĢ∑√ő Ĺ”Ņŕ£¨ żĺ›…®√Ťň„◊”£®Table
Scanner£©Ņ…“‘ŌŮ∑√ő ∆’Õ®őńľĢ“Ľ—ý∑√ő Cache÷–Ķńńŕ»›°£
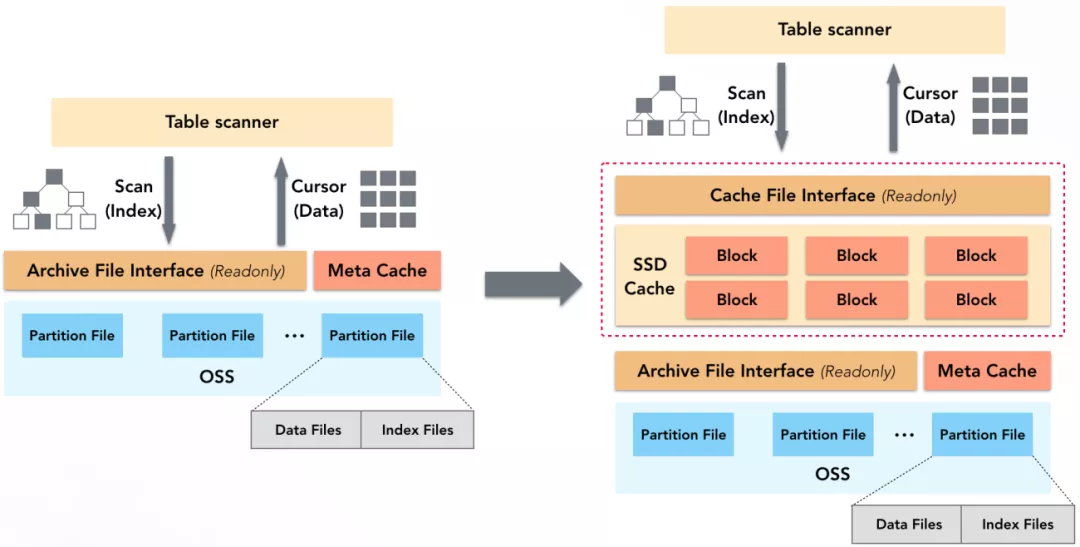
≤ť—Į÷–∂‘OSSĶńňý”–∑√ő £®ňų“ż°Ę żĺ›Ķ»£©∂ľŅ…ĹŤ÷ķSSD Cacheľ”ňŔ£¨÷Ľ”–ĶĪ żĺ›≤Ľ‘ŕCache÷– Ī≤ŇĽŠ∑√ő OSS°£’Ž∂‘’‚ŅťCache£¨ADBĽĻ◊ŲŃň»ÁŌ¬”ŇĽĮ£ļ
∂ŗŃ£∂»ĶńCache Block£¨ľ”‘ō‘™–ŇŌĘ Ī Ļ”√ĹŌ–°ĶńBlock£¨ľ”‘ō żĺ› Ī Ļ”√ĹŌīůĶńBlock£¨“‘īňŐŠłŖCacheŅ’ľšņŻ”√¬ °£
°§‘™ żĺ›‘§»»£¨◊‘∂Įľ”‘ō żĺ›ļÕňų“żĶń‘™ żĺ›ĶĹCache÷–≤ĘňÝ∂®£¨“‘ ĶŌ÷‘™ żĺ›łŖ–ß∑√ő °£
°§Ľý”ŕņš»»∑√ő ∂”Ń–ĶńņŗLRUň„∑®£¨ ĶŌ÷őřňÝĽĮłŖ–‘ń‹ĽĽ»ŽĽĽ≥Ų°£
°§◊‘∂ĮIOļŌ≤Ę£¨ŌŗŃŕ żĺ›Ķń∑√ő ļŌ≤Ęő™“ĽłŲ«Ž«ů£¨ľű…Ŕ”ŽOSSĶńĹĽĽ•īő ż°£
»ż ◊‹ĹŠ
ňś◊Ň∆ů“Ķ żĺ›ŃŅĶń≤Ľ∂Ō‘Ų≥§£¨īśīĘ≥…Īĺ≥…ő™∆ů“Ķ‘§ň„÷–Ķń÷ō“™◊ť≥…≤Ņ∑÷£¨ żĺ›≤÷Ņ‚◊ųő™∆ů“ĶīśīĘļÕĻ‹ņŪ żĺ›ĶńĽýī°…Ť ©£¨Õ®Ļż∑÷≤„īśīĘľľ űļ‹ļ√ĶńĹ‚ĺŲŃň∆ů“Ķ÷–īśīĘ≥…Ī唎–‘ń‹Ķń∆Ĺļ‚ő Ő‚°£∂‘”ŕ∑÷≤„īśīĘľľ ű÷–ĶńĻōľŁŐŰ’Ĺ£¨Īĺőń“‘‘∆‘≠…ķ żĺ›≤÷Ņ‚AnalyticDB
MySQLő™‘≠–Õ£¨Ĺť…‹Ńň∆š»ÁļőÕ®Ļżņš»»≤Ŗ¬‘∂®“Ś£¨»»∑÷«ÝīįŅŕ£¨őńľĢĻťĶĶ£¨SSD CacheņīĹ‚ĺŲņš»» żĺ›∂®“Ś£¨ņš»» żĺ›«®“∆£¨ņš żĺ›∑√ő ”ŇĽĮĶ»ĻōľŁő Ő‚°£ |









