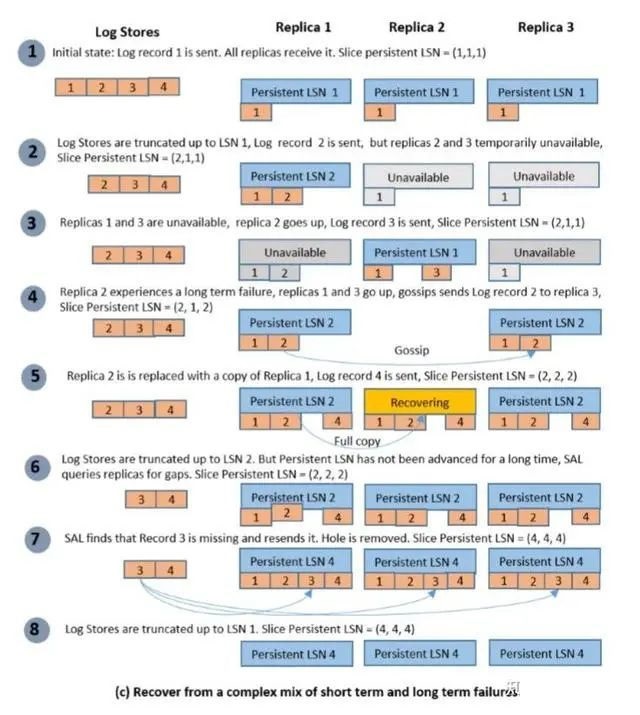
| БрМЭЦМі: |
БОЮФИљОнТлЮФЬсЙЉЕФаХЯЂЖдTaurusЕФЩшМЦНјааМђЕЅНщЩм,ЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгк51CTOВЉПЭЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ЧАбд
ЖрФъвдРДЃЌИїдЦЪ§ОнПтГЇЩЬЛљгкДЋЭГЕФЕЅЬхЪ§ОнПтЮЊПЭЛЇЬсЙЉСЫдЦЩЯЕФЪ§ОнПтЗўЮёЃЌТњзуСЫПЭЛЇвЛЖЈВуДЮЕФашЧѓЃКЗўЮёИпПЩгУЁЂЪ§ОнИпПЩППЁЂЭъЩЦЕФдЫгЊЁЃШЛЖјЃЌДЋЭГЕЅЬхЪ§ОнПтМмЙЙДцдкбЯжиЕФЖЬАхЃЌЮоЗЈТњзуПЭЛЇИќИпВуДЮЕФашЧѓЃЌЫљвдНќФъРДЭЗВПдЦГЇЩЬПЊЪМЬсЙЉЁАдЦдЩњЁБЪ§ОнПтЗўЮёЃЌПЫЗўСЫДЋЭГЕЅЬхЪ§ОнПтЕФвЛаЉЖЬАхЁЃ
дЦдЩњЪ§ОнПтЕФжївЊЬиЕуЪЧЃК
ИќКУЕФЕЏадЃКеМгУПеМфЫцЪ§ОнДѓаЁздЖЏРЉЫѕШнЃЌЩѕжСПЩвдзіЕНМЦЫузЪдДЫцЙЄзїИКдиздЖЏРЉЫѕШнЃЌЭЛЦЦЕЅЛњЦПОБЁЃ
ИќЧПОЂЕФадФмЃКдЦдЩњМмЙЙЯрЖдДЋЭГЕЅЛњЪ§ОнПтЃЌадФмЬьЛЈАхИќИпЁЃ
ИќИпЕФПЩгУадЃКЪ§ОнПтБРРЃЛжИДЕФЪБМфБШДЋЭГЕЅЛњЪ§ОнПтИќЖЬЃЌПЩгУадЕУЕНЬсЩ§ЁЃ
ИќЕЭЕФГЩБОЃКЬэМгЖюЭтЕФМЦЫуНкЕуВЛашвЊдіМгЖюЭтЕФШЋСПЪ§ОнЃЌНкЪЁГЩБОЁЃ
ЫљИЖМДЫљЕУЃКПЭЛЇЫљЛЈЕФЗбгУгыЪЕМЪЯћКФЕФМЦЫузЪдДЁЂДцДЂПеМфЯрЙиЁЃ
ФПЧАЃЌЙњЭтЕФдЦдЩњЪ§ОнПтгаЃКAWS AuroraЁЂЮЂШэSocratesЃЌЖМвбОЩЬвЕЛЏЁЃ
ЙњФкЕФдЦдЩњЪ§ОнПтгаЃКАЂРядЦPOLARDBЁЂЬкбЖдЦCynosDBЁЂЛЊЮЊTaurusЁЃЦфжаPOLARDBЁЂCynosDBЖМвбОЩЬвЕЛЏКмГЄЪБМфЃЌTaurusФПЧАгІИУЪЧЛЙЮДЩЬвЕЛЏЁЃ
ЕЋЪЧзюНќTaurusЗЂБэСЫвЛЦЊPaperЁЖTaurus Database: How to be Fast,
Available, and Frugal in the Cloud ЁЗЃЌЯъЯИНщЩмСЫЫќЕФМмЙЙЬиЕуЁЂЩшМЦРэФюЁЃБОЮФЖдPaperжаЕФФкШнНјаавЛЯТИХРЈЁЃ
БГОА
ЩЯЪіМИИідЦдЩњЪ§ОнПтЖМЪЧВЩгУМЦЫугыДцДЂЗжРыЕФМмЙЙЃЌДцДЂВуПЩвдЫЎЦНРЉеЙжЇГжЩЯАйTBЕФЪ§ОнЃЌМЦЫуВувВПЩвдДЙжБРЉеЙвдМАЫЎЦНРЉеЙЃЈЬэМгжЛЖСЪЕР§ЃЉЁЃЕЋЪЧШчКЮзіЕНМЦДцЗжРыЃЌИїздЗжЗЈЖМгаВЛЭЌжЎДІЁЃ
POLARDBЭЈЙ§НЋInnodbЕФlogКЭpageДцЗХЕНРрPOSIXНгПкЕФЗжВМЪНЮФМўЯЕЭГЃЈPolarFsЃЉРДЪЕЯжМЦДцЗжРыЁЃетжжзіЗЈПДЫЦКмУРКУЁЂЖдInnodbЕФЧжШыЗЧГЃаЁЃЌЕЋЪЧШДгавЛаЉбЯжиЕФЮЪЬтЃЌTaurusТлЮФжагаЬсМАЁЃОпЬхРДЫЕЃЌДѓСПЫЂдрЕФЪБКђЃЌГжОУЛЏpageЕФЭјТчСїСПЖдгкМЦЫуВуЁЂДцДЂВуЖМЪЧвЛИіКмДѓЕФЬєеНЃЌвђЮЊpageСїСПЪЧЕЅДПlogСїСПЕФМИБЖЕНМИЪЎБЖВЛЕШЃЌОпЬхШЁОігкгУЛЇЕФЙЄзїИКдиЁЃСэЭтЃЌpageЫЂдрЛсЧРеМlogЕФГжОУЛЏашвЊЕФзЪдДЃЈЭјТчДјПэЁЂIOДјПэЃЉЃЌдіДѓlogГжОУЛЏЕФбгЪБЃЌМЬЖјдіДѓЪТЮёЬсНЛЕФбгЪБЁЃСэЭтЃЌгЩгкPolarFsЕФЛљгкraftЃЈзМШЗЫЕЪЧParallelRaftЃЉЕФЪ§ОнИДжЦЗНЪНЃЌЕМжТЪТЮёЬсНЛЕФТЗОЖЩЯжСЩйашвЊСНЬјЭјТчДЋЪфЃЌетИіМмЙЙЕМжТЦфашвЊдкМЦЫуНкЕуЁЂДцДЂНкЕуЖМашвЊв§ШыRDMAРДМѕЩйЭјТчДјРДЕФrtЁЃ
СэЭтЃЌЮвОѕЕУPOLARDBдкЭЈгУЗжВМЪНЮФМўЯЕЭГPolarFsЩЯЬсЙЉдЦдЩњЪ§ОнПтЗўЮёЃЌЖрЖрЩйЩйдкадФмЩЯЁЂЙІФмЪЕЯжЩЯБЛPolarFsЯожЦЃЌГ§ЗЧPolarFsеыЖдdbГЁОАзіЖЈжЦЃЌБШШчашвЊжЇГжБЃДцЖрИіАцБОЕФpageЁЃ
ЦфЪЕЃЌМЦДцЗжРыЕФзюгХзіЗЈЪЧВЩгУЁАlog is databaseЁБЕФРэФюЃЌжЛашвЊАбlogаДЕНДцДЂВуЃЌгЩДцДЂВуИКд№жиЗХlogЁЂЛиаДpageВЂОЁСПМѕЩйаДЗХДѓЁЃНЋЫЂдретИіВйзїДгМЦЫуВуЬоГ§жЎКѓЃЌПЩвдНЕЕЭМЦЫуНкЕуЕФЭјТчПЊЯњЁЃAuroraЪзЯШВЩгУетжжзіЗЈЃЌКѓајЕФSocratesЁЂCynosDBЁЂTaurusвВОљВЩгУетИізіЗЈЁЃ
AuroraНЋdbЕФЪ§ОнЃЈвВМДЪЧЫљгаpageЃЉЗжГЩШєИЩИі10GBДѓаЁЕФshardЃЌЯргІЕФlogвВЫцdataвЛЦ№БЃДцдкshardжаЁЃУПИіshardга6ИіИББОЃЌВЩгУN=6ЃЌW=4ЃЌR=3ЕФВпТдЃЌЪТЮёЬсНЛЪБашвЊЕШЕНlogдкжСЩй4ИіИББОГжОУЛЏжЎКѓВХФмЭъГЩЬсНЛЁЃAuroraЕФlogГжОУЛЏЁЂpageЖСШЁЖМжЛашвЊвЛЬјЭјТчДЋЪфЁЃ
SocratesвВЪЧВЩгУЁАlog is databaseЁБЕФРэФюЃЌЕЋЪЧЫќЕЅЖРСЫвЛИіlogВугУгкПьЫйГжОУЛЏlogЃЈОпЬхЪЕЯжВЛЯъЃЉЃЌБмУтЪмЕНжиЗХlogЁЂЛиаДpageЕФгАЯьЁЃСэЭтЃЌpage
svrВуДгlogВуРШЁlogНјаажиЗХЁЂЛиаДpageЃЌВЂЯђМЦЫуНкЕуЬсЙЉЖСШЁpageЕФЗўЮёЁЃЕЋЪЧpage
svrВужЛНЋВПЗжpageЛКДцдкБОЕиЃЌШЋСПЕФpageдкЖюЭтЕФРфБИВуЁЃЫљвдSocratesЕФЖСЧыЧѓгаПЩФмдкpage
svrВуБОЕиЮоЗЈУќжаЃЌНјЖјДгРфБИВуЛёШЁpageЁЃ
CynosDBвВЪЧВЩгУЁАlog is databaseЁБЕФРэФюЃЌДгЙЋПЊзЪСЯРДПДЃЌДцДЂВуЮЊМЦЫуНкЕуЬсЙЉСЫLog
IOНгПкгыPage IOНгПкЃЌЧАепИКд№ГжОУЛЏlogЃЌКѓепИКд№pageЕФЖСШЁЁЃ
TaurusвВЪЧВЩгУЁАlog is databaseЁБЕФРэФюЃЌДцДЂВуЗжЮЊLog StoreЁЂPage
StoreСНИіФЃПщЃЌЧАепИКд№ГжОУЛЏlogЃЌКѓепИКд№pageЕФЖСШЁЁЃlogГжОУЛЏЁЂpageЖСШЁЖМжЛашвЊвЛЬјЭјТчДЋЪфЁЃ
БОЮФИљОнТлЮФЬсЙЉЕФаХЯЂЖдTaurusЕФЩшМЦНјааМђЕЅНщЩмЁЃ
змЬхМмЙЙ
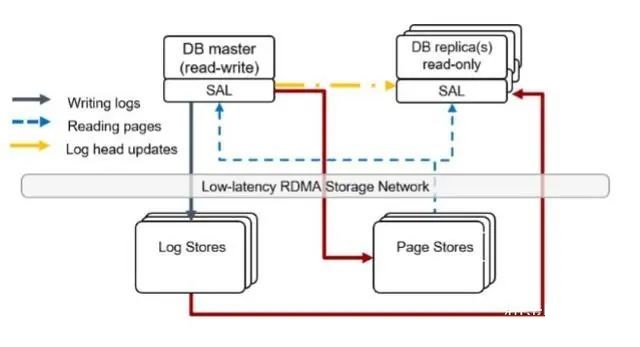
TaurusАќКЌЫФИіжївЊЕФФЃПщЃКSQLЧАЖЫЃЈаоИФЙ§ЕФMySQLЃЉЁЂЧЖШыЕНSQLЧАЖЫЕФSAL libraryЃЈ
Storage Abstraction LayerЃЉЁЂLog StoresКЭPage StoresЁЃЦфжаSQLЧАЖЫКЭSALзщГЩСЫМЦЫуВуЃЌLog
StoresКЭPage StoresзщГЩСЫДцДЂВуЁЃШчЯТЭМЫљЪОЃК
SQLЧАЖЫ
SQLЧАЖЫЪЧЛљгкMySQL 8.0ЕФаоИФАцЃЌАќКЌвЛИіЬсЙЉЖСаДЗўЮёЕФMasterЪЕР§ЃЌвдМАШєИЩИіЬсЙЉжЛЖСЗўЮёЕФROЪЕР§ЁЃMasterЪЕР§ЬсНЛЪТЮёЪБЛсВњЩњredo
logЃЌетаЉlogФкШнУшЪіСЫЪТЮёЖдpageЫљзіЕФИФЖЏЁЃMasterЛсНЋlogЗЂЫЭИјLog StoreЁЃСэЭтЃЌMasterвВЛсБЛАбlogЗжЗЂИјPage
StoresЁЃЦфжаЃЌаДlogЁЂЖСШЁpageЕФТпМЖМЗтзАдкСЫSALжаЃЌЮЊMySQLЦСБЮСЫДцДЂВуЕФИДдгадЁЃ
Log Store
Log StoreИКд№ГжОУЛЏlogЃЌвЛЕЉЪТЮёЕФЫљгаlogГжОУЛЏжЎКѓЃЌФЧУДSQLЧАЖЫМДПЩЭЈжЊclientЪТЮёвбОЬсНЛЭъГЩЁЃСэЭтЃЌLog
StoreИКд№ЮЊROЪЕР§ЬсЙЉlogФкШнЃЌКѓепашвЊжиЗХlogРДИќаТздМКbuffer poolжаЕФpageЁЃMasterЪЕР§жмЦкадЕиИцжЊROЪЕР§зюаТlogЕФЮЛжУЃЌвдБуROЪЕР§ПЩвдЖСШЁЕНзюаТЕФlogЁЃ
Log StoreЬсЙЉСЫвЛИіЙиМќЕФГщЯѓЖдЯѓЃЌPLogЃЌУПИіPLogЖМЪЧДѓаЁгаЯоЃЈзюДѓ64MBЃЉЁЂappend-onlyЕФЖдЯѓЃЌВЂЧПЭЌВНИДжЦЕНЖрИіLog
StoreЃЈНјГЬ/ЛњЦїЃЉЩЯЁЃФГИіdbЪЕР§ЕФlogБЃДцдкЖрИіЕФPLogжаЃЌетаЉPLogзщГЩЕФгаађСаБэзїЮЊдЊаХЯЂБЃДцдквЛИіЕЅЖРЕФmetadata
PLogжаЃЌетИіЬиЪтPLogдкdbГѕЪМЛЏЕФЪБКђОЭЛсДДНЈЃЌЫќЕФЖСаДФЃЪНгыЦеЭЈPLogвЛжТЁЃ
Log StoreЛњЦївдМЏШКЕФЗНЪНзщжЏЃЌЕфаЭЕФВПЪ№АќКЌМИАйИіLog Store ЛњЦїЁЃЕБашвЊДДНЈPLogЪБЃЌМЏШКЙмПиЦНЬЈЛсбЁдё3ИіLog
StoreЛњЦїЃЈЛђГЦЮЊНкЕуЃЉРДИКд№PLogЕФ3ИіИББОЁЃМЏШКЙмПиЦНЬЈЛсИјPLogЗжХф24зжНкЕФIDЮЈвЛБъЪЖИУPLogЁЃЕБPLogЕФДѓаЁДяЕН64MBжЎКѓЃЌЛсДДНЈвЛИіаТЕФPLogЃЌбЁдёаТPLogЕФ3ИіLog
StoreНкЕуЪБЛсПМТЧМЏШКжаLog StoreНкЕуЕФПеЯаПеМфвдМАЙЄзїИКдиЁЃ
ЙцЖЈPLogЕФДѓаЁЩЯЯоЮЊ64MBЪЧЮЊСЫФмНЋlogаДШыИКдиОљКтДђЩЂЕНВЛЭЌЕФLog StoreЩЯЃЌЭЌЪБгжБмУтЙ§ЖШЫщЦЌЛЏЁЃвђЮЊШчЙћPLogЬЋДѓЛсЕМжТLog
StoreжЎМфИКдиВЛОљКтЃЌПЩФмДцдкФГИіdbаДШыСїСПКмДѓЃЌЖЬЪБМфФкМЏжадкФГ3ИіLog StoreжаЁЃЗДЙ§РДЃЌШчЙћPLogЬЋаЁЃЌЫфШЛПЩвдНЋаДШыИКдидкМЏШКжаПьЫйЙіЖЏЦ№РДЃЌЕЋЪЧЙ§ЖШЫщЦЌЛЏЛсЕМжТPLogЕФЦЕЗБДДНЈЁЂЩОГ§ЃЌЕМжТдЊаХЯЂЕФХђеЭЃЌСэЭтЃЌЛсЖдlogаДШыЁЂlogЖСШЁдьГЩвЛЖЈЕФадФмЖЖЖЏЁЃ
PLogЕФreplicationВЩгУN=3ЃЌW=3ЃЌ R=1ЕФleaderless replicationВпТдЁЃЕБSALашвЊНЋвЛХњlogаДШыPLogЪБЃЌжЛгаШЋВП3ИіPLogИББОЖМГЩЙІаДШыжЎКѓЃЌЖдЫќЕФаДШыВйзїВХЫуГЩЙІЁЃШчЙћЦфжавЛИіLog
StoreЮоЗЈЯьгІЃЌФЧУДЖдИУPLogЕФаДШыВйзїОЭШЯЮЊЪЧЪЇАмЕФЃЌВЂЧвВЛЛсдйгааДШыЧыЧѓЗЂЫЭИјИУPLogЃЌШЁЖјДњжЎЕФЪЧгЩСэЭт3ИіLog
StoreзщГЩЕФаТPLogЁЃетИізіЗЈПЩвдБЃжЄlogаДШыБиЖЈЪЧПЩвдГЩЙІЭъГЩЕФЃЈТлЮФжаШЯЮЊаДlogЕФПЩгУадЮЊ100%ЃЉЃЌжЛвЊМЏШКжажСЩйЛЙга3ИіНЁПЕЕФLog
StoreЁЃДгPLogЖСШЁlogЕФВйзїПЩгУадвВЗЧГЃИпЃЌжЛвЊга1ИіPLogЕФИББОДцдкЃЌЖСШЁlogЕФВйзїМДПЩГЩЙІЁЃ
Page Store
Page StoreИКд№ЮЊSQLЧАЖЫЬсЙЉpageЖСШЁЗўЮёЃЌУПИіPage StoreДІРэЪєгкВЛЭЌdbЕФШєИЩИіsliceЃЈTaurusНЋdbЕФЫљгаpageЛЎЗжЮЊШєИЩИі10GBДѓаЁЕФЗжЦЌЃЌГЦЮЊsliceЃЌУПИіsliceОпгаЮЈвЛЕФidЃЉЃЌЭЌЪБНгЪеетаЉsliceЯрЙиЕФlogВЂГжОУЛЏЁЃPage
StoreОпгаЙЙдьSQLЧАЖЫЫљашвЊЕФЁЂШЮвтАцБОЕФpageЕФФмСІЁЃ
Page StoreЯђSALЬсЙЉСЫжївЊЕФ4ИіAPIЃК
(1) WriteLogsЃКгУгкДЋЪфвЛХњlogЕНPage Store
(2) ReadPageЃКгУгкЖСШЁжИЖЈАцБОЕФpageЃЌАцБОгЩpage IDвдМАLSNЙВЭЌБъЪЖЁЃ
(3) SetRecycleLSNЃКгУгкЩшЖЈвЛИіLSNЃЌаЁгкИУLSNЕФОЩАцБОвГУцЖМПЩАВШЋЛиЪе ЁЃИУLSNЪЧЫљгаSQLЧАЖЫПЩФмЛсЧыЧѓЕФЁЂзюОЩЕФpageЕФLSNЁЃ
(4) GetPersistentLSNЃКЗЕЛиИУPage StoreГжОУЛЏЕФЁЂзюДѓЕФЁЂУЛгаПеЖДЕФLSNЁЃ
ЕБSQLЧАЖЫашвЊЖСШЁФГИіpageЪБЃЌSALЛсжИЖЈslice IDЁЂpage IDвдМАpageЕФАцБОРДЕїгУReadPageНгПкЁЃPage
StoreБиаыгаФмСІЬсЙЉpageЕФОЩАцБОЪ§ОнЃЌвђЮЊROгыMasterжЎМфЕФЪгЭМЛсгавЛЖЈЕФlagЃЌКѓЮФЛсНВЕНЁЃ
гЩгкБЃСєОЩАцБОЕФвГУцашвЊеМгУзЪдДЃЈгВХЬПеМфЁЂФкДцЃЉЃЌЫљвдSALЛсжмЦкадЕФЕїгУSetRecycleLSNРДИцжЊPage
StoreПЩвдЛиЪеЕФLSNЮЛЕуЁЃ
ЧАЮФгаНВЕНSALЛсНЋвЛХњlogаДШыЕНPLogГЩЙІжЎКѓЃЌЪТЮёМДПЩЬсНЛЁЃЭЌЪБЃЌЕБаДШыPlogГЩЙІжЎКѓЃЌSALЛЙЛсНЋИУХњlogАДееЫљЪєsliceНјааЧаИюЛЎЗжЃЌcopyЕНЯргІЕФslice
write bufferжаЁЃЕБФГИіsliceЕФ write bufferТњСЫЃЌЛђепвЛЖЈГЌЪБжЎКѓЃЌSALЛсЕїгУWriteLogsНгПкНЋИУbufferаДШыЕНИУsliceЫљЪєЕФPage
StoresжаЁЃ
SliceЕФreplicationВЩгУN=3ЃЌW=1ЃЌ R=3ЕФleaderless replicationВпТдЃЌжЛвЊSALЕШЕНСЫЦфжа1ИіsliceИББОЕФЯьгІЃЌФЧУДЖдгІЕФwrite
bufferМДПЩЪЭЗХВЂжигУЁЃФГИіsliceИББОЪеЕНЕФзюДѓЕФLSNНазіflush LSNЁЃгЩгкsliceИББОПЩФмЛсШБЩйФГаЉbufferаЮГЩПеЖДЃЌЫљвдУПИіbufferЖМгаslice
IDКЭађСаКХБъЪЖЃЌPage StoreПЩвдИљОнетађСаКХРДЗЂЯжвХТЉЕФbufferЃЌвВМДЪЧХаЖЯЪЧЗёгаПеЖДЁЃФГИіsliceИББОГжОУЛЏЕФЁЂзюДѓЕФЁЂУЛгаПеЖДЕФLSNНазіpersistent
LSNЁЃSliceЕФИББОжЎМфЛсЭЈЙ§gossipавщВЙЦыздЩэЕФПеЖДЁЃ
ЖдгкpageЖСЧыЧѓЃЌTaurusвВРрЫЦAuroraзіСЫгХЛЏЃЌЮоашЖСШЁ3ИіsliceИББОЃЌе§ГЃЧщПіЯТжЛашЖСШЁ1ИіsliceИББОМДПЩЛёШЁашвЊЕФpageФкШнЃЌвђЮЊSALЛсЮЌЛЄУПИіsliceИББОЕФpersistent
LSNаХЯЂЃЌНјЖјжЊЕРФФИіsliceИББОПЩвдТњзуpageЖСЧыЧѓЁЃSALЪЧЭЈЙ§ЯдЪОЕїгУGetPersistentLSNНгПкВщбЏИУаХЯЂЃЌЛђепЭЈЙ§WriteLogsКЭReadPageНгПкЩгДјИУаХЯЂЁЃ
ЕЋЪЧЃЌБЯОЙSALЛсЮЌЛЄУПИіsliceИББОЕФpersistent LSNВЛЪЧЪЕЪБЕФЃЌЫљвдгааЉЧщПіSALжЊЕРЫљга3ИіИББОЖМВЛТњзуpageЖСЧыЧѓЃЌвВЛсЗЂЫЭReadPageЧыЧѓИјЦфжа1ИіИББОЁЃФЧPage
StoreШчКЮХаЖЯздЩэФмЗёТњзуИУЧыЧѓФиЃПPage StoreБОЕизюаТАцБОЕФpageвВПЩФмЛсБШSALЦкЭћЕФвЊОЩЃЌдѕУДЪЖБ№етжжЧщПіЃПTaurusЮЌЛЄСЫЗЂЫЭЕНУПИіsliceзюКѓвЛИіlogЕФsent
LSNЃЌReadPageЧыЧѓЛсДјЩЯsent LSNЃЌШчЙћPage StoreУЛгаНгЪеЕНаЁгкЕШгкsent
LSNЕФЫљгаlogЃЌФЧУДЫќБуЮоЗЈТњзуИУЧыЧѓЃЌЗЕЛиЬиЖЈДэЮѓТыЃЌSALНгзХГЂЪдЯТвЛИіPage StoreЃЌжБЕНевЕНвЛИіТњзуЬѕМўЕФPage
StoreЁЃ
е§ГЃРДЫЕЃЌSALЛсзюЖрЗУЮЪ3ДЮPage StoreОЭФмЛёШЁЕНашвЊЕФpageЃЌЕЋЪЧШчЙћНсКЯЙЪеЯЛжИДЕФГЁОАЃЌПЩФмЛсашвЊЧыЧѓИќЖрДЮЁЃ
СэЭтЃЌЩОГ§Log StoreжаЮогУЕФPLogвВвРРЕгкsliceЕФpersistent LSNЁЃSALЛсзлКЯУПИіsliceЕФУПИіИББОЕФpersistent
LSNЃЌвдФЧаЉЛЙгаlogЮДДяГЩ3ИББОЕФslicesжаЕФзюаЁpersistent LSNзїЮЊdb persistent
LSNЁЃЭЌЪБЃЌSALвВжЊЕРУПИіPLogЕФLSNЗЖЮЇЃЌЫљвдНјЖјПЩвджЊЕРФФаЉPLogЕФLSNаЁгкdb persistent
LSNЃЌПЩвдАВШЋЩОГ§етРрPLogЁЃ
СэЭтЃЌSALЛсжмЦкадЕФНЋdb persistent LSNМЧТМЦ№РДЃЈгІИУЪЧМЧТМЕНmetadata
PLogжаЃЉгУгкdbЕФЙЪеЯЛжИДгУЭОЁЃКѓЮФЛсНВЕНЁЃ
SAL
SALЃЈ Storage Abstraction LayerЃЉЪЧвЛИіСДНгЕНSQLЧАЖЫЕФlibraryЃЌНЋдЖГЬДцДЂЁЂЪ§ОнЗжЦЌЁЂЙЪеЯЛжИДЁЂжїДгИДжЦЕФИДдгадДгSQLЧАЖЫИєРыПЊРДЁЃ
ЧАУцЬсЕНЙ§ЃЌаДlogЁЂЖСШЁpageЕФТпМЖМЗтзАдкСЫSALжаЁЃГ§ДЫжЎЭтЃЌSALЛЙИКд№ДДНЈЁЂЙмРэЁЂЯњЛйPage
StoresжаЕФslicesЃЌИКд№АДеевЛЖЈЙцдђгГЩфpagesЕНslicesЁЃЕБФГИіdbИеДДНЈВЂГѕЪМЛЏЛђепНјааРЉеЙЪБЃЌSALЛсбЁдё3ИіPage
StoresВЂдкЩЯУцДДНЈsliceЁЃ
SALСэвЛИіживЊЕФЙІФмЪЧЃЌДІРэSQLЧАЖЫЕФЙЪеЯЛжИДЁЂажњPage StoreЕФЙЪеЯЛжИДЃЌКѓЮФЛсНВЕНЁЃ
етаЉФЃПщжЎМфЕФНЛЛЅСїГЬЃЈвдаДlogЮЊР§ЃЉШчЯТЫљЪОЃК
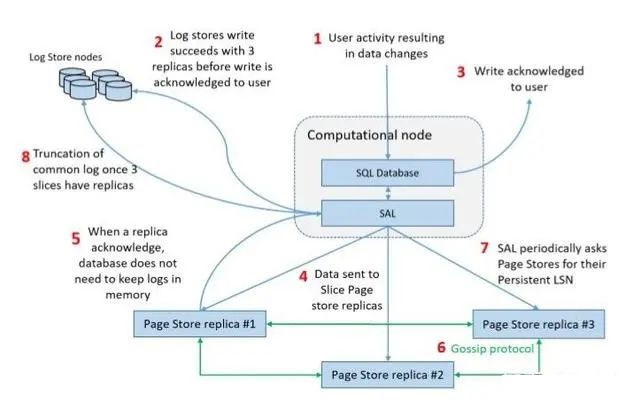
ЙЪеЯЛжИД
Log StoresКЭPage StoresЕФНкЕуПЩгУадгЩвЛИіRecoveryЗўЮёМрПиЃЌШчЙћМьВтЕНФГИіStoreНкЕуЙЪеЯЃЌФЧУДетИіЙЪеЯЪзЯШЛсБЛШЯЮЊЪЧЖЬднЙЪеЯЃЌВЂЧвЛЙЛсГжајМрПиИУStoreНкЕуЁЃШчЙћИУНкЕуГЄЪБМфЖМВЛПЩгУЃЈ15minЃЉЃЌФЧУДЛсБЛШЯЮЊЪЧГЄЦкЙЪеЯЁЃTaurusШЯЮЊ15minетИіуажЕвбОзуЙЛаЁЃЌвђЮЊ15minФкЫфШЛЪ§ОнжЛга2ИіИББОЃЌЕЋЪЧвВВЛЛсЦЦЛЕЪ§ОнЕФГжОУадБЃжЄЁЃ
Log StoreЛжИД
Log StoreЕФЙЪеЯКмШнвзДІРэВЂЛжИДЁЃШчЧАЫљЪіЃЌжЛвЊФГИіLog StoreВЛПЩгУЃЌИУLog StoreЩЯЕФPLogЖМЛсЭЃжЙНгЪеаДШыЧыЧѓБфГЩread-onlyЁЃЫљвдЃЌШчЙћжЛЪЧЖЬднЙЪеЯЃЌВЛашвЊШЮКЮRecoveryСїГЬЃЌвђЮЊЫљгаЪ§ОнШдШЛЪЧ3ИББОЁЃШчЙћЪЧЩ§МЖЮЊГЄЦкЙЪеЯЃЌФЧУДЙЪеЯЕФLog
StoreНкЕуЛсБЛДгМЏШКЬоГ§ЃЌВЂЧвЦфЩЯЕФPLogИББОЛсдкМЏШКжаЕФЦфЫќНкЕужажиНЈЃЌДгЦфЫќ2ИіПЩгУИББОжЎвЛИДжЦШЋСПЪ§ОнРДНЈСЂаТЕФИББОЁЃ
вЩЮЪЃКPLogБЛШЯЮЊБфГЩread-onlyжЎКѓЃЌШчКЮfencingвтЭтЕФаДШыЧыЧѓЃПRecoveryЗўЮёШчКЮгыSALвЛЦ№СЊЖЏЃП
Page StoreЛжИД
Page StoreЕФЙЪеЯЛжИДБШНЯИДдгЃЌТлЮФжаНВСЫPage StoreЙЪеЯЛжИДЕФЫФжжГЁОАЁЃ
ГЁОА1
ФГИіPage StoreНкЕуДгЖЬднЙЪеЯЛжИДЩЯЯпКѓЃЌЫќЛсПЊЪМдЫааgossipавщЃЌДгИУДгЫќИКд№ЕФsliceЕФЦфЫќИББОжаЛёШЁШБЩйЕФШежОЃЌШчЯТЭМЫљЪОЃК
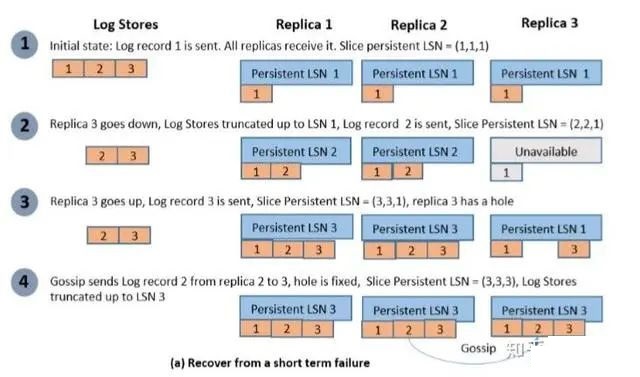
ГЁОА2
ЕБPage StoreНкЕуЗЂЩњГЄЦкЙЪеЯЃЌМЏШКЙмПиЦНЬЈЛсНЋЙЪеЯЕФНкЕуЬоГ§ЃЌВЂжиаТНЋЦфЩЯЕФsliceИББОЗжВМЕНМЏШКЪЃгрЕФPage
StoreНкЕужаНјаажиНЈЁЃФГИіДІгкжиНЈзДЬЌЕФИББОИеПЊЪМЕФЪБКђЪЧУЛгаШЮКЮЪ§ОнЕФЃЌЫќПЩвдСЂТэНгЪеWriteLogsЧыЧѓЃЌЕЋЪЧгЩгкЫќЛЙУЛгаШЮКЮpageФкШнЃЌвВУЛгаЙ§ШЅвЛЖЮЪБМфЕФlogФкШнЃЌЫљгаЫќЛЙЮоЗЈЬсЙЉЖСЧыЧѓЗўЮёЁЃНгзХЃЌЫќЛсЧыЧѓЦфЫќsliceИББОжаЕФЦфжавЛИіЃЌЛёШЁЫљгаpageЕФзюаТАцБОЁЃвЛЕЉНгЪеЕНЫљгаЕФpageжЎКѓЃЌжиНЈКѓЕФsliceИББОМДПЩЬсЙЉЖСЗўЮёЁЃ
вЩЮЪЃКФЧаТЕФsliceИББОжиНЈЭъБЯжЎКѓЃЌШчЙћгаROЪЕР§ЧыЧѓОЩАцБОЕФpageЃЌИУИББОРэТлЩЯЛсЮоЗЈТњзуетжжЧыЧѓЃЌвђЮЊаТжиНЈЕФsliceИББОВЛАќКЌОЩАцБОЕФpageФкШнЁЃЫљвдЃЌTaurusжиНЈsliceИББОЪБЃЌгІИУЪЧгУе§ГЃsliceИББОЕФећИіПьееРДжиНЈаТИББОЃП
ГЁОА3
ИУГЁОАЪЧЖЬднЙЪеЯКЭГЄЦкЙЪеЯНсКЯЕФГЁОАЁЃ
ИУГЁОАЯТЃЌСНИіИББОдтгіЖЬднЙЪеЯУЛгаЪеЕНФГИіlogЃЌЮЈвЛЪеЕНlogЕФИББОгжвђЮЊГЄЦкЙЪеЯБЛжиНЈЃЌЕМжТУЛгаШЮКЮИББОАќКЌЧАЪіЕФlogЁЃетжжЧщПіШчКЮЛжИДФиЃПД№АИЪЧSALЗЂЯжФГИіsliceИББОЕФpersistent
LSNЗЂЩњЛиЭЫжЎКѓЃЌЛсДгLog StoreЖСШЁlogВЂжиаТЗЂЫЭИјЯргІЕФPage StoresЁЃЦфжаЃЌДгLog
StoreЖСШЁlogЕФЦ№ЪМLSNЮЛЕуЪЧsliceШ§ИББОжазюаЁЕФpersistent LSNЁЃШчЯТЭМЫљЪОЃК
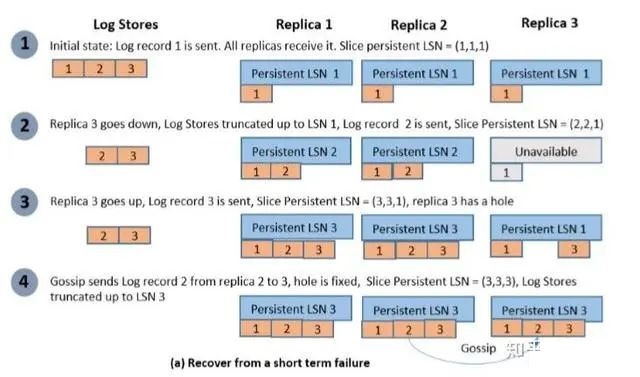
ЕЋЪЧЃЌгЩSLAШЅЬНВтФГИіИББОpersistent LSNЛиЭЫетжжзіЗЈВЂВЛФмГфЗжЕФБЃжЄЪ§ОнВЛЖЊЃЌБЯОЙSLAБОЩэвВЛсжиЦєЖЊЪЇжЎЧАЮЌЛЄЕФИїsliceИББОЕФpersistent
LSNаХЯЂ ЁЃСэЭтЃЌвВДцдкЯТЮФЕФГЁОА4ЃЌЭЈЙ§етжжзіЗЈЪЧЮоЗЈБЃжЄЪ§ОнВЛЖЊЕФЁЃ
ГЁОА4
ИУГЁОАЪЧЖЬднЙЪеЯКЭГЄЦкЙЪеЯНсКЯЕФГЁОАЃЌЕЋЪЧИќИДдгвЛаЉЁЃ
ЕБвЛЯЕСаЙЪеЯЗЂЩњжЎКѓЃЌгЩгкШ§ИіИББОФкЖМДцдкПеЖДЃЌЕМжТФГsliceЕФpersistent LSNвЛжБЮоЗЈЭЦНјЃЌЖјЧввВУЛгаЗЂЩњsliceИББОЕФpersistent
LSNЛиЭЫЕФЧщПіЁЃетжжЧщПіШчКЮЛжИДФиЃПД№АИЪЧSALЛсжмЦкадЕФЛёШЁsliceЕФpersistent LSNКЭflush
LSNЃЌШчЙћЗЂЯжpersistent LSNаЁгкflush LSNЖјЧвВЛЛсЭЦНјЃЌФЧУДSALЛсВщбЏУПИіИББОЕФПеЖДЕФLSNЗЖЮЇЁЃШчЙћSALЗЂЯжФГаЉlogдкЫљга3ИіИББОжаЖМВЛДцдкЃЌФЧУДЫќЛсДгLog
StoreЖСШЁШБЪЇЕФlogВЂжиаТЗЂЫЭИјЯргІЕФPage StoresЁЃШчЯТЭМЫљЪОЃК
ДгPage StoreЯрЙиЕФЛжИДТпМПЩвдПДЕНSALЕФТпМгаЕуЙ§гкИДдгЃЌИљвђЪЧвђЮЊSALЯђPage
StoreаДШыШежОЪБЃЌВЩгУСЫЗжЗЂИДжЦN=3ЃЌW=1ЕФleaderless replicationЪжЖЮЃЌЕМжТФГаЉsliceИББОФкВњЩњПеЖДЃЌЛђепpersistent
LSNдкжиНЈжЎКѓЗЂЩњЛиЭЫЁЃЛђаэВЩгУleader-follower replicationЪжЖЮЛсИќКЯЪЪвЛаЉЃЌетбљПЩвдДѓДѓНЕЕЭSALВуЕФИДдгЖШЃЌЫфШЛЖрвЛЬјЭјТчrtЃЌЕЋЪЧвђЮЊаДШыlogЕНPage
StoreЕФВйзїВЛдкЪТЮёЬсНЛЕФТЗОЖЩЯЃЌrtИпвЛЕуЮЪЬтВЛДѓЃЌжЛвЊЭЬЭТСПФмЙЛЦЅХфredo logВњЩњЕФЫйЖШМДПЩЁЃ
МЦЫуВуЛжИД
МЦЫуВуЛжИДЩцМА2ИіжївЊЕФВНжшЃК1ЃЉSALЛжИД КЭ 2ЃЉSQLЧАЖЫЛжИДЁЃ
ЪзЯШЪЧSALЛжИДЃЌетИіЛжИДЙ§ГЬЕФФПБъЪЧШЗБЃdbЕФslicesЖМКЌгаМЦЫуВуБРРЃжЎЧАвбОаДШыЕНLog
StoreЕФЫљгаlogЁЃSALЛжИДЕФТпМвВКмМђЕЅЃЌДгЧАЮФЬсЕНЕФdb persistent LSNПЊЪМДгLog
StoreЖСШЁlogЃЌВЂАбsliceШБЪЇЕФlogжиаТаДШыЕНЯргІЕФPage StoresЁЃ
SALЛжИДжЎКѓЃЌSQLЧАЖЫМДПЩНгЪеаТЕФЧыЧѓЁЃгыДЫЭЌЪБЃЌSQLЧАЖЫЛсЛиЙіЕєЮДЬсНЛЛюдОЪТЮёЕФИФЖЏЁЃ
ЮвШЯЮЊSALЛжИДСїГЬжаЛЙШБЩйвЛВНЃЌвВЪЧзюПЊЪМвЊжДааЕФСїГЬЃКевЕНЩЯДЮзюКѓЪЙгУЕФPLogЕФгааЇЕФНсЪјLSNЃЌЕЋЪЧТлЮФжаЮДЬсМАетвЛЕуЁЃвђЮЊИУPLogЕФФЉЮВПЩФмАќКЌДѓСПЮДДяГЩ3ИББОЕФlogЃЌSALЛжИДЕФЪБКђЃЌвЊевЕНPLogЕФ3ИББОжазюаЁЕФНсЪјLSNЃЌзїЮЊИУPLOGЕФНсЪјLSNЃЌВЂЧвЧхПеЖргрЕФlogЃЌЛђепНЋИУPlogЩшЮЊread-onlyаТНЈвЛИіPlogгУгкКѓајЕФlogаДШыЁЃ
жЛЖСЪЕР§
TaurusЕФжЛЖСЪЕР§МмЙЙШчЯТЭМЫљЪОЃК
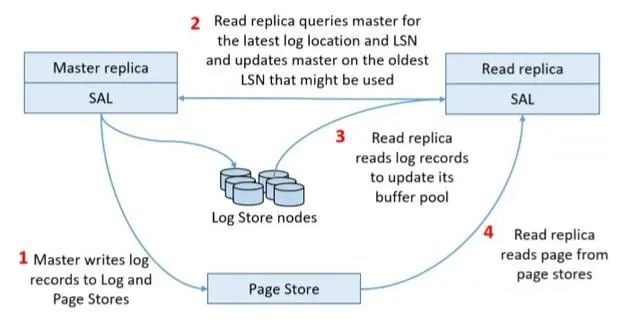
ЕБMasterНЋlogаДШыЕНLog StoreжЎКѓЃЌROЪЕР§ЛсДгMasterЪеЕНЯћЯЂЃЌЯћЯЂАќКЌlogЕФЮЛжУЃЈЭЦВтЪЧPLog
IDЃЉЁЂslicesСаБэЕФБфЖЏЁЂsliceЕФpersistent LSNЁЃНгзХЃЌROЪЕР§ДгLog StoresжаЖСШЁlogгУгкИќаТbuffer
poolжаЕФpageЁЃзюКѓЃЌШчЙћROЪЕР§ашвЊЖСШЁpageЃЌФЧУДЫќвВЛсДгPage StoreжаЛёШЁжИЖЈАцБОЕФpageЁЃ
гЩгкPLogжаФЉЮВЕФlogПЩФмЪЧЛЙЮДБЛMasterШЗШЯГжОУЛЏГЩЙІЕФlogЃЌЫљвдЃЌашвЊБмУтROЖСШЁЕНВЂжиЗХетаЉlogЃЌЫљвдЮвЭЦВтЩЯЪіЯћЯЂжаЕФLSNЪЧгУгкИУФПЕФЃЌИцжЊROзюЖржЛФмЙЛжиЗХЕНИУLSNЮЛЕуЕФlogЃЌКѓајЕФlogднЪБВЛФмжиЗХЁЃ
жїДгЮяРэИДжЦЕФГЃЙцзіЗЈЪЧдкMasterгыROжЎМфДЋЪфlogФкШнЃЌШЛЖјTaurusУЛгаетбљзіЃЌвђЮЊетбљзіЛсЪЙЕУMasterНЧЩЋГЩЮЊЦПОБЃЌMasterВЛЕЋашвЊЯћКФCPUКЭФкДцРДДЋЪфlogФкШнЃЌЖјЧвЭјПЈДјПэЛсГЩЮЊЦПОБЁЃЖдгкУПУыВњЩњ100MBЕФlogЕФаДУмМЏЙЄзїИКдиРДЫЕЃЌШчЙћга15ИіROЪЕР§ЃЌФЧУДЙтЪЧДЋЪфlogФкШнЃЌMasterОЭашвЊЗЂЫЭ12GpbsЕФЪ§ОнЁЃЫљвдTaurusЕФжїДгИДжЦРрЫЦгкSocratesЃЌШУROЪЕР§ДгLog
StoreЛёШЁlogФкШнЁЃ
ЫфШЛетжжзіЗЈЬсИпСЫLog StoreЕФЭјПЈДјПэЯћКФЃЌЕЋЪЧгЩгкLog StoreЗўЮёЪЧвдМЏШКЕФЗНЪНЙмРэЃЌПЩвдКмЧсЫЩЫЎЦНРЉеЙЃЌЖјЧвИКдиЛљБОЪЧОљКтЕФЃЌЫљвдетжжзіЗЈВЛЛсЖдLog
StoreдьГЩЬєеНЁЃ
гЩгкMasterгыROЙВЯэДцДЂЃЌЫљвдpageЛсБЛMasterаоИФВЂЧвгыROжЎМфУЛгаШЮКЮЭЌВНЛЅГтЃЌЫљвдШчКЮШУROПДЕНвЛжТЕФЪ§ОнЪЧвЛИіживЊЬєеНЁЃ
ЪзЯШЃЌвЊБЃжЄЮяРэвГУцвЛжТЃЌвВМДЪЧB+ЪїЕФвЛжТЁЃБШШчЃЌЕБФГИіЯпГЬе§дкЗжСбФГИіB+ЪїЕФpageЃЌетЪБКђЕФИФЖЏЛсЩцМАЕНЖрИіpageЃЌЭЌЪБЃЌгавВдкБщРњетвЛПХЪїЦфЫћЯпГЬЃЌФЧУДШЗБЃИУЯпГЬПДЕНвЛжТЕФНсЙћЃЌвВМДЪЧЗжСбВйзїПДЦ№РДЯёЪЧвЛИідзгВйзїЁЃдкMasterЩЯЃЌетжжвЛжТадПЩвдЭЈЙ§ЖдpagesМгЫјРДЪЕЯжЁЃЕЋЪЧЃЌШчЙћдкMasterКЭROжЎМфвВаЕїРрЫЦЕФЫјЃЌФЧУДдьГЩЕФПЊЯњЪЧЗЧГЃДѓЕФЁЃЮЊСЫБмУтетбљЕФПЊЯњЃЌMasterвдgroupЮЊЕЅЮЛВњЩњlogЃЌВЂЧвБЃжЄgroupЕФБпНчЪЧвЛжТЕФЃЌЭЌЪБROЖСШЁКЭжиЗХlogЕФЪБКђЃЌвВЪЧвдgroupЮЊдзгСЃЖШЃЌЭЈЙ§етжжЗНЪНБЃжЄROПДЕНЕФB+ЪїЪЧвЛжТЕФЁЃ
ЦфДЮЃЌвЊБЃжЄЪТЮёИєРыМЖБ№ЯрЙиЕФвЛжТадЁЃTaurusЭЈЙ§дкЪТЮёЬсНЛжЎКѓЃЌаДШывЛЬѕcommit logЁЃдкROНтЮіИУlogжЎКѓЃЌОЭПЩвдИќаТЫќЕФЛюдОЪТЮёСаБэЃЌВњЩњаТЕФread
viewЃЌРДБЃжЄЪТЮёИєРыЕФвЛжТадЁЃ
ЕБШЛЃЌROгыMasterНЈСЂжїДгИДжЦЙиЯЕЕФЪБКђЃЌMasterашвЊНЋЕБЪБЕФДцСПЕФЛюдОЪТЮёИцжЊROЁЃ
ROдкжиЗХlogЕФЙ§ГЬжаЃЌГжајЭЦНјЫќЕФvisible LSNЃЌЕЋЪЧROдкЭЦНјvisible LSNЪБЃЌашвЊБЃжЄВЛЛсГЌЙ§sliceЕФpersistent
LSNЃЌБмУтГіЯжФГИіPage StoreЮоЗЈТњзуROЕФЖСЧыЧѓЕФЧщПіЁЃЕБжЛЖСЪТЮёашвЊЖСШЁpageЪБЃЌашвЊМЧТМЕБЧАЕФvisible
LSNЃЌМЧЮЊTV-LSNЁЃВЛЭЌЕФЪТЮёгаВЛЭЌЕФTV-LSNЁЃвђЮЊROдкВЛЖЯЭЦНјvisible LSNЃЌЫљвдЪТЮёЕФTV-LSNПЩФмЛсТфКѓЁЃROЪЕР§ЛсГжОУЮЌЛЄзюаЁЕФTV-LSNВЂИцжЊMasterЁЃMasterЪеМЏВЛЭЌROЕФLSNВЂШЁзюаЁжЕЃЌЩшжУЕНЫљгаsliceжазїЮЊаТЕФrecycle
LSNЁЃаЁгкИУLSNЕФОЩАцБОвГУцВХПЩвдАВШЋЩОГ§ЁЃ
Page StoreЩшМЦ
ТлЮФжазЈУХНВСЫPage StoreЕФвЛаЉЩшМЦвЊЕуЁЃЪзЯШЃЌslice ИББОжЎМфЕФlogжиЗХЁЂpageЛиаДЖМЪЧЖРСЂНјааЕФЃЌВЛашвЊдкИББОМфreplicateЙЙдьpageВњЩњЕФЪ§ОнЃЌМѕЩйСЫЭјТчДјПэПЊЯњЁЃЦфДЮЃЌДХХЬIOЖМЪЧappend-onlyЃЌЬсЩ§адФмВЂМѕЩйЩшБИЫ№КФЁЃЕкШ§ЃЌЙЙдьаТpageашвЊЕФЪ§ОнЃЈlog+ЛљзМpageЃЉдкФкДцжагаНјааcacheЃЌЬсИпЙЙдьpageЕФЫйЖШЁЃСэЭтЃЌТлЮФжаЛЙНВСЫШчКЮдкЙЙдьЁЂЛиаДаТpageЕФЙ§ГЬжаОЁСПНЕЕЭаДЗХДѓЃЌетвЛЕувВЪЧЗЧГЃживЊЁЃ
ЦфжаЙиМќвЛИіЪ§ОнНсЙЙЪЧLog DirectoryЃЌЪЧвЛИіЮоЫјhashБэЃЌkeyЪЧpage IDЃЌvalueЪЧЯргІpageЕФвЛЯЕСаlogЕФДцДЂЮЛжУЁЂИїАцБОpageЕФДцДЂЮЛжУЁЃИУЪ§ОнНсЙЙЛсБЛжмЦкадЕФГжОУЛЏЁЃPage
StoreЕФЙЄзїСїГЬШчЯТЭМЫљЪОЃЌЯИНкДЫДІВЛдйзИЪіЃК
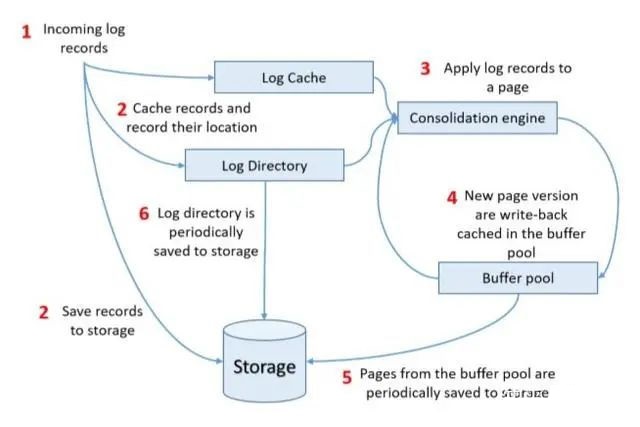
ЮвВТВтДцДЂЮЛжУжИЕФЪЧдкappend-onlyЮФМўжаЕФoffsetЃЌетИіЮФМўУВЫЦНазіslice_logЃЌТлЮФжаВЂУЛгаУїШЗЕФЫЕУїЁЃЮвВТВтsliceЪеЕНЕФlogФкШнЁЂЙЙдьЕФpageФкШнЖМЪЧЫГађаДШыдкslice_logжаЁЃЭЈЙ§append-onlyЕФЗНЪННЋдБОЛиаДpageЕФЫцЛњIOзЊЛЛГЩСЫЫГађIOЁЃВТВтвВАбЖрИіsliceЕФlogФкШнЁЂpageФкШнЗХЕНСЫЭЌвЛИіslice_logЃЌБмУтЖрИіsliceжБНгИїаДИїЕФЪ§ОнаЮГЩЫцЛњIOЁЃЭЌЪБЃЌдкLog
DirectoryЮЌЛЄСЫpageЕФДцДЂЮЛжУЃЌПЩвдПьЫйдкslice_logжаЖСШЁЕНашвЊЕФpageЁЃЕЋЪЧЃЌетбљЕФзіЗЈШчКЮЪЕЯжШпгрЪ§ОнЕФЛиЪеФиЃЌБШШчашвЊЩОГ§ЕєОЩАцБОЕФpageЃЌгІИУШчКЮВйзїЃПВЩгУcompactionЕФЗНЪННЋslice_logФкЕФШпгрЪ§ОнЩОЕєЃПЕЋЪЧдкLog
DirectoryжаЮЌЛЄЕФЮЛжУЪЧВЛЪЧЖМвЊЯргІЕїећЃЌДјРДЕФаДЗХДѓЪЧЗёПЩвдНгЪмЃП
| 








