| БрМЭЦМі: |
БОЮФжївЊНВНтЃКЮЊЪВУДвЊЙЙНЈЪЕЪБЪ§ОнВжПтЁЂВЫФёЁЂжЊКѕЁЂУРЭХЁЂЭјвзЪЕЪБЪ§ВжЗНАИЁЂИїИіПЊдД
OLAP Ъ§ОнПтЕФгХШБЕуЁЂЮвУЧИУШчКЮзіММЪѕбЁаЭЁЃ
БОЮФРДзджЊКѕЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
дкПЊдДЪЂЪРЕФНёЬьЃЌЪЕЪБЪ§ВжЕФНЈЩшвЕНчвбОгаСЫГЩЪьЕФЗНАИЁЃММЪѕбЁаЭЩЯЪЕЪБМЦЫуЁЂЯћЯЂЖгСаЖМгазюгХНтЃЌЮЈЖРдк
OLAP СьгђЃЌАйМвељУљЃЌИїгаЫљГЄЁЃ
ДѓЪ§ОнСьгђПЊдД OLAP в§ЧцАќРЈВЛЯогк HiveЁЂHawqЁЂPrestoЁЂKylinЁЂImpalaЁЂSparkSQLЁЂDruidЁЂClickhouseЁЂGreeplum
ЕШЕШЁЃЮвУЧОЭИїИіГЃгУПЊдД OLAP в§ЧцЕФгХШБЕуКЭЪЙгУГЁОАзіГіЯъЯИЖдБШЃЌШУПЊЗЂепНјааММЪѕбЁаЭЪБзіЕНаФжагаЪ§ЁЃ
ЧАбд
НёФъгаИіЯжЯѓЃЌЪЕЪБЪ§ВжНЈЩшЭЛШЛОЭБЛДѓМвЫљЙизЂЁЃЮвИіШЫдкЙЋжкКХвВаДЙ§КЭзЊдиЙ§МИЦЊЙигкЪЕЪБЪ§ОнВжПтЕФЮФеТКЭЗНАИЁЃ
ЕЋЪЧЖдгкЪЕЪБЪ§ВжЕФПёШШзЗЧѓДѓПЩВЛБиЁЃ
ЪзЯШЃЌдкММЪѕЩЯМИКѕУЛгаФбЕуЃЌЛљгкЧПДѓЕФПЊдДжаМфМўЪЕЯжЪЕЪБЪ§ОнВжПтЕФашЧѓвбОБфЕУУЛгаФЧУДРЇФбЁЃЦфДЮЃЌЪЕЪБЪ§ВжЕФНЈЩшвЛЖЈЪЧАщЫцзХвЕЮёЕФЗЂеЙЖјЗЂеЙЃЌЮфЖЯЕФШЯЮЊKappaМмЙЙвЛЖЈЪЧзюКУЕФЪЕЪБЪ§ВжМмЙЙЪЧВЛЖдЕФЁЃЪЕМЪЧщПіжаЫцзХвЕЮёЕФЗЂеЙЪ§ВжЕФМмЙЙБфЕУУЛгаФЧУДЗЧДЫМДБЫЁЃ
дкећИіЪЕЪБЪ§ВжЕФНЈЩшжаЃЌOLAPЪ§ОнПтЕФбЁаЭжБНгжЦдМЪЕЪБЪ§ВжЕФПЩгУадКЭЙІФмадЁЃБОЮФДгвЕФкМИИіЕфаЭЕФЪ§ВжНЈЩшКЭЗЂеЙЧщПіШыЪжЃЌДгМмЙЙЁЂММЪѕбЁаЭКЭгХШБЕуЗжБ№ИјДѓМвЗжЮіЯждкЪаГЁЩЯЕФПЊдДOLAPв§ЧцЃЌжМдкЗНБуДѓМвММЪѕбЁаЭЙ§ГЬжаФмЙЛИљОнЪЕМЪвЕЮёНјаабЁдёЁЃ
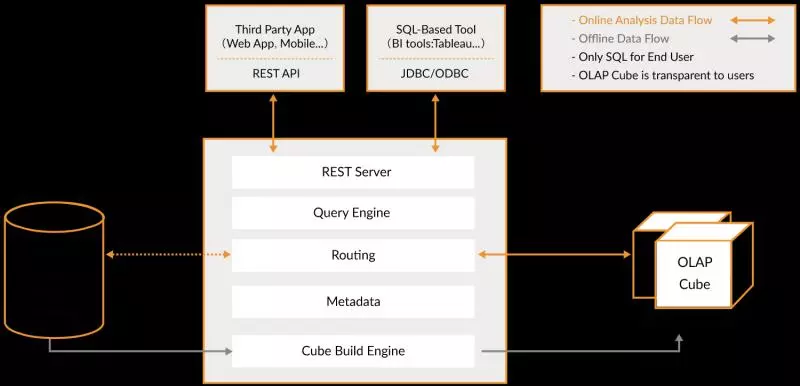
ЙмжаПњБЊ-ВЫФё/жЊКѕ/УРЭХ/ЭјвзбЯбЁЪЕЪБЪ§ВжНЈЩш
ЮЊЪВУДвЊЙЙНЈЪЕЪБЪ§ОнВжПт
ДЋЭГЕФРыЯпЪ§ОнВжПтНЋвЕЮёЪ§ОнМЏжаНјааДцДЂКѓЃЌвдЙЬЖЈЕФМЦЫуТпМЖЈЪБНјааETLКЭЦфЫќНЈФЃКѓВњГіБЈБэЕШгІгУЁЃРыЯпЪ§ОнВжПтжївЊЪЧЙЙНЈT+1ЕФРыЯпЪ§ОнЃЌЭЈЙ§ЖЈЪБШЮЮёУПЬьРШЁдіСПЪ§ОнЃЌШЛКѓДДНЈИїИівЕЮёЯрЙиЕФжїЬтЮЌЖШЪ§ОнЃЌЖдЭтЬсЙЉT+1ЕФЪ§ОнВщбЏНгПкЁЃМЦЫуКЭЪ§ОнЕФЪЕЪБадОљНЯВюЃЌвЕЮёШЫдБЮоЗЈИљОнздМКЕФМДЪБадашвЊЛёШЁМИЗжжгжЎЧАЕФЪЕЪБЪ§ОнЁЃЪ§ОнБОЩэЕФМлжЕЫцзХЪБМфЕФСїЪХЛсж№ВНМѕШѕЃЌвђДЫЪ§ОнЗЂЩњКѓБиаыОЁПьЕФДяЕНгУЛЇЕФЪжжаЃЌЪЕЪБЪ§ВжЕФЙЙНЈашЧѓвВгІдЫЖјЩњЁЃ
змжЎОЭЪЧвЛОфЛАЃКЪБаЇадЕФвЊЧѓЁЃ
АЂРяВЫФёЕФЪЕЪБЪ§ВжЩшМЦ
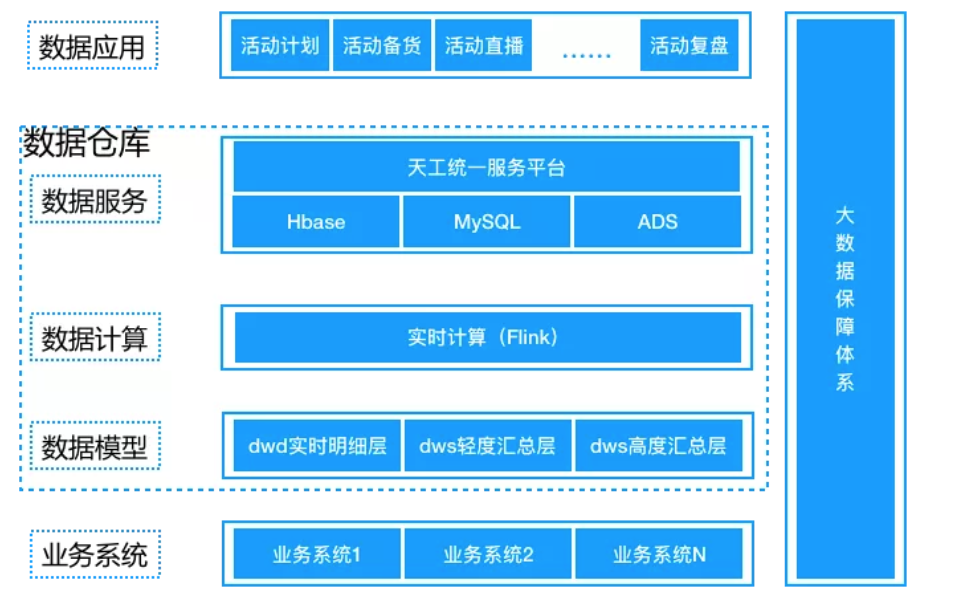
ВЫФёЕФЪЕЪБЪ§ВжећЬхЩшМЦШчЩЯЭМЃЌЛљгквЕЮёЯЕЭГЕФЪ§ОнЃЌЪ§ОнФЃаЭЪЧДЋЭГЕФЗжВуЛузмЩшМЦЃЈУїЯИ/ЧсЖШЛузм/ИпЖШЛузмЃЉЃЛМЦЫув§ЧцЃЌбЁдёЕФЪЧАЂРяФкВПЕФBlinkЃЛЪ§ОнЗУЮЪгУЬьЙЄНгШы(ЬьЙЄЪЧвЛИіСЌНгЖржжЪ§ОндДЕФЙЄОпЃЌФПЕФЪЧЦСБЮДѓСПЕФЖдИїжжЪ§ОнПтЕФжБСЌ)ЃЛЪ§ОнгІгУЖдгІЕФЪЧВЫФёЕФИїИівЕЮёЁЃ
ВЫФёЕФЪЕЪБЪ§ВжЕФМмЙЙЩшМЦЪЧвЛИіКмЕфаЭКмОЕУЦ№ПМбщЕФЩшМЦЁЃЪЕЪБЪ§ОнНгШыВПЗжЭЈЙ§ЯћЯЂжаМфМў(ПЊдДДѓЪ§ОнСьгђЗЧKafkaФЊЪєЃЌPulsarЪЧКѓЦ№жЎау)ЃЌHbaseзїЮЊИпЖШЛузмЕФK-VВщбЏИЈжњЁЃ
ФЧУДДѓСПЕФЖдвЕЮёЕФжБНгжЇГХдкФФРяЃПдкетРяЃКADSЁЃ
ADSЃЈКѓИќУћЮЊADBЃЌМгШыаТЬиадЃЉЪЧАЂРяАЭАЭзджїбаЗЂЕФКЃСПЪ§ОнЪЕЪБИпВЂЗЂдкЯпЗжЮіЃЈRealtime
OLAPЃЉдЦМЦЫуЪ§ОнПтЁЃВЮПМ
ОЕфЕФЪЕЪБЪ§ОнЧхЯДГЁОА
ОЕфЕФЪЕЪБЪ§ВжГЁОА
дкADBЕФЙйЗНЮФЕЕжаИјГіСЫADBЕФФмСІЃК
ПьADBВЩгУMPP+DAGШкКЯв§ЧцЃЌВЩгУааСаЛьДцММЪѕЁЂздЖЏЫїв§ЕШММЪѕЃЌПЩвдПьЫйРЉШнжСЪ§ЧЇНкЕуЁЃ
СщЛюЫцвтЕїећНкЕуЪ§СПКЭЖЏЬЌЩ§НЕХфЪЕР§ЙцИёЁЃ
взгУШЋУцМцШнMySQLавщКЭSQL
ГЌДѓЙцФЃШЋЗжВМЪННсЙЙЃЌЮоШЮКЮЕЅЕуЩшМЦЃЌЗНБуКсЯђРЉеЙдіМгSQLДІРэВЂЗЂЁЃ
ИпВЂЗЂаДШыаЁЙцФЃЕФ10ЭђTPSаДШыФмСІЃЌЭЈЙ§КсЯђРЉШнНкЕуЬсЩ§жС200Эђ+TPSЕФаДШыФмСІЁЃЪЕЪБаДШыЪ§ОнКѓЃЌдМ1УызѓгвМДПЩВщбЏЗжЮіЁЃЕЅИіБэзюДѓжЇГж2PBЪ§ОнЃЌЪЎЭђвкМЧТМЁЃ
жЊКѕЕФЪЕЪБЪ§ВжЩшМЦ
жЊКѕЕФЪЕЪБЪ§ВжЪЕМљвдМАМмЙЙЕФбнНјЗжЮЊШ§ИіНзЖЮЃК
ЪЕЪБЪ§Вж 1.0 АцБОЃЌжїЬтЃК ETL ТпМЪЕЪБЛЏЃЌММЪѕЗНАИЃКSpark Streaming
ЪЕЪБЪ§Вж 2.0 АцБОЃЌжїЬтЃКЪ§ОнЗжВуЃЌжИБъМЦЫуЪЕЪБЛЏЃЌММЪѕЗНАИЃКFlink Streaming
ЪЕЪБЪ§ВжЮДРДеЙЭћЃКStreaming SQL ЦНЬЈЛЏЃЌдЊаХЯЂЙмРэЯЕЭГЛЏЃЌНсЙћбщЪездЖЏЛЏ
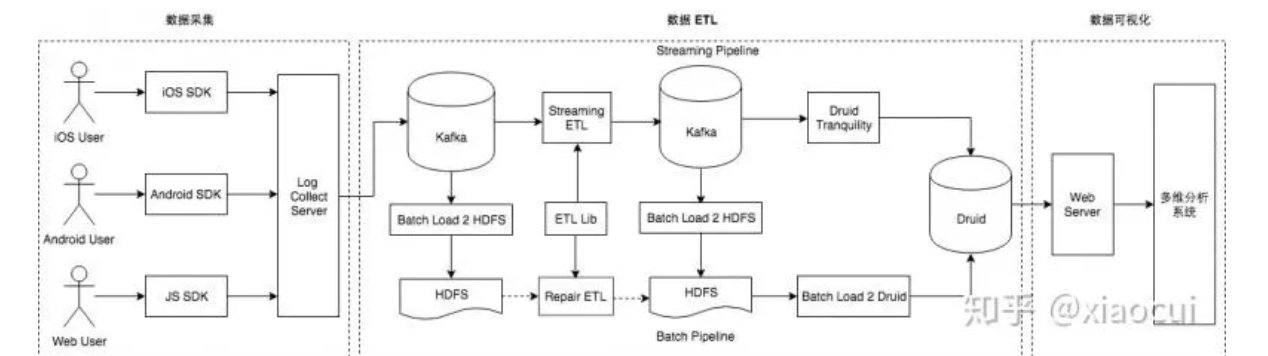
ЪЕЪБЪ§Вж 1.0 АцБО
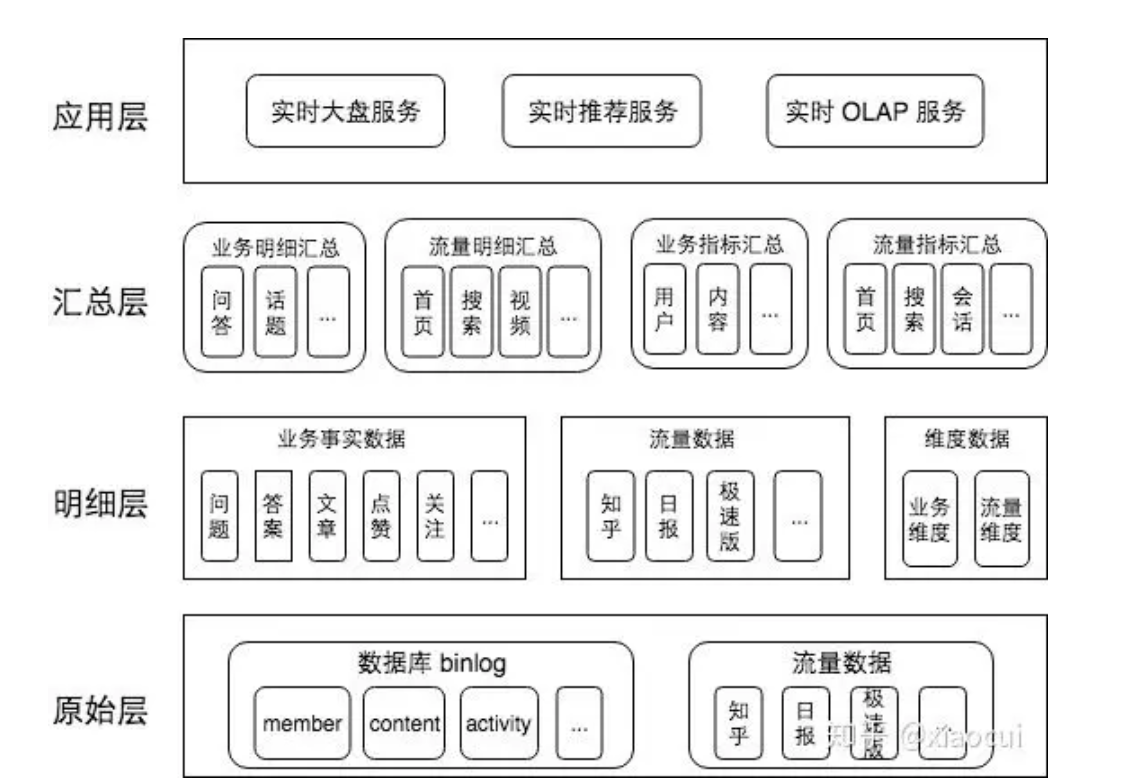
ЪЕЪБЪ§Вж 2.0 АцБО
дкММЪѕМмЙЙЩЯЃЌдіМгСЫжИБъЛузмВуЃЌжИБъЛузмВуЪЧгЩУїЯИВуЛђепУїЯИЛузмВуЭЈЙ§ОлКЯМЦЫуЕУЕНЃЌетвЛВуВњГіСЫОјДѓВПЗжЕФЪЕЪБЪ§ВжжИБъЃЌетвВЪЧгыЪЕЪБЪ§Вж
1.0 зюДѓЕФЧјБ№ЁЃ
ММЪѕбЁаЭЩЯЃЌжЊКѕИљОнВЛЭЌвЕЮёГЁОАбЁдёСЫHBase КЭ Redis
зїЮЊЪЕЪБжИБъЕФДцДЂв§ЧцЃЌдкOLAPбЁаЭЩЯЃЌжЊКѕбЁдёСЫDruidЁЃ
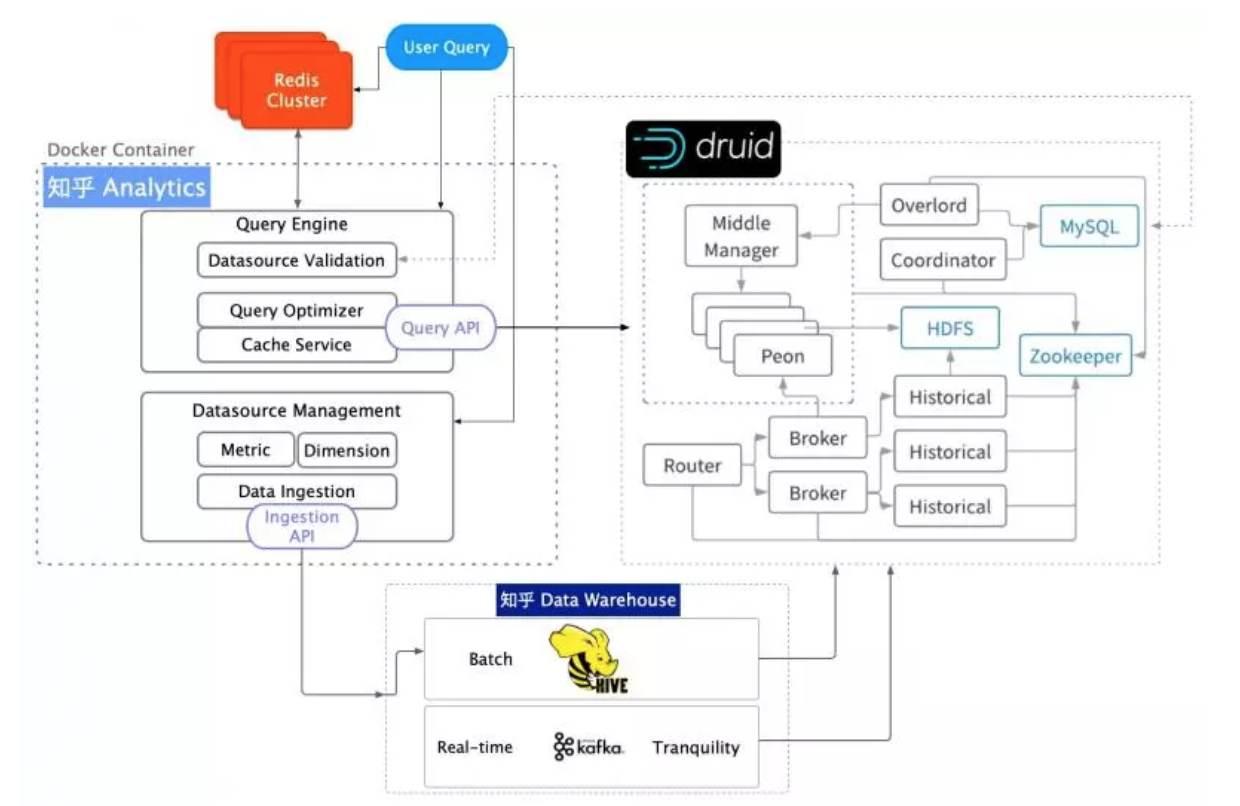
жЊКѕЪЕЪБЖрЮЌЗжЮіЦНЬЈ
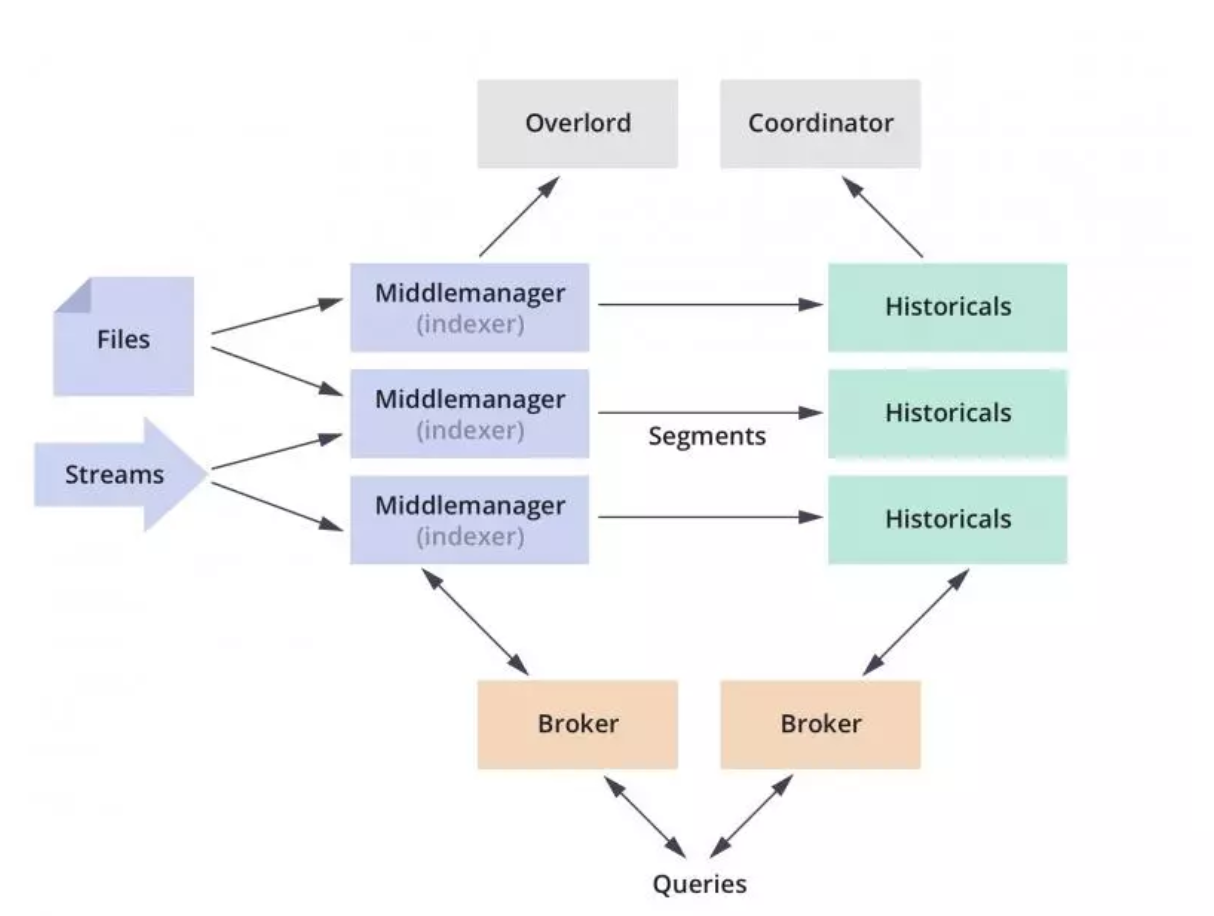
МмЙЙDruid ећЬхМмЙЙ
DruidЪЧвЛИіИпаЇЕФЪ§ОнВщбЏЯЕЭГЃЌжївЊНтОіЕФЪЧЖдгкДѓСПЕФЛљгкЪБађЕФЪ§ОнНјааОлКЯВщбЏЁЃЪ§ОнПЩвдЪЕЪБЩуШыЃЌНјШыЕНDruidКѓСЂМДПЩВщЃЌЭЌЪБЪ§ОнЪЧМИКѕЪЧВЛПЩБфЁЃЭЈГЃЪЧЛљгкЪБађЕФЪТЪЕЪТМўЃЌЪТЪЕЗЂЩњКѓНјШыDruidЃЌЭтВПЯЕЭГОЭПЩвдЖдИУЪТЪЕНјааВщбЏЁЃDruidВЩгУЕФМмЙЙ:
shared-nothingМмЙЙгыlambdaМмЙЙ
DruidЩшМЦЕФШ§Иіддђ:
ПьЫйВщбЏЃКВПЗжЪ§ОнОлКЯЃЈPartial AggregateЃЉ + ФкДцЛЏЃЈIn-MemoryЃЉ +
Ыїв§ЃЈIndexЃЉ
ЫЎЦНЭиеЙФмСІЃКЗжВМЪНЪ§ОнЃЈDistributed dataЃЉ+ВЂааЛЏВщбЏЃЈParallelizable
QueryЃЉ
ЪЕЪБЗжЮіЃКImmutable Past , Append-Only Future
УРЭХЕФЪЕЪБЪ§ВжЩшМЦ
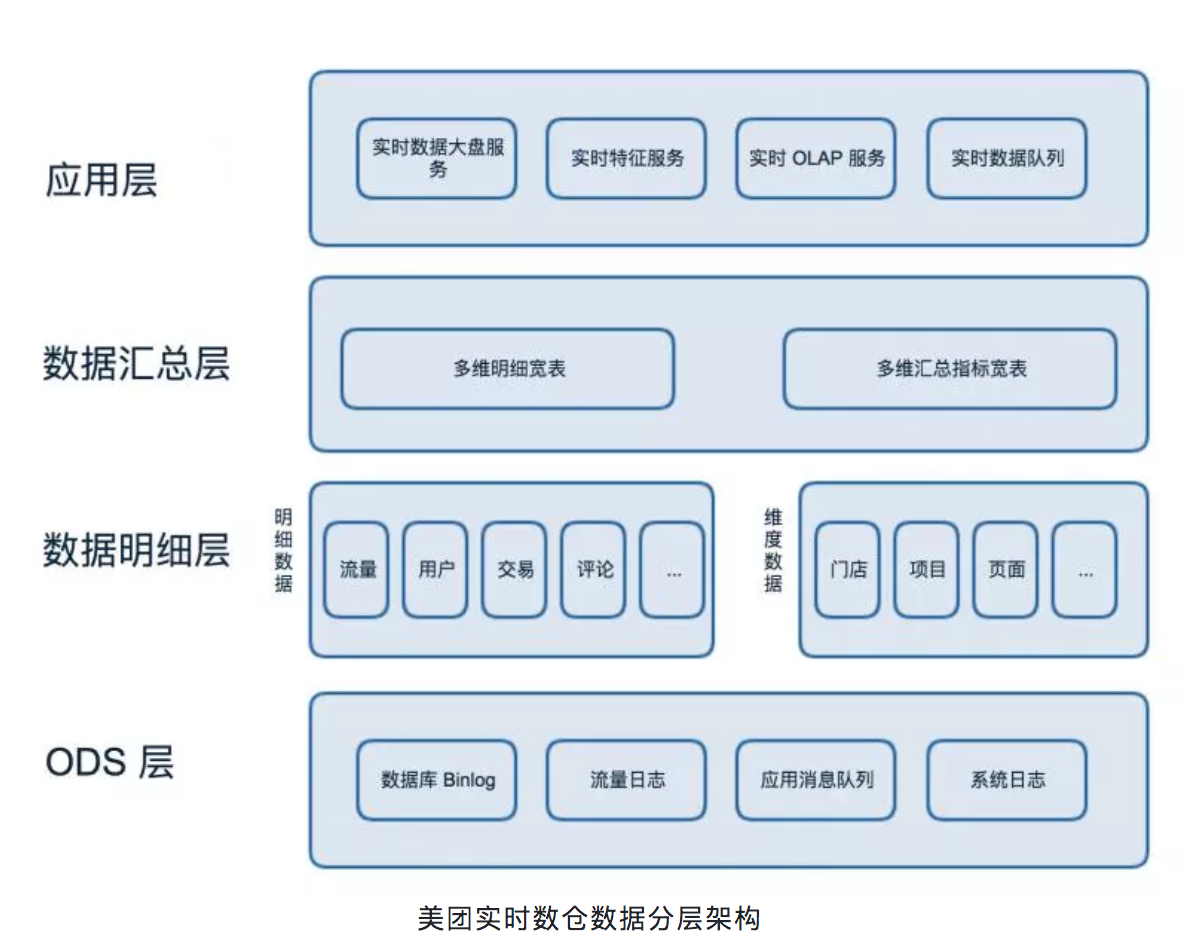
УРЭХЪЕЪБЪ§ВжЪ§ОнЗжВуМмЙЙ
УРЭХЕФММЪѕЗНАИгЩвдЯТЫФВуЙЙГЩЃК
ODS ВуЃКBinlog КЭСїСПШежОвдМАИївЕЮёЪЕЪБЖгСаЁЃ
Ъ§ОнУїЯИВуЃКвЕЮёСьгђећКЯЬсШЁЪТЪЕЪ§ОнЃЌРыЯпШЋСПКЭЪЕЪББфЛЏЪ§ОнЙЙНЈЪЕЪБЮЌЖШЪ§ОнЁЃ
Ъ§ОнЛузмВуЃКЪЙгУПэБэФЃаЭЖдУїЯИЪ§ОнВЙГфЮЌЖШЪ§ОнЃЌЖдЙВаджИБъНјааЛузмЁЃ
App ВуЃКЮЊСЫОпЬхашЧѓЖјЙЙНЈЕФгІгУВуЃЌЭЈЙ§ RPC ПђМмЖдЭтЬсЙЉЗўЮёЁЃ
ИљОнВЛЭЌвЕЮёГЁОАЃЌЪЕЪБЪ§ВжИїИіФЃаЭВуДЮЪЙгУЕФДцДЂЗНАИКЭOLAPв§ЧцШчЯТЃК
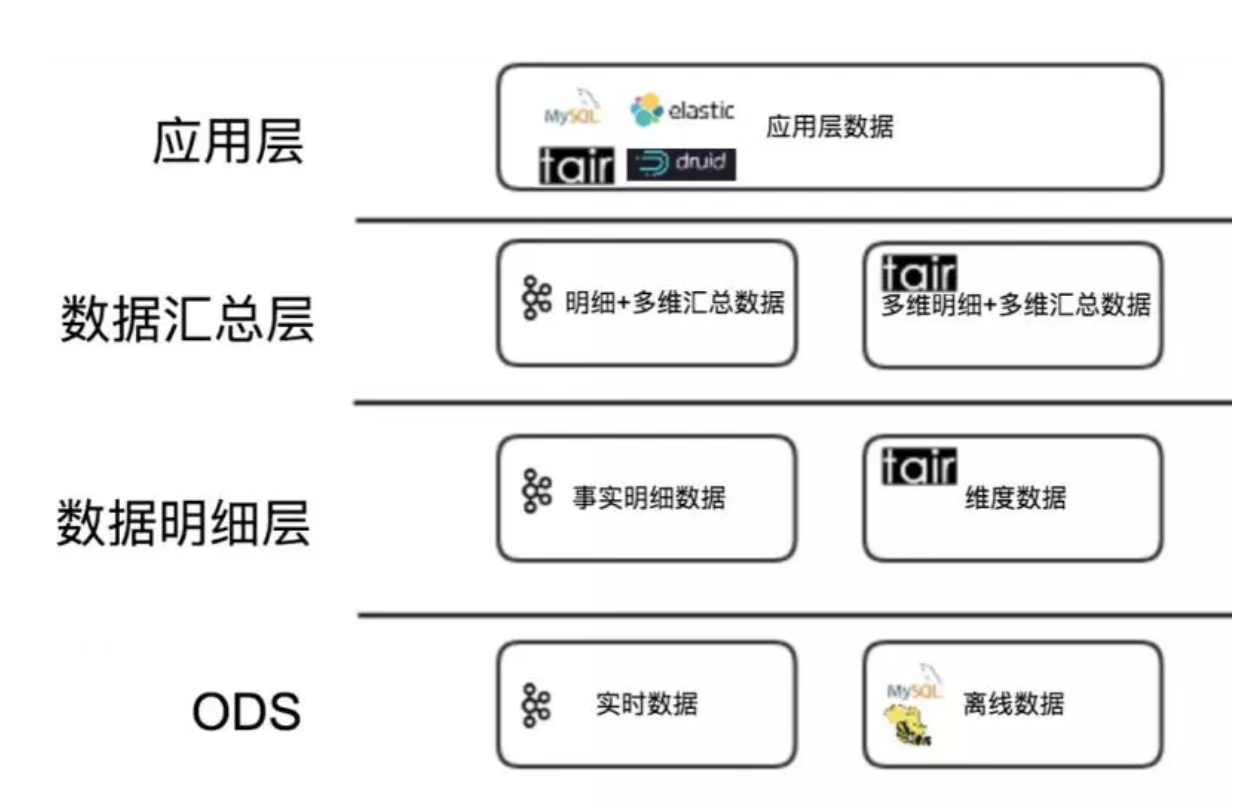
Ъ§ОнУїЯИВу ЖдгкЮЌЖШЪ§ОнВПЗжГЁОАЯТЙиСЊЕФЦЕТЪПЩДя 10w+ TPSЃЌЮвУЧбЁдё CellarЃЈУРЭХФкВПЗжВМЪНK-VДцДЂЯЕЭГЃЌРрЫЦRedisЃЉ
зїЮЊДцДЂЃЌЗтзАЮЌЖШЗўЮёЮЊЪЕЪБЪ§ВжЬсЙЉЮЌЖШЪ§ОнЁЃ
Ъ§ОнЛузмВу ЖдгкЭЈгУЕФЛузмжИБъЃЌашвЊНјааРњЪЗЪ§ОнЙиСЊЕФЪ§ОнЃЌВЩгУКЭЮЌЖШЪ§ОнвЛбљЕФЗНАИЭЈЙ§ Cellar
зїЮЊДцДЂЃЌгУЗўЮёЕФЗНЪННјааЙиСЊВйзїЁЃ
Ъ§ОнгІгУВу гІгУВуЩшМЦЯрЖдИДдгЃЌдйЖдБШСЫМИжжВЛЭЌДцДЂЗНАИКѓЁЃЮвУЧжЦЖЈСЫвдЪ§ОнЖСаДЦЕТЪ 1000 QPS
ЮЊЗжНчЕФХаЖЯвРОнЁЃЖдгкЖСаДЦНОљЦЕТЪИпгк 1000 QPS ЕЋВщбЏВЛЬЋИДдгЕФЪЕЪБгІгУЃЌБШШчЩЬЛЇЪЕЪБЕФОгЊЪ§ОнЁЃВЩгУ
Cellar ЮЊДцДЂЃЌЬсЙЉЪЕЪБЪ§ОнЗўЮёЁЃЖдгквЛаЉВщбЏИДдгЕФКЭашвЊУїЯИСаБэЕФгІгУЃЌЪЙгУ Elasticsearch
зїЮЊДцДЂдђИќЮЊКЯЪЪЁЃЖјвЛаЉВщбЏЦЕТЪЕЭЃЌБШШчвЛаЉФкВПдЫгЊЕФЪ§ОнЁЃ Druid ЭЈЙ§ЪЕЪБДІРэЯћЯЂЙЙНЈЫїв§ЃЌВЂЭЈЙ§дЄОлКЯПЩвдПьЫйЕФЬсЙЉЪЕЪБЪ§Он
OLAP ЗжЮіЙІФмЁЃЖдгквЛаЉРњЪЗАцБОЕФЪ§ОнВњЦЗНјааЪЕЪБЛЏИФдьЪБЃЌвВПЩвдЪЙгУ MySQL ДцДЂБугкВњЦЗЕќДњЁЃ
змжЎЃЌдкOLAPбЁаЭЩЯЭЌбљвдDruidЮЊжїЁЃ
ЭјвзбЯбЁЕФЪЕЪБЪ§ВжЩшМЦ
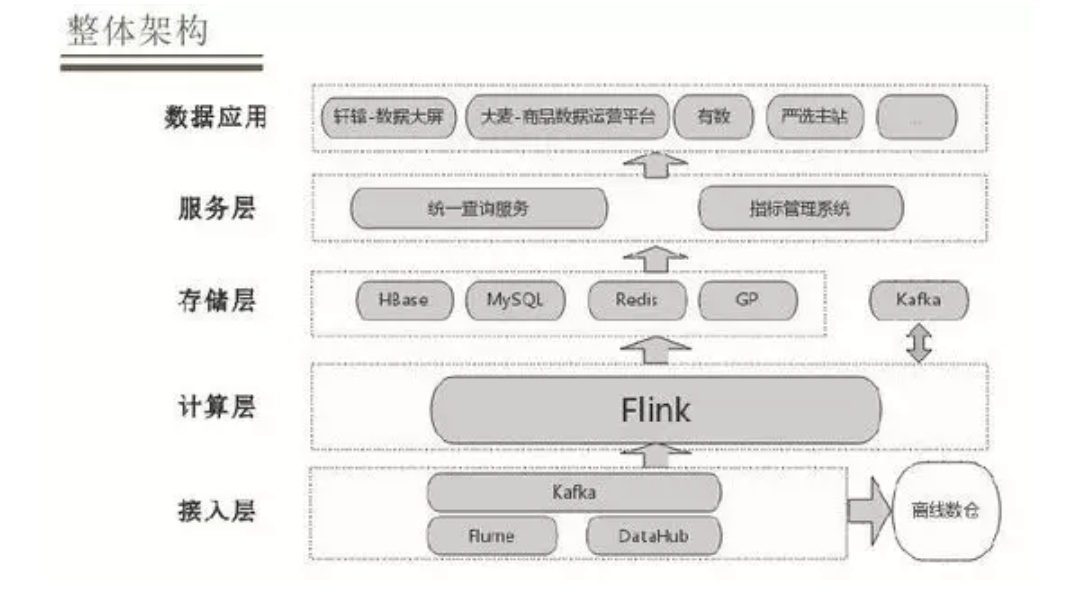
ЭјвзбЯбЁЕФЪЕЪБЪ§ВжећЬхПђМмвРОнЪ§ОнЕФСїЯђЗжЮЊВЛЭЌЕФВуДЮЃЌНгШыВуЛсвРОнИїжжЪ§ОнНгШыЙЄОп
ЪеМЏИїИівЕЮёЯЕЭГЕФЪ§ОнЁЃЯћЯЂЖгСаЕФЪ§ОнМШЪЧРыЯпЪ§ВжЕФдЪМЪ§ОнЃЌвВЪЧЪЕЪБМЦЫуЕФдЪМЪ§ОнЃЌетбљПЩвдБЃжЄЪЕЪБКЭРыЯпЕФдЪМЪ§ОнЪЧЭГвЛЕФЁЃ
дкМЦЫуВуОЙ§ Flink+ЪЕЪБМЦЫув§ЧцзівЛаЉМгЙЄДІРэЃЌШЛКѓТфЕиЕНДцДЂВужаВЛЭЌДцДЂНщжЪЕБжаЁЃВЛЭЌЕФДцДЂНщжЪЪЧвРОнВЛЭЌЕФгІгУГЁОАРДбЁдёЁЃПђМмжаЛЙгаFlinkКЭKafkaЕФНЛЛЅЃЌдкЪ§ОнЩЯНјаавЛИіЗжВуЩшМЦЃЌМЦЫув§ЧцДгKafkaжаРЬШЁЪ§ОнзівЛаЉМгЙЄШЛКѓЗХЛиKafkaЁЃдкДцДЂВуМгЙЄКУЕФЪ§ОнЛсЭЈЙ§ЗўЮёВуЕФСНИіЗўЮёЃКЭГвЛВщбЏЁЂжИБъЙмРэЃЌЭГвЛВщбЏЪЧЭЈЙ§вЕЮёЗНЕїШЁЪ§ОнНгПкЕФвЛИіЗўЮёЃЌжИБъЙмРэЪЧЖдЪ§ОнжИБъЕФЖЈвхКЭЙмРэЙЄзїЁЃЭЈЙ§ЗўЮёВугІгУЕНВЛЭЌЕФЪ§ОнгІгУЃЌЪ§ОнгІгУПЩФмЪЧЮвУЧЕФе§ЪНВњЦЗЛђепжБНгЕФвЕЮёЯЕЭГЁЃ
ЛљгквдЩЯЕФЩшМЦЃЌММЪѕбЁаЭШчЯТЃК
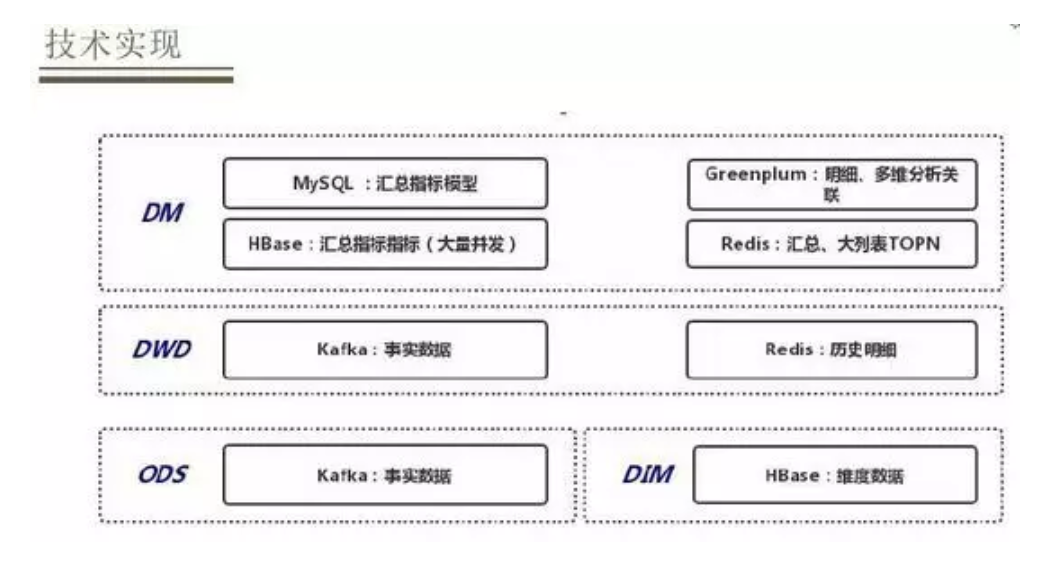
ЖдгкДцДЂВуЛсвРОнВЛЭЌЕФЪ§ОнВуЕФЬиЕубЁдёВЛЭЌЕФДцДЂНщжЪЃЌODSВуКЭDWDВуЖМЪЧДцДЂЕФвЛаЉЪЕЪБЪ§ОнЃЌбЁдёЕФЪЧKafkaНјааДцДЂЃЌдкDWDВуЛсЙиСЊвЛаЉРњЪЗУїЯИЪ§ОнЃЌЛсНЋЦфЗХЕН
Redis РяУцЁЃдкDIMВужївЊзівЛаЉИпВЂЗЂЮЌЖШЕФВщбЏЙиСЊЃЌвЛАуНЋЦфДцЗХдкHBaseРяУцЃЌЖдгкDIMВуБШМлИДдгЃЌашвЊзлКЯПМТЧЖдгкЪ§ОнТфЕиЕФвЊЧѓвдМАОпЬхЕФВщбЏв§ЧцРДбЁдёВЛЭЌЕФДцДЂЗНЪНЁЃЖдгкГЃМћЕФжИБъЛузмФЃаЭжБНгЗХдк
MySQL РяУцЃЌЮЌЖШБШНЯЖрЕФЁЂаДШыИќаТБШНЯДѓЕФФЃаЭЛсЗХдкHBaseРяУцЃЌЛЙгаУїЯИЪ§ОнашвЊзівЛаЉЖрЮЌЗжЮіЛђепЙиСЊЛсНЋЦфДцДЂдкGreenplumРяУцЃЌЛЙгавЛжжЪЧЮЌЖШБШНЯЖрЁЂашвЊзіХХађЁЂВщбЏвЊЧѓБШНЯИпЕФЃЌШчЛюЖЏЦкМфгУЛЇЕФЯњЪлСаБэЕШДѓСаБэжБНгДцДЂдкRedisРяУцЁЃ
ЭјвзбЯбЁбЁдёСЫGreenPulmЁЂHbaseЁЂRedisКЭMySQLзїЮЊЪ§ОнЕФМЦЫуКЭЭИГіВуЁЃ
GreenPulmЕФММЪѕЬиЕуШчЯТЃК
жЇГжКЃСПЪ§ОнДцДЂКЭДІРэ
жЇГжJust In Time BIЃКЭЈЙ§зМЪЕЪБЁЂЪЕЪБЕФЪ§ОнМгдиЗНЪНЃЌЪЕЯжЪ§ОнВжПтЕФЪЕЪБИќаТЃЌНјЖјЪЕЯжЖЏЬЌЪ§ОнВжПтЃЈADWЃЉЃЌЛљгкЖЏЬЌЪ§ОнВжПтЃЌвЕЮёгУЛЇФмЖдЕБЧАвЕЮёЪ§ОнНјааBIЪЕЪБЗжЮіЃЈJust
In Time BIЃЉ
жЇГжжїСїЕФsqlгяЗЈЃЌЪЙгУЦ№РДЪЎЗжЗНБуЃЌбЇЯАГЩБОЕЭ
РЉеЙадКУЃЌжЇГжЖргябдЕФздЖЈвхКЏЪ§КЭздЖЈвхРраЭЕШ
ЬсЙЉСЫДѓСПЕФЮЌЛЄЙЄОпЃЌЪЙгУЮЌЛЄЦ№РДКмЗНБу
жЇГжЯпадРЉеЙЃКВЩгУMPPВЂааДІРэМмЙЙЁЃдкMPPНсЙЙжадіМгНкЕуОЭПЩвдЯпадЬсЙЉЯЕЭГЕФДцДЂШнСПКЭДІРэФмСІ
НЯКУЕФВЂЗЂжЇГжМАИпПЩгУаджЇГжГ§СЫЬсЙЉгВМўМЖЕФRaidММЪѕЭтЃЌЛЙЬсЙЉЪ§ОнПтВуMirrorЛњжЦБЃЛЄЃЌЬсЙЉMaster/Stand
byЛњжЦНјаажїНкЕуШнДэЃЌЕБжїНкЕуЗЂЩњДэЮѓЪБЃЌПЩвдЧаЛЛЕНStand byНкЕуМЬајЗўЮё
жЇГжMapReduceЃКвЛжжДѓЙцФЃЪ§ОнЗжЮіММЪѕ
Ъ§ОнПтФкВПбЙЫѕ
змНс
ЮвУЧЭЈЙ§вдЩЯЕФЗжЮіПЩвдПДГіЃЌдкећИіЪЕЪБЪ§ВжЕФНЈЩшжаЃЌвЕНчвбОгаСЫГЩЪьЕФЗНАИЁЃећЬхМмЙЙЩшМЦЭЈЙ§ЗжВуЩшМЦЮЊOLAPВщбЏЗжЕЃбЙСІЃЌШУГіМЦЫуПеМфЃЌИДдгЕФМЦЫуЭГвЛдкЪЕЪБМЦЫуВузіЃЌБмУтИјOLAPВщбЏДјРДЙ§ДѓЕФбЙСІЁЃЛузмМЦЫуНЬИјOLAPЪ§ОнПтНјааЁЃЮвУЧПЩвдетУДЫЕЃЌдкећИіМмЙЙжаЪЕЪБМЦЫувЛАуЪЧSpark+FlinkХфКЯЃЌЯћЯЂЖгСаKafkaвЛМвЖРДѓЃЌећИіДѓЪ§ОнСьгђЯћЯЂЖгСаЕФгІгУжаШдШЛДІРэТЂЖЯЕиЮЛЃЌКѓРДепPulsarЯызіГіГЌдНФбЖШКмДѓЃЌHbaseЁЂRedisКЭMySQLЖМдкЬиЖЈГЁОАЯТгавЛЯЏжЎЕиЁЃЮЈЖРдкOLAPСьгђЃЌАйМвељУљЃЌИїгаЫљГЄЁЃДѓЪ§ОнСьгђПЊдДOLAPв§ЧцАќРЈЕЋЪЧВЛЯогкHiveЁЂDruidЁЂHawqЁЂPrestoЁЂImpalaЁЂSparksqlЁЂClickhouseЁЂGreenplumЕШЕШЁЃЯТвЛЦЊЮвУЧОЭИїИіПЊдДOLAPв§ЧцЕФгХШБЕуКЭЪЙгУГЁОАзіГіЯъЯИЖдБШЃЌШУПЊЗЂепНјааММЪѕбЁаЭЪБзіЕНаФжагаЪ§ЁЃ
OLAPАйМвељУљ
OLAPМђНщ
OLAPЃЌвВНаСЊЛњЗжЮіДІРэЃЈOnline Analytical ProcessingЃЉЯЕЭГЃЌгаЕФЪБКђвВНаDSSОіВпжЇГжЯЕЭГЃЌОЭЪЧЮвУЧЫЕЕФЪ§ОнВжПтЁЃгыДЫЯрЖдЕФЪЧOLTPЃЈon-line
transaction processingЃЉСЊЛњЪТЮёДІРэЯЕЭГЁЃ
СЊЛњЗжЮіДІРэ (OLAP) ЕФИХФюзюдчЪЧгЩЙиЯЕЪ§ОнПтжЎИИE.F.Coddгк1993ФъЬсГіЕФЁЃOLAPЕФЬсГів§Ц№СЫКмДѓЕФЗДЯьЃЌOLAPзїЮЊвЛРрВњЦЗЭЌСЊЛњЪТЮёДІРэ
(OLTP) УїЯдЧјЗжПЊРДЁЃ
CoddШЯЮЊСЊЛњЪТЮёДІРэЃЈOLTPЃЉвбВЛФмТњзужеЖЫгУЛЇЖдЪ§ОнПтВщбЏЗжЮіЕФвЊЧѓЃЌSQLЖдДѓЪ§ОнПтЕФМђЕЅВщбЏвВВЛФмТњзугУЛЇЗжЮіЕФашЧѓЁЃгУЛЇЕФОіВпЗжЮіашвЊЖдЙиЯЕЪ§ОнПтНјааДѓСПМЦЫуВХФмЕУЕННсЙћЃЌЖјВщбЏЕФНсЙћВЂВЛФмТњзуОіВпепЬсГіЕФашЧѓЁЃвђДЫЃЌCoddЬсГіСЫЖрЮЌЪ§ОнПтКЭЖрЮЌЗжЮіЕФИХФюЃЌМДOLAPЁЃ
OLAPЮЏдБЛсЖдСЊЛњЗжЮіДІРэЕФЖЈвхЮЊЃКДгдЪМЪ§ОнжазЊЛЏГіРДЕФЁЂФмЙЛеце§ЮЊгУЛЇЫљРэНтЕФЁЂВЂецЪЕЗДгГЦѓвЕЖрЮЌЬиадЕФЪ§ОнГЦЮЊаХЯЂЪ§ОнЃЌЪЙЗжЮіШЫдБЁЂЙмРэШЫдБЛђжДааШЫдБФмЙЛДгЖржжНЧЖШЖдаХЯЂЪ§ОнНјааПьЫйЁЂвЛжТЁЂНЛЛЅЕиДцШЁЃЌДгЖјЛёЕУЖдЪ§ОнЕФИќЩюШыСЫНтЕФвЛРрШэМўММЪѕЁЃOLAPЕФФПБъЪЧТњзуОіВпжЇГжЛђЖрЮЌЛЗОГЬиЖЈЕФВщбЏКЭБЈБэашЧѓЃЌЫќЕФММЪѕКЫаФЪЧ"ЮЌ"етИіИХФюЃЌвђДЫOLAPвВПЩвдЫЕЪЧЖрЮЌЪ§ОнЗжЮіЙЄОпЕФМЏКЯЁЃ
OLAPЕФзМдђКЭЬиад
E.F.CoddЬсГіСЫЙигкOLAPЕФ12ЬѕзМдђЃК
зМдђ1 OLAPФЃаЭБиаыЬсЙЉЖрЮЌИХФюЪгЭМ
зМдђ2 ЭИУїадзМдђ
зМдђ3 ДцШЁФмСІзМдђ
зМдђ4 ЮШЖЈЕФБЈБэФмСІ
зМдђ5 ПЭЛЇ/ЗўЮёЦїЬхЯЕНсЙЙ
зМдђ6 ЮЌЕФЕШЭЌадзМдђ
зМдђ7 ЖЏЬЌЕФЯЁЪшОиеѓДІРэзМдђ
зМдђ8 ЖргУЛЇжЇГжФмСІзМдђ
зМдђ9 ЗЧЪмЯоЕФПчЮЌВйзї
зМдђ10 жБЙлЕФЪ§ОнВйзн
зМдђ11 СщЛюЕФБЈБэЩњГЩ
зМдђ12 ВЛЪмЯоЕФЮЌгыОлМЏВуДЮ
вЛбдвдБЮжЎЃК
OLTPЯЕЭГЧПЕїЪ§ОнПтФкДцаЇТЪЃЌЧПЕїФкДцИїжжжИБъЕФУќСюТЪЃЌЧПЕїАѓЖЈБфСПЃЌЧПЕїВЂЗЂВйзїЃЌЧПЕїЪТЮёадЃЛOLAPЯЕЭГдђЧПЕїЪ§ОнЗжЮіЃЌЧПЕїSQLжДааЪБГЄЃЌЧПЕїДХХЬI/OЃЌЧПЕїЗжЧјЁЃ
OLAPПЊдДв§Чц
ФПЧАЪаУцЩЯжїСїЕФПЊдДOLAPв§ЧцАќКЌВЛЯогкЃКHiveЁЂHawqЁЂPrestoЁЂKylinЁЂImpalaЁЂSparksqlЁЂDruidЁЂClickhouseЁЂGreeplumЕШЃЌПЩвдЫЕФПЧАУЛгавЛИів§ЧцФмдкЪ§ОнСПЃЌСщЛюГЬЖШКЭадФмЩЯзіЕНЭъУРЃЌгУЛЇашвЊИљОнздМКЕФашЧѓНјаабЁаЭЁЃ
зщМўЬиЕуКЭМђНщ
Hive
HiveЪЧЛљгкHadoopЕФвЛИіЪ§ОнВжПтЙЄОпЃЌПЩвдНЋНсЙЙЛЏЕФЪ§ОнЮФМўгГЩфЮЊвЛеХЪ§ОнПтБэЃЌВЂЬсЙЉЭъећЕФsqlВщбЏЙІФмЃЌПЩвдНЋsqlгяОфзЊЛЛЮЊMapReduceШЮЮёНјаадЫааЁЃЦфгХЕуЪЧбЇЯАГЩБОЕЭЃЌПЩвдЭЈЙ§РрSQLгяОфПьЫйЪЕЯжМђЕЅЕФMapReduceЭГМЦЃЌВЛБиПЊЗЂзЈУХЕФMapReduceгІгУЃЌЪЎЗжЪЪКЯЪ§ОнВжПтЕФЭГМЦЗжЮіЁЃ
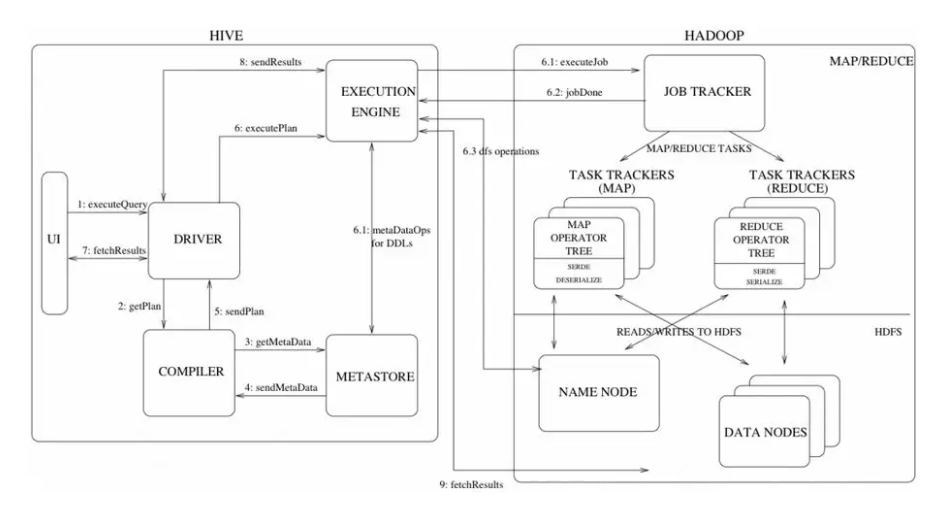
ЖдгкhiveжївЊеыЖдЕФЪЧOLAPгІгУЃЌЦфЕзВуЪЧhdfsЗжВМЪНЮФМўЯЕЭГЃЌhiveвЛАужЛгУгкВщбЏЗжЮіЭГМЦЃЌЖјВЛФмЪЧГЃМћЕФCUDВйзїЃЌHiveашвЊДгвбгаЕФЪ§ОнПтЛђШежОНјааЭЌВНзюжеШыЕНhdfsЮФМўЯЕЭГжаЃЌЕБЧАвЊзіЕНдіСПЪЕЪБЭЌВНЖМЯрЕБРЇФбЁЃ
HiveЕФгХЪЦЪЧЭъЩЦЕФSQLжЇГжЃЌМЋЕЭЕФбЇЯАГЩБОЃЌздЖЈвхЪ§ОнИёЪНЃЌМЋИпЕФРЉеЙадПЩЧсЫЩРЉеЙЕНМИЧЇИіНкЕуЕШЕШЁЃ
ЕЋЪЧHive дкМгдиЪ§ОнЕФЙ§ГЬжаВЛЛсЖдЪ§ОнНјааШЮКЮДІРэЃЌЩѕжСВЛЛсЖдЪ§ОнНјааЩЈУшЃЌвђДЫвВУЛгаЖдЪ§ОнжаЕФФГаЉ
Key НЈСЂЫїв§ЁЃHive вЊЗУЮЪЪ§ОнжаТњзуЬѕМўЕФЬиЖЈжЕЪБЃЌашвЊБЉСІЩЈУшећИіЪ§ОнПтЃЌвђДЫЗУЮЪбгГйНЯИпЁЃ
HiveецЕФЬЋТ§СЫЁЃДѓЪ§ОнСПОлКЯМЦЫуЛђепСЊБэВщбЏЃЌHiveЕФКФЪБЖЏщќвдаЁЪБМЦЫуЃЌдкФГвЛИіЫВМфЃЌЮвЩѕжСЯыАб۝όçóOLAP"ЙњМЎ"ЃЌЕЋЪЧВЛЕУВЛГаШЯHiveШдШЛЪЧЛљгкHadoopЬхЯЕгІгУзюЙуЗКЕФOLAPв§ЧцЁЃ
Hawq
HawqЪЧвЛИіHadoopдЩњДѓЙцФЃВЂааSQLЗжЮів§ЧцЃЌHawqВЩгУ
MPP МмЙЙЃЌИФНјСЫеыЖд Hadoop ЕФЛљгкГЩБОЕФВщбЏгХЛЏЦїЁЃГ§СЫФмИпаЇДІРэБОЩэЕФФкВПЪ§ОнЃЌЛЙПЩЭЈЙ§
PXF ЗУЮЪ HDFSЁЂHiveЁЂHBaseЁЂJSON ЕШЭтВПЪ§ОндДЁЃHAWQШЋУцМцШн SQL БъзМЃЌФмБраД
SQL UDFЃЌЛЙПЩгУ SQL ЭъГЩМђЕЅЕФЪ§ОнЭкОђКЭЛњЦїбЇЯАЁЃЮоТлЪЧЙІФмЬиадЃЌЛЙЪЧадФмБэЯжЃЌHAWQ
ЖМБШНЯЪЪгУгкЙЙНЈ Hadoop ЗжЮіаЭЪ§ОнВжПтгІгУЁЃ
вЛИіЕфаЭЕФHawqМЏШКзщМўШчЯТЃК

ЭјТчЩЯгаШЫЖдHawqгыHiveВщбЏадФмНјааСЫЖдБШВтЪдЃЌзмЬхРДПДЃЌЪЙгУHawqФкВПБэБШHiveПьЕФЖрЃЈ4-50БЖЃЉЁЃ
Spark SQL
SparkSQLЕФЧАЩэЪЧSharkЃЌЫќНЋ
SQL ВщбЏгы Spark ГЬађЮоЗьМЏГЩ,ПЩвдНЋНсЙЙЛЏЪ§ОнзїЮЊ Spark ЕФ RDD НјааВщбЏЁЃSparkSQLзїЮЊSparkЩњЬЌЕФвЛдБМЬајЗЂеЙЃЌЖјВЛдйЪмЯогкHiveЃЌжЛЪЧМцШнHiveЁЃ
Spark SQLдкећИіSparkЬхЯЕжаЕФЮЛжУШчЯТЃК
SparkSQLЕФМмЙЙЭМШчЯТЃК
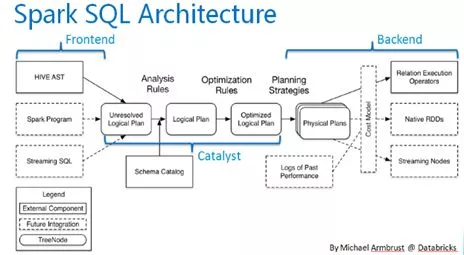
Spark SQLЖдЪьЯЄSparkЕФЭЌбЇРДЫЕЃЌКмШнвзРэНтВЂЩЯЪжЪЙгУЃКЯрБШгкSpark RDD APIЃЌSpark
SQLАќКЌСЫЖдНсЙЙЛЏЪ§ОнКЭдкЦфЩЯдЫЫуЕФИќЖраХЯЂЃЌSpark SQLЪЙгУетаЉаХЯЂНјааСЫЖюЭтЕФгХЛЏЃЌЪЙЖдНсЙЙЛЏЪ§ОнЕФВйзїИќМгИпаЇКЭЗНБуЁЃSQLЬсЙЉСЫвЛИіЭЈгУЕФЗНЪНРДЗУЮЪИїЪНИїбљЕФЪ§ОндДЃЌАќРЈHive,
Avro, Parquet, ORC, JSON, and JDBCЁЃHiveМцШнадМЋКУЁЃ
Presto
Presto is an open source distributed SQL query engine
for running interactive analytic queries against data
sources of all sizes ranging from gigabytes to petabytes.Presto
allows querying data where it lives, including Hive,
Cassandra, relational databases or even proprietary
data stores. A single Presto query can combine data
from multiple sources, allowing for analytics across
your entire organization. Presto is targeted at analysts
who expect response times ranging from sub-second to
minutes. Presto breaks the false choice between having
fast analytics using an expensive commercial solution
or using a slow "free" solution that requires
excessive hardware.
етЪЧPrestoЙйЗНЕФМђНщЁЃPresto ЪЧгЩ Facebook ПЊдДЕФДѓЪ§ОнЗжВМЪН SQL ВщбЏв§ЧцЃЌЪЪгУгкНЛЛЅЪНЗжЮіВщбЏЃЌПЩжЇГжжкЖрЕФЪ§ОндДЃЌАќРЈ
HDFSЃЌRDBMSЃЌKAFKA ЕШЃЌЖјЧвЬсЙЉСЫЗЧГЃгбКУЕФНгПкПЊЗЂЪ§ОндДСЌНгЦїЁЃ
PrestoжЇГжБъзМЕФANSI SQLЃЌАќРЈИДдгВщбЏЁЂОлКЯЃЈaggregationЃЉЁЂСЌНгЃЈjoinЃЉКЭДАПкКЏЪ§ЃЈwindow
functions)ЁЃзїЮЊHiveКЭPigЃЈHiveКЭPigЖМЪЧЭЈЙ§MapReduceЕФЙмЕРСїРДЭъГЩHDFSЪ§ОнЕФВщбЏЃЉЕФЬцДњепЃЌPresto
БОЩэВЂВЛДцДЂЪ§ОнЃЌЕЋЪЧПЩвдНгШыЖржжЪ§ОндДЃЌВЂЧвжЇГжПчЪ§ОндДЕФМЖСЊВщбЏЁЃ
PrestoУЛгаЪЙгУMapReduceЃЌЫќЪЧЭЈЙ§вЛИіЖЈжЦЕФВщбЏКЭжДаав§ЧцРДЭъГЩЕФЁЃЫќЕФЫљгаЕФВщбЏДІРэЪЧдкФкДцжаЃЌетвВЪЧЫќЕФадФмКмИпЕФвЛИіжївЊдвђЁЃPrestoКЭSpark
SQLгаКмДѓЕФЯрЫЦадЃЌетЪЧЫќЧјБ№гкHiveЕФзюИљБОЕФЧјБ№ЁЃ
ЕЋPrestoгЩгкЪЧЛљгкФкДцЕФЃЌЖјhiveЪЧдкДХХЬЩЯЖСаДЕФЃЌвђДЫprestoБШhiveПьКмЖрЃЌЕЋЪЧгЩгкЪЧЛљгкФкДцЕФМЦЫуЕБЖреХДѓБэЙиСЊВйзїЪБвзв§Ц№ФкДцвчГіДэЮѓЁЃ
Kylin
ЬсЕНKylin
ОЭВЛЕУВЛЫЕЫЕROLAPКЭMOLAPЁЃ
ДЋЭГOLAPИљОнЪ§ОнДцДЂЗНЪНЕФВЛЭЌЗжЮЊROLAPЃЈrelational olapЃЉвдМАMOLAPЃЈmulti-dimension
olapЃЉ
ROLAP вдЙиЯЕФЃаЭЕФЗНЪНДцДЂгУзїЖрЮЊЗжЮігУЕФЪ§ОнЃЌгХЕудкгкДцДЂЬхЛ§аЁЃЌВщбЏЗНЪНСщЛюЃЌШЛЖјШБЕувВЯдЖјвзМћЃЌУПДЮВщбЏЖМашвЊЖдЪ§ОнНјааОлКЯМЦЫуЃЌЮЊСЫИФЩЦЖЬАхЃЌROLAPЪЙгУСЫСаДцЁЂВЂааВщбЏЁЂВщбЏгХЛЏЁЂЮЛЭМЫїв§ЕШММЪѕЁЃ
MOLAP НЋЗжЮігУЕФЪ§ОнЮяРэЩЯДцДЂЮЊЖрЮЌЪ§зщЕФаЮЪНЃЌаЮГЩCUBEНсЙЙЁЃЮЌЖШЕФЪєаджЕгГЩфГЩЖрЮЌЪ§зщЕФЯТБъЛђепЯТБъЗЖЮЇЃЌЪТЪЕвдЖрЮЌЪ§зщЕФжЕДцДЂдкЪ§зщЕЅдЊжаЃЌгХЪЦЪЧВщбЏПьЫйЃЌШБЕуЪЧЪ§ОнСПВЛШнвзПижЦЃЌПЩФмЛсГіЯжЮЌЖШБЌеЈЕФЮЪЬтЁЃ
ЖјKylinздЩэОЭЪЧвЛИіMOLAPЯЕЭГЃЌЖрЮЌСЂЗНЬхЃЈMOLAP CubeЃЉЕФЩшМЦЪЙЕУгУЛЇФмЙЛдкKylinРяЮЊАйвквдЩЯЪ§ОнМЏЖЈвхЪ§ОнФЃаЭВЂЙЙНЈСЂЗНЬхНјааЪ§ОнЕФдЄОлКЯЁЃ
Apache KylinЪЧвЛИіПЊдДЕФЗжВМЪНЗжЮів§ЧцЃЌЬсЙЉHadoop/SparkжЎЩЯЕФSQLВщбЏНгПкМАЖрЮЌЗжЮіЃЈOLAPЃЉФмСІвджЇГжГЌДѓЙцФЃЪ§ОнЃЌзюГѕгЩeBay
Inc. ПЊЗЂВЂЙБЯзжСПЊдДЩчЧјЁЃЫќФмдкбЧУыФкВщбЏОоДѓЕФHiveБэЁЃ
KylinЕФгХЪЦгаЃК
ЬсЙЉANSI-SQLНгПк
НЛЛЅЪНВщбЏФмСІ
MOLAP Cube ЕФИХФю
гыBIЙЄОпПЩЮоЗьећКЯ
ЫљвдЪЪКЯKylinЕФГЁОААќРЈЃК
гУЛЇЪ§ОнДцдкгкHadoop HDFSжаЃЌРћгУHiveНЋHDFSЮФМўЪ§ОнвдЙиЯЕЪ§ОнЗНЪНДцШЁЃЌЪ§ОнСПОоДѓЃЌдк500GвдЩЯ
УПЬьгаЪ§GЩѕжСЪ§ЪЎGЕФЪ§ОндіСПЕМШы
га10ИівдФкНЯЮЊЙЬЖЈЕФЗжЮіЮЌЖШ
МђЕЅРДЫЕЃЌKylinжаЪ§ОнСЂЗНЕФЫМЯыОЭЪЧвдПеМфЛЛЪБМфЃЌЭЈЙ§ЖЈвхвЛЯЕСаЕФЮГЖШЃЌЖдУПИіЮГЖШЕФзщКЯНјаадЄЯШМЦЫуВЂДцДЂЁЃгаNИіЮГЖШЃЌОЭЛсга2ЕФNДЮжжзщКЯЁЃЫљвдзюКУПижЦКУЮГЖШЕФЪ§СПЃЌвђЮЊДцДЂСПЛсЫцзХЮГЖШЕФдіМгБЌеЈЪНЕФдіГЄЃЌВњЩњджФбадКѓЙћЁЃ
Impala
ImpalaвВЪЧвЛИіSQL
on HadoopЕФВщбЏЙЄОпЃЌЕзВуВЩгУMPPММЪѕЃЌжЇГжПьЫйНЛЛЅЪНSQLВщбЏЁЃгыHiveЙВЯэдЊЪ§ОнДцДЂЁЃImpaladЪЧКЫаФНјГЬЃЌИКд№НгЪеВщбЏЧыЧѓВЂЯђЖрИіЪ§ОнНкЕуЗжЗЂШЮЮёЁЃstatestoredНјГЬИКд№МрПиЫљгаImpaladНјГЬЃЌВЂЯђМЏШКжаЕФНкЕуБЈИцИїИіImpaladНјГЬЕФзДЬЌЁЃcatalogdНјГЬИКд№ЙуВЅЭЈжЊдЊЪ§ОнЕФзюаТаХЯЂЁЃ
ImpalaЕФМмЙЙЭМШчЯТЃК
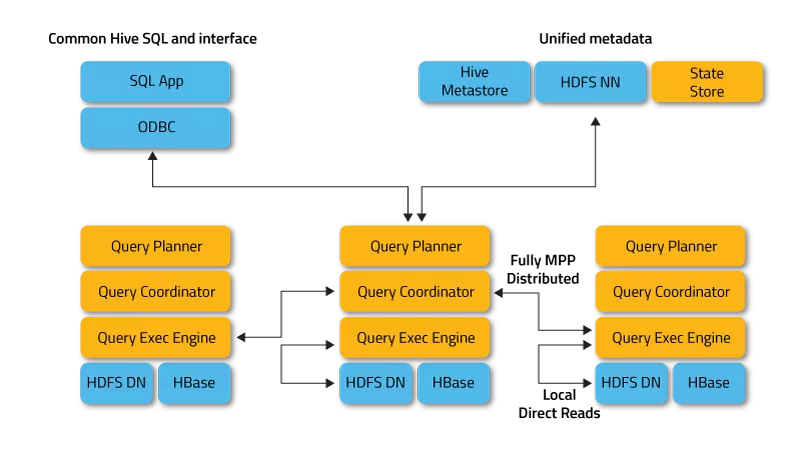
ImpalaЕФЬиадАќРЈЃК
жЇГжParquetЁЂAvroЁЂTextЁЂRCFileЁЂSequenceFileЕШЖржжЮФМўИёЪН
жЇГжДцДЂдкHDFSЁЂHBaseЁЂAmazon S3ЩЯЕФЪ§ОнВйзї
жЇГжЖржжбЙЫѕБрТыЗНЪНЃКSnappyЁЂGzipЁЂDeflateЁЂBzip2ЁЂLZO
жЇГжUDFКЭUDAF
здЖЏвдзюгааЇЕФЫГађНјааБэСЌНг
дЪаэЖЈвхВщбЏЕФгХЯШМЖХХЖгВпТд
жЇГжЖргУЛЇВЂЗЂВщбЏ
жЇГжЪ§ОнЛКДц
ЬсЙЉМЦЫуЭГМЦаХЯЂЃЈCOMPUTE STATSЃЉ
ЬсЙЉДАПкКЏЪ§ЃЈОлКЯ OVER PARTITION, RANK, LEAD, LAG, NTILEЕШЕШЃЉвджЇГжИпМЖЗжЮіЙІФм
жЇГжЪЙгУДХХЬНјааСЌНгКЭОлКЯЃЌЕБВйзїЪЙгУЕФФкДцвчГіЪБзЊЮЊДХХЬВйзї
дЪаэдкwhereзгОфжаЪЙгУзгВщбЏ
дЪаэдіСПЭГМЦЁЊЁЊжЛдкаТЪ§ОнЛђИФБфЕФЪ§ОнЩЯжДааЭГМЦМЦЫу
жЇГжmapsЁЂstructsЁЂarraysЩЯЕФИДдгЧЖЬзВщбЏ
ПЩвдЪЙгУimpalaВхШыЛђИќаТHBase
ЭЌбљЃЌImpalaОГЃЛсКЭHiveЁЂPrestoЗХдквЛЦ№зіБШНЯЃЌImpalaЕФСгЪЦвВЭЌбљУїЯдЃК
ImpalaВЛЬсЙЉШЮКЮЖдађСаЛЏКЭЗДађСаЛЏЕФжЇГжЁЃ
ImpalaжЛФмЖСШЁЮФБОЮФМўЃЌЖјВЛФмЖСШЁздЖЈвхЖўНјжЦЮФМўЁЃ
УПЕБаТЕФМЧТМ/ЮФМўБЛЬэМгЕНHDFSжаЕФЪ§ОнФПТМЪБЃЌИУБэашвЊБЛЫЂаТЁЃетИіШБЕуЛсЕМжТе§дкжДааЕФВщбЏsqlгіЕНЫЂаТЛсЙвЦ№ЃЌВщбЏВЛЖЏЁЃ
Druid
Druid
ЪЧвЛжжФмЖдРњЪЗКЭЪЕЪБЪ§ОнЬсЙЉбЧУыМЖБ№ЕФВщбЏЕФЪ§ОнДцДЂЁЃDruid жЇГжЕЭбгЪБЕФЪ§ОнЩуШЁЃЌСщЛюЕФЪ§ОнЬНЫїЗжЮіЃЌИпадФмЕФЪ§ОнОлКЯЃЌМђБуЕФЫЎЦНРЉеЙЁЃЪЪгУгкЪ§ОнСПДѓЃЌПЩРЉеЙФмСІвЊЧѓИпЕФЗжЮіаЭВщбЏЯЕЭГЁЃ
DruidНтОіЕФЮЪЬтАќРЈЃКЪ§ОнЕФПьЫйЩуШыКЭЪ§ОнЕФПьЫйВщбЏЁЃЫљвдвЊРэНтDruidЃЌашвЊНЋЦфРэНтЮЊСНИіЯЕЭГЃЌМДЪфШыЯЕЭГКЭВщбЏЯЕЭГЁЃ
DruidЕФМмЙЙШчЯТЃК
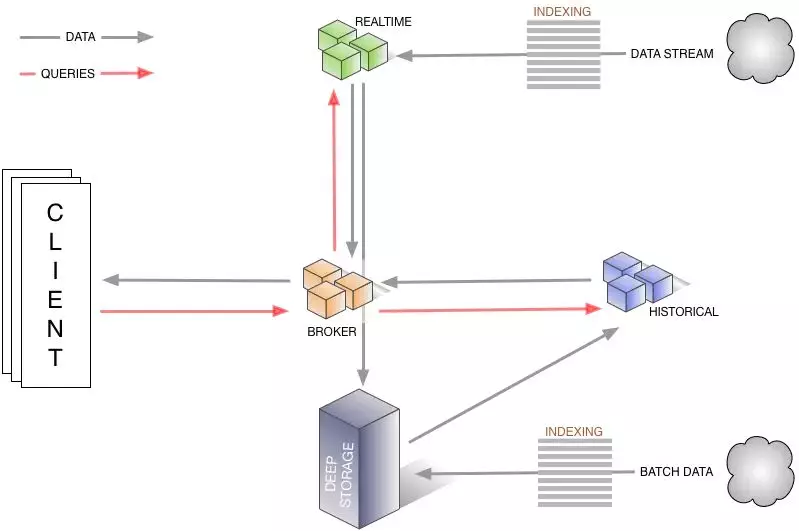
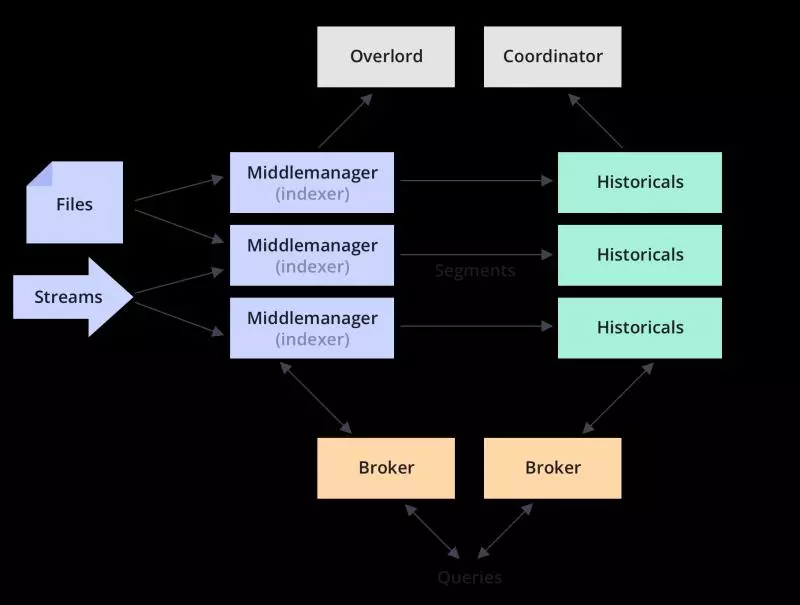
DruidЕФЬиЕуАќРЈЃК
DruidЪЕЪБЕФЪ§ОнЯћЗбЃЌеце§зіЕНЪ§ОнЩуШыЪЕЪБЁЂВщбЏНсЙћЪЕЪБ
DruidжЇГж PB МЖЪ§ОнЁЂЧЇвкМЖЪТМўПьЫйДІРэЃЌжЇГжУПУыЪ§ЧЇВщбЏВЂЗЂ
DruidЕФКЫаФЪЧЪБМфађСаЃЌАбЪ§ОнАДееЪБМфађСаЗжХњДцДЂЃЌЪЎЗжЪЪКЯгУгкЖдАДЪБМфНјааЭГМЦЗжЮіЕФГЁОА
DruidАбЪ§ОнСаЗжЮЊШ§РрЃКЪБМфДСЁЂЮЌЖШСаЁЂжИБъСа
DruidВЛжЇГжЖрБэСЌНг
DruidжаЕФЪ§ОнвЛАуЪЧЪЙгУЦфЫћМЦЫуПђМм(SparkЕШ)дЄМЦЫуКУЕФЕЭВуДЮЭГМЦЪ§Он
DruidВЛЪЪКЯгУгкДІРэЭИЪгЮЌЖШИДдгЖрБфЕФВщбЏГЁОА
DruidЩУГЄЕФВщбЏРраЭБШНЯЕЅвЛЃЌвЛаЉГЃгУЕФSQL(groupby ЕШ)гяОфдкdruidРядЫааЫйЖШвЛАу
DruidжЇГжЕЭбгЪБЕФЪ§ОнВхШыЁЂИќаТЃЌЕЋЪЧБШhbaseЁЂДЋЭГЪ§ОнПтвЊТ§КмЖр
гыЦфЫћЕФЪБађЪ§ОнПтРрЫЦЃЌDruidдкВщбЏЬѕМўУќжаДѓСПЪ§ОнЧщПіЯТПЩФмЛсгаадФмЮЪЬтЃЌЖјЧвХХађЁЂОлКЯЕШФмСІЦеБщВЛЬЋКУЃЌСщЛюадКЭРЉеЙадВЛЙЛЃЌБШШчШБЗІJoinЁЂзгВщбЏЕШЁЃ
ЮвИіШЫЖдDruidЕФРэНтдкгкЃЌDruidБЃжЄЪ§ОнЪЕЪБаДШыЃЌЕЋВщбЏЩЯЖдSQLжЇГжЕФВЛЙЛЭъЩЦ(ВЛжЇГжJoin)ЃЌЪЪКЯНЋЧхЯДКУЕФМЧТМЪЕЪБТМШыЃЌШЛКѓбИЫйВщбЏАќКЌРњЪЗЕФНсЙћЃЌдкЮвУЧФПЧАЕФвЕЮёЩЯУЛгаЪЕМЪгІгУЁЃ
Greeplum
GreenplumЪЧвЛИіПЊдДЕФДѓЙцФЃВЂааЪ§ОнЗжЮів§ЧцЁЃНшжњMPPМмЙЙЃЌдкДѓаЭЪ§ОнМЏЩЯжДааИДдгSQLЗжЮіЕФЫйЖШБШКмЖрНтОіЗНАИЖМвЊПьЁЃ
GPDBЭъШЋжЇГжANSI SQL 2008БъзМКЭSQL OLAP 2003 РЉеЙЃЛДггІгУБрГЬНгПкЩЯНВЃЌЫќжЇГжODBCКЭJDBCЁЃЭъЩЦЕФБъзМжЇГжЪЙЕУЯЕЭГПЊЗЂЁЂЮЌЛЄКЭЙмРэЖМДѓЮЊЗНБуЁЃжЇГжЗжВМЪНЪТЮёЃЌжЇГжACIDЁЃБЃжЄЪ§ОнЕФЧПвЛжТадЁЃзіЮЊЗжВМЪНЪ§ОнПтЃЌгЕгаСМКУЕФЯпадРЉеЙФмСІЁЃGPDBгаЭъЩЦЕФЩњЬЌЯЕЭГЃЌПЩвдгыКмЖрЦѓвЕМЖВњЦЗМЏГЩЃЌЦЉШчSASЃЌCognosЃЌInformaticЃЌTableauЕШЃЛвВПЩвдКмЖржжПЊдДШэМўМЏГЩЃЌЦЉШчPentaho,Talend
ЕШЁЃ
GreenPulmЕФМмЙЙШчЯТЃК
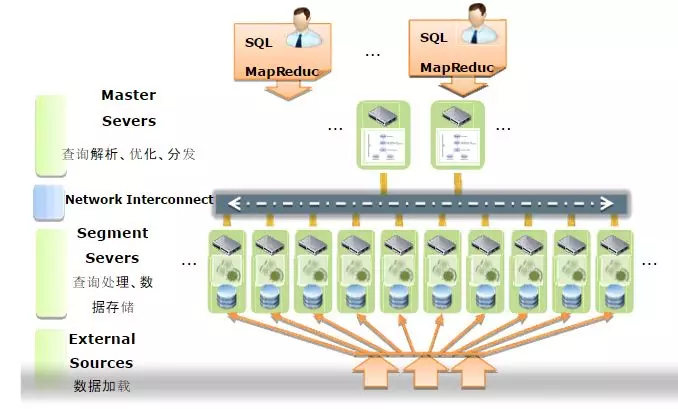
GreenPulmЕФММЪѕЬиЕуШчЯТЃК
жЇГжКЃСПЪ§ОнДцДЂКЭДІРэ
жЇГжJust In Time BIЃКЭЈЙ§зМЪЕЪБЁЂЪЕЪБЕФЪ§ОнМгдиЗНЪНЃЌЪЕЯжЪ§ОнВжПтЕФЪЕЪБИќаТЃЌНјЖјЪЕЯжЖЏЬЌЪ§ОнВжПтЃЈADWЃЉЃЌЛљгкЖЏЬЌЪ§ОнВжПтЃЌвЕЮёгУЛЇФмЖдЕБЧАвЕЮёЪ§ОнНјааBIЪЕЪБЗжЮіЃЈJust
In Time BIЃЉ
жЇГжжїСїЕФsqlгяЗЈЃЌЪЙгУЦ№РДЪЎЗжЗНБуЃЌбЇЯАГЩБОЕЭ
РЉеЙадКУЃЌжЇГжЖргябдЕФздЖЈвхКЏЪ§КЭздЖЈвхРраЭЕШ
ЬсЙЉСЫДѓСПЕФЮЌЛЄЙЄОпЃЌЪЙгУЮЌЛЄЦ№РДКмЗНБу
жЇГжЯпадРЉеЙЃКВЩгУMPPВЂааДІРэМмЙЙЁЃдкMPPНсЙЙжадіМгНкЕуОЭПЩвдЯпадЬсЙЉЯЕЭГЕФДцДЂШнСПКЭДІРэФмСІ
НЯКУЕФВЂЗЂжЇГжМАИпПЩгУаджЇГжГ§СЫЬсЙЉгВМўМЖЕФRaidММЪѕЭтЃЌЛЙЬсЙЉЪ§ОнПтВуMirrorЛњжЦБЃЛЄЃЌЬсЙЉMaster/Stand
byЛњжЦНјаажїНкЕуШнДэЃЌЕБжїНкЕуЗЂЩњДэЮѓЪБЃЌПЩвдЧаЛЛЕНStand byНкЕуМЬајЗўЮё
жЇГжMapReduce
Ъ§ОнПтФкВПбЙЫѕ
вЛИіживЊЕФаХЯЂЃКGreenplumЛљгкPostgresqlЃЌвВОЭЪЧЫЕGreenPulmКЭTiDBЕФЖЈЮЛРрЫЦЃЌЯывЊдкOLTPКЭOLAPЩЯНјааЭГвЛЁЃ
ClickHouse
ЙйЭјЖдXClickHouseЕФНщЩмЃК
ClickHouse is an open source column-oriented database
management system capable of real time generation
of analytical data reports using SQL queries.
ClickhouseгЩЖэТоЫЙyandexЙЋЫОПЊЗЂЁЃзЈЮЊдкЯпЪ§ОнЗжЮіЖјЩшМЦЁЃYandexЪЧЖэТоЫЙЫбЫїв§ЧцЙЋЫОЁЃЙйЗНЬсЙЉЕФЮФЕЕБэУћЃЌClickHouse
ШеДІРэМЧТМЪ§"ЪЎвкМЖ"ЁЃ
Ьиад:ВЩгУСаЪНДцДЂЃЛЪ§ОнбЙЫѕЃЛжЇГжЗжЦЌЃЌВЂЧвЭЌвЛИіМЦЫуШЮЮёЛсдкВЛЭЌЗжЦЌЩЯВЂаажДааЃЌМЦЫуЭъГЩКѓЛсНЋНсЙћЛузмЃЛжЇГжSQLЃЛжЇГжСЊБэВщбЏЃЛжЇГжЪЕЪБИќаТЃЛздЖЏЖрИББОЭЌВНЃЛжЇГжЫїв§ЃЛЗжВМЪНДцДЂВщбЏЁЃ
ДѓМвЖМNginxВЛФАЩњАЩЃЌеНЖЗУёзхПЊдДЕФШэМўЦеБщЕФЬиЕуАќРЈЃКЧсСПМЖЃЌПьЁЃ
ClickHouseзюДѓЕФЬиЕуОЭЪЧПьЃЌПьЃЌПьЃЌживЊЕФЛАЫЕШ§БщЃЁгыHadoopЁЂSparkетаЉОоЮоАдзщМўЯрБШЃЌClickHouseКмЧсСПМЖЃЌЦфЬиЕуЃК
СаЪНДцДЂЪ§ОнПтЃЌЪ§ОнбЙЫѕ
ЙиЯЕаЭЁЂжЇГжSQL
ЗжВМЪНВЂааМЦЫуЃЌАбЕЅЛњадФмбЙеЅЕНМЋЯо
ИпПЩгУ
Ъ§ОнСПМЖдкPBМЖБ№
ЪЕЪБЪ§ОнИќаТ
Ыїв§
ЪЙгУClickHouseвВгаЦфБОЩэЕФЯожЦЃЌАќРЈЃК
ШБЩйИпЦЕТЪЃЌЕЭбгГйЕФаоИФЛђЩОГ§вбДцдкЪ§ОнЕФФмСІЁЃНіФмгУгкХњСПЩОГ§ЛђаоИФЪ§ОнЁЃ
УЛгаЭъећЕФЪТЮёжЇГж
ВЛжЇГжЖўМЖЫїв§
гаЯоЕФSQLжЇГжЃЌjoinЪЕЯжгыжкВЛЭЌ
ВЛжЇГжДАПкЙІФм
дЊЪ§ОнЙмРэашвЊШЫЙЄИЩдЄЮЌЛЄ
змНс
ЩЯУцИјГіСЫГЃгУЕФвЛаЉOLAPв§ЧцЃЌЫќУЧИїздгаИїздЕФЬиЕуЃЌЮвУЧНЋЦфЗжзщЃК
HiveЃЌHawqЃЌImpala - ЛљгкSQL on Hadoop
PrestoКЭSpark SQLРрЫЦ - ЛљгкФкДцНтЮіSQLЩњГЩжДааМЦЛЎ
Kylin - гУПеМфЛЛЪБМфЃЌдЄМЦЫу
Druid - вЛИіжЇГжЪ§ОнЕФЪЕЪБЩуШы
ClickHouse - OLAPСьгђЕФHbaseЃЌЕЅБэВщбЏадФмгХЪЦОоДѓ
Greenpulm - OLAPСьгђЕФPostgresql
ШчЙћФуЕФГЁОАЪЧЛљгкHDFSЕФРыЯпМЦЫуШЮЮёЃЌФЧУДHiveЃЌHawqКЭImaplaОЭЪЧФуЕФЕїбаФПБъЃЛШчЙћФуЕФГЁОАНтОіЗжВМЪНВщбЏЮЪЬтЃЌгавЛЖЈЕФЪЕЪБадвЊЧѓЃЌФЧУДPrestoКЭSparkSQLПЩФмИќЗћКЯФуЕФЦкЭћЃЛШчЙћФуЕФЛузмЮЌЖШБШНЯЙЬЖЈЃЌЪЕЪБадвЊЧѓНЯИпЃЌПЩвдЭЈЙ§гУЛЇХфжУЕФЮЌЖШ+жИБъНјаадЄМЦЫуЃЌФЧУДВЛЗСГЂЪдKylinКЭDruidЃЛClickHouseдђдкЕЅБэВщбЏадФмЩЯЖРСьЗчЩЇЃЌдЖГЌЙ§ЦфЫћЕФOLAPЪ§ОнПтЃЛGreenpulmзїЮЊЙиЯЕаЭЪ§ОнПтВњЦЗЃЌадФмПЩвдЫцзХМЏШКЕФРЉеЙЯпаддіГЄЃЌИќМгЪЪКЯНјааЪ§ОнЗжЮіЁЃ
ОЭЯёУРЭХдкЕїбаKylinЕФБЈИцжаЫљЫЕЕФЃК
ФПЧАЛЙУЛгавЛИіOLAPЯЕЭГФмЙЛТњзуИїжжГЁОАЕФВщбЏашЧѓЁЃЦфБОжЪдвђЪЧЃЌУЛгавЛИіЯЕЭГФмЭЌЪБдкЪ§ОнСПЁЂадФмЁЂКЭСщЛюадШ§ИіЗНУцзіЕНЭъУРЃЌУПИіЯЕЭГдкЩшМЦЪБЖМашвЊдкетШ§епМфзіГіШЁЩсЁЃ
|









