| Īŗľ≠Õ∆ľŲ: |
ĪĺĹŕ÷ų“™Ĺť…‹
Ńň–‘ń‹”ŇĽĮ∑÷ņŗ°Ę »ŪľĢ≤„√ś”ŇĽĮ°ĘŌĶÕ≥≤„√ś”ŇĽĮĶ»∑Ĺ√śńŕ»›°£
Īĺőńņī◊‘≤©ŅÕ‘į£¨”…ĽūŃķĻŻ»ŪľĢAnnaĪŗľ≠°ĘÕ∆ľŲ°£ |
|
1. –‘ń‹”ŇĽĮ∑÷ņŗ
mongodb–‘ń‹”ŇĽĮ∑÷ő™»ŪľĢ≤„√śļÕ≤Ŕ◊ųŌĶÕ≥≤„√ś°£
»ŪľĢ≤„√ś£¨“Ľį„Õ®Ļż–řłńmongodb»ŪľĢŇš÷√≤ő żņīīÔĶĹ£¨’‚łŲ–Ť“™∑«≥£ žŌ§mongodbņÔ√śĶńłų÷÷Ňš÷√≤ő ż£Ľ
∂Ý≤Ŕ◊ųŌĶÕ≥≤„√ś£¨Ōŗ∂‘ľÚĶ•Ķ„£¨÷ų“™ «–řłń≤Ŕ◊ųŌĶÕ≥≤ő ż£¨Ī»»ÁňĶ£ļĻōĪ’īę š“≥Ľļīś°Ę Ļ”√SSDŐśīķĽķ∆ų”≤ŇŐĶ»Ķ»°£
2. »ŪľĢ≤„√ś”ŇĽĮ
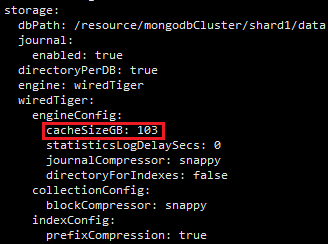
2.1 …Ť÷√WiredTigerĶńcacheSizeGB
Õ®ĻżcacheSizeGB—°ŌÓŇš÷√Ņō÷∆WiredTiger“ż«ś Ļ”√ńŕīśĶń…ŌŌř£¨ń¨»ŌŇš÷√‘ŕŌĶÕ≥Ņ…”√ńŕīśĶń60%◊ů”“°£
»ÁĻŻ“ĽŐ®Ľķ∆ų…Ō÷Ľ≤Ņ ū“ĽłŲmongod£¨mongodŅ…“‘ Ļ”√ňý”–Ņ…”√ńŕīś£¨‘Ú Ļ”√ń¨»ŌŇš÷√ľīŅ…°£
»ÁĻŻ“ĽŐ®Ľķ∆ų…Ō≤Ņ ū∂ŗłŲmongod£¨ĽÚ’Ŗmongodłķ∆šňŻĶń“Ľ–©ĹÝ≥Ő“Ľ∆ū≤Ņ ū£¨‘Ú–Ť“™łýĺ›∑÷łÝmongodĶńńŕīśŇš∂ÓņīŇš÷√cacheSizeGB£¨įīŇš∂ÓĶń60%◊ů”“Ňš÷√ľīŅ…°£
Õ®ĻżŇš÷√őńľĢŇš÷√cacheSizeGB£¨»ÁŌ¬£ļ
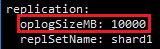
2.2 ∑÷Ňš◊„ĻĽĶńOplogŅ’ľš
Oplog «MongoDB localŅ‚Ō¬Ķń“ĽłŲĻŐ∂®ľĮļŌ£¨SecondaryĺÕ «Õ®Ļż≤ťŅīPrimary
Ķńoplog’‚łŲľĮļŌņīĹÝ––łī÷∆Ķń°£OplogŅ…“‘ňĶ «MongoDB ReplicationĶńҶīÝ°£Oplog «ĻŐ∂®īů–°Ķń£¨ňŁ÷Ľń‹Ī£īśŐō∂® żŃŅĶń≤Ŕ◊ų»’÷ĺ°£»ÁĻŻoplog
sizeĻżīů£¨ĽŠņň∑—īśīĘŅ’ľš£Ľ»ÁĻŻoplog sizeĻż–°£¨ņŌĶńoplogľ«¬ľļ‹ŅžĺÕĽŠĪĽł≤ł«£¨ń«√īŚīĽķĶńĹŕĶ„ļ‹»›“◊≥ŲŌ÷őř∑®Õ¨≤Ĺ żĺ›ĶńŌ÷Ōů£¨“Úīň…Ť÷√ļŌņŪĶńoplogīů–°∂‘mongodbļ‹÷ō“™°£MongoDBń¨»ŌĹę∆šīů–°…Ť÷√ő™Ņ…”√diskŅ’ľšĶń5%£®ń¨»Ō◊Ó–°ő™1G£¨◊Óīůő™50G£©°£
’‚ņÔ…Ť÷√oplogő™10000MB£¨»Á£ļ
2.3 ∆Ű”√Log Rotation»’÷ĺ«–ĽĽ
∑ņ÷ĻMongoDBĶńlogőńľĢőřŌř‘Ųīů£¨’ľ”√Őę∂ŗīŇŇŐŅ’ľš°£ Ļ”√Log Rotation≤Ęľį Ī«ŚņŪņķ ∑»’÷ĺőńľĢ£¨‘ŕŇš÷√őńľĢŇš÷√»ÁŌ¬ļžŅÚ…Ť÷√°£
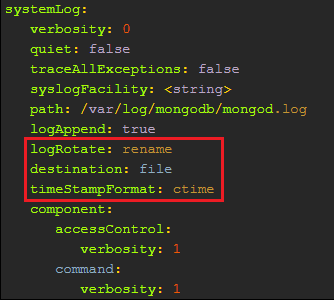
logRotate£ļ»’÷ĺĽō◊™£¨∑ņ÷Ļ“ĽłŲ»’÷ĺőńľĢŐōĪūīů£¨Ņ…—°÷Ķ£ļrename£¨÷ō√Ł√Ż»’÷ĺőńľĢ£¨ń¨»Ō÷Ķ£Ľreopen£¨ Ļ”√Linux»’÷ĺrotateŐō–‘£¨ĻōĪ’≤Ę÷ō–¬īÚŅ™īő»’÷ĺőńľĢ£¨Ņ…“‘Ī‹√‚»’÷ĺ∂™ ߣ¨Ķę «logAppendĪō–Žő™true°£
timeStampFormat£ļ÷ł∂®»’÷ĺłŮ ĹĶń ĪľšīŃłŮ Ĺ£¨Ņ…—°÷Ķ£ļctime£¨Ō‘ ĺ ĪľšīŃWed Dec
31 18:17:54.811£ĽIso8601-utc£¨Ō‘ ĺ ĪľšīŃ“‘–≠ĶųÕ®”√ Īľš£®UTC£©‘ŕISO-8601÷–ĶńłŮ Ĺ£¨ņż»Á£¨Ň¶‘ľ ĪīķĶńŅ™ ľ Īľš:1970-01-01t00:00:
00.000z£Ľiso8601-local£¨Ō‘ ĺĶĪĶō ĪľšISO-8601łŮ ĹŌ‘ ĺ ĪľšīŃ
2.4 …Ť÷√journal»’÷ĺňĘ–¬ ĪľšļÕflush Īľš
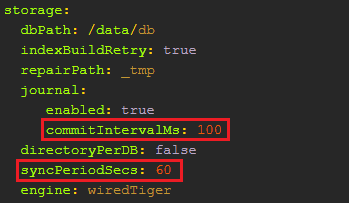
commitIntervalMs£ļmongodĶńjournal»’÷ĺňĘ–¬÷Ķ∑∂őßī”1ĶĹ500ļŃ√Ž°£ĹŌĶÕĶń÷Ķ‘Ųľ”ŃňjournalĶńńÕĺ√–‘£¨“‘őĢ…Ł–‘ń‹ő™īķľŘ£¨‘ŕWiredTiger“ż«ś…Ō£¨ń¨»ŌĶń»’÷ĺŐŠĹĽľšłŰő™100ļŃ√Ž£¨‘ŲīůcommitIntervalMsŅ…“‘ĹĶĶÕīŇŇŐĶńIO—ĻѶ£¨∆ūĶĹ“Ľ∂®Ķń”ŇĽĮ◊ų”√°£≤ĽĻż“Ľį„«ťŅŲŌ¬£¨≤ĽĹ®“ť–řłń°£
syncPeriodSecs£ļmongod Ļ”√fsync≤Ŕ◊ųĹę żĺ›flushĶĹīŇŇŐĶń ĪľšľšłŰ£¨ń¨»Ō÷Ķő™60£®Ķ•őĽ£ļ√Ž£©£¨‘Ųīůł√÷Ķ“≤Ņ…“‘ĹĶĶÕīŇŇŐIO—ĻѶ£¨∆ūĶĹ“Ľ∂®”ŇĽĮ◊ų”√°£“Ľį„«ťŅŲŌ¬£¨«ŅŃ“Ĺ®“ť≤Ľ“™–řłńīň÷Ķ°£mongodĹęĪšłŁĶń żĺ›–ī»Žjournalļů‘Ŕ–ī»Žńŕīś£¨≤Ęľš–™–‘ĶńĹęńŕīś żĺ›flushĶĹīŇŇŐ÷–£¨ľī—”≥Ŕ–ī»ŽīŇŇŐ£¨”––ßŐŠ…żīŇŇՖ߬ °£īň÷łŃÓ≤Ľ”įŌžjournalīśīĘ£¨ĹŲ∂‘mongod”––ß°£
3. ŌĶÕ≥≤„√ś”ŇĽĮ
3.1 MongoDBѨŔńŕīś”ŇĽĮ
MongoDB∑ĢőŮ∆ųńŕīś“™¬ķ◊„connection overhead + data size + index
size£¨ľīѨŔ żŅ™Ōķ + »»Ķ„ żĺ› + ňų“ż°£
linux≤Ŕ◊ųŌĶÕ≥ń¨»Ō√ŅłŲѨŔ ż’ľ”√10Mńŕīś°£
Ļ”√ulimit -a ≤ťŅīstack size£¨ľīő™√ŅłŲѨŔ ż’ľ”√Ķńńŕīś°£
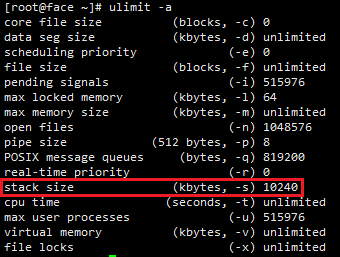
ňý”–ѨŔ żŌŻļńĶńńŕīśľ”∆ūņīŌŗĶĪĺ™»ň£¨Õ∆ľŲį—Stack…Ť÷√–°“ĽĶ„£¨Ī»»ÁňĶ1024£ļ‘ŕlinux√ŁŃÓīįŅŕ š»Žulimit
-s 1024°£’‚÷÷∑Ĺ ĹĶń»ĪĶ„ «£¨÷ō–¬īÚŅ™“ĽłŲshell√ŁŃÓīįŅŕĺÕ ß–ßņ≤£¨–Ť“™÷ō–¬÷ī––’‚“ĽŐű√ŁŃÓ°£
”ņĺ√…ķ–ßĶń∑Ĺ Ĺ£¨–řłń/etc/profile£¨‘ŕ◊ÓļůŐŪľ”ulimit -s 1024£¨»ĽļůĪ£īś≤Ęsource
/etc/profile
3.2 MongoDBѨŔ ż”ŇĽĮ
MongoDBѨŔ ż÷ų“™ «Õ®ĻżŐŠłŖ≤Ŕ◊ųŌĶÕ≥Ķńń¨»ŌőńľĢ√Ť Ų∑ŻļÕĹÝ≥Ő/ŌŖ≥Ő żŌř÷∆°£Linuxń¨»ŌĶńőńľĢ√Ť Ų∑Ż żļÕ◊ÓīůĹÝ≥Ő ż∂‘”ŕMongoDBņīňĶ“Ľį„ĽŠŐęĶÕ°£Ĺ®“ťį—’‚łŲ ż÷Ķ…Ťő™100000“‘…Ō°£“Úő™MongoDB∑ĢőŮ∆ų∂‘√Ņ“ĽłŲ żĺ›Ņ‚őńľĢ“‘ľį√Ņ“ĽłŲŅÕĽß∂ňѨŔ∂ľ–Ť“™”√ĶĹ“ĽłŲőńľĢ√Ť Ų∑Ż°£»ÁĻŻ’‚łŲ ż◊÷Őę–°ĶńĽį‘ŕīůĻśń£≤Ę∑Ę≤Ŕ◊ų«ťŅŲŌ¬Ņ…ń‹ĽŠ≥ŲīŪĽÚőř∑®Ōž”¶°£Ī®“‘Ō¬īŪőů–ŇŌĘ£ļ
"too many
open files"
"too many open connections" |
…Ō√śĪ®īŪĶń–ŇŌĘ£¨ňĶ√ųīÚŅ™ĶńѨŔ żŐę∂ŗŃň£¨”–ŃĹłŲŌř÷∆mongod/mongosѨŔ żĶńĶō∑Ĺ£ļ
ĘŔ ≤Ŕ◊ųŌĶÕ≥ĶńulimitŌř÷∆£¨ĪĺĹŕ÷ōĶ„Ĺť…‹£Ľ
Ęŕ mongodb◊‘…ŪĶńŌř÷∆£Ľ
≤Ŕ◊ųŌĶÕ≥ĶńulimitŌř÷∆£¨Ņ…“‘”√ulimit -a≤ťŅīopen files£¨ «∑ŮĻĽīů°£linuxŌ¬ń¨»ŌĶńopen
files «1024£¨‘ŕŐŠĻ©∑ĢőŮĶń ĪļÚÕýÕýŐę–°°£
Ņ…“‘Õ®Ļż“‘Ō¬√ŁŃÓņī–řłń’‚–©÷Ķ£¨‘› Ī–‘£¨÷ō–¬īÚŅ™shell√ŁŃÓīįŅ༊ ߖߣļ
ulimit -n 1048576
ulimit -u 524288 |
’‚ ĪŅ…“‘Õ®Ļż–řłń/etc/security/limits.conf£®
≤Ņ∑÷ĶńŌĶÕ≥ «‘ŕ/etc/security/limits.d/90-nproc.conf£©≥÷ĺ√ĽĮ…Ť÷√‘ –Ū”√Ľß/ĹÝ≥ŐīÚŅ™őńľĢĺšĪķ ż£¨’‚“Ľ≤Ĺ–Ť“™÷ō∆ŰŌĶÕ≥£¨≤Ľ»Ľ≤Ľ∆ū◊ų”√£¨‘ŕlimits.confŐŪľ”»ÁŌ¬…Ť÷√£ļ
* soft nofile
1048576
* hard nofile 1048576
* soft nproc 524288
* hard nproc 524288 |
3.3 ĻōĪ’Transparent Huge Pages
Transparent Huge Pages(THP) «LinuxĶń“Ľ÷÷ńŕīśĻ‹ņŪ”ŇĽĮ ÷∂ő£¨Õ®Ļż Ļ”√łŁīůĶńńŕīś“≥ņīľű…ŔTranslation
Lookaside Buffer(TLB)Ķń∂ÓÕ‚Ņ™Ōķ°£MongoDB żĺ›Ņ‚īů≤Ņ∑÷ «Ī»ĹŌ∑÷…ĘĶń–°ŃŅ żĺ›∂Ń–ī£¨THP∂‘MongoDB’‚÷÷«ťŅŲĽŠ”–łļ√śĶń”įŌž£¨ňý“‘Ĺ®“ťĻōĪ’°£
‘› Ī–‘Ķń◊Ų∑®£¨ĽŠ ߖߣļ
echo never >
/sys/kernel/mm/transparent _hugepage/enabled
echo never > /sys/kernel/mm/transparent _hugepage/defrag |
”ņĺ√–‘◊Ų∑®£¨–řłń/etc/rc.d/rc.local£¨ŐŪľ”»ÁŌ¬…Ť÷√£ļ
if test -f /sys/kernel/mm/transparent
_hugepage/enabled; then
echo never > /sys/kernel/mm/transparent _hugepage/enabled
fi
if test -f /sys/kernel/mm/transparent _hugepage/defrag;
then
echo never > /sys/kernel/mm/transparent _hugepage/defrag
fi |
3.4 Ļ”√XFSőńľĢŌĶÕ≥£¨Õ¨ ĪĹŻĶŰ żĺ›Ņ‚őńľĢĶńatime
MongoDB‘ŕWiredTigerīśīĘ“ż«śŌ¬Ĺ®“ť Ļ”√XFSőńľĢŌĶÕ≥°£Ext4◊Óő™≥£ľŻ£¨Ķę «”…”ŕextőńľĢŌĶÕ≥Ķńńŕ≤ŅjournalļÕWiredTiger”–ňý≥ŚÕĽ£¨ňý“‘‘ŕIO—ĻѶĹŌīů«ťŅŲŌ¬ĪŪŌ÷≤Ľľ—°£
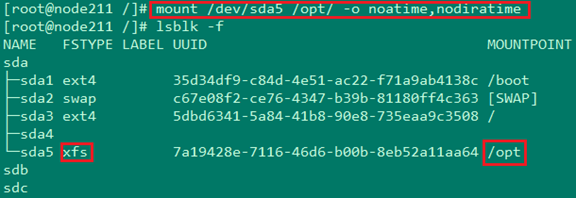
‘ŕ Ļ”√XFSőńľĢŌĶÕ≥ĶńÕ¨ Ī£¨ő“√«Ĺ®“ť‘ŕőńľĢŌĶÕ≥Ķńmount≤ő ż…Ōľ”…Ōnoatime£¨nodiratimeŃĹłŲ—°ŌÓ°£”√noatime
mountĶńĽį£¨őńľĢŌĶÕ≥‘ŕ≥Ő–Ú∑√ő ∂‘”¶ĶńőńľĢĽÚ’ŖőńľĢľ– Ī£¨≤ĽĽŠłŁ––∂‘”¶Ķńaccess time°£
“Ľį„ņīňĶ£¨LinuxĽŠłÝőńľĢľ«¬ľ»żłŲ Īľš£¨change time£¨modify time ļÕ access
time°£ő“√«Ņ…“‘Õ®Ļżstatņī≤ťŅīőńľĢĶń»żłŲ Īľš°£∆š÷–access time÷łőńľĢ◊Óļů“ĽīőĪĽ∂Ń»°Ķń Īľš£¨modify
time÷łĶń «őńľĢĶńőńĪĺńŕ»›◊Óļů∑Ę…ķĪšĽĮĶń Īľš£¨change time÷łĶń «őńľĢĶńinode◊Óļů∑Ę…ķĪšĽĮ£®Ī»»ÁőĽ÷√°Ę”√Ľß Ű–‘°Ę◊ť Ű–‘Ķ»£©Ķń Īľš°£
“Ľį„ņīňĶ£¨őńľĢ∂ľ «∂Ń∂ŗ–ī…ŔĶń£¨∂Ý«“ő“√«“≤ļ‹…ŔĻō–ńń≥“ĽőńľĢ◊ÓĹŁ ≤√ī ĪľšĪĽ∑√ő Ńň£¨ňý“‘£¨ő“√«Ĺ®“ť≤…”√noatime—°ŌÓ£¨’‚—ýőńľĢŌĶÕ≥≤Ľľ«¬ľaccess
time£¨Ī‹√‚ņň∑—◊ ‘ī°£ĹŻ÷ĻŌĶÕ≥∂‘őńľĢĶń∑√ő ĪľšłŁ–¬ĽŠ”––ßŐŠłŖőńľĢ∂Ń»°Ķń–‘ń‹°£
≤Ŕ◊ų»ÁŌ¬£ļ
1) Centos7Ķńį≤◊įxfsprogs-4.5.0-15.el7.x86_64.rpmįŁ£¨∂ÝCentos6Ķńį≤◊įxfsprogs-3.1.1-20.el6.x86_64.rpm°£
rpm -ivh xfsprogs- 3.1.1 -20.el6.x86_64.rpm
2) łŮ ĹĽĮő™XFSőńľĢŌĶÕ≥£¨”–ŃĹ÷÷«ťŅŲ£¨“Ľ «į—“—īś‘ŕĶńExt4Ķ»őńľĢŌĶÕ≥łŮ ĹĽĮő™XFSőńľĢŌĶÕ≥£¨∂Ģ «į—…–őīłŮ ĹĽĮĶńīŇŇճ٠żĮő™XFSőńľĢŌĶÕ≥°£
“Ľ°Ęį—“—īś‘ŕĶńExt4łŮ ĹĽĮő™XFSőńľĢŌĶÕ≥£¨“‘/optńŅ¬ľő™ņż£¨ő“√«į—/opt◊ųő™mongodbĶńį≤◊įľįīśīĘńŅ¬ľ£ļ
ĘŔ ◊Ō» Ļ”√√ŁŃÓ lsblk -f ≤ťŅīīŇŇŐ∑÷«Ýľį∆š∂‘”¶ĶńńŅ¬ľ
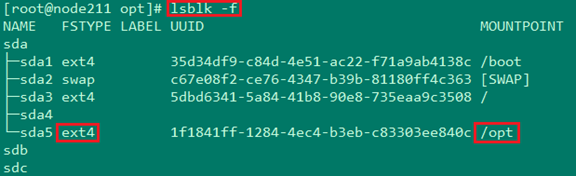
Ęŕ »Ľļů umount /opt į—/optńŅ¬ľ–∂‘ōĶŰ

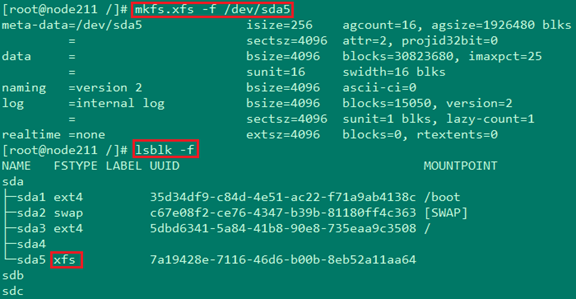
ĘŘ Ļ”√ mkfs.xfs -f /dev/sda5 į—ext4őńľĢŌĶÕ≥ł≤ł«ő™xfsőńľĢŌĶÕ≥£¨≤Ę Ļ”√lsblk
-f≤ťŅī «∑Ů–řłń≥…Ļ¶
Ę‹ Ĺ”◊Ň–řłń/etc/fstabőńľĢ£¨»√ŌĶÕ≥Ņ™Ľķ◊‘∂ĮĻ“‘ōł√īŇŇŐ∑÷«Ýő™/opt£¨‘ŕ/etc/fstabőńľĢņÔ£¨į—/opt∂‘”¶ń«––Ķńext4łńő™xfs£¨≤Ę‘ŕdefaultsļů√śľ”…Ō°į,noatime°Ī£¨į—atimeĹŻĶŰ
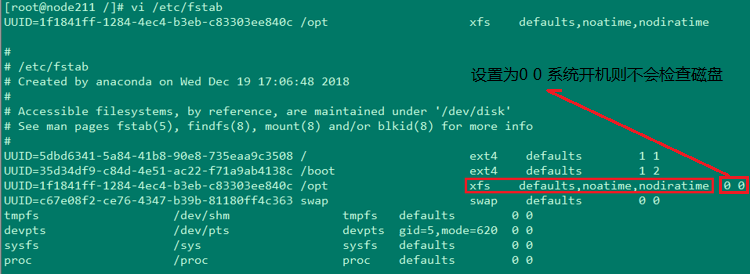
Ę› ◊Óļů£¨į—/optĻ“‘ō…Ō£¨≤ĘĹŻĶŰatime£¨≤Ę”√ lsblk -f ≤ťŅī
∂Ģ°Ęį—…–őīłŮ ĹĽĮĶńīŇŇճ٠żĮő™XFSőńľĢŌĶÕ≥
ĘŔ ◊Ō» Ļ”√√ŁŃÓ fdisk -l ≤ťŅīŅ’Ō–ĶńīŇŇŐ∑÷«Ý
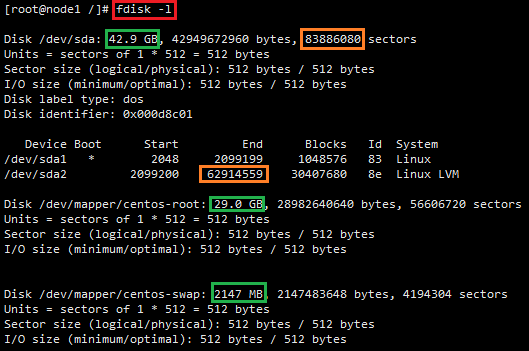
ī”…ŌÕľŅ…“‘Ņī≥ŲīŇŇŐ/dev/sda◊‹īů–°ő™42.9GB£¨/dev/mapper/centos-root’ľ”√29GB£¨∂Ý/dev/mapper/centos-swap’ľ”√2GB£¨Ļ Ņ’”ŗ…–őīłŮ ĹĽĮĶńīŇŇŐīů‘ľ’ľ10GB£ĽīŇŇŐ/dev/sda’ľ”√83886080łŲsectors£¨∂ÝńŅ«į/dev/sda2 Ļ”√ĶĹĶńsectorső™62914559£¨ĽĻ £”ŗ20971521łŲsectors…–őī Ļ”√£¨’‚“≤ «Ņī≥Ų…–őīłŮ ĹĽĮĶńīŇŇŐĶń∑Ĺ∑®£Ľ
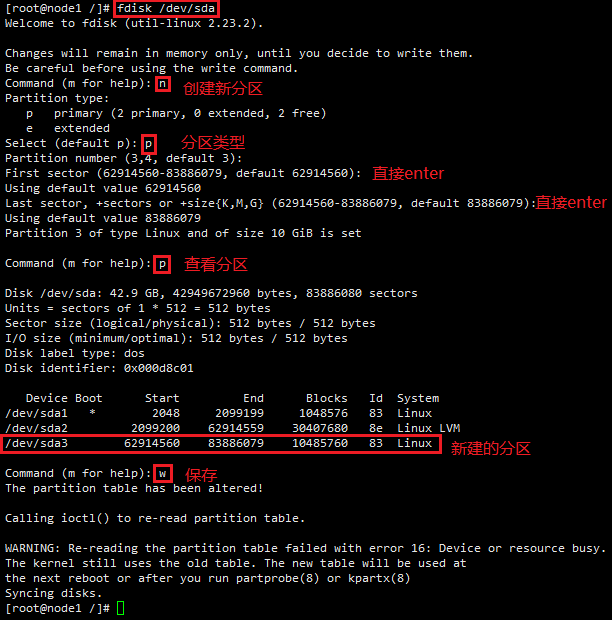
Ęŕ īīĹ®–¬ĶńīŇŇŐ∑÷«Ý
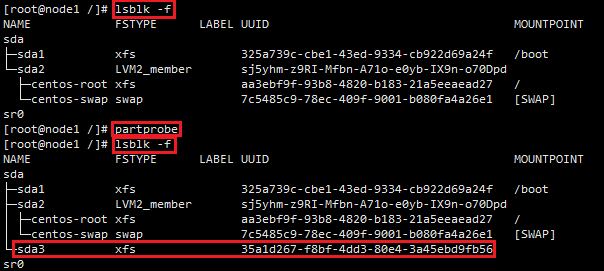
ĘŘ ÷ī––partprobeĽÚ’Ŗ÷ō∆Ű
÷ī–– partprobe √ŁŃÓ”√”ŕĹęīŇŇŐ∑÷«ÝĪŪĪšĽĮ–ŇŌĘÕ®÷™ńŕļň£¨≤Ę«Ž«ů≤Ŕ◊ųŌĶÕ≥÷ō–¬ľ”‘ō∑÷«ÝĪŪ£¨Ņ…“‘Ī‹√‚Īō–Ž÷ō–¬∆Ű∂ĮĶńő Ő‚
÷ī–– partprobe √ŁŃÓ÷ģ«į£¨ Ļ”√ lsblk -f ņī≤ťŅīīŇŇŐ∑÷«Ý£¨√Ľ”–ŅīĶĹ/dev/sda3£Ľ÷ī––
partprobe √ŁŃÓļů£¨‘Ŕīő Ļ”√ lsblk -f ≤ťŅīīŇŇŐ∑÷«Ý
ļů√śĶń≤Ŕ◊ųÕ¨∑Ĺ Ĺ“ĽĶńĘ‹Ę›≤Ŕ◊ų£¨Ļ“‘ō≤ĘĹŻĶŰatime£¨◊Óļů‘ŕ/etc/fstab…Ō√śŐŪľ”/dev/sda3ľį∆š∂‘”¶Ļ“‘ōĶń¬∑ĺ∂
3.5 Ļ”√SSDĽÚRAID10ņīŐŠĻ©īśīĘIOPSń‹Ń¶
MongoDB «“ĽłŲłŖ–‘ń‹łŖ≤Ę∑ĘĶń żĺ›Ņ‚£¨∆šīů≤Ņ∑÷ĶńIO≤Ŕ◊ųő™ňśĽķłŁ–¬°£“Ľį„ņīňĶĪĺĽķ◊‘īÝĶńSSD «◊Óľ—ĶńīśīĘ∑Ĺįł°£»ÁĻŻ Ļ”√∆’Õ®ĶńīŇŇŐ£¨Ĺ®“ť Ļ”√RAID10ŐűīÝĽĮņīŐŠĻ©IOÕ®ĶņĶń≤Ę∑Ęń‹Ń¶°£
◊Ę“‚£ļ
IOPS (Input/Ouput Operations Per Second)£ļ «īśīĘ…ŤĪł√Ņ√Ž∂Ń–īĶńīő ż°£
RAID10£ļRAID1 + RAID0ĶńĹŠļŌ£¨RAID1 «“ĽłŲ»Ŗ”ŗĶńĪł∑›’ůŃ–£¨RAID0 «łļ‘ū żĺ›Ķń∂Ń–ī’ůŃ–°£ņż»Á£ļīŇŇŐ1ļÕīŇŇŐ2◊ť≥…“ĽłŲRaid1£¨īŇŇŐ3ļÕīŇŇŐ4”÷◊ť≥…ŃŪÕ‚“ĽłŲRaid1;’‚ŃĹłŲRaid1◊ť≥…Ńň“ĽłŲ–¬ĶńRaid0°£∆š÷–īŇŇŐ1ļÕīŇŇŐ2Ķń żĺ› «ŌŗĽ•Īł∑›Ķń£¨īŇŇŐ3ļÕīŇŇŐ4Ķń żĺ› «ŌŗĽ•Īł∑›Ķń°£
3.6 ő™DataļÕJournal/log∑÷Īū Ļ”√Ķ•∂ņĶńőÔņŪĺŪ
MongoDBļ‹∂ŗĶń–‘ń‹∆ŅĺĪļÕIOŌŗĻō°£Ĺ®“ťő™»’÷ĺŇŐ(JournalļÕMongoDBŌĶÕ≥»’÷ĺ)Ķ•∂ņ…Ť∂®“ĽłŲőÔņŪĺŪ£¨ľű…Ŕ∂‘ żĺ›ŇŐIOĶń◊ ‘ī’ľ”√°£
MongoDBŌĶÕ≥»’÷ĺŅ…“‘÷ĪĹ”‘ŕ√ŁŃÓ––ĽÚ’ŖŇš÷√őńľĢ≤ő żńŕ÷ł∂®°£Journal»’÷ĺ≤Ľ÷ß≥÷÷ĪĹ”÷ł∂®ĶĹŃŪÕ‚ĶńńŅ¬ľ£¨Ņ…“‘Õ®Ļż∂‘JournalńŅ¬ľīīĹ®symbol
linkĶń∑Ĺ ĹņīĹ‚ĺŲ°£
»Á£¨/resourceńŅ¬ľļÕ /optńŅ¬ľ∑÷Īū «ŃĹłŲ≤ĽÕ¨ĶńőÔņŪīŇŇŐ£¨
dataīśīĘ żĺ›…Ť÷√‘ŕ /resource ńŅ¬ľ£¨Õ®Ļż»ÁŌ¬Ňš÷√≤ő ż…Ť÷√
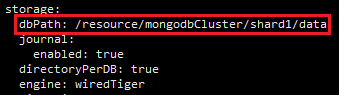
JournalļÕlog żĺ›…Ť÷√‘ŕ /opt ńŅ¬ľ£¨Õ®Ļż»ÁŌ¬Ňš÷√≤ő ż…Ť÷√

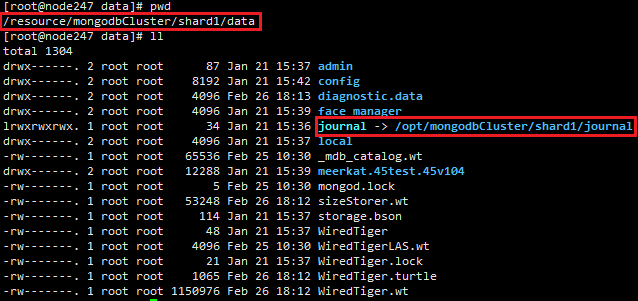
Journal»’÷ĺ «MongoDBĶń‘§∂Ń–ī»’÷ĺ£¨”√”ŕ żĺ›Ņ‚Īņņ£ ĪĶń żĺ›Ľ÷łī£¨Ņ…“‘‘ŕŇš÷√őńľĢŇš÷√≤ő żĹŻĶŰ£¨Õ®≥£…ķ≤ķĽ∑ĺ≥≤ĽĹ®“ťĹŻĶŰ°£Journal“Ľį„ «‘ŕdataīśīĘńŅ¬ľŌ¬£¨Õ®ĻżīīĹ®»ŪѨŔsymbol
linkņīį—¬∑ĺ∂“żĶĹ/optńŅ¬ľŌ¬
ln -s /resource/mongodbCluster/shard1/data/journal
/opt/mongodbCluster/shard1/journal
3.7 ĹŻ”√NUMA
∑«“Ľ÷¬īśīĘ∑√ő ĹŠĻĻ£®NUMA£ļNon-Uniform Memory Access£© «◊Ó–¬ĶńńŕīśĻ‹ņŪľľ ű°£‘ŕ“ĽłŲ Ļ”√NUMAľľ űĶń∂ŗī¶ņŪ∆ųLinuxŌĶÕ≥…Ō£¨ĶĪńŕīś≤Ľ◊„ Ī£¨ĽŠ≤…”√SWAPĶń∑Ĺ ĹņīĽŮĶ√ńŕīś£¨∂ÝSWAPĽŠĶľ÷¬ żĺ›Ņ‚–‘ń‹ľĪĺÁŌ¬ĹĶ£¨ňý“‘”¶ł√ĹŻ÷ĻNUMAĶń Ļ”√°£ŃŪÕ‚£¨MongoDB‘ŕNUMAĽ∑ĺ≥Ō¬‘ň–––‘ń‹”– ĪļÚŅ…ń‹ĽŠĪš¬ż£¨ŐōĪū «‘ŕĹÝ≥Őłļ‘ōļ‹łŖĶń«ťŅŲŌ¬°£
ĹŻ”√NUMAĶń∑Ĺ∑®£¨‘ŕmongod«į√śľ”°įnumactl --interleave=all°Ī£ļ
numactl --interleave=all /opt/app/mongodb/bin/mongod
-f /opt/app/mongodbCluster/conf/config.conf
3.8 …Ť÷√vm.swappiness
vm.swappiness «≤Ŕ◊ųŌĶÕ≥Ņō÷∆őÔņŪńŕīśĹĽĽĽ≥Ų»•Ķń≤Ŗ¬‘°£ňŁ‘ –ŪĶń÷Ķ «“ĽłŲįŔ∑÷Ī»Ķń÷Ķ£¨◊Ó–°ő™0£¨◊Óīůő™100£¨ł√÷Ķń¨»Ōő™60.
vm.swappiness…Ť÷√ő™0ĪŪ ĺĺ°ŃŅ…Ŕswap£¨100ĪŪ ĺĺ°ŃŅĹęinactiveĶńńŕīś“≥ĹĽĽĽ≥Ų»•°£
ĺŖŐŚĶńňĶ£¨ĶĪńŕīśĽýĪĺ”√¬ķĶń ĪļÚ£¨ŌĶÕ≥ĽŠłýĺ›’‚łŲ≤ő żņīŇ–∂Ō «į—ńŕīś÷–ļ‹…Ŕ”√ĶĹĶńinactiveńŕīśĹĽĽĽ≥Ų»•£¨ĽĻ « Õ∑Ň żĺ›Ķńcache°£cache÷–Ľļīś◊Ňī”īŇŇŐ∂Ń≥ŲņīĶń żĺ›£¨łýĺ›≥Ő–ÚĶńĺ÷≤Ņ–‘‘≠ņŪ£¨’‚–© żĺ›”–Ņ…ń‹‘ŕĹ”Ō¬ņī”÷“™ĪĽ∂Ń»°£ĽinactiveńŕīśĻň√Żňľ“Ś£¨ĺÕ «ń«–©ĪĽ”¶”√≥Ő–Ú”≥…š◊Ň£¨Ķę «°į≥§ Īľš°Ī≤Ľ”√Ķńńŕīś°£
ő“√«Ņ…“‘ņŻ”√vmstatŅīĶĹinactiveĶńńŕīś żŃŅ£¨“≤Ņ…“‘Õ®Ļż /proc/meminfo ŅīĶĹłŁŌÍŌłĶń–ŇŌĘ£ļ
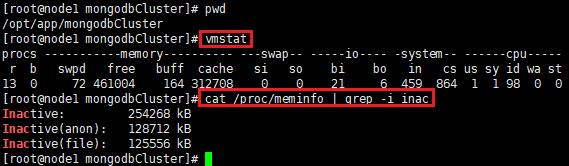
MonogDBĪĺ…Ū“≤ «“ĽłŲńŕīś Ļ”√ŃŅĹŌīůĶń żĺ›Ņ‚£¨ňŁ’ľ”√ĶńńŕīśĪ»ĹŌ∂ŗ£¨≤Ľĺ≠≥£∑√ő Ķńńŕīś“≤ĽŠ≤Ľ…Ŕ£¨’‚–©ńŕīś»ÁĻŻĪĽlinuxīŪőůĶńĹĽĽĽ≥Ų»•Ńň£¨Ĺęņň∑—ļ‹∂ŗCPUļÕIO◊ ‘ī£¨ľęīůĶōĹĶĶÕ żĺ›Ņ‚Ķń–‘ń‹°£»ÁĻŻvm.swappiness…Ť÷√ő™0£¨ĽŠīÝņīńŕīś“Á≥ŲĶńő Ő‚£¨ĶĪńŕīś≤Ľ◊„ Ī£¨ĽŠ«Ņ÷∆į—ń≥–©≥Ő–ÚkillĶŰ°£ňý“‘◊Óļ√‘ŕMongoDBĶń∑ĢőŮ∆ų…Ō…Ť÷√vm.swappinessĶń÷Ķ‘ŕ1~10÷ģľš£¨ĺ°Ņ…ń‹…ŔĶō Ļ”√swap°£»ÁĻŻ∑ĢőŮ∆ųńŕīśĪ»ĹŌīů Ī£¨Ņ…“‘Ņľ¬«…Ť÷√vm.swappiness=0°£
3.9 –řłńīŇŇŐĶų∂»ň„∑®
∂‘”ŕīŇŇŐI/O£¨LinuxŐŠĻ©ŃňCompletely Fair Queuing(CFQ)£¨Deadline
schedulerļÕNOOP»ż÷÷Ķų∂»≤Ŗ¬‘
ńŅ«įLinuxń¨»ŌĶų∂»≤Ŗ¬‘ «CFQ£¨ňŁ…ý≥∆∂‘√Ņ“ĽłŲIO«Ž«ů∂ľ «Ļę∆ĹĶń£¨’‚÷÷Ķų∂»≤Ŗ¬‘∂‘īů≤Ņ∑÷”¶”√∂ľ « ”√Ķń°£Ķę «»ÁĻŻ żĺ›Ņ‚”–ŃĹłŲ«Ž«ů£¨“ĽłŲ«Ž«ů3īőIO£¨“ĽłŲ«Ž«ů10000īőIO£¨”…”ŕĺÝ∂‘Ļę∆Ĺ£¨3īőIOĶń«Ž«ů–Ť“™łķ10000īőIOĶń«Ž«ůĺļ’ý£¨Ņ…ń‹“™Ķ»īż…Ō«ßłŲIOÕÍ≥…≤Ňń‹∑ĶĽō£¨Ķľ÷¬ňŁĶńŌž”¶ Īľš∑«≥£¬ż°£≤Ę«“»ÁĻŻ‘ŕī¶ņŪĶńĻż≥Ő÷–£¨”÷”–ļ‹∂ŗIO«Ž«ů¬Ĺ–Ý∑ĘňÕĻżņī£¨≤Ņ∑÷IO«Ž«ů…ű÷ŃŅ…ń‹“Ľ÷Īőř∑®Ķ√ĶĹĶų∂»ĪĽ°į∂Ųňņ°Ī°£∂ÝDeadline
schedulerĶų∂»≤Ŗ¬‘‘ÚŅ…“‘ľśĻňĶĹ“ĽłŲ«Ž«ů≤ĽĽŠ‘ŕ∂”Ń–÷–Ķ»īżŐęĺ√Ķľ÷¬∂Ųňņ£¨∂‘ żĺ›Ņ‚’‚÷÷”¶”√ņīňĶłŁľ” ”√°£
‘› Ī–‘…Ť÷√£¨ĽŠ ߖߣļ
echo deadline > /sys/block/sda/queue/scheduler
”ņĺ√–‘…Ť÷√£¨∂‘”ŕCentos6ņīňĶ£¨‘ŕ/etc/grub.confĶńkernel––◊ÓļůŐŪľ”elevator=deadlineņī”ņĺ√…ķ–ߣļ

∂‘”ŕCentos7ņīňĶ£¨÷ī––»ÁŌ¬√ŁŃÓ£ļ
grubby --update-kernel=ALL --args="elevator=deadline"
»Ľļů÷ō∆Ű…ķ–ß°£
◊Ę“‚£ļ
“Ľį„Centos7ń¨»Ō÷ß≥÷Ķń «deadlineň„∑®£¨∂ÝCentos6ń¨»Ō÷ß≥÷Ķńcfq£¨∂Ý“Ľį„ő“√«ĽŠ‘ŕSSD”≤ŇŐĽ∑ĺ≥÷– Ļ”√noopň„∑®°£
3.10 ‘§∂Ń÷Ķ(readahead)…Ť÷√
‘§∂Ń÷Ķ «őńľĢ≤Ŕ◊ųŌĶÕ≥Ķń“ĽłŲ”ŇĽĮ ÷∂ő°£Linux‘§∂Ńń¨»Ō256łŲ…»«Ý£¨īů–°ő™128K°£MongoDBļ‹∂ŗ∂ľ «ňśĽķ∑√ő £¨∂‘”ŕňśĽķ∑√ő £¨‘§∂Ń÷Ķreadhead”¶ł√…Ť÷√ĹŌ–°ő™ļ√°£≤…”√LinuxĶńblockdev√ŁŃÓņīį—‘§∂Ńreadhead…Ť÷√–°“ĽĶ„£¨Ņ…“‘ľű…Ŕńŕīś÷–őř”√ żĺ›’ľ”√£¨ī”∂ݔҼĮIO–‘ń‹°£RAīķĪŪ‘§∂Ńīů–°£®…»«Ý£©£¨Õ∆ľŲ ż÷Ķ «16ĶĹ32£¨»ÁőńĶĶĹŌ–°£¨‘§∂Ń ż÷ĶŅ…“‘–°“ĽĶ„£¨–řłńļůMongoDB÷ō∆Ű≤Ňń‹…ķ–ß°£
Ņ…“‘ Ļ”√Ō¬ Ų√ŁŃÓņīŌ‘ ĺĶĪ«įŌĶÕ≥Ķń‘§∂Ń÷Ķ£ļ
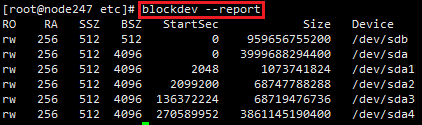
‘› Ī–‘łŁłń‘§∂Ń÷Ķ£¨÷ī––√ŁŃÓ blockdev --setra 32 /dev/sdb £¨/dev/sdbő™mongodbīśīĘĶńīŇŇŐ…ŤĪł£ļ
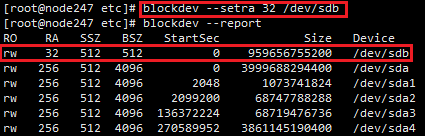
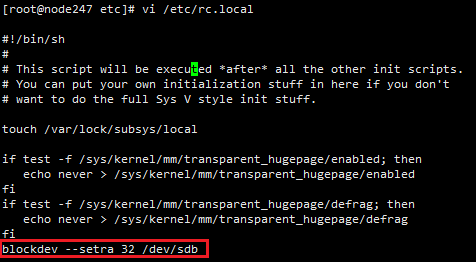
”ņĺ√–‘łŁłń£¨Ĺę blockdev --setra 32 /dev/sdb –ī»ŽŇš÷√őńľĢ/etc/rc.local£¨∑Ů‘Ú÷ō∆ŰĺÕĽŠ ߖߣļ
3.11 …Ť÷√Linuxńŕļň≤ő ż
īÚŅ™/etc/sysctl.conf£¨‘ŕņÔ√śŐŪľ”»ÁŌ¬ńŕ»›£ļ
#≤Ę∑ĘѨŔbacklog…Ť÷√
net.core.somaxconn=32768
net.core.netdev_max_backlog=16384
net.core.rmem_default=262144
net.core.wmem_default=262144
net.core.rmem_max=16777216
net.core.wmem_max=16777216
net.core.optmem_max=16777216
#Ņ…”√÷™√Ż∂ňŅŕ∑∂őß:
net.ipv4.ip_local_port_range ='1024 65535'
net.ipv4.tcp_max_syn_backlog =16384
#TCP Socket ∂Ń–ī Buffer …Ť÷√:
net.ipv4.tcp_rmem= '1024 4096 16777216'
net.ipv4.tcp_wmem= '1024 4096 16777216' |
ŐŪľ”ÕÍ÷ģļů£¨≤Ľ÷ō∆ŰłŁ–¬£ļsysctl -p
| 








