| Īŗľ≠Õ∆ľŲ: |
Īĺőń÷ų“™Ĺť…‹Ńň÷ų“™Ĺť…‹īů żĺ›‘ňő¨‘ŕĹ®…ŤDataOps żĺ›≤÷Ņ‚ļÕETLĻ§≥ŐĶńňľ¬∑°£
Īĺőńņī◊‘csdn£¨”…ĽūŃķĻŻ»ŪľĢLindaĪŗľ≠°ĘÕ∆ľŲ°£ |
|
1.“ż—‘
ĶĪ«į“ĶĹÁ∂ľ‘ŕ≥©ŐłAI°ĘīůŃńAIOps£¨∆š Ķ∑Ľľš”–’‚—ýĶńňĶ∑®°™°™“™◊ŲAIŌ»◊ŲBI°£’żňýőĹ°į«…łĺń—ő™őř√◊÷ģī∂°Ī£¨AI–Ť“™ żĺ› š»Ž£¨Data‘Ú «÷ō÷–÷ģ÷ō£¨’‚“≤ «ő“√«∂®“ŚĹ®…ŤDataOpsĶń≥ű÷‘°£Ō¬őńĹę÷ų“™Ĺť…‹īů żĺ›‘ňő¨‘ŕĹ®…ŤDataOps żĺ›≤÷Ņ‚ļÕETLĻ§≥ŐĶńňľ¬∑°£
2. żĺ› ”Ĺ«VS‘ňő¨ŇŇ≤ť
ĶĪ“ĽłŲĹĽĽĽĽķ≥ŲŌ÷Ļ ’Ō£¨SRE»•ŇŇ≤ťő Ő‚Ķń ĪļÚÕýÕý «÷ī––“Ľ∂—√ŁŃÓ◊Óļůłýĺ›√ŁŃÓĶńĹŠĻŻ◊Ų≥ŲĹŠ¬Ř–‘ĶńŇ–∂Ō°£ Ķľ …Ō’‚ņÔ”–2łŲ≤Ĺ÷Ť£ļ
« żĺ›≤…ľĮ£¨ľī÷ī––√ŁŃÓ.
¬Ŗľ≠Ň–∂Ō(łý囫į√ś÷ī––Ķń√ŁŃÓĹŠĻŻ£¨»ÁĻŻń‹Ň–∂Ō≥Ųő Ő‚‘ÚÕ£÷Ļ£¨∑Ů‘ÚľŐ–Ý÷ī––≤Ĺ÷Ť1)
ń«√ī£¨”–√Ľ”–įž∑®»√2łŲ≤Ĺ÷Ť’ś’żĹ‚ŮÓ£Ņ
»ÁĻŻő“√«“—ĺ≠į—ŌŗĻōŃ™Ķń żĺ›ŐŠ«į≤…ľĮĶĹŃň żĺ›≤÷Ņ‚£¨’‚—ýĶńĻż≥ŐĺÕĪš≥…Ńň÷ī––SQLĹÝ––ő Ő‚ŇŇ≤ťŃň°£ń«√īī”ETLĶń ”Ĺ«Ņī£¨ŇŇ≤ťő Ő‚Ļż≥Ő «’‚—ýĶń≤Ĺ÷Ť£ļ
żĺ›≤…ľĮ-> żĺ›≤÷Ņ‚
Õ®ĻżSQLŇŇ≤ťŌĶÕ≥ő Ő‚
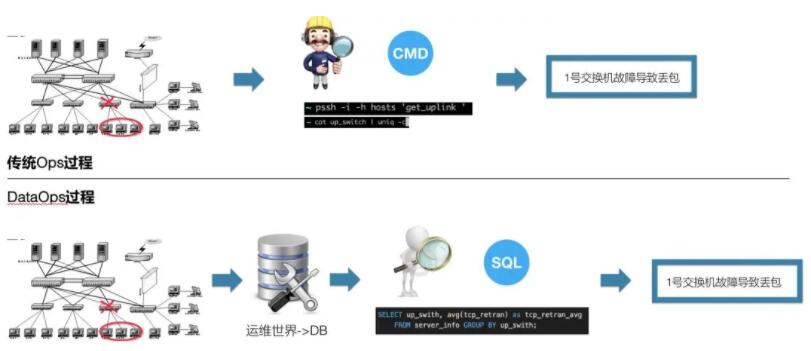
”–Õ¨—ß“Ľ∂®ĽŠ“…Ľů£¨ Ō¬√śĶńETLĻż≥ŐņīŇŇ≤ťő Ő‚£¨Īō–Ž“™«ů żĺ›≤÷Ņ‚ņÔĪō–Ž”–»ęŃŅĶń żĺ›į°£¨ő“√«ł√»ÁļőņīĹ®…Ť’‚łŲ»ęŃŅĶń żĺ›ńō£Ņ
Ķľ ÷ī––Ķń ĪļÚ£¨“Ľő∂◊∑«ůīů∂Ý»ęĶń żĺ› «≤ĽŅ…»°Ķń£¨ő“√«Ņ…“‘ī”2łŲ∑ĹŌÚ◊ųő™≥Ų∑ĘĶ„£¨Ľý”ŕŌ÷”– żĺ›Ĺ®…Ť żĺ›≤÷Ņ‚£ļ
łý囑ňő¨ĺ≠—ť£¨»Ōő™–Ť“™≤…ľĮĶń żĺ›£¨«“Ī»ĹŌ»›“◊≤…ľĮĶĹĶń żĺ›°£
łýĺ›ņķ ∑≥ŲŌ÷ĻżĶńő Ő‚£¨łīŇŐņīŅī£¨ńń–© żĺ›÷ĶĶ√≤…ľĮ°£
‘ňő¨ żĺ›ņŗ–Õ
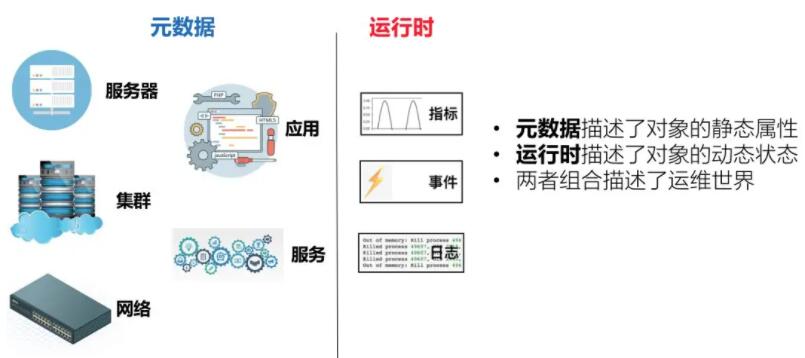
‘ŕ żĺ›≤÷Ņ‚ĶńĹ®…Ť÷–£¨“™≥š∑÷»Ō ∂ő“√«”–ńń–© żĺ›ņŗ–Õ£Ľ÷™ľļ÷™Īň£¨∑Ĺń‹įŔ’Ĺ≤Ľīý°£
‘™ żĺ›£ļ‘™ żĺ› «Ōŗ∂‘ĺ≤Ő¨Ķń żĺ›£¨“Ľį„”√”ŕ√Ť Ų∂‘ŌůĶń»Űł… Ű–‘°£ Ī»»ÁĽķ∆ųĶńłų÷÷–ŇŌĘ£®÷ųĽķ√Ż°Ęip°ĘĽķ–ÕĶ»£©°ĘľĮ»ļ£®ľĮ»ļ√Ż≥∆°Ę∂‘”¶ĶńIDC°Ę»ŪľĢįśĪĺĶ»£©°£
‘ň–– Ī£®∂»ŃŅ£©£ļ‘ň–– Ī“Ľį„ «łķ ĪľšŌŗĻōĶń żĺ›£¨ «∂ĮŐ¨Ķń żĺ›£ĽĪ»»ÁĽķ∆ų‘ň––Ļż≥Ő÷–≤ķ…ķĶń÷łĪÍ°Ę»’÷ĺ°Ę ¬ľĢĶ»°£
ņŪĹ‚’‚2÷÷ĽýĪĺĶń żĺ›ņŗ–Õ£¨∂‘”ŕő“√«Ĺ®…Ť żĺ›≤÷Ņ‚ «”–įÔ÷ķĶń, ‘ŕĹ®…Ť’‚ŃĹņŗ żĺ› Ī£¨”¶≥š∑÷Ņľ¬«ŃĹ’ŖĶńŐō–‘£ļ
‘™ żĺ›∂‘◊ľ»∑∂»”–∑«≥£łŖĶń“™«ů£¨–Ť“™◊Ų◊ľ»∑∂»Ķń«ŅĪ£’Ō£Ľ∂ÝīśīĘĶń żĺ›ŃŅ”÷ «Ī»ĹŌ–°Ķń£Ľ
‘ň–– Ī żĺ›∂‘◊ľ»∑∂»“™«ůŌŗ∂‘ĹŌĶÕ£¨Ķę∂‘ Ķ Ī–‘ļÕĻśń£ĽĮīśīĘľ∆ň„“™«ůĹŌłŖ.
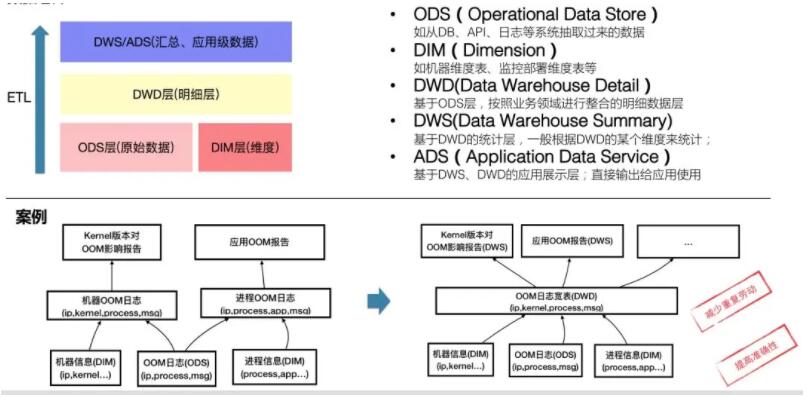
3.Õ≥“Ľ żĺ›∑÷≤„Ļś∑∂
‘ŕ żĺ›≤÷Ņ‚ņŪ¬Ř÷–£¨«į√śő“√«ŐŠĶĹĶń‘™ żĺ›≥∆ő™DIM£®ő¨∂»£©£¨‘ň–– Ī∂‘”¶ĶĹODS£®‘≠ ľ żĺ›£©°£
ő“√«Ķń żĺ›≤÷Ņ‚Ĺ®…Ť–Ť“™įī’’‘≠ ľ żĺ›+ő¨∂» żĺ›Ķń∑Ĺ∑®ņīĻĻĹ®£¨“‘ľű…Ŕ żĺ›ĻĻ÷ĢĶń÷ōłī–‘Ļ§◊ų°£
ĺŔłŲņż◊”£¨ő“√«Ō÷‘ŕ”–“Ľ∑›‘≠ ľ żĺ› «Ľķ∆ųĶńĹÝ≥ŐOOM»’÷ĺľ«¬ľ°£ņÔ√śīůłŇįŁļ¨’‚—ýĶń–ŇŌĘ°£

’‚ ĪSRE A–Ť“™∑÷őŲńń÷÷ĹÝ≥Ő‘ŕ ≤√ī—ýĶńkerenlŌ¬Ī»ĹŌ»›“◊OOM£¨ňŻĽŠį—ĹÝ≥ŐOOM»’÷ĺľ«¬ľļÕĽķ∆ų–ŇŌĘĪŪ◊ŲJoin£¨ĹÝ∂Ýń√ĶĹĹÝ≥ŐOOMļÕKernelĶńĻōŌĶ£¨Ķ√≥ŲŌŗ”¶ĶńĹŠ¬Ř°£
ľŔ…ŤSRE B–Ť“™∑÷őŲńń÷÷ĹÝ≥Ő‘ŕ ≤√ī—ýĶńńŕīśŇš÷√Ō¬Ī»ĹŌ»›“◊OOM£¨ňŻ“≤ĽŠį—ĹÝ≥ŐOOM»’÷ĺľ«¬ľļÕĽķ∆ų–ŇŌĘĪŪ◊ŲJoin£¨ĹÝ∂Ýń√ĶĹĹÝ≥ŐOOMļÕńŕīśīů–°ĶńĻōŌĶ£¨Ķ√≥ŲŌŗ”¶ĶńĹŠ¬Ř°£
SRE AļÕSRE B ◊ŲŃň“ĽľĢÕ¨—ýĶń ¬«ť£¨ «į—ĹÝ≥ŐOOMľ«¬ľĪŪļÕĽķ∆ųĪŪ◊ŲJoin£¨»Ľļů∑÷ĪūĶ√≥ŲĹŠ¬Ř°£ő“√«Ņ…“‘ŌŽŌů£¨‘Ŕņī“ĽłŲ∑÷őŲ≥°ĺįŅ…ń‹ĽĻ“™‘ŔJoin“Ľīő°£
ń«√ī»ÁļőĪ‹√‚÷ōłīĶńĻ§◊ų£Ņ
īūįł «£ļ≤…”√∑÷≤„ń£–Õ£¨“‘…Ō√śĶńņż◊”ņīŅī£¨ő“√«į—OOMľ«¬ľĪŪļÕĽķ∆ųĪŪJoinļůĶńĪŪīÚ‘ž≥…“ĽłŲŅŪĪŪ£¨ľīįŁļ¨ŃňőīņīŅ…ń‹∑÷őŲĶĹĶńňý”–ő¨∂»ĶńĪŪ£¨ń«√īļů–ÝĹÝ“Ľ≤Ĺ∑÷Ķń∑÷őŲĻ§◊ų∂ľŅ…“‘“‘’‚’ŇŅŪĪŪő™Ľý◊ľŃň°£

ļ√£¨ő“√«Ō÷‘ŕņī’ż ĹņŪĹ‚“ĽŌ¬’ŻłŲĻż≥Ő£¨ ő“√«į—≤…ľĮĻżņīĶń żĺ›Ĺ–◊ŲODS≤„£¨į—ő¨∂»ŌŗĻōĶń≥∆ő™DIM≤„£®Ī»»Áł’≤ŇĽķ∆ųĶń“Ľ–©ĺ≤Ő¨–ŇŌĘ£¨»ÁCPU°ĘMEMŇš÷√£©£¨’‚ ĪļÚODS≤„Ķń żĺ›ļÕDIM≤„Ķń żĺ›◊ŲJOIN£¨ĺÕį—ODS≤„Ķń żĺ›ņ©’ĻŃň£¨≤ķ…ķŃňő¨∂»Ī»ĹŌ∑ŠłĽĶń żĺ›£¨ő“√«Ĺ–◊ŲDWD≤„£®“≤ĺÕ «ő“√«…Ō√śĶń°įŅŪĪŪ°Ī£©°£÷ģļůĽý”ŕDWD≤„Ķń żĺ›£¨įī’’»Űł…łŲő¨∂»ņīīÚ‘žĺÕŅ…“‘–ő≥…DWS≤„£®Ľ„◊‹≤„£©£¨“≤Ņ…“‘ĺ≠Ļż“Ľ–©ETLĻż≥ŐĪš≥… ļŌ”¶”√Ķń żĺ›£¨Õ¨≤ĹĶĹ“ĶőŮ żĺ›Ņ‚»• Ļ”√°£
ļ√£¨ő“√«Ō÷‘ŕņī’ż ĹņŪĹ‚“ĽŌ¬’ŻłŲĻż≥Ő£¨ ő“√«į—≤…ľĮĻżņīĶń żĺ›Ĺ–◊ŲODS≤„£¨į—ő¨∂»ŌŗĻōĶń≥∆ő™DIM≤„£®Ī»»Áł’≤ŇĽķ∆ųĶń“Ľ–©ĺ≤Ő¨–ŇŌĘ£¨»ÁCPU°ĘMEMŇš÷√£©£¨’‚ ĪļÚODS≤„Ķń żĺ›ļÕDIM≤„Ķń żĺ›◊ŲJOIN£¨ĺÕį—ODS≤„Ķń żĺ›ņ©’ĻŃň£¨≤ķ…ķŃňő¨∂»Ī»ĹŌ∑ŠłĽĶń żĺ›£¨ő“√«Ĺ–◊ŲDWD≤„£®“≤ĺÕ «ő“√«…Ō√śĶń°įŅŪĪŪ°Ī£©°£÷ģļůĽý”ŕDWD≤„Ķń żĺ›£¨įī’’»Űł…łŲő¨∂»ņīīÚ‘žĺÕŅ…“‘–ő≥…DWS≤„£®Ľ„◊‹≤„£©£¨“≤Ņ…“‘ĺ≠Ļż“Ľ–©ETLĻż≥ŐĪš≥… ļŌ”¶”√Ķń żĺ›£¨Õ¨≤ĹĶĹ“ĶőŮ żĺ›Ņ‚»• Ļ”√°£
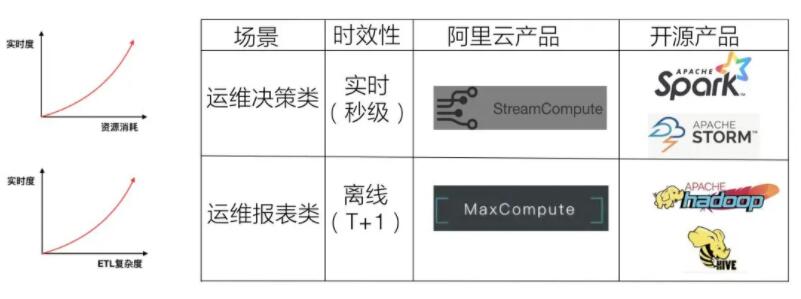
4. żĺ›Ķń Ī–ß–‘Ķń»®ļ‚
‘ňő¨≥°ĺį∂‘ żĺ› Ķ Ī–‘Ķń“™«ů”ņ‘∂ «Őįņ∑Ķń, żĺ›‘Ĺ Ķ Ī£¨ł∂≥ŲĶń◊ ‘īļÕETLłī‘”∂»ĶńīķľŘ‘Ĺīů°£“Úīň£¨≤Ę≤Ľ «ňý”–Ķń żĺ›ő“√«∂ľ“™ Ķ ĪĽĮ£¨–Ť“™łýĺ›’ś ĶĶń≥°ĺįļÕ–Ť«ů£¨—°‘ŮļŌ Ķń Ī–ß–‘°£
“Ľį„∂Ý—‘£¨ …śľįĶĹ‘ňő¨ĺŲ≤ŖņŗĶń≥°ĺį£¨ Ī–ß–‘“™«ů «Ī»ĹŌłŖĶń£¨Ĺ®“ť Ļ”√ Ķ ĪĶń∑Ĺįł£Ľ∂Ý∂‘”ŕĪ®ĪŪņŗĶń≥°ĺį£¨“Ľį„”√T+1Ķń∑Ĺ Ĺ»•◊ŲľīŅ…°£
5.–°ĹŠ
żĺ›≤÷Ņ‚“—ĺ≠”–“ĽŐ◊≥… žĶńľľ űļÕņŪ¬ŘŃň£¨»ÁļőĹę‘ňő¨”Ž żĺ›≤÷Ņ‚Ĺ®…ŤĹŠļŌļ√£¨īÚ‘ž≥Ų ļŌDataOpsĶń żĺ›≤÷Ņ‚£¨ Ķľ …Ō «“ĽłŲĺ…∆Ņ◊į–¬ĺ∆Ķńő Ő‚°£
»√ żĺ›≤÷Ņ‚ņŪ¬Ř‘ŕDataops÷–≥š∑÷ŐŚŌ÷£¨»√DataOpsĶń Ķľý«ż∂ĮSRE‘ňő¨÷«ń‹ĽĮĶń≥Ő∂»£¨“≤ «ő“√«‘ŕ≤Ľ∂ŌŐĹňųļÕ◊∑«ůĶńńŅĪÍ°£ |









