| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫЪБађЪ§ОнДцДЂЬєеНЁЂ
Lindorm TSDB БГКѓЕФММЪѕЫМПМЁЂ Lindorm TSDB ЙиМќММЪѕМАЪБађДцДЂНтОіЗНАИ
ЁЃ
БОЮФРДздЮЂаХЙЋжкКХАЂРяММЪѕЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
ЫцзХ IoT ММЪѕЕФПьЫйЗЂеЙЃЌЮяСЊЭјЩшБИВњЩњЕФЪ§ОнГЪБЌеЈЪНдіГЄЃЌЪ§ОнЕФзмСПЃЈVolumeЃЉЁЂЪ§ОнРраЭдНРДдНЖрЃЈVarietyЃЉЁЂЗУЮЪЫйЖШвЊЧѓдНРДдНПьЃЈVelocityЃЉЁЂЖдЪ§ОнМлжЕЃЈValueЃЉЕФЭкОђдНРДдНжиЪгЁЃЮяСЊЭјВњЩњЕФЪ§ОнЭЈГЃЖМОпБИЪБМфађСаЬиеїЃЌЪБађЪ§ОнПтЪЧЕБЧАеыЖдЮяСЊЭј
IoTЁЂЙЄвЕЛЅСЊЭј IIoTЁЂгІгУадФмМрПи APM ГЁОАЕШДЙжБСьгђЖЈжЦЕФЪ§ОнПтНтОіЗНАИЃЌБОЮФжївЊЗжЮіЮяСЊЭјГЁОАКЃСПЪБађЪ§ОнДцДЂгыДІРэЕФЙиМќММЪѕЬєеНМАНтОіЗНАИЁЃ
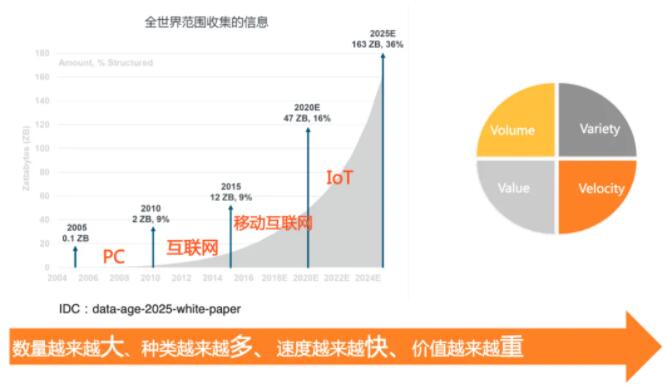
вЛ ЪБађЪ§ОнДцДЂЬєеН
1 ЕфаЭЪБађгІгУГЁОА
ЫцзХ 5G/IoT ММЪѕЕФЗЂеЙЃЌЪ§ОнГЪБЌеЈЪНдіГЄЃЌЦфжаЮяСЊЭј (IoT) гыгІгУадФмМрПи (APM)
ЕШЪЧЪБађЪ§ОнзюЕфаЭЕФгІгУСьгђЃЌИВИЧЮяСЊЭјЁЂГЕСЊЭјЁЂжЧФмМвОгЁЂЙЄвЕЛЅСЊЭјЁЂгІгУадФмМрПиЕШГЃМћЕФгІгУГЁОАЃЌКЃСПЕФЩшБИГжајВњЩњдЫааЪБжИБъЪ§ОнЃЌЖдЪ§ОнЕФЖСаДЁЂДцДЂЙмРэЖМЬсГіСЫКмДѓЕФЬєеНЁЃ

2 ЪБађЪ§ОнЕФЬиеї
дкЕфаЭЕФЮяСЊЭјЁЂAPM ЪБађЪ§ОнГЁОАРяЃЌЪ§ОнЕФВњЩњЁЂЗУЮЪЖМгаБШНЯУїЯдЕФЙцТЩЃЌгаКмЖрЙВЭЌЕФЬиеїЃЌЯрБШЕБЧАЛЅСЊЭјЕфаЭЕФгІгУЬиеїгаБШНЯДѓЕФЧјБ№ЁЃ
Ъ§ОнАДЪБМфЫГађВњЩњЃЌвЛЖЈДјгаЪБМфДСЃЌКЃСПЕФЮяСЊЭјЩшБИЛђепБЛМрПиЕНгІгУГЬађЃЌАДЙЬЖЈЕФжмЦкЛђЬиЖЈЬѕМўДЅЗЂЃЌГжајВЛЖЯЕФВњЩњаТЕФЪБађЪ§ОнЁЃ
Ъ§ОнЪЧЯрЖдНсЙЙЛЏЕФЃЌвЛИіЩшБИЛђгІгУЃЌВњЩњЕФжИБъвЛАувдЪ§жЕРраЭЃЈОјДѓВПЗжЃЉЁЂзжЗћРраЭЮЊжїЃЌВЂЧвдкдЫааЙ§ГЬжаЃЌжИБъЕФЪ§СПЯрЖдЙЬЖЈЃЌжЛгаФЃаЭБфИќЁЂвЕЮёЩ§МЖЪБВХЛсаТді/МѕЩй/БфИќжИБъЁЃ
аДЖрЖСЩйЃЌМЋЩйгаИќаТВйзїЃЌЮоашЪТЮёФмСІжЇГжЃЌдкЛЅСЊЭјгІгУГЁОАРяЃЌЪ§ОнаДШыКѓЃЌЭљЭљЛсБЛЖрДЮЗУЮЪЃЌБШШчЕфаЭЕФЩчНЛЁЂЕчЩЬГЁОАЖМЪЧШчДЫЃЛЖјдкЮяСЊЭјЁЂAPM
ГЁОАЃЌЪ§ОнВњЩњДцДЂКѓЃЌЭљЭљдкашвЊзіЪ§ОндЫгЊЗжЮіЁЂМрПиБЈБэЁЂЮЪЬтХХВщЪБВХЛсШЅЖСШЁЗУЮЪЁЃ
АДЪБМфЖЮХњСПЗУЮЪЪ§ОнЃЌгУЛЇжївЊЙизЂЭЌвЛИіЛђЭЌвЛРрРрЩшБИдквЛЖЮЪБМфФкЕФЗУЮЪЧїЪЦЃЌБШШчФГИіжЧФмПеЕїдкЙ§ШЅ1аЁЪБЕФЦНОљЮТЖШЃЌФГИіМЏШКЫљгаЪЕР§змЕФЗУЮЪ
QPS ЕШЃЌашвЊжЇГжЖдСЌајЕФЪБМфЖЮЪ§ОнНјааГЃгУЕФМЦЫуЃЌБШШчЧѓКЭЁЂМЦЪ§ЁЂзюДѓжЕЁЂзюаЁжЕЁЂЦНОљжЕЕШЦфЫћЪ§бЇКЏЪ§МЦЫуЁЃ
НќЦкЪ§ОнЕФЗУЮЪдЖИпгкРњЪЗЪ§ОнЃЌЗУЮЪЙцТЩУїЯдЃЌРњЪЗЪ§ОнЕФМлжЕЫцЪБМфВЛЖЯНЕЕЭЃЌЮЊНкЪЁГЩБОЃЌЭЈГЃжЛашвЊБЃДцзюНќвЛЖЮЪБМфШчШ§ИідТЁЂАыФъЕФЪ§ОнЃЌашвЊжЇГжИпаЇЕФЪ§Он
TTL ЛњжЦЃЌФмздЖЏХњСПЩОçМЪЗЪ§ОнЃЌзюаЁЛЏЖде§ГЃаДШыЕФгАЯьЁЃ
Ъ§ОнДцДЂСПДѓЃЌРфШШЬиеїУїЯдЃЌвђДЫЖдДцДЂГЩБОвЊЧѓБШНЯИпЃЌашвЊгаеыЖдадЕФДцДЂНтОіЗНАИЁЃ
НсКЯЪБађЕФЬиеїЃЌвЊТњзуДѓЙцФЃЪБађЪ§ОнДцДЂашЧѓЃЌжСЩйУцСйШчЯТЕФМИИіКЫаФЬєеНЃК
ИпВЂЗЂЕФаДШыЭЬЭТЃКдквЛаЉДѓЙцФЃЕФгІгУадФмМрПиЁЂЮяСЊЭјГЁОАЃЌКЃСПЕФЩшБИГжајВњЩњЪБађЪ§ОнЃЌР§ШчФГЪЁгђЕчЭјгУЕчВтСПЪ§ОнЃЌ9000ЭђЕФЕчБэЩшБИЃЌдРДУПИідТВЩМЏвЛДЮЃЌКѓајвЕЮёЩ§МЖКѓ15ЗжжгВЩМЏвЛДЮЃЌУПУыЕФЪБађЪ§ОнЕуЪ§ДяЕНЪ§АйЭђЩѕжСЧЇЭђЪБМфЕуЃЌашвЊЪ§ЪЎЕНЩЯАйЬЈЛњЦїЕФМЏШКЙцФЃРДжЇГХШЋСПЕФвЕЮёаДШыЃЛЪБађЪ§ОнДцДЂашвЊНтОіДѓЙцФЃМЏШКЕФКсЯђРЉеЙЃЌИпадФмЦНЮШаДШыЕФашЧѓЁЃ
ИпаЇЕФЪБађЪ§ОнВщбЏЗжЮіЃКдкЕфаЭЕФМрПиГЁОАЃЌЭЈГЃашвЊЖдГЄжмЦкЕФЪ§ОнНјааВщбЏЗжЮіЃЌБШШчеыЖдФГаЉжИБъзюНќ1ЬьЁЂ3ЬьЁЂ7ЬьЁЂ1ИідТЕФЧїЪЦЗжЮіЁЂБЈБэЕШЃЛЖјдкЮяСЊЭјГЁОАЃЌгавЛРрБШНЯЕфаЭЕФЖЯУцВщбЏашЧѓЃЌР§ШчВщбЏФГИіЪЁжИЖЈЪБМфЫљгаЕчБэЕФгУЕчСПСПУїЯИЪ§ОнЃЌВщбЏФГИіЦЗХЦПеЕїЕФФГИіЪБМфЕФЦНОљдЫааЮТЖШЃЛетаЉВщбЏЖМашвЊЩЈУшДѓСПЕФМЏШКЪ§ОнВХФмФУЕННсЙћЃЌЭЌЪБВщбЏЕФНсЙћМЏвВПЩФмЗЧГЃДѓЃЛЪБађЪ§ОнДцДЂашвЊжЇГжЖрЮЌЪБМфЯпМьЫїЁЂВЂОпБИСїЪНДІРэЁЂдЄМЦЫуЕШФмСІЃЌВХФмТњзуДѓЙцФЃ
APMЁЂIoT вЕЮёГЁОАЕФЕфаЭВщбЏашЧѓЃЌВЂЧвеыЖдЪБађДѓВщбЏвЊзюаЁЛЏЖдаДШыЕФгАЯьЁЃ
ЕЭГЩБОЕФЪБађЪ§ОнДцДЂЃКФГЕфаЭЕФГЕСЊЭјГЁОАЃЌНі20000СОГЕУПаЁЪБОЭВњЩњНќАйGBЕФГЕСОжИБъЪ§ОнЃЌШчЙћвЊБЃДцвЛФъЕФдЫааЪ§ОнОЭашвЊPBМЖЕФЪ§ОнДцДЂЙцФЃЃЛгЩгкЪ§ОнЙцФЃОоДѓЃЌЖдДцДЂЕФЕЭГЩБОвЊЧѓКмИпЃЌСэЭтЪБађЪ§ОнЕФРфШШЬиеїУїЯдЁЃЪБађЪ§ОнДцДЂашвЊГфЗжРћгУКУЪБађЪ§ОнСПДѓЁЂРфШШЗУЮЪЬиеїУїЯдЁЂзіКУМЦЫуЁЂДцДЂзЪдДЕФНтёюЃЌЭЈЙ§ЕЭГЩБОДцДЂНщжЪЁЂбЙЫѕБрТыЁЂРфШШЗжРыЁЂИпаЇ
TTLЁЂServereless ЕШММЪѕНЋЪ§ОнДцДЂГЩБОНЕЕЭЕНМЋжТЁЃ
МђЕЅБуНнЕФЩњЬЌаЭЌЃКдкЮяСЊЭјЁЂЙЄвЕЛЅСЊЭјЕШГЁОАЃЌЪБађЪ§ОнЭЈГЃгаНјвЛВНзідЫгЊЗжЮіДІРэЕФашЧѓЃЌдкКмЖрЧщПіЯТЪБађЪ§ОнжЛЪЧвЕЮёЪ§ОнЕФвЛВПЗжЃЌашвЊгыЦфЫћРраЭЕФЪ§ОнзщКЯРДЭъГЩВщбЏЗжЮіЃЛЪБађЪ§ОнДцДЂашвЊФмгыЩњЬЌ
BI ЗжЮіЙЄОпЁЂДѓЪ§ОнДІРэЁЂСїЪНЗжЮіЯЕЭГЕШзіКУЖдНгЃЌгыжмБпЩњЬЌаЮГЩаЭЌРДДДдьвЕЮёМлжЕЁЃ
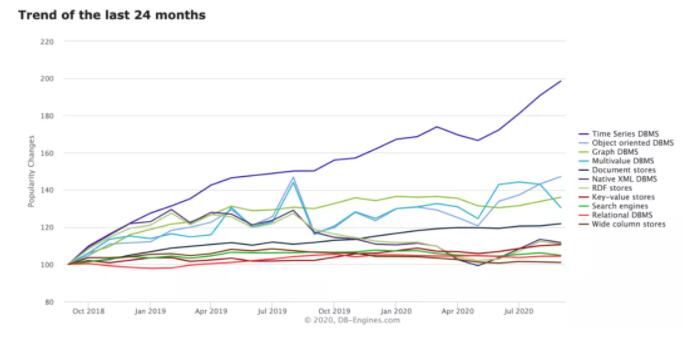
ЮЊСЫгІЖдКЃСПЪБађЪ§ОнЕФДцДЂгыДІРэЕФЬєеНЃЌДг2014ФъПЊЪМЃЌТНајгаеыЖдЪБађЪ§ОнДцДЂЩшМЦЕФЪ§ОнПтЕЎЩњЃЌВЂЧвЪБађЪ§ОнПтЕФдіГЄЧїЪЦГжајСьЯШЃЌЪБађЪ§ОнПтНсКЯЪБађЪ§ОнЕФЬиеїЃЌГЂЪдНтОіЪБађЪ§ОнДцДЂдкИпаДШыЭЬЭТЁЂКсЯђРЉеЙЁЂЕЭГЩБОДцДЂЁЂЪ§ОнХњСПЙ§ЦкЁЂИпаЇМьЫїЁЂМђЕЅЗУЮЪгыЪБађЪ§ОнМЦЫуЕШЗНУцУцСйЕФЬєеНЁЃ
3 вЕНчЪБађЪ§ОнПтЗЂеЙ
ЪБађЪ§ОнПтОЙ§НќаЉФъЕФЗЂеЙЃЌДѓжТОРњСЫМИИіНзЖЮЃК
ЕквЛНзЖЮЃЌвдНтОіМрПиРрвЕЮёашЧѓЮЊжїЃЌВЩгУЪБМфЫГађзщжЏЪ§ОнЃЌЗНБуЖдЪ§ОнАДЪБМфжмЦкДцДЂМАМьЫїЃЌНтОіЙиЯЕаЭЪ§ОнПтДцДЂЪБађЪ§ОнЕФВПЗжЭДЕуЃЌЕфаЭЕФДњБэАќРЈ
RDDToolЁЂWishperЃЈGraphiteЃЉЕШЃЌетРрЯЕЭГДІРэЕФЪ§ОнФЃаЭБШНЯЕЅвЛЃЌЕЅЛњШнСПЪмЯоЃЌВЂЧвЭЈГЃФкЧЖгкМрПиИцОЏНтОіЗНАИЁЃ
ЕкЖўНзЖЮЃЌАщЫцДѓЪ§ОнКЭHadoopЩњЬЌЕФЗЂеЙЃЌЪБађЪ§ОнСППЊЪМбИЫйдіГЄЃЌвЕЮёЖдгкЪБађЪ§ОнДцДЂДІРэРЉеЙадЗНУцЬсГіИќИпЕФвЊЧѓЁЃЛљгкЭЈгУПЩРЉеЙЕФЗжВМЪНДцДЂзЈУХЙЙНЈЕФЪБМфађСаЪ§ОнПтПЊЪМГіЯжЃЌЕфаЭЕФДњБэАќРЈ
OpenTSDBЃЈЕзВуЪЙгУ HBaseЃЉЁЂKairosDBЃЈЕзВуЪЙгУ CassandraЃЉЕШЃЌРћгУЕзВуЗжВМЪНДцДЂПЩРЉеЙЕФгХЪЦЃЌдк
KV ФЃаЭЩЯЙЙНЈЖЈжЦЕФЪБађФЃаЭЃЌжЇГжКЃСПЪБађЕФЕЙХХМьЫїгыДцДЂФмСІЁЃетРрЪ§ОнПтЕФЪ§ОнДцДЂБОжЪШдШЛЪЧЭЈгУЕФ
KV ДцДЂЃЌдкЪБађЪ§ОнЕФМьЫїЁЂДцДЂбЙЫѕаЇТЪЩЯЖМЮоЗЈзіЕНМЋжТЃЌдкЪБађЪ§ОнЕФДІРэжЇГжЩЯвВЯрЖдНЯШѕЁЃ
ЕкШ§НзЖЮЃЌЫцзХ DockerЁЂKubernetesЁЂЮЂЗўЮёЁЂIoT ЕШММЪѕЕФЗЂеЙЃЌЪБМфађСаЪ§ОнГЩЮЊдіГЄзюПьЕФЪ§ОнРраЭжЎвЛЃЌеыЖдЪБађЪ§ОнИпадФмЁЂЕЭГЩБОЕФДцДЂашЧѓШевцЭњЪЂЃЌеыЖдЪБађЪ§ОнЖЈжЦДцДЂЕФЪ§ОнПтПЊЪМГіЯжЃЌЕфаЭЕФвдInfluxDB
ЮЊДњБэЃЌInfluxDB ЕФ TSM ДцДЂв§ЧцеыЖдЪБађЪ§ОнЖЈжЦЃЌжЇГжКЃСПЪБМфЯпЕФМьЫїФмСІЃЌЭЌЪБеыЖдЪБађЪ§ОнНјаабЙЫѕНЕЕЭДцДЂГЩБОЃЌВЂжЇГжДѓСПУцЯђЪБађЕФДАПкМЦЫуКЏЪ§ЃЌInfluxDB
ФПЧАвВЪЧ DB Engine Rank ХХУћЕквЛЕФЪБађЪ§ОнПтЁЃInfluxDB НіПЊдДСЫЕЅЛњАцБОЃЌИпПЩгУМЏШКАцНідкЦѓвЕАцКЭдЦЗўЮёЕФАцБОРяЬсЙЉЁЃ
ЕкЫФНзЖЮЃЌЫцзХдЦМЦЫуЕФИпЫйЗЂеЙЃЌдЦЩЯЪБађЪ§ОнПтЗўЮёж№ВНЕЎЩњЃЌАЂРядЦдчдк2017ФъОЭЭЦГіСЫ TSDB
дЦЗўЮёЃЌЫцКѓ AmazonЁЂAzure ЭЦГі Amazon TimeStreamЁЂAzure Timeseires
Insight ЗўЮёЃЌInfluxData вВж№ВНЭљдЦЩЯзЊаЭЃЌЭЦГі InfluxDB дЦЗўЮёЃЛЪБађЪ§ОнПтдЦЗўЮёПЩвдгыдЦЩЯЦфЫћЕФЛљДЁЩшЪЉаЮГЩИќКУЕФаЭЌЃЌдЦЪ§ОнПтвбЪЧВЛПЩФцЕФЗЂеЙЧїЪЦЁЃ
Жў Lindorm TSDB БГКѓЕФММЪѕЫМПМ
1 Lindorm дЦдЩњЖрФЃЪ§ОнПт
ЮЊСЫгНг 5g/IoT ЪБДњЕФЪ§ОнДцДЂЬєеНЃЌАЂРядЦЭЦГідЦдЩњЖрФЃЪ§ОнПт Lindorm ЃЌжТСІгкНтОіКЃСПЖрРраЭЕЭГЩБОДцДЂгыДІРэЮЪЬтЃЌШУКЃСПЪ§ОнДцЕУЦ№ЁЂПДЕУМћЁЃ
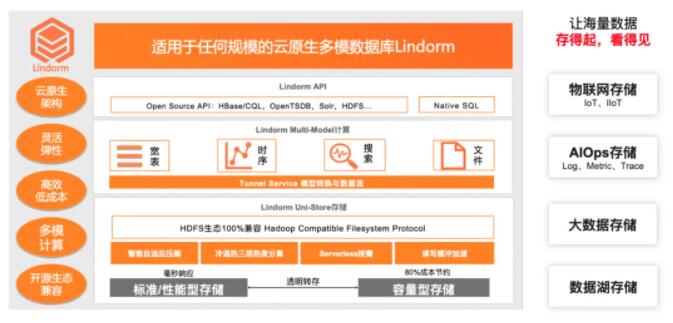
Lindorm жЇГжПэБэЁЂЪБађЁЂЫбЫїЁЂЮФМўЕШЖржжФЃаЭЃЌТњзуЖрРраЭЪ§ОнЭГвЛДцДЂашЧѓЃЌЙуЗКгІгУгкЮяСЊЭјЁЂГЕСЊЭјЁЂЙуИцЁЂЩчНЛЁЂгІгУМрПиЁЂгЮЯЗЁЂЗчПиЕШГЁОАЁЃЦфжа
Lindorm TSDB ЪБађв§ЧцЬсЙЉИпаЇЖСаДадФмЁЂЕЭГЩБОЪ§ОнДцДЂЁЂЪБађЪ§ОнОлКЯЁЂВхжЕЁЂдЄВтЕШМЦЫуФмСІЃЌжївЊгІгУгкЮяСЊЭј(IoT)ЁЂЙЄвЕЛЅСЊЭјЃЈIIoTЃЉЁЂгІгУадФмМрПиЃЈAPMЃЉЕШГЁОАЁЃ
2 Lindorm TSDB КЫаФЩшМЦРэФю
Lindorm TSDB зіЮЊЯТвЛДњЪБађЪ§ОнПтЃЌдкМмЙЙЩ§МЖЙ§ГЬжаЃЌЮвУЧШЯЮЊЪБађЪ§ОнПтЕФЗЂеЙЛсгаШчЯТЧїЪЦЃК
ЖрФЃШкКЯЃКЮДРДЪБађЪ§ОнПтгыЭЈгУKVЪ§ОнПтЁЂЙиЯЕаЭЪ§ОнПтЕШЕФХфКЯСЊЯЕЛсдНРДдННєУмЃЌР§ШчдкЮяСЊЭјГЁОАЃЌЩшБИдЊЪ§ОнЕФДцДЂЁЂдЫааЪБЪ§ОнЕФДцДЂЁЂвЕЮёРрЪ§ОнЕФДцДЂЭЈГЃЛсЪЙгУВЛЭЌЕФЪ§ОнФЃаЭРДДцДЂЁЃ
дЦдЩњЃКЫцзХдЦМЦЫуЕФЗЂеЙЃЌЮДРДЪБађЪ§ОнПтЕФДцДЂвЊЛљгкдЦдЩњММЪѕЃЌГфЗжРћгУдЦЩЯЕФЛљДЁЩшЪЉЃЌаЮГЩЯрЛЅвРРЕЛђаЭЌЃЌНјвЛВНЙЙНЈГіЪБађДцДЂЕФОКељСІЁЃ
ЪБађдЩњЃКЮДРДЪБађЪ§ОнПтЕФДцДЂв§ЧцЪЧеыЖдЪБађЪ§ОнИпЖШЖЈжЦЛЏЕФЃЌБЃжЄИпаЇЕФЪБађЖрЮЌМьЫїФмСІЃЌИпаДШыЭЬЭТМАИпбЙЫѕТЪЃЌжЇГжРфШШЪ§ОнздЖЏЛЏЙмРэЁЃ
ЗжВМЪНЕЏадЃКЮДРДЪБађЪ§ОнПтвЊОпБИЗжВМЪНРЉеЙЕФФмСІЃЌгІЖдДѓЙцФЃЕФЪБађЪ§ОнПтДцДЂЃЌдкЪБађЕФЕфаЭгІгУГЁОАЃЌР§ШчЮяСЊЭјЁЂЙЄвЕЕчЭјЁЂМрПиЁЂЖМгаКЃСПЩшБИЪ§ОнаДШыКЭДцДЂЕФашЧѓЃЌБиаывЊзіЕНЕЏадРЉеЙЃЌЭЈЙ§ЗжВМЪНЁЂServerless
ЕШММЪѕЪЕЯжЙцФЃДгаЁЕНДѓЕФЕЏадЩьЫѕЁЃ
ЪБађ SQLЃКЮДРДЪБађЪ§ОнПтЕФЗУЮЪвЊжЇГжБъзМ SQLЃЈor SQL Like БэДяЗНЪНЃЉЃЌвЛЗНУцЪЙгУЩЯИќМгБуНнЃЌНЕЕЭЪ§ОнПтЕФЪЙгУУХМїЃЌЭЌЪБвВФмЛљгк
SQL ЬсЙЉИќМгЧПДѓВЂгаЪБађЬиЩЋЕФМЦЫуФмСІЁЃ
дЦБпвЛЬхЃКЮДРДЪБађЪ§ОнПтдкБпдЕЩшБИЖЫВЛдйЪЧЙТСЂЕФЪ§ОнДцДЂЃЌБпдЕВрЛсВЛЖЯМгЩюгыдЦЖЫаЭЌЃЌаЮГЩвЛЬхЛЏЕФЪБађДцДЂНтОіЗНАИЁЃ
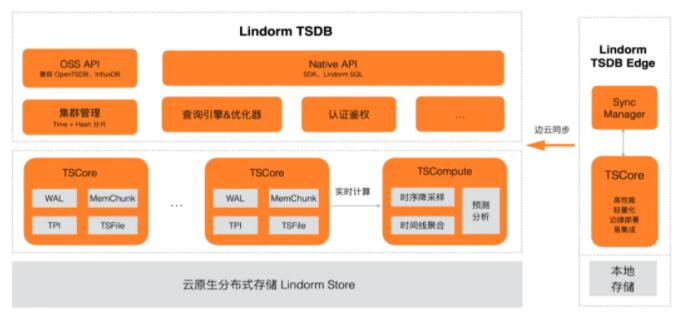
ЛљгквдЩЯХаЖЯЃЌЮвУЧЙЙНЈСЫдЦдЩњЖрФЃЪ§ОнПт LindormЃЌжЇГжПэБэЁЂЪБађЁЂЫбЫїЁЂЮФМўЕШЖржжГЃгУФЃаЭЃЌНтОіЮяСЊЭј/ЛЅСЊЭјКЃСПЪ§ОнДцДЂЕФГЃМћашЧѓЃЌЦфжа
Lindorm TSDB ВЩгУМЦЫуДцДЂЗжРыЕФМмЙЙЃЌГфЗжРћгУдЦдЩњДцДЂЛљДЁЩшЪЉЃЌЖЈжЦЪБађДцДЂв§ЧцЃЌЯрБШвЕНчЕФНтОіЗНАИИќОпОКељСІЁЃ
ЖрФЃШкКЯЁЂЭГвЛДцДЂЃКLindorm TSDB в§ЧцгыПэБэЁЂЫбЫїЁЂЮФМўЕШаЮГЩХфКЯЃЌНтОігУЛЇЖрРраЭЪ§ОнЕФЭГвЛДцДЂДІРэашЧѓЁЃ
дЦдЩњЕЭГЩБОДцДЂЃЌМЦЫуДцДЂЗжРыЃКLindorm TSDB в§ЧцЛљгкдЦдЩњЗжВМЪНДцДЂЦН LindormStoreЃЌЬсЙЉИпПЩППЕФЪ§ОнДцДЂЃЌВЂжЇГжЕЏадРЉеЙЃЌЬсЙЉБъзМаЭЁЂадФмаЭЁЂШнСПаЭЕШЖржжДцДЂаЮЬЌЃЌТњзуВЛЭЌГЁОАЕФашЧѓЃЌЭЌЪБжЇГжРфШШЪ§ОнвЛЬхЛЏЙмРэЕФФмСІЁЃ
ЪБађЖЈжЦДцДЂв§ЧцЃКLindorm TSDB в§ЧцеыЖдЪБађЪ§ОнЕФЬиеїЃЌЖЈжЦЛљгк LSM Tree НсЙЙЕФЪБађв§ЧцЃЌдкШежОаДШыЁЂФкДцзщжЏНсЙЙЁЂЪБађЪ§ОнДцДЂНсЙЙвдМА
Compaction ВпТдЩЯЖМеыЖдЪБађЬиеїгХЛЏЃЌБЃжЄМЋИпЕФаДШыЭЬЭТФмСІЁЃдкв§ЧцФкВПжЇГжФкжУЕФдЄДІРэМЦЫув§ЧцЃЌжЇГжЖдЪБађЪ§ОнНјаадЄНЕВЩбљЁЂдЄОлКЯЃЌРДгХЛЏВщбЏаЇТЪЁЃ
ЖрЮЌЪ§ОнЗжЦЌЁЂЕЏадЩьЫѕЃКLindorm TSDB в§ЧцжЇГжКсЯђРЉеЙЃЌЭЈЙ§ЖдЪБМфЯпНјаа Hash ЗжЦЌЃЌНЋКЃСПЪБМфЯпЪ§ОнЗжЩЂЕНЖрИіНкЕуДцДЂЃЛдкНкЕуФкВПЃЌжЇГжАДЪБМфЮЌЖШНјвЛВНЧаЗжЃЌжЇГжМЏШКЕФЮоЗьРЉШнЃЌЭЌЪБвВФмНтОідЦдЩњМрПиГЁОАЪБМфЯпХђеЭЕФЮЪЬтЃЛЭЈЙ§
Serverless аЮЬЌЪЕЯжШЮвтЙцФЃЕФЕЏадЩьЫѕЁЃ
ЖЈжЦЪБађ SQL ВщбЏЃКLindorm TSDB в§ЧцЬсЙЉЪБађ SQL ЗУЮЪФмСІЃЌеыЖдЪБађГЁОАЖЈжЦЬиЩЋМЦЫуЫузгЃЌгУЛЇбЇЯАЁЂЪЙгУГЩБОЕЭЁЃ
БпдЦЭЌВНвЛЬхЛЏЃКLindorm TSDB в§ЧцЬсЙЉЧсСПМЖБпдЕВПЪ№ЕФАцБОЃЌНтОіБпдЕЪБађДцДЂашЧѓЃЌВЂжЇГжБпдЕВрЪ§ОнгыдЦЖЫЮоЗьЭЌВНЃЌвдБуГфЗжРћгУдЦЩЯЛљДЁЩшЪЉРДНјвЛВНЭкОђЪ§ОнМлжЕЁЃ
Ш§ Lindorm TSDB ЙиМќММЪѕ
1 ЪБађЖЈжЦДцДЂв§Чц
Lindorm ЛљгкДцДЂМЦЫуЗжРыМмЙЙЩшМЦЃЌвдЪЪгІдЦМЦЫуЪБДњзЪдДНтёюКЭЕЏадЩьЫѕЕФЫпЧѓЃЌЦфжадЦдЩњДцДЂЗжВМЪНДцДЂ
Lindorm Store ЮЊЭГвЛЕФДцДЂЕззљЃЌЯђЩЯЙЙНЈИїИіДЙжБзЈгУЕФЖрФЃв§ЧцЃЌАќРЈПэБэв§ЧцЁЂЪБађв§ЧцЁЂЫбЫїв§ЧцЁЂЮФМўв§ЧцЁЃLindormStore
ЪЧУцЯђЙЋЙВдЦЛљДЁДцДЂЩшЪЉ(ШчдЦХЬЁЂDBFSЁЂOSS) ЩшМЦЁЂМцШн HDFS авщЕФЗжВМЪНДцДЂЯЕЭГЃЌВЂЭЌЪБжЇГждЫаадкБОЕиХЬЛЗОГЃЌвдТњзуВПЗжзЈгадЦЁЂзЈЪєДѓПЭЛЇЕФашЧѓЃЌЯђЖрФЃв§ЧцКЭЭтВПМЦЫуЯЕЭГЬсЙЉЭГвЛЕФЁЂгыЛЗОГЮоЙиЕФБъзМНгПкЁЃ
ЛљгкдЦдЩњЗжВМЪНДцДЂ LindomStoreЃЌLindorm TSDB ВЩгУеыЖдаДШыгХЛЏЕФ LSM
Tree НсЙЙРДДцДЂЪБађЪ§ОнЃЌВЂНсКЯЪБађЪ§ОнЕФЬиеїЃЌдкШежОаДШыЁЂФкДцзщжЏНсЙЙЁЂЪБађЪ§ОнДцДЂНсЙЙНјааЪБађбЙЫѕЃЌзюДѓЛЏФкДцРћгУаЇТЪЁЂДХХЬДцДЂаЇТЪЃЛЭЌЪБдк
Compaction ВпТдЩЯвВеыЖдЪ§ОнЭЈГЃгаађВњЩњЕФЬиеїНјаагХЛЏЁЃЭЈЙ§в§ЧцздДјЕФ WAL ШежОЃЌLindorm
TSDB ФмЗЧГЃЗНБуЕФжЇГжЪЕЪБЕФЪ§ОнЖЉдФЃЌвдМАдкв§ЧцФкВПЖдЪ§ОнНјааеыЖдадЕФНЕВЩбљЁЂОлКЯЕШдЄДІРэВйзїЁЃ
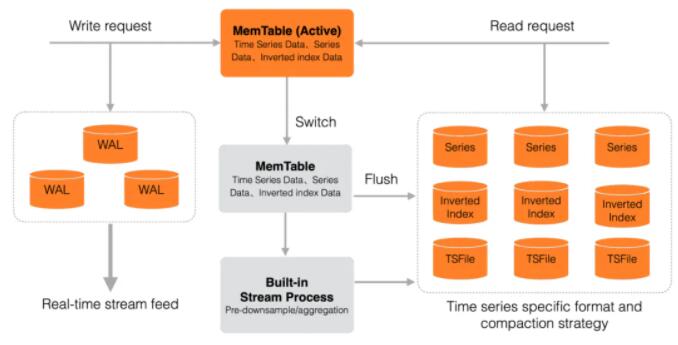
Lindorm TSDB еыЖдЪБађЪ§ОнЕФВщбЏЃЌжЇГжЗсИЛЕФДІРэЫузгЃЌАќРЈНЕВЩбљЁЂОлКЯЁЂВхжЕЁЂЙ§ТЫЕШЁЃгУЛЇЕФВщбЏЧыЧѓОЙ§
Parser НтЮіКѓЃЌЭЈГЃЗжЮЊЖрИіжївЊЕФДІРэНзЖЮЃЌвд Pipeline ЕФаЮЪНИпаЇДІРэЁЃ
Index ScanЃКИљОнгУЛЇжИЖЈЕФВщбЏЬѕМўЃЌЛљгке§ХХЫїв§ + ЕЙХХЫїв§евГіЫљгаТњзуЬѕМўЕФЪБМфЯп
ID МЏКЯЁЃ
Data ScanЃКЛљгкЕк1НзЖЮевГіЕФЪБМфЯп IDЃЌДг TSFile ЖСШЁЖдгІЪБМфЗЖЮЇЕФЪ§ОнЁЃ
Aggregation/Filter: еыЖдЕк2НзЖЮЕФЩЈУшНсЙћЃЌЖдЪБМфЯпЪ§ОнНјвЛВНЕФДІРэЃЌАќРЈдквЛЬѕЪБМфЯпЩЯЖдЪ§ОнАДвЛЖЈжмЦкНјааНЕВЩбљЃЌЛђЖдЖрЬѕЪБМфЯпЯрЭЌЪБМфЕуЩЯЕФЪ§ОнНјааОлКЯЃЈsumЁЂcountЁЂavgЁЂminЁЂmaxЕШЃЉВйзїЕШЁЃ
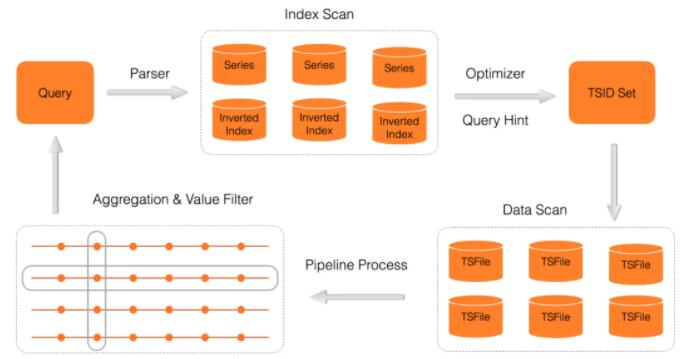
2 ЗжВМЪНЕЏад
Lindorm TSDB ОпБИКсЯђРЉеЙЕФФмСІЃЌКЃСПЕФЪБМфЯпЪ§ОнЛсБЛЗжЩЂДцДЂЕНЖрИі Shard жаЃЌShard
ЪЧМЏШКжаЖРСЂЕФЪ§ОнЙмРэЕЅдЊЃЌShard ФкВПЪЧвЛИізджЮЙмРэЕФ LSM Tree ДцДЂв§ЧцЃЈВЮПМ2.2ЃЉЃЌАќКЌЕЅЖРЕФ
WALЁЂTPIЁЂTSFile ЕШЮФМўЁЃ
дкЫЎЦНЗНЯђЃЌЪБМфађСаЪ§ОнЛсИљОн metric + tags зщГЩЕФЪБМфЯпБъЪЖЃЌВЩгУ Hash ЗжЦЌЕФВпТдЃЌНЋЪ§ОнЗжЕНЖрИіНкЕуЃЛдкДЙжБЗНЯђЃЈЪБМфжсЮЌЖШЃЉЃЌЗжЕНЭЌвЛИіНкЕуЕФЪ§ОнЃЌПЩАДееЪБМфЮЌЖШНјааЧаЗжЃЌетбљУПИі
Shard ОЭИКд№вЛВПЗжЪБМфЯпдквЛЖЈЪБМфЗЖЮЇФкЕФЪ§ОнЙмРэЁЃ
ЫЎЦНЗНЯђЕФЗжЦЌФмБЃжЄМЏШКЕФИКдиОљЗжЕНИїИіНкЕуЃЌКѓајЛЙЛсНсКЯвЕЮёЬиеїЃЌжЇГжвЕЮёздЖЈвхЕФЗжЦЌВпТдЃЌгХЛЏЖСаДаЇТЪЃЛДЙжБЗНЯђЃЈАДЪБМфЗЖЮЇЃЉЕФЗжЦЌЃЌЖдгкХђеЭаЭЪБМфЯпГЁОАЃЈБШШчдЦдЩњМрПиЕФГЁОАЃЌШнЦїЦЕЗБЩЯЯТЯпЕМжТДѓСПРЯЪБМфЯпЕФЯћЭіЃЌаТЪБМфЯпЕФДДНЈЃЉЗЧГЃгаАяжњЃЌЭЌЪБдкМЏШКРЉШнЪБЃЌвВПЩвдНшжњЪБМфЗжЦЌВпТдРДОЁПЩФмЕФМѕаЁЖдаДШыЕФгАЯьЁЃ
3 TSQL ЪБађВщбЏ
Lindorm TSDB ЬсЙЉ SQL ЗУЮЪФмСІЃЌLindorm TSDB ЕФЪ§ОнФЃаЭеыЖдЮяСЊЭјГЁОАИпЖШгХЛЏЖЈжЦЃЌИХФюЩЯОЁСПБЃСєПЊЗЂепЖдЪ§ОнПтЕФЦеБщРэНтЃЌвЛИіЪЕР§АќКЌЖрИіЪ§ОнПтЃЌвЛИіЪ§ОнПтАќКЌЖреХБэЃЌБэРяДцДЂЖрИіЩшБИЕФЪБађЪ§ОнЃЌУПИіЩшБИАќКЌвЛзщгУгкУшЪіЩшБИЕФ
TagЁЂЩшБИАќКЌЖрИі Field жИБъЃЌаТЕФжИБъЪ§ОнЫцЪБМфГжајВЛЖЯЕФВњЩњЁЃГ§СЫжЇГжГЃЙцЕФ SQL ЛљДЁФмСІЃЌLindorm
TSDB ЛЙЖЈжЦСЫ sample byЁЂlatest ЕШЫузгЃЌгУгкЗНБуЕФБэДяЪБађНЕВЩбљЁЂЪБађОлКЯЁЂзюаТЕуВщбЏЕШГЃМћЕФЪБађВйзїЃЌМђЛЏЪЙгУЕФЭЌЪБЃЌдіЧПСЫЪБађ
SQL ЕФБэДяФмСІЃЌШУгУЛЇЪЙгУЪБађЪ§ОнПтИќМгМђЕЅЁЂИпаЇЁЃ
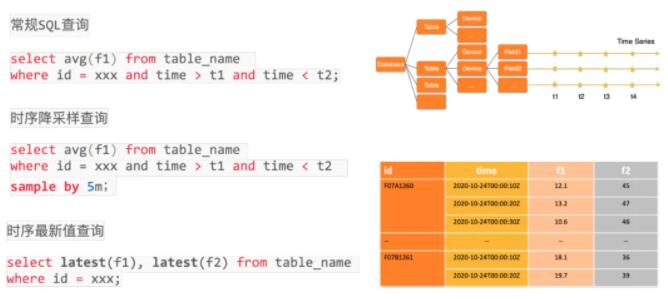
Лљгк TSQL ВщбЏНгПкЃЌLindorm TSDB ЛЙФмеыЖдЪБађЪ§ОнНјаавЛЯЕСаЕФЭиеЙЗжЮіЃЌАќРЈЪБађЪ§ОндЄВтЁЂвьГЃМьВтЕШЃЌШУгІгУФмИќКУЕФЗЂЛгЪБађЪ§ОнМлжЕЁЃ
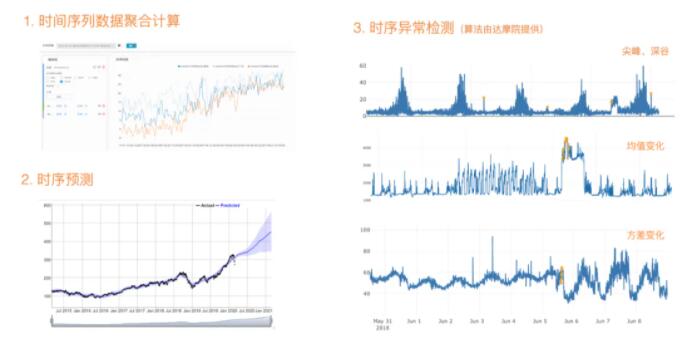
4 Serverless
Lindorm TSDB ЭЈЙ§ЪБађЖЈжЦЕФДцДЂв§ЧцЁЂНсКЯЗжВМЪНРЉеЙЕФФмСІЃЌФмКмКУЕФТњзуДѓЙцФЃЪБађГЁОАЕФвЕЮёашЧѓЁЃЕЋЖдгквЛаЉвЕЮёЗУЮЪНЯаЁЕФгІгУГЁОАЦ№ВНГЩБОЯрЖдНЯИпЃЌР§ШчдкЦНЬЈМЖЕФгІгУМрПиЁЂIoT
ГЁОАЃЌЦНЬЈашвЊЙмРэДѓСПгУЛЇЕФЪБађЪ§ОнЃЌЖјДѓВПЗжгУЛЇЕФЪ§ОнЙцФЃГѕЦкЖМЯрЖдНЯаЁЃЌЮЊСЫНјвЛВННЕЕЭгУЛЇЕФЪЙгУГЩБОЃЌЪЪгІДгаЁЕНДѓШЮвтЙцФЃЕФЪБађДцДЂашЧѓЃЌИќКУЕФИГФмЩЯВуЕФгІгУМрПиЁЂЮяСЊЭјРр
SaaS ЦНЬЈЗўЮёЃЌЮДРД Lindorm НЋЛсбизХЖрзтЛЇ Serverless ЗўЮёФЃЪНГжајбнНјЃЌЬсЩ§ЕЏадФмСІЁЃ
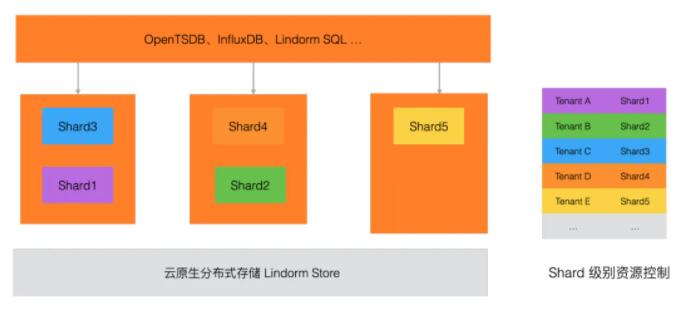
5 БпдЦЭЌВН
ЫцзХ IoT ММЪѕЕФЗЂеЙЃЌБпдЕМЦЫуашЧѓШевцУїЯдЃЌдкжЧФмМвОгЁЂЙЄвЕЙЄПиЁЂжЧЛлдАЧјЁЂНЛЭЈДѓФдЕШГЁОАЃЌПМТЧЕНЭјТчДјПэГЩБОЕШдвђЃЌЪ§ОнЭЈГЃашвЊЯШОЭНќБОЕиДцДЂЃЌВЂжмЦкадЕФЭЌВНЕНдЦЖЫНјааНјвЛВНЗжЮіДІРэЁЃЮЊСЫЗНБуБпдЕВрЕФВПЪ№ЃЌLindorm
TSDB жЇГжБпдЕЧсСПМЖВПЪ№ЕФАцБОЃЌВЂжЇГжЪ§ОнШЋСПЁЂдіСПЭЌВНЕНдЦЖЫЃЌаЮГЩБпдЦвЛЬхЛЏЕФНтОіЗНАИЁЃ
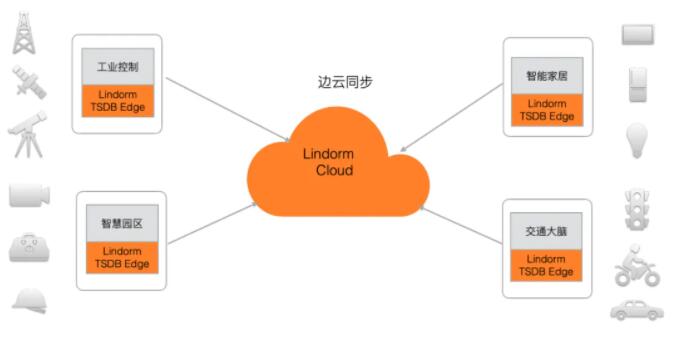
ЫФ ЪБађДцДЂНтОіЗНАИ
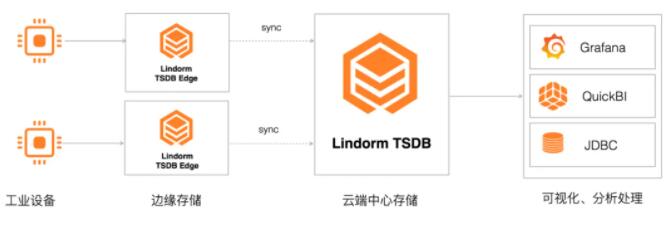
1 ЮяСЊЭјЩшБИЪ§ОнДцДЂ
Lindorm TSDB ЪЧЮяСЊЭјЩшБИдЫааЪ§ОнДцДЂЕФзюМббЁдёЃЌЮоЗьгыАЂРядЦ IoT ЦНЬЈЁЂDataHubЁЂFlink
ЕШНјааСЌНгЃЌМЋДѓЕФМђЛЏЮяСЊЭјгІгУПЊЗЂСїГЬЁЃР§ШчЭЈЙ§ Lindorm TSDBЃЌФуПЩвдЪеМЏВЂДцДЂжЧФмЩшБИЕФдЫаажИБъЃЌЭЈЙ§здДјЕФОлКЯМЦЫув§ЧцЛђBIРрЙЄОпНјаажЧФмЗжЮіЃЌЩюШыСЫНтЩшБИдЫаазДЬЌЁЃ
2 ЙЄвЕБпдЕЪБађДцДЂ
Lindorm TSDB БпдЕАцЗЧГЃЪЪКЯЙЄвЕЛЅСЊЭјГЁОАЃЌдкБпдЕВрЧсСПЛЏЪфГіЃЌгыЙЄвЕЩшБИОЭНќВПЪ№ЃЌЭЌЪБжЇГжНЋЪ§ОнЭЌВНЕН
Lindorm дЦЖЫЁЃР§ШчЭЈЙ§ Lindorm TSDBЃЌФуПЩвдЪЕЪБВЩМЏЙЄвЕЩњВњЯпЩшБИЕФдЫаажИБъЃЌЖдВњЯпЕФдЫаазДПіНјааЗжЮіМАПЩЪгЛЏЃЌДгЖјгХЛЏВњЯпдЫаааЇФмЁЃ
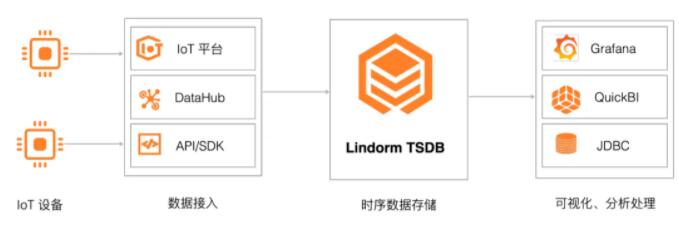
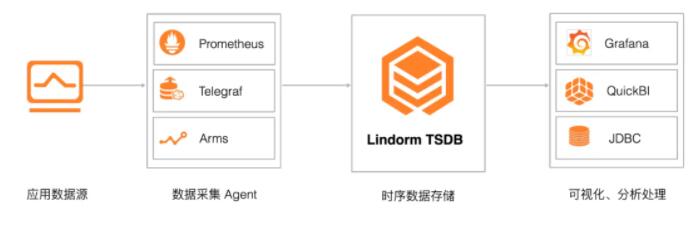
3 гІгУМрПиЪ§ОнДцДЂ
Lindorm TSDB ЗЧГЃЪЪКЯгІгУМрПиЪ§ОнДцДЂЃЌЮоЗьЖдНг PrometheusЁЂTelegrafЁЂARMS
ЕШМрПиЩњЬЌЃЌЬсЙЉеыЖдМрПижИБъЕФИпаЇЖСаДгыДцДЂЃЌЭЌЪБЬсЙЉОлКЯЗжЮіЁЂВхжЕМЦЫуЕШФмСІЁЃР§ШчЭЈЙ§ Lindorm
TSDBЃЌФуПЩвдЪеМЏгІгУГЬађЕФ CPUЁЂФкДцЁЂДХХЬЕШжИБъЕФЪЙгУЧщПіЃЌВЂНјааЗжЮіМАПЩЪгЛЏЃЌЪЕЪБМрВтгІгУдЫааЧщПіЁЃ
Юх змНс
ДгЛЅСЊЭј&ДѓЪ§ОнЪБДњЕФЗжВМЪНЃЌЕНдЦМЦЫуЁЂ5G/IoTЪБДњЕФдЦдЩњЖрФЃЃЌвЕЮёЧ§ЖЏЪЧLindormВЛБфЕФбнНјддђЁЃУцЖдзЪдДАДашЕЏадКЭЪ§ОнЖрбљЛЏДІРэЕФаТЪБДњашЧѓЃЌLindormвдЭГвЛДцДЂЁЂЭГвЛВщбЏЁЂЖрФЃв§ЧцЕФМмЙЙНјааШЋаТЩ§МЖЃЌВЂНшжњдЦЛљДЁЩшЪЉКьРћЃЌжиЕуЗЂЛгдЦдЩњЕЏадЁЂЖрФЃШкКЯДІРэЁЂМЋжТадМлБШЁЂЦѓвЕМЖЮШЖЈадЕФгХЪЦФмСІЃЌШЋСІГадиКУОМУЬхФкВПКЭЦѓвЕПЭЛЇЕФКЃСПЪ§ОнДцДЂДІРэашЧѓЁЃ
Lindorm TSDB ЪБађв§ЧцУцЯђЮяСЊЭјЁЂЙЄвЕЛЅСЊЭјЁЂгІгУадФмМрПиЕШСьгђЕФЪБађЪ§ОнДцДЂашЧѓЃЌШЋУцгЕБЇдЦдЩњЃЌВЂГфЗжРћгУдЦдЩњЛљДЁЩшЪЉЃЌЖЈжЦЪБађДцДЂв§ЧцЃЌЙЙНЈКЃСПЕЭГЩБОЕФЪБађЪ§ОнДцДЂгыДІРэФмСІЃЌЬсЙЉБпдЦвЛЬхЛЏЕФЪБађДцДЂНтОіЗНАИЁЃЮДРД
Lindorm в§ЧцНЋМЬајдкЕЏадЩьЫѕЁЂЕЭГЩБОКЃСПДцДЂЁЂЖрФЃШкКЯЁЂЪБађСїМЦЫуЕШЗНЯђГжајЭЛЦЦЃЌЙЙНЈЭђЮяЛЅСЊЕФЪ§ОнЕззљЁЃ
| 








