| БрМЭЦМі: |
БОЮФНщЩмСЫNeo4j
ЕФЪ§ОнФЃаЭНсЙЙЁЂЪ§ОнВйзїРраЭЁЂБщРњЫуЗЈЁЂТпММмЙЙЁЂМЏШКМмЙЙЁЂЪЪгУГЁОАЃЌФмЙЛАяжњЖСепПьЫйСЫНтNeo4jЁЃ
БОЮФРДздЮЂаХЙЋжкКХtwtЦѓвЕITЩчЧјЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
1. Neo4j ЪЧЪВУДЃП
АДееЙйЗНЕФНтЪЭЃЌNeo4jЪЧвЛИігУJavaПЊЗЂЕФЭМаЮЪ§ОнПтЁЃЪєгкNoSQLЪ§ОнПтГЩдБЁЃ
ФЧУДЪзЯШЮвУЧашвЊУїАзЪВУДЪЧЭМЃПЪВУДЪЧЭМаЮЪ§ОнПтЃП
ЁА A graph is a pictorial representation of a set
of objects where some pairs of objects are connected
by links. It is composed of two elements - nodes (vertices)
and relationships (edges). Graph database is a database
used to model the data in the form of graph. In here,
the nodes of a graph depict the entities while the
relationships depict the association of these nodes.
ЁБ
вдЩЯЪЧЮвУЧеЊздЯрЙиЮФЯзЕФФкШнЃЌДгетИіНтЪЭЕБжаЮвУЧПЩвдПДЕНЃЌЫљЮНЕФЭМЪЧжИвЛзщЯрЛЅПЩвдСЊЯЕЕФЖдЯѓЕФзщКЯЃЌетаЉЖдЯѓЕФЛљБОдЊЫиАќКЌСНИіЃКНкЕуКЭЙиЯЕЃЌНкЕуОЭЪЧЖдЯѓБОЩэЃЌЙиЯЕОЭЪЧЯрЛЅЕФСЊЯЕЁЃФЧУДЭМаЮЪ§ОнПтОЭЪЧРДНтОіетРрЪ§ОнЖдЯѓДцКЭШЁЕФЬиЪтЪ§ОнПтЁЃ
Neo4jЪЧDB engine ЩЯХХУћЪзЮЛЕФЭМаЮЪ§ОнПтДњБэЁЃ
Дг2010 Neo4j1.0ЕНФПЧАЕФNeo4j4.2АцБОЃЌЙйЗНвбОЗЂВМСЫ300ЖрИіАцБОЁЃ
2. Neo4j ЕФЪ§ОнФЃаЭНсЙЙ
ЭМDBЪ§ОнФЃаЭжївЊгУРДУшЪіЭМаЮЖдЯѓКЭЖдЯѓжЎМфЕФЙиЯЕЃЌШчЙћЖдгкЯжЪЕЪРНчЕБжаЕФЖдЯѓЃЌЮвУЧгУНкЕуРДБэЪОЃЌФЧУДЖдЯѓгыЖдЯѓжЎМфЕФЙиЯЕОЭгУБпРДБэЪОЃЌШчЭМ2.1ЫљЪОЁЃ
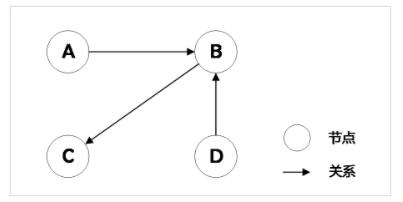
ЭМ2.1 Ъ§ОнНЈФЃЭМ
жБЙлПДЭМ2.1ЃЌЦфЪЕЮвУЧЭЈЙ§етРрФЃаЭБэЪОГіРДЕФНсЙЙЃЌзюДѓЕФФПЕФОЭЪЧЯывЊХЊЧхAЁЂBЁЂCЁЂDЫФИіНкЕужЎМфЕФЙиЯЕЁЃЮЊСЫЭъГЩетИіФПЕФЃЌвдЩЯЪ§ОнНЈФЃЕБжагаШ§ИіБиВЛПЩЩйЕФвђЫиЃК
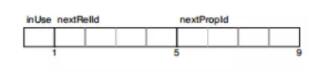
(1 ). НкЕуЃКНкЕудкNeo4jЕБжаЪЧвЛИіжИЯђСЊЯЕКЭЪєадЕФЕЅЯђСДБэЃЌетИіСДБэЪЧЙЬЖЈДѓаЁЃЛАќКЌЪЧЗёБЛЪЙгУЕФБъжОЮЛЃЌЙиСЊЕНетИіНкЕуЕФЕквЛИіЙиЯЕЕФIDЃЌЕквЛИіЪєадIDЃЌНкЕуЕФБъЧЉМАжИеыЃЌБЃСєЮЛЁЃ
( 2). ЪєадЃКвВЪЧЙЬЖЈДѓаЁСДБэЃЌУПИіЪєадМЧТМАќРЈ4ИіЪєадПщКЭжИЯђЪєадСДжаЯТвЛИіЪєадЕФIDЁЃЪєадМЧТМАќРЈЪєадРраЭКЭжИЯђЪєадЫїв§ЮФМўЕФжИеыЁЃЭЌЪБЪєадМЧТМжаПЩвдФкСЊЖЏЬЌДцДЂЃЌдкЪєаджЕДцДЂеМгУаЁЪБЃЌЛсжБНгДцДЂдкЪєадМЧТМжаЃЌЖдгкДѓЪєаджЕЃЌПЩвдЗжБ№ДцДЂдкЖЏЬЌзжЗћДцДЂКЭЖЏЬЌЪ§зщДцДЂжаЁЃ
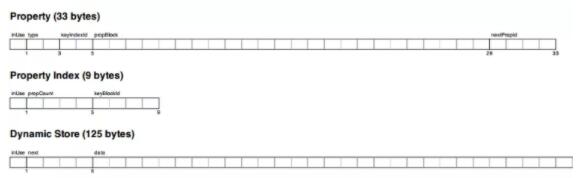
( 3). ЙиЯЕЃКЫЋЯђСДБэЃЌетИіСДБэвВЪЧЙЬЖЈДѓаЁЃЛАќКЌЪЧЗёБЛЪЙгУЕФБъжОЮЛЃЌЦ№ЪМНкЕуЕФIDЃЌНсЪјНкЕуЕФIDЃЌЙиЯЕРраЭЃЌЦ№ЪМНкЕуЕФЩЯЯТСЊЯЕКЭНсЪјНкЕуЕФЩЯЯТНкЕуЃЌвдМАвЛИіжИЪОЕБЧАМЧТМЪЧЗёЮЛгкСЊЯЕСДЕФзюЧАУцЁЃашвЊЧПЕїЕФвЛЕуЪЧЙиЯЕБиаыгаЗНЯђЃЌвВОЭЪЧЫЕгаЦ№ЕуЁЂжеЕуЁЃ
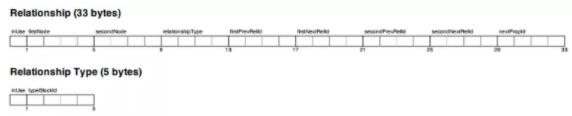
змНсРДПДЃЌдкЭМЪ§ОнПтЕФЪ§ОнНсЙЙЕБжаЃЌзюживЊЕФНкЕуКЭЙиЯЕСНИідЊЫиБЃДцЕФЛљБОЪЧЙЬЖЈДѓаЁЕФдЊЪ§ОнаХЯЂЛђепЫЕжИеыаХЯЂЃЌШчЙћЪєадаХЯЂНЯДѓЃЌФЧУДеце§ЕФЪ§ОнЪЧдкDynamic
StoreЪ§ОнНсЙЙЕБжаЁЃЮвУЧПЩвдЭЈЙ§вдЯТЕФР§згРДкЙЪЭдкNeo4jЕБжаШчКЮШЅДДНЈетаЉЪ§ОнНсЙЙЁЃ
CREATE (sally:Person { name: 'Sally', age: 32 })
CREATE (john:Person { name: 'John', age: 27 })
CREATE (sally)-[:FRIEND_OF { since: 1357718400 }]->(john)
вдЩЯР§згЕБжаЃЌЮвУЧДДНЈСЫСНИівдШЫЮЊЖдЯѓЕФНкЕувдМАетСНИіНкЕуздНЈЕФЙиЯЕ FRIEND_OF ЁЃЕБШЛдкетРяУцЦфНкЕуРяУцЕФЪєадЗЧГЃМђЕЅЃЌНіНіАќКЌаеУћЁЂФъСфЕФМќжЕЖдЁЃЪЕМЪЩЯЫќжЇГжЁА
bool ЁЂ byte ЁЂ short ЁЂ int ЁЂ log ЁЂ float ЁЂ double ЁЂ
char ЁЂ string ЁБЕШКмЖржжЪ§ОнРраЭЁЃОпЬхЪЕМљПЩвдВЮПМNeo4jЕФУќСюCQLжИФЯЁЃ
3. Neo4j ЕФЪ§ОнВйзїРраЭ
CQLДњБэCypherВщбЏгябдЁЃЯёOracleЪ§ОнПтОпгаВщбЏгябдSQLЃЌNeo4jОпгаCQLзїЮЊВщбЏгябдЁЃдкNeo4jЪ§ОнПтЕБжаЃЌЮвУЧПЩвдЪЕЯжЕФОпЬхЪ§ОнДцШЁВйзїКмМђЕЅЃЌжївЊАќРЈСНРрЃК
1). ДДНЈЁЂЩОГ§ЁЂаоИФЪ§ОнЖдЯѓЃЌАќРЈНкЕуЁЂЪєадКЭЙиЯЕЁЃ
2). ВщбЏЪ§ОнЃЌАќРЈЖдНкЕуЁЂЙиЯЕБОЩэЕФМьЫїЃЌМьЫїБОЩэжЇГжОЋШЗЦЅХфвдМАЬѕМўЦЅХфЕШЁЃ
Бэ3.1БэЪОЕФЪЧCQLгябдПЩвдЪЕЯжЕФОпЬхВйзїРраЭвдМАПЩвдЪЕЯжЕФЯъЯИЙІФмУшЪіЃК
Бэ3.1 Neo4jЪ§ОнВйзїРраЭ
ЯъЯИЕФгяЗЈЮвУЧОЭВЛдкБОЮФЯъЪіЃЌДѓМвПЩвдВщбЏCQLгябдЕФжИФЯЪжВсЁЃЮЊСЫИќКУЕФРэНтCQLгябдЕФОпЬхВйзїЙІФмЃЌЮвУЧЭЈЙ§вдЯТР§згРДеЙЪОвЛИіОпЬхГЁОАЁЃР§згЕБжаЃКгаПЭЛЇЃЈcustЃЉЁЂаХгУПЈЃЈccЃЉСНРрНкЕуЃЌНкЕуЕБжаОпгаIDЁЂPriceЁЂShopdateЕШЪєадаХЯЂЁЃЮвУЧВщбЏНкЕуаХЯЂЃЌНЈСЂЯћЗбЕФЙиЯЕЁЃ
MATCH (cust:Customer),(cc:CreditCard)
WHERE cust.id = "1001" AND cc.id= "5001"
CREATE (cust)-[r:DO_SHOPPING_WITH{shopdate:"12/1
0 /20 20 ",price:5000}]->(cc)
RETURN r
Р§згЕБжаЃЌЮвУЧЭЈЙ§вдЁАПЭЛЇID=1001&аХгУПЈID=5001ЁБЮЊЬѕМўЃЌМьЫїЕНЯргІПЭЛЇМАаХгУПЈЕФНкЕуаХЯЂЃЌВЂЧвНЈСЂСЫДгПЭЛЇЕНЦфаХгУПЈЕФЯћЗбМЧТМЙиЯЕЁЃ
4. Neo4j ЕФБщРњЫуЗЈ
ЭМаЮЪ§ОнПтЖдгкЙиЯЕЮЪЬтЕФНтОіБШНЯЩУГЄЖрЖдЖрЙиЯЕЕФДІРэЁЃжЎЫљвдЫќФмЙЛЩУГЄгкИїжжЛљгкЭМЕФвЕЮёГЁОАЕФМьЫїДІРэЃЌОЭдкгкЦфЧПДѓЕФБщРњЫуЗЈЁЃГЃМћБщРњЫуЗЈга15жжЃЌЮвУЧЭЈЙ§ЫќЕФЖЈвхЃЈWhatЃЉКЭШчКЮЪЙгУЃЈHowЃЉСНИіЗНУцРДНјааМђЕЅзмНсЃК
1.ЙуЖШгХЯШЫуЗЈ(BFS)
WhatЃКБщРњЪїЪ§ОнНсЙЙЃЌЬНЫїзюНќЕФСкОгКЭЫћУЧЕФДЮМЖСкОгЁЃЫќгУгкЖЈЮЛСЌНгЃЌЪЧаэЖрЦфЫћЭМЫуЗЈЕФЧАЩэЁЃЕБЪїНЯВЛЦНКтЛђФПБъИќНгНќЦ№ЕуЪБЃЌBFSЪЧЪзбЁЁЃЫќвВПЩгУгкВщевНкЕужЎМфЕФзюЖЬТЗОЖЛђБмУтЩюЖШгХЯШЫбЫїЕФЕнЙщЙ§ГЬЁЃ
HowЃКЙуЖШгХЯШЫбЫїПЩгУгкЖдЕШЭјТчжаЕФСкОгНкЕуЃЌПЩОЋШЗЖЈЮЛИННќЕФЮЛжУЃЌЩчНЛЭјТчЗўЮёПЩдкЬиЖЈОрРыФкВщевЖдЯѓЁЃ
2.ЩюЖШгХЯШЫуЗЈ(DFS)
WhatЃКБщРњЪїЪ§ОнНсЙЙЃЌЭЈЙ§дкЛиЫнжЎЧАОЁПЩФмЬНЫїУПИіЗжжЇЁЃгУгкЩюВуДЮЕФЪ§ОнЃЌЪЧаэЖрЦфЫћЭМЫуЗЈЕФЧАЩэЁЃЕБЪїНЯЦНКтЛђФПБъИќНгНќЖЫЕуЪБЃЌЩюЖШгХЯШЫбЫїЪЧЪзбЁЁЃ
HowЃКЩюЖШгХЯШЫуЗЈЭЈГЃгУгкгЮЯЗФЃФтЃЌЦфжаУПИібЁдёЛђЖЏзїв§ЗЂСэвЛИіВйзїЃЌДгЖјРЉеЙГЩПЩФмадЕФЪїаЮЭМЁЃЫќНЋБщРњбЁдёЪїЃЌжБЕНевЕНзюМбНтОіЗНАИТЗОЖЁЃ
3.ЕЅдДзюЖЬТЗОЖ
WhatЃКМЦЫуНкЕугыЫљгаЦфЫћНкЕужЎМфЕФТЗОЖЃЌвдМАЦфгыЫљгаЦфЫћНкЕуЕФзмКЭжЕ(ГЩБОЃЌОрРыЃЌЪБМфЛђШнСПЕШЙиЯЕЕФШЈжи)ВЂЕУГізмКЭзюаЁЁЃ
HowЃКЕЅдДзюЖЬТЗОЖЭЈГЃгУгкздЖЏЛёШЁЮяРэЮЛжУжЎМфЕФТЗЯпЃЌР§ШчЭЈЙ§GoogleЕиЭМЛёШЁМнГЕТЗЯпЁЃдкТпМТЗгЩжавВКмживЊЃЌР§ШчЕчЛАКєНаТЗгЩ(зюЕЭГЩБОТЗгЩ)ЁЃ
4.ШЋдДзюЖЬТЗОЖ
WhatЃКМЦЫуАќКЌЭМжаНкЕужЎМфЫљгазюЖЬТЗОЖЕФзюЖЬТЗОЖЩСж(зщ)ЁЃЕБзюЖЬТЗОЖБЛзшШћЛђБфЕУДЮгХЪБЃЌЧаЛЛЕНаТЕФзюЖЬТЗОЖЃЌЭЈГЃгУгкБИгУТЗгЩЁЃ
HowЃКгУгкЦРЙРБИгУТЗгЩЃЌР§ШчИпЫйЙЋТЗБИЗнЛђЭјТчШнСПЁЃЫќвВЪЧЮЊТпМТЗгЩЬсЙЉЖрТЗОЖЕФЙиМќЃЌБШШчКєНаТЗгЩбЁдёЁЃ
5.зюаЁЩњГЩЪї(MWST)
WhatЃКМЦЫугыЗУЮЪЪїжаЫљгаНкЕуЯрЙиЕФзюаЁжЕЕФТЗОЖЃЌгУгкБЦНќвЛаЉNPФбЬтЁЃ
HowЃКзюаЁЩњГЩЪїЙуЗКгУгкЭјТчЩшМЦЃКГЩБОзюЕЭЕФТпМЛђЮяРэТЗгЩЃЌШчЦЬЩшЕчРТЃЌзюПьЕФРЌЛјЪеМЏТЗЯпЃЌЙЉЫЎЯЕЭГШнСПЃЌИпаЇЕчТЗЩшМЦЕШЕШЁЃЫќЛЙПЩгУгкЙіЖЏгХЛЏЕФЪЕЪБгІгУГЬађЃЌШчЛЏбЇСЖгЭГЇЕФЙ§ГЬЛђааЪЛТЗЯпаое§ЁЃ
6.PageRank
WhatЃКЙРМЦЕБЧАНкЕуЖдЦфЯрСкНкЕуЕФживЊадЃЌШЛКѓдйДгЦфСкОгФЧРяЛёЕУНкЕуЕФживЊадЁЃвЛИіНкЕуЕФХХУћРДдДгкЦфДЋЕнСДНгЕФЪ§СПКЭжЪСПЁЃ
HowЃКPageRankгУгкЦРЙРживЊадКЭгАЯьСІЃЌгУгкЛњЦїбЇЯАЃЌвдШЗЖЈзюгагАЯьЕФЬсШЁЬиеїЁЃдкЩњЮябЇжаЃЌЫќБЛгУРДЪЖБ№ЪГЮяЭјжаФФаЉЮяжжЕФУ№ОјЛсЕМжТЮяжжЫРЭіЕФзюДѓСЌЫјЗДгІЁЃ
7.Degree Centrality
WhatЃКВтСПНкЕу(ЛђећИіЭМБэ)ЫљОпгаЕФЙиЯЕЪ§СПЃЌБЛЗжЮЊСїШыКЭСїГіСНИіЗНЯђЃЌЙиЯЕОпгажИЯђадЁЃ
HowЃКDegree CentralityзХблгкгУЭОЕФжБНгСЌЭЈадЃЌР§ШчЦРЙРЛМепНгНќВЁЖОЛђЬ§ШЁаХЯЂЕФНќЦкЗчЯеЁЃдкЩчЛсбаОПжаЃЌПЩвдгУРДдЄЙРШЫЦјЛђепЦфЫќЧщИаЁЃ
8.Closeness Centrality
WhatЃККтСПвЛИіНкЕуЖдЦфМЏШКФкЫљгаСкОгЕФМЏжаГЬЖШЁЃМйЖЈЕНЫљгаЦфЫћНкЕуЕФТЗОЖЖМЪЧзюЖЬЕФЃЌФЧУДИУНкЕуОЭФмЙЛвдзюПьЕФЫйЖШЕНДяећИізщЁЃ
HowЃКCloseness CentralityЪЪгУгкЖржжзЪдДЁЂНЛСїКЭааЮЊЗжЮіЃЌгШЦфЪЧЕБНЛЛЅЫйЖШЯдзХЪБЁЃдкаТЙЋЙВЗўЮёжаЃЌБЛгУгкШЗЖЈзюДѓПЩЗУЮЪадЕФЮЛжУЁЃдкЩчНЛЭјТчЗжЮіжаЃЌгУгкевЕНОпгаРэЯыЩчНЛЭјТчЮЛжУЕФШЫЃЌвдБуИќПьЕиДЋВЅаХЯЂЁЃ
9.Betweenness Centrality
WhatЃКВтСПЭЈЙ§НкЕуЕФзюЖЬТЗОЖЕФЪ§СПЁЃЫќЭЈГЃгыПижЦзЪдДКЭаХЯЂЕФСїЖЏгаЙиЁЃ
HowЃКBetweenness CentralityЪЪгУгкЭјТчПЦбЇжаЕФИїжжЮЪЬтЃЌгУгкВщУїЭЈаХКЭНЛЭЈЭјТчжаЕФЦПОБЛђПЩФмЕФЙЅЛїФПБъЁЃдкЛљвђзщбЇжаЃЌБЛгУгкСЫНтПижЦФГаЉЛљвђдкЕААзжЪЭјТчжаЕФИФНјЁЃвВБЛгУРДЦРЙРЖрШЫдкЯпгЮЯЗЭцМвКЭЙВЯэвНЪІзЈвЕжЊЪЖЕФаХЯЂСїЁЃ
10.Label Propagation
WhatЃКЛљгкСкгђЖрЪ§ЕФБъЧЉзїЮЊЭЦЖЯМЏШКЕФЪжЖЮЁЃетжжМЋЦфПьЫйЕФЭМаЮЗжИюашвЊКмЩйЕФЯШбщаХЯЂЁЃ
HowЃКLabel PropagationОпгаВЛЭЌЕФгІгУЃЌР§ШчСЫНтЩчЛсЭХЬхжаЕФЙВЪЖаЮГЩЁЂЪЖБ№дкЩњЮяЭјТчЕФЙ§ГЬ(ЙІФмФЃПщ)жаЫљЩцМАЕФЕААзжЪМЏКЯЕШЕШЁЃЩѕжСЛЙПЩвдгУгкАыМрЖНКЭЮоМрЖНЕФЛњЦїбЇЯАзїЮЊГѕЪМЕФдЄДІРэВНжшЁЃ
11.Strongly Connected
WhatЃКЖЈЮЛНкЕузщЃЌЦфжаУПИіНкЕуПЩДгЭЌвЛзщжаЕФЫљгаЦфЫћНкЕуАДееЙиЯЕЕФЗНЯђЕНДяЁЃ
HowЃКStrongly ConnectedЭЈГЃгУгкдкЪЖБ№ЕФМЏШКЩЯЖРСЂдЫааЦфЫћЫуЗЈЁЃзїЮЊгаЯђЭМЕФдЄДІРэВНжшЃЌЫќгажњгкПьЫйЪЖБ№ВЛСЌЭЈЕФМЏШКЁЃдкСуЪлЭЦМіжаЃЌЫќгажњгкЪЖБ№ОпгаЧПЧзКЭадЕФзщЃЌШЛКѓНЋЯђФЧаЉЩаЮДЙКТђЩЬЦЗЕФШКЬхЭЦМіЪзбЁЩЬЦЗЁЃ
12.Union-Find/Connected Components/Weakly Connected
WhatЃКВщевНкЕузщЃЌЦфжаУПИіНкЕуПЩДгЭЌвЛзщжаЕФШЮКЮЦфЫћНкЕуЕНДяЃЌЖјВЛПМТЧЙиЯЕЕФЗНЯђЁЃЫќЬсЙЉМИКѕКуЖЈЕФЪБМфВйзїРДЬэМгаТЕФзщЃЌКЯВЂЯжгаЕФзщЃЌВЂШЗЖЈСНИіНкЕуЪЧЗёдкЭЌвЛзщжаЁЃ
HowЃКUnion-find/connected ОГЃгыЦфЫћЫуЗЈНсКЯЪЙгУЃЌЬиБ№ЪЧЖдгкИпадФмЗжзщЁЃзїЮЊЮоЯђЭМЕФдЄДІРэВНжшЃЌЫќгажњгкПьЫйЪЖБ№ЖЯПЊЕФзщЁЃ
13.Louvain Modularity
WhatЃКЭЈЙ§БШНЯЫќЕФЙиЯЕУмЖШгыЪЪЕБЖЈвхЕФЫцЛњЭјТчРДВтСПЩчЭХЗжзщЕФжЪСП(МДМйЖЈЕФзМШЗад)ЁЃ
HowЃКЫќЭЈГЃгУгкЦРЙРИДдгЭјТчЕФзщжЏКЭЩчЧјВуДЮНсЙЙЁЃетЖдгкЮоМрЖНЛњЦїбЇЯАжаЕФГѕЪМЪ§ОндЄДІРэвВЪЧгагУЕФЁЃLouvainгУгкЦРЙРвЛИізщжЏЪЧжЛДцдквЛаЉВЛСМааЮЊЃЌЛЙЪЧБГКѓвЛИіСЌЛЗЦлеЉЁЃ
14.Local Clustering Coefficient/Node Clustering Coefficient
WhatЃКЖдгквЛИіЬиЖЈЕФНкЕуЃЌСПЛЏСЫЦфЕНСкОгНкЕуЕФОрРыЁЃ
HowЃКLocal cluster coefficientЭЈЙ§РэНтШКЬхЯрЙиадЛђЫщЦЌЛЏЕФПЩФмадЃЌЖдЙРМЦЕЏадОпгаживЊвтвхЁЃгУетжжЗНЗЈЖдХЗжоЕчЭјЕФЗжЮіЗЂЯжЃЌгыЯЁЪшСЌНгЕФНкЕуЯрБШЃЌМЏШКИќФмЕжгљЦеБщЕФЙЪеЯЁЃ
15.Triangle-Count and Average Clustering Coefficient
WhatЃКВтСПгаЖрЩйНкЕуОпгаШ§НЧаЮвдМАНкЕуЧуЯђгкОлМЏдквЛЦ№ЕФГЬЖШЁЃЦНОљОлРрЯЕЪ§ЮЊ1ЪББэУїгавЛИіЗжзщЃЌ0ЪБУЛгаСЌНгЁЃЮЊЪЙОлРрЯЕЪ§гавтвхЃЌЫќгІИУУїЯдИпгкЭјТчжаЫљгаЙиЯЕЫцЛњЕФАцБОЁЃ
HowЃКЦНОљОлРрЯЕЪ§ЭЈГЃгУгкЙРМЦЭјТчЪЧЗёПЩФмеЙЯжЛљгкНєУмМЏШКЕФЁАаЁЪРНчЁБааЮЊЁЃетвВЪЧМЏШКЮШЖЈадКЭЕЏадЕФвЛИівђЫиЁЃСїааВЁбЇМвЪЙгУЦНОљОлРрЯЕЪ§РДАяжњдЄВтВЛЭЌЩчЧјЕФИїжжИаШОТЪЁЃ
5. Neo4j ЕФТпММмЙЙ
Neo4jЪ§ОнПтФкВПЕФТпММмЙЙЯрЖдБШНЯМђЕЅЃЌШчЭМ5.1ЫљЪОЃК
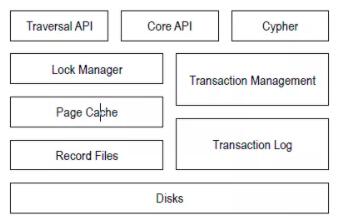
ЭМ5.1 Neo4jДцДЂв§ЧцМмЙЙ
ДгЭМ5.1ПЩвдПДГіЃЌДгЩЯЕНЯТЃЌзнЯђЗжЮЊШ§ИіДѓЕФВуДЮЃЌЗжБ№ЪЧНгПкВуЁЂЪ§ОнЙмРэВувдМАДцДЂВуЁЃНгПкВугаTraversal
APIЁЂCore APIЁЂCypherЕШНгПкЁЃTranversal API жївЊЪЧБщРњЫуЗЈЕФЕїгУНгПкЃЛCore
APIЪЧNeo4jЕФФкВПКЫаФJavaзщМўНгПкЃЌЖСЪ§ОнЕФЪБКђЃЌПЩвдЭЈЙ§ЫќеЙЪОНкЕуЁЂЙиЯЕЁЂЪєадЕШдЪМЭМЪ§ОнЃЛаДЪ§ОнЕФЪБКђЃЌЭЈЙ§ЫќРДБЃжЄЪ§ОнЕФдзгадЁЂИєРыадЁЂСЌајадЕШЃЛCypherЪЧNeo4jЪ§ОнПтжївЊЕФВщбЏгябдНгПкCQLНгПкЁЃжаМфЪ§ОнЙмРэВуАќРЈЖдЪ§ОнЕФВЂЗЂЫјЙмРэЁЂЪТЮёЙмРэЁЂЛКДцЙмРэвдМАДцДЂЙмРэЕШЃЛзюЯТВуОЭЪЧеце§ЕФДцДЂПеМфСЫЁЃ
6. Neo4j ЕФМЏШКМмЙЙ
ЭЈГЃНВNeo4jЕФМЏШКМмЙЙЪЧжИ Causal cluster ЁЃИУМЏШКМмЙЙгЩСНИіВЛЭЌЕФНЧЩЋCore
ServersКЭRead ReplicasзщГЩЃЌетСНИіНЧЩЋЪЧШЮКЮЩњВњВПЪ№жаЕФЛљДЁЃЌЕЋБЫДЫжЎМфЕФЙмРэЙцФЃВЛЭЌЃЌВЂЧвдкЙмРэећИіМЏШКЕФШнДэадКЭПЩЩьЫѕадЗНУцГаЕЃзХВЛЭЌЕФНЧЩЋЁЃШчЭМ6.1ЫљЪОЃК
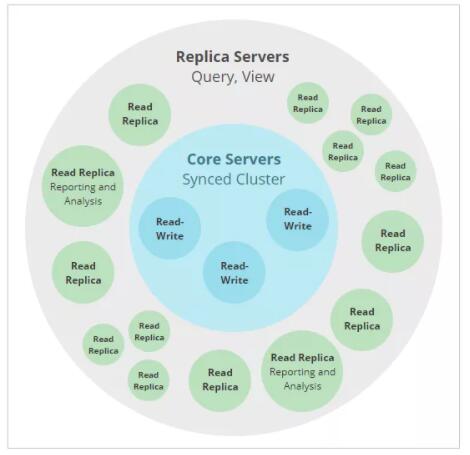
ЭМ6.1 Neo4j ClusterМмЙЙ
1). КЫаФЗўЮёЦїЃЈCore ServersЃЉЃККЫаФЗўЮёЦїЭЈЙ§ЪЙгУRaftавщИДжЦЫљгаЪТЮёРДЪЕЯжЖдЪ§ОнБЃЛЄЕФФПЕФЁЃдкШЗШЯЯђзюжегУЛЇгІгУГЬађЬсНЛЪТЮёжЎЧАЃЌRaftШЗБЃЪ§ОнАВШЋГжОУЃЌМЏШКЃЈN
/ 2 + 1ЃЉжаЕФДѓЖрЪ§КЫаФЗўЮёЦїЖМашвЊШЗШЯСЫЪТЮёЁЃЫцзХШКМЏжаКЫаФЗўЮёЦїЪ§СПЕФдіМгЃЌШЗШЯвЛДЮаДШыЫљашЕФCore
ServersЕФЪ§СПвВЛсдіМгЁЃЪЕМЪЩЯЃЌетвтЮЖзХЕфаЭЕФCore ServerМЏШКжаашвЊвЛЖЈЪ§СПЕФЗўЮёЦїЃЌзувдЮЊЬиЖЈВПЪ№ЬсЙЉзуЙЛЕФШнДэФмСІЁЃетЪЧЪЙгУЙЋЪНM
= 2F +1МЦЫуЕФЃЌMЪЧШнШЬFЙЪеЯЫљашЕФКЫаФЗўЮёЦїЪ§СПЁЃ
2). ИББОЗўЮёЦїЃЈRead ReplicasЃЉЃКИББОЗўЮёЦїЕФжївЊжАд№ЪЧРЉеЙЭМЪ§ОнИКдиФмСІЁЃзїгУРрЫЦгкCore
ServerБЃЛЄЕФЪ§ОнЕФЛКДцЃЌЕЋЫќУЧВЛЪЧМђЕЅЕФМќжЕЛКДцЃЌЭЌЪБЫќЪЧЙІФмЦыШЋЕФNeo4jЪ§ОнПтЃЌФмЙЛЭъГЩШЮвтЃЈжЛЖСЃЉЭМЪ§ОнВщбЏКЭЙ§ГЬЁЃжЛЖСИББОЪЧЭЈЙ§ЪТЮёШежОДЋЫЭДгCore
ServersвьВНИДжЦЕФЁЃЫќЖЈЦкТжбЏКЫаФЗўЮёЦївдВщевздЩЯДЮТжбЏвдРДвбДІРэЕФШЮКЮаТЪТЮёЃЌВЂЧвКЫаФЗўЮёЦїЛсНЋетаЉЪТЮёЗЂЫЭЕНжЛЖСИББОЁЃПЩвдДгЯрЖдНЯЩйЕФCore
ServerжаРЁЫЭаэЖржЛЖСИББОЪ§ОнЃЌДгЖјЪЙВщбЏЙЄзїСПДѓЮЊдіМгЃЌДгЖјРЉДѓЙцФЃЁЃЕЋЪЧЃЌгыКЫаФЗўЮёЦїВЛЭЌЃЌжЛЖСИББОВЛВЮгыгаЙиШКМЏЭиЦЫЕФОіВпЁЃ
7. Neo4j ЪЪгУГЁОА
ФПЧАЃЌвЕФквбОгаСЫЯрЖдБШНЯГЩЪьЕФЛљгкЭМЪ§ОнПтЕФНтОіЗНАИ.ЮвУЧПЩвдНЋЭМСьгђЛЎЗжГЩСНВПЗжЃК1. гУгкСЊЛњЪТЮёЭМЕФГжОУЛЏММЪѕЃЈЭЈГЃжБНгЪЕЪБЕиДггІгУГЬађжаЗУЮЪЃЉЁЃетРрММЪѕБЛГЦЮЊЭМЪ§ОнПтЃЌЫќУЧКЭЁАЭЈГЃЕФЁБЙиЯЕаЭЪ§ОнПтЪРНчжаЕФСЊЛњЪТЮёДІРэЃЈOLTPЃЉЪ§ОнПтЪЧвЛбљЕФЁЃ2.
гУгкРыЯпЭМЗжЮіЕФММЪѕ, етРрММЪѕБЛГЦЮЊЭММЦЫув§ЧцЁЃЫќУЧПЩвдКЭЦфЫћДѓЪ§ОнЗжЮіММЪѕПДзівЛРрЃЌШчЪ§ОнЭкОђКЭСЊЛњЗжЮіДІРэЁЃ
АДееаавЕЗжРрЃЌФПЧАNeo4jгІгУЕФвЕЮёГЁОАЗжЮЊвдЯТМИРрЃК
1ЃЎ Н№ШкаавЕЗДЦлеЉЖрЮЌЙиСЊЗжЮіГЁОА
ЗДЦлеЉвбОЪЧН№ШкаавЕвЛИіКЫаФгІгУЃЌЭЈЙ§ЭМЗжЮіПЩвдЧхГўЕижЊЕРЯДЧЎЭјТчМАЯрЙиЯгвЩЃЌР§ШчЖдгУЛЇЫљЪЙгУЕФеЪКХЁЂЗЂЩњНЛвзЪБЕФIPЕижЗЁЂMACЕижЗЁЂЪжЛњIMEIКХЕШНјааЙиСЊЗжЮіЁЃР§ШчШЅЙ§ЕиЗНЕФIPЕижЗЁЂдјОЪЙгУЙ§ЕФMACЕижЗЃЈАќРЈЪжЛњЖЫЁЂPCЖЫЁЂWIFIЕШЃЉЁЂЩчНЛЭјТчЕФЙиСЊЖШЗжЮіЃЌЭЌвЛЪБМфЕуЪЧЗёдјОдкЭЌвЛЕиРэЮЛжУИННќГіЯжЙ§ЃЌвјааеЫКХжЎМфЪЧЗёгаРњЪЗНЛвзаХЯЂЕШЁЃ
2ЃЎ ЩчНЛЭјТчЗжЮі
дкЩчНЛЭјТчжаЃЌЙЋЫОЁЂдБЙЄЁЂММФмЕФаХЯЂЃЌетаЉЖМЪЧНкЕуЃЌЫќУЧжЎМфЕФЙиЯЕКЭХѓгбжЎМфЕФЙиЯЕЖМЪЧБпЃЌдкетРяУцЭМЪ§ОнПтПЩвдзівЛаЉЗЧГЃИДдгЕФЙЋЫОжЎМфЙиЯЕЕФВщбЏЁЃБШШчЫЕЙЋЫОЕНдБЙЄЁЂдБЙЄЕНЦфЫћЙЋЫОЃЌДгжаевРрЫЦЕФЙЋЫОЁЂЯрЫЦЕФЙЋЫОЃЌЖМПЩвддкетИіЯЕЭГФкЭъГЩЁЃ
3ЃЎ ЦѓвЕЙиЯЕЭМЦз
ЭМЪ§ОнПтПЩвдЖдИїжжЦѓвЕНјаааХЯЂЭМЦзЕФНЈСЂЃЌАќРЈзюЛљБОЕФЙЄЩЬаХЯЂЃЌАќРЈКЮЪБзЂВсЁЂЫзЂВсЁЂзЂВсзЪБОЁЂдкКЮДІАьЙЋЁЂОгЊЗЖЮЇЁЂИпЙмМмЙЙЁЃЮЇШЦЦѓвЕЕФОгЊЗЖЮЇЃЌМЬајЯИЛЏШЅВщбЏЦѓвЕОПОЙгаФФаЉВњЦЗЛђЗўЮёЃЌР§ШчЭЈЙ§ЦѓвЕУћГЦВщбЏЕНЦѓвЕЕФздУНЬхЃЌДгЖјИјгшЦфИќЖрЙизЂКЭСЫНтЁЃСэЭтвВАќРЈЖдЦѓвЕЕФВњЦЗКЭЗўЮёЕФЪ§ОнЙиСЊЃЌВщПДИУЦѓвЕгаУЛгаСюШЫаХЗўЕФзджїжЊЪЖВњШЈКЭЯрЙизЪжЪРДжЇГХвЕЮёЕФПЊеЙЁЃЁЂ
4ЃЎ АВШЋМьВтЗжЮі
ЭЈЙ§МЧТМШэМўЛђепЭјТчааЮЊЕФИїжжЙиЯЕЪ§ОнЃЌР§ШчЦфЗУЮЪСЫФФаЉIPЁЂЗУЮЪСЫФФаЉЯЕЭГзЪдДЃЌНјЖјЗжЮіШэМўааЮЊЪЧЗёЪєгке§ГЃЗУЮЪЃЌЪЧЗёОпгаЖёвтЕШЁЃ
5ЃЎ МрПиЙмРэ
ЯжЪЕЕБжаЛсгаКмЖрЛЗОГАќКЌвЛИіИіЕФЪЕЬхЃЌЪЕЬхжЎМфгжЪЧЯрЛЅЙиСЊЕФЃЌДгЖјзщГЩСЫвЛИіИДдгЕФЭјТчЙиЯЕЭМЁЃР§ШчЪ§ОнжааФАќКЌИїжжЩшБИЁЂИїжжЩшБИжЎМфгжЭЈЙ§гаЯпЮоЯпЭјТчСЌНгЃЌР§ШчЕиЬњЭјгЩГЕСОЁЂеОЕуЁЂЕїЖШШЫдБЕШИїИіЪЕЬхзщГЩЃЌЫћУЧгжгаИїжжЕФСЊЖЏЙиЯЕЁЃФЧУДЮвУЧПЩвдЭЈЙ§ЭМЪ§ОнПтЕФаХЯЂВЩМЏКЭЙиЯЕЗжЮіРДЪЕЯжСЊЖЏЕФМрПиБЈОЏЁЃ | 








