| 编辑推荐: |
本文主要介绍了时序数据和时序数据库特点、一些开源的时序数据库及时序数据库在机器学习应用的几个趋势。希望对您的学习有所帮助
。
本文来自于简书,由火龙果软件Linda编辑、推荐。 |
|
什么数据是工业大数据最重要的数据?什么样的数据能够刻画出环境和状态的变化?
就是我们每每遇到,但有可能没有意识到它特殊性的时序数据。
时序数据是机器学习解决行业场景,尤其是大数据场景的最重要的一种数据,因为数据输入的特殊性,时序存储的方式和数据库的设计方式也和普通的关系型数据库有很大的区别。比如传感器网络的采集数据、二级市场的交易数据、社交网络的发布和评论数据等,这些以时间为基准索引的数据源,都是时序数据,而能够基于这些时序数据做出对未来的预测,也就是能做出科学的“占卜”,在行业一直有着强烈的需求。
实时数据库 vs. 时序数据库
* 实时数据库起源于工业场景的需求,若干年前就已经开始了应用,解决的是工业大量生产、测量数据的高速写入,查询的动作;
* 高性能的商业数据库,价格昂贵;
* 结构化数据存储,高数据压缩比;
* 数据库灵活性比较差,拓展性差,但性能稳定,SLA服务有保障;
* 时序数据库则起源于互联网比如用户行为数据、内容数据的产生,进而物联网传感器网络产生的数据,解决的是网络中节点产生的海量数据写入和查询的动作;
* 开源数据库居多,开源社区活跃;
* 结构化海量数据存储;
* 分布式的设计体现出极强的拓展性,但稳定性相比商业软件还有差距,SLA只有开发团队保障;
虽然起源不同,但我们还是可以看到实时数据库和时序数据库解决的问题和需求是相同的,而且在互联网企业逐渐转向产业互联网,IIoT给互联网和工业场景做了非常适合的连接,实时数据库和时序数据库一定会出现融合的现象,那么在保证SLA的条件下,合理的判断时序数据库的拓展性和灵活性一定会是工业后续应用的主流数据库选择,接下来我们就主要对时序数据和数据库做一些分析。
时序数据的特点
一个小问题:自动驾驶、黑灯工厂、二级市场量化交易、天气监测和预报,地震预测有什么共同点? -- 都产生了海量的时序数据,也利用海量的时序数据产生了巨大的价值。
* 世界变化以时间为轴:时序数据的记录帮助我们记录了第四象限的所有状态数据;
* 以时间戳为index:我们看到的数据都是以时间戳为索引;
* INSERT not UPDATE:时序数据不断产生,所以不断地会插入新的数据,数据库写入的操作极其高频,但是数据表的更新操作则非常稀少;
* 记录变化:时序数据最重要的特征就是记录变化,无论是微观的扰动或是事件的巨变;
* 数据量超大:取决于采集数据的颗粒度,我们自然会观察到时序数据有可能随时间有着爆发式的增长速度,存储和处理数据成为巨大的挑战;一辆车有可能一天就存储4GB的时序数据;一个工厂装有5-10万个传感器,那么一天产生的数据都会达到TB级别; 
IoT设备的数据高频接入过程
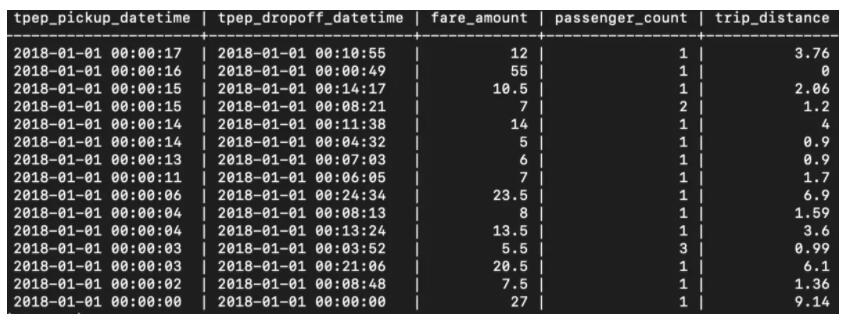
公开数据 NY Taxi的时序数据集
对于机器学习而言,传统的时序预测受困于算法结构和算力,没有办法处理海量的数据,也不能支撑大规模计算的场景,导致预测结果不佳甚至于无法实现结果输出。这样的问题,引发了开源社区出现了不少项目来解决这个问题,比如:
对于机器学习而言,一个时序数据库需要能够具备如下的几个特点:
* 稳定性和可拓展性:在数据量不断累积新增、甚至“激增”的情况下,数据库的架构能够保持稳定性能,支撑超大规模的数据IO;
* 跨数据库查询性能:能够支撑数据的全局查询,这里的全局指的是跨数据库的能力;
* 低延时的SLA:数据的吞吐低延时,保证业务层的交互和用户体验;
* 标注的Metrics:有已经标注好的数据库metrics;
* 后向兼容:能够与其他的时序数据库的接口兼容,数据迁移和复制不影响现有业务;
一些开源的时序数据库
Uber M3
M3的诞生主要是由于以往的时序数据库框架无法满足Uber自有的时序数据量增长,不得已Uber开始了自有时序数据库的研发。在M3的定位上,突出了“规模化”和“低延时”的两个特点,M3能够实现每秒处理5亿metrics同时整合2亿metrics的操作;我们换算成24小时的时长来看,意味着M3每天能够处理接近45万亿的metrics,这样的性能远远超过了传统的时序数据库。实现这样的性能,M3主要依靠以下的三个部分:
* M3DB:这是M3的分布式时序数据库,能够支持可拓展的存储及时序的反向索引;
* M3Query:M3 Query 作为同时能够支持实时和历史metrics的服务,还可以支持多种查询语言;
* M3Aggregator:M3 Aggregator 提供基于动态规则的、下采样的一种metrics聚合的服务;
* M3Coordinator:M3 Coordinator 是一个与上层系统比如Prometheus和M3DB进行读写交互的服务;
* M3QL:专为时序数据优化的查询语言;
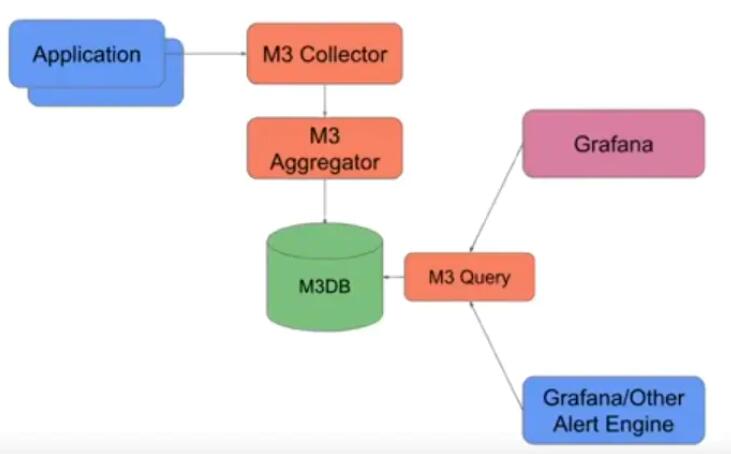
M3功能模块的关系
展开每一模块的一些细节:
M3DB
M3DB是M3框架最核心的功能,基于Go语言,目的就是为了优化大规模的时序数据分析。M3DB同时利用了内存和硬盘的存储模型,介质的选择取决于数据的使用目的:频繁访问或基于查询的计算任务。
M3DB最优秀的是它精巧的存储模型设计。对于时序数据而言,在一个请求中,绝大多数数据变换的发生,都会跨越一个时间切片的多个序列中。M3DB通过将数据进行列式存储,将不同序列的数据存储在一个内存区块内,这样大部分据数据变换工作就可以非常快速的在不同的区块内进行并行计算,因而提高了计算速度。
M3DB存储模型
M3QL
M3框架在早期支持Prometheus的查询语言PromQL和Graphite的Path Navigation
Language. Uber设计的M3QL也是一种pipe-based语言,更加补充和增强了更丰富的数据访问路径,和其他的pipe-based语言一样,M3QL也允许用户从左至右进行查询读取,从而提供更丰富的语法结构。
M3 Query Engine
M3 Query Engine的目的是为了提升M3框架的吞吐性能。最近一次在Uber内部的Benchmarking测试中,M3实现了每秒处理2500次请求的性能。M3的一次查询可以分为三个阶段:
Parsing ---> Execution---> Data Retrieval
Parsing和Execution模块一起执行一个完整的query请求,data retrieval服务则通过存储节点的封装执行完成。
M3框架还通过有向无环图DAG(Directed Acyclic Graph)来实现对多种查询语言比如M3QL和PromQL的支持;目前M3
Query Engine的实现还是和M3DB强耦合的,但从架构设计上来看,应该是可以支持其他的时序数据库。
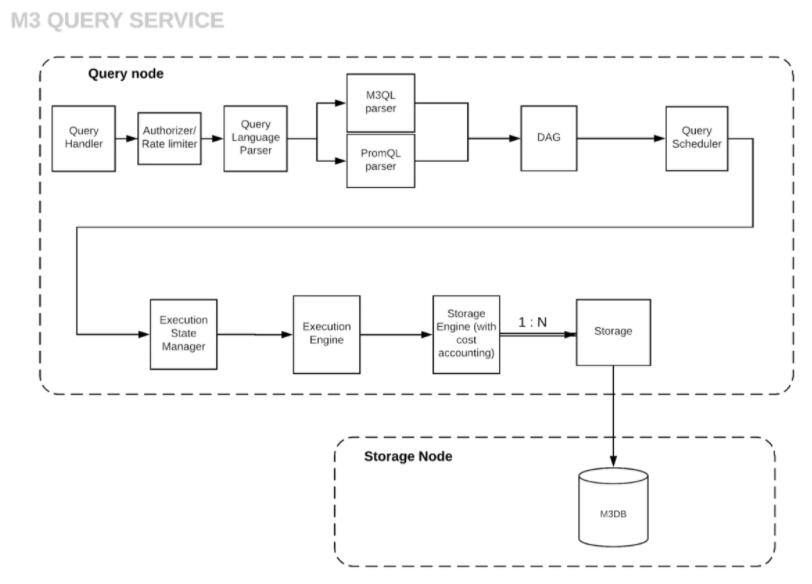
M3 Query Engine流程
M3 Coordinator
M3 Coordinator提供了API服务,作为与M3DB在全局和内部不同层级的读写功能,同时提供了M3与外部时序数据分析系统例如Prometeus的集成能力,这样实现了M3DB和Prometheus的桥接功能。
总结:
M3的快速使用非常简单,全部的M3都已经被封装在Docker容器中,同时能够支持在Google Cloud这样的公有云环境中运行。虽然M3还没有能够够全部在商业环境中验证,但能够经历Uber这样庞大的数据锤炼和验证,对于大多数企业而言,不应该再有更多的担心。
InfluxDB
InfluxDB是InfluxData在2013年开发的一套全部开源的时序数据库(现在集群的InfluxDB需要购买了),能够支持全部主流的操作系统和绝大多数的编程语言,InfluxDB主要是为了优化写入的效率和高并发的需求。
InfluxDB是基于NoSQL的原理,没有schema的限制。同时拥有了Flux这个处理语言,也能够帮助InfluxDB与Chronograf的集成。
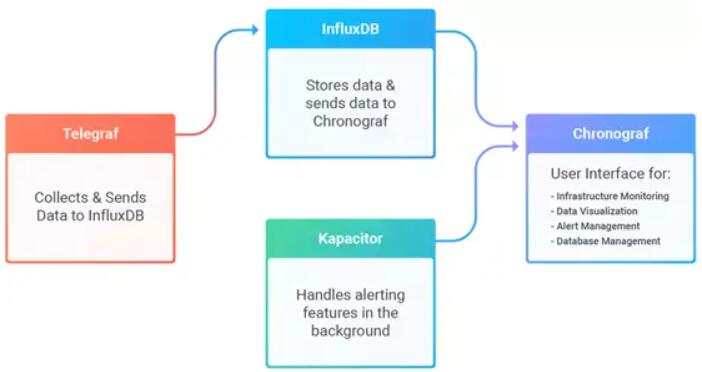
InfluxDB的业务流程
TimescaleDB
TimescaleDB也是一个开源的时序数据库(商业版收费),遵循SQL的语法框架,同时支持了比如Java、Python的语言支持,能够支撑向上的应用集成。
TimescaleDB最大的优点是直接与PostgreSQL相通,通过TimescaleDB使得这个著名的开源关系型数据库具备了独特的一些时序数据的处理和操作。作为企业级的数据库,关系型数据库在短期内还会占据主流,所以我们可期PostgreSQL也会提升自己的渗透率,那么自然会带动TimescaleDB的利用率。
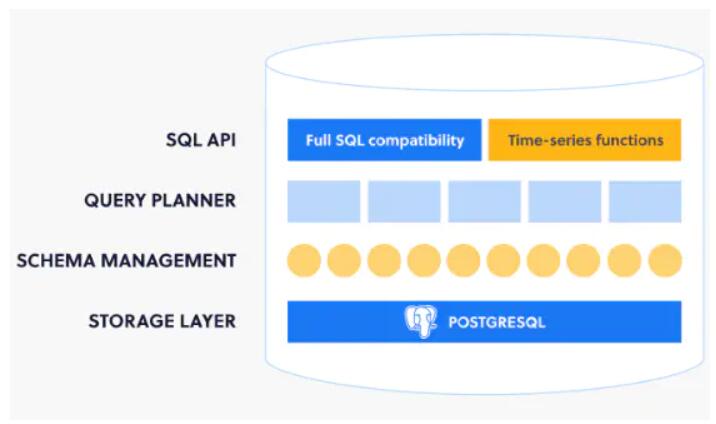
TimescaleDB功能框架
OpenTSDB
OpenTSDB是最早一批的时序数据库(2011年),也是最早一批支持大规模时序数据的数据库。OpenTSDB通过分布式的TSD
Servers实现超过千亿级数据记录存储的性能。
OpenTSDB是基于Apache HBase的schema-free数据库。OpenTSDB著名的就是它强大的读写性能,Ted
Dunning(MapR的首席架构师)测试OpenTSDB将DBMS的写入速度提升到每秒2000万
- 3000万次写入,相比InfluxDB每秒最多100万的写入而言,简直是神一般的数据写入速度。
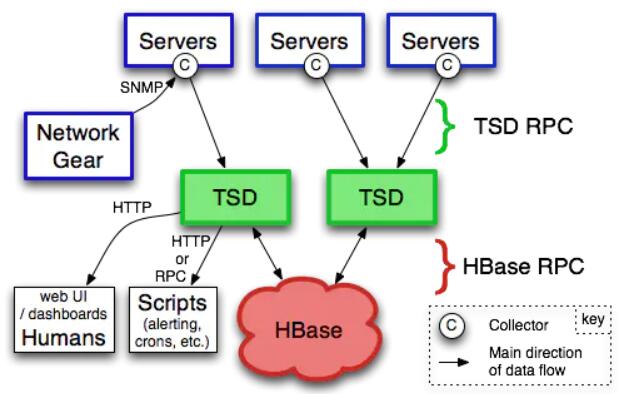
OpenTSDB功能模块
Graphite
Graphite项目发布的时间比OpenTSDB还早(2006年),Graphite作为一个强大的监控工具,背后则存储着大量的数值型时序数据,通过Graphite
Web UI来展示。Graphite通常还是被用来作为系统后台的监控工具,比如booking.com,Reddit,GitHub都在使用Graphite。
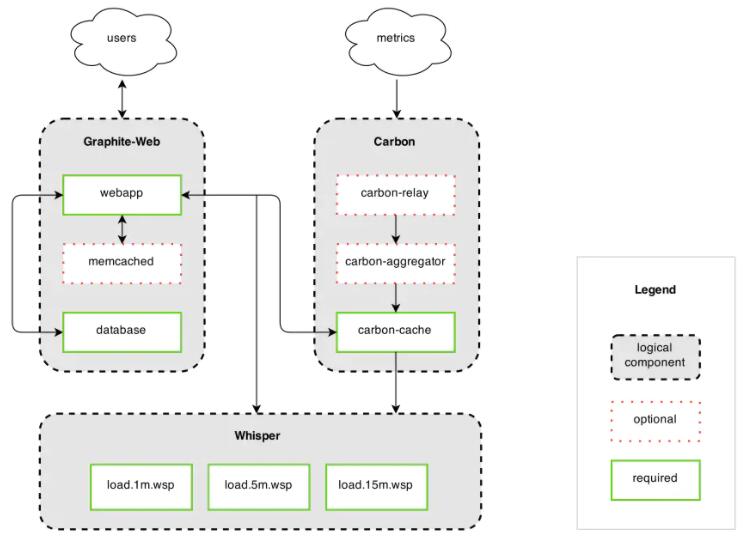
Graphite功能模块
Prometheus
Prometheus起源是SoundCloud开发的开源的监控和告警的框架,核心存储的是时序数据,所以本质上也是时序数据库,通过Key/Value做数据存储。同时,Prometheus还提供了PromQL这一个自行开发的数据查询DSL语言。
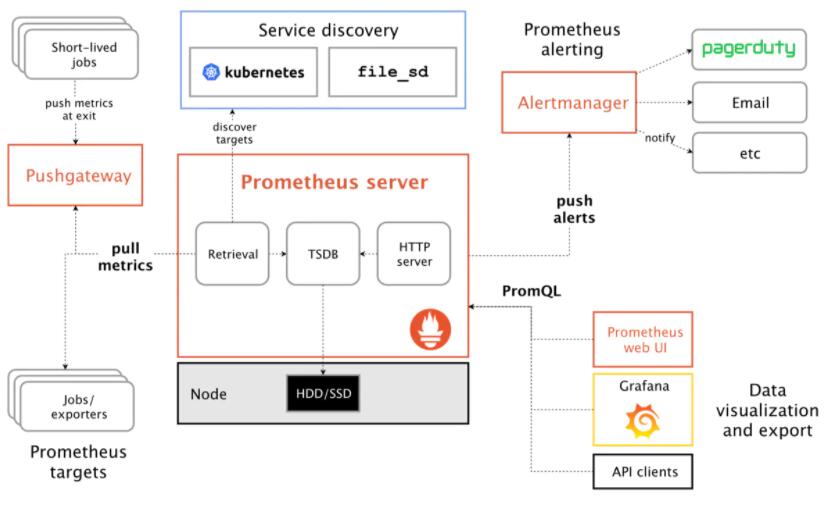
Prometheus架构
时序数据库在机器学习应用的几个趋势
作为物联网产生海量数据的最重要组成部分 - 时序数据,尤其以传感器网络产生的结构化数据和摄像头等产生的图像、视频等部分非结构化数据,组成了我们在工业互联网时代的“大数据”,而结合机器学习的应用,我看到了几个趋势:
1、机器学习应用场景驱动的海量数据查询
在传统实时数据库高写入的特性满足了记录和监控的任务后,由于机器学习的场景化价值的诉求,一定会在底层的时序数据出现高频率的基本或者高级查询任务,以满足机器学习任务需要的训练数据集以及推理阶段,尤其是实时推理需要的线上数据记录。这样就要求时序数据库在满足了基础高写入的功能后,还需要针对机器学习任务,满足数据在离线训练数据和线上推理数据的快读查询的优化。
2、时序数据的云存储和中心模型开发能力
时序数据库相比传统实时数据库最大的优势还是在于灵活性和可拓展性,而海量的数据积累一定会需要分布式的存储和处理,那么对于时序数据而言,云架构(无论是私有云还是公有云)就会成为非常理想的承载,同时在云侧的海量数据也给我们训练更好效果的机器学习模型创造了更高概率的可能性
- 数据越多,模型越“聪明”,而在中心强大的算力也会帮助我们在更短的时间得到机器学习模型,即模型从中心侧生成。
3、连接时序数据的边缘计算推理
当更大规模的工业互联网应用遍布工厂的角落,无论是设备状态监测、预测性维护,还是生产过程控制、员工管理,一个工厂可能会出现成百上千的机器学习模型同时进行推理,那么在工业环境下,网络限制、设备限制或者数据安全限制,都会推动模型从中心生成,而在端侧或者说边缘侧部署,再进行推理,以此往复,形成云和端的机器学习流程的闭环。同时,这样细粒度的时序数据应用和存储传输可以分成两个任务,互不影响,既满足了场景对于机器学习的实时性需求,也满足了海量数据传输和存储的任务。
| 






 订阅
订阅