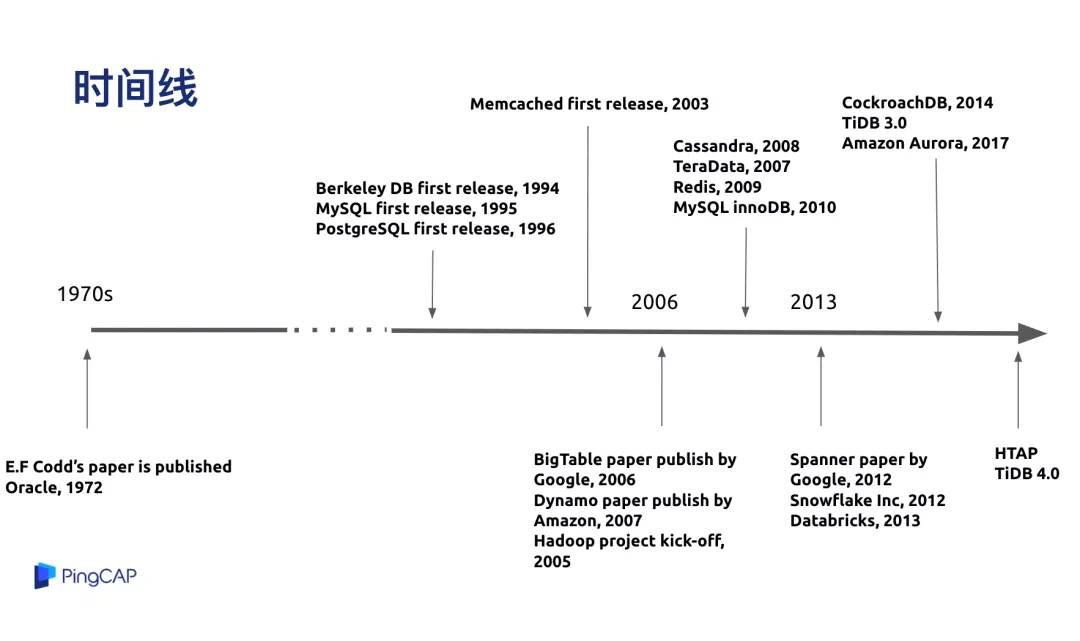
| Īŗľ≠Õ∆ľŲ: |
Īĺőń÷ų“™Ĺť…‹Ńň≥£ľŻĶń∑÷≤ľ Ĺ żĺ›Ņ‚ŃųŇ…°Ę żĺ›Ņ‚÷–ľšľĢ°Ę
NoSQL - Not Only SQL°ĘĶ໿īķ∑÷≤ľ Ĺ żĺ›Ņ‚ NewSQL°ĘĶŕňńīķŌĶÕ≥£ļ∑÷≤ľ Ĺ
HTAP żĺ›Ņ‚Ķ»ŌŗĻōńŕ»› °£
Īĺőńņī◊‘ InfoQ£¨”…ĽūŃķĻŻ»ŪľĢLindaĪŗľ≠°ĘÕ∆ľŲ°£ |
|
≥£ľŻĶń∑÷≤ľ Ĺ żĺ›Ņ‚ŃųŇ…
∑÷≤ľ Ĺ żĺ›Ņ‚Ķń∑Ę’Ļņķ≥Ő£¨ő“įī’’ńÍīķĹÝ––Ńň∑÷ņŗ£¨ĶĹńŅ«įő™÷Ļ∑÷≥…Ńňňńīķ°£Ķŕ“Ľīķ «Ľý”ŕľÚĶ•Ķń∑÷Ņ‚∑÷ĪŪĽÚ’Ŗ÷–ľšľĢņī◊Ų
Data Sharding ļÕ ňģ∆Ĺņ©’Ļ°£Ķŕ∂ĢīķŌĶÕ≥ «“‘ Cassandra°ĘHBase ĽÚ’Ŗ MongoDB
ő™īķĪŪĶń NoSQL żĺ›Ņ‚£¨“Ľį„∂ŗő™Ľ•Ń™ÕÝĻęňĺ‘ŕ Ļ”√£¨”Ķ”–ļ‹ļ√Ķńňģ∆Ĺņ©’Ļń‹Ń¶°£
Ķ໿īķŌĶÕ≥ő“łŲ»ň»Ōő™ «“‘ Google Spanner ļÕ AWS Aurora ő™īķĪŪĶń–¬“Ľīķ‘∆ żĺ›Ņ‚£¨ňŻ√«ĶńŐōĶ„ «»ŕļŌŃň
SQL ļÕ NoSQL Ķńņ©’Ļń‹Ń¶£¨∂‘“ĶőŮ≤„Ī©¬∂Ńň SQL ĶńĹ”Ņŕ£¨‘ŕ Ļ”√…ŌŅ…“‘◊ŲĶĹňģ∆ĹĶńņ©’Ļ°£
ĶŕňńīķŌĶÕ≥ «“‘Ō÷‘ŕ TiDB Ķń…Ťľ∆ő™ņż£¨Ņ™ ľĹÝ»ŽĶĹĽžļŌ“ĶőŮłļ‘ōĶń Īīķ£¨“ĽŐ◊ŌĶÕ≥”Ķ”–ľ»ń‹◊ŲĹĽ“◊“≤ń‹ī¶ņŪłŖ≤Ę∑Ę ¬őŮĶńŐō–‘£¨Õ¨ Ī”÷ń‹ĹŠļŌ“Ľ–© żĺ›≤÷Ņ‚ĽÚ’Ŗ∑÷őŲ–Õ żĺ›Ņ‚Ķńń‹Ń¶£¨ňý“‘Ĺ–
HTAP£¨ĺÕ «»ŕļŌ–ÕĶń żĺ›Ņ‚≤ķ∆∑°£
őīņī « ≤√ī—ý◊”£¨ļů√śĶń∑÷ŌŪő“ĽŠĹť…‹Ļō”ŕőīņīĶń“Ľ–©’ĻÕŻ°£ī”’ŻłŲ ĪľšŌŖŅī£¨ī” 1970 ńÍīķ∑Ę’ĻĶĹŌ÷‘ŕ£¨database
“≤ň„ «łŲĻŇņŌĶń––“ĶŃň£¨ĺŖŐŚ√ŅłŲĹ◊∂őĶń∑Ę’Ļ«ťŅŲ£¨ő“ĺÕ≤ĽĻż∂ŗ’ĻŅ™°£
żĺ›Ņ‚÷–ľšľĢ
∂‘”ŕ żĺ›Ņ‚÷–ľšľĢņīňĶ£¨Ķŕ“ĽīķŌĶÕ≥ «÷–ľšľĢĶńŌĶÕ≥£¨ĽýĪĺ…Ō’ŻłŲ÷ųŃųń£ Ĺ”–ŃĹ÷÷£¨“Ľ÷÷ «‘ŕ“ĶőŮ≤„◊Ų ÷∂ĮĶń∑÷Ņ‚∑÷ĪŪ£¨Ī»»Á żĺ›Ņ‚Ķń Ļ”√’Ŗ‘ŕ“ĶőŮ≤„ņÔłśňŖń„£ĽĪĪĺ©Ķń żĺ›∑Ň‘ŕ“ĽłŲ żĺ›Ņ‚ņÔ£¨∂Ý…Ōļ£Ķń żĺ›∑Ň‘ŕŃŪ“ĽłŲ żĺ›Ņ‚ĽÚ’Ŗ–īĶĹ≤ĽÕ¨ĶńĪŪ…Ō£¨’‚÷÷ĺÕ «“ĶőŮ≤„ ÷∂ĮĶń◊ÓľÚĶ•Ķń∑÷Ņ‚∑÷ĪŪ£¨Ōŗ–Ňīůľ“≤Ŕ◊ųĻż żĺ›Ņ‚ĶńŇů”—∂ľļ‹ žŌ§°£
Ķŕ∂Ģ÷÷Õ®Ļż“ĽłŲ żĺ›Ņ‚÷–ľšľĢ÷ł∂® Sharding ĶńĻś‘Ú°£Ī»»ÁŌŮ”√ĽßĶń≥« –°Ę”√ĽßĶń ID°Ę Īľšņī◊Ųő™∑÷∆¨ĶńĻś‘Ú£¨Õ®Ļż÷–ľšľĢņī◊‘∂ĮĶń∑÷Ňš£¨ĺÕ≤Ľ”√“ĶőŮ≤„»•◊Ų°£
’‚÷÷∑Ĺ ĹĶń”ŇĶ„ĺÕ «ľÚĶ•°£»ÁĻŻ“ĶőŮ‘ŕŐōĪūľÚĶ•Ķń«ťŅŲŌ¬£¨Ī»»ÁňĶ–ī»ŽĽÚ’Ŗ∂Ń»°ĽýĪĺń‹ÕňĽĮ≥…‘ŕ“ĽłŲ∑÷∆¨…ŌÕÍ≥…£¨‘ŕ”¶”√≤„◊Ų≥š∑÷ Ňš“‘ļů£¨—”≥ŔĽĻ «Ī»ĹŌĶÕĶń£¨∂Ý’ŻŐŚ…Ō£¨»ÁĻŻ
workload «ňśĽķĶń£¨“ĶőŮĶń TPS “≤ń‹◊ŲĶĹŌŖ–‘ņ©’Ļ°£
Ķę «»ĪĶ„“≤Ī»ĹŌ√ųŌ‘°£∂‘”ŕ“Ľ–©Ī»ĹŌłī‘”Ķń“ĶőŮ£¨ŐōĪū «“Ľ–©ŅÁ∑÷∆¨Ķń≤Ŕ◊ų£¨Ī»»ÁňĶ≤ť—ĮĽÚ’Ŗ–ī»Ž“™Ī£≥÷ŅÁ∑÷∆¨÷ģľšĶń żĺ›«Ņ“Ľ÷¬–‘Ķń ĪļÚĺÕĪ»ĹŌ¬ť∑≥°£ŃŪÕ‚“ĽłŲĪ»ĹŌ√ųŌ‘Ķń»ĪĶ„ «ňŁ∂‘”ŕīů–ÕľĮ»ļĶń‘ňő¨ «Ī»ĹŌņßń—Ķń£¨ŐōĪū «»•◊Ų“Ľ–©ņŗň∆ĶńĪŪĹŠĻĻĪšłŁ÷ģņŗĶń≤Ŕ◊ų°£ŌŽŌů“ĽŌ¬»ÁĻŻ”–“ĽįŔłŲ∑÷∆¨£¨“™»•ľ”“ĽŃ–ĽÚ’Ŗ…ĺ“ĽŃ–£¨ŌŗĶĪ”ŕ“™‘ŕ“ĽįŔŐ®Ľķ∆ų…Ō∂ľ÷ī––≤Ŕ◊ų£¨∆š Ķļ‹¬ť∑≥°£
NoSQL - Not Only SQL
‘ŕ 2010 ńÍ«įļů£¨ļ√∂ŗĽ•Ń™ÕÝĻęňĺ∂ľ∑ĘŌ÷Ńň’‚łŲīůĶńÕīĶ„£¨◊–ŌłňľŅľŃň“ĶőŮļů£¨ňŻ√«∑ĘŌ÷“ĶőŮļ‹ľÚĶ•£¨“≤≤Ľ–Ť“™
SQL ŐōĪūłī‘”ĶńĻ¶ń‹£¨”ŕ «ĺÕ∑Ę’Ļ≥ŲŃň“ĽłŲŃųŇ…ĺÕ « NoSQL żĺ›Ņ‚°£NoSQL ĶńŐōĶ„ĺÕ «∑Ň∆ķĶŰŃňłŖľ∂Ķń
SQL ń‹Ń¶£¨Ķę «”–Ķ√Īō”– ߣ¨ĽÚ’ŖňĶ∑Ň∆ķĶŰŃň∂ęőų◊‹ń‹ĽĽņī“Ľ–©∂ęőų£¨NoSQL ĽĽņīĶń «“ĽłŲ∂‘“ĶőŮÕł√ųĶń°Ę«ŅĶńňģ∆Ĺņ©’Ļń‹Ń¶£¨Ķę∑īĻżņīĺÕ“‚ő∂◊Ňń„Ķń“ĶőŮ‘≠ņī «Ľý”ŕ
SQL »•–īĶńĽį£¨Ņ…ń‹ĽŠīÝņīĪ»ĹŌīůĶńłń‘ž≥…Īĺ£¨īķĪŪĶńŌĶÕ≥”–ł’≤Ňő“ňĶĶĹĶń MongoDB°ĘCassandra°ĘHBase
Ķ»°£
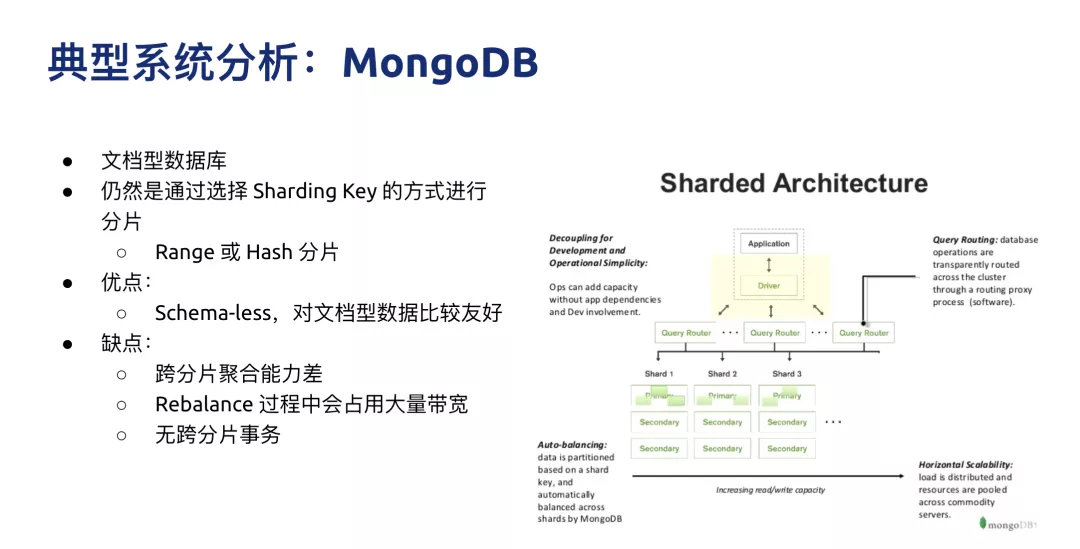
◊Ó”–√ŻĶńŌĶÕ≥ĺÕ « MongoDB£¨MongoDB ňš»Ľ“≤ «∑÷≤ľ Ĺ£¨Ķ껑»ĽĽĻ «ŌŮ∑÷Ņ‚∑÷ĪŪĶń∑Ĺįł“Ľ—ý£¨“™—°‘Ů∑÷∆¨Ķń
key£¨ňŻĶń”ŇĶ„īůľ“∂ľĪ»ĹŌ žŌ§£¨ĺÕ «√Ľ”–ĪŪĹŠĻĻ–ŇŌĘ£¨ŌŽ–ī ≤√īĺÕ–ī ≤√ī£¨∂‘”ŕőńĶĶ–ÕĶń żĺ›Ī»ĹŌ”—ļ√£¨Ķę»ĪĶ„“≤Ī»ĹŌ√ųŌ‘£¨ľ»»Ľ—°‘ŮŃň
Sharding Key£¨Ņ…ń‹ «įī’’“ĽłŲĻŐ∂®ĶńĻś‘Ú‘ŕ◊Ų∑÷∆¨£¨ňý“‘ĶĪ”–“Ľ–©ŅÁ∑÷∆¨ĶńĺŘļŌ–Ť«ůĶń ĪļÚĽŠĪ»ĹŌ¬ť∑≥£¨Ķŕ∂Ģ «‘ŕŅÁ∑÷∆¨Ķń
ACID ¬őŮ…Ō√Ľ”–ļ‹ļ√Ķń÷ß≥÷°£
HBase « Hadoop …ķŐ¨Ō¬ĶńĪ»ĹŌ”–√ŻĶń∑÷≤ľ Ĺ NoSQL żĺ›Ņ‚£¨ňŁ «ĻĻĹ®‘ŕ HDFS
÷ģ…ŌĶń“ĽłŲ NoSQL żĺ›Ņ‚°£Cassandra «“ĽłŲ∑÷≤ľ ĹĶń KV żĺ›Ņ‚£¨∆šŐōĶ„ «‘ŕ KV
≤Ŕ◊ų…ŌŐŠĻ©∂ŗ÷÷“Ľ÷¬–‘ń£–Õ£¨»ĪĶ„”Žļ‹∂ŗ NoSQL Ķńő Ő‚“Ľ—ý£¨įŁņ®‘ňő¨Ķńłī‘”–‘£¨ KV ĶńĹ”Ņŕ∂‘”ŕ‘≠”–“ĶőŮłń‘žĶń“™«ůĶ»°£
Ķ໿īķ∑÷≤ľ Ĺ żĺ›Ņ‚ NewSQL
ł’≤ŇňĶĻż Sharding ĽÚ’Ŗ∑÷Ņ‚∑÷ĪŪ£¨NoSQL “≤ļ√£¨∂ľ√śŃŔ◊Ň“ĽłŲ“ĶőŮĶń«÷»Ž–‘ő Ő‚£¨»ÁĻŻń„Ķń“ĶőŮ «÷ō∂»“ņņĶ
SQL£¨ń«√ī”√’‚ŃĹ÷÷∑Ĺįł∂ľ «ļ‹≤Ľ ś Ķń°£”ŕ «“Ľ–©ľľ űĪ»ĹŌ«į—ōĶńĻęňĺĺÕ‘ŕňľŅľ£¨ń‹≤Ľń‹ĹŠļŌīęÕ≥ żĺ›Ņ‚Ķń”ŇĶ„£¨Ī»»Á
SQL ĪŪīÔѶ£¨ ¬őŮ“Ľ÷¬–‘Ķ»Őō–‘£¨Õ¨ Ī”÷łķ NoSQL Īīķļ√Ķńņ©’Ļ–‘Ķ»Ļ¶ń‹ĹŠļŌ£¨◊Ó÷’∑Ę’Ļ≥Ų“Ľ÷÷–¬Ķń°ĘŅ…ņ©’Ļ≤Ę«“”√∆ūņī”÷ŌŮĶ•Ľķ żĺ›Ņ‚“Ľ—ý∑ĹĪ„ĶńŌĶÕ≥°£◊Ó÷’£¨‘ŕ’‚łŲňľ¬∑Ō¬ĺÕĶģ…ķ≥ŲŃňŃĹłŲŃųŇ…£¨“ĽłŲ «
Spanner£¨“ĽłŲ « Aurora£¨ŃĹłŲ∂ľ «∂•ľ∂ĶńĽ•Ń™ÕÝĻęňĺ‘ŕ√śŃŔĶĹ’‚÷÷ő Ő‚ Ī◊Ų≥ŲĶń“ĽłŲ—°‘Ů°£
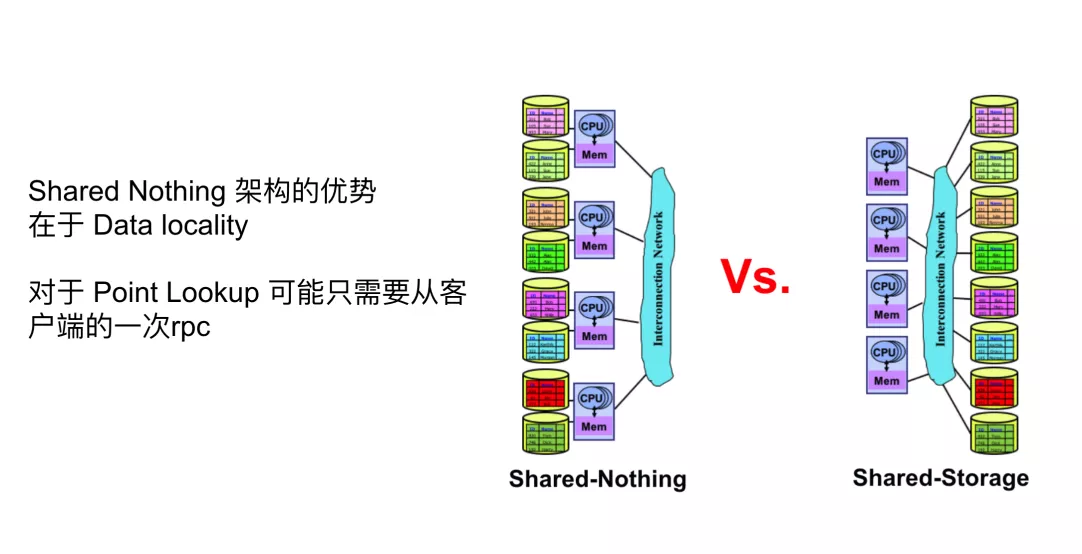
Shared Nothing ŃųŇ…
Shard Nothing ’‚łŲŃųŇ… «“‘ Google Spanner ő™īķĪŪ£¨ļ√ī¶ «‘ŕ”ŕŅ…“‘◊ŲĶĹľłļűőřŌřĶńňģ∆Ĺņ©’Ļ£¨’ŻłŲŌĶÕ≥√Ľ”–∂ňĶ„£¨≤ĽĻ‹ «
1 łŲ T°Ę10 łŲ T ĽÚ’Ŗ 100 łŲ T£¨“ĶőŮ≤„ĽýĪĺ…Ō≤Ľ”√Ķ£–ńņ©’Ļń‹Ń¶°£Ķŕ∂ĢłŲļ√ī¶ «ňŻĶń…Ťľ∆ńŅĪÍ «ŐŠĻ©«Ņ
SQL Ķń÷ß≥÷£¨≤Ľ–Ť“™÷ł∂®∑÷∆¨Ļś‘Ú°Ę∑÷∆¨≤Ŗ¬‘£¨ŌĶÕ≥ĽŠ◊‘∂ĮĶńįÔń„◊Ųņ©’Ļ°£Ķ໿ «÷ß≥÷ŌŮĶ•Ľķ żĺ›Ņ‚“Ľ—ýĶń«Ņ“Ľ÷¬Ķń ¬őŮ£¨Ņ…“‘”√ņī÷ß≥÷Ĺū»ŕľ∂ĪūĶń“ĶőŮ°£
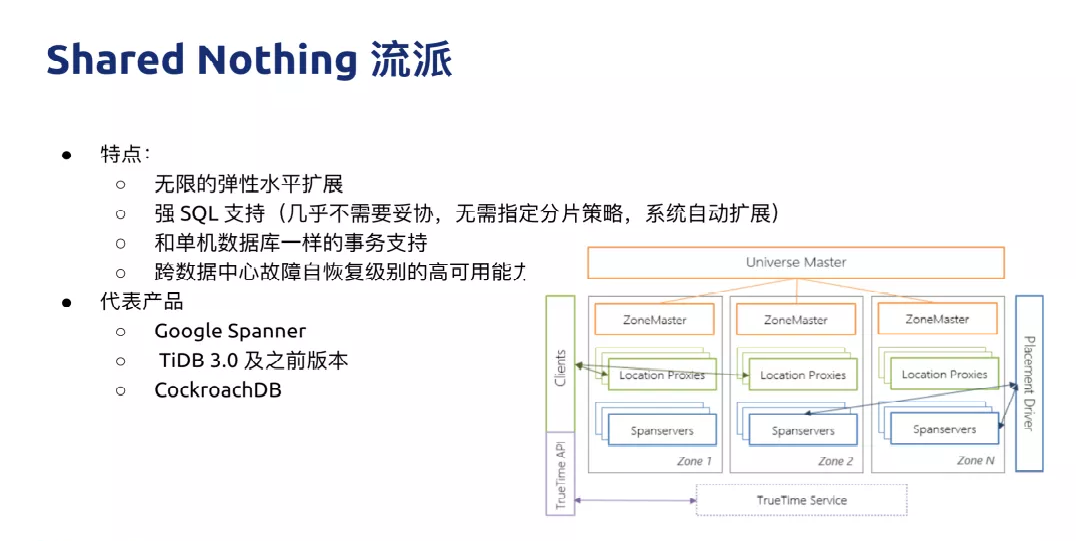
īķĪŪ≤ķ∆∑ĺÕ « Spanner ”Ž TiDB£¨’‚ņŗŌĶÕ≥“≤”–“Ľ–©»ĪĶ„£¨ī”Īĺ÷ …ŌņīňĶ“ĽłŲīŅ∑÷≤ľ Ĺ żĺ›Ņ‚£¨ļ‹∂ŗ––ő™√Ľ”–įž∑®łķĶ•Ľķ––ő™“Ľń£“Ľ—ý°£ĺŔłŲņż◊”£¨Ī»»ÁňĶ—”≥Ŕ£¨Ķ•Ľķ żĺ›Ņ‚‘ŕ◊ŲĹĽ“◊ ¬őŮĶń ĪļÚ£¨Ņ…ń‹‘ŕĶ•Ľķ…ŌĺÕÕÍ≥…Ńň£¨Ķę «‘ŕ∑÷≤ľ Ĺ żĺ›Ņ‚…Ō£¨»ÁĻŻ“™»• ĶŌ÷Õ¨—ýĶń“ĽłŲ”Ô“Ś£¨’‚łŲ ¬őŮ–Ť“™≤Ŕ◊ųĶń––Ņ…ń‹∑÷≤ľ‘ŕ≤ĽÕ¨ĶńĽķ∆ų…Ō£¨–Ť“™…śľįĶĹ∂ŗīőÕݬÁĶńÕ®–ŇļÕĹĽĽ•£¨Ōž”¶ňŔ∂»ļÕ–‘ń‹ŅŌ∂®≤Ľ»Á‘ŕĶ•Ľķ…Ō“Ľīő≤Ŕ◊ųÕÍ≥…£¨ňý“‘‘ŕ“Ľ–©ľś»›–‘ļÕ––ő™…Ō”ŽĶ•Ľķ żĺ›Ņ‚ĽĻ «”–“Ľ–©«ÝĪūĶń°£ľī Ļ «’‚—ý£¨∂‘”ŕļ‹∂ŗ“ĶőŮņīňĶ£¨”Ž∑÷Ņ‚∑÷ĪŪŌŗĪ»£¨∑÷≤ľ Ĺ żĺ›Ņ‚ĽĻ «ĺŖĪłļ‹∂ŗ”Ň ∆£¨Ī»»Á‘ŕ“◊”√–‘∑Ĺ√śĽĻ «Ī»∑÷Ņ‚∑÷ĪŪĶń«÷»Ž–‘–°ļ‹∂ŗ°£
Shared Everything ŃųŇ…
Ķŕ∂Ģ÷÷ŃųŇ…ĺÕ « Shared Everything ŃųŇ…£¨īķĪŪ”– AWS Aurora°ĘįĘņÔ‘∆Ķń PolarDB£¨ļ‹∂ŗ żĺ›Ņ‚∂ľ∂®“Ś◊‘ľļ «
Cloud-Native Database£¨Ķęő“ĺűĶ√’‚ņÔĶń Cloud-Native łŁ∂ŗ «‘ŕ”ŕÕ®≥£’‚–©∑Ĺįł∂ľ «”…Ļę”–‘∆∑ĢőŮ…ŐņīŐŠĻ©Ķń£¨÷Ń”ŕĪĺ…ŪĶńľľ ű «≤Ľ «‘∆‘≠…ķ£¨≤Ę√Ľ”–“ĽłŲÕ≥“ĽĶńĪÍ◊ľ°£ī”īŅľľ űĶńĹ«∂»ņī»•ňĶ“ĽłŲļň–ńĶń“™Ķ„£¨’‚ņŗŌĶÕ≥Ķńľ∆ň„”ŽīśīĘ «≥ĻĶ◊∑÷ņŽĶń£¨ľ∆ň„ĹŕĶ„”ŽīśīĘĹŕĶ„Ň‹‘ŕ≤ĽÕ¨Ľķ∆ų…Ō£¨īśīĘŌŗĶĪ”ŕį—“ĽłŲ
MySQL Ň‹‘ŕ‘∆ŇŐ…ŌĶńł–ĺű£¨ő“łŲ»ň»Ōő™ņŗň∆ Aurora ĽÚ’Ŗ PolarDB Ķń’‚÷÷ľ‹ĻĻ≤Ę≤Ľ «“ĽłŲīŅī‚Ķń∑÷≤ľ Ĺľ‹ĻĻ°£
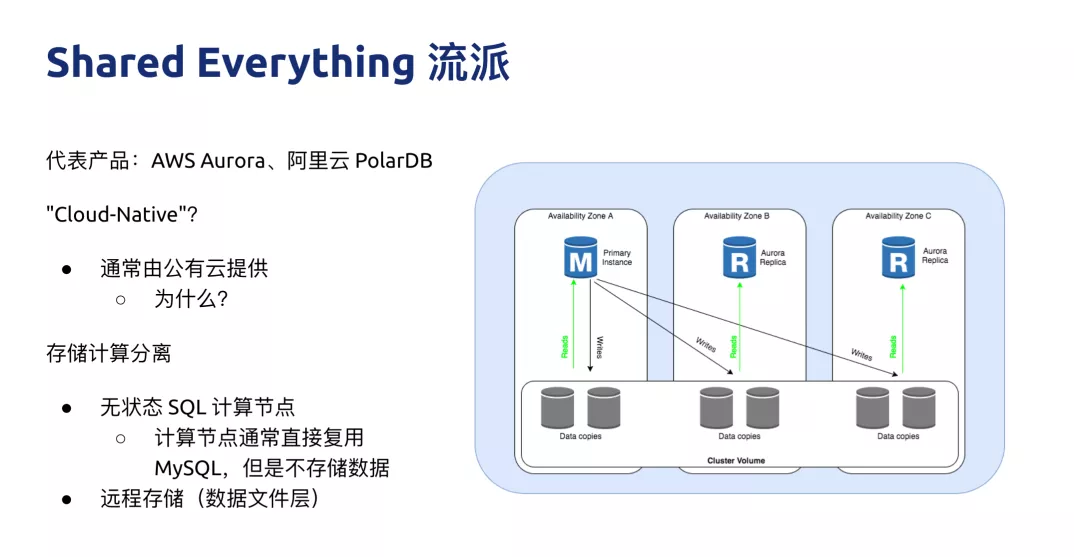
‘≠ņī MySQL Ķń÷ųī”łī÷∆∂ľ◊Ŗ Binlog£¨Aurora ◊ųő™“Ľ÷÷‘ŕ‘∆…Ō Share Everything
Database ĶńīķĪŪ£¨Aurora Ķń…Ťľ∆ňľ¬∑ «į—’ŻłŲ IO Ķń flow ÷ĽÕ®Ļż redo log
Ķń–ő Ĺņī◊Ųłī÷∆£¨∂Ý≤Ľ «Õ®Ļż’ŻłŲ IO Ńī¬∑īÚĶĹ◊Óļů Binlog£¨‘Ŕ∑ĘĶĹŃŪÕ‚“ĽŐ®Ľķ∆ų…Ō£¨»Ľļů‘Ŕ apply
’‚łŲ Binlog£¨ňý“‘ Aurora Ķń IO Ńī¬∑ľű…Ŕļ‹∂ŗ£¨’‚ «“ĽłŲļ‹īůĶńīī–¬°£
»’÷ĺłī÷∆ĶńĶ•őĽĪš–°£¨“‚ő∂◊Ňő“∑ĘĻż»•Ķń÷Ľ”– Physical log£¨≤Ľ « Binlog£¨“≤≤Ľ «÷ĪĹ”∑Ę”ÔĺšĻż»•£¨÷ĪĹ”∑ĘőÔņŪĶń»’÷ĺń‹īķĪŪ◊ŇłŁ–°Ķń
IO Ķń¬∑ĺ∂“‘ľįłŁ–°ĶńÕݬÁįŁ£¨ňý“‘’ŻłŲ żĺ›Ņ‚ŌĶÕ≥ĶńÕŐÕ¬–߬ ĽŠĪ»īęÕ≥Ķń MySQL Ķń≤Ņ ū∑Ĺįłļ√ļ‹∂ŗ°£
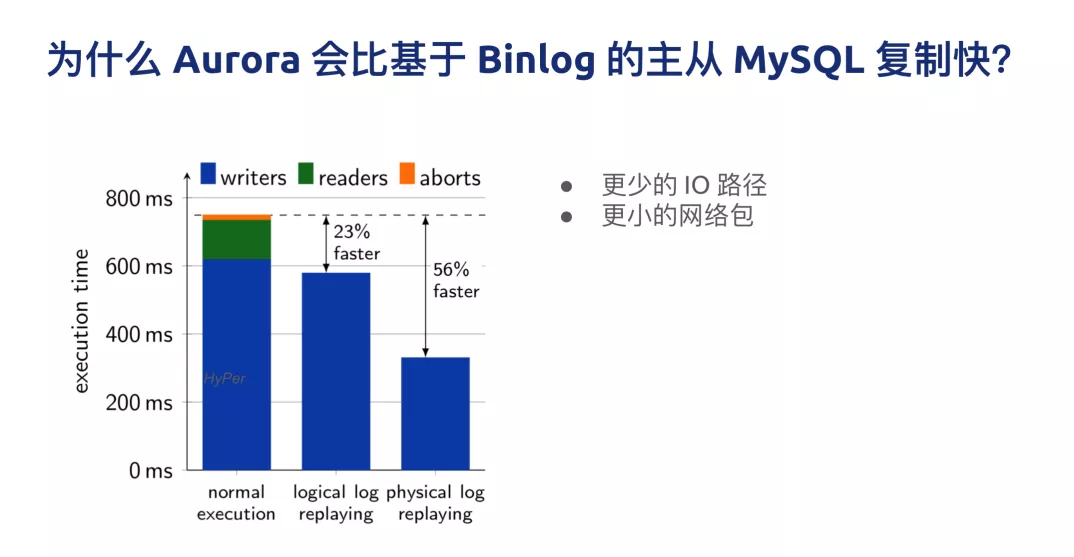
Aurora Ķń”Ň ∆ « 100% ľś»› MySQL£¨“ĶőŮľś»›–‘ļ√£¨“ĶőŮĽýĪĺ…Ō≤Ľ”√łńĺÕŅ…“‘”√£¨∂Ý«“∂‘”ŕ“Ľ–©Ľ•Ń™ÕÝĶń≥°ĺį£¨∂‘“Ľ÷¬–‘“™«ů≤ĽłŖĶńĽį£¨ żĺ›Ņ‚Ķń∂Ń“≤Ņ…“‘◊ŲĶĹňģ∆Ĺņ©’Ļ£¨≤ĽĻ‹ «
Aurora “≤ļ√£¨PolarDB “≤ļ√£¨∂Ń–‘ń‹ «”–…ŌŌřĶń°£
Aurora Ķń∂ŐįŚīůľ““≤ń‹ŅīĶ√≥Ųņī£¨Īĺ÷ …Ō’‚ĽĻ «“ĽłŲĶ•Ľķ żĺ›Ņ‚£¨“Úő™ňý”– żĺ›ŃŅ∂ľ «īśīĘ‘ŕ“Ľ∆ūĶń£¨Aurora
Ķńľ∆ň„≤„∆š ĶĺÕ «“ĽłŲ MySQL Ķņż£¨≤ĽĻō–ńĶ◊Ō¬’‚–© żĺ›Ķń∑÷≤ľ£¨»ÁĻŻ”–īůĶń–ī»ŽŃŅĽÚ’Ŗ”–īůĶńŅÁ∑÷∆¨≤ť—ĮĶń–Ť«ů£¨»ÁĻŻ“™÷ß≥÷īů żĺ›ŃŅ£¨ĽĻ «–Ť“™∑÷Ņ‚∑÷ĪŪ£¨ňý“‘
Aurora «“ĽŅÓłŁļ√Ķń‘∆…ŌĶ•Ľķ żĺ›Ņ‚°£
ĶŕňńīķŌĶÕ≥£ļ∑÷≤ľ Ĺ HTAP żĺ›Ņ‚
ĶŕňńīķŌĶÕ≥ĺÕ «–¬–őŐ¨Ķń HTAP żĺ›Ņ‚£¨”Ęőń√Ż≥∆ « Hybrid Transactional and
Analytical Processing£¨Õ®Ļż√Ż◊÷“≤ļ‹ļ√ņŪĹ‚£¨ľ»Ņ…“‘◊Ų ¬őŮ£¨”÷Ņ…“‘‘ŕÕ¨“ĽŐ◊ŌĶÕ≥ņÔ√ś◊Ų Ķ Ī∑÷őŲ°£HTAP
żĺ›Ņ‚Ķń”Ň ∆ «Ņ…“‘ŌŮ NoSQL “Ľ—ýĺŖĪłőřŌřňģ∆Ĺņ©’Ļń‹Ń¶£¨ŌŮ NewSQL “Ľ—ýń‹ĻĽ»•◊Ų SQL
Ķń≤ť—Į”Ž ¬őŮĶń÷ß≥÷£¨łŁ÷ō“™Ķń «‘༞ļŌ“ĶőŮĶ»łī‘”Ķń≥°ĺįŌ¬£¨OLAP ≤ĽĽŠ”įŌžĶĹ OLTP “ĶőŮ£¨Õ¨ Ī °»•Ńň‘ŕÕ¨“ĽłŲŌĶÕ≥ņÔ√śį— żĺ›įŠņīįŠ»•Ķń∑≥ń’°£ńŅ«į£¨ő“ŅīĶĹ‘ŕĻ§“ĶĹÁĽýĪĺ÷Ľ”–
TiDB 4.0 ľ”…Ō TiFlash ’‚łŲľ‹ĻĻń‹ĻĽ∑ŻļŌ…Ō Ų“™«ů°£
∑÷≤ľ Ĺ HTAP żĺ›Ņ‚£ļTiDB (with TiFlash)
ő™ ≤√ī TiDB ń‹ĻĽ ĶŌ÷ OLAP ļÕ OLTP Ķń≥ĻĶ◊łŰņŽ£¨Ľ•≤Ľ”įŌž£Ņ“Úő™ TiDB «ľ∆ň„ļÕīśīĘ∑÷ņŽĶńľ‹ĻĻ£¨Ķ◊≤„ĶńīśīĘ «∂ŗłĪĪĺĽķ÷∆£¨Ņ…“‘į—∆š÷–“Ľ–©łĪĪĺ◊™ĽĽ≥…Ń– ĹīśīĘĶńłĪĪĺ°£OLAP
Ķń«Ž«ůŅ…“‘÷ĪĹ”īÚĶĹŃ– ĹĶńłĪĪĺ…Ō£¨“≤ĺÕ « TiFlash ĶńłĪĪĺņīŐŠĻ©łŖ–‘ń‹Ń– ĹĶń∑÷őŲ∑ĢőŮ£¨◊ŲĶĹŃňÕ¨“Ľ∑› żĺ›ľ»Ņ…“‘◊Ų Ķ ĪĶńĹĽ“◊”÷◊Ų Ķ ĪĶń∑÷őŲ£¨’‚ «
TiDB ‘ŕľ‹ĻĻ≤„√śĶńĺřīůīī–¬ļÕÕĽ∆∆°£
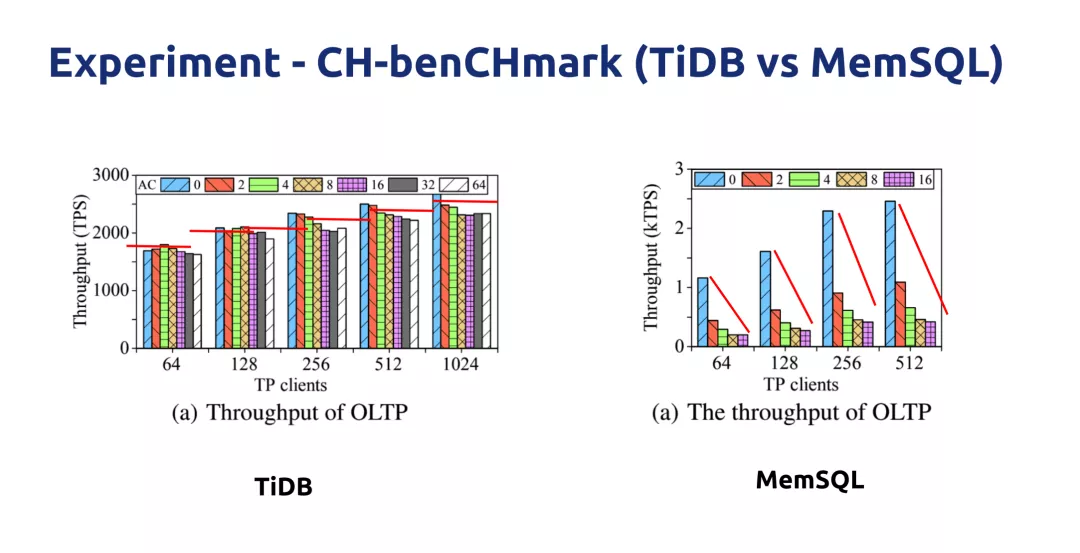
Ō¬Õľ « TiDB Ķń≤‚ ‘ĹŠĻŻ£¨”Ž MemSQL ĹÝ––Ńň∂‘Ī»£¨łýĺ›”√Ľß≥°ĺįĻĻ‘žŃň“Ľ÷÷ workload£¨ļŠ÷Š «≤Ę∑Ę ż£¨◊›÷Š «
OLTP Ķń–‘ń‹£¨ņ∂…ę°ĘĽ∆…ę°Ę¬Ő…ę’‚–© « OLAP Ķń≤Ę∑Ę ż°£’‚łŲ Ķ—ťĶńńŅĶńĺÕ «‘ŕ“ĽŐ◊ŌĶÕ≥…Ōľ»Ň‹ OLTP
”÷Ň‹ OLAP£¨Õ¨ Ī≤Ľ∂ŌŐŠ…ż OLTP ļÕ OLAP Ķń≤Ę∑Ę—ĻѶ£¨ī”∂Ý≤ťŅī’‚ŃĹ÷÷ workload
«∑ŮĽŠĽ•Ōŗ”įŌž°£Ņ…“‘ŅīĶĹ‘ŕ TiDB ’‚ĪŖ£¨Õ¨ Īľ”īů OLTP ļÕ OLAP Ķń≤Ę∑Ę—ĻѶ£¨’‚ŃĹ÷÷ workload
Ķń–‘ń‹ĪŪŌ÷√Ľ”– ≤√ī√ųŌ‘ĪšĽĮ£¨ľłļű «≤Ó≤Ľ∂ŗĶń°£Ķę «£¨Õ¨—ýĶń Ķ—ť∑Ę…ķ‘ŕ MemSQL …Ō£¨īůľ“Ņ…“‘ŅīĶĹ
MemSQL Ķń–‘ń‹īů∑ýň•ľű£¨ňś◊Ň OLAP Ķń≤Ę∑Ę żĪšīů£¨OLTP Ķń–‘ń‹Ō¬ĹĶĪ»ĹŌ√ųŌ‘°£
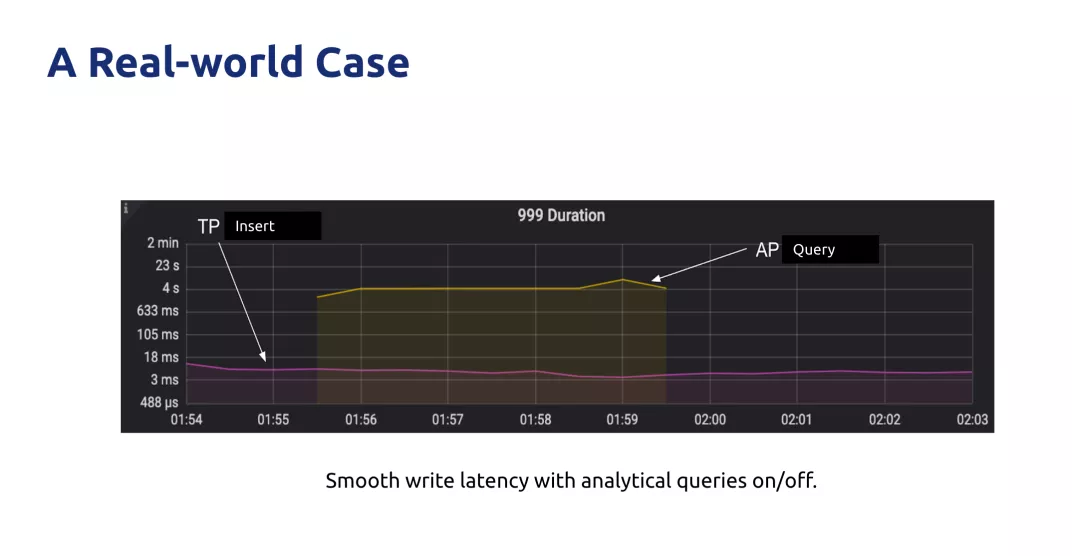
Ĺ”Ō¬ņī « TiDB ‘ŕ“ĽłŲ”√Ľß Ķľ “ĶőŮ≥°ĺįĶńņż◊”£¨‘ŕĹÝ–– OLAP “ĶőŮĶń≤ť—ĮĶń ĪļÚ£¨OLTP “ĶőŮ»‘»ĽŅ…“‘ ĶŌ÷∆ĹĽ¨Ķń–ī»Ž≤Ŕ◊ų£¨—”≥Ŕ“Ľ÷Īő¨≥÷‘ŕĹŌĶÕĶńňģ∆Ĺ°£
őīņī‘ŕńńņÔ
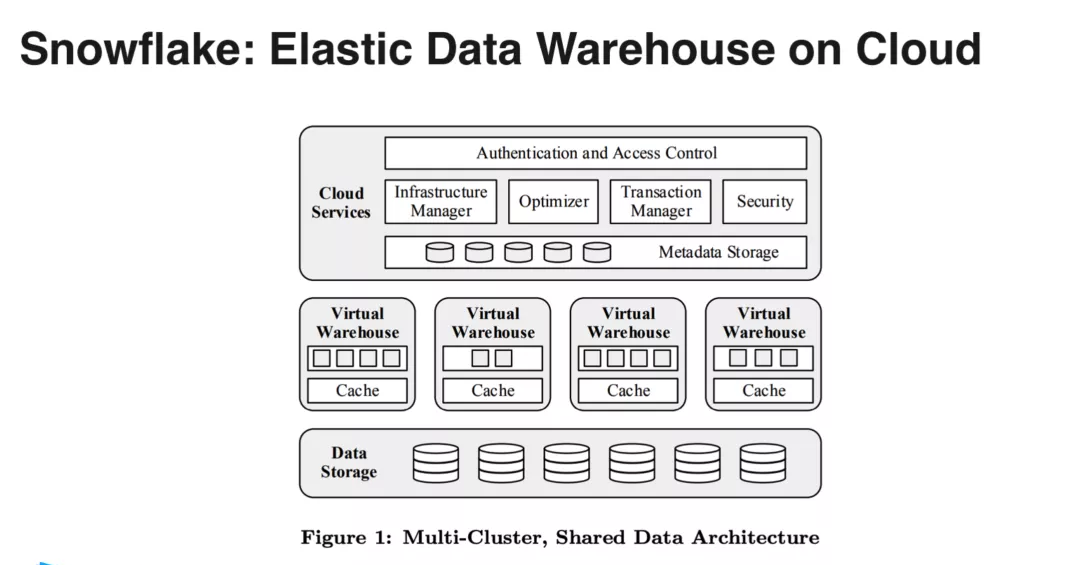
Snowflake
Snowflake «“ĽłŲ 100% ĻĻĹ®‘ŕ‘∆…ŌĶń żĺ›≤÷Ņ‚ŌĶÕ≥£¨Ķ◊≤„ĶńīśīĘ“ņņĶ S3£¨ĽýĪĺ…Ō√ŅłŲĻę”–‘∆∂ľĽŠŐŠĻ©ņŗň∆
S3 ’‚—ýĶń∂‘ŌůīśīĘ∑ĢőŮ£¨Snowflake “≤ «“ĽłŲīŅī‚Ķńľ∆ň„”ŽīśīĘ∑÷ņŽĶńľ‹ĻĻ£¨‘ŕŌĶÕ≥ņÔ√ś∂®“ŚĶńľ∆ň„ĹŕĶ„Ĺ–
Virtual Warehouse£¨Ņ…“‘»Ōő™ĺÕ «“ĽłŲłŲ EC2 Ķ•‘™£¨ĪĺĶōĶńĽļīś”–»’÷ĺŇŐ£¨Snowflake
Ķń÷ų“™ żĺ›īś‘ŕ S3 …Ō£¨ĪĺĶōĶńľ∆ň„ĹŕĶ„ «‘ŕĻę”–‘∆Ķń–ťĽķ…Ō°£
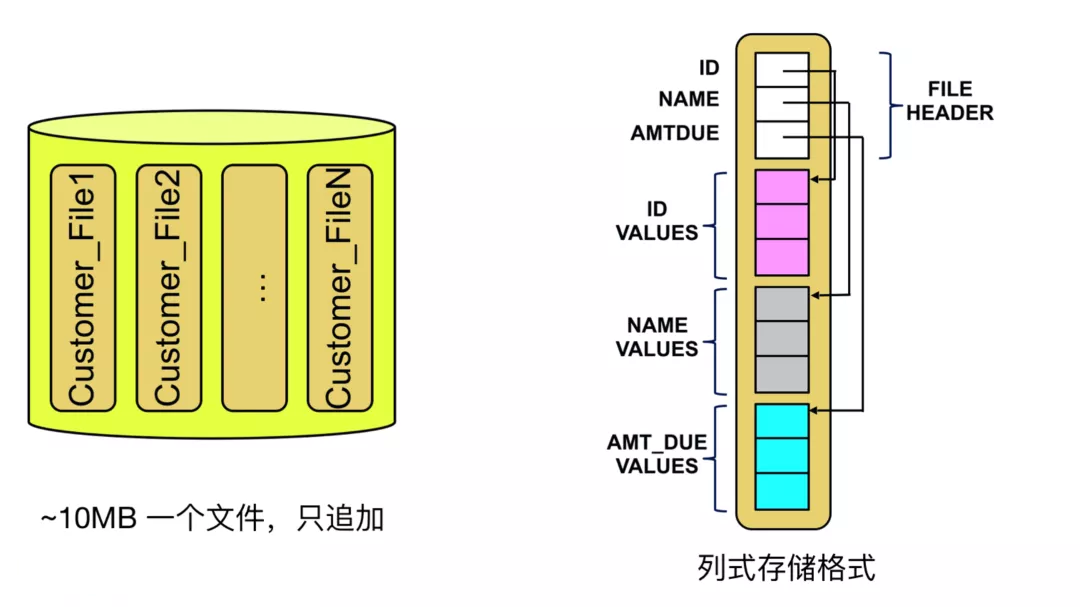
’‚ « Snowflake ‘ŕ S3 ņÔ√śīśīĘĶń żĺ›łŮ ĹĶńŐōĶ„£¨√Ņ“ĽłŲ S3 Ķń∂‘Ōů « 10 ’◊“ĽłŲőńľĢ£¨÷Ľ◊∑ľ”£¨√Ņ“ĽłŲőńľĢņÔ√śįŁļ¨‘ī–ŇŌĘ£¨Õ®ĻżŃ– ĹĶńīśīʬšĶĹīŇŇŐ…Ō°£
Snowflake ’‚łŲŌĶÕ≥◊Ó÷ō“™Ķń“ĽłŲ…ŃĻ‚Ķ„ĺÕ «∂‘”ŕÕ¨“Ľ∑› żĺ›Ņ…“‘∑÷Ňš≤ĽÕ¨Ķńľ∆ň„◊ ‘īĹÝ––ľ∆ň„£¨Ī»»Áń≥łŲ
query Ņ…ń‹÷Ľ–Ť“™ŃĹŐ®Ľķ∆ų£¨ŃŪÕ‚“ĽłŲ query –Ť“™łŁ∂ŗĶńľ∆ň„◊ ‘ī£¨Ķę «√ĽĻōŌĶ£¨ Ķľ …Ō’‚–© żĺ›∂ľ‘ŕ
S3 …Ō√ś£¨ľÚĶ•ņīňĶŃĹŐ®Ľķ∆ųŅ…“‘Ļ“‘ōÕ¨“ĽŅťīŇŇŐ∑÷Īū»•ī¶ņŪ≤ĽÕ¨ĶńĻ§◊ųłļ‘ō£¨’‚ĺÕ «“ĽłŲľ∆ň„”ŽīśīĘĹ‚ŮÓĶń÷ō“™ņż◊”°£
Google BigQuery
Ķŕ∂ĢłŲŌĶÕ≥ « BigQuery£¨BigQuery « Google Cloud …ŌŐŠĻ©Ķńīů żĺ›∑÷őŲ∑ĢőŮ£¨ľ‹ĻĻ…Ťľ∆…Ōłķ
Snowflake ”–Ķ„ņŗň∆°£BigQuery Ķń żĺ›īśīĘ‘ŕĻ»łŤńŕ≤ŅĶń∑÷≤ľ ĹőńľĢŌĶÕ≥ Colossus
…Ō√ś£¨Jupiter «ńŕ≤ŅĶń“ĽłŲłŖ–‘ń‹ÕݬÁ£¨…Ō√ś’‚łŲ «Ļ»łŤĶńľ∆ň„ĹŕĶ„°£
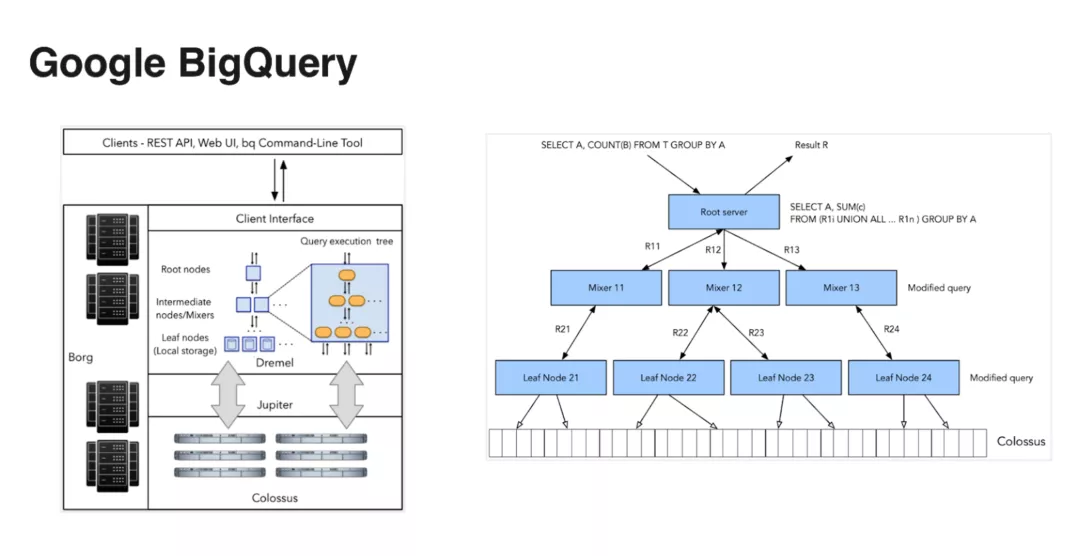
BigQuery Ķńī¶ņŪ–‘ń‹Ī»ĹŌ≥Ų…ę£¨√Ņ√Ž‘ŕ żĺ›÷––ńńŕĶń“ĽłŲňęŌÚĶńīÝŅŪŅ…“‘īÔĶĹ 1 PB£¨»ÁĻŻ Ļ”√
2000 łŲ◊® ŰĶńľ∆ň„ĹŕĶ„Ķ•‘™£¨īůłŇ“ĽłŲ‘¬Ķń∑—”√ «ňńÕÚ√ņĹū°£BigQuery «“ĽłŲįī–Ťł∂∑—Ķńń£ Ĺ£¨“ĽłŲ
query Ņ…ń‹ĺÕ”√ŃĹłŲ slot£¨ĺÕ ’»°’‚ŃĹłŲ slot Ķń∑—”√£¨BigQuery ĶńīśīĘ≥…ĪĺŌŗ∂‘ĹŌĶÕ£¨1
TB ĶńīśīĘīůłŇ 20 √ņĹū“ĽłŲ‘¬°£
RockSet
Ķ໿łŲŌĶÕ≥ « RockSet£¨īůľ“÷™Ķņ RocksDB «“ĽłŲĪ»ĹŌ”–√ŻĶńĶ•Ľķ KV żĺ›Ņ‚£¨∆šīśīĘ“ż«śĶń żĺ›ĹŠĻĻĹ–
LSM-Tree£¨LSM-Tree Ķńļň–ńňľŌŽĹÝ––∑÷≤„…Ťľ∆£¨łŁņšĶń żĺ›ĽŠ‘ŕ‘ĹŌ¬≤„°£RockSet į—ļů√śĶń≤„∑Ň‘ŕŃň
S3 ĶńīśīĘ…Ō√ś£¨…Ō√śĶń≤„∆š Ķ «”√ local disk ĽÚ’ŖĪĺĶōĶńńŕīśņī◊Ų“ż«ś£¨Őž»Ľ «“ĽłŲ∑÷≤„ĶńĹŠĻĻ£¨ń„Ķń”¶”√ł–÷™≤ĽĶĹŌ¬√ś «“ĽłŲ‘∆ŇŐĽĻ «ĪĺĶōīŇŇŐ£¨Õ®Ļżļ‹ļ√ĶńĪĺĶōĽļīś»√ń„ł–÷™≤ĽĶĹŌ¬√ś‘∆īśīĘĶńīś‘ŕ°£
ňý“‘ł’≤ŇŅīŃň’‚»żłŲŌĶÕ≥£¨ő“ĺűĶ√”–ľłłŲŐōĶ„£¨“ĽłŲ « ◊Ō»∂ľ «Őž»Ľ∑÷≤ľ ĹĶń£¨Ķŕ∂ĢłŲ «ĻĻĹ®‘ŕ‘∆ĶńĪÍ◊ľ∑ĢőŮ…Ō√śĶń£¨”»∆š «
S3 ļÕ EBS£¨Ķ໿ « pay as you go£¨‘ŕľ‹ĻĻņÔ√ś≥š∑÷ņŻ”√Ńň‘∆ĶńĶĮ–‘ń‹Ń¶°£ő“ĺűĶ√’‚»żĶ„◊Ó÷ō“™Ķń“ĽĶ„ «īśīĘ£¨īśīĘŌĶÕ≥ĺŲ∂®Ńň‘∆…Ō żĺ›Ņ‚Ķń…Ťľ∆∑ĹŌÚ°£
ő™ ≤√ī S3 «ĻōľŁ£Ņ
‘ŕīśīĘņÔĪŖő“ĺűĶ√łŁĻōľŁĶńŅ…ń‹ « S3°£EBS ∆š Ķő“√«“≤”–—–ĺŅĻż£¨TiDB Ķŕ“ĽĹ◊∂ő∆š Ķ“—ĺ≠’ż‘ŕłķ
EBS ŅťīśīĘ◊Ų»ŕļŌ£¨Ķęī”łŁ≥§‘∂ĶńĹ«∂»ņīŅī£¨ő“ĺűĶ√łŁ”–“‚ňľĶń∑ĹŌÚ «‘ŕ S3 ’‚ĪŖ°£
◊Ō»Ķŕ“ĽĶ„ S3 ∑«≥£Ľģň„£¨ľŘłŮ‘∂ĶÕ”ŕ EBS£¨Ķŕ∂Ģ S3 ŐŠĻ©Ńň 9 łŲ 9 ļ‹łŖĶńŅ…ŅŅ–‘£¨Ķ໿ «ĺŖĪłŌŖ–‘ņ©’ĻĶńÕŐÕ¬ń‹Ń¶£¨Ķŕňń «Őž»ĽŅÁ‘∆£¨√Ņ“ĽłŲ‘∆…Ō∂ľ”–
S3 API Ķń∂‘ŌůīśīĘ∑ĢőŮ°£Ķę « S3 Ķńő Ő‚ĺÕ «ňśĽķ–ī»ŽĶń—”≥Ŕ∑«≥£łŖ£¨Ķę «ÕŐÕ¬–‘ń‹≤ĽīŪ£¨ňý“‘ő“√«“™»•ņŻ”√’‚łŲÕŐÕ¬–‘ń‹≤ĽīŪĶń’‚łŲŐōĶ„£¨ĻśĪ‹—”≥ŔłŖĶń∑ÁŌ’°£’‚ «
S3 benchmark Ķń“ĽłŲ≤‚ ‘£¨Ņ…“‘ŅīĶĹňś◊ŇĽķ–ÕĶńŐŠ…ż£¨ÕŐÕ¬ń‹Ń¶“≤ «≥÷–ÝĶńŐŠ…ż°£
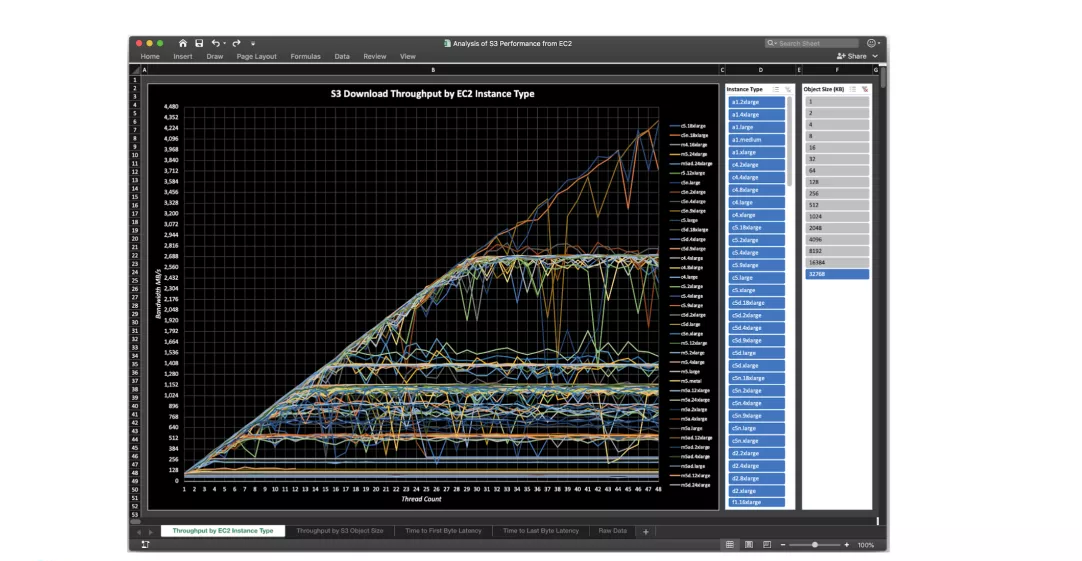
»ÁļőĹ‚ĺŲ Latency Ķńő Ő‚£Ņ
»ÁĻŻ“™Ĺ‚ĺŲ S3 Ķń Latency ő Ő‚£¨’‚ņÔŐŠĻ©“Ľ–©ňľ¬∑£¨Ī»»ÁŌŮ RockSet ń«—ý”√ SSD
ĽÚ’ŖĪĺĶōīŇŇŐņī◊Ų cache£¨ĽÚ’ŖÕ®Ļż kinesis –ī»Ž»’÷ĺ£¨ņīĹĶĶÕ’ŻłŲ–ī»ŽĶń—”≥Ŕ°£ĽĻ”– żĺ›Ķńłī÷∆ĽÚ’Ŗń„“™»•◊Ų“Ľ–©≤Ę∑Ęī¶ņŪĶ»£¨∆š ĶŅ…“‘»•◊Ų
Zero-copy data cloning£¨“≤ «ĹĶĶÕ—”≥ŔĶń“Ľ–©∑Ĺ Ĺ°£
…Ō Ųņż◊””–“Ľ–©Ļ≤Õ¨Ķ„∂ľ « żĺ›≤÷Ņ‚£¨≤Ľ÷™Ķņīůľ“”–√Ľ”–∑ĘŌ÷£¨ő™ ≤√ī∂ľ « żĺ›≤÷Ņ‚£Ņ żĺ›≤÷Ņ‚∂‘”ŕÕŐÕ¬Ķń“™«ů∆š Ķ «łŁłŖĶń£¨∂‘”ŕ—”≥Ŕ≤Ę≤Ľ «ń«√ī‘ŕ“‚£¨“ĽłŲ
query Ņ…ń‹Ň‹őŚ√Ž≥ŲĹŠĻŻĺÕ––Ńň£¨≤Ľ”√“™«ůőŚļŃ√Ž÷ģńŕłÝ≥ŲĹŠĻŻ£¨ŐōĪū «∂‘”ŕ“Ľ–© Point Lookup
’‚÷÷≥°ĺįņīňĶ£¨Shared Nothing Ķń database Ņ…ń‹÷Ľ–Ť“™ī”ŅÕĽß∂ňĶń“Ľīő rpc£¨Ķę «∂‘”ŕľ∆ň„”ŽīśīĘ∑÷ņŽĶńľ‹ĻĻ£¨÷–ľšőř¬Ř»Áļő“™◊ŖŃĹīőÕݬÁ£¨’‚ «“ĽłŲļň–ńĶńő Ő‚°£
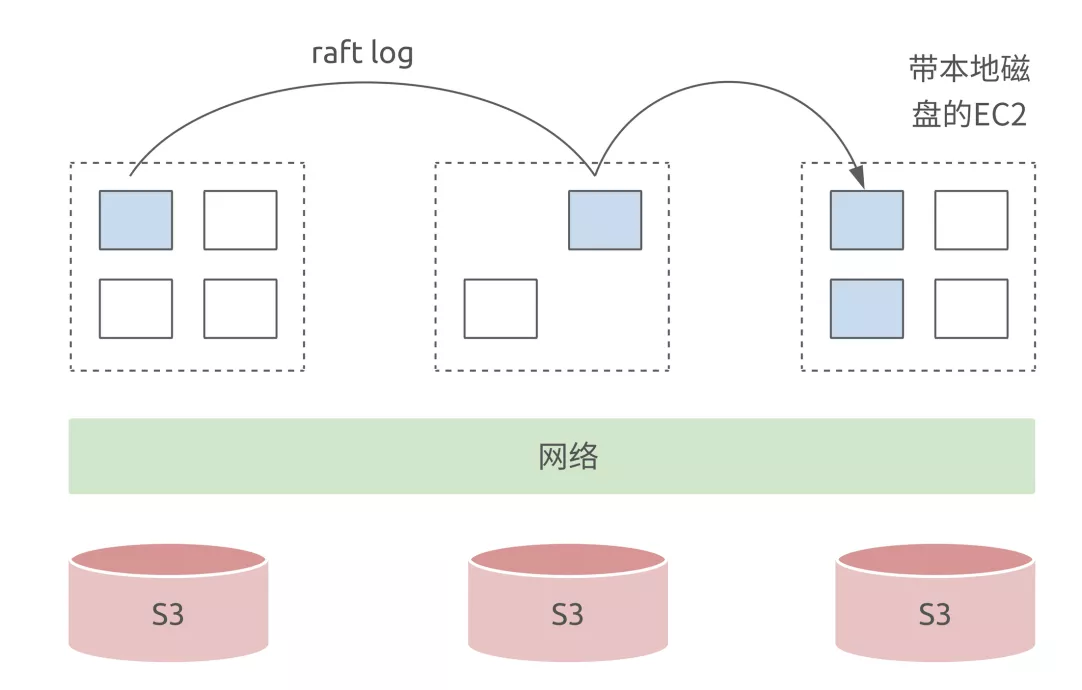
ń„Ņ…ń‹ĽŠňĶ√Ľ”–ĻōŌĶ£¨∑ī’żľ∆ň„ļÕīśīĘ“—ĺ≠∑÷ņŽŃň£¨īůѶ≥Ų∆śľ££¨Ņ…“‘ľ”ľ∆ň„ĹŕĶ„°£Ķę «ő“ĺűĶ√–¬ňľ¬∑√ĽĪō“™’‚√īľę∂ň£¨Aurora
«“ĽłŲľ∆ň„īśīĘ∑÷ņŽľ‹ĻĻ£¨ĶęňŁ «“ĽłŲĶ•Ľķ żĺ›Ņ‚£¨Spanner «“ĽłŲīŅ∑÷≤ľ ĹĶń żĺ›Ņ‚£¨īŅ Shared
Nothing Ķńľ‹ĻĻ≤Ę√Ľ”–ņŻ”√ĶĹ‘∆Ľýī°…Ť ©ŐŠĻ©Ķń“Ľ–©”Ň ∆°£
Ī»»ÁňĶőīņīő“√«Ķń żĺ›Ņ‚Ņ…“‘◊Ų’‚—ýĶń…Ťľ∆£¨‘ŕľ∆ň„≤„∆š ĶīÝ◊Ň“ĽĶ„Ķ„◊īŐ¨£¨“Úő™√ŅŐ® EC2 ∂ľĽŠīÝ“ĽłŲĪĺĶōīŇŇŐ£¨Ō÷‘ŕ÷ųŃųĶń
EC2 ∂ľ « SSD£¨Ī»ĹŌ»»Ķń żĺ›Ņ…“‘‘ŕ’‚“Ľ≤„◊Ų Shared Nothing£¨‘ŕ’‚“Ľ≤„»•◊ŲłŖŅ…”√£¨‘ŕ’‚“Ľ≤„»•◊ŲňśĽķĶń∂Ń»°”Ž–ī»Ž°£»» żĺ›“ĽĶ©
cache miss£¨≤ŇĽŠ¬šĶĹ S3 …Ō√ś£¨Ņ…“‘‘ŕ S3 ÷Ľ◊Ųļů√śľł≤„Ķń żĺ›īśīĘ£¨’‚÷÷◊Ų∑®Ņ…ń‹ĽŠīÝņīő Ő‚£¨“ĽĶ©ī©ÕłŃňĪĺĶō
cache£¨Latency ĽŠ”–“Ľ–©∂∂∂Į°£
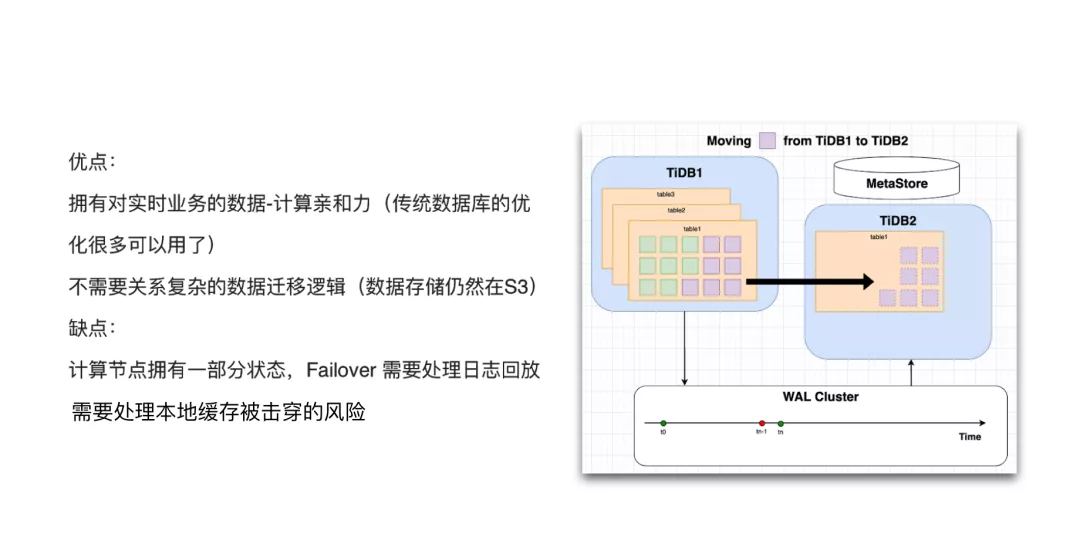
’‚÷÷ľ‹ĻĻ…Ťľ∆Ķńļ√ī¶£ļ ◊Ō»£¨”Ķ”–∂‘ Ķ Ī“ĶőŮĶń żĺ›ľ∆ň„«◊ļÕѶ£¨‘ŕ local disk …ŌĽŠ”–ļ‹∂ŗ żĺ›£¨‘ŕ’‚Ķ„…Ōļ‹∂ŗīęÕ≥ żĺ›Ņ‚Ķń“Ľ–©–‘ń‹”ŇĽĮľľ«…Ņ…“‘”√∆ūņī£ĽĶŕ∂Ģ£¨ żĺ›«®“∆∆š ĶĽŠĪšĶ√ļ‹ľÚĶ•£¨ Ķľ …ŌĶ◊Ō¬ĶńīśīĘ «Ļ≤ŌŪĶń£¨∂ľ‘ŕ
S3 …Ō√ś£¨Ī»»ÁňĶ A Ľķ∆ųĶĹ B Ľķ∆ųĶń żĺ›«®“∆∆š Ķ≤Ľ”√’śĶń◊Ų«®“∆£¨÷Ľ“™‘ŕ B Ľķ∆ų…Ō∂Ń»° żĺ›ĺÕ––Ńň°£
’‚łŲľ‹ĻĻĶń»ĪĶ„ «£ļĶŕ“Ľ£¨Ľļīśī©ÕłŃň“‘ļů£¨Latency ĽŠĪšłŖ£ĽĶŕ∂Ģ£¨ľ∆ň„ĹŕĶ„Ō÷‘ŕ”–Ńň◊īŐ¨£¨»ÁĻŻľ∆ň„ĹŕĶ„Ļ“ĶŰŃň“‘ļů£¨Failover
“™»•ī¶ņŪ»’÷ĺĽō∑ŇĶńő Ő‚£¨’‚Ņ…ń‹ĽŠ‘Ųľ”“ĽĶ„ ĶŌ÷Ķńłī‘”∂»°£
ĽĻ”–ļ‹∂ŗ÷ĶĶ√—–ĺŅĶńŅőŐ‚
…Ō√śĶńľ‹ĻĻ÷Ľ «“ĽłŲ…ŤŌŽ£¨TiDB ∆š ĶĽĻ≤Ľ «’‚—ýĶńľ‹ĻĻ£¨ĶęőīņīŅ…ń‹ĽŠ‘ŕ’‚∑ĹŌÚ»•◊Ų“Ľ–©≥Ę ‘ĽÚ’Ŗ—–ĺŅ£¨‘ŕ’‚łŲŃž”ÚņÔ√ś∆š ĶĽĻ”–ļ‹∂ŗ
open question ő“√«ĽĻ√Ľ”–īūįł£¨įŁņ®‘∆≥ß…Ő°ĘįŁņ®ő“√«£¨įŁņ®—ß űĹÁ∂ľ√Ľ”–īūįł°£
Ō÷‘ŕ”–“Ľ–©—–ĺŅĶńŅőŐ‚£¨Ķŕ“Ľ£¨»ÁĻŻő“√«“™ņŻ”√ĪĺĶōīŇŇŐ£¨”¶ł√Ľļīś∂ŗ…Ŕ żĺ›£¨LRU Ķń≤Ŗ¬‘ « ≤√ī—ý◊”£¨łķ
performance ĶĹĶ◊”– ≤√īĻōŌĶ£¨łķ workload ”– ≤√īĻōŌĶ°£Ķŕ∂Ģ£¨∂‘”ŕÕݬÁ£¨ł’≤Ňő“√«ŅīĶĹ
S3 ĶńÕݬÁÕŐÕ¬◊ŲĶńļ‹ļ√£¨ ≤√ī—ýĶń–‘ń‹“™Ňš…Ō ≤√ī—ýĶńÕŐÕ¬£¨“™Ňš∂ŗ…ŔłŲľ∆ň„ĹŕĶ„£¨ŐōĪū «∂‘”ŕ“Ľ–©Ī»ĹŌłī‘”≤ť—ĮĶń
Reshuffle£ĽĶ໿£¨ľ∆ň„łī‘”∂»ļÕľ∆ň„ĹŕĶ„°ĘĽķ–ÕĶńĻōŌĶ « ≤√ī£Ņ’‚–©ő Ő‚∆š Ķ∂ľ «Ī»ĹŌłī‘”Ķńő Ő‚£¨ŐōĪū «‘ű√ī”√ ż—ßņīĪŪīÔ£¨“Úő™–Ť“™◊‘∂ĮĽĮĶō»•◊Ų’‚–© ¬«ť°£
ľī Ļ’‚–©ő Ő‚∂ľĹ‚ĺŲŃň£¨ő“ĺűĶ√“≤÷Ľ «‘∆…Ō żĺ›Ņ‚ ĪīķĶń“ĽłŲŅ™ ľ°£őīņī‘ŕ Serverless£¨įŁņ® AI-Driven
ľłīů∑ĹŌÚ…Ō£¨‘ű√ī…Ťľ∆≥ŲłŁļ√Ķń database£¨’‚ «ő“√«Ň¨Ń¶Ķń∑ĹŌÚ°£◊Óļů“ż”√«Ł‘≠Ķń“ĽĺšĽį£¨ĺÕ «¬∑¬Ģ¬Ģ∆š–ř‘∂Ŕ‚£¨ő“√«ĽĻ”–ļ‹∂ŗ ¬«ť–Ť“™»•◊Ų£¨–Ľ–Ľīůľ“°£
| 








