| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫИХЪідЦдЩњЪ§ОнПтЁЂДЋЭГЙиЯЕаЭЪ§ОнПтЯђдЦдЩњЛЗОГЧЈвЦЁЂЙмРэPolarDB
Oв§ЧцЃЈМцШнOracleгяЗЈЁЂPolarDB Oв§ЧцЃЈМцШнOracleгяЗЈЃЉЕФПЊЗЂЪЕМљЃКЪ§ОнПтЛљБОЙцЗЖЕШЯрЙиФкШн
ЁЃ
БОЮФРДздАЂРядЦЪ§ОнПтЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
вЛЁЂИХЪідЦдЩњЪ§ОнПт
ЃЈвЛЃЉдЦМЦЫуЪЧЪ§зжЛЏЕФЛљДЁЩшЪЉ

жкЫљжмжЊЃЌФПЧАдЦМЦЫувбОГЩЮЊЪ§зжЛЏЕФЛљДЁЩшЪЉЃЌећИіЩчЛсвВдкЪ§зжЛЏЁЃЪ§зжЛЏЩјЭИНјЮвУЧЕФШеГЃЩњЛюжаЃЌГ§СЫвТЪГзЁааЃЌЛЙАќРЈНЬг§ЁЂвНСЦЁЂгЮЯЗЕШЁЃ
вдвНСЦСьгђЮЊР§ЃЌдчаЉФъШЅвНдКЃЌВЛЙмЪЧбщбЊЛЙЪЧХФаиЦЌЃЌвЛЖЈЪЧвЊШЅШЁжНжЪБЈИцЃЌШЛКѓДђвЛеХЫмСЯЕФаиЦЌЭМЁЃЕЋЪЧзюНќвЛСНФъЃЌГ§СЫШ§МзвНдКЃЌЦфЫћвНдКвВЛљБОЪЧЭЈЙ§ЭјЩЯЯђЛМепЬсЙЉЮоТлЪЧБЈИцЛЙЪЧаиЦЌжЎРрЕФВФСЯЃЌвНСЦСьгђЪ§зжЛЏЯжЯѓЪЎЗжУїЯдЁЃ
ЖјетаЉЪ§ОнШЋВПЖМЪ§зжЛЏвдКѓЃЌУцСйвЛИіЗЧГЃДѓЕФЮЪЬтЃЌЫќдкФФаЉЦНЬЈГадиЃЌдѕУДбљГадиЃПАЂРядЦЪЧЦфжаЗЧГЃживЊЕФвЛИіЛЗНкЃЌЪ§ОнПтдкЪ§зжЛЏНјГЬжаГадиСЫЪ§ОнЕФЩњВњЁЂМЏГЩЁЂЪЕЪБДІРэКЭЗжЮіЕФећЬзСїГЬЁЃдкећИіЪ§ОнПтжмБпЃЌПЩФмЛЙгагВМўЁЂАВШЋЁЂЕЏадМЦЫуЕШФмСІЃЌетаЉДѓДѓаЁаЁЕФЖЋЮїзюжезщГЩАЂРядЦетИіЦНЬЈЁЃ
ЃЈЖўЃЉЪВУДЪЧдЦдЩњЪ§ОнПтММЪѕ
дЦМЦЫудкжиЫмЪ§ОнПтММЪѕгыЩЬвЕЁЃ
дкЪ§зжЛЏБГОАЯТЃЌЮвУЧгааэЖрЫМПМЁЃ
Ъ§ОнПтИњвдЧАФЧгаЪВУДВЛвЛбљФиЃПЪВУДЪЧЫљЮНЕФдЦдЩњЪ§ОнПтФиЃПзїЮЊЪЙгУЪ§ОнПтЕФПЊЗЂепЃЌЖдЪ§ОнПтЕФашЧѓгаЪВУДБфЛЏЃПШчНёЪЙгУЪ§ОнПтЮвУЧвЛАуЛсЬсЪВУДбљЕФЫпЧѓЃП
ШчНёЃЌЩЯВуЕФвЕЮёБфЛЏЗЧГЃПьЃЌАќРЈвдЧААЂРяАЭАЭЬдБІФкВПЦфЪЕвВгаЭЌбљЕФЮЪЬтЁЃвЕЮёЕФПьЫйБфЛЏШУПЊЗЂепУцСйвЛИіЗЧГЃДѓЕФЬєеНЃЌОЭЪЧвЊЗЧГЃПьЫйЕиЪЪгІБфЛЏЁЃдкдЦЦеМАжЎЧАЃЌетИіЙ§ГЬЦфЪЕЛЙЪЧБШНЯТ§ЕФЃЌДгЙЙНЈЗўЮёЦїЃЌШЛКѓЭјТчДђКУЃЌАВзАВйзїЯЕЭГКЭЪ§ОнПтЕШЃЌећИіСїГЬЗЧГЃГЄЁЃ
ЖдЪ§ОнПтЕФЫпЧѓЃЌзмНсЦ№РДПЩФмгавдЯТМИИіЁЃ

ЕквЛИіОЭЪЧЮвУЧЯЃЭћИќзЈзЂдквЕЮёПЊЗЂЩЯЃЌВЛвЊАбЬЋЖрЪБМфЗХдкЕзВуЕФгВМўЁЂШэМўЁЂЛњЗПЁЂЭјТчЕШЩшЪЉЕФХфжУЩЯЁЃ
ЕкЖўИіЪЧПЊЯфМДгУЕФЃЌЮвУЧЯЃЭћЪ§ОнПтДДНЈКУСЫПЩвджБНгЪЙгУЃЌВЛашвЊдйШЅзіХфжУЁЂгХЛЏЕШЗЧГЃЗБЫіКФЪБЧвзЈвЕадЧПЕФЪТЧщЁЃ
ЕкШ§ИіЪЧАВШЋПЩаХЃЌАбЪ§ОнЗХдкЕкШ§ЗНЦНЬЈЩЯЃЌАВШЋПЩаХЪЧвЛИіЗЧГЃЛљБОЕФвЊЧѓЁЃ
ЕкЫФИіЪЧПЊЗХМцШнЃЌЮвУЧВЛЯЃЭћБЛФФИідЦГЇЩЬЫјЖЈЃЌЯЃЭћФмЗЧГЃздгЩЕиЧЈвЦНјРДКЭЧЈвЦГіШЅЁЃ
ЕкЮхИіЪЧКЃСПРЉеЙЃЌЫцзХвЕЮёБЌЗЂЪНЕФдіГЄЃЌЯЕЭГбЙСІКмПьОЭЛсБфГЩдРДЕФЪ§БЖЩѕжСЪ§ЪЎБЖЁЃдкетжжЧщПіЯТЃЌШчЙћУЛгавЛИіКмКУЕФКсЯђЁЂзнЯђРЉеЙЕФЪ§ОнПтЯЕЭГЃЌФЧУДКмФбжЇГХвЕЮёе§ГЃдЫааЃЌДІРэЦ№РДОЭЛсЗЧГЃМЌЪжЁЃ
ЕкСљИіЪЧШЋЧђЛЏЁЃжаЙњКмЖргЮЯЗГЇЩЬдкКЃЭтЕФЭиеЙКЭЭЦЙузіЕУЗЧГЃВЛДэЃЌгШЦфЪЧдкЖЋФЯбЧвЛДјЃЌСэЭтвВгавЛаЉгЮЯЗдкХЗУРШеБОЛёЕУСЫЗЧГЃДѓЕФГЩЙІЃЌЫљвдЯждкгааЉПЊЗЂепвВУцСйзХШЋЧђЛЏЕФЫпЧѓЃЌзїЮЊЪ§ОнПтЕФЛљДЁЩшЪЉЃЌгІИУЫМПМШчКЮЬсЙЉШЋЧђЛЏЕФФмСІЁЃ
ЕкЦпИіЪЧГжајПЩгУЃЌЮвУЧдРДздМКзівЛЬзЪ§ОнПтЯЕЭГЃЌГжајПЩгУвВЪЧКЫаФПМТЧжЎвЛЁЃ
Г§ДЫжЎЭтЛЙгаПЩППадЃЌвЊЧѓВЛФмЗЂЩњЪ§ОнЖЊЪЇЁЃ
зюКѓЪЧЕЭГЩБОЃЌЕБвЕЮёЗЂеЙЕНБШНЯГЩЪьЕФНзЖЮЃЌЮвУЧЛсЙизЂЕЭГЩБОЁЃ
дкетаЉПЭЛЇЫпЧѓЯТЃЌЮвУЧЫМПМЯТвЛДњЪ§ОнПтЛђепЫЕаТЕФЪ§ОнПтвЊОпБИФФаЉЬиадЃЌвВОЭЪЧдЦдЩњЪ§ОнПтЫќЫљОпБИЕФВњЦЗФмСІЃЌШчЯТЫљЪОЁЃ

ЕквЛИіЪЧШЋУцЭаЙмЃЌгУЛЇВЛдйашвЊШЅЙизЂАВзАЁЂБИЗнЁЂВПЪ№ЁЂМрПиЁЂИпПЩгУЕШЃЌПЩвдвЛМќДДНЈЪЕР§ЃЌДДНЈГіРДЕФЪЕР§ОпБИвдЩЯЖЋЮїЁЃ
ЕкЖўИіЪЧАДСПИЖЗбЃЌАДСПИЖЗбПЩвдШУвЕЮёЦ№ВНЕФГЩБОБфЕУЗЧГЃЕЭЃЌЗёдђЛњЗПЁЂгВМўЁЂЭјТчЕШвЛећЬзЩшЪЉХфжУЯТРДЃЌГЩБОЗЧГЃИпАКЁЃ
ЕкШ§ИіЪЧАДашЕЏадЃЌЫќЗжЮЊСНИіЗНУцЃЌвЛЗНУцЪЧвЊОпБИЭљЩЯЕЏЕФФмСІЃЌЕБвЕЮёдкПьЫйЗЂеЙЕФЙ§ГЬжаЃЌЪ§ОнПтвВвЊФмЙЛПьЫйЭљЩЯЕЏЁЃСэвЛЗНУцЪЧЭљЯТЕЏЃЌЕБвЕЮёИпЗхЙ§ШЅСЫЃЌашвЊКмПьЕиАбзЪдДЪЙгУСПНЕЯТРДЃЌДяЕННЕЕЭГЩБОЕФФПЕФЁЃ
ЕкЫФИіЪЧЩњЬЌМцШнЃЌЮоТлгУЛЇФПЧАЪЙгУЕФЪЧMySQLЃЌЛЙЪЧOracleЃЌЛђепЪЧЦфЫћЪ§ОнПтЃЌЮвУЧФмЧЈвЦНјРДЃЌвВФмЧЈвЦГіШЅЁЃ
ЩЯЗНЪЧЮвУЧШЯЮЊдЦдЩњЪ§ОнПтЫќЫљОпБИЕФВњЦЗФмСІЁЃ
дкетаЉВњЦЗФмСІЕзЯТЃЌЛЙЪЧгаКмЖрЕФММЪѕдкжЇГжЁЃ

СљДѓКЫаФММЪѕЗжБ№ЪЧжЧФмЛЏЁЂЖрФЃЁЂШэгВМўвЛЬхЛЏЁЂАВШЋПЩаХЁЂHTAPЃКДѓЪ§ОнПтЪ§ОнПтвЛЬхЛЏЁЂдЦдЩњ+ЗжВМЪНЁЃетСљДѓКЫаФММЪѕжЇГХСЫЩЯЮФЕФВњЦЗФмСІЃЌНтОіПЊЗЂепЫпЧѓЁЃ
ЃЈШ§ЃЉдЦдЩњЙиЯЕаЭЪ§ОнПт PolarDB
PolarDBЪЧАЂРяАЭАЭздбаЕФаТвЛДњдЦдЩњЪ§ОнПтЃЌдкДцДЂМЦЫуЗжРыМмЙЙЯТЃЌРћгУСЫШэгВМўНсКЯЕФгХЪЦЃЌЮЊгУЛЇЬсЙЉОпБИМЋжТЕЏадЁЂИпадФмЁЂКЃСП
ДцДЂЁЂАВШЋПЩППЕФЪ§ОнПтЗўЮёЁЃ100%МцШнMySQL 5.6/5.7/8.0ЃЌPostgreSQL 11ЃЌИпЖШМцШнOracleЁЃ
PolarDB-XЮЊPolarDBЗжВМЪНАцБОЃЌШкКЯЗжВМЪНSQLв§ЧцгыЗжВМЪНздбаДцДЂX-DBЃЌзЈзЂНтОіКЃСПЪ§ОнДцДЂЁЂГЌИпВЂЗЂЭЬЭТЁЂИДдгМЦЫугыЗжЮіЕШЮЪЬтЁЃ

ЃЈЫФЃЉдЦдЩњЙиЯЕаЭЪ§ОнПтPolarDBВњЦЗМмЙЙ
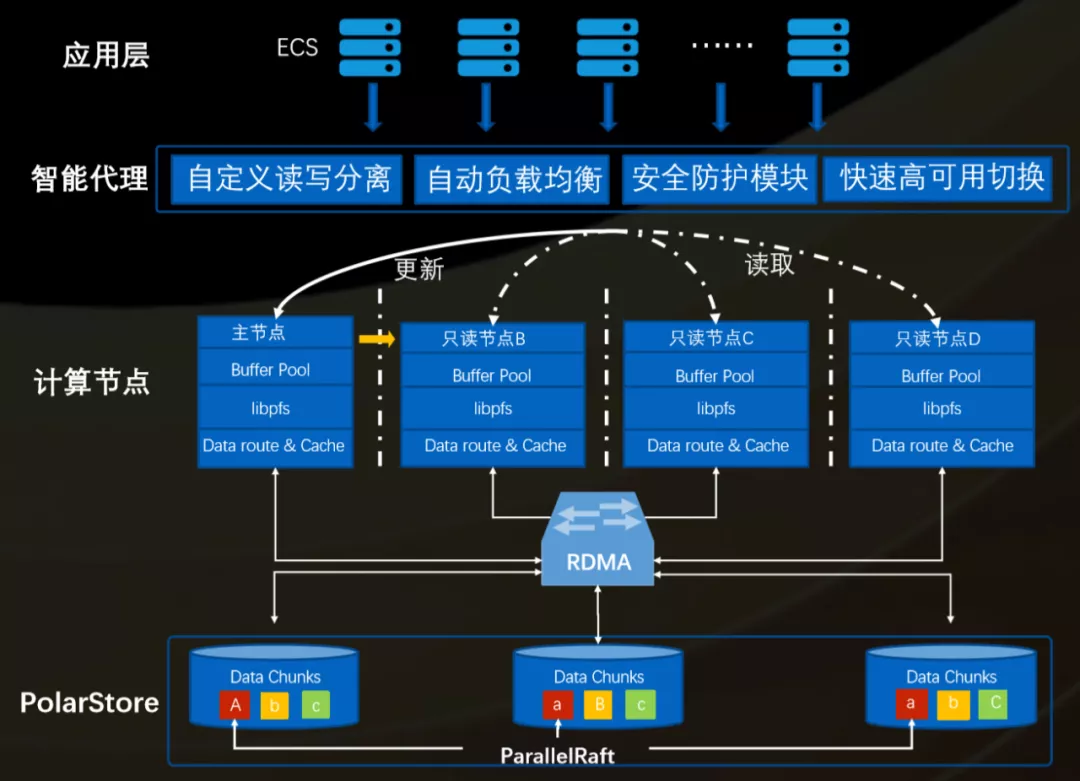
PolarDBВњЦЗМмЙЙЭМ
PolarDBВњЦЗгавдЯТЬиадЃК
ЁЄДцДЂМЦЫуЗжРы
1ЃЉЗжжгМЖЕЏадЩ§НЕМЖ
2ЃЉЗжжгМЖаТді/ЩОГ§жЛЖСНкЕу
ЁЄжЧФмДњРэзЊЗЂ
1ЃЉЪЕЯжЪ§ОнПтЭИУїРЉШн
2ЃЉЖржжвЛжТадМЖБ№
3ЃЉздЖЈвхEndpoint
ЁЄЗжВМЪНДцДЂ
1ЃЉжЇГж100TB
2ЃЉПьЫйБИЗнгыЛжИД
3ЃЉИќИпЕЅЪЕР§IOФмСІ
ЁЄlibpfs+rdma+optane
1ЃЉИпадФмЭИУїЪЕЯжШ§ИББО RPO=0
2ЃЉИпадФмаДШыЃКЪЕЯжИпВЂЗЂЕФаДШы
ЁЄЛљгкredoИДжЦ
1ЃЉжЛЖСЪЕР§КСУыМЖбгГй
2ЃЉНтОіbinlog/redoЫЋШежОвЛжТадгыадФмЮЪЬт
ЁЄВЂаажДаа
1ЃЉВПЗжГЁОАЯТЕФВщбЏгыЗжЮі
2ЃЉПЩвдздгЩПижЦЕФВЂааЖШЃЌБЃеЯадФмгыЮШЖЈад
етРяжївЊНВвЛИіКЭПЊЗЂепЪЙгУЙ§ГЬжаЙиЯЕБШНЯДѓЕФЬиадЃКжЧФмДњРэзЊЗЂЁЃ
дкЪ§ОнПтжагавЛИіЗЧГЃФбЕФЕуЃЌЫќИњгІгУЗўЮёЦїВЛвЛбљЃЌЕБгІгУЗўЮёЦїЯЕЭГбЙСІЬиБ№ДѓЕФЪБКђЃЌЛЙЪЧБШНЯШнвззіРЉеЙЕФЃЌПЩвдМгвЛзщгІгУЗўЮёЦїЃЌАбЯрЙиЕФСїСПРЉеЙЕНаТЕФгІгУЗўЮёЦїЩЯОЭПЩвдСЫЁЃ
ЕЋЪ§ОнПтЭЈГЃзіВЛЕНЃЌвђЮЊЪ§ОндкВщбЏКЭЪЙгУЩЯЖМЪЧЯрЛЅЙиСЊЕФЃЌЪ§ОнВЛФмМђЕЅЕизіВ№ЗжЁЃPolarDBдкЩЯВугавЛИіжЧФмДњРэВуНаProxyЃЌЫќЮЊПЊЗЂепНтОіСЫетИіЮЪЬтЁЃЕБЪ§ОнПтЯЕЭГбЙСІЬиБ№ДѓЕФЪБКђЃЌЭЈЙ§жЧФмДњРэПЩвдздЖЏАбвЛаЉВщбЏЕФQueryЗжЗЂЕНБ№ЕФжЛЖСНкЕуЩЯЁЃБШШчдРДЪЧвЛжївЛБИЃЌПЩвдБфГЩвЛжїШ§БИЃЌОЭПЩвдАбСїСПздЖЏЗжЗЂЕНШ§ИіНкЕуЁЃ
ДѓМвПЩФмЯыЃЌетИіВЛОЭИњдРДЪ§ОнПтМгМИИіБИПтЪЧвЛбљЕФЕРРэТ№ЃП
PolarDBЭЈЙ§жЧФмДњРэНтОіСЫвЛИіЗЧГЃЙиМќЕФЮЪЬтЃЌФЧОЭЪЧМгСЫетаЉжЛЖСНкЕувдКѓЃЌгІгУЗўЮёЦїЩЯЕФСЌНгХфжУЪЧВЛашвЊзіШЮКЮИФЖЏЃЌПЩвдЫцЪБМгЩЯШЅЃЌжЧФмДњРэЪеЕНQueryвдКѓЛсздЖЏзЊЗЂЙ§ШЅЁЃ
вдЯжЪЕвЕЮёГЁОАОйР§ЃЌБШШчФГЬьЧАЖЫЕФвЕЮёЯЕЭГИцЫпЮвУЧЃЌУїЬьдчЩЯ10ЕувЊзівЛИіДйЯњЛюЖЏЃЌЧызіКУЪ§ОнПтЕФРЉШнЁЃ
вдЧАШчЙћМгСЫжЛЖСНкЕуЃЌПЩФмгіЕНЕФЮЪЬтЪЧЧАЖЫгІгУЗўЮёЦїИљБООЭЗУЮЪВЛЕНетИіжЛЖСНкЕуЃЌЛђепПЩвдЗУЮЪЕНжЛЖСНкЕуЃЌЕЋвЊЖдгІгУЗўЮёЦїЕФХфжУзівЛаЉИФБфЃЌПЩФмЕМжТгІгУвЊАбгІгУЗўЮёЦїжиЦєЁЃЯждкЭЈЙ§PolarDBЕФжЧФмДњРэПЩвдгааЇНтОіетИіЮЪЬтЃЌЗНБуПьНнЕизіШнСПРЉеЙЁЃ
ЖўЁЂДЋЭГЙиЯЕаЭЪ§ОнПтЯђдЦдЩњЛЗОГЧЈвЦ
ЃЈвЛЃЉДЋЭГЩЬвЕЪ§ОнПтЬцЛЛЕФЬєеН
ШчНёЃЌШчЙћвЊДгБ№ЕФЩЬвЕЪ§ОнПтЧЈвЦЕН PolarDBЩЯЃЌБШШчДгOracleЪ§ОнПтЃЌвЛАуРДЫЕгаМИИіБШНЯДѓЕФЬєеНЁЃ

ЕквЛИіЬєеНЪЧгІгУёюКЯЖШИпЁЃЭЈГЃЧщПіЯТЃЌЪ§ОнПтИњгІгУЕФёюКЯЖШЗЧГЃИпЃЌШчЙћвЊЖдЪ§ОнПтзівЛИіЖЏзїЕФЛАЃЌгІгУЧАЖЫЕФгІгУвЊХфКЯзХвЛЦ№зіЃЌПЩФмЛсгАЯьЧАЖЫЕФПЩгУадЃЌвђЮЊЭЈГЃЧщПіЯТЪ§ОнПтЕзЯТГадиЕФвЕЮёЖМЪЧБШНЯЙиМќЕФЃЌЖЏЪ§ОнПтЭљЭљвтЮЖзХЖЏЧАЖЫгІгУЁЃ
ЕкЖўИіЬєеНЪЧЮШЖЈадвЊЧѓИпЁЃЪ§ОнПтвЛГіЮЪЬтЃЌЧАЖЫЕФвЕЮёОЭЛсГіЮЪЬтЃЌЫљвдЪ§ОнПтЕФБфИќКЭЖЏзїОГЃЛсдкЭэЩЯжДааЁЃ
ЕкШ§ИіЬєеНЪЧЪ§ОнСПДѓЁЃгЩгкЯждквЕЮёЖМБШНЯДѓЃЌвђДЫКЫаФЪ§ОнПтЕФЪ§ОнСПЭЈГЃЛсБШНЯДѓЁЃ
ЕкЫФИіЬєеНЪЧгяЗЈМцШнвЊЧѓИпЁЃЫфШЛДѓМвЪЙгУЕФЖМЪЧ SQLЃЌЕЋЪЧВЛЭЌЪ§ОнПтЕФSQLЛЙЪЧВЛвЛбљЕФЁЃШчЙћДгOracleЪ§ОнПтЧЈвЦЕНPolarDBЃЌSQLвЊзіЬЋЖрЕФИФдьЕФЛАЃЌОЭвтЮЖзХЧАЖЫвЕЮёЯЕЭГЕФИФдьвЊЗЧГЃДѓЃЌЧщПівВКмИДдгЁЃ
ЃЈЖўЃЉЪЙгУдЦдЩњЪ§ОнПтPolarDBЬцЛЛДЋЭГЩЬвЕЪ§ОнПт
ЪЧвЛИіПЦбЇЕФБъзМЛЏЁЂВњЦЗЛЏЕФЙ§ГЬЁЃ
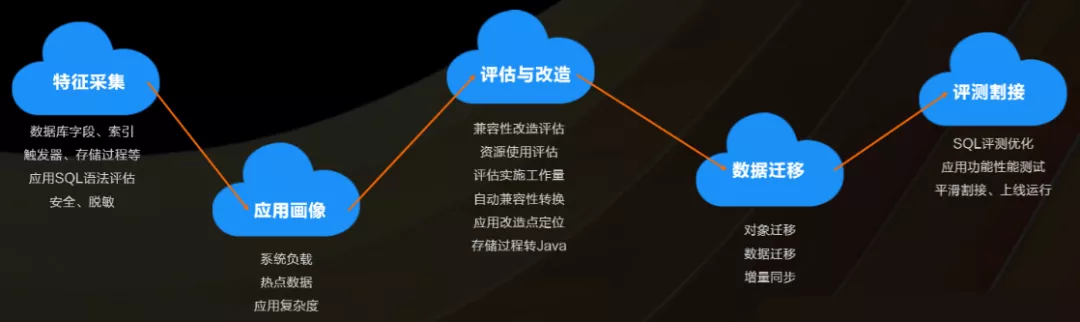
ЧЈвЦСїГЬЭМ
дкАЂРядЦЩЯЃЌЮвУЧЛсЬсЙЉвЛЬзБъзМЛЏСїГЬКЭВњЦЗАяжњгУЛЇДгдЪМЪ§ОнПтвЦЕНPolarDBЪ§ОнПтЁЃ
ЪзЯШЃЌЮвУЧЛсИјгУЛЇвЛИіЙЄОпЛђепНХБОЃЌЕНгУЛЇЕФЯЕЭГРяУцдЫаавЛЯТЃЌЫќПЩвдВЩМЏЕНгУЛЇЪ§ОнПтЕФвЛаЉЬиеїЃЌетИіЬиеїАќРЈгаФФаЉ
SQLЁЂКЏЪ§ЁЂДцДЂЙ§ГЬИњФПБъЪ§ОнПтаДЗЈВЛЦЅХфЃЌдЪМЕФЪ§ОнПтЕФЬиЕуЃЌБШШчЫќЪЧвЛИіЯЕЭГбЙСІЬиБ№ДѓЕФЪ§ОнПтЃЌЛЙЪЧвЛИіШШЕуЪ§ОнЬиБ№УїЯдЕФЪ§ОнПтЁЃЬНВтЕНетаЉЕуКѓЃЌЛсИцЫпгУЛЇдкКѓЦкЕФИФдьжавЊзЂвтЪВУДЮЪЬтЁЃ
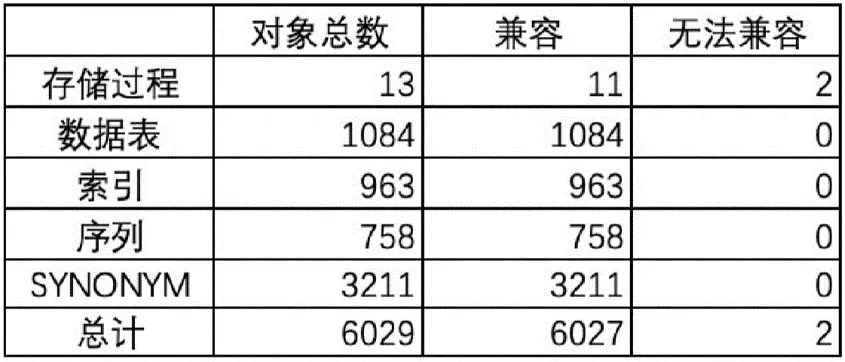
ЩЯЗНБэИёОЭЪЧдкЪЕМЪЕФвЕЮёЙ§ГЬжаЭЈЙ§НХБОХмГіРДЕФЁЃ
ЭЈЙ§етИіБэИёЃЌЮвУЧПЩвдПДЕНдЪМЪ§ОнПтШчЙћвЊЧЈвЦЕНPolarDBЕФЪБКђЃЌЫќећЬхЕФМцШнадЛЙЪЧБШНЯИпЕФЁЃЮвУЧвЛЙВЬНВтСЫ6029ИіЖдЯѓЃЌетИіЖдЯѓПЩФмАќРЈДцДЂЙ§ГЬЁЂЪ§ОнБэЁЂЫїв§ађСаЃЌЛЙгавЛаЉЭЌвхДЪЕШЯрЙиЕФЖЋЮїЃЌЦфжаВЛМцШнЕФЖдЯѓжЛгаСНИіЃЌЦфЪЕЪЧБШНЯЩйЕФЁЃБЈБэРяЛсжИГіОпЬхЪЧФФСНИіБэЃЌРяУцвВгавЛаЉБШНЯОпЬхЕФаоИФНЈвщЃЌШЛКѓОЭПЩвдЧЈвЦЙ§РДСЫЁЃ
ЯТЭМЪЧвЛИіБШНЯОпЬхЕФЙ§ГЬЃЌДЫДІВЛЯъЯИеЙПЊВћЪіЁЃ

ФПЧАЃЌАЂРядЦвбОАбетвЛЬзБъзМЛЏЁЂВњЦЗЛЏЕФСїГЬКЭжаЙњаХЭЈдКвЛЦ№зіГЩСЫЪ§ОнПтЧЈвЦЕФБъзМжИФЯЃЌПЊЗЂепПЩвдЕНЭјЩЯВщдФЃЌзёеежИФЯзіЪ§ОнПтЧЈвЦЁЃ
Ш§ЁЂЙмРэPolarDB Oв§ЧцЃЈМцШнOracleгяЗЈЃЉ
ЃЈвЛЃЉPolarDBЬсЙЉУцЯђOracleЕФШЋеЛМцШнад
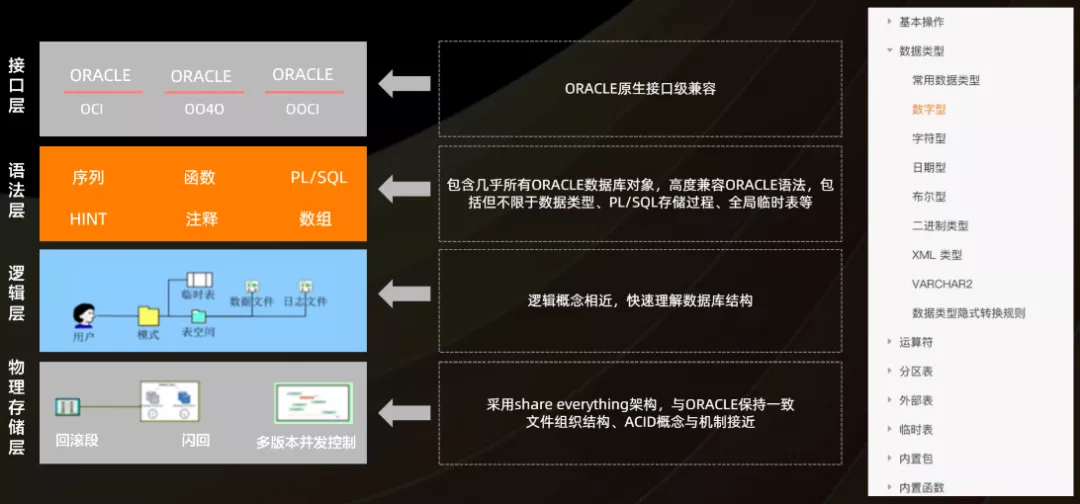
PolarDBЬсЙЉЕФOracleМцШнадЪЧАќРЈЖрИіЗНУцЕФЃЌГ§СЫгяЗЈВуЕФМцШнЃЌЛЙгаЮяРэДцДЂВуЁЂТпМВуКЭНгПкВуЁЃ
ЃЈЖўЃЉЙмРэPolarDB Oв§ЧцЃЈМцШнOracleгяЗЈЃЉЃКГЃгУЙЄОп
ШчЙћгУЛЇДгOracleЧЈвЦЙ§РДЃЌдкЪЙгУЛђепЙмРэPolarDBЕФЪБКђЃЌКЭдРДгаФФаЉВЛвЛбљЃП
дкЙмРэЙЄОпЗНУцЃЌгУЛЇПЩвдЪЙгУАЂРядЦдЦЖЫЕФЪ§ОнЙмРэЦНЬЈDMSЃЌдкПижЦЬЈЩЯевЕННаЕЧТМЪ§ОнПтЕФШыПкЃЌОЭПЩвдЕЧТМЕНDMSЩЯЃЌШчЯТЫљЪОЁЃ
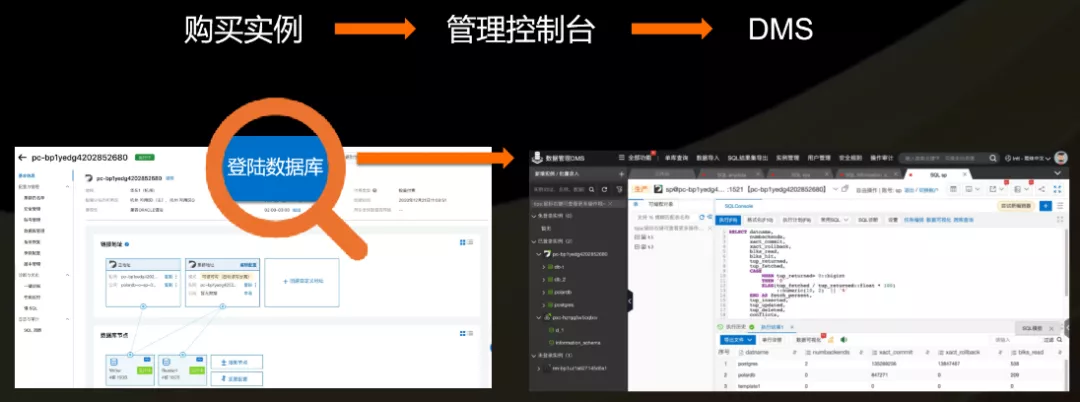
ЕкЖўИіЪЧгУПЊдДЕФЪ§ОнЙмРэЦНЬЈНаpgAdminЃЌдкетИіЦНЬЈЩЯПЩвдзіЛљБОЕФЪ§ОнЙмРэВйзїЃЌАќРЈЛљДЁаХЯЂЕФВщПДЃЌЪ§ОнВщбЏЃЌПДвЛаЉжДааМЦЛЎЁЂБэЁЂЖдЯѓЕШЃЌШчЯТЫљЪОЁЃ
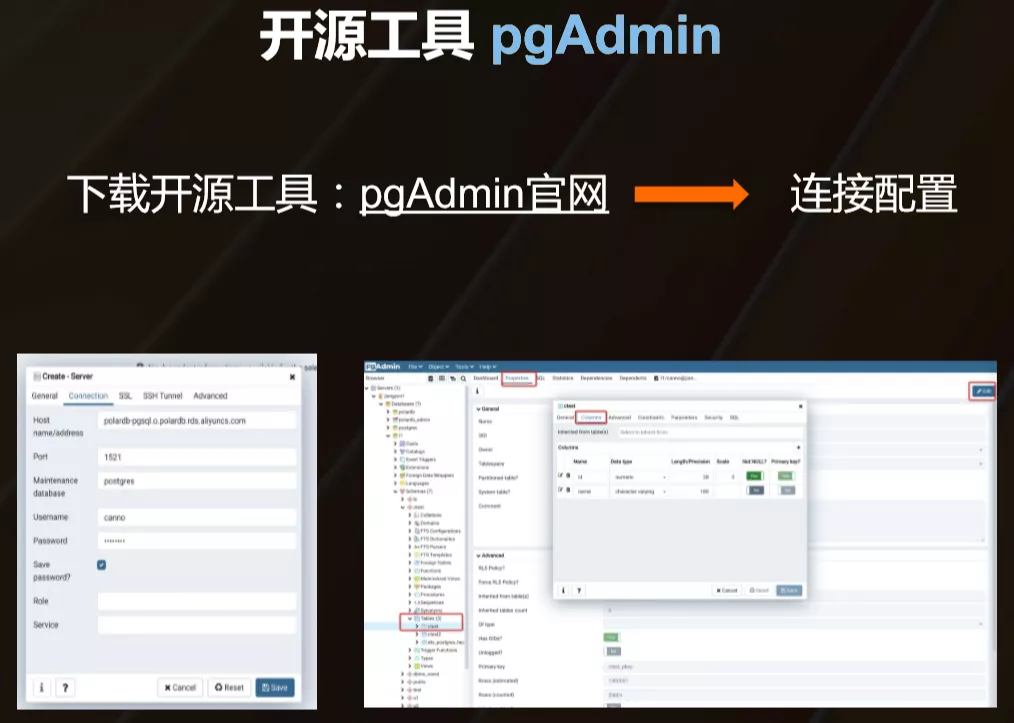
ЫФЁЂPolarDB Oв§ЧцЃЈМцШнOracleгяЗЈЃЉЕФПЊЗЂЪЕМљЃКЪ§ОнПтЛљБОЙцЗЖ
ЙмРэPolarDB Oв§ЧцЃЈМцШнOracleгяЗЈЃЉЃКПЊЗЂЙцЗЖЃЈ1ЃЉ
СэЭтЃЌАЂРядЦгавЛаЉГЃгУЕФПЊЗЂЙцЗЖЃЌПЊЗЂЙцЗЖЪЧАЂРядЦФкВПЬНЫїГіРДЕФЃЌвВГЦЮЊЙцдМЃЌдкАЂРяАЭАЭФкВПЪЧБШНЯбЯИёзёЪижДааЕФЃЌЮДРДЛсЗЂВМдкПЊЗЂепЩчЧјКЭАЂРядЦЕФЮФЕЕЬхЯЕжаЁЃПЊЗЂЙцЗЖЗжГЩМИИіЗНУцЃЌгааЉЕиЗНКЭПЊЗЂепдкОпЬхЪЙгУPolarDBЕФЪБКђЙиЯЕЛсБШНЯДѓЃЌЯТУцМђЕЅВћЪівЛЯТЁЃ
ЙцЗЖжагавЛаЉЪЧЮвУЧФкВПвЊЧѓЧПжЦжДааЃЌгавЛаЉдђЪЧЭЦМіжДааЃЌгУЛЇПЩвдИљОнздМКЕФЪЕМЪЧщПіНјааШЁЩсЁЃ

ЩЯЗНЮЊНЈБэЙцдМЁЃБШШчгавЛИіЖдзжЖЮУћЕФЙцЗЖЃЌвЊЧѓБиаывЊгУаЁаДзжФИКЭЪ§зжЃЌВЛФмгУЙиМќзжЃЌЮЊЪВУДЛсгаетбљЕФЙцЗЖЃПвђЮЊзжЖЮУћЕФаоИФЪЧвЛИіДњМлБШНЯДѓЕФЪТЧщЃЌЭЈГЃВЛФмЁАдЄЗЂЁБЁЃ
ЮвУЧЗЂЯжЃЌдкЪЕМЪЕФЩњВњЙ§ГЬжаИФвЛИізжЖЮУћЪЧЗЧГЃТщЗГЕФЁЃвђЮЊЧАУцЕФвЕЮёвбОдкдЫааЃЌШчЙћИФвЛИізжЖЮУћЃЌОЭвтЮЖзХвЕЮёЯЕЭГВЛФме§ГЃдЫааЁЃЫљвдвдЧАДѓЖрЪ§ЕФзіЗЈОЭЪЧМгаТЕФзжЖЮЃЌвђДЫЮвУЧЖдзжЖЮУћЬсСЫвЛаЉЙцЗЖЃЌБШШчжЛФмгУаЁаДзжФИЃЌВЛФмгУЙиМќзжЕШЁЃ
ЕкЖўИіЪЧБэУћКЭзжЖЮУћЃЌЮвУЧвЊЧѓМгcreate_timeКЭ update_timeЁЃетЛсДјРДМИИіКУДІЃЌЕквЛИіОЭЪЧШчЙћЪ§ОнЗЂЩњДэЮѓЕФЪБКђЃЌФуПЩвдКмПьжЊЕРзжЖЮЕФаоИФЧщПіКЭЪБМфЁЃЕкЖўИіЪЧдкЩЯЯТгЮЯЕЭГРяУцЃЌШчЙћвЊРШЁвЛаЉБфЛЏЪ§ОнЕФЪБКђЃЌЫќвВПЩвдЗЧГЃПьЕиевЕНФФаЉЪ§ОнЗЂЩњСЫБфЛЏЃЌШЛКѓШЅзіЖдгІЕФДІРэЁЃ
СэЭтЃЌБэБиаыгажїМќЁЃетРягаМИИідвђЃЌЕквЛИіЪЧВщбЏадФмЛсЗЧГЃКУЃЌЕкЖўИіЪЧдкЯТгЮЕФЯЕЭГРШЁвЛаЉБфЛЏЕФЪ§ОнЕФЪБКђЃЌЫќЭЈЙ§жїМќПЩвдБШНЯПьЫйЕиФУЕНЁЃ

ДЫЭтЛЙгавЛЯЕСаЕФЫїв§ЙцдМЃЌШчЩЯЭМЫљЪОЁЃ
ЙцдМжаЬсЕНЃЌЫїв§ЕФНЈСЂвЊгаЫГађЃЌетИіЫГађЕФПМТЧПЩФмЛсШЅЙизЂwhereЬѕМўРяУцгаФФаЉзжЖЮЃЌвЊзЂвтorder
byЬѕМўРяУцзжЖЮЕФЫГађЃЌетИіЫГађПЩФмвЊгАЯьЫїв§НЈСЂЕФзжЖЮЫГађЃЌжЛгаЫќУЧСНИіБШНЯЦЅХфЕФЪБКђЃЌећИіЕФадФмВХЛсБШНЯКУЁЃ
СэЭтЃЌШчЙћПЩвдгУИВИЧЫїв§ВщбЏЕФЪБКђЃЌОЁСПгУИВИЧВщЫїв§ВщбЏЃЌЛсДѓДѓдіМгаЇТЪЁЃ
ЙцдМжаЛЙгавЛИіЭЦМіЯюЃКРћгУбгГйЙиСЊЛђепзгВщбЏгХЛЏГЌЖрЗжвГГЁОАЁЃетвВЪЧЮвУЧдкЪ§ОнПтЕФЫїв§гХЛЏРяУцЕФОбщЁЃЕБзіЗжвГВщбЏЕФЪБКђЃЌБШШчЫЕЕБФуЗЕНСЫЕк1000вГЃЌЛђепЪЧЕк500вГетбљППКѓЕФвГУцЪБЃЌетЪБКђНЈвщЕФзіЗЈЪЧЃЌБШШчЫЕЗвГвЊВщГі10вГЕФФкШнЃЌзюКУЯШАбет10вГФкШнЕФжїМќIDЯШВщГіРДЃЌВщГіРДжЎКѓдйЛиБэвЛДЮЃЌАбЫљгаЕФЪ§ОнВщГіРДЃЌетЪЧвЛИіБШНЯГЃМћЕФЭЦМізіЗЈЁЃ
СэЭтЫїв§ЙцдМРяУцЛЙЬсЕНвЛЬѕЃЌОЭЪЧвЊзЂвтВЛЭЌзжЖЮРраЭЃЌОЁПЩФмЩйЛђепВЛвЊЗЂЩњвўЪНзЊЛЛЃЌвђЮЊвўЪНзЊЛЛЛсЕМжТећИіЫїв§ЪЇаЇЁЃ
ЙмРэPolarDB Oв§ЧцЃЈМцШнOracleгяЗЈЃЉЃКПЊЗЂЙцЗЖЃЈ2ЃЉ


SQLКЭдЫЮЌвВгааэЖрЙцдМЃЌетРяжївЊНВвЛЯТдЫЮЌЗНУцЦфжаМИИіЕуЁЃ
ЪзЯШЪЧЪ§ОнЖЉе§ЃЌПЊЗЂепШчЙћвЊШЅзівЛаЉаоИФЪ§ОнЕФЛАЃЌвЛЖЈвЊЯШАбетаЉЪ§ОнВщбЏГіРДЃЌЯШПДвЛБщдйШЅзіЩОГ§ЃЌвЊВЛШЛЕФЛАКмШнвзГіЯжЮѓЩОГ§ЁЃ
СэЭтЭЦМіЪЙгУЪ§ОнЙмРэВњЦЗDMSЁЃШчЙћдкDMSЩЯзіЪ§ОнЖЉе§ЕФЛАЃЌЫќгавЛИіКУДІЪЧПЩвдЙДбЁБИЗнЃЌЕБзіЪ§ОнЖЉе§ЕФЪБКђЃЌЫќЛсздЖЏАбЫљгавЊЖЉе§ЕФЪ§ОнШЋВПзівЛИіБИЗнЁЃШчЙћЗЂЯжЪ§ОнЖЉе§ГіСЫЮЪЬтЕФЪБКђЃЌПЩвдевЕНDMSздЖЏБИЗнЯТРДЕФЪ§ОнЃЌжиаТдйАбетИіЪ§ОнЛжИДЦ№РДЁЃ
ЦфЫћЕФетаЉетРяВЛзіЙ§ЖрВћЪіЃЌЮДРДЛсЗЂВМдкПЊЗЂепЩчЧјКЭАЂРядЦЕФЮФЕЕЬхЯЕжаЁЃ
ЮхЁЂPolarDB Oв§ЧцЃЈМцШнOracleгяЗЈЃЉЕФПЊЗЂЪЕМљЃКГЃМћЕФSQLгХЛЏ
ЃЈвЛЃЉЙмРэ PolarDB Oв§ЧцЃЈМцШнOracleгяЗЈЃЉЃКSQLгХЛЏАИР§вЛ ВЂааВщбЏ
ЕБВщвЛаЉДјИДдгМЦЫуЕФQueryЃЌгУВЂааВщбЏПЩвдДѓДѓМгЫйВщбЏаЇТЪЁЃ
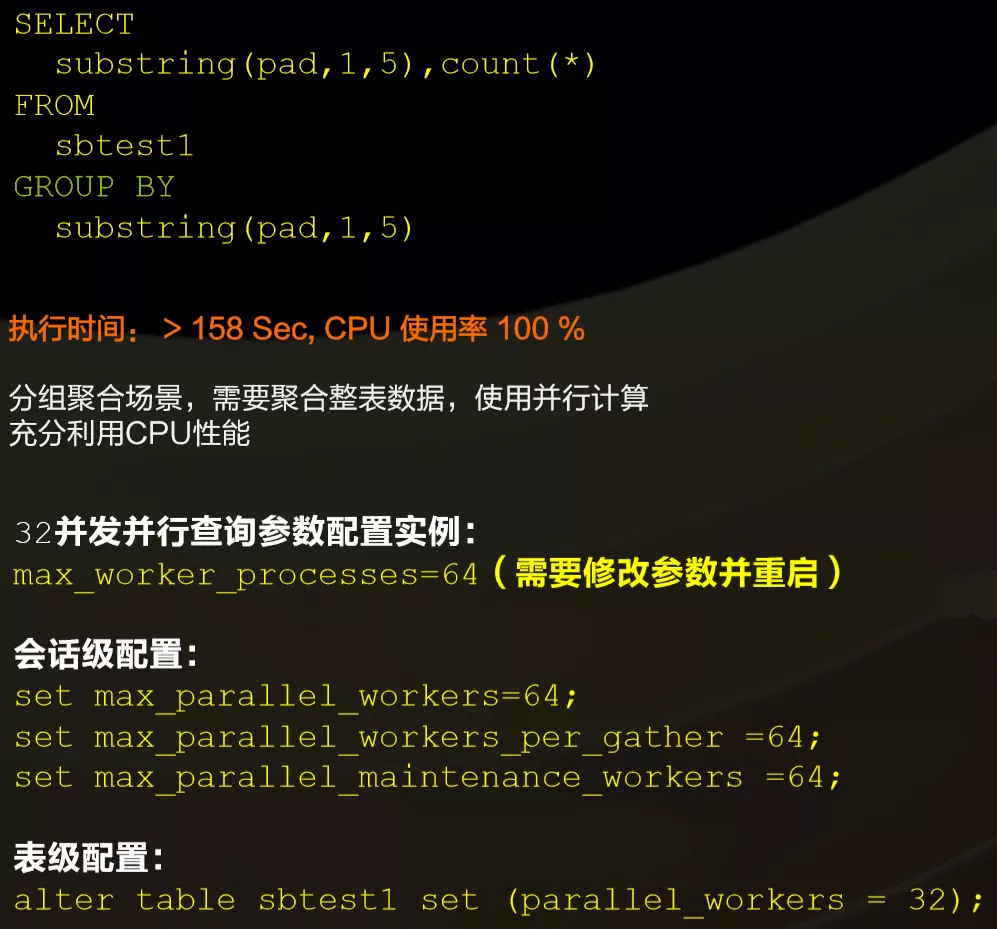
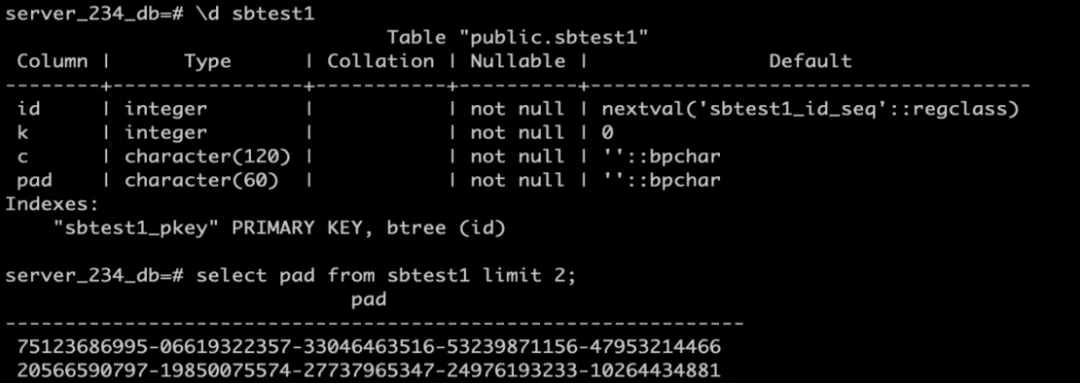
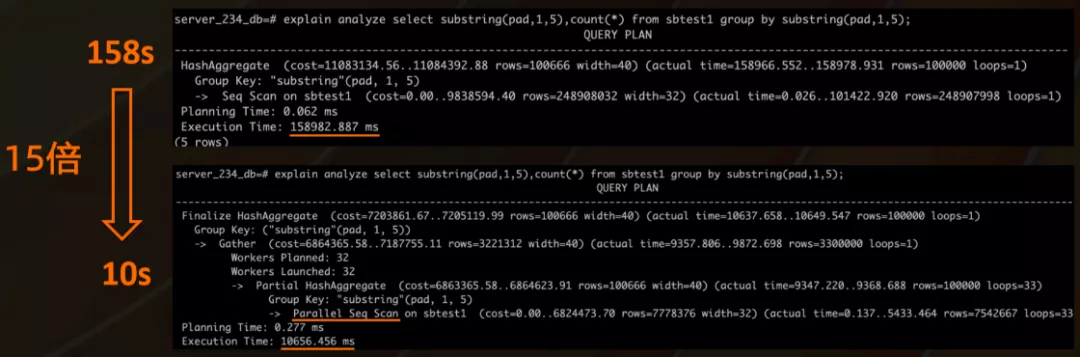
ЩЯЗНЪЧвЛИіМђЕЅЕФР§згЃЌдкGROUP BYЕФЪБКђгавЛИіЗЧГЃМђЕЅЕФМЦЫуЃЌЕБетИіQueryвЊЩЈУшЕФЪ§ОнЗЧГЃЖрЕФЪБКђЃЌПЊвЛИіВЂааВщбЏПЩвдШУКФЪБДгдРДЕФ100ЖрУыЕН10УыЪБМфЃЌЫйЖШЗСЫ10БЖЃЌетЪЧгУЛЇдкЪЙгУPolarDBЕФвЛИіаЁММЧЩЁЃ
ЃЈЖўЃЉЙмРэPolarDB Oв§ЧцЃЈМцШнOracleгяЗЈЃЉЃКSQLгХЛЏАИР§Жў бЁдёКЯЪЪЕФJOINЗНЪН

ЮвУЧжЇГжhash joinЃЌmerge joinКЭnest-loop joinЃЌгУЛЇПЩвдИљОнВЛЭЌЕФГЁОАбЁдёКЯЪЪЕФJoinЗНЪНЁЃ
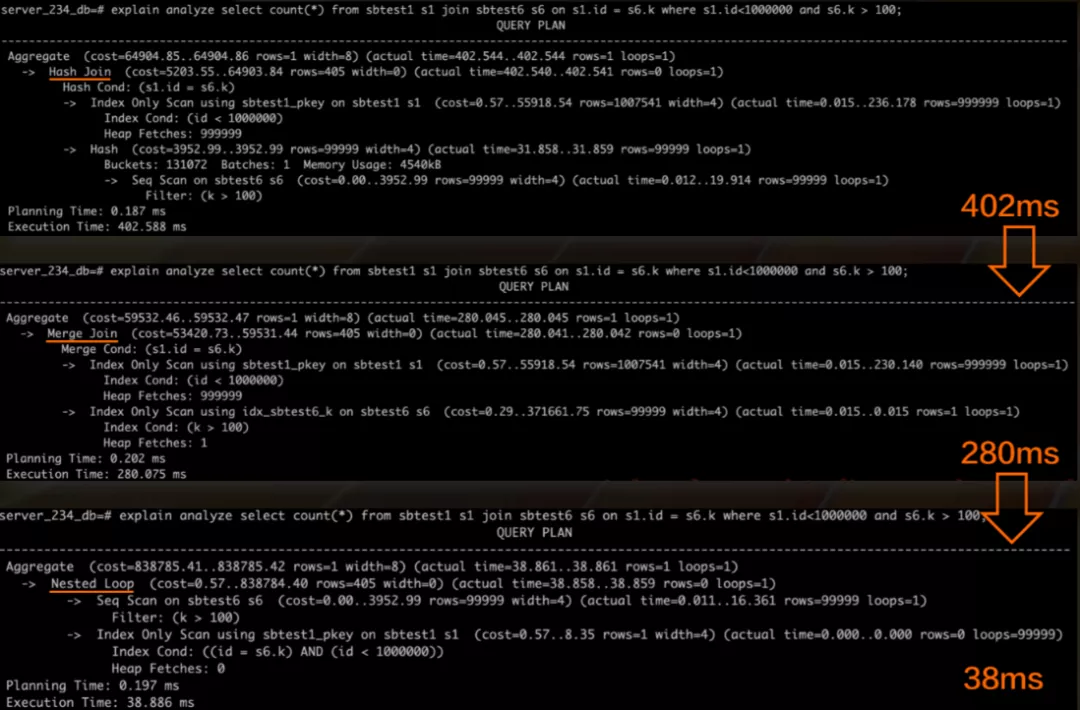
ПЩвдПДЕНЃЌдкЩЯУцетИіАИР§жаЃЌбЁдёnest-loop joinЪЧзюПьЕФЁЃ
СљЁЂАИР§гыШЯПЩ
ЃЈвЛЃЉЭъећЕФЪ§ОнПтЩњЬЌ
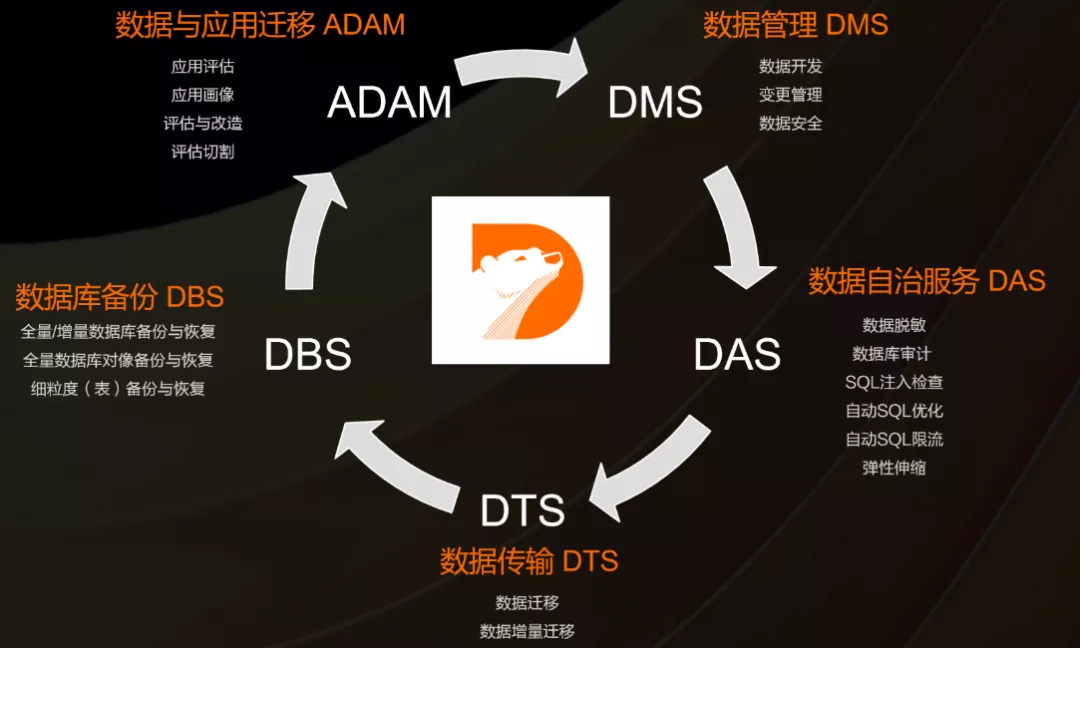
ЫфШЛPolarDBЪЧвЛИіЕЅЖРЕФВњЦЗЃЌЕЋЪЧЫќгаЗЧГЃЭъЩЦЕФВњЦЗЩњЬЌЃЌАќРЈЪ§ОнЙмРэDMSЃЌЪ§ОнзджЮЗўЮёDASЃЌЪ§ОнДЋЪфDTSЃЌЪ§ОнПтБИЗнDBSЃЌЪ§ОнгыгІгУЧЈвЦADAMЕШЃЌПЩвдТњзугУЛЇИїжжГЁОАЃЌДјРДШЋЗНЮЛЕФЗўЮёЁЃ
ЃЈЖўЃЉАИР§ЃКPolarDBжњСІPrestoMallЦНЛЌДгOracleЧЈвЦЩЯдЦ
PrestoMall ЪЧвЛМвГЩСЂгк2014ФъЕФЖЋФЯбЧЕчЩЬЦѓвЕЃЌЮЊСЫгІЖдвЕЮёЕФПьЫйдіГЄЃЌАЂРядЦЪ§ОнПтPolarDBжњСІPrestoMallЦНЛЌДгOracleЧЈвЦЩЯдЦЁЃ
ЧЈвЦЩЯдЦжївЊУцСйвдЯТвЕЮёЬєеНЃК
вЕЮёПьЫйЗЂеЙЃЌIT ЗбгУвВЫцжЎЫЎеЧДЌИпЃЌOracleГЩБОИпАКЃЛ
вЕЮёЕФПьЫйдіГЄЃЌгІЖдЫЋЪЎвЛДѓДйЗІСІЃЌгІгУОпБИЫЎЦНРЉеЙЕФФмСІЃЌЕЋЪЧЪ§ОнПтЕЏадВЛзуЃЛ
ШЅOИДдгЖШЬЋИпЃЌШБЗІОбщЃЌЯЃЭћгазЈвЕЦРЙРжИЕМЃЛ
зюгХЧЈвЦГЩБОЃЌПижЦЗчЯеГЩЮЊФбЬтЁЃ
ИљОнПЭЛЇвЕЮёашЧѓЃЌЮвУЧжЦЖЈСЫЧЈвЦжСPolarDB OЃЈМцШнOracleгяЗЈЃЉЕФЗНАИЃЌдвђЪЧЃК
1.PolarDB Oв§ЧцЃЈМцШнOracleгяЗЈЃЉ зїЮЊдЦЪ§ОнПтЃЌУЛгаАКЙѓЕФlicenseЗбгУЃЛ
2.PolarDB Oв§ЧцЃЈМцШнOracleгяЗЈЃЉдЦдЩњЕЏадЃЌНтОіПЭЛЇЪ§ОнПтЕЏадВЛзуЕФЮЪЬтЃЛ
3.ADAMЮЊПЭЛЇЬсЙЉзЈвЕЕФЪ§ОнПт/гІгУМцШнадЦРЙРБЈИцЃЌжЦЖЈЭъЩЦЕФЧЈвЦМЦЛЎЃЛНсКЯPolarDB Oв§ЧцЃЈМцШнOracleгяЗЈЃЉЖдOracleЕФИпМцШнадЃЌДѓЗљЬсЩ§ИФдьаЇТЪЃЛ
4.DTSЪЕЪБЧЈвЦ/ЛиСїЕФЙІФмЃЌХфКЯзЈМвЗўЮёЃЌДѓЗљЫѕЖЬИюНгЪБМфВЂНЕЕЭЗчЯеЁЃ
ЧЈвЦЕНPolarDB Oв§ЧцЃЈМцШнOracleгяЗЈЃЉКѓЃЌЭЈЙ§зюжеЪЕЯжСЫвдЯТПЭЛЇМлжЕЃК
1.PolarDB Oв§ЧцЃЈМцШнOracleгяЗЈЃЉдкГЩЙІжЇГХПЭЛЇвЕЮёЕФЭЌЪБЃЌЙЋЫОећЬхITГЩБОНЕЕЭ40%ЃЛ
2.ЫЋЪЎЖўДѓДйPolarDB Oв§ЧцЃЈМцШнOracleгяЗЈЃЉЕЏадЩ§МЖЃЌгІЖдздШчЃЛ
3.ADAM + PolarDB Oв§ЧцЃЈМцШнOracleгяЗЈЃЉАяжњПЭЛЇДњТыИФдьГЩБОНЕЕЭ93%
4.дкМЦЛЎФкЫГРћЦНЮШЭъГЩИюНгЃЌвЕЮёЮШЖЈдЫааЁЃ
ЃЈШ§ЃЉБЛЙуЗКШЯПЩЕФдЦдЩњЙиЯЕаЭЪ§ОнПтPolarDB

ФПЧАЃЌPolarDBдквЕНчЪмЕНЗЧГЃЙуЗКЕФШЯПЩЃЌЖЅМЖбЇЛсЕФТлЮФвбОГЌЙ§СЫ10ЦЊСЫЃЌЛёЕУСЫНёФъжаЙњЕчзгбЇЛсЕФПЦММНјВНвЛЕШНБЃЌЛЙгавЛаЉЦфЫћШЈЭўШйгўЁЃ | 








