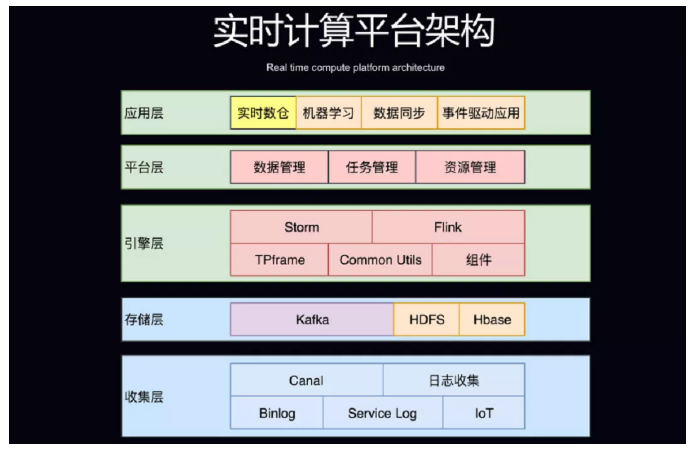
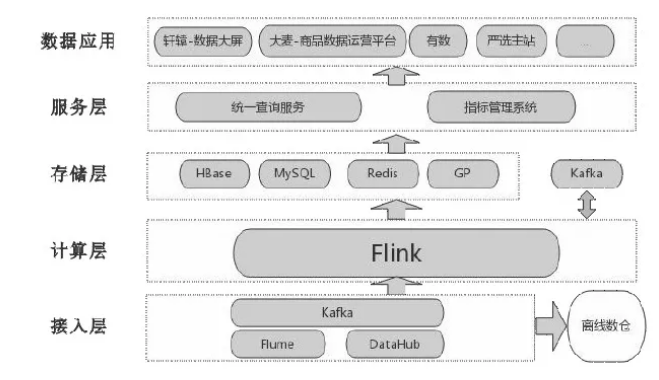
| БрМЭЦМі: |
БОЮФжївЊНВЪіУРЭХЕуЦРЛљгкFlinkЕФЪЕЪБЪ§ВжЦНЬЈЪЕМљ,ЭјвзЛљгкFlinkЕФбЯбЁЪЕЪБЪ§ВжЪЕМљ,жЊКѕЕФЪЕЪБЪ§ВжЪЕМљвдМАМмЙЙЕФбнНј,ЯЃЭћФмИјДѓМвДјРДЦєЗЂЁЃ
БОЮФРДздЩчЧјОЋбЁЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
Ъ§ОнВжПтИХФюЕФЬсГіЖМвЊзЗЫнЕНЩЯЪРМЭСЫЃЌЮвУЧШЯЮЊдкДѓЪ§ОндЊФъжЎЧАЕФЪ§ВжПЩвдГЦЮЊДЋЭГЪ§ВжЃЌЖјКѓЫцзХКЃСПЪ§ОнВЛЖЯдіГЄЃЌвдМАHadoopЩњЬЌВЛЖЯЗЂеЙЃЌжївЊЛљгкHive/HDFSЕФРыЯпЪ§ВжМмЙЙПЩвдаЫЦ№ВЂбгајжСНёЃЌНќМИФъЫцзХStorm/SparkЃЈStreamingЃЉ/FlinkЕШЪЕЪБДІРэПђМмЕФИќаТЕќДњФЫжСЯрЛЅШЁДњЃЌИїГЇЖМдкзХСІЙЙНЈздМКЕФЪЕЪБЪ§ВжЃЌЬиБ№ЪЧНќСНФъЃЌЫцзХFlinkЩљУћШЕЦ№ЃЌЪЕЪБЪ§ВжИќЪЧУћЩљдкЭтВЂЧвЛЙдкВЛЖЯПьЫйЗЂеЙЁЃ
ФПЧАДѓЖрЦѓвЕЕФЪ§ОнЬхЯЕЖМЪЧЮЇШЦЪ§ВжЕФЪ§ОнЦНЬЈМмЙЙЃЌЬиБ№ЪЧдкзХСІНЈЩшЪЕЪБЪ§ВжЃЌЛђепдкНЈЩшРыЯпЪ§ВжгыЪЕЪБЪ§ВжЯрЭГвЛЕФЪ§ВжЬхЯЕЁЃБОЮФЮвУЧОЋбЁСЫЪЕЪБЪ§ВжНЈЩшЕФЕфаЭДњБэЃЌАќРЈУРЭХЕуЦРЁЂЭјвзЁЂжЊКѕЁЂOPPOЕШМИМвЕФЪЕЪБЪ§ВжМмЙЙЃЌЫћУЧЕФЪ§ВжЪЕМљПЯЖЈЖдЮвУЧгаЫљНшМјЛђЦєЕЯЁЃБЪепетРяЬиБ№ЭЦМіВЮПМЫћУЧЕФЗжВуЩшМЦЃЌДцДЂгыМЦЫув§ЧцЕФбЁаЭЁЃ
БОЮФОйЕФЫФИіДњБэАИР§ЃК
1.УРЭХЕуЦРЛљгк Flink ЕФЪЕЪБЪ§ВжЦНЬЈЪЕМљ
2.ЭјвзЛљгкFlinkЕФбЯбЁЪЕЪБЪ§ВжЪЕМљ
3.жЊКѕЪЕЪБЪ§ВжЪЕМљМАМмЙЙбнНј
4.OPPO ЪЕЪБЪ§ВжНвУиМАРыЯпЕНЪЕЪБЕФЦНЛЌЧЈвЦ
УРЭХЕуЦРЛљгкFlinkЕФЪЕЪБЪ§ВжЦНЬЈЪЕМљ
ЪЕЪБМЦЫуЦНЬЈМмЙЙ
ЯТЭМЫљЪОЕФЪЧУРЭХЕуЦРЪЕЪБМЦЫуЦНЬЈЕФМмЙЙЁЃ
зюЕзВуЪЧЪеМЏВуЃЌетвЛВуИКд№ЪеМЏгУЛЇЕФЪЕЪБЪ§ОнЃЌАќРЈ BinlogЁЂКѓЖЫЗўЮёШежОвдМА IoT Ъ§ОнЃЌОЙ§ШежОЪеМЏЭХЖгКЭ
DB ЪеМЏЭХЖгЕФДІРэЃЌЪ§ОнНЋЛсБЛЪеМЏЕН Kafka жаЁЃетаЉЪ§ОнВЛжЛЪЧВЮгыЪЕЪБМЦЫуЃЌвВЛсВЮгыРыЯпМЦЫуЁЃ
ЪеМЏВужЎЩЯЪЧДцДЂВуЃЌетвЛВуГ§СЫЪЙгУ Kafka зіЯћЯЂЭЈЕРжЎЭтЃЌЛЙЛсЛљгк HDFS зізДЬЌЪ§ОнДцДЂвдМАЛљгк
HBase зіЮЌЖШЪ§ОнЕФДцДЂЁЃ
ДцДЂВужЎЩЯЪЧв§ЧцВуЃЌАќРЈ Storm КЭ FlinkЁЃЪЕЪБМЦЫуЦНЬЈЛсдкв§ЧцВуЮЊгУЛЇЬсЙЉвЛаЉПђМмЕФЗтзАвдМАЙЋЙВАќКЭзщМўЕФжЇГжЁЃ
дкв§ЧцВужЎЩЯОЭЪЧЦНЬЈВуСЫЃЌЦНЬЈВуДгЪ§ОнЁЂШЮЮёКЭзЪдДШ§ИіЪгНЧШЅЙмРэЁЃ
МмЙЙЕФзюЩЯВуЪЧгІгУВуЃЌАќРЈСЫЪЕЪБЪ§ВжЁЂЛњЦїбЇЯАЁЂЪ§ОнЭЌВНвдМАЪТМўЧ§ЖЏгІгУЕШЁЃ
ДгЙІФмНЧЖШРДПДЃЌУРЭХЕуЦРЕФЪЕЪБМЦЫуЦНЬЈжївЊАќРЈзївЕКЭзЪдДЙмРэСНИіЗНУцЕФЙІФмЁЃЦфжаЃЌзївЕВПЗжАќРЈзївЕХфжУЁЂзївЕЗЂВМвдМАзївЕзДЬЌШ§ИіЗНУцЕФЙІФмЁЃ
дкзївЕХфжУЗНУцЃЌдђАќРЈзївЕЩшжУЁЂдЫааЪБЩшжУвдМАЭиЦЫНсЙЙЩшжУЃЛ
дкзївЕЗЂВМЗНУцЃЌдђАќРЈАцБОЙмРэЁЂБрвы/ЗЂВМ/ЛиЙіЕШЃЛ
зївЕзДЬЌдђАќРЈдЫааЪБзДЬЌЁЂздЖЈвхжИБъКЭБЈОЏвдМАУќСю/дЫааЪБШежОЕШЁЃ
дкзЪдДЙмРэЗНУцЃЌдђЮЊгУЛЇЬсЙЉСЫЖрзтЛЇзЪдДИєРывдМАзЪдДНЛИЖКЭВПЪ№ЕФФмСІЁЃ
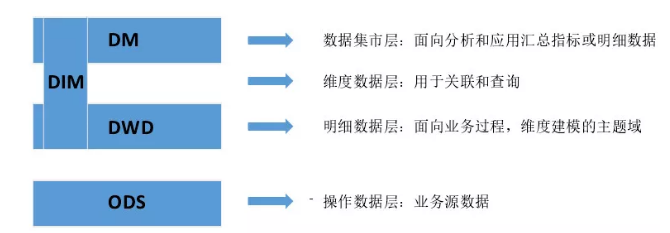
ДЋЭГЪ§ВжФЃаЭ
ЮЊСЫИќгааЇЕизщжЏКЭЙмРэЪ§ОнЃЌЪ§ВжНЈЩшЭљЭљЛсНјааЪ§ОнЗжВуЃЌвЛАуздЯТЖјЩЯЗжЮЊЫФВуЃКODSЃЈВйзїЪ§ОнВуЃЉЁЂDWDЃЈЪ§ОнУїЯИВуЃЉЁЂDWSЃЈЛузмВуЃЉКЭгІгУВуЁЃМДЪБВщбЏжївЊЭЈЙ§
PrestoЁЂHive КЭ Spark ЪЕЯжЁЃ
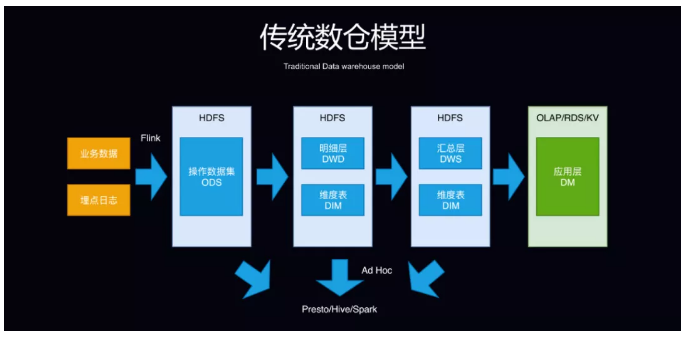
ЪЕЪБЪ§ВжФЃаЭ
ЪЕЪБЪ§ВжЕФЗжВуЗНЪНвЛАувВзёЪиДЋЭГЪ§ОнВжПтФЃаЭЃЌвВЗжЮЊСЫ ODS ВйзїЪ§ОнМЏЁЂDWD УїЯИВуКЭ DWS
ЛузмВувдМАгІгУВуЁЃЕЋЪЕЪБЪ§ВжФЃаЭЕФДІРэЕФЗНЪНШДКЭДЋЭГЪ§ВжгаЫљВюБ№ЃЌШчУїЯИВуКЭЛузмВуЕФЪ§ОнвЛАуЛсЗХдк
Kafka ЩЯЃЌЮЌЖШЪ§ОнвЛАуПМТЧЕНадФмЮЪЬтдђЛсЗХдк HBase Лђеп Tair ЕШ KV ДцДЂЩЯЃЌМДЯЏВщбЏдђПЩвдЪЙгУ
Flink ЭъГЩЁЃ
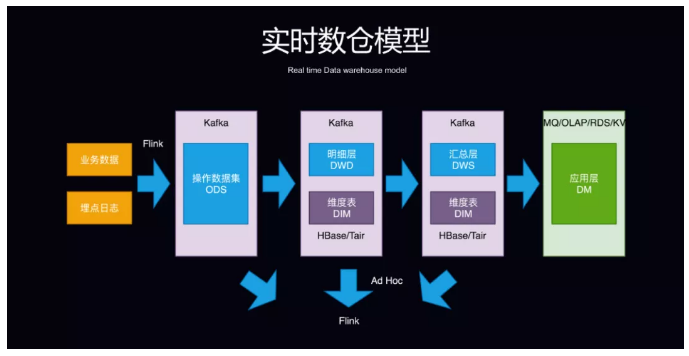
зМЪЕЪБЪ§ВжФЃаЭ
дквдЩЯСНжжЪ§ВжФЃаЭжЎЭтЃЌЮвУЧЗЂЯжвЕЮёЗНдкЪЕМљЙ§ГЬжаЛЙгавЛжжзМЪЕЪБЪ§ВжФЃаЭЃЌЦфЬиЕуЪЧВЛЭъШЋЛљгкСїШЅзіЃЌЖјЪЧНЋУїЯИВуЪ§ОнЕМШыЕН
OLAP ДцДЂжаЃЌЛљгк OLAP ЕФМЦЫуФмСІШЅзіЛузмВЂНјааНјвЛВНЕФМгЙЄЁЃ
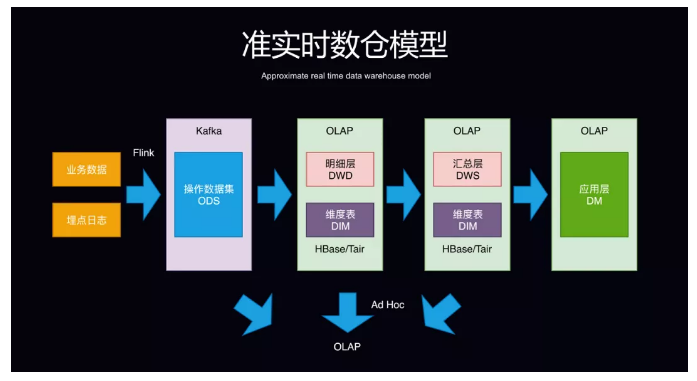
ЪЕЪБЪ§ВжКЭДЋЭГЪ§ВжЕФЖдБШжївЊПЩвдДгЫФИіЗНУцПМТЧЃК
ЕквЛИіЪЧЗжВуЗНЪНЃЌРыЯпЪ§ВжЮЊСЫПМТЧЕНаЇТЪЮЪЬтЃЌвЛАуЛсВЩШЁПеМфЛЛЪБМфЕФЗНЪНЃЌВуМЖЛЎЗжЛсБШНЯЖрЃЛдђЪЕЪБЪ§ВжПМТЧЕНЪЕЪБадЮЪЬтЃЌвЛАуЗжВуЛсБШНЯЩйЃЌСэЭтвВМѕЩйСЫжаМфСїГЬГіДэЕФПЩФмадЁЃ
ЕкЖўИіЪЧЪТЪЕЪ§ОнДцДЂЗНУцЃЌРыЯпЪ§ВжЛсЛљгк HDFSЃЌЪЕЪБЪ§ВждђЛсЛљгкЯћЯЂЖгСаЃЈШч KafkaЃЉЁЃ
ЕкШ§ИіЪЧЮЌЖШЪ§ОнДцДЂЃЌЪЕЪБЪ§ВжЛсНЋЪ§ОнЗХдк KV ДцДЂЩЯУцЁЃ
ЕкЫФИіЪЧЪ§ОнМгЙЄЙ§ГЬЃЌРыЯпЪ§ВжвЛАувд HiveЁЂSpark ЕШХњДІРэЮЊжїЃЌЖјЪЕЪБЪ§ВждђЪЧЛљгкЪЕЪБМЦЫув§ЧцШч
StormЁЂFlink ЕШЃЌвдСїДІРэЮЊжїЁЃ
ЭјвзЛљгкFlinkЕФбЯбЁЪЕЪБЪ§ВжЪЕМљ
ећЬхМмЙЙ
ЪЕЪБЪ§ВжећЬхПђМмвРОнЪ§ОнЕФСїЯђЗжЮЊВЛЭЌЕФВуДЮЃЌНгШыВуЛсвРОнИїжжЪ§ОнНгШыЙЄОпЪеМЏИїИівЕЮёЯЕЭГЕФЪ§ОнЃЌШчТђЕуЕФвЕЮёЪ§ОнЛђепвЕЮёКѓЬЈЕФВЂЙКЗХЕНЯћЯЂЖгСаРяУцЁЃЯћЯЂЖгСаЕФЪ§ОнМШЪЧРыЯпЪ§ВжЕФдЪМЪ§ОнЃЌвВЪЧЪЕЪБМЦЫуЕФдЪМЪ§ОнЃЌетбљПЩвдБЃжЄЪЕЪБКЭРыЯпЕФдЪМЪ§ОнЪЧЭГвЛЕФЁЃгаСЫдДЪ§ОнЃЌдкМЦЫуВуОЙ§FLink+ЪЕЪБМЦЫув§ЧцзівЛаЉМгЙЄДІРэЃЌШЛКѓТфЕиЕНДцДЂВужаВЛЭЌДцДЂНщжЪЕБжаЁЃВЛЭЌЕФДцДЂНщжЪЪЧвРОнВЛЭЌЕФгІгУГЁОАРДбЁдёЁЃПђМмжаЛЙгаFLinkКЭKafkaЕФНЛЛЅЃЌдкЪ§ОнЩЯНјаавЛИіЗжВуЩшМЦЃЌМЦЫув§ЧцДгKafkaжаРЬШЁЪ§ОнзівЛаЉМгЙЄШЛКѓЗХЛиKafkaЁЃдкДцДЂВуМгЙЄКУЕФЪ§ОнЛсЭЈЙ§ЗўЮёВуЕФСНИіЗўЮёЃКЭГвЛВщбЏЁЂжИБъЙмРэЃЌЭГвЛВщбЏЪЧЭЈЙ§вЕЮёЗНЕїШЁЪ§ОнНгПкЕФвЛИіЗўЮёЃЌжИБъЙмРэЪЧЖдЪ§ОнжИБъЕФЖЈвхКЭЙмРэЙЄзїЁЃЭЈЙ§ЗўЮёВугІгУЕНВЛЭЌЕФЪ§ОнгІгУЃЌЪ§ОнгІгУПЩФмЪЧЮвУЧЕФе§ЪНВњЦЗЛђепжБНгЕФвЕЮёЯЕЭГЁЃКѓУцЛсДгЪ§ОнЕФЗжВуЩшМЦКЭОпЬхЕФЪЕЯжСНИіЗНУцНщЩмЁЃ
ећЬхЩшМЦ
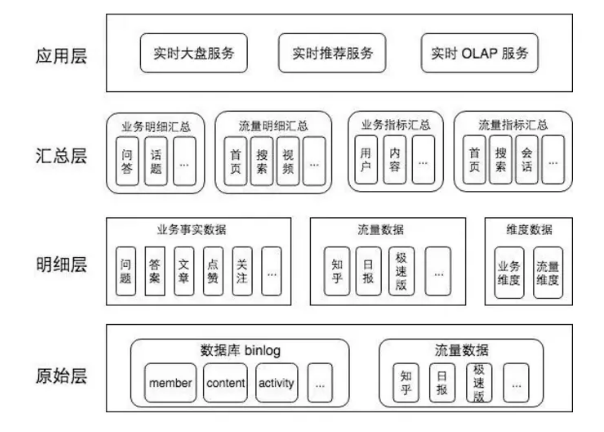
ЩЯУцЪЧЖдЪ§ОнЕФећЬхЩшМЦЃЌжївЊВЮПМСЫРыЯпЪ§ВжЕФЩшМЦЗНАИЃЌвВВЮПМСЫвЕНчЭЌааЕФвЛаЉзіЗЈЁЃНЋЪ§ОнЗжЮЊЫФИіВуДЮЃК
ЪзЯШЪЧODSВуЃЌМДВйзїЪ§ОнВуЃЌЭЈЙ§Ъ§ОнВЩМЏЙЄОпЪеМЏИїИівЕЮёдДЪ§ОнЃЛDWDВуЃЌУїЯИЪ§ОнВуЪЧАДжїЬтгђРДЛЎЗжЃЌЭЈЙ§ЮЌЖШНЈФЃЗНЪНРДзщжЏИїИівЕЮёЙ§ГЬЕФУїЯИЪ§ОнЁЃжаМфЛсгавЛИіDIMВуЃЌЮЌЖШЪ§ОнВужївЊзівЛаЉВщбЏКЭЙиСЊЕФВйзїЁЃзюЩЯВуЪЧDMВуЃЌЭЈЙ§DWDВуЪ§ОнзівЛаЉжИБъМгЙЄЃЌжївЊУцЯђвЛаЉЗжЮіКЭгІгУЛузмЕФжИБъЛђепЪЧзіЖрЮЌЗжЮіЕФУїЯИЪ§ОнЁЃ
ММЪѕЪЕЯж
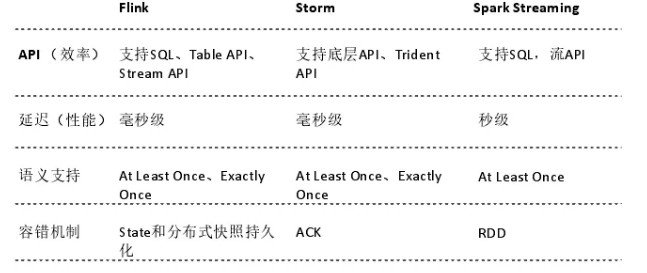
ШЛКѓНщЩмЯТММЪѕЪЕЯжЗНУцЕФПМСПЃЌжївЊЗжЮЊМЦЫуКЭДцДЂЁЃЖдгкМЦЫуЗНУцЃЌгаКмЖрЪЕЪБМЦЫув§ЧцЃЌгаFlinkЁЂStormЁЂSpark
StreamingЃЌFlinkЯрЖдгкStormЕФгХЪЦОЭЪЧжЇГжSQLЃЌЯрЖдгкSpark StreamingгжгавЛИіЯрЖдКУЕФадФмБэЯжЁЃЭЌЪБFlinkдкжЇГжКУЕФгІгУКЭадФмЗНУцЛЙгаБШНЯКУЕФгявхжЇГжКЭБШНЯКУЕФШнДэЛњжЦЃЌвђДЫЙЙНЈЪЕЪБЪ§ВжFlinkЪЧвЛИіБШНЯКУЕФЪЕЪБМЦЫув§ЧцбЁдёЁЃ
ММЪѕЪЕЯжжаFlinkЕФОпЬхзїгУЃК
FlinkзїЮЊЪЕЪБЕФМЦЫув§ЧцЃЌВЛЭЌЕФЪ§ОнВуЃЈods->dwd->dmЃЉжЎМфЃЌВЛЭЌЕФДцДЂв§ЧцЃЈkafka->dbЃЉЖМЪЧЭЈЙ§Flink
jobДЎСЊЕФЃЌЯрЙиЕФetlКЭЙиСЊЁЂОлКЯЕШВйзївВЪЧдкFlinkжаЭъГЩЁЃ
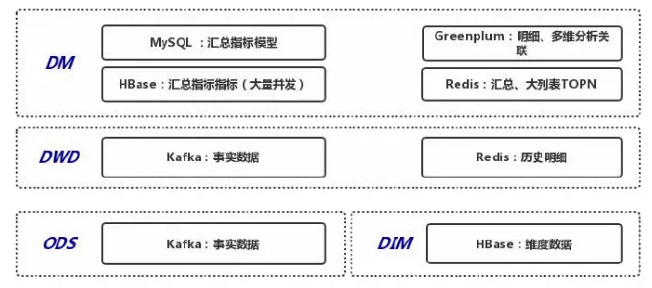
ЖдгкДцДЂВуЛсвРОнВЛЭЌЕФЪ§ОнВуЕФЬиЕубЁдёВЛЭЌЕФДцДЂНщжЪЃЌODSВуКЭDWDВуЖМЪЧДцДЂЕФвЛаЉЪЕЪБЪ§ОнЃЌбЁдёЕФЪЧKafkaНјааДцДЂЃЌдкDWDВуЛсЙиСЊвЛаЉРњЪЗУїЯИЪ§ОнЃЌЛсНЋЦфЗХЕНRedisРяУцЁЃдкDIMВужївЊзівЛаЉИпВЂЗЂЮЌЖШЕФВщбЏЙиСЊЃЌвЛАуНЋЦфДцЗХдкHBaseРяУцЃЌЖдгкDIMВуБШМлИДдгЃЌашвЊзлКЯПМТЧЖдгкЪ§ОнТфЕиЕФвЊЧѓвдМАОпЬхЕФВщбЏв§ЧцРДбЁдёВЛЭЌЕФДцДЂЗНЪНЁЃЖдгкГЃМћЕФжИБъЛузмФЃаЭжБНгЗХдкMySQLРяУцЃЌЮЌЖШБШНЯЖрЕФЁЂаДШыИќаТБШНЯДѓЕФФЃаЭЛсЗХдкHBaseРяУцЃЌЛЙгаУїЯИЪ§ОнашвЊзівЛаЉЖрЮЌЗжЮіЛђепЙиСЊЛсНЋЦфДцДЂдкGreenplumРяУцЃЌЛЙгавЛжжЪЧЮЌЖШБШНЯЖрЁЂашвЊзіХХађЁЂВщбЏвЊЧѓБШНЯИпЕФЃЌШчЛюЖЏЦкМфгУЛЇЕФЯњЪлСаБэЕШДѓСаБэжБНгДцДЂдкRedisРяУцЁЃ
жЊКѕЪЕЪБЪ§ВжМмЙЙЪЕМљгыбнНј
БОЮФжївЊНВЪіжЊКѕЕФЪЕЪБЪ§ВжЪЕМљвдМАМмЙЙЕФбнНјЃЌетАќРЈвдЯТМИИіЗНУцЃК
ЪЕЪБЪ§Вж 1.0 АцБОЃЌжїЬтЃКETL ТпМЪЕЪБЛЏЃЌММЪѕЗНАИЃКSpark StreamingЁЃ
ЪЕЪБЪ§Вж 2.0 АцБОЃЌжїЬтЃКЪ§ОнЗжВуЃЌжИБъМЦЫуЪЕЪБЛЏЃЌММЪѕЗНАИЃКFlink StreamingЁЃ
ЪЕЪБЪ§ВжЮДРДеЙЭћЃКStreaming SQL ЦНЬЈЛЏЃЌдЊаХЯЂЙмРэЯЕЭГЛЏЃЌНсЙћбщЪездЖЏЛЏЁЃ
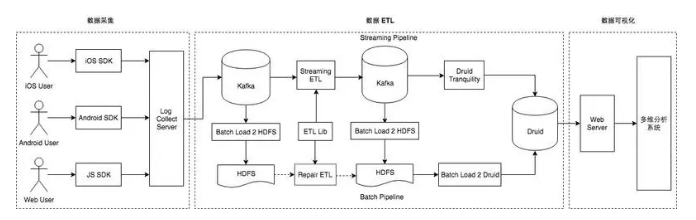
ЪЕЪБЪ§Вж 1.0
ЕквЛВПЗжЪЧЪ§ОнВЩМЏЃЌгЩШ§ЖЫ SDK ВЩМЏЪ§ОнВЂЭЈЙ§ Log Collector Server ЗЂЫЭЕН
KafkaЁЃЕкЖўВПЗжЪЧЪ§Он ETLЃЌбЁдёСЫ Spark Streaming зїЮЊЪЕЪБЪ§ОнЕФДІРэПђМмЃЌжївЊЭъГЩЖддЪМЪ§ОнЕФЧхЯДКЭМгЙЄВЂЗжЪЕЪБКЭРыЯпЕМШы
DruidЁЃЕкШ§ВПЗжЪЧЪ§ОнПЩЪгЛЏЃЌгЩ Druid ИКд№МЦЫужИБъВЂЭЈЙ§ Web Server ХфКЯЧАЖЫЭъГЩЪ§ОнПЩЪгЛЏЁЃ
1.0 АцБОЕФЪЕЪБЪ§ВжгавдЯТМИИіВЛзуЃК
ЫљгаЕФСїСПЪ§ОнДцЗХдкЭЌвЛИі Kafka Topic жаЃЌШчЙћЯТгЮУПИівЕЮёЯпЖМвЊЯћЗбЃЌетЛсЕМжТШЋСПЪ§ОнБЛЯћЗбЖрДЮЃЌKafka
ГіСїСПЬЋИпЮоЗЈТњзуИУашЧѓЁЃ
ЫљгаЕФжИБъМЦЫуШЋВПгЩ Druid ГаЕЃЃЌDruid ЭЌЪБМцЙЫЪЕЪБЪ§ОндДКЭРыЯпЪ§ОндДЕФВщбЏЃЌЫцзХЪ§ОнСПЕФБЉеЧ
Druid ЮШЖЈадМБОчЯТНЕЃЌетЕМжТИїИівЕЮёЕФКЫаФБЈБэВЛФмЮШЖЈВњГіЁЃ
гЩгкУПИівЕЮёЪЙгУЭЌвЛИіСїСПЪ§ОндДХфжУБЈБэЃЌЕМжТВщбЏаЇТЪЕЭЯТЃЌЭЌЪБЮоЗЈЖдвЕЮёзіЪ§ОнИєРыКЭГЩБОМЦЫуЁЃ
ЫцзХЪ§ОнСПЕФБЉеЧЃЌDruid жаЕФСїСПЪ§ОндДОГЃВщбЏГЌЪБЭЌЪБИївЕЮёЯћЗбЪЕЪБЪ§ОнЕФашЧѓвВПЊЪМдіЖрЃЌШчЙћМЬајбигУЪЕЪБЪ§Вж
1.0 МмЙЙЃЌашвЊИЖГіДѓСПЕФЖюЭтГЩБОЁЃгкЪЧЃЌдкЪЕЪБЪ§Вж 1.0 ЕФЛљДЁЩЯЃЌЮвУЧНЈСЂЦ№СЫЪЕЪБЪ§Вж 2.0ЃЌЪсРэГіСЫаТЕФМмЙЙЩшМЦВЂПЊЪМзХЪжНЈСЂЪЕЪБЪ§ВжЬхЯЕЃЌаТЕФМмЙЙШчЯТЭМЫљЪОЁЃ
ЯрБШЪЕЪБЪ§Вж 1.0 вд Spark Streaming зїЮЊжївЊЪЕЯжММЪѕЃЌдкЪЕЪБЪ§Вж 2.0 жаЃЌЮвУЧНЋ
Flink зїЮЊжИБъЛузмВуЕФжївЊМЦЫуПђМмЁЃFlink ЯрБШ Spark Streaming гаИќУїЯдЕФгХЪЦЃЌжївЊЬхЯждкЃКЕЭбгГйЁЂExactly-once
гявхжЇГжЁЂStreaming SQL жЇГжЁЂзДЬЌЙмРэЁЂЗсИЛЕФЪБМфРраЭКЭДАПкМЦЫуЁЂCEP жЇГжЕШЁЃ
ДгЪЕЪБЪ§Вж 1.0 ЕН 2.0ЃЌВЛЙмЪЧЪ§ОнМмЙЙЛЙЪЧММЪѕЗНАИЃЌЮвУЧдкЩюЖШКЭЙуЖШЩЯЖМгаСЫИќЖрЕФЛ§РлЁЃЫцзХЙЋЫОвЕЮёЕФПьЫйЗЂеЙвдМАаТММЪѕЕФЕЎЩњЃЌЪЕЪБЪ§ВжвВЛсВЛЖЯЕФЕќДњгХЛЏЁЃЖЬЦкПЩдЄМћЕФЮвУЧЛсДгвдЯТЗНУцНјвЛВНЬсЩ§ЪЕЪБЪ§ВжЕФЗўЮёФмСІЃК
Streaming SQL ЦНЬЈЛЏЁЃФПЧА Streaming SQL ШЮЮёЪЧвдДњТыПЊЗЂ maven
ДђАќЕФЗНЪНЬсНЛШЮЮёЃЌПЊЗЂГЩБОИпЃЌКѓЦкЫцзХ Streaming SQL ЦНЬЈЕФЩЯЯпЃЌЪЕЪБЪ§ВжЕФПЊЗЂЗНЪНвВЛсгЩ
Jar АќзЊБфЮЊ SQL ЮФМўЁЃ
ЪЕЪБЪ§ОндЊаХЯЂЙмРэЯЕЭГЛЏЁЃЖдЪ§ВждЊаХЯЂЕФЙмРэПЩвдДѓЗљЖШНЕЕЭЪЙгУЪ§ОнЕФГЩБОЃЌРыЯпЪ§ВжЕФдЊаХЯЂЙмРэвбОЛљБОЭъЩЦЃЌЪЕЪБЪ§ВжЕФдЊаХЯЂЙмРэВХИеИеПЊЪМЁЃ
ЪЕЪБЪ§ВжНсЙћбщЪездЖЏЛЏЁЃЖдЪЕЪБНсЙћЕФбщЪежЛФмНшжњгыРыЯпЪ§ОнжИБъЖдБШЕФЗНЪНЃЌвд
Hive КЭ Kafka Ъ§ОндДЮЊР§ЃЌЗжБ№жДаа Hive SQL КЭ Flink SQLЃЌЭГМЦНсЙћВЂЖдБШЪЧЗёвЛжТЪЕЯжЪЕЪБНсЙћбщЪеЕФздЖЏЛЏЁЃ
OPPO ЪЕЪБЪ§ВжНвУиЃКДгЖЅВуЩшМЦЪЕЯжРыЯпгыЪЕЪБЕФЦНЛЌЧЈвЦ
вдЪ§ВжЮЊжааФЕФЪ§ОнМмЙЙ
дкЙ§ШЅМИФъЕФЪБМфРяУцЃЌOPPO ФкВПЕФетЬзвдЪ§ВжЮЊКЫаФЕФЪ§ОнМмЙЙвбОж№НЅПЊЪМГЩЪьСЫЁЃ

РыЯпЕНЪЕЪБЪ§ВжЕФЦНЛЌЧЈвЦ
OPPO ЯЃЭћЫљЩшМЦГіРДЕФЪЕЪБЪ§ВжФмЙЛЪЕЯжДгРыЯпЕНЪЕЪБЕФЦНЛЌЧЈвЦЃЌжЎЧАДѓМвШчКЮЪЙгУКЭПЊЗЂРыЯпЪ§ВжЃЌШчНёЕНСЫЪЕЪБЪ§ВжвВЯЃЭћДѓМвШчКЮПЊЗЂКЭЪЙгУЁЃЭЈГЃЖјбдЃЌЕБЩшМЦвЛПюВњЦЗЛђепЦНЬЈЕФЪБКђЃЌПЩвдЛЎЗжЮЊСНВуЃЌМДЕзВуЪЕЯжКЭЩЯВуГщЯѓЁЃЖдгкЕзВуЪЕЯжЖјбдЃЌПЩФмЛсгаВЛЭЌЕФММЪѕЃЌДг
Hive ЕН FlinkЃЌДг HDFS ЕН KafkaЁЃЖјдкЩЯВуГщЯѓЖјбдЃЌдђЯЃЭћЖдгкгУЛЇЖјбдЪЧЭИУїЕФЁЃ
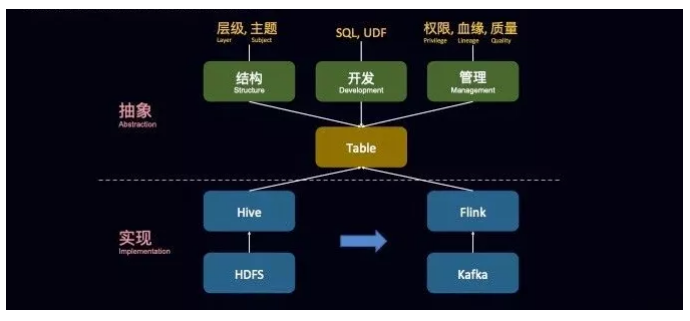
ЪЕЪБЪ§ВжЕФВуМЖЛЎЗж
ШчЯТЭМЫљЪОЕФЪЧ OPPO ЪЕЪБЪ§ВжЕФЗжВуНсЙЙЃЌДгНгШыВуЙ§РДжЎКѓЃЌЫљгаЕФЪ§ОнЖМЪЧЛсгУ Kafka РДжЇГХЕФЃЌЪ§ОнНгШыНјРДЗХЕН
Kafka РяУцЪЕЯж ODS ВуЃЌШЛКѓЪЙгУ Flink SQL ЪЕЯжЪ§ОнЕФЧхЯДЃЌШЛКѓОЭБфЕНСЫ DWD
ВуЃЌжаМфЪЙгУ Flink SQL ЪЕЯжвЛаЉОлКЯВйзїЃЌОЭЕНСЫ ADS ВуЃЌзюКѓИљОнВЛЭЌЕФвЕЮёЪЙгУГЁОАдйЕМШыЕНESЕШЯЕЭГжаШЅЁЃЕБШЛЃЌЦфжаЕФвЛаЉЮЌЖШВуЮЛгк
MySQL Лђеп Hive жаЁЃ
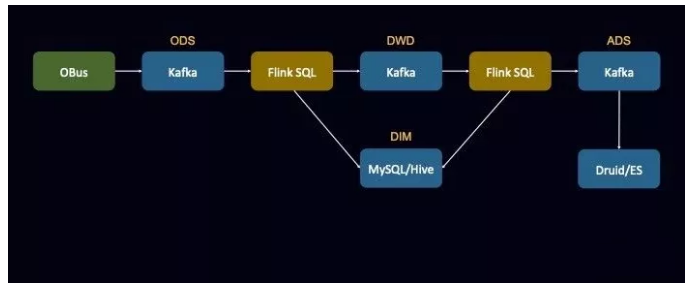
SQLвЛЭГЬьЯТЕФЪ§ОнМмЙЙ
ЖдгкЪ§ВжСьгђЕФНќЦкЗЂеЙЖјбдЃЌЦфжаКмгавтЫМЕФвЛЕуЪЧЃКЮоТлЪЧРыЯпЛЙЪЧЪЕЪБЕФЪ§ОнМмЙЙЃЌЖМТ§Т§бнНјГЩСЫ SQL
вЛЭГЬьЯТЕФМмЙЙЁЃЮоТлЪЧРыЯпЛЙЪЧЪЕЪБЪЧЪ§ОнВжПтЃЌЮоТлЪЧНгШыЃЌВщбЏЁЂПЊЗЂЛЙЪЧвЕЮёЯЕЭГЖМЪЧдкЩЯУцаД SQL
ЕФЗНЪНЁЃ
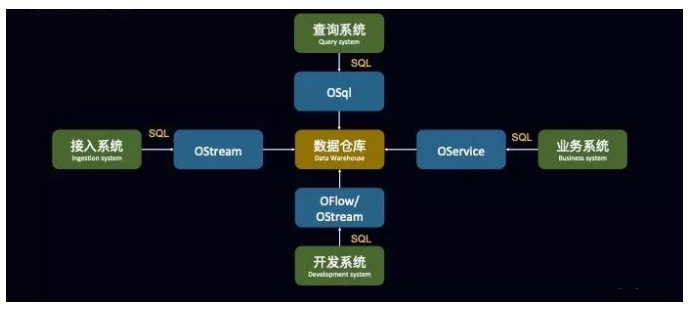
аДдкзюКѓЕФЛА
змНсЯТЃЌЪЕЪБЪ§ВжжївЊгаСНИівЊЕуЁЃЪзЯШЪЧЗжВуЩшМЦЩЯЃЌвЛАувВЪЧВЮПМРыЯпЪ§ВжЕФЩшМЦЃЌЭЈГЃЛсЗжЮЊODSВйзїЪ§ОнВуЁЂDWDУїЯИВуЁЂDWSЛузмВувдМАADSгІгУВуЃЌПЩФмЛЙЛсЗжГівЛВуDIMЮЌЖШЪ§ОнВуЁЃСэЭтЗжВуЩшМЦЩЯвВгаВЛЭЌЕФЫМТЗЃЌБШШчПЩвдНЋDWSКЭADSЙщЮЊDMЪ§ОнМЏЪаВуЃЌЭјвзбЯбЁОЭЪЧетбљЩшМЦЕФЁЃ
ММЪѕбЁаЭЩЯЃЌРыЯпЪ§ВжвЛАувРЭаHDFSЛђHiveЙЙНЈЃЌбЁдёMRЛђSparkМЦЫув§ЧцЃЛЪЕЪБЪ§ВжДцДЂВуИќЖрЪЧбЁдёKafkaЕШЯћЯЂв§ЧцЃЌЭЈГЃУїЯИВуКЭЛузмВуЖМЗХдкKafkaЃЌМЦЫуВудђЖрЪЧбЁдёFlink/Spark
Streaming/StormЃЌетЗНУцFlinkИќгагХЪЦЃЌЩчЧјвВИќЧуЯђгкбЁдёFlinkЁЃ |









