| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫЪ§ОнВжПтНЈФЃЕФФПЕФЃПГЃМћЕФЪ§ОнНЈФЃЗНЗЈЃЌГЃМћЫФжжНЈФЃЗНЗЈЕФНЈФЃВНжшгыбнЪОвдМАЫФжжФЃаЭзмНсЁЃ
БОЮФРДздcsdnЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
1.Ъ§ОнВжПтНЈФЃЕФФПЕФЃП
ЮЊЪВУДвЊНјааЪ§ОнВжПтНЈФЃЃПДѓЪ§ОнЕФЪ§ВжНЈФЃЪЧЭЈЙ§НЈФЃЕФЗНЗЈИќКУЕФзщжЏЁЂДцДЂЪ§ОнЃЌвдБудк адФмЁЂГЩБОЁЂаЇТЪКЭЪ§ОнжЪСПжЎМфевЕНзюМбЦНКтЕуЁЃвЛАужївЊДгЯТУцЫФЕуПМТЧ
ЗУЮЪадФмЃКФмЙЛПьЫйВщбЏЫљашЕФЪ§ОнЃЌМѕЩйЪ§ОнI/O
Ъ§ОнГЩБОЃКМѕЩйВЛБивЊЕФЪ§ОнШпгрЃЌЪЕЯжМЦЫуНсЙћЪ§ОнИДгУЃЌНЕЕЭДѓЪ§ ОнЯЕЭГжаЕФДцДЂГЩБОКЭМЦЫуГЩБО
ЪЙгУаЇТЪЃКИФЩЦгУЛЇгІгУЬхбщЃЌЬсИпЪЙгУЪ§ОнЕФаЇТЪ
Ъ§ОнжЪСПЃКИФЩЦЪ§ОнЭГМЦПкОЖЕФВЛвЛжТадЃЌМѕЩйЪ§ОнМЦЫуДэЮѓ ЕФПЩФмадЃЌЬсЙЉИпжЪСПЕФЁЂвЛжТЕФЪ§ОнЗУЮЪЦНЬЈ
2.ГЃМћЕФЪ§ОнНЈФЃЗНЗЈ
Ъ§ОнВжПтБОжЪЪЧДгЪ§ОнПтбмЩњГіРДЕФЃЌЫљвдЪ§ОнВжПтЕФНЈФЃвВЪЧВЛЖЯбмЩњЗЂеЙЕФЁЃДгзюдчЕФНшМјЪ§ОнПтЕФЗЖЪННЈФЃЃЌЕНж№НЅЬсГіЮЌЖШНЈФЃЃЌData
VaultФЃаЭЃЌAnchorФЃаЭЕШЕШЃЌдНЭљКѓНЈФЃЕФвЊЧѓдНИпЃЌдНашТњзу3NF,4NFЕШЁЃЕЋЪЧЖдгкЪ§ОнВжПтРДЫЕЃЌФПЧАжїСїЛЙЪЧЮЌЖШНЈФЃ,ЛсМадгзХЗЖЪННЈФЃЁЃ
Ъ§ОнВжПтНЈФЃЗНЗЈТлПЩЗжЮЊЃКЗЖЪННЈФЃЁЂЮЌЖШНЈФЃЁЂData VaultФЃаЭЁЂAnchorФЃаЭЁЃ

3.ГЃМћЫФжжНЈФЃЗНЗЈЕФНЈФЃВНжшгыбнЪО
3.1.ЗЖЪННЈФЃЃЈE-RФЃаЭЃЉ
НЋЪТЮяГщЯѓЮЊЁАЪЕЬхЁБЁЂЁАЪєадЁБЁЂЁАЙиЯЕЁБРДБэЪОЪ§ ОнЙиСЊКЭЪТЮяУшЪіЃЛЪЕЬхЃКEntityЃЌЙиЯЕЃКRelationshipЃЌетжжЖдЪ§ОнЕФГщЯѓ
НЈФЃЭЈГЃБЛГЦЮЊERЪЕЬхЙиЯЕФЃаЭ
ERФЃаЭЪЧЪ§ОнПтЩшМЦЕФРэТлЛљДЁЃЌЕБЧАМИКѕЫљгаЕФOLTPЯЕЭГ ЩшМЦЖМВЩгУERФЃаЭНЈФЃЕФЗНЪНЃЌЧвИУНЈФЃЗНЗЈашвЊТњзу3NFЁЃBill
InomЬсГіЕФЪ§ВжРэТлЃЌЭЦМіВЩгУERЙиЯЕФЃаЭНјааНЈФЃЃЌBIМмЙЙЬсГіЗжВуМмЙЙЃЌЪ§ВжЕзВуodsЁЂdwdвВЖрВЩгУERЙиЯЕФЃаЭОЭааЩшМЦЁЃ
ЕЋЪЧ ж№НЅЫцзХЦѓвЕЪ§ОнЕФИпдіГЄЃЌИДдгЛЏЃЌЪ§ВжШЋВПЪЙгУERФЃаЭНЈФЃ ЯдЕУдНРДдНВЛКЯЪБвЫЁЃЮЊЪВУДФиЃЌвђЮЊЦфАДВПОЭАрЕФВНжшЃЌШ§ЗЖЪНЕШЃЌВЛЪЪКЯЯжДњЛЏИДдгЃЌЖрБфЕФвЕЮёзщжЏЁЃ
E-RФЃаЭНЈФЃЕФВНжшЃЈТњзу3NFЃЉШчЯТЃК
1.ГщЯѓГіжїЬх (НЬЪІЃЌПЮГЬ)
2.ЪсРэжїЬхжЎМфЕФЙиЯЕ ЃЈвЛИіРЯЪІПЩвдНЬЖрУХПЮЃЌвЛУХПЮПЩвдБЛЖрИіРЯЪІНЬЃЉ
3.ЪсРэжїЬхЕФЪєад ЃЈНЬЪІЃКНЬЪІУћГЦЃЌадБ№ЃЌбЇРњЕШЃЉ
4.ЛГіE-RЙиЯЕЭМ

3.2.ЮЌЖШНЈФЃ
ЮЌЖШНЈФЃЃЌЪЧЪ§ОнВжПтДѓЪІRalph KimballЬсГіЕФЃЌЪЧЪ§ОнВжПтЙЄГЬСьгђзюСїааЕФЪ§ВжНЈФЃОЕфЁЃ
ЮЌЖШНЈФЃвдЗжЮіОіВпЕФашЧѓГіЗЂЙЙНЈФЃаЭЃЌЙЙНЈЕФЪ§ОнФЃаЭЮЊЗжЮіашЧѓЗўЮёЃЌвђДЫЫќжиЕуНтОігУЛЇШчКЮИќПьЫйЭъГЩЗжЮіашЧѓЃЌЭЌЪБЛЙгаНЯКУЕФДѓЙцФЃИДдгВщбЏЕФЯьгІадФмЁЃЮЌЖШНЈФЃЪЧУцЯђЗжЮіЕФЃЌЮЊСЫЬсИпВщбЏадФмПЩвддіМгЪ§ОнШпгрЃЌЗДЙцЗЖЛЏЕФЩшМЦММЪѕЁЃ
Ralph KimballЬсГіЖдЪ§ОнВжПтЮЌЖШНЈФЃЃЌВЂЧвНЋЪ§ОнВжПтжаЕФБэЛЎЗжЮЊЪТЪЕБэЁЂЮЌЖШБэСНжжРраЭЁЃ
3.2.1.ЪТЪЕБэ
дкERФЃаЭжаГщЯѓГіСЫгаЪЕЬхЁЂЙиЯЕЁЂЪєадШ§жжРрБ№ЃЌдкЯжЪЕЪРНчжаЃЌУПвЛИіВйзїаЭЪТМўЃЌЛљБОЖМЪЧЗЂЩњдкЪЕЬхжЎМфЕФЃЌАщЫцзХетжжВйзїЪТМўЕФЗЂЩњЃЌЛсВњЩњПЩЖШСПЕФжЕЃЌЖјетИіЙ§ГЬОЭВњЩњСЫвЛИіЪТЪЕБэЃЌДцДЂСЫУПвЛИіПЩЖШСПЕФЪТМўЁЃ
вдЕчЩЬаавЕЮЊР§ЃКЕчЩЬГЁОАЃКвЛДЮЙКТђЪТМўЃЌЩцМАжїЬхАќРЈПЭЛЇЁЂЩЬЦЗЁЂЩЬМвЃЌВњЩњЕФПЩЖШСПжЕ АќРЈЩЬЦЗЪ§СПЁЂН№ЖюЁЂМўЪ§ЕШ

ЪТЪЕБэИљОнСЃЖШЕФНЧЩЋЛЎЗжВЛЭЌЃЌПЩЗжЮЊЪТЮёЪТЪЕБэЁЂжмЦкПьееЪТЪЕБэЁЂРлЛ§ПьееЪТЪЕБэЁЃзЂвтЃКетРяашвЊжЕЕУзЂвтЕФЪЧЃЌдкЪТЪЕБэЕФЩшМЦЪБЃЌвЛЖЈвЊзЂвтвЛИіЪТЪЕБэжЛФмгавЛИіСЃЖШЃЌВЛФмНЋВЛЭЌСЃЖШЕФЪТЪЕНЈСЂдкЭЌвЛеХЪТЪЕБэжаЁЃ
ЪТЮёЪТЪЕБэЃЌгУгкГадиЪТЮёЪ§ОнЃЌЭЈГЃСЃЖШБШНЯЕЭЃЌЫќЪЧУцЯђЪТЮёЕФЃЌЦфСЃЖШЪЧУПвЛааЖдгІвЛИіЪТЮёЃЌЫќЪЧзюЯИСЃЖШЕФЪТЪЕБэЃЌР§ШчВњЦЗНЛвзЪТЮёЪТЪЕЁЂATMНЛвзЪТЮёЪТЪЕЁЃ
жмЦкПьееЪТЪЕБэЃЌАДеевЛЖЈЕФЪБМфжмЦкМфИє(УПЬьЃЌУПдТ)РДВЖзНвЕЮёЛюЖЏЕФжДааЧщПіЃЌвЛЕЉзАШыЪТЪЕБэОЭВЛЛсдйШЅИќаТЃЌЫќЪЧЪТЮёЪТЪЕБэЕФВЙГфЁЃгУРДМЧТМгаЙцТЩЕФЁЂЙЬЖЈЪБМфМфИєЕФвЕЮёРлМЦЪ§ОнЃЌЭЈГЃСЃЖШБШНЯИпЃЌР§ШчеЫЛЇдТЦНОљгрЖюЪТЪЕБэЁЃ
РлЛ§ПьееЪТЪЕБэЃЌгУРДМЧТМОпгаЪБМфПчЖШЕФвЕЮёДІРэЙ§ГЬЕФећИіЙ§ГЬЕФаХЯЂЃЌУПИіЩњУќжмЦквЛааЃЌЭЈГЃетРрЪТЪЕБэБШНЯЩйМћЁЃ
3.2.2.ЮЌЖШБэ
ЮЌЖШЃЌЙЫУћЫМвхЃЌвЕЮёЙ§ГЬЕФЗЂЩњЛђЗжЮіНЧЖШЁЃБШШчДгбеЩЋЁЂГпДчЕФНЧЖШРДБШНЯЪжЛњЕФЭтЙлЃЌДгcpuЁЂФкДцЕШНЯБШБШНЯЪжЛњадФмЮЌЁЃЮЌЖШБэвЛАуЮЊЕЅвЛжїМќЃЌдкERФЃаЭжаЃЌЪЕЬхЮЊПЭЙлДцдкЕФЪТЮяЃЌЛсДјгаздМКЕФ
УшЪіадЪєадЃЌЪєадвЛАуЮЊЮФБОадЁЂУшЪіадЕФЃЌетаЉУшЪіБЛГЦЮЊЮЌЖШЁЃ
БШШчЩЬЦЗЃЌЕЅвЛжїМќЃКЩЬЦЗIDЃЌЪєадАќРЈВњЕиЁЂбеЩЋЁЂВФжЪЁЂГпДчЁЂЕЅМлЕШЃЌ ЕЋВЂЗЧЪєадвЛЖЈЪЧЮФБОЃЌБШШчЕЅМлЁЂГпДчЃЌОљЮЊЪ§жЕаЭУшЪіадЕФЃЌШеГЃжївЊЕФЮЌЖШГщЯѓАќРЈЃКЪБМфЮЌЖШБэЁЂЕиРэЧјгђЮЌЖШБэЕШ
АИР§ЃКФГЕчЩЬЦНЬЈЃЌОГЃашвЊЖдЖЉЕЅНјааЗжЮіЃЌвдФГБІЕФЙКЮяЖЉЕЅЮЊР§ЃЌвдЮЌЖШНЈ ФЃЕФЗНЪНЩшМЦИУФЃаЭ
ЩцМАЕНЪТЪЕБэЮЊЖЉЕЅБэЁЂЖЉЕЅУїЯИБэЃЌЮЌЖШАќРЈЩЬЦЗЮЌЖШЁЂгУЛЇЮЌЖШЁЂЩЬМвЮЌЖШЁЂЧјгђЮЌ ЖШЁЂЪБМфЮЌЖШ
ЩЬЦЗЮЌЖШЃКЩЬЦЗIDЁЂЩЬЦЗУћГЦЁЂЩЬЦЗжжРрЁЂЕЅМлЁЂВњЕиЕШ
гУЛЇЮЌЖШЃКгУЛЇIDЁЂаеУћЁЂадБ№ЁЂФъСфЁЂГЃзЁЕиЁЂжАвЕЁЂбЇРњЕШ
ЪБМфЮЌЖШЃКШеЦкIDЁЂШеЦкЁЂжмМИЁЂЩЯ/жа/ЯТбЎЁЂЪЧЗёжмФЉЁЂЪЧЗёМйЦкЕШ

ЮЌЖШЗжЮЊЃК
ЃЈ1ЃЉЭЫЛЏЮЌЖШЃЈDegenerateDimensionЃЉ
дкЮЌЖШРраЭжаЃЌгавЛжжживЊЕФЮЌЖШГЦзїЮЊЭЫЛЏЮЌЖШЃЌврЮЌЖШЭЫЛЏвЛЫЕЁЃетжжЮЌЖШжИЕФЪЧжБНгАбвЛаЉМђЕЅЕФЮЌЖШЗХдкЪТЪЕБэжаЁЃЭЫЛЏЮЌЖШЪЧЮЌЖШНЈФЃСьгђжаЕФвЛИіЗЧГЃживЊЕФИХФюЃЌЫќЖдРэНтЮЌЖШНЈФЃгазХЗЧГЃживЊЕФзїгУЃЌЭЫЛЏЮЌЖШвЛАудкЗжЮіжаПЩвдгУРДзіЗжзщЪЙгУЁЃ
ЃЈ2ЃЉЛКТ§БфЛЏЮЌЃЈSlowly Changing DimensionsЃЉ
ЮЌЖШЕФЪєадВЂВЛЪЧЪМжеВЛБфЕФЃЌЫќЛсЫцзХЪБМфЕФСїЪХЗЂЩњЛКТ§ЕФБфЛЏЃЌетжжЫцЪБМфЗЂЩњБфЛЏЕФЮЌЖШЮвУЧвЛАуГЦжЎЮЊЛКТ§БфЛЏЮЌЃЈSCDЃЉЁЃБШШчдБЙЄБэжаЕФВПУХЮЌЖШЃЌдБЙЄЕФЫљдкВПУХгаПЩФмСНФъКѓЕїећвЛДЮЁЃ
3.2.3.ЮЌЖШНЈФЃФЃаЭЕФЗжРр
ЮЌЖШНЈФЃАДЪ§ОнзщжЏРраЭЛЎЗжПЩЗжЮЊаЧаЭФЃаЭЁЂбЉЛЈФЃаЭЁЂаЧзљФЃаЭЁЃ
ЃЈ1ЃЉ аЧаЭФЃаЭ
аЧаЭФЃаЭжївЊЪЧЮЌБэКЭЪТЪЕБэЃЌвдЪТЪЕБэЮЊжааФЃЌЫљгаЮЌЖШжБНгЙиСЊдкЪТЪЕБэЩЯЃЌГЪаЧаЭЗжВМЁЃ

ЃЈ2ЃЉбЉЛЈФЃаЭ
бЉЛЈФЃаЭЃЌдкаЧаЭФЃаЭЕФЛљДЁЩЯЃЌЮЌЖШБэЩЯгжЙиСЊСЫЦфЫћЮЌЖШБэЁЃетжжФЃаЭЮЌЛЄГЩБОИпЃЌадФмЗНУцвВНЯВюЃЌЫљвдвЛАуВЛНЈвщЪЙгУЁЃгШЦфЪЧЛљгкhadoopЬхЯЕЙЙНЈЪ§ВжЃЌМѕЩйjoinОЭЪЧМѕЩйshuffleЃЌадФмВюОрЛсКмДѓЁЃ

МтНаЬсЪОЃКЫљвдгЩЩЯПЩвдПДГі
аЧаЭФЃаЭКЭбЉЛЈФЃаЭжївЊЧјБ№ОЭЪЧЖдЮЌЖШБэЕФВ№Зж
ЖдгкбЉЛЈФЃаЭЃЌЮЌЖШБэЕФЩцМАИќМгЙцЗЖЃЌвЛАуЗћКЯ3NFЃЌгааЇНЕЕЭЪ§ОнШпгрЃЌЮЌЖШБэжЎМфВЛЛсЯрЛЅЙиСЊЃЌЕЋЪЧ
ЖјаЧаЭФЃаЭЃЌвЛАуВЩгУНЕЮЌЕФВйзїЃЌЗДЙцЗЖЛЏЃЌВЛЗћКЯ3NF,РћгУШпгрРДБмУтФЃаЭЙ§гкИДдгЃЌЬсИпвзгУадКЭЗжЮіаЇТЪЃЌаЇТЪЯрЖдНЯИпЁЃ
ЃЈ3ЃЉаЧзљФЃаЭ
аЧзљФЃаЭЃЌЪЧЖдаЧаЭФЃаЭЕФРЉеЙбгЩьЃЌЖреХЪТЪЕБэЙВЯэЮЌЖШБэЁЃЪ§ВжФЃаЭНЈЩшКѓЦкЃЌДѓВПЗжЮЌЖШНЈФЃЖМЪЧаЧзљФЃаЭЁЃ
3.2.4. ЮЌЖШНЈФЃВНжш
ЮЌЖШНЈФЃВНжшЃКбЁдёвЕЮёЙ§ГЬ->ЩљУїСЃЖШ->ШЗЖЈЮЌЖШ->ШЗЖЈЪТЪЕЁЃжМдкжиЕуНтОіЪ§ОнСЃЖШЁЂЮЌЖШЩшМЦКЭЪТЪЕБэЩшМЦЮЪЬтЁЃ
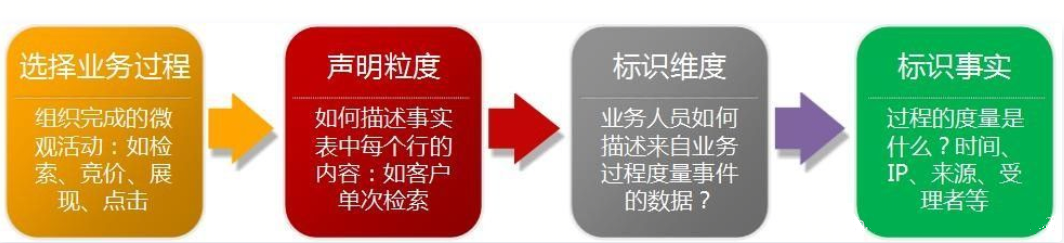
ЩљУїСЃЖШЃЌЮЊвЕЮёзюаЁЛюЖЏЕЅдЊЛђВЛЭЌЮЌЖШзщКЯЁЃвдЙВЭЌСЃЖШДгЖрИізщжЏвЕЮёЙ§ГЬКЯВЂЖШСПЕФЪТЪЕБэГЦЮЊКЯВЂЪТЪЕБэЃЌашвЊзЂвтЕФЪЧЃЌРДздЖрИівЕЮёЙ§ГЬЕФЪТЪЕКЯВЂЕНКЯВЂЪТЪЕБэЪБЃЌЫќУЧБиаыОпгаЭЌбљЕШМЖЕФСЃЖШЁЃ
3.3 DataVaultФЃаЭ
Data VaultЪЧDan LinstedtЗЂЦ№ДДНЈЕФвЛжжФЃаЭЗНЗЈТлЃЌData VaultЪЧдкERФЃаЭЕФЛљДЁЩЯбмЩњЖјРДЃЌФЃаЭЩшМЦЕФГѕждЪЧгааЇЕФзщжЏЛљДЁЪ§ОнВуЃЌЪЙжЎвзРЉеЙЁЂСщЛюЕФгІЖдвЕЮёЕФБфЛЏЃЌЭЌЪБЧПЕїРњЪЗадЁЂПЩзЗЫнадКЭдзгадЃЌВЛвЊЧѓЖдЪ§ОнНјааЙ§ЖШЕФвЛжТадДІРэЁЃЭЌЪБЩшМЦЕФГіЗЂЕувВЪЧЮЊСЫЪЕЯжЪ§ОнЕФећКЯЃЌВЂЗЧЮЊЪ§ОнОіВпЗжЮіжБНгЪЙгУЁЃ
Data VaultФЃаЭЪЧвЛжжжааФЗјЩфЪНФЃаЭЃЌЦфЩшМЦжиЕуЮЇШЦзХвЕЮёМќЕФМЏГЩФЃЪНЁЃетаЉвЕЮёМќЪЧДцДЂдкЖрИіЯЕЭГжаЕФЁЂеыЖдИїжжаХЯЂЕФМќЃЌгУ
гкЖЈЮЛКЭЮЈвЛБъЪЖМЧТМЛђЪ§Он
Data VaultФЃаЭАќКЌШ§жжЛљБОНсЙЙ ЃК
жааФБэ-Hub ЃКЮЈвЛвЕЮёМќЕФСаБэЃЌЮЈвЛБъЪЖЦѓвЕЪЕМЪвЕЮёЃЌЦѓвЕЕФвЕЮёжїЬхМЏКЯ
СДНгБэ-LinkЃК БэЪОжааФБэжЎМфЕФЙиЯЕЃЌЭЈЙ§СДНгБэДЎСЊећИіЦѓвЕЕФвЕЮёЙиСЊЙиЯЕ
ЮРаЧБэ- SatelliteЃК РњЪЗЕФУшЪіадЪ§ОнЃЌЪ§ОнВжПтжаЪ§ОнЕФеце§диЬх
3.3.1 жааФБэ-Hub

3.3.2 СДНгБэ-Link

3.3.3 ЮРаЧБэ- Satellite

3.3.4 Data VaultФЃаЭНЈФЃСїГЬ
1.ЪсРэЫљгажївЊЪЕЬх
2.НЋгаШыБпЕФЪЕЬхЖЈвхЮЊжааФБэ
3.НЋУЛгаШыБпЧаНігавЛИіГіБпЕФБэЖЈвхЮЊжааФБэ
4.дДПрждУЛгаШыБпЧвгаСНЬѕЛђвдЩЯГіБпЕФБэЖЈвхЮЊСЌНгБэ
5.НЋЭтМќЙиЯЕЖЈвхЮЊСДНгБэ

МтНаЬсЪОЃКHubЯыЯёГЩШЫЬхЕФЙЧМмЃЌФЧУДLinkОЭЪЧСЌНгЙЧМмЕФШЭДјзщжЏЃЌ
ЖјsateliteОЭЪЧЙЧМмЩЯЕФбЊШтЁЃ Data VaultЪЧЖдERФЃаЭИќНќвЛВНЕФЙцЗЖЛЏЃЌгЩгкЖдЪ§ОнЕФВ№НтКЭИќЦЋЯђгкЛљДЁЪ§ОнзщжЏЃЌдкДІРэЗжЮіРрГЁОАЪБЯрЖдИДдгЃЌ
ЪЪКЯЪ§ВжЕЭВуЙЙНЈЃЌФПЧАЪЕМЪгІгУГЁОАНЯЩй
3.4AnchorФЃаЭ
AnchorЪЧЖдData VaultФЃаЭзіСЫИќНќвЛВНЕФЙцЗЖЛсДІРэЃЌГѕждЪЧЮЊСЫ ЩшМЦИпЖШПЩРЉеЙЕФФЃаЭЃЌКЫаФЫМЯыЪЧЫљгаЕФРЉеХжЛЬэМгЖјВЛаоИФЃЌгк
ЪЧЩшМЦГіЕФФЃаЭЛљБОБфГЩСЫk-vНсЙЙЕФФЃаЭЃЌФЃаЭЗЖЪНДяЕНСЫ6NF
гЩгкЙ§ЖШЙцЗЖЛЏЃЌЪЙгУжаЧЃЩцЕНЬЋЖрЕФjoinВйзїЃЌФПЧАФОгаЪЕМЪАИР§ЃЌНізїСЫНт
4.ЫФжжФЃаЭзмНс
вдЩЯЮЊЫФжжЛљБОЕФНЈФЃЗНЗЈЃЌЕБЧАжїСїНЈФЃЗНЗЈЮЊЃК ERФЃаЭЁЂЮЌЖШФЃаЭ
ERФЃаЭГЃгУгкOLTPЪ§ОнПтНЈФЃЃЌгІгУЕНЙЙНЈЪ§ВжЪБИќЦЋжиЪ§ОнећКЯЃЌ еОдкЦѓвЕећЬхПМТЧЃЌНЋИїИіЯЕЭГЕФЪ§ОнАДЯрЫЦадвЛжТадЁЂКЯВЂДІРэЃЌЮЊ
Ъ§ОнЗжЮіЁЂОіВпЗўЮёЃЌЕЋВЂВЛБугкжБНггУРДжЇГжЗжЮіЁЃШБЯнЃКашвЊШЋУцЪсРэЦѓвЕЫљгаЕФвЕЮёКЭЪ§ОнСїЃЌжмЦкГЄЃЌШЫдБвЊЧѓИпЁЃ
ЮЌЖШНЈФЃЪЧУцЯђЗжЮіГЁОАЖјЩњЃЌеыЖдЗжЮіГЁОАЙЙНЈЪ§ВжФЃаЭЃЛжиЕуЙизЂПь ЫйЁЂСщЛюЕФНтОіЗжЮіашЧѓЃЌЭЌЪБФмЙЛЬсЙЉДѓЙцФЃЪ§ОнЕФПьЫйЯьгІадФмЁЃеыЖдад
ЧПЃЌжївЊгІгУгкЪ§ОнВжПтЙЙНЈКЭOLAPв§ЧцЕЭВуЪ§ОнФЃаЭЁЃгХЕуЃКВЛашвЊЭъећЕФЪсРэЦѓвЕвЕЮёСїГЬКЭЪ§ОнЃЌЪЕЪЉжмЦкИљОнжїЬтБпНчЖјЖЈЃЌШнвзПьЫйЪЕЯжdemo
Ъ§ВжФЃаЭЕФбЁдёЪЧСщЛюЕФЃЌВЛОжЯогкФГвЛжжФЃаЭЗНЗЈ
Ъ§ВжФЃаЭЕФЩшМЦвВЪЧСщЛюЕФЃЌвдЪЕМЪашЧѓГЁОАЮЊЕМЯђ
ФЃаЭЩшМЦвЊМцЙЫСщЛюадЁЂПЩРЉеЙЃЌЖјЖджеЖЫгУЛЇЭИУїад
ФЃаЭЩшМЦвЊПМТЧММЪѕПЩППадКЭЪЕЯжГЩБО
5.ГЃгУНЈФЃЙЄОп
НЈФЃЙЄОпЃЌвЛАуЦѓвЕвдErwinЁЂpowerdesignerЁЂvisioЃЌЩѕжСExcelЕШЮЊжїЁЃвВгааЉЦѓвЕздаабаЗЂЙЄОпЃЌЛђЪЙгУАЂРяЕШГЩЪьЬззАзщМўВњЦЗЁЃ
|









