| БрМЭЦМі: |
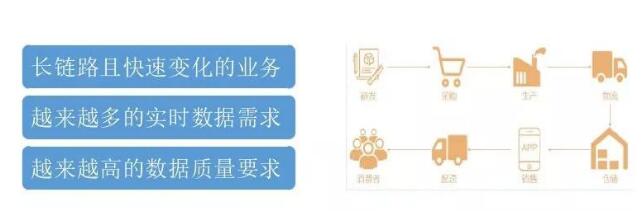
БОЦЊЪзЯШЛсНщЩмЯТбЯбЁЪЕЪБЪ§ВжЕФБГОАЁЂВњЩњЕФвЛаЉЮЪЬтЁЃШЛКѓЪЧеыЖдетаЉБГОАКЭЮЪЬтЖдЪЕЪБЪ§ВжЕФећЬхЩшМЦКЭОпЬхЕФЪЕЪЉЗНАИЃЌНгзХЛсНщЩмЯТдкЪЕЪБЪ§ВжЕФЪ§ОнжЪСПЗНУцЕФЙЄзїЃЌзюКѓНВвЛЯТЪЕЪБЪ§ВждкбЯбЁжаЕФгІгУГЁОАЁЃ
БОЮФРДздИіШЫЭМЪщЙнЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
1ЁЂБГОА
бЯбЁЪЕЪБЪ§ВжЯюФПЪЧДг17ФъЯТАыФъПЊЪМзіЕФЃЌБГОАзмНсЮЊШ§ИіЗНУцЃК
ЕквЛИіЪЧГЄСДТЗЧвПьЫйБфЛЏЕФвЕЮёЃЌбЯбЁзїЮЊвЛИіODMЕчЩЬЃЌећИівЕЮёСДЖШДгЩЬЦЗВЩЙКЁЂЩњВњЁЂВжПтЁЂЕНЯњЪлетИіНзЖЮПЩвддкжїеОAPPЩЯЙКТђЛђепЗжГЇЙКТђЃЌШЛКѓЭЈЙ§ЩЬЛЇХфЫЭЕНДяЯћЗбепЁЃСДЖШЪЧЗЧГЃГЄЕФЃЌетвВОіЖЈЪ§ОнЕФЪ§ОнгђЗЧГЃЙуЃЛбЯбЁзїЮЊвЛИіГЩГЄЕФЕчЩЬЃЌЛсгаКмЖраТЕФвЕЮёГіЯжЁЃ
ЕкЖўИіЪЧдНРДдНЖрЕФЪЕЪБЪ§ОнашЧѓЃЌФПЧАашвЊИќЖрЕФЪЕЪБЪ§ОнРДзівЕЮёОіВпЃЌашвЊвРОнЯњЪлЧщПізівЛИізЪдДЮЛЕФЕїећЃЛЭЌЪБгааЉЛюЖЏвВашвЊЪЕЪБЪ§ОнРДдіЧПгыгУЛЇЕФЛЅЖЏЁЃШчЙћЪ§ОнгаЪЕЪБКЭРыЯпСНжжЗНАИЃЌгХЯШПМТЧЪЕЪБЕФЃЌШчЙћЪЕЪБЪЕЯжВЛСЫдйПМТЧРыЯпЕФЗНЪНЁЃ
ЕкШ§ИіОЭЪЧдНРДдНИпЕФЪ§ОнжЪСПвЊЧѓЃЌвђЮЊЪ§ОнЛсжБНггАЯьвЕЮёОіВпЃЌгАЯьЯпЩЯдЫгЊЛюЖЏаЇЙћЃЌвђДЫЖдЪ§ОнжЪСПЕФвЊЧѓдНРДдНИпЁЃ
еыЖдетбљЕФЯюФПБГОАЬсГіСЫШ§ИіЩшМЦФПБъЃЌЕквЛИіЪЧСщЛюПЩРЉеЙЃЌЕкЖўИіЪЧПЊЗЂаЇТЪИпЃЌЕкШ§ИіЪЧЪ§ОнжЪСПвЊЧѓИпЁЃ
2ЁЂећЬхЩшМЦКЭЪЕЯж
ЛљгкетбљЕФЩшМЦФПБъЃЌНщЩмвЛЯТећЬхЕФЩшМЦКЭЪЕЯжЗНАИЃК
ЪЕЪБЪ§ВжећЬхПђМмвРОнЪ§ОнЕФСїЯђЗжЮЊВЛЭЌЕФВуДЮЃЌНгШыВуЛсвРОнИїжжЪ§ОнНгШыЙЄОпЪеМЏИїИівЕЮёЯЕЭГЕФЪ§ОнЃЌШчТђЕуЕФвЕЮёЪ§ОнЛђепвЕЮёКѓЬЈЕФВЂЙКЗХЕНЯћЯЂЖгСаРяУцЁЃЯћЯЂЖгСаЕФЪ§ОнМШЪЧРыЯпЪ§ВжЕФдЪМЪ§ОнЃЌвВЪЧЪЕЪБМЦЫуЕФдЪМЪ§ОнЃЌетбљПЩвдБЃжЄЪЕЪБКЭРыЯпЕФдЪМЪ§ОнЪЧЭГвЛЕФЁЃгаСЫдДЪ§ОнЃЌдкМЦЫуВуОЙ§FLink+ЪЕЪБМЦЫув§ЧцзівЛаЉМгЙЄДІРэЃЌШЛКѓТфЕиЕНДцДЂВужаВЛЭЌДцДЂНщжЪЕБжаЁЃВЛЭЌЕФДцДЂНщжЪЪЧвРОнВЛЭЌЕФгІгУГЁОАРДбЁдёЁЃПђМмжаЛЙгаFLinkКЭKafkaЕФНЛЛЅЃЌдкЪ§ОнЩЯНјаавЛИіЗжВуЩшМЦЃЌМЦЫув§ЧцДгKafkaжаРЬШЁЪ§ОнзівЛаЉМгЙЄШЛКѓЗХЛиKafkaЁЃдкДцДЂВуМгЙЄКУЕФЪ§ОнЛсЭЈЙ§ЗўЮёВуЕФСНИіЗўЮёЃКЭГвЛВщбЏЁЂжИБъЙмРэЃЌЭГвЛВщбЏЪЧЭЈЙ§вЕЮёЗНЕїШЁЪ§ОнНгПкЕФвЛИіЗўЮёЃЌжИБъЙмРэЪЧЖдЪ§ОнжИБъЕФЖЈвхКЭЙмРэЙЄзїЁЃЭЈЙ§ЗўЮёВугІгУЕНВЛЭЌЕФЪ§ОнгІгУЃЌЪ§ОнгІгУПЩФмЪЧЮвУЧЕФе§ЪНВњЦЗЛђепжБНгЕФвЕЮёЯЕЭГЁЃКѓУцЛсДгЪ§ОнЕФЗжВуЩшМЦКЭОпЬхЕФЪЕЯжСНИіЗНУцНщЩмЁЃ
ЩЯУцЪЧЖдЪ§ОнЕФећЬхЩшМЦЃЌжївЊВЮПМСЫРыЯпЪ§ВжЕФЩшМЦЗНАИЃЌвВВЮПМСЫвЕНчЭЌааЕФвЛаЉзіЗЈЁЃНЋЪ§ОнЗжЮЊЫФИіВуДЮЃК
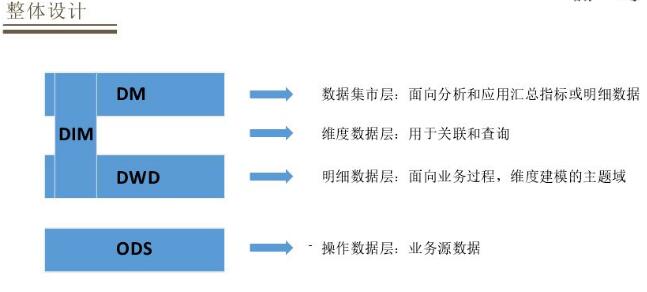
ЪзЯШЪЧODSВуЃЌМДВйзїЪ§ОнВуЃЌЭЈЙ§Ъ§ОнВЩМЏЙЄОпЪеМЏИїИівЕЮёдДЪ§ОнЃЛDWDВуЃЌУїЯИЪ§ОнВуЪЧАДжїЬтгђРДЛЎЗжЃЌЭЈЙ§ЮЌЖШНЈФЃЗНЪНРДзщжЏИїИівЕЮёЙ§ГЬЕФУїЯИЪ§ОнЁЃжаМфЛсгавЛИіDIMВуЃЌЮЌЖШЪ§ОнВужївЊзівЛаЉВщбЏКЭЙиСЊЕФВйзїЁЃзюЩЯВуЪЧDMВуЃЌЭЈЙ§DWDВуЪ§ОнзівЛаЉжИБъМгЙЄЃЌжївЊУцЯђвЛаЉЗжЮіКЭгІгУЛузмЕФжИБъЛђепЪЧзіЖрЮЌЗжЮіЕФУїЯИЪ§ОнЁЃ
ОйР§ЫЕУївЛЯТЪ§ОнЩшМЦСїЯђЙ§ГЬЃЌМйШчвЊЖдбЯбЁжїРрФПЩЯЕБЬьЯњЪлКЭСїСПЕФЭГМЦЃЌЭГМЦУПИіРрФПЕФЯњЪлСПКЭСїСПДгODSВуРДдДСНВПЗжЃЌвЛВПЗжРДздЗУЮЪЃЌетЪЧРДдДгкТёЕуЪ§ОнЃЌетжжЪ§ОнЭЈГЃБШНЯЙцЗЖЃЌЭЈЙ§вЛаЉМђЕЅМгЙЄЃЌдкDWDВуаЮГЩвЛеХЩЬЦЗЗУЮЪУїЯИБэЃЛНЛвзЪ§ОнРДздНЛвзУїЯИБэЃЌдкODSВуРДдДгкЖЉЕЅБэКЭЖЉЕЅЙКЮяГЕБэЁЃНЋСНИіБэЛуОлдкDWDВуаЮГЩвЛИіНЛвзгђЕФНЛвзУїЯИБэЃЌвђЮЊЭГМЦашвЊЭГМЦЕНРрФПЮЌЖШЃЌЫљвдДгDWDВуЯђDMМгЙЄашвЊДгЩЬЦЗЮЌЖШБэзівЛИіЙиСЊЃЌетбљОЭПЩвддкDMВузівЛаЉЛузмЭГМЦЃЌОЭПЩвдаЮГЩDMЫљашвЊЕФжИБъЪ§ОнЁЃетРяЕФЪ§ОнЗжЮЊСНРрЃЌвЛжжЪЧЪЕЪБЕФЃЌвЛжжЪЧзМЪЕЪБЃЛШчЙћЮЌЖШБШНЯИДдгЃЌШчзМЪЕЪБЕЏФЛзівЛаЉХфжУРДзіЕНЭЌВНЃЌШчЙћгавЛаЉЙиСЊЙиЯЕБШНЯМђЕЅЕФОЭзіГЩЪЕЪБЮЌБэЁЃетбљЕФКУДІЪЧФмЪЕЪБЭГМЦЃЌФмБШНЯжБЙлЙлВьЁЃ
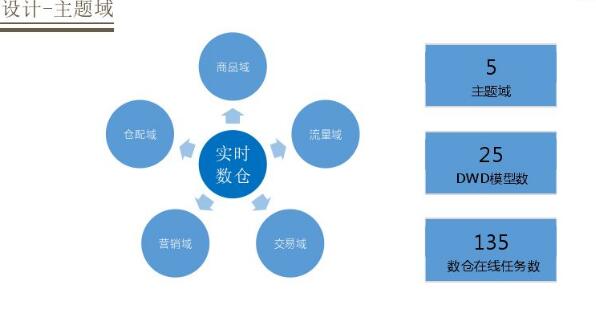
ЪЕЪБЪ§ВжЩшМЦЗжЮЊ5ИіжїЬтгђЃЌЗжБ№ЪЧЩЬЦЗЁЂСїСПЁЂНЛвзЁЂгЊЯњЁЂВжХфЁЃдкетЮхИіжїЬтгђЯТГСЕэСЫ25ИіФЃаЭЃЌећИіЪЕЪБЪ§ВждкЯпШЮЮёЪ§ДяЕН135ЁЃЛљгкетбљЕФЩшМЦЗНАИФмећЬхЪЕЯжЩшМЦФПБъЁЃ

ЪзЯШЭЈЙ§жїЬхгђЕФФЃаЭИДгУФмЙЛЬсИпПЊЗЂаЇТЪЃЌзюГЃгУЕФОЭЪЧНЛвзгђЕФЪЕЪБЪ§ОнЁЃНЛвзгђЕФНЛвзУїЯИФЃаЭФмЙЛВњЩњЖрИіМЏЪаВуФЃаЭЃЌНЛвзУїЯИЕФзжЖЮЧхЯДБШНЯЙцЗЖЃЌвЛАуСНЬьОЭФмПЊЗЂвЛИіФЃаЭЃЌШчЙћФЃаЭМђЕЅвЛЬьОЭФмИуЖЈЁЃЕкЖўИіОЭЪЧБШНЯСщЛюЃЌдкDWDВуЗтзАвЛаЉвЕЮёТпМЃЌПьЫйгІЖдвЛаЉвЕЮёЕїећЁЃОйР§ЫЕУїЯТЃЌбЯбЁЩЯЯпвЛИіжкГявЕЮёЃЌЯШЧАЖдНЛвзЖЈвхЖМЪЧвджЇИЖРДЫуЃЌЕЋЪЧжкГяНЛвзКЭжЇИЖЯрИєЪБМфНЯГЄЃЌЖдгкРыЯпжЛашвЊЛюЖЏНсЪјдйНјааЭГМЦЃЌЕЋЪЧЪЕЪБжЛЙизЂгкЕБЬьЪ§ОнЃЌетИіЪБКђЭГМЦОЭУЛгавтвхЁЃвђДЫашвЊНЋжкГяЪ§ОнЬоГ§ЃЌЪЕЯжЪБжЛашвЊдкНЛвзУїЯИРяУцНјааЙ§ТЫЃЌетбљМЏЪаВуЫљгажИБъЪ§ОнЖМЭГвЛИќИФЕєЁЃЕкШ§ИіОЭЪЧЭГвЛЃЌЪ§ОнЖМЪЧАДеевЕЮёгђЛЎЗжЃЌЙмРэКЭЮЌЛЄЖМБШНЯЗНБуЃЌЖдгкПЊЗЂзЪдДЗжХфвВБШНЯБуРћЁЃ
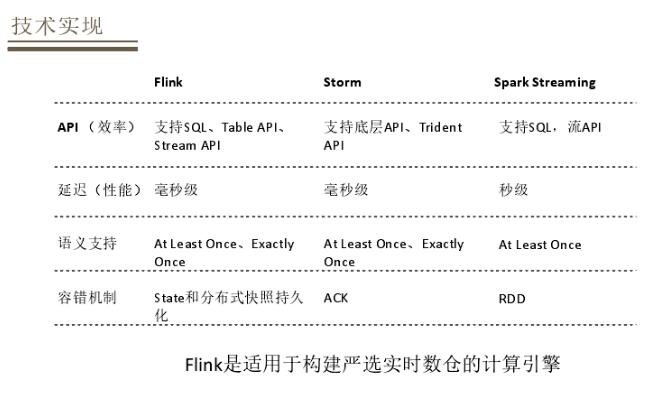
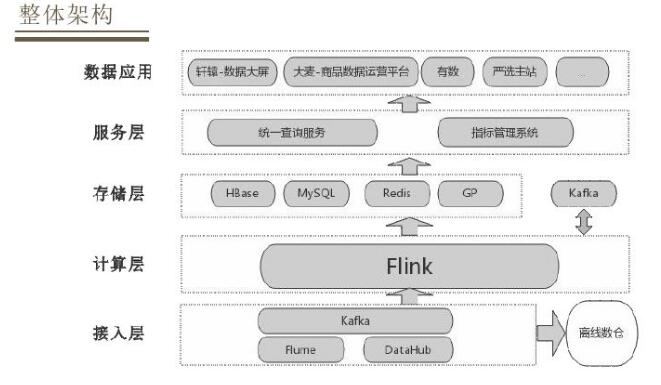
ШЛКѓНщЩмЯТММЪѕЪЕЯжЗНУцЕФПМСПЃЌжївЊЗжЮЊМЦЫуКЭДцДЂЁЃЖдгкМЦЫуЗНУцЃЌгаКмЖрЪЕЪБМЦЫув§ЧцЃЌгаFlinkЁЂStormЁЂSpark
StreamingЃЌFlinkЯрЖдгкStormЕФгХЪЦОЭЪЧжЇГжSQLЃЌЯрЖдгкSpark StreamingгжгавЛИіЯрЖдКУЕФадФмБэЯжЁЃЭЌЪБFlinkдкжЇГжКУЕФгІгУКЭадФмЗНУцЛЙгаБШНЯКУЕФгявхжЇГжКЭБШНЯКУЕФШнДэЛњжЦЃЌвђДЫЙЙНЈЪЕЪБЪ§ВжFlinkЪЧвЛИіБШНЯКУЕФЪЕЪБМЦЫув§ЧцбЁдёЁЃ
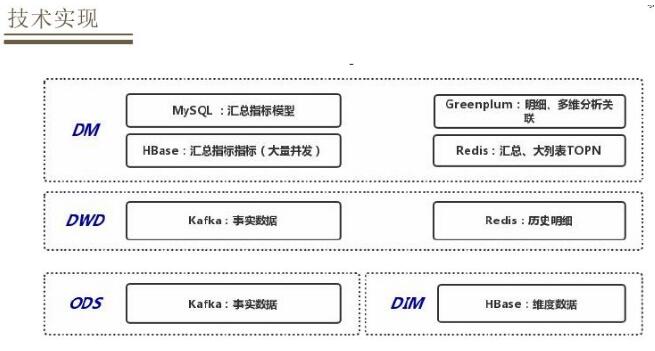
ЖдгкДцДЂВуЛсвРОнВЛЭЌЕФЪ§ОнВуЕФЬиЕубЁдёВЛЭЌЕФДцДЂНщжЪЃЌODSВуКЭDWDВуЖМЪЧДцДЂЕФвЛаЉЪЕЪБЪ§ОнЃЌбЁдёЕФЪЧKafkaНјааДцДЂЃЌдкDWDВуЛсЙиСЊвЛаЉРњЪЗУїЯИЪ§ОнЃЌЛсНЋЦфЗХЕНRedisРяУцЁЃдкDIMВужївЊзівЛаЉИпВЂЗЂЮЌЖШЕФВщбЏЙиСЊЃЌвЛАуНЋЦфДцЗХдкHBaseРяУцЃЌЖдгкDIMВуБШМлИДдгЃЌашвЊзлКЯПМТЧЖдгкЪ§ОнТфЕиЕФвЊЧѓвдМАОпЬхЕФВщбЏв§ЧцРДбЁдёВЛЭЌЕФДцДЂЗНЪНЁЃЖдгкГЃМћЕФжИБъЛузмФЃаЭжБНгЗХдкMySQLРяУцЃЌЮЌЖШБШНЯЖрЕФЁЂаДШыИќаТБШНЯДѓЕФФЃаЭЛсЗХдкHBaseРяУцЃЌЛЙгаУїЯИЪ§ОнашвЊзівЛаЉЖрЮЌЗжЮіЛђепЙиСЊЛсНЋЦфДцДЂдкGreenplumРяУцЃЌЛЙгавЛжжЪЧЮЌЖШБШНЯЖрЁЂашвЊзіХХађЁЂВщбЏвЊЧѓБШНЯИпЕФЃЌШчЛюЖЏЦкМфгУЛЇЕФЯњЪлСаБэЕШДѓСаБэжБНгДцДЂдкRedisРяУцЁЃ
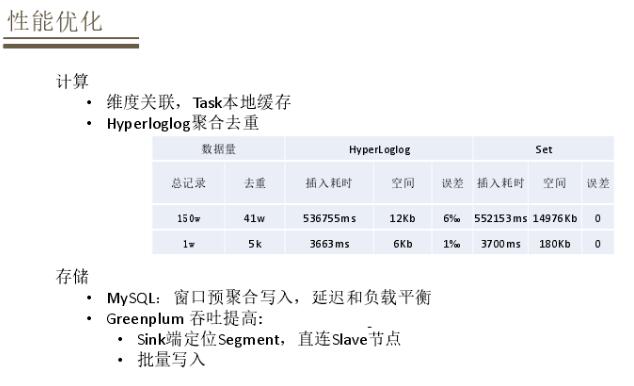
адФмгХЛЏЗНУцЃЌдкМЦЫужаВЩгУКмЖрЮЌЖШЙиСЊЃЌШчЙћУПвЛДЮЮЌЖШЙиСЊЖМДгHBaseжаЕїгУадФмЪмЯоЃЌвђДЫНЋЮЌЖШЪ§ОндкБОЕиtaskНјаавЛДЮЛКДцЁЃОлКЯШЅжигУвЛаЉОЋЖШШЅжиЫуЗЈЃЌШчHyperloglogЃЌМШФмБЃжЄдквЛИіПЩНгЪмЕФЪ§ОнЭГМЦЮѓВюЃЌгжФмБШНЯКУЕФгХЛЏДцДЂЁЃДцДЂЗНУцжївЊеыЖдMySQLКЭGreenplumСНжжГЁОАЃЌдкДѓЪ§ОнГЁОАЯТMySQLаДШыбЙСІБШНЯИпЃЌдкаДШыжЎЧАзівЛИіДАПкдЄОлКЯЃЌЪЕЯжбгГйКЭИКдиОљКтЃЌНЯЩйMySQLЕФаДШыбЙСІЁЃЖдгкУїЯИЪ§ОнаДШыGreenplumЃЌУїЯИЪ§ОнВЛЪЪКЯИпВЂЗЂаДШыЃЌвђДЫЛсЖдвЊаДШыЕФБэвРОнжїМќзіЙўЯЃЃЌЖЈЮЛвЊТМШыЕФsegmentЃЌжБНгЕНSlaveНкЕуЃЌХњСПаДШыЪ§ОнЃЌетбљвВФмгааЇЬсИпаДШыЕФДцДЂСПЁЃ
3ЁЂЪ§ОнжЪСП
Ъ§ОнжЪСПЗжЮЊСНИіЗНУцРДНщЩмЃЌЪ§ОнвЛжТадКЭЪ§ОнМрПиЁЃ
Ъ§ОнвЛжТаджївЊеыЖдЪЕЪБгыРыЯпЕФЪ§ОнвЛжТадЃЌЭЌвЛИіжИБъЪЕЪБгыРыЯпЖМЛсВњГіЁЃетСНепвЛжТадЗжЮЊЫФИіЗНУцЃК
ЕквЛЃЌНЈФЃЗНЗЈгыЗжВуЛљБОЭГвЛЃЌНЈФЃЛљгкЮЌЖШНЈФЃЃЌЗжВувВЪЧвЕФкЭЈгУЗНЗЈЃЛ
ЕкЖўЃЌвЕЮёЩЯжїЬтгђКЭФЃаЭЩшМЦЭЌВНЃЛ
ЕкШ§ЃЌЪ§ОнНгШыгыдДЪ§ОнЭГвЛЃЛ
зюКѓЃЌЪ§ОнВњГіЗНУцЃЌжИБъЖЈвхКЭНгПкЖМЪЧЭГвЛЪфГіЁЃ
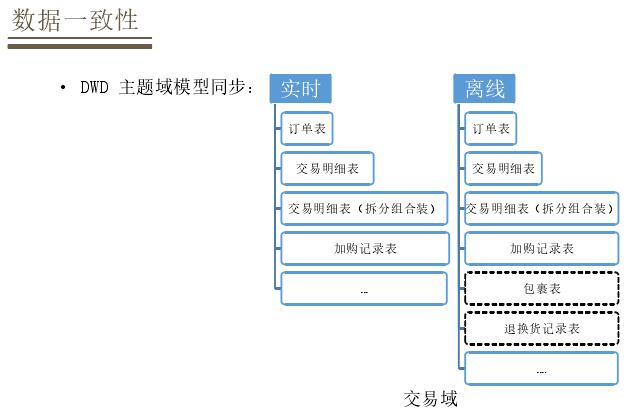
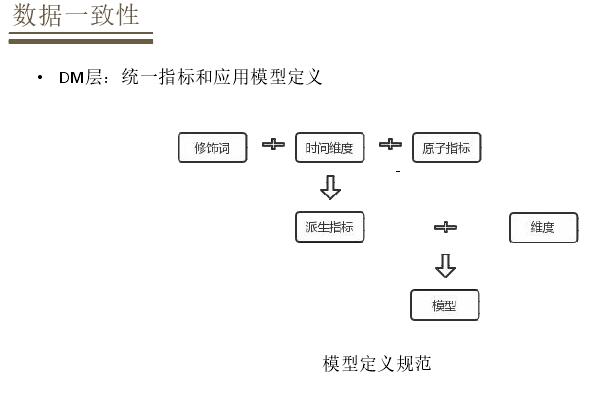
DWDВузіЕНжїЬтгђгыФЃаЭЭЌВНЃЌАДеевЕЮёЙ§ГЬРДЩшМЦФЃаЭЃЌетжжЗНЗЈЖдгкЪЕЪБКЭРыЯпЖМЪЧЭГвЛЕФЁЃвдНЛвзгђЮЊР§ЃЌдкЪЕЪБКЭРыЯпЖМгаЖЉЕЅЁЂЖЉЕЅУїЯИЁЂзщКЯзАЕФНЛвзУїЯИЃЌЛЙгаМгЙКЪ§ОнФЃаЭЃЌгЩгкПЊЗЂГЩБОдвђЪЕЪБФЃаЭДѓЖМЪЧРыЯпФЃаЭЕФзгМЏЁЃдкDMВуЛсЭГвЛЖЈвхжИБъКЭФЃаЭЖЈвхЕФЗНЗЈЃЌЙцЗЖЖдгкЪЕЪБКЭРыЯпЖМЪЧЪЪгУЕФЃЌЖЈвхФЃаЭЛсжИЖЈЯргІЕФжИБъКЭЮЌЖШЃЌжИБъЭЈГЃЪЧХЩЩњжИБъЃЌЭЈЙ§дзгжИБъ+ЪБМфЮЌЖШ+аоЪЮДЪЭъГЩХЩЩњжИБъЕФЖЈвхЃЌдйОЙ§ЖЈвхЮЌЖШаЮГЩФЃаЭЁЃ
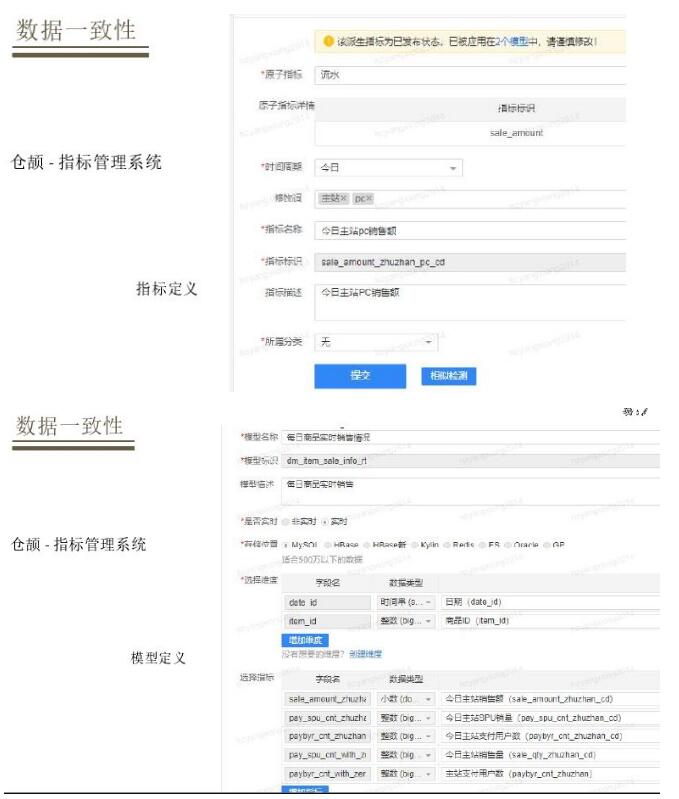
гаСЫФЃаЭЖЈвхЙцЗЖОпЬхТфЕиЃЌШчЙћвЊЖЈвхЕБШежїеОPCЖЫЯњЪлЃЌЪзЯШЖЈвхдзгжИБъСїЫЎЃЌЪБМфЮЌЖШНёЬьЃЌЖЫЪЧPCЃЌШЛКѓЖЈвхХЩЩњжИБъЃЌгаСЫХЩЩњжИБъНгзХЖЈвхФЃаЭЃЌЖЈвхЮЊУПЬьЩЬЦЗЯњЪлЪЕЪБЧщПіЃЌзівЛИіЪЕЪБгыРыЯпЕФБъМЧЃЌбЁдёЦфДцДЂЃЌЮЌЖШбЁдёвЛИіЪЧЪБМфЮЌЖШЁЂвЛИіЪЧЩЬЦЗЮЌЖШЃЌШЛКѓМгШыЯШЧАЕФХЩЩњжИБъЃЌзюКѓЩњГЩФЃаЭЁЃВЛЭЌФЃаЭжЊЪЖЪЕЪБКЭРыЯпБъМЧЃЌЕїгУЖМЪЧЛљгкЭЌвЛЬзНгПкРДЕїгУЁЃ

Ъ§ОнМрПиЩцМАСНИіЗНУцЃЌвЛИіЪЧЪ§ОнЦНЬЈМрПиЁЃжївЊЪЧЖдШЮЮёЪЇАмЧщПіМрПиЁЂвьГЃШежОМрПиЁЂШЮЮёЪЇАмЪЧRPSвьГЃМрПиЁЃЛЙгаШЮЮёБОЩэдЫаае§ГЃЃЌЕЋЪЧЪ§ОнвбОДІРэВЛЙ§РДЃЌгЩгкFlinkЛњжЦЃЌЪ§ОнМЗбЙЕНЯћЗбЙмРэЃЌЭЈЙ§ЖдKafkaЪ§ОнбгГйМрПиФмЙЛМАЪБЗЂЯжЮЪЬтЁЃНЋЮЪЬтЭЈЙ§МрПиЗЂЯжЃЌРћгУжЕАрСїГЬЙцЗЖНЋЮЪЬтМАЪБЗЂЯжКЭДІРэЃЌМАЪБЭЈБЈКЭЖЈЦкНјаааоИДЃЌРДЬсИпећИіЪ§ОнжЪСПЁЃ

ЮЊСЫХфКЯЪ§ОнМрПиЃЌе§дкзіЪЕЪБЪ§ОнбЊдЕЁЃжївЊЪЧЪсРэЪЕЪБЪ§ВжжаЪ§ОнвРРЕЙиЯЕЃЌвдМАЪЕЪБШЮЮёЕФвРРЕЙиЯЕЃЌДгЕзВуODSЕНDIMдйЕНDMЃЌвдМАDMВуБЛФФаЉФЃаЭгУЕНЃЌНЋећИіСДЖШДЎСЊЦ№РДЁЃетбљЕФКУДІЪЧЃК
ЃЈ1ЃЉЪ§Он/ШЮЮёжїЖЏЕїећПЩвджмжЊЙиСЊЕФЯТгЮЃЛ
ЃЈ2ЃЉШЮЮёвьГЃМАЪБХаЖЯгАЯьЗЖЮЇЃЌЭЈжЊВњЦЗКЭвЕЮёЗНЃЛ
ЃЈ3ЃЉжИБъвьГЃЪБНшжњбЊдЕЖЈЮЛЮЪЬтЁЃ
4ЁЂгІгУГЁОА
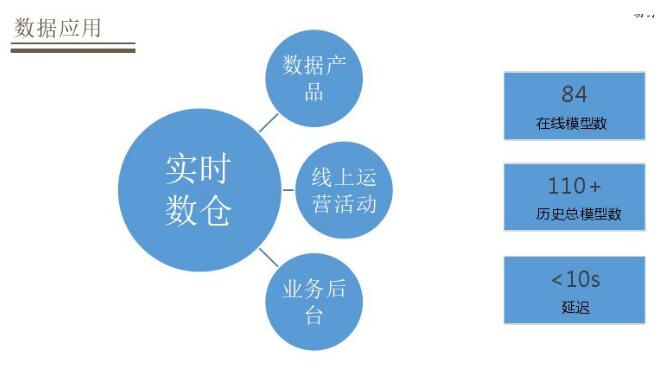
ЪЕЪБЪ§ВжгІгУГЁОАЗжЮЊШ§РрЃКЪ§ОнВњЦЗЁЂЯпЩЯдЫгЊЛюЖЏЁЂвЕЮёКѓЬЈЁЃдкЯпФЃаЭЪ§га84ИіЃЌРњЪЗзмФЃаЭЪ§ЮЊ110+ЃЌДѓВПЗжЪ§ОнбгГйЖМдк10sвдФкЃЌЖдгкЪ§ОнДѓЦСетжжЖдбгГйвЊЧѓБШНЯИпЪ§ОнбгГйдкКСУыМЖЁЃ
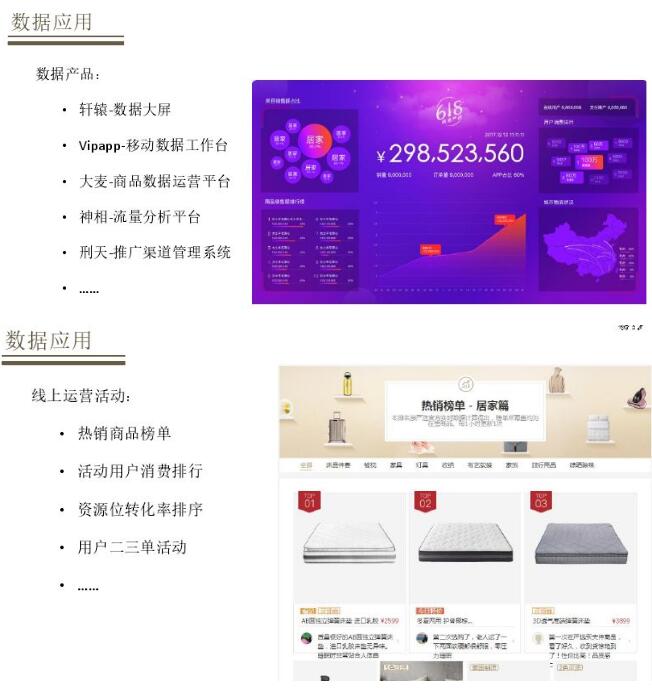
Ъ§ОнДѓЦСЪЧзюГЃгУЕФЪЕЪБЪ§ОнгІгУГЁОАЃЌгаеыЖдПЭЗўвЕЮёДѓЦСЃЌШчДѓТѓ-ЩЬЦЗЪ§ОндЫгЊЦНЬЈЁЂЩёЯр-СїСПЗжЮіЦНЬЈЁЂаЬЬь-ЭЦЙуЧўЕРЙмРэЯЕЭГЁЃЕкЖўИіЪЧЯпЩЯдЫгЊЛюЖЏЃЌШчШШЯњЩЬЦЗАёЕЅЁЂЛюЖЏгУЛЇЯћЗбХХааЁЂзЪдДЮЛХХађзЊЛЏВпТдЃЌвЕЮёКѓЬЈВжХфВњФмМрПиЁЂЮяСїЪБаЇМрПиЁЂПтДцдЄОЏЁЂЩЬЦЗБфИќЭЈжЊЁЃ
5ЁЂеЙЭћ
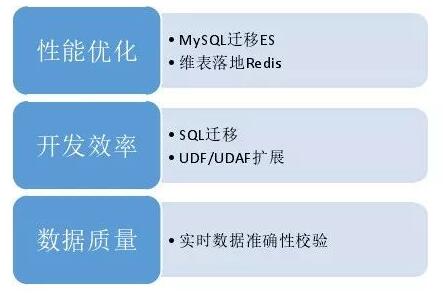
ЮДРДеЙЭћДгШ§ИіЗНУцЃК
ЕквЛЃЌадФмЗНУцЁЃФЃаЭгУMySQLаЇТЪВЛИпЃЌКѓЦкЧЈвЦЕНESЩЯЃЛЮЌЖШБэТфЕиЕНRedisЩЯНјвЛВНЬсИпЭЬЭТСПЁЃ
ЕкЖўЃЌПЊЗЂаЇТЪЁЃПЊЗЂЪЧSQLКЭAPIСНжжВЂДцЃЌПЊЗЂаЇТЪВЛИпЃЌКѓЦкЭљSQLЧЈвЦЃЌгЩгкSQLБОЩэОжЯоЃЌНјааUDFРЉеЙЁЃ
ЕкШ§ЃЌЪ§ОнжЪСПЁЃФПЧАжївЊЪЧВрУцИЈжњОіВпЃЌЯЃЭћЖдЪцЪЪЪ§ОнзМШЗадаЃбщЪЕЯжБШНЯЭЈгУЕФЙцЗЖЃЌПЊЗЂвЛаЉЙЄОпЭъГЩетаЉЙЄзїЁЃ |









