| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫMongoDB
ЬиЕуЁЂвЊЫиЁЂЪ§ОнПтЁЂНсКЯЁЂЪгЭМЁЂЫїв§МАИДжЦМЏЕШЛљДЁжЊЪЖЁЃЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздЮЂаХЙЋжкКХЪ§ОнЗжЮігыПЊЗЂЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
MongoDB зїЮЊвЛПюгХауЕФЛљгкЗжВМЪНЮФМўДцДЂЕФ NoSQL Ъ§ОнПтЃЌдквЕНчгазХЙуЗКЕФгІгУЁЃЯТЮФЖд
MongoDB ЕФвЛаЉЛљДЁИХФюНјааМђЕЅНщЩмЁЃ
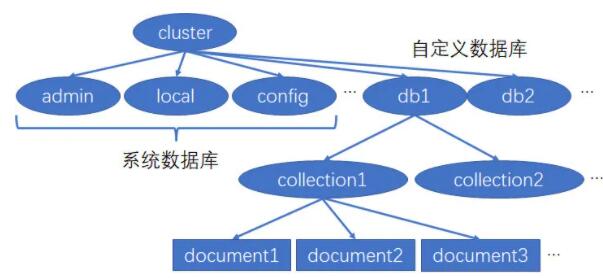
1 MongoDB ЬиЕу
УцЯђМЏКЯДцДЂЃКMongoDB ЪЧУцЯђМЏКЯЕФЃЌЪ§Онвд collection ЗжзщДцДЂЁЃУПИі collection
дкЪ§ОнПтжаЖМгаЮЈвЛЕФУћГЦЁЃ
ФЃЪНздгЩЃКМЏКЯЕФИХФюРрЫЦ MySQL РяЕФБэЃЌЕЋЫќВЛашвЊЖЈвхШЮКЮФЃЪНЁЃ
НсЙЙЫЩЩЂЃКЖдгкДцДЂдкЪ§ОнПтжаЕФЮФЕЕЃЌВЛашвЊЩшжУЯрЭЌЕФзжЖЮЃЌВЂЧвЯрЭЌЕФзжЖЮВЛашвЊЯрЭЌЕФЪ§ОнРраЭЃЌВЛЭЌНсЙЙЕФЮФЕЕПЩвдДцдкЭЌвЛИі
collection РяЁЃ
ИпаЇЕФЖўНјжЦДцДЂЃКДцДЂдкМЏКЯжаЕФЮФЕЕЃЌЪЧвдМќжЕЖдЕФаЮЪНДцдкЕФЁЃМќгУгкЮЈвЛБъЪЖвЛИіЮФЕЕЃЌвЛАуЪЧ ObjectId
РраЭЃЌжЕЪЧвд BSON аЮЪНДцдкЕФЁЃBSON = Binary JSONЃЌ ЪЧдк JSON ЛљДЁЩЯМгСЫвЛаЉРраЭМАдЊЪ§ОнУшЪіЕФИёЪНЁЃ
жЇГжЫїв§ЃКПЩвддкШЮвтЪєадЩЯНЈСЂЫїв§ЃЌАќКЌФкВПЖдЯѓЁЃMongoDB ЕФЫїв§КЭ MySQL ЕФЫїв§ЛљБОвЛбљЃЌПЩвддкжИЖЈЪєадЩЯДДНЈЫїв§вдЬсИпВщбЏЕФЫйЖШЁЃГ§ДЫжЎЭтЃЌMongoDB
ЛЙЬсЙЉДДНЈЛљгкЕиРэПеМфЕФЫїв§ЕФФмСІЁЃ
жЇГж mapreduceЃКЭЈЙ§ЗжжЮЕФЗНЪНЭъГЩИДдгЕФОлКЯШЮЮёЁЃ
жЇГж failoverЃКЭЈЙ§жїДгИДжЦЛњжЦЃЌПЩвдЪЕЯжЪ§ОнБИЗнЁЂЙЪеЯЛжИДЁЂЖСРЉеЙЕШЙІФмЁЃЛљгкИДжЦМЏЕФИДжЦЛњжЦЬсЙЉСЫздЖЏЙЪеЯЛжИДЕФЙІФмЃЌШЗБЃСЫМЏШКЪ§ОнВЛЛсЖЊЪЇЁЃ
жЇГжЗжЦЌЃКMongoDB жЇГжМЏШКздЖЏЧаЗжЪ§ОнЃЌПЩвдЪЙМЏШКДцДЂИќЖрЕФЪ§ОнЃЌЪЕЯжИќДѓЕФИКдиЃЌдкЪ§ОнВхШыКЭИќаТЪБЃЌФмЙЛздЖЏТЗгЩКЭДцДЂЁЃ
жЇГжДцДЂДѓЮФМўЃКMongoDB жа BSON ЖдЯѓзюДѓВЛФмГЌЙ§ 16 MBЁЃЖдгкДѓЮФМўЕФДцДЂЃЌBSON
ИёЪНЮоЗЈТњзуЁЃGridFS ЛњжЦЬсЙЉСЫвЛИіДцДЂДѓЮФМўЕФЛњжЦЃЌПЩвдНЋвЛИіДѓЮФМўЗжИюГЩЮЊЖрИіНЯаЁЕФЮФЕЕНјааДцДЂЁЃ
2 MongoDB вЊЫи
database: Ъ§ОнПтЁЃ
collection: Ъ§ОнМЏКЯЃЌЯрЕБгк MySQL ЕФ tableЁЃ
document: Ъ§ОнМЧТМааЃЌЯрЕБгк MySQL ЕФ rowЁЃ
field: Ъ§ОнгђЃЌЯрЕБгк MySQL ЕФ columnЁЃ
index: Ыїв§ЁЃ
primary key: жїМќЁЃ
3 MongoDB Ъ§ОнПт
вЛИі MongoDB ЪЕР§ПЩвдДДНЈЖрИі databaseЁЃСЌНгЪБШчЙћУЛПЊЦєУтШЯжЄФЃЪНЕФЛАЃЌашвЊСЌНгЕН
admin ПтНјааШЯжЄЁЃШчЙћПЊЦєУтШЯжЄФЃЪНЃЌШєВЛжИЖЈ database НјааСЌНгЃЌФЌШЯСЌНгвЛИіНа db
ЕФЪ§ОнПтЃЌИУЪ§ОнПтДцДЂдк data ФПТМжаЁЃЭЈЙ§ show dbs УќСюПЩвдВщПДЫљгаЕФЪ§ОнПтЁЃЪ§ОнПтУћВЛФмАќКЌПезжЗћЁЃЪ§ОнПтУћВЛФмЮЊПеВЂЧвБиаыаЁгк
64 ИізжЗћЁЃ
MongoDB дЄСєСЫМИИіЬиЪтЕФ databaseЁЃ
admin: admin Ъ§ОнПтжївЊЪЧБЃДц root гУЛЇКЭНЧЩЋЁЃР§ШчЃЌsystem.users
БэДцДЂгУЛЇЃЌsystem.roles БэДцДЂНЧЩЋЁЃвЛАуВЛНЈвщгУЛЇжБНгВйзїетИіЪ§ОнПтЁЃНЋвЛИігУЛЇЬэМгЕНетИіЪ§ОнПтЃЌЧвЪЙЫќгЕга
admin ПтЩЯЕФУћЮЊ dbAdminAnyDatabase ЕФНЧЩЋШЈЯоЃЌетИігУЛЇздЖЏМЬГаЫљгаЪ§ОнПтЕФШЈЯоЁЃвЛаЉЬиЖЈЕФЗўЮёЦїЖЫУќСювВжЛФмДгетИіЪ§ОнПтдЫааЃЌБШШчЙиБеЗўЮёЦїЁЃ
local: local Ъ§ОнПтЪЧВЛЛсБЛИДжЦЕНЦфЫћЗжЦЌЕФЃЌвђДЫПЩвдгУРДДцДЂБОЕиЕЅЬЈЗўЮёЦїЕФШЮвт collectionЁЃвЛАуВЛНЈвщгУЛЇжБНгЪЙгУ
local ПтДцДЂШЮКЮЪ§ОнЃЌвВВЛНЈвщНјаа CRUD ВйзїЃЌвђЮЊЪ§ОнЮоЗЈБЛе§ГЃБИЗнгыЛжИДЁЃ
config: ЕБ MongoDB ЪЙгУЗжЦЌЩшжУЪБЃЌconfig Ъ§ОнПтПЩгУРДБЃДцЗжЦЌЕФЯрЙиаХЯЂЁЃ
вЛИі MongoDB ЪЕР§ЕФЪ§ОнНсЙЙШчЯТЭМЃК
4 MongoDB МЏКЯ
MongoDB МЏКЯДцдкгкЪ§ОнПтжаЃЌУЛгаЙЬЖЈЕФНсЙЙЃЌПЩвдЭљМЏКЯВхШыВЛЭЌИёЪНКЭРраЭЕФЪ§ОнЁЃМЏКЯВЛашвЊЪТЯШДДНЈЁЃЕБЕквЛИіЮФЕЕВхШыЃЌЛђепЕквЛИіЫїв§ДДНЈЪБЃЌМЏКЯОЭЛсБЛДДНЈЁЃМЏКЯУћБиаывдЯТЛЎЯпЛђепзжФИЗћКХПЊЪМЃЌВЂЧвВЛФмАќКЌ
$ЃЌВЛФмЮЊПезжЗћДЎЃЈБШШч ""ЃЉЃЌВЛФмАќКЌПезжЗћЃЌЧвВЛФмвд system. ЮЊЧАзКЁЃ
capped collection ЪЧЙЬЖЈДѓаЁЕФМЏКЯЃЌжЇГжИпЭЬЭТЕФВхШыВйзїКЭВщбЏВйзїЁЃЫќЕФЙЄзїЗНЪНгыбЛЗЛКГхЧјРрЫЦЃЌЕБвЛИіМЏКЯЬюТњСЫБЛЗжХфЕФПеМфЃЌдђЭЈЙ§ИВИЧзюдчЕФЮФЕЕРДЮЊаТЕФЮФЕЕЬкГіПеМфЁЃКЭБъзМЕФ
collection ВЛЭЌЃЌcapped collection ашвЊЯдЪНДДНЈЃЌжИЖЈДѓаЁЃЌЕЅЮЛЪЧзжНкЁЃ
capped collection ПЩвдАДееЮФЕЕЕФВхШыЫГађБЃДцЕНМЏКЯжаЃЌЖјЧветаЉЮФЕЕдкДХХЬЩЯДцЗХЮЛжУвВЪЧАДееВхШыЫГађРДБЃДцЕФЃЌЫљвдИќаТ
capped collection жаЕФЮФЕЕЃЌВЛПЩвдГЌЙ§жЎЧАЮФЕЕЕФДѓаЁЃЌвдБуШЗБЃЫљгаЮФЕЕдкДХХЬЩЯЕФЮЛжУвЛжББЃГжВЛБфЁЃ
5 MongoDB ЪгЭМ
ЪгЭМЛљгквбгаЕФМЏКЯНјааДДНЈЃЌЪЧжЛЖСЕФЃЌВЛЪЕМЪДцДЂгВХЬЃЌЭЈЙ§ЪгЭМНјаааДВйзїЛсБЈДэЁЃЪгЭМЪЙгУЦфЩЯгЮМЏКЯЕФЫїв§ЁЃгЩгкЫїв§ЪЧЛљгкМЏКЯЕФЃЌЫљвдФуВЛФмЛљгкЪгЭМДДНЈЁЂЩОГ§ЛђжиНЈЫїв§ЃЌвВВЛФмЛёШЁЪгЭМЕФЫїв§СаБэЁЃШчЙћЪгЭМвРРЕЕФМЏКЯЪЧЗжЦЌЕФ,
ФЧУДЪгЭМвВЪгЮЊЗжЦЌЕФЁЃЪгЭМЪЧЪЕЪБМЦЫуВЂЖСШЁЕФЁЃ
6 MongoDB Ыїв§
MongoDB жЇГжЗсИЛЕФЫїв§ЗНЪНЁЃШчЙћУЛгаЫїв§ЃЌЖСВйзїОЭБиаыЩЈУшМЏКЯжаЕФУПИіЮФЕЕВЂЩИбЁЗћКЯВщбЏЬѕМўЕФМЧТМЁЃЫїв§ФмЙЛдкКмДѓГЬЖШЩЯЬсИпВщбЏЫйЖШЁЃ
ЕЅзжЖЮЫїв§ЃКгаШ§жжЗНЪНЃЌЃЈ1ЃЉдкЕЅИізжЖЮЩЯДДНЈЫїв§ЃЛЃЈ2ЃЉдкЧЖШыЪНзжЖЮЩЯДДНЈЫїв§ЃЛЃЈ3ЃЉдкФкЧЖЮФЕЕЩЯДДНЈЫїв§ЁЃ
ИДКЯЫїв§ЃКжЇГждкЖрИізжЖЮЩЯЦЅХфЕФВщбЏЁЃЖдШЮКЮИДКЯЫїв§ЪЉМг 32 ИізжЖЮЕФЯожЦЁЃЖдгкИДКЯЫїв§ЃЌMongoDB
ПЩвдЪЙгУЫїв§РДжЇГжЖдЫїв§ЧАзКЕФВщбЏЁЃ
ЖрМќЫїв§ЃКЮЊСЫЫїв§АќКЌЪ§зщжЕЕФзжЖЮЃЌMongoDB ЮЊЪ§зщжаЕФУПИідЊЫиДДНЈвЛИіЫїв§МќЁЃетаЉЖрМќЫїв§жЇГжЖдЪ§зщзжЖЮЕФИпаЇВщбЏЁЃ
ЮФБОЫїв§ЃКжЇГжЖдзжЗћДЎФкШнЕФЮФБОЫбЫїВщбЏЁЃЮФБОЫїв§ПЩвдАќКЌШЮКЮжЕЮЊзжЗћДЎЛђзжЗћДЎдЊЫиЪ§зщЕФзжЖЮЁЃвЛИіМЏКЯзюЖрПЩвдгавЛИіЮФБОЫїв§ЁЃ
ЭЈХфЗћЫїв§ЃКжЇГжеыЖдЮДжЊЛђШЮвтзжЖЮЕФВщбЏЁЃР§ШчЃКdb.collection.createIndex(
{"a.$**" : 1 } ) ПЩжЇГжжюШч db.collection.find({
"a.b" : 1 })ЁЂdb.collection.find({ "a.c"
: { $lt : 2 } }) ЕШВщбЏЃЌЬсИпВщбЏаЇТЪЁЃВЛФмЪЙгУЭЈХфЗћЫїв§РДЗжЦЌМЏКЯЁЃВЛФмЮЊЭЈХфЗћДДНЈИДКЯЫїв§ЁЃ
ЭЈХфЗћЮФБОЫїв§ЃКЭЈХфЗћЮФБОЫїв§ВЛЭЌгкЭЈХфЗћЫїв§ЁЃЭЈХфЗћЫїв§ВЛжЇГжЪЙгУ $textВйзїЗћЕФВщбЏЁЃЭЈХфЗћЮФБОЫїв§ЮЊМЏКЯжаУПИіЮФЕЕжаАќКЌзжЗћДЎЪ§ОнЕФУПИізжЖЮНЈСЂЫїв§ЁЃЫїв§ЕФДДНЈЗНЪНЪОР§ЃКdb.collection.createIndex(
{ "$**": "text" } )ЁЃ
2dsphere Ыїв§ЃКжЇГжЧђЬхЩЯЕФЕиРэПеМфВщбЏЃКАќКЌЁЂЯрНЛКЭСкНќЖШВщбЏЁЃ
hashed Ыїв§ЃКжЇГжЪЙгУЙўЯЃЕФЗжЦЌМќНјааЗжЦЌЁЃЛљгкЙўЯЃЕФЗжЦЌЪЙгУзжЖЮЕФЩЂСаЫїв§зїЮЊЗжЦЌМќЃЌвдБуПчЗжЦЌМЏШКЖдЪ§ОнНјааЗжЧјЁЃMongoDB
жЇГжШЮКЮЕЅИізжЖЮЕФЙўЯЃЫїв§ЃЌЕЋВЛжЇГжДДНЈОпгаЖрИіЙўЯЃзжЖЮЕФИДКЯЫїв§ЃЌвВВЛФмдкЫїв§ЩЯжИЖЈЮЈвЛЙўЯЃЫїв§ЁЃ
ttl Ыїв§ЃКвЛжжЬиЪтЕФЕЅзжЖЮЫїв§ЃЌжЇГждквЛЖЈЕФЪБМфЛђЬиЖЈЕФЦкЯоКѓздЖЏДгМЏКЯжаЩОГ§ЮФЕЕЁЃTTL Ыїв§ВЛФмБЃжЄЙ§ЦкЪ§ОндкЙ§ЦкЪБСЂМДЩОГ§ЁЃФЌШЯУП
60 УыдЫаавЛДЮЩОГ§Й§ЦкЮФЕЕЕФКѓЬЈНјГЬЁЃcapped collection ВЛжЇГж ttl Ыїв§ЁЃ
ЮЈвЛЫїв§ЃКШЗБЃЫїв§зжЖЮВЛЛсДцДЂжиИДжЕЁЃШчЙћМЏКЯвбОДцдкСЫЮЅЗДЫїв§ЕФЮЈвЛдМЪјЕФЮФЕЕЃЌдђКѓЬЈДДНЈЮЈвЛЫїв§ЛсЪЇАмЁЃ
ВПЗжЫїв§ЃКжЛЫїв§МЏКЯжаТњзужИЖЈЩИбЁЦїБэДяЪНЕФЮФЕЕЁЃР§ШчЃКdb.collection.createIndex({
a:1 },{ partialFilterExpression: { b: { $lt: 100 }
} }) БэЪОжЛЖдМЏКЯжа b зжЖЮаЁгк 100 ЕФЮФНјааЫїв§ЃЌДѓгкЕШгк 100 ЕФЮФЕЕВЛЛсБЛЫїв§ЁЃетПЩвдгааЇЬсИпДцДЂаЇТЪЁЃ
ЯЁЪшЫїв§ЃКжЛАќКЌгаЫїв§зжЖЮЕФЮФЕЕЕФЬѕФПЃЌМДЪЙЫїв§зжЖЮАќКЌПежЕЁЃЫїв§ЛсЬјЙ§ШЮКЮШБЩйЫїв§зжЖЮЕФЮФЕЕЁЃЗЧЯЁЪшЫїв§АќКЌМЏКЯжаЕФЫљгаЮФЕЕЃЌЮЊФЧаЉВЛАќКЌЫїв§зжЖЮЕФЮФЕЕДцДЂПежЕЁЃ
7 MongoDB ObjectId
ObjectId ПЩвдПьЫйЩњГЩВЂХХађЃЌГЄЖШЮЊ 12 ИізжНкЃЌАќРЈЃК
вЛИі 4 зжНкЕФЪБМфДСЃЌБэЪО unix ЪБМфДС
5 зжНкЫцЛњжЕ
3 зжНкЕндіМЦЪ§ЦїЃЌГѕЪМЛЏЮЊЫцЛњжЕ
дк MongoDB жаЃЌДцДЂдкМЏКЯжаЕФУПИіЮФЕЕЖМашвЊвЛИіЮЈвЛЕФ _id зжЖЮзїЮЊжїМќЁЃШчЙћВхШыЕФЮФЕЕЪЁТдСЫ
_id зжЖЮЃЌдђздЖЏЮЊЮФЕЕЩњГЩвЛИі _idЁЃ
8 MongoDB ИДжЦМЏ
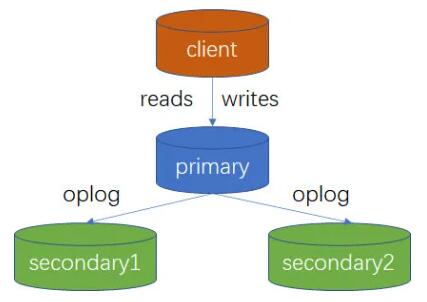
MongoDB ЕФИДжЦМЏгжГЦЮЊИББОМЏЃЈReplica SetЃЉЃЌЪЧвЛзщЮЌЛЄЯрЭЌЪ§ОнМЏКЯЕФ mongod
НјГЬЁЃИДжЦМЏАќКЌЖрИіЪ§ОнНкЕуКЭвЛИіПЩбЁЕФжйВУНкЕуЃЈarbiterЃЉЁЃдкЪ§ОнНкЕужаЃЌгаЧвНігавЛИіГЩдБЮЊжїНкЕуЃЈprimaryЃЉЃЌЦфЫћНкЕуЮЊДгНкЕуЃЈsecondaryЃЉЁЃ
вЛИіЕфаЭЕФИДжЦМЏМмЙЙЭМШчЯТЃК
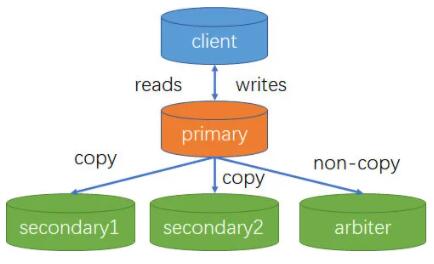
8.1 ИДжЦМЏНкЕуРраЭ
жїНкЕуЃКНгЪеЫљгаЕФаДВйзїЃЌВЂНЋМЏКЯЫљгаЕФБфЛЏМЧТМЕНВйзїШежОжаЃЌМД oplogЁЃ
ДгНкЕуЃКЭЈЙ§ИДжЦжїНкЕуЕФВйзїРДЮЌЛЄвЛИіЯрЭЌЕФЪ§ОнМЏЁЃДгНкЕугаМИИібЁХфЯюЃКv ВЮЪ§ОіЖЈЪЧЗёОпгаЭЖЦБШЈЃЛpriority
ВЮЪ§ОіЖЈНкЕубЁжїЙ§ГЬЪБЕФгХЯШМЖЃЛhidden ВЮЪ§ ОіЖЈЪЧЗёЖдПЭЛЇЖЫПЩМћЃЛslaveDelay ВЮЪ§БэЪОИДжЦ
n УыжЎЧАЕФЪ§ОнЃЌБЃГжгыжїНкЕуЕФЪБМфВюЁЃДгНкЕуПЩвдХфжУГЩ 0 гХЯШМЖЃЌзшжЙЫќдкбЁОйжаГЩЮЊжїНкЕуЃЌЪЪгУгкНЋИУНкЕуВПЪ№дкБИгУЪ§ОнжааФЃЌЛђепНЋЫќзїЮЊвЛИіРфНкЕуЃЛПЩвдХфжУЮЊвўВиИДжЦМЏЃЌЗРжЙгІгУГЬађДгЫќЖСШЁЪ§ОнЃЌЪЪгУгкдкИУНкЕуЩЯдЫааашвЊгые§ГЃСїСПЗжРыЕФГЬађЃЛПЩвдХфжУЮЊбгГйИДжЦМЏЃЌБЃГжвЛИіРњЪЗПьееЃЌвдБузіАДЬиЖЈЪБМфЕФЙЪеЯЛжИДЁЃ
жйВУНкЕуЃКШчЙћНЋвЛИі mongod ЪЕР§зїЮЊжйВУНкЕуЬэМгЕНвЛИіИДжЦМЏжаЃЌИУНкЕуПЩвдВЮгыжїНкЕубЁОйЃЌЕЋВЛБЃДцЪ§ОнЁЃжйВУНкЕугРдЖжЛФмЪЧжйВУНкЕуЁЃ
8.2 ИДжЦМЏбЁжї
MongoDB ЕФИББОМЏавщЃЈгжГЦЮЊ pv1)ЃЌЪЧвЛжж raft-like авщЃЌМДЛљгк raft
авщЕФРэТлЫМЯыЪЕЯжЃЌВЂЧвЖджЎНјааСЫвЛаЉРЉеЙЁЃЕБЭљИДжЦМЏЬэМгвЛИіНкЕуЃЌЛђЕБжїНкЕуЮоЗЈКЭМЏШКжаЦфЫћНкЕуЭЈаХЕФЪБМфГЌЙ§ВЮЪ§
electionTimeoutMillis ХфжУЕФЦкЯоЪБЃЌДгНкЕуЛсГЂЪдЭЈЙ§ pv1 авщЗЂЦ№бЁОйРДЭЦМіздМКГЩЮЊаТжїНкЕуЁЃ
дкбЁОйЧАОпгаЭЖЦБШЈЕФНкЕужЎМфСНСНЛЅЯрЗЂЫЭаФЬјЃЌвдеьВтНкЕуЪЧЗёДцЛюЁЃИДжЦМЏНкЕуУПСНУыЯђБЫДЫЗЂЫЭаФЬјЁЃШчЙћаФЬјЮДдк
10 УыФкЗЕЛиЃЌдђЗЂЫЭаФЬјЕФвЛЗННЋБЛЗЂЫЭЗНБъМЧЮЊВЛПЩЗУЮЪЃЌвВОЭЪЧЫЕЃЌФЌШЯЕБ 5 ДЮаФЬјЮДЪеЕНЪБХаЖЯЮЊНкЕуЪЇСЊЁЃ
ШчЙћЪЇСЊЕФЪЧжїНкЕуЃЌДгНкЕуЛсЗЂЦ№бЁОйЃЌбЁГіаТЕФжїНкЕуЃЛШчЙћЪЇСЊЕФЪЧДгНкЕудђВЛЛсВњЩњаТЕФбЁОйЁЃбЁОйЛљгк
raft вЛжТадЫуЗЈЪЕЯжЃЌдкДѓЖрЪ§ЭЖЦБНкЕуДцЛюЯТбЁОйГіжїНкЕуЁЃжЛгаФмЙЛгыЖрЪ§НкЕуНЈСЂСЌНгЧвОпгаНЯаТЕФ
oplog ЕФНкЕуВХПЩФмБЛбЁОйЮЊжїНкЕуЃЌШчЙћМЏШКРяЕФНкЕуХфжУСЫгХЯШМЖЃЌФЧУДОпгаНЯИпЕФгХЯШМЖЕФНкЕуИќПЩФмБЛбЁОйЮЊжїНкЕуЁЃ
ИДжЦМЏжазюЖрПЩвдга 50 ИіНкЕуЃЌЕЋОпгаЭЖЦБШЈЕФНкЕузюЖр 7 ИіЁЃ
8.3 ИДжЦМЏзїгУ
жїНкЕуЗЂЩњЙЪеЯЪБздЖЏбЁОйГівЛИіаТЕФжїНкЕуЃЌвдЪЕЯж failoverЁЃ
НЋЪ§ОнДгвЛИіЪ§ОнжааФИДжЦЕНСэвЛИіЪ§ОнжааФЃЌМѕЩйСэвЛИіЪ§ОнжааФЕФЖСбгГйЁЃ
ЪЕЯжЖСаДЗжРыЁЃ
ЪЕЯжШнджЃЌПЩвддкЪ§ОнжааФЙЪеЯЪБПьЫйЧаЛЛЕНЭЌГЧЛђвьЕиЕФЪ§ОнжааФЁЃ
9 MongoDB ЗжЦЌМЏ
MongoDB жЇГжЭЈЙ§ЗжЦЌММЪѕРДжЇГжКЃСПЪ§ОнДцДЂЁЃНтОіЪ§ОндіГЄЕФРЉеЙЗНЪНгаСНжжЃКДЙжБРЉеЙКЭЫЎЦНРЉеЙЁЃДЙжБРЉеЙЭЈЙ§діМгЕЅИіЗўЮёЦїЕФФмСІРДЪЕЯжЃЌБШШчДХХЬПеМфЁЂФкДцШнСПЁЂCPU
Ъ§СПЕШЃЛЫЎЦНРЉеЙдђЭЈЙ§НЋЪ§ОнДцДЂЕНЖрИіЗўЮёЦїЩЯРДЪЕЯжЁЃMongoDB ЭЈЙ§ЗжЦЌЪЕЯжЫЎЦНРЉеЙЁЃ
вЛИіЕфаЭЕФЗжЦЌМЏШКМмЙЙШчЯТЃК
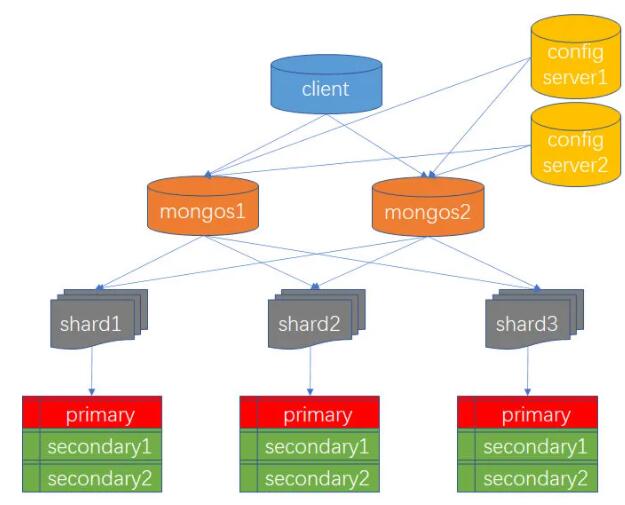
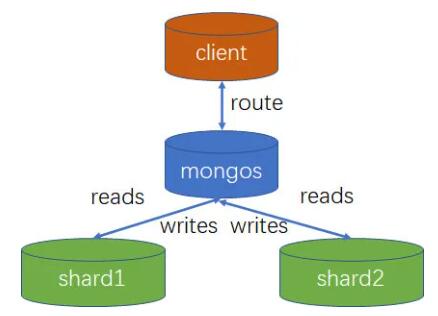
9.1 ЗжЦЌМЏзщМў
shardЃКУПИіЗжЦЌЩЯПЩвдБЃДцвЛИіМЏКЯЕФзгМЏЃЌЫљгаЗжЦЌЩЯЕФзгМЏЕФЪ§ОнЛЅВЛЯрНЛЃЌЙЙГЩЭъећЕФМЏКЯЁЃУПИіЗжЦЌПЩвдБЛВПЪ№ЮЊИДжЦМЏМмЙЙЁЃзюДѓЮЊ
1024 ИіЗжЦЌЁЃ
mongosЃКГфЕБВщбЏТЗгЩЦїЃЌдкПЭЛЇЖЫКЭЗжЦЌМЏжЎМфЬсЙЉЖСаДНгПкЁЃmongos ЬсЙЉМЏШКЕЅвЛШыПкЃЌзЊЗЂгІгУЖЫЧыЧѓЃЌбЁдёКЯЪЪЕФЪ§ОнНкЕуНјааЖСаДЃЌКЯВЂЖрИіЪ§ОнНкЕуЕФЗЕЛиЁЃmongos
ЪЧЮозДЬЌЕФЃЌЗжЦЌМЏШКвЛАуашвЊХфжУжСЩй 2 Иі mongosЁЃ
config serverЃКДцДЂЗжЦЌМЏЕФЯрЙиХфжУаХЯЂЁЃ
9.2 ЗжЦЌМќ
MongoDB МЏКЯШєвЊВЩгУЗжЦЌЃЌБиаывЊжИЖЈЗжЦЌМќЃЈshard keyЃЉЁЃЗжЦЌМќгЩЮФЕЕжаЕФвЛИіЛђЖрИізжЖЮзщГЩЁЃЗжЦЌМЏКЯБиаыОпгажЇГжЗжЦЌМќЕФЫїв§ЃЌЫїв§ПЩвдЪЧЗжЦЌМќЕФЫїв§ЃЌвВПЩвдЪЧвдЗжЦЌМќЪЧЫїв§ЧАзКЕФИДКЯЫїв§ЁЃвЊЖдвбЬюГфЕФМЏКЯНјааЗжЦЌЃЌИУМЏКЯБиаыОпгавдЗжЦЌМќПЊЭЗЕФЫїв§ЃЛЗжЦЌвЛИіПеМЏКЯЪБЃЌШчЙћИУМЏКЯЛЙУЛгаАќКЌжИЖЈЗжЦЌМќЕФЫїв§ЃЌдђ
MongoDB ЛсФЌШЯИјЗжЦЌМќДДНЈЫїв§ЁЃ
ЖдгквЛИіМДНЋвЊЗжЦЌЕФМЏКЯЃЌШчЙћИУМЏКЯОпгаЦфЫћЮЈвЛЫїв§ЃЌдђЮоЗЈЗжЦЌИУМЏКЯЁЃ
ЖдгквбЗжЦЌЕФМЏКЯЃЌВЛФмдкЦфЫћзжЖЮЩЯДДНЈЮЈвЛЫїв§ЁЃ
4.2 АцБОПЊЪМПЩвдИќИФЮФЕЕЕФЗжЦЌМќжЕЃЌГ§ЗЧЗжЦЌМќзжЖЮЮЊВЛПЩБфЕФ _id зжЖЮЁЃИќаТЗжЦЌМќЪББиаыдкЪТЮёжаЛђвдПЩжиЪдаДШыЕФЗНЪНдк
mongos ЩЯдЫааЃЌВЛФмжБНгдкЗжЦЌЩЯжДааВйзїЁЃдкДЫжЎЧАЮФЕЕЕФЗжЦЌМќзжЖЮжЕЪЧВЛПЩБфЕФЁЃ
4.4 АцБОПЊЪМЃЌПЩвдЯђЯжгаЦЌМќжаЬэМгвЛИіЛђЖрИіКѓзКзжЖЮвдгХЛЏМЏКЯЕФЦЌМќЁЃ
5.0 АцБОПЊЪМЃЌЪЕЯжСЫЪЕЪБжиаТЗжЦЌЃЈlive reshardingЃЉЃЌПЩвдЪЕЯжЗжЦЌМќЕФЭъШЋжиаТбЁдёЁЃlive
resharding ЛњжЦЯТЃЌЪ§ОнНЋИљОнаТЕФЗжЦЌЙцдђНјааЧЈвЦЃЌВЛЙ§гавЛаЉЯожЦЃЌБШШчвЛИіЪЕР§жагаЧвжЛФмгавЛИіМЏКЯдкЯрЭЌЕФЪБМфЯТ
resharding ЕШЁЃ
Ъ§ОнПтПЩвдЛьКЯЪЙгУЗжЦЌКЭЮДЗжЦЌМЏКЯЁЃЗжЦЌМЏКЯБЛЗжЧјВЂЗжВМдкМЏШКжаЕФИїИіЗжЦЌжаЁЃЖјЮДЗжЦЌМЏКЯНіДцДЂдкжїЗжЦЌжаЁЃ
ЩшжУ shard key ЪБгІИУГфЗжПМТЧШЁжЕЛљЪ§КЭШЁжЕЗжВМЁЃЗжЦЌМќгІБЛОЁПЩФмЖрЕФвЕЮёГЁОАгУЕНЁЃОЁПЩФмБмУтЪЙгУЕЅЕїЕндіЛђЕнМѕЕФзжЖЮзїЮЊЗжЦЌМќЁЃ
9.3 ЗжЦЌВпТд
MongoDB НЋЗжЦЌЪ§ОнВ№ЗжГЩПщЁЃУПИіЗжПщЖМгавЛИіЛљгкЗжЦЌМќЕФЩЯЯТЯоЗЖЮЇ ЁЃЗжЦЌВпТдАќРЈЙўЯЃЗжЦЌЁЂЗЖЮЇЗжЦЌКЭздЖЈвх
zone ЗжЦЌЁЃ
ЙўЯЃЗжЦЌЛсМЦЫуЗжЦЌМќзжЖЮЕФЙўЯЃжЕЃЌетИіжЕБЛгУзїЦЌМќЃЌШЛКѓИљОнЙўЯЃжЕЕФЩЂСаЮЊУПИіПщЗжХфвЛИіЗЖЮЇЁЃ
ЗЖЮЇЗжЦЌИљОнЗжЦЌМќЕФжЕНЋЪ§ОнЛЎЗжЮЊЖрИіСЌајЗЖЮЇЁЃЃЌШЛКѓЛљгкЗжЦЌМќЕФжЕЗжХфУПИіПщЕФЗЖЮЇЁЃЕБЦЌМќЕФЛљЪ§ДѓЁЂЦЕТЪЕЭЧвжЕЗЧЕЅЕїБфИќЪБЃЌЗЖЮЇЗжЦЌИќИпаЇЁЃ
здЖЈвх zone ЗжЦЌЛљгк shard key ДДНЈЁЃУПИі zone гыМЏШКжаЕФвЛИіЛђепИќЖрЗжЦЌЙиСЊЁЃвЛИіЗжЦЌПЩвдКЭШЮвтЪ§ФПЕФЗЧГхЭЛ
zone ЯрЙиСЊЁЃ
10 MongoDB ОлКЯ
MongoDB ОлКЯПђМмЃЈAggregation FrameworkЃЉЪЧвЛИіМЦЫуПђМмЃЌЙІФмЪЧЃК
зїгУдквЛИіЛђМИИіМЏКЯЩЯЁЃ
ЖдМЏКЯжаЕФЪ§ОнНјааЕФвЛЯЕСадЫЫуЁЃ
НЋетаЉЪ§ОнзЊЛЏЮЊЦкЭћЕФаЮЪНЁЃ
MongoDB ЬсЙЉСЫШ§жжжДааОлКЯЕФЗНЗЈЃКОлКЯЙмЕРЃЌmap-reduce КЭЕЅвЛФПЕФОлКЯЗНЗЈЃЈШч countЁЂdistinct
ЕШЗНЗЈЃЉЁЃ
10.1 ОлКЯЙмЕР
дкОлКЯЙмЕРжаЃЌећИіОлКЯдЫЫуЙ§ГЬГЦЮЊЙмЕРЃЈpipelineЃЉЃЌЫќЪЧгЩЖрИіВНжшЃЈstageЃЉзщГЩЕФЃЌ УПИіЙмЕРЕФЙЄзїСїГЬЪЧЃК
НгЪмвЛЯЕСадЪМЪ§ОнЮФЕЕ
ЖдетаЉЮФЕЕНјаавЛЯЕСадЫЫу
НсЙћЮФЕЕЪфГіИјЯТвЛИі stage
ОлКЯМЦЫуЛљБОИёЪНШчЯТЃК

10.2 map-reduce
map-reduce ВйзїАќРЈСНИіНзЖЮЃКmap НзЖЮДІРэУПИіЮФЕЕВЂНЋ key гы value ДЋЕнИј
reduce КЏЪ§НјааДІРэЃЌreduce НзЖЮНЋ map ВйзїЕФЪфГізщКЯдквЛЦ№ЁЃmap-reduce
ПЩЪЙгУздЖЈвх JavaScript КЏЪ§РДжДаа map КЭ reduce ВйзїЃЌвдМАПЩбЁЕФ finalize
ВйзїЁЃЭЈГЃЧщПіЯТаЇТЪБШОлКЯЙмЕРЕЭЁЃ
10.3 ЕЅвЛФПЕФОлКЯЗНЗЈ
жївЊАќРЈвдЯТШ§ИіЃК
db.collection.estimatedDocumentCount()
db.collection.count()
db.collection.distinct()
11 MongoDB вЛжТад
ЗжВМЪНЯЕЭГгаИі PACELC РэТлЁЃИљОн CAPЃЌдквЛИіДцдкЭјТчЗжЧјЃЈPЃЉЕФЗжВМЪНЯЕЭГжаЃЌвЊУцСйдкПЩгУадЃЈAЃЉКЭвЛжТадЃЈCЃЉжЎМфЕФШЈКтЃЌГ§ДЫжЎЭтЃЈEЃЉЃЌМДЪЙУЛгаЭјТчЗжЧјЕФДцдкЃЌдкЪЕМЪЯЕЭГжаЃЌЮвУЧвВвЊУцСйдкЗУЮЪбгГйЃЈLЃЉКЭвЛжТадЃЈCЃЉжЎМфЕФШЈКтЁЃMongoDB
ЕФвЛжТадФЃаЭЖдЖСаДВйзї L КЭ C ЕФбЁдёЬсЙЉСЫЗсИЛЕФбЁЯюЁЃ
11.1 вђЙћвЛжТад
ЕЅНкЕуЕФЪ§ОнПтгЩгкЮЊЖСаДВйзїЬсЙЉСЫЫГађБЃжЄЃЌвђДЫЪЕЯжСЫвђЙћвЛжТадЁЃЗжВМЪНЯЕЭГЭЌбљПЩвдЬсЙЉетаЉБЃжЄЃЌЕЋБиаыЖдЫљгаНкЕуЩЯЕФЯрЙиЪТМўНјаааЕїКЭХХађЁЃ
вдЯТЪЧвЛИіВЛзёбвђЙћвЛжТадЕФР§згЃК
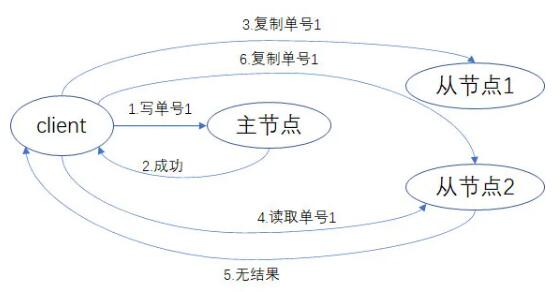
ЮЊСЫБЃГжвђЙћвЛжТадЃЌБиаыгавдЯТБЃжЄЃК

ЪЕЯжвђЙћвЛжТадЕФЕЅКХЖСаДгІзёбвдЯТСїГЬЃК
ЮЊСЫНЈСЂИДжЦМЏКЭЗжЦЌМЏЪТМўЕФШЋОжЦЋађЙиЯЕЃЌMongoDB ЪЕЯжСЫвЛИіТпМЪБжгЃЌГЦЮЊ lamport
logical clockЁЃУПИіаДВйзїдкгІгУгкжїНкЕуЪБЖМЛсБЛЗжХфвЛИіЪБМфжЕЁЃетИіжЕПЩвддкИББОКЭЗжЦЌжЎМфНјааБШНЯЁЃ
ДгЧ§ЖЏЕНВщбЏТЗгЩЦїдйЕНЪ§ОнГадиНкЕуЃЌЗжЦЌМЏШКжаЕФУПИіГЩдБЖМБиаыдкУПЬѕЯћЯЂжаИњзйКЭЗЂЫЭЦфзюаТЪБМфжЕЃЌДгЖјдЪаэЗжЦЌжЎМфЕФУПИіНкЕудкзюаТЪБМфБЃГжвЛжТЁЃ
жїНкЕуНЋзюаТЕФЪБМфжЕИГжЕИјКѓајЕФаДШыЃЌетЮЊШЮКЮвЛЯЕСаЯрЙиВйзїДДНЈСЫвЛИівђЙћЫГађЁЃНкЕуПЩвдЪЙгУетИівђЙћЫГађдкжДааЫљашЕФЖСЛђаДжЎЧАЕШД§ЃЌвдШЗБЃЫќдкСэвЛИіВйзїжЎКѓЗЂЩњЁЃ
Дг MongoDB 3.6 ПЊЪМЃЌдкПЭЛЇЖЫЛсЛАжаПЊЦєвђЙћвЛжТадЃЌБЃжЄ read concern ЮЊ
majority ЕФЖСВйзїКЭ write concern ЮЊ majority ЕФаДВйзїЕФЙиСЊађСаОпгавђЙћЙиЯЕЁЃгІгУГЬађБиаыШЗБЃвЛДЮжЛгавЛИіЯпГЬдкПЭЛЇЖЫЛсЛАжажДааетаЉВйзїЁЃ
ЖдгквђЙћЯрЙиЕФВйзїЃК
ПЭЛЇЖЫПЊЦєПЭЛЇЖЫЛсЛАЃЌашТњзувдЯТЬѕМўЃКread concern ЮЊ majorityЃЌЪ§ОнвбБЛДѓЖрЪ§ИДжЦМЏГЩдБШЗШЯВЂЧвЪЧГжОУЛЏЕФЃЛwrite
concern ЮЊ majorityЃЌШЗШЯИУВйзївбгІгУгкИДжЦМЏжаДѓЖрЪ§ПЩЭЖЦБГЩдБЁЃ
ЕБПЭЛЇЖЫЗЂГі read concern ЮЊ majority ЕФЖСВйзїКЭ write concern
ЮЊ majority ЕФаДВйзїЕФађСаЪБЃЌПЭЛЇЖЫНЋЛсЛАаХЯЂАќКЌдкУПИіВйзїжаЁЃ
ЖдгкгыЛсЛАЯрЙиСЊЕФУПИі read concern ЮЊ majority ЕФЖСВйзїКЭ write concern
ЮЊ majority ЕФаДВйзїЃЌМДЪЙВйзїГіДэЃЌMongoDB вВЛсЗЕЛиВйзїЪБМфКЭМЏШКЪБМфЁЃ
ЯрЙиЕФПЭЛЇЖЫЛсЛАЛсИњзйетСНИіЪБМфзжЖЮЁЃ
11.2 ЯпадвЛжТад
ЯпадвЛжТадгжБЛГЦЮЊЧПвЛжТадЁЃCAP жаЕФ C жИЕФОЭЪЧЯпадвЛжТадЁЃЫГађвЛжТаджаНјГЬжЛЙиаФИїздЕФЫГађвЛбљОЭааЃЌВЛашвЊгыШЋОжЪБжгвЛжТЁЃЯпадвЛжТадЪЧЫГађвЛжТадЕФНјЛЏАцЃЌвЊЧѓЫГађвЛжТадЕФетжжЦЋађЃЈpartial
orderЃЉвЊДяЕНШЋађЃЈtotal orderЃЉЁЃ
дкЪЕЯжСЫЯпадвЛжТадЕФЯЕЭГжаЃЌШЮКЮВйзїдкИУЯЕЭГЩњаЇЕФЪБПЬЖМЖдгІЪБМфжсЩЯЕФвЛИіЕуЁЃАбетаЉЪБПЬСЌНгГЩвЛЬѕЯпЃЌдђетЬѕЯпЛсвЛжБбиЪБМфжсЯђЧАЃЌВЛЛсЗДЯђЁЃШЮКЮВйзїЖМашвЊЛЅЯрБШНЯОіЖЈЗЂЩњЕФЫГађЁЃ
вдЯТЪЧвЛИіЯпадвЛжТадЕФЯЕЭГЪОР§ЃК
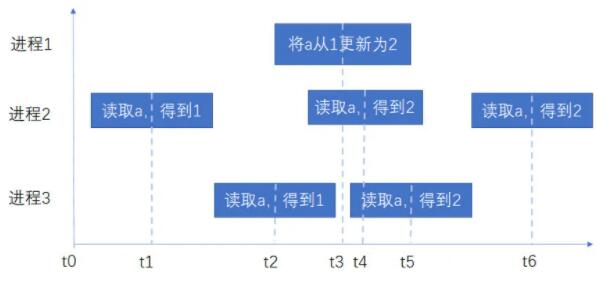
дквдЩЯЯЕЭГжаЃЌаДВйзїЩњаЇжЎЧАЕФШЮКЮЪБПЬЃЌЖСШЁжЕОљЮЊ 1ЃЌЩњаЇКѓОљЮЊ 2ЁЃвВОЭЪЧЫЕЃЌШЮКЮЖСВйзїЖМФмЖСЕНФГИіЪ§ОнЕФзюНќвЛДЮаДЕФЪ§ОнЁЃЯЕЭГжаЕФЫљгаНјГЬПДЕНЕФВйзїЫГађЃЌЖМзёбШЋОжЪБжгЕФЫГађЁЃ
11.3 read concern
read concern ЪЧеыЖдЖСВйзїЕФХфжУЁЃЫќПижЦЖСШЁЪ§ОнЕФаТНќЖШКЭГжОУадЁЃread concern
бЁЯюПижЦЪ§ОнЖСШЁЕФвЛжТадЃЌЗжЮЊ localЁЂavailableЁЂmajorityЁЂlinearizable
ЫФжжЃЌЫќУЧЖдвЛжТадЕФГаХЕвРДЮгЩШѕЕНЧПЁЃЦфжа linearizable БэЪОЯпадвЛжТадЃЌСэЭт 3 жжМЖБ№ДњБэСЫ
MongoDB дкЪЕЯжзюжевЛжТадЪБЃЌЖдЗУЮЪбгГйКЭвЛжТадЕФШЁЩсЁЃ
local/available: гявхЛљБОвЛжТЃЌЖМЪЧЖСВйзїжБНгЖСШЁБОЕизюаТЕФЪ§ОнЃЌЕЋВЛБЃжЄИУЪ§ОнвбБЛаДШыДѓЖрЪ§ИДжЦМЏГЩдБЁЃЪ§ОнПЩФмЛсБЛЛиЙіЁЃФЌШЯЪЧеыЖджїНкЕуЖСЁЃШчЙћЖСШЁВйзїгывђЙћвЛжТЕФЛсЛАЯрЙиСЊЃЌдђеыЖдИБНкЕуЖСЁЃЮЈвЛЕФЧјБ№дкгкЃЌavaliable
дкЗжЦЌМЏШКГЁОАЯТЃЌЮЊСЫБЃжЄадФмЃЌПЩФмЗЕЛиЙТЖљЮФЕЕЁЃ
majorityЃКЖСШЁ majority committed ЕФЪ§ОнЃЌПЩвдБЃжЄЖСШЁЕФЪ§ОнВЛЛсБЛЛиЙіЃЌЕЋЪЧВЂВЛФмБЃжЄЖСЕНБОЕизюаТЕФЪ§ОнЁЃЪмЯогкВЛЭЌНкЕуЕФИДжЦНјЖШЃЌПЩФмЛсЖСШЁЕНИќОЩЕФжЕЁЃЕБаДВйзїЖдгІЕФ
write concern ХфжУжа w ЕФжЕдНДѓЃЌдђаДВйзїдкРЉЩЂЕНИќЖрЕФИДжЦМЏНкЕуЩЯжЎКѓВХЗЕЛиаДГЩЙІЃЌетЪБЭЈЙ§
read concern БЛХфжУЮЊ majority ЕФЖСВйзїНјааЖСШЁЪ§ОнЃЌОЭгаИќДѓЕФИХТЪЖСШЁЕНзюаТЕФЪ§ОнЁЃ
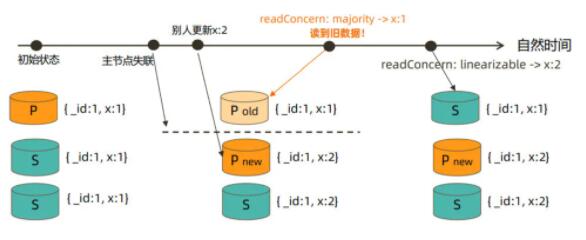
linearizableЃКЖСШЁ majority committed ЕФЪ§ОнЃЌЕЋЛсЕШД§дкЖСжЎЧАЫљгаЕФ
majority committed ШЗШЯЁЃЫќГаХЕЯпадвЛжТадЃЌвЊЧѓЖСаДЫГађКЭВйзїецЪЕЗЂЩњЕФЪБМфЭъШЋвЛжТЃЌМШБЃжЄФмЖСШЁЕНзюаТЕФЪ§ОнЃЌвВБЃжЄЖСЕНЪ§ОнВЛЛсБЛЛиЙіЁЃжЛЖдЖСШЁЕЅИіЮФЕЕЪБгааЇЃЌЧвПЩФмЕМжТЗЧГЃТ§ЕФЖСЃЌвђДЫзмЪЧНЈвщХфКЯЪЙгУ
maxTimeMS ЪЙгУЁЃ
linearizable жЛФмгУдкжїНкЕуЕФЖСВйзїЩЯЃЌПМТЧЕНаДВйзївВжЛФмЗЂЩњдкжїНкЕуЩЯЃЌЯрЕБгкЫЕ MongoDB
ЕФЯпадвЛжТадБЛЯоЖЈдкЕЅЛњЛЗОГЯТЪЕЯжЁЃЪЕЯж linearizableЃЌЖСШЁЕФЪ§ОнгІИУЪЧБЛ write
concern ЮЊ majority ЕФаДВйзїаДШыЕН MongoDB МЏШКжаЕФЁЂЧвГжОУЛЏЕНШежОжаЕФЪ§ОнЁЃ
ШчЙћЪ§ОнаДШыЕНЖрЪ§НкЕуКѓЃЌУЛгадкШежОжаГжОУЛЏЃЌЕБетаЉНкЕуЗЂЩњжиЦєЛжИДЃЌФЧУДжЎЧАЭЈЙ§ХфжУ read concern
ЮЊ linearizable ЕФЖСВйзїЖСШЁЕНЕФЪ§ОнОЭПЩФмЖЊЪЇЁЃПЩвдЭЈЙ§ writeConcernMajorityJournalDefault
бЁЯюБЃжЄжИЖЈ write concern ЮЊ majority ЕФаДВйзїдкШежОжаЪЧЗёГжОУЛЏЁЃШчЙћаДВйзїГжОУЛЏЕНСЫШежОжаЃЌЕЋЪЧУЛгаИДжЦЕНЖрЪ§НкЕуЃЌдкжиаТбЁжїКѓЃЌЭЌбљПЩФмЛсЗЂЩњЪ§ОнЖЊЪЇЃЌЮЅБГвЛжТадГаХЕЁЃ
snapshot: гыЙиЯЕаЭЪ§ОнПтжаЕФПьееИєРыМЖБ№гявхвЛжТЁЃзюИпИєРыМЖБ№ЃЌНгНќгк serializableЁЃЪЧАщЫцзХ
MongoDB 4.0 АцБОжааТГіЯжЕФЖрЮФЕЕЪТЮёЖјЩшМЦЕФЃЌжЛФмгУдкЯдЪНПЊЦєЕФЖрЮФЕЕЪТЮёжаЁЃШчЙћЪТЮёЪЧвђЙћвЛжТЛсЛАЕФвЛВПЗжЃЌЧв
write concern ЮЊ majorityЃЌдђдкЪТЮёЬсНЛКѓЃЌЖСВйзїПЩвдБЃжЄвбДгЖрЪ§ЬсНЛЪ§ОнЕФПьеежаЖСШЁЃЌИУПьееЬсЙЉгыИУЪТЮёПЊЪМжЎЧАЕФВйзїЕФвђЙћвЛжТадЁЃ
ЫќЖСШЁ majority committed ЕФЪ§ОнЃЌЕЋПЩФмЖСВЛЕНзюаТЕФвбЬсНЛЪ§ОнЁЃsnapshot
БЃжЄдкЪТЮёжаЕФЖСВЛГіЯждрЖСЁЂВЛПЩжиИДЖСКЭЛУЖСЁЃвђЮЊЫљгаЕФЖСЖМНЋЪЙгУЭЌвЛИіПьееЃЌжБЕНЪТЮёЬсНЛЮЊжЙИУПьееВХБЛЪЭЗХЁЃ
ЯТУцНшгУвЛеХЭМеЙЪО majority КЭ linearizable ЕФЧјБ№ЃК
11.4 write concern
write concern ЪЧеыЖдаДВйзїЕФХфжУЃЌБэЪОаДЧыЧѓЖдЖРСЂ mongod ЪЕР§ЛђИДжЦМЏЛђЗжЦЌМЏНјаааДВйзїЕФШЗШЯМЖБ№ЁЃЫќжївЊЪЧПижЦЪ§ОнаДШыЕФГжОУадЁЃАќКЌШ§ИібЁЯюЃК
wЃКжИЖЈСЫаДВйзїашвЊИДжЦВЂгІгУЕНЖрЩйИіИДжЦМЏГЩдБВХФмЗЕЛиГЩЙІЃЌПЩвдЮЊЪ§зжЛђ majorityЁЃ
w:0 БэЪОПЭЛЇЖЫВЛашвЊЪеЕНШЮКЮгаЙиаДВйзїЪЧЗёжДааГЩЙІЕФШЗШЯЃЌОЭжБНгЗЕЛиГЩЙІЃЌОпгазюИпадФмЁЃ
w:1 БэЪОаДжїГЩЙІдђЗЕЛиЁЃ
w: majority ашвЊЪеЕНЖрЪ§НкЕуЃЈКЌжїНкЕуЃЉЙигкВйзїжДааГЩЙІЕФШЗШЯЃЌОпЬхИіЪ§гЩ MongoDB
ИљОнИДжЦМЏХфжУздЖЏЕУГіЁЃw жЕдНДѓЃЌЖдПЭЛЇЖЫРДЫЕЃЌЪ§ОнЕФГжОУадБЃжЄдНЧПЃЌаДВйзїЕФбгГйдНДѓЁЃw:1 вЊЧѓЪТЮёжЛвЊдкБОЕиГЩЙІЬсНЛМДПЩЃЌЖј
w: majority вЊЧѓЪТЮёдкИДжЦМЏЕФЖрЪ§ХЩНкЕуЬсНЛГЩЙІЁЃ
w:all БэЪОШЋВПНкЕуШЗШЯВХЗЕЛиГЩЙІЁЃ
jЃКБэЪОаДВйзїЖдгІЕФаоИФЪЧЗёвЊБЛГжОУЛЏЕНДцДЂв§ЧцШежОжаЃЌжЛФмбЁЬю true Лђ falseЁЃ
j:false БэЪОаДВйзїЕНДяФкДцМДЫузїГЩЙІЁЃ
j:true БэЪОаДВйзїТфЕН journal ЮФМўжаВХЫуГЩЙІЁЃw:0 ШчЙћжИЖЈ j:trueЃЌдђгХЯШЪЙгУ
j:true РДЧыЧѓЖРСЂЛђИДжЦМЏжїИББОЕФШЗШЯЁЃj:true БОЩэВЂВЛФмБЃжЄВЛЛсвђИДжЦМЏжїЙЪеЯзЊвЦЖјЛиЙіаДВйзїЁЃ
wtimeoutЃКжїНкЕудкЕШД§зуЙЛЪ§СПЕФШЗШЯЪБЕФГЌЪБЪБМфЃЌЕЅЮЛЮЊКСУыЁЃГЌЪБЗЕЛиДэЮѓЃЌЕЋВЂВЛДњБэаДВйзївбОжДааЪЇАмЁЃИњ
w гаЙиЃЌБШШчЃКw ЪЧ 1ЃЌдђЪЧДјжїНкЕуШЗШЯЕФГЌЪБЪБМфЃЛw ЮЊ 0ЃЌдђгРВЛЗЕЛиДэЮѓЃЛw ЮЊ majorityЃЌБэЪОЖрЪ§НкЕуШЗШЯЕФГЌЪБЪБМфЁЃ
12 MongoDB WiredTiger в§Чц
Дг 3.2 АцБОПЊЪМЃЌФЌШЯЪЙгУ WiredTiger ДцДЂв§ЧцЃЌУПИіБЛДДНЈЕФБэКЭЫїв§ЃЌЖМЖдгІИїздЖРСЂЕФ
WiredTiger БэЁЃЮЊСЫБЃжЄ MongoDB жаЪ§ОнЕФГжОУадЃЌЪЙгУ WiredTiger ЕФаДВйзїЛсЯШаДШы
cacheЃЌВЂГжОУЛЏЕН WALЃЈwrite ahead logЃЉЃЌУП 60s ЛђШежОЮФМўДяЕН 2 GBЃЌОЭЛсзівЛДЮ
checkpointЃЌЖЈЦкНЋЛКДцЪ§ОнЫЂЕНДХХЬЃЌНЋЕБЧАЕФЪ§ОнГжОУЛЏВњЩњвЛИіаТЕФПьееЁЃ
12.1 WiredTiger Ъ§ОнНсЙЙ
MongoDB ВЩгУВхМўЪНДцДЂв§ЧцМмЙЙЃЌЪЕЯжСЫЗўЮёВуКЭДцДЂв§ЧцВуЕФНтёюЃЌПЩжЇГжЪЙгУЖржжДцДЂв§ЧцЁЃГ§ДЫжЎЭтЃЌЕзВуЕФ
WiredTiger в§ЧцЛЙжЇГжЪЙгУ B+ ЪїКЭ LSM СНжжЪ§ОнНсЙЙНјааЪ§ОнЙмРэКЭДцДЂЃЌФЌШЯЪЙгУ
B+ ЪїНсЙЙзіДцДЂЁЃЪЙгУ B+ ЪїЪБЃЌWiredTiger вд page ЮЊЕЅЮЛЭљДХХЬЖСаДЪ§ОнЃЌB+
ЪїЕФУПИіНкЕуЮЊвЛИі pageЃЌАќКЌШ§жжРраЭЕФ pageЃЌМД root pageЁЂinternal page
КЭ leaf pageЁЃ
вдЯТЪЧ B+ ЪїЕФНсЙЙЪОвтЭМЃК
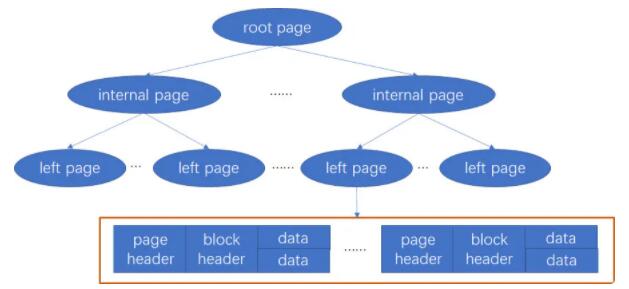
root page ЪЧ B+ ЪїЕФИљНкЕуЁЃ
internal page ЪЧВЛЪЕМЪДцДЂЪ§ОнЕФжаМфЫїв§НкЕуЁЃ
leaf page ЪЧеце§ДцДЂЪ§ОнЕФвЖзгНкЕуЃЌАќКЌвГЭЗЃЈpage headerЃЉЁЂПщЭЗЃЈblock
headerЃЉКЭеце§ЕФЪ§ОнЃЈkey-value ЖдЃЉЁЃpage header ЖЈвхСЫвГЕФРраЭЁЂвГДцДЂЕФМЧТМЬѕЪ§ЕШаХЯЂЃЛПщЭЗЖЈвхСЫвГЕФаЃбщКЭ
checksumЁЂПщдкДХХЬЩЯЕФбАжЗЮЛжУЕШаХЯЂЁЃ
еце§ЕФЪ§ОнгЩвЛИі WT_ROW НсЙЙЕФЪ§зщБфСПНјааДцДЂЃЌУПвЛЬѕМЧТМЛЙгавЛИі cell_offset
БфСПЃЌБэЪОетЬѕМЧТМдк page ЩЯЕФЦЋвЦСПЁЃWiredTiger гавЛИігУРДЮЊ page ЗжХф block
ЕФПщЩшБИЙмРэФЃПщЁЃЖЈЮЛЮФЕЕЮЛжУЪБЃЌЯШМЦЫу block ЕФЮЛжУЃЌЭЈЙ§ block ЕФЮЛжУевЕНЫќЖдгІЕФ
pageЃЌдйЭЈЙ§ page евЕНЮФЕЕааЪ§ОнЕФЯрЖдЮЛжУЁЃ
leaf page ЮЊСЫЪЕЯж MVCCЃЌЛЙЛсЮЌЛЄвЛИі WT_UPDATE НсЙЙЕФЪ§зщБфСПЃЌУПЬѕМЧТМЖдгІвЛИіЪ§зщдЊЫиЃЌУПИідЊЫиЪЧвЛИіСДБэЃЌНЋЫљгааоИФжЕвдСДБэаЮЪНБЃДцЁЃ
12.2 WiredTiger бЙЫѕ
WiredTiger жЇГждкФкДцКЭДХХЬЩЯЖдЫїв§НјаабЙЫѕЃЌЭЈЙ§ЧАзКбЙЫѕЕФЗНЪНМѕЩй RAM ЕФЪЙгУЁЃ
12.3 WiredTiger вЛжТаддРэ
WiredTiger ЪЙгУСЫЖўМЖЛКДц WiredTiger Cache КЭ File System
Cache РДБЃжЄ Disk ЩЯ Database File Ъ§ОнЕФзюжевЛжТадЁЃ
WiredTiger CacheЃКЭЈЙ§ B+ ЪїЛКДцЮДбЙЫѕЕФЪ§ОнЃЌВЂЭЈЙ§ЬдЬЫуЗЈШЗБЃФкДцеМгУдкКЯРэЗЖЮЇФкЁЃ
File System CacheЃКгЩВйзїЯЕЭГЙмРэЃЌЛКДцбЙЫѕКѓЕФЪ§ОнЁЃ
Database FileЃКДцДЂбЙЫѕКѓЕФЪ§ОнЁЃУПИі WiredTiger БэЖдгІвЛИіЖРСЂЕФДХХЬЮФМўЁЃДХХЬЮФМўЛЎЗжГЩЖрИіАД
4 KB ЖдЦыЕФ extentЃЌВЂЭЈЙ§ 3 ИіСДБэРДЙмРэЃКavailable listЃЈПЩЗжХфЕФ extent
СаБэ) ЃЌdiscard listЃЈЗЯЦњЕФ extent СаБэЃЉКЭ allocate listЃЈЕБЧАвбЗжХфЕФ
extent СаБэЃЉ
12.4 WiredTiger MVCC
WiredTiger ЪЙгУ MVCC НјаааДВйзїЃЌЖрИіПЭЛЇЖЫПЩвдВЂЗЂЭЌЪБаоИФМЏКЯЕФВЛЭЌЮФЕЕЁЃЪТЮёПЊЪМЪБЃЌWiredTiger
ЮЊВйзїЬсЙЉЗДгГФкДцЪ§ОнЕФвЛжТЪгЭМЕФЪБМфЕуПьееЁЃMVCC ЭЈЙ§ЗЧЫјЛњжЦНјааЖСаДВйзїЃЌЪЧвЛжжРжЙлВЂЗЂПижЦФЃЪНЁЃWiredTiger
НідкШЋОжЁЂЪ§ОнПтКЭМЏКЯМЖБ№ЪЙгУвтЯђЫјЁЃЕБДцДЂв§ЧцМьВтЕНСНИіВйзїжЎМфДцдкГхЭЛЪБЃЌНЋв§ЗЂаДГхЭЛЃЌДгЖјЕМжТ
MongoDB здЖЏжиЪдИУВйзїЁЃ
ЪЙгУ WiredTigerЃЌШчЙћУЛга journal МЧТМЃЌMongoDB ФмЧвНіФмДгзюКѓвЛИіМьВщЕуЛжИДЁЃШчЙћашвЊЛжИДзюКѓвЛДЮ
checkpoint жЎКѓЫљзіЕФИќИФЃЌФЧУДПЊЦєШежОЪЧБивЊЕФЁЃ
13 MongoDB Ъ§ОнЖСаД
13.1 ЖСЦЋКУ ReadPerference
ФЌШЯЧщПіЯТЃЌПЭЛЇЖЫЖСШЁИДжЦМЏжїНкЕуЩЯЕФЪ§ОнЁЃЕЋПЭЛЇЖЫПЩвджИЖЈвЛИі read perference ИФБфЖСШЁааЮЊЃЌвдБуЖдИДжЦМЏЩЯЕФЦфЫћНкЕуНјаажБНгЖСВйзїЁЃПЩбЁжЕАќРЈЃК

13.2 дкИДжЦМЏЩЯНјааЖСаДВйзї
ЖСВйзїгЩПЭЛЇЖЫжИЖЈЕФ read prefenence бЁЯюОіЖЈЁЃ
ЫљгаЕФаДВйзїЖМдкМЏКЯЕФжїНкЕуЩЯжДааЁЃжїНкЕужДаааДВйзїВЂНЋВйзїМЧТМдкВйзїШежОЛђ oplog ЩЯЁЃoplog
ЪЧ local Ъ§ОнПтЕФвЛИіМЏКЯЃЌНа local.oplog.rsЁЃетЪЧвЛИі capped collectionЃЌЪЧЙЬЖЈДѓаЁЃЌбЛЗЪЙгУЕФЁЃoplog
ЪЧЖдЪ§ОнМЏЕФПЩжиИДВйзїађСаЃЌЦфМЧТМЕФУПИіВйзїЖМЪЧУнЕШЕФЃЌвВОЭЪЧЫЕЃЌЖдФПБъЪ§ОнМЏгІгУвЛДЮЛђЖрДЮ oplog
ВйзїЖМЛсВњЩњЯрЭЌЕФНсЙћЁЃ
ДгНкЕуДгЩЯвЛДЮНсЪјЪБМфЕуНЈСЂ tailable cursorЃЌВЛЖЯЕФДгЭЌВНдДРШЁ oplog ВЂжиЗХгІгУЕНздЩэЃЌЧвбЯИёАДеедЪМЕФаДЫГађЖдИјЖЈЕФЮФЕЕжДаааДВйзїЁЃmongodb
ЪЙгУЖрЯпГЬХњСПжДаааДВйзїРДЬсИпВЂЗЂЃЌИљОнЮФЕЕ id НјааЗжХњжДааЁЃMongoDB ЮЊСЫЬсЩ§ЭЌВНаЇТЪЃЌНЋРШЁ
oplog вдМАжиЗХ oplog ЗжЕНСЫВЛЭЌЕФЯпГЬРДжДааЁЃ
ДѓжТЕФаДСїГЬШчЯТЃК
producer thread ВЛЖЯЕФДгжїНкЕуЩЯРШЁ oplogЃЌВЂАбЫќМгШыЕНвЛИі blockQueue
РяЃЌblockQueue ВЛЪЧЮоЯоШнСПЕФЃЌЕБГЌЙ§зюДѓДцДЂШнСПЃЌproducer thread ОЭБиаыЕШЕН
oplog БЛ replBatcher thread ДгЖгСаРяШЁГіКѓВХФмМЬајРШЁ oplogЁЃ
replBatcher thread ВЛЖЯДг producer thread ЖдгІЕФ blockQueue
РяШЁГі oplogЃЌЗХЕНздМКЕФФкДцЖгСаРяЃЌФкДцЖгСавВВЛЪЧЮоЯоШнСПЃЌвЛЕЉТњСЫЃЌОЭашвЊЕШД§БЛ oplogApplication
thread ЯћЗбЁЃ
oplogApplication thread ВЛЖЯШЁГі replBatch thread ФкДцЖгСаРяЕФЫљгадЊЫиЃЌЗжЩЂЕНВЛЭЌЕФ
replWriter threadЃЌгЩ replWriter thread ИљОн oplog НјаааДВйзїЁЃЕШД§Ыљга
oplog ЖМгІгУЭъБЯЃЌoplogApplication hread НЋЫљгаЕФ oplog ЫГађаДШыЕН
local.oplog.rs МЏКЯЁЃ
13.3 дкЗжЦЌМЏШКЩЯНјааЖСаДВйзї
ЖдгкЗжЦЌМЏШКЃЌашвЊвЛИі mongos ЪЕР§ЬсЙЉПЭЛЇЖЫгІгУГЬађКЭЗжЦЌМЏШКжЎМфЕФНгПкЁЃдкПЭЛЇЖЫПДРДЃЌИУ
mongos ЪЕР§ЕФааЮЊгыЦфЫћ MongoDB ЪЕР§ЪЧЯрЭЌЕФЁЃПЭЛЇЖЫЯђТЗгЩНкЕу mongos ЗЂЫЭЧыЧѓЃЌгЩИУНкЕуОіЖЈЭљФФИіЗжЦЌНјааЖСаДЁЃЖдгкЖСШЁВйзїЃЌШєФмЖЈЯђЕНЬиЖЈЗжЦЌЪБЃЌаЇТЪзюИпЁЃ
вЛАуЖјбдЃЌЗжЦЌМЏКЯЕФВщбЏгІАќКЌМЏКЯЕФЗжЦЌМќЃЌвдБмУтЕЭаЇЕФШЋЗжЦЌВщбЏЁЃдкетжжЧщПіЯТЃЌmongos ПЩвдЪЙгУХфжУЪ§ОнПт
config жаЕФМЏШКдЊЪ§ОнаХЯЂЃЌНЋВщбЏТЗгЩЕНЗжЦЌЁЃШчЙћВщбЏВЛАќКЌЗжЦЌМќЃЌдђ mongos НкЕуБиаыНЋВщбЏЖЈЯђЕНМЏШКжаЕФЫљгаЗжЦЌЃЌШЛКѓдк
mongos ЩЯОлКЯЫљгаЗжЦЌЕФВщбЏНсЙћЃЌЗЕЛиИјПЭЛЇЖЫЁЃ
ЖдгкаДВйзїЃЌ mongos ЖЈЯђЕНИКд№Ъ§ОнМЏЬиЖЈВПЗжЕФЗжЦЌЃЌconfig Ъ§ОнПтЩЯгаМЏКЯЯрЙиЕФЗжЦЌМќаХЯЂЃЌmongos
ДгжаЖСШЁХфжУЃЌВЂТЗгЩаДВйзїЕНЪЪЕБЕФЗжЦЌЁЃ
14 MongoDB ЪТЮё
14.1 ACID Ьиад
MongoDB дквЛЖЈГЬЖШЩЯжЇГжСЫЪТЮёЕФ ACID ЬиадЁЃMongoDB 4.0 АцБОПЊЪМжЇГжИДжЦМЏЩЯЕФЖрЮФЕЕЪТЮёЃЌ4.2
АцБОв§ШыСЫЗжВМЪНЪТЮёЃЌЫќдіМгСЫЖдЗжЦЌШКМЏЩЯЖрЮФЕЕЪТЮёЕФжЇГжЁЃ
дзгадЃКГЩЙІЬсНЛЪТЮёЪБЃЌЪТЮёжаЫљгаЪ§ОнИќаТНЋЭъШЋНјааГЩЙІЃЌВЂдкЪТЮёЭтВППЩМћЁЃдкЬсНЛЪТЮёжЎЧАЃЌЪТЮёЭтВППДВЛЕНдкЪТЮёжаНјааЕФШЮКЮЪ§ОнИќаТЁЃЕБЪТЮёБЛДђЖЯЛђжежЙЪБЃЌЪТЮёжаНјааЕФЫљгаЪ§ОнИќаТЖМНЋБЛЖЊЦњЃЌЖдЪТЮёЭтВПЭъШЋВЛПЩМћЁЃЕЋЪЧЕБЪТЮёаДШыЖрИіЗжЦЌЪБЃЌВЂЗЧЫљгаЪТЮёЭтЕФЖСВйзїЖМашвЊЕШД§ЪТЮёЬсНЛКѓЫљгаЗжЦЌЩЯЪ§ОнЭъШЋПЩМћЁЃ
ИєРыадЃКMongoDB ЬсЙЉ snapshot ИєРыМЖБ№ЃЌдкЪТЮёПЊЪМДДНЈвЛИі WiredTiger
snapshotЃЌШЛКѓдкећИіЪТЮёЙ§ГЬжаЃЌБуПЩвдЪЙгУетИіПьееЬсЙЉЪТЮёЖСЁЃ
ГжОУадЃКЪТЮёЪЙгУ write concern жИЖЈ {j: true} ЪБЃЌMongoDB ЛсБЃжЄЪТЮёШежОЬсНЛВХЗЕЛиЃЌМДЪЙЗЂЩњ
crashЃЌвВФмИљОнЪТЮёШежОРДЛжИДЃЛЖјШчЙћУЛгажИЖЈ {j: true} МЖБ№ЃЌМДЪЙЪТЮёЬсНЛГЩЙІСЫЃЌдкЙЪеЯЛжИДжЎКѓЃЌЪТЮёЕФвВПЩФмБЛЛиЙіЕєЁЃ
вЛжТадЃКВЮПМЧАЮФЬсЕНЕФ MongoDB вЛжТадЁЃ
14.2 ЪТЮёЕФЪЙгУЯожЦ
Ні WiredTiger в§ЧцжЇГжЪТЮёЁЃ
ЖдМЏКЯЕФДДНЈКЭЩОГ§ВйзїЃЌВЛФмГіЯждкЪТЮёжаЁЃ
ЖдЫїв§ЕФДДНЈКЭЩОГ§ВйзїЃЌВЛФмГіЯждкЪТЮёжаЁЃ
ВЛФмЖдЯЕЭГМЖБ№ЕФЪ§ОнПтКЭМЏКЯНјааВйзїЁЃ
ФЌШЯЧщПіЯТЃЌЪТЮёДѓаЁЕФЯожЦдк 16 MBЁЃ
ФЌШЯЧщПіЯТЃЌЪТЮёВйзїећЬхВЛдЪаэГЌЙ§ 60 УыЁЃ
ЪТЮёВЛФмдк session ЭтдЫааЁЃ
вЛИі session жЛФмдЫаавЛИіЪТЮёЃЌЖрИі session ПЩвдВЂаадЫааЪТЮёЁЃ
ВЛФмЖд capped collection НјааВйзїЁЃ
ВЛФмЪЙгУ explain ВйзїзіВщбЏЗжЮіЁЃ
14.3 ЪТЮёгы read concern
ЪТЮёжаЕФВйзїЪЙгУЪТЮёМЖБ№ЕФ read concernЁЃЪТЮёФкВПКіТддкМЏКЯКЭЪ§ОнПтМЖБ№ЩшжУЕФШЮКЮ read
concernЁЃЪТЮёжЇГжЩшжУ read concern ЮЊ localЁЂmajority КЭ snapshot
ЦфжажЎвЛЁЃ
ЕБ read concern ЮЊ local ЪБЃЌПЩЖСШЁНкЕуПЩгУЕФзюаТЪ§ОнЃЌЕЋЪ§ОнПЩФмЛиЙіЁЃЖдгкЗжЦЌШКМЏЩЯЕФЪТЮёЃЌlocal
ВЛФмБЃжЄЪ§ОнЪЧДгећИіЗжЦЌЕФЭЌвЛПьееЪгЭМЛёШЁЁЃ
ЕБ read concern ЮЊ majority ЪБЃЌШчЙћдкЬсНЛЪТЮёЪБжИЖЈСЫ write concern
ЮЊ majority МЖБ№ЃЌдђЗЕЛиДѓЖрЪ§ИББОГЩдБвбШЗШЯЕФЪ§ОнЃЈМДЮоЗЈЛиЙіЪ§ОнЃЉЁЃШчЙћЪТЮёЮДжИЖЈ write
concern ЮЊ majority МЖБ№ЃЌдђВЛБЃжЄЖСВйзїПЩвдЖСШЁЖрЪ§ЬсНЛЕФЪ§ОнЁЃЖдгкЗжЦЌШКМЏЩЯЕФЪТЮёЃЌВЛФмБЃжЄЪ§ОнЪЧДгећИіЗжЦЌЕФЭЌвЛПьееЪгЭМжаЛёШЁЁЃ
ЕБ read concern ЮЊ snapshot ЪБЃЌШчЙћдкЬсНЛЪТЮёЪБжИЖЈСЫ write concern
ЮЊ majority МЖБ№ЃЌдђДгДѓЖрЪ§вбЬсНЛЪ§ОнЕФПьеежаЗЕЛиЪ§ОнЁЃШчЙћЪТЮёЮДжИЖЈ write concern
ЮЊ majority МЖБ№ЃЌдђВЛБЃжЄЖСВйзїЪЙгУСЫ majority commited ЕФЪ§ОнЕФПьееЁЃЖдгкЗжЦЌШКМЏЩЯЕФЪТЮёЃЌsnapshot
ПчЗжЦЌЭЌВНЁЃ
14.4 ЪТЮёгы write concern
ЪТЮёЪЙгУЪТЮёМЖБ№ЕФ write concern РДНјаааДВйзїЬсНЛЃЌПЩвдЭЈЙ§ХфжУ w бЁЯюЩшжУНкЕуИіЪ§ЃЌРДОіЖЈЪТЮёаДШыЪЧЗёГЩЙІЃЌФЌШЯЧщПіЯТЮЊ
1ЁЃ
w:0 БэЪОЪТЮёаДШыВЛЙизЂЪЧЗёГЩЙІЃЌФЌШЯЮЊГЩЙІЁЃ
w:1 БэЪОЪТЮёаДШыЕНжїНкЕуОЭПЊЪМЭљПЭЛЇЖЫЗЂЫЭШЗШЯаДШыГЩЙІЁЃ
w:majority БэЪОДѓЖрЪ§НкЕуГЩЙІддђЃЌР§ШчвЛИіИДжЦМЏ 3 ИіНкЕуЃЌ2 ИіНкЕуГЩЙІОЭШЯЮЊБОДЮЪТЮёаДШыГЩЙІЁЃ
w:all БэЪОЫљгаНкЕуЖМаДШыГЩЙІЃЌВХШЯЮЊЪТЮёЬсНЛГЩЙІЁЃ
j:false БэЪОаДВйзїЕНДяФкДцОЭЫуЪТЮёГЩЙІЁЃ
j:true БэЪОаДВйзїжЛгаМЧТМЕНШежОЮФМўВХЫуЪТЮёГЩЙІЁЃ
wtimeout: аДШыГЌЪБЪБМфЃЌЙ§ЦкБэЪОЪТЮёЪЇАмЁЃ
15 MongoDB Change Stream
15.1 БфИќСїЪЙгУГЁОА
MongoDB 3.6 в§ШыСЫ change streamЃЈБфИќСїЃЉЁЃЫќЕФЪЙгУГЁОААќРЈЃК
Ъ§ОнЭЌВНЃКЖрИі MongoDB МЏШКжЎМфЕФдіСПЪ§ОнЭЌВНЁЃ
ЩѓМЦЃКЖд MongoDB ВйзїНјааЩѓМЦЁЂМрПиЁЃ
Ъ§ОнЖЉдФЃКЭтВПГЬађЖЉдФ MongoDB ЕФЪ§ОнБфИќЃЌПЩРыЯпЪ§ОнЭЌВНЁЂМЦЫуЛђЗжЮіЕШЁЃ
15.2 БфИќСїЬиЕу
change stream дЪаэЭтВПГЬађЗУЮЪЪЕЪБЪ§ОнИќИФЃЌЖјВЛЛсдіМг MongoDB ЛљДЁВйзїЕФИДдгадЃЌвВВЛЛсЕМжТ
oplog бгГйЕФЗчЯеЁЃгІгУГЬађПЩвдЪЙгУ change stream РДЖЉдФЕЅИіМЏКЯЁЂЪ§ОнПтЛђећИіМЏШКжаЕФЫљгаЪ§ОнБфИќЁЃШєвЊПЊЦє
change streamЃЌБиаыЪЙгУ WiredTiger ДцДЂв§ЧцЁЃ
change stream ПЩгІгУгкИДжЦМЏКЭЗжЦЌМЏЁЃгІгУгкИДжЦМЏЪБЃЌПЩвддкИДжЦМЏжаШЮвтвЛИіНкЕуЩЯПЊЦєМрЬ§ЃЛгІгУгкЗжЦЌМЏЪБЃЌдђжЛФмдк
mongos ЩЯПЊЦєМрЬ§ЁЃдк mongos ЩЯЗЂЦ№МрЬ§ЃЌЪЧРћгУШЋОжТпМЪБжгЬсЙЉСЫећИіЗжЦЌЩЯБфИќЕФзмЬхХХађЃЌШЗБЃМрЬ§ЪТМўПЩвдАДНгЪеЕНЕФЫГађАВШЋЕиНтЪЭЁЃ
mongos ЛсвЛжБМьВщУПИіЗжЦЌЃЌВщПДУПИіЗжЦЌЪЧЗёДцдкзюаТЕФБфИќЁЃШчЙћЖрИіЗжЦЌЩЯвЛжБКмЩйГіЯжБфИќЃЌдђПЩФмЛсЖд
change stream ЕФЯьгІЪБМфВњЩњИКУцгАЯьЃЌвђЮЊ mongos ШдБиаыМьВщетаЉРфЗжЦЌБЃГжзмЬхгаађЁЃ
15.3 БфИќСїМрЬ§ЪТМўРраЭ
Дг change stream жаФмМрЬ§ЕНЕФБфИќЪТМўАќРЈЃКinsertЁЂupdateЁЂreplaceЁЂdeleteЁЂdropЁЂrenameЁЂdropDatabase
КЭ invalidateЁЃ
15.4 БфИќСїЙЪеЯЛжИД
MongoDB 4.0 жЎКѓЃЌПЩвдЭЈЙ§жИЖЈ startAtOperationTime РДПижЦДгФГИіЬиЖЈЕФЪБМфЕуПЊЦєМрЬ§ЃЌЕЋИУЪБМфЕуБиаыдкЫљбЁдёНкЕуЕФгааЇ
oplog ЪБМфЗЖЮЇФкЁЃchange stream МрЬ§ЗЕЛиЕФзжЖЮжагаИі _id зжЖЮЃЌБэЪОЕФЪЧ resume
tokenЃЌетЪЧЮЈвЛБъжО change stream СїжаЕФЮЛжУЕФзжЖЮЁЃ
ШчЙћ change stream МрЬ§БШжажЙКѓашвЊМЬајМрЬ§ЃЌФЧУДПЩжИЖЈ resumeAfter ЛжИДЖЉдФЁЃжИЖЈ
resumeAfter ЮЊ change stream жаЖЯДІЕФ _id зжЖЮМДПЩЁЃ
ЕБМрЬ§ЕФМЏКЯЗЂЩњ renameЁЂdrop Лђ dropDatabase ЪТМўЃЌОЭЛсЕМжТ invalidate
ЪТМўЃЛЕБМрЬ§ЕФЪ§ОнПтГіЯж dropDatabase ЪТМўЃЌвВЛсЕМжТЮоаЇЪТМўЁЃinvalidate ЪТМўКѓ
change stream ЕФгЮБъЛсБЛЙиБеЃЌетЪБОЭашвЊЪЙгУ resumeAfter бЁЯюРДЛжИД change
stream ЕФМрЬ§ЃЌдк 4.2 АцБОКѓвВПЩвдЭЈЙ§ startAfter бЁЯюДДНЈаТЕФИќИФСїРДЛжИДМрЬ§ЁЃ
15.5 БфИќСїЪЙгУЯожЦ
change stream ЮоЗЈХфжУЕНЯЕЭГПтЛђеп system.xxx БэЩЯЁЃ
change stream вРРЕгк oplogЃЌвђДЫжаЖЯЪБМфВЛПЩГЌЙ§ oplog ЛиЪеЕФзюДѓЪБМфДАЁЃ
16 MongoDB адФмЮЪЬтЖЈЮЛЗНЪН
ПЩвдЮЊ mongod ЪЕР§ЦєгУЪ§ОнПтЗжЮіЁЃЪ§ОнПтЗжЮіЦїМШПЩвддкЪЕР§ЩЯЦєгУЃЌвВПЩвддкЕЅИіЪ§ОнПтВуУцЩЯЦєгУЁЃЫќЪеМЏдкЪЕР§ЩЯжДааЕФ
CRUD ВйзїЁЂгЮБъЁЂУќСюЁЂХфжУЕШЯъЯИаХЯЂЃЌВЂНЋЫќЪеМЏЕФЫљгаЪ§ОнаДЕН system.profile
МЏКЯЁЃетЪЧвЛИі capped collectionЃЌФЌШЯЧщПіЯТЃЌsystem.profile ШнСПДѓаЁЮЊ
4MЁЃПЊЦєЪЕЪБЪ§ОнПтЗжЮіЭљЭљАщЫцзХИБзїгУЃЌЧыНїЩїЪЙгУЁЃ
ЪЙгУ db.currentOp() ВйзїЁЃЫќЗЕЛивЛИіЮФЕЕЃЌЦфжаАќКЌгаЙиЪ§ОнПтЪЕР§е§дкНјааЕФВйзїЕФаХЯЂЁЃ
ЪЙгУ db.serverStatus() УќСюЁЃЫќЗЕЛивЛИіЮФЕЕЃЌЬсЙЉЪ§ОнПтзДЬЌЕФИХЪіЃЌЭЈЙ§ЫќПЩвдЪеМЏгаЙиИУЪЕР§ЕФЭГМЦаХЯЂЁЃ
ЪЙгУ explain РДЦРЙРВщбЏадФмЃЌР§Шч cursor.explain() Лђ db.collection.explain()
ЗНЗЈПЩвдгУРДЗЕЛиЙигкВщбЏжДааЕФаХЯЂЁЃ
НшгУвЛаЉЩЬвЕЙЄОпЃЌБШШч MongoDB Ops ManagerЁЂPercona ЕШЁЃ | 








