| БрМЭЦМі: |
БОНкжївЊНщЩм
СЫадФмгХЛЏЗжРрЁЂ ШэМўВуУцгХЛЏЁЂЯЕЭГВуУцгХЛЏЕШЗНУцФкШнЁЃ
БОЮФРДздЬкбЖдЦЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
ЫцзХЙњФкЗўЮёЙВЯэЛЏЕФШШГБЦеМАЃЌЙВЯэЕЅГЕЃЌЙВЯэгъЩЁЃЌЙВЯэГфЕчБІЕШИїжжЗўЮёШчгъКѓДКЫёЃЌЫцжЎЖјРДЕФLBSЗўЮёЖЈЮЛЮЪЬтГЩЮЊСЫКѓЖЫЗўЮёЕФвЛИіЬєеНЁЃMongoDBЖдLBSВщбЏЕФжЇГжНЯЮЊгбКУЃЌвВЪЧИїДѓLBSЗўЮёЩЬЕФЪзбЁЪ§ОнПтЁЃЬкбЖдЦMongoDBЭХЖгдкдЫгЊжаЗЂЯжЃЌдЩњMongoDBдкLBSЗўЮёГЁОАЯТгаНЯДѓЕФадФмЦПОБЃЌОЬкбЖдЦЭХЖгзЈвЕЕФЖЈЮЛЗжЮігыгХЛЏКѓЃЌдЦMongoDBдкLBSЗўЮёЕФзлКЯадФмЩЯЃЌга10БЖвдЩЯЕФЬсЩ§ЁЃ
ЬкбЖдЦMongoDBЬсЙЉЕФгХвьзлКЯадФмЃЌЮЊЙњФкИїДѓLBSЗўЮёЩЬЃЌР§ШчФІАнЕЅГЕЕШЃЌЬсЙЉСЫЧПгаСІЕФБЃеЯЁЃ
LBSвЕЮёЬиЕу
вдЙВЯэЕЅГЕЗўЮёЮЊР§ЃЌLBSвЕЮёОпга2ИіЬиЕуЃЌЗжБ№ЪЧЪБМфжмЦкадКЭзјБъЗжВМВЛОљдШЁЃ
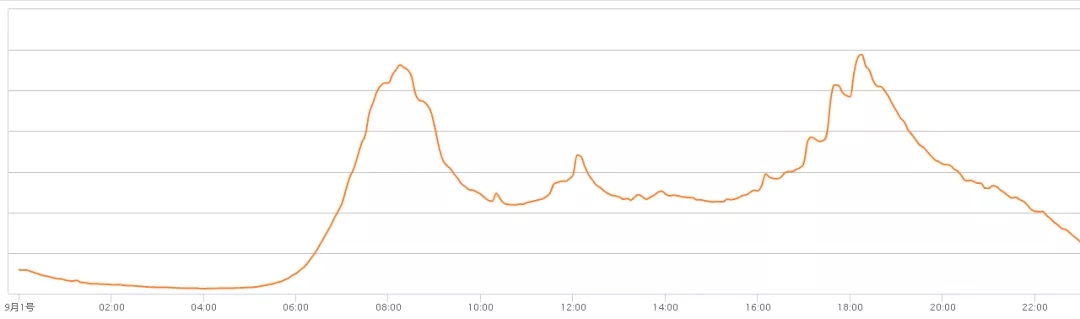
вЛЃЎЪБМфжмЦкад
ИпЗхЦкгыЕЭЙШЦкЕФQPSСПЯрВюУїЯдЃЌВЂЧвИпЗхЦкКЭЕЭЗхЦкЕФЪБМфЕуЯрЖдЙЬЖЈЁЃ
Жў.зјБъЗжВМВЛОљдШ
зјЕиЬњЕФЩЯАрзхЃЌШчЙћСєвтПЩФмЛсЗЂЯжЃЌдкЩЯАрдчИпЗхЪБЃЌЕиЬњжмЮЇАкТњСЫЙВЯэЕЅГЕЃЌЖјЯТАр ЪБЖЮЃЌЕиЬњжмЮЇЕФЙВЯэЕЅГЕЪ§СПЗЧГЃЩйЁЃШчЯТЭМЃЌОЮГЖШЃЈ121ЃЌ31.44ЃЉИННќМЏжаСЫ99%вдЩЯ
ЕФзјБъЁЃДЫЭтЃЌвЛаЉЬиЪтЪТМўвВЛсдьГЩЕуЕФЗжВМВЛОљдШЃЌР§ШчЩюлкЭхЙЋдАдкЬиЪтМвМйШегПШыДѓСПЕФПЭЛЇЃЌЭЌЪБетИіЕигђвВЛсЭЖЗХДѓСПЕФЕЅГЕЁЃВПЗжЕигђЕЅГЕСПЗЧГЃМЏжаЃЌЖјЦфЫћЕигђОЭЗЧГЃЯЁЪшЁЃ
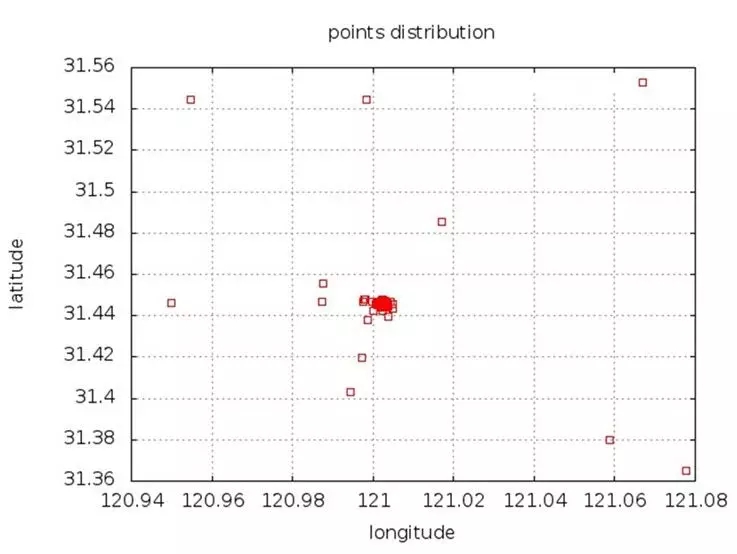
MongoDBЕФLBSЗўЮёдРэ
MongoDBжаЪЙгУ2d_index Лђ2d_sphere_indexРДДДНЈЕиРэЮЛжУЫїв§(geoIndex),СНепВюБ№ВЛДѓЃЌЯТУцЮвУЧвд2d_indexЮЊР§РДНщЩмЁЃ
вЛЃЎ2DЫїв§ЕФДДНЈгыЪЙгУ
db.coll.createIndex({"lag":"2d"},
{"bits":int}))ЭЈЙ§ЩЯЪіУќСюРДДДНЈвЛИі2dЫїв§ЃЌЫїв§ЕФОЋЖШЭЈЙ§bitsРДжИЖЈЃЌbitsдНДѓЃЌЫїв§ЕФОЋЖШОЭдНИпЁЃИќДѓЕФbitsДјРДЕФВхШыЕФoverheadПЩвдКіТдВЛМЦ
db.runCommand ({geoNear: tableName,maxDistance: 0.0001567855942887398,distanceMultiplier:
6378137.0,num: 30,near: [ 113.8679388183982, 22.58905429302385
],spherical: true|false})
ЭЈЙ§ЩЯЪіУќСюРДВщбЏвЛИіЫїв§ЃЌЦфжаsphericalЃКtrue|false БэЪОгІИУШчКЮРэНтДДНЈЕФ2dЫїв§ЃЌfalseБэЪОНЋЫїв§РэНтЮЊЦНУц2dЫїв§ЃЌtrueБэЪОНЋЫїв§РэНтЮЊЧђУцОЮГЖШЫїв§ЁЃетвЛЕуБШНЯгавтЫМЃЌвЛИі2dЫїв§ПЩвдБэДяСНжжКЌвхЃЌЖјВЛЭЌЕФКЌвхЪЧдкВщбЏЪББЛРэНтЕФЃЌЖјВЛЪЧдкЫїв§ДДНЈЪБЁЃ
ЖўЃЎ2DЫїв§ЕФРэТлMongoDB ЪЙгУGeoHashЕФММЪѕРДЙЙНЈ2dЫїв§ЁЃMongoDBЪЙгУЦНУцЫФВцЪїЛЎЗжЕФЗНЪНРДЩњГЩGeoHashIdЃЌУПЬѕМЧТМгавЛИіGeoHashIdЃЌЭЈЙ§GeoHashId->RecordIdЕФЫїв§гГЩфЗНЪНДцДЂдкBtreeжа
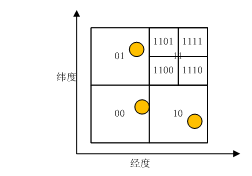
КмЯдШЛЕФЃЌвЛИі2bitsЕФОЋЖШФмАбЦНУцЗжЮЊ4ИіgridЃЌвЛИі4bitsЕФОЋЖШФмАбЦНУцЗжЮЊ16ИіgridЁЃ
2dЫїв§ЕФФЌШЯОЋЖШЪЧГЄПэИїЮЊ26ЃЌЫїв§АбЕиЧђЗжЮЊ(2^26)(2^26)ПщЃЌУПвЛПщЕФБпГЄЙРЫуЮЊ2PI6371000/(1<<26)
= 0.57 Уз
mongodbЕФЙйЭјЩЯЫЕЕФ60cmЕФОЋЖШОЭЪЧетУДЙРЫуГіРДЕФ
By default, a 2d index on legacy coordinate pairs
uses 26 bits of precision, which isroughly equivalent
to 2 feet or 60 centimeters of precision using the
default range of-180 to 180
Ш§.2DЫїв§дкMongodbжаЕФДцДЂ
ЩЯУцЮвУЧНВЕНMongodbЪЙгУЦНУцЫФВцЪїЕФЗНЪНМЦЫуGeohashЁЃЪТЪЕЩЯЃЌЦНУцЫФВцЪїНіДцдкгкдЫЫуЕФЙ§ГЬжаЃЌдкЪЕМЪДцДЂжаВЂВЛЛсБЛЪЙгУЕНЁЃ
ВхШыЖдгквЛИіОЮГЖШзјБъ[x,y]ЃЌMongoDbМЦЫуГіИУзјБъдк2dЦНУцФкЕФgridБрКХЃЌИУБрКХЮЊЪЧвЛИі52bitЕФint64РраЭЃЌИУРраЭБЛгУзїbtreeЕФkeyЃЌвђДЫЪЕМЪЪ§ОнЪЧАДее
{GeoHashId->RecordValue}ЕФЗНЪНБЛВхШыЕНbtreeжаЕФЁЃ
ВщбЏЖдгкgeo2DЫїв§ЕФВщбЏЃЌГЃгУЕФгаgeoNearКЭgeoWithinСНжжЁЃgeoNearВщевОрРыФГИіЕузюНќЕФNИіЕуЕФзјБъВЂЗЕЛиЃЌИУашЧѓПЩвдЫЕЪЧЙЙГЩСЫLBSЗўЮёЕФЛљДЁЃЈФАФАЃЌЕЮЕЮЃЌФІАнЃЉЃЌgeoWithinЪЧВщбЏвЛИіЖрБпаЮФкЕФЫљгаЕуВЂЗЕЛиЁЃЮвУЧзХжиНщЩмЪЙгУзюЙуЗКЕФgeoNearВщбЏЁЃ
geoNearЕФВщбЏЙ§ГЬ,ВщбЏгяОфШчЯТ
db.runCommand({geoNear: "places", //table
Namenear: [ -73.9667, 40.78 ] , // central pointspherical:
true, // treat the index as a spherical indexquery:
{ category: "public" } // filtersmaxDistance:
0.0001531 // distance in about one kilometer}
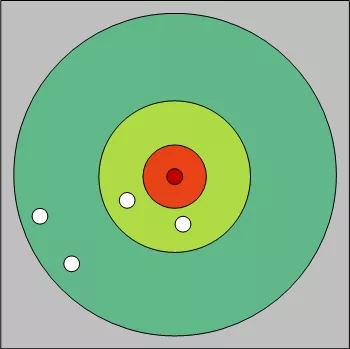
geoNearПЩвдРэНтЮЊвЛИіДгЦ№ЪМЕуПЊЪМЕФВЛЖЯЯђЭтРЉЩЂЕФЛЗаЮЫбЫїЙ§ГЬЁЃШчЯТЭМЫљЪОЃК
гЩгкдВздЩэЕФаджЪЃЌЭтЛЗЕФШЮвтЕуЕНдВаФЕФОрРывЛЖЈДѓгкФкЛЗШЮвтЕуЕНдВаФЕФОрРыЃЌЫљвдвддВ
ЛЗНјааРЉеХЕќДњЕФКУДІЪЧЃК1ЃЉМѕЩйашвЊХХађБШНЯЕФЕуЕФИіЪ§2ЃЉФмЙЛОЁдчЗЂЯжТњзуЬѕМўЕФЕуДгЖјЗЕЛиЃЌБмУтВЛБивЊЕФЫбЫїMongoDBдкЪЕЯжЕФЯИНкжаЃЌШчЙћФкЛЗЫбЫїЕНЕФЕуЪ§Й§ЩйЃЌдВЛЗУПДЮРЉеХЕФВНГЄЛсБЖді
MongoDB LBSЗўЮёгіЕНЕФЮЪЬт
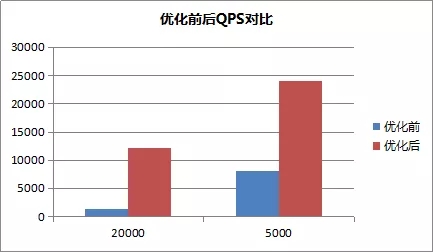
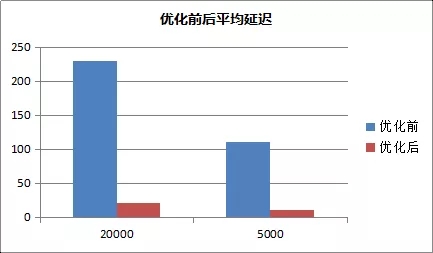
ВПЗжДѓПЭЛЇдкЪЙгУMongoDBЕФgeoNearЙІФмВщевИННќЕФЖдЯѓЪБЃЌОГЃЛсЗЂЩњТ§ВщбЏНЯЖрЕФЮЪЬтЃЌдчИпЗхбЙСІЪЧЕЭЙШЪБЖЮЕФ10-20БЖЃЌзјБъВЛОљдШЕФЧщПіТ§ВщбЏбЯжиЃЌБєСйбЉБРЁЃГѕВНЗжЮіЗЂЯжЃЌетаЉВщбЏЩЈУшСЫЙ§ЖрЕФЕуМЏЁЃ
ШчЯТЭМЃЌВщев500УзЗЖЮЇФкЃЌОрРызюНќЕФ10ЬѕМЧТМЃЌЛЈЗбСЫ500msЃЌЩЈУшСЫ24000+ЕФМЧТМЁЃРрЫЦЕФТ§ВщбЏеМОнСЫИпЗхЦк5%зѓгвЕФВщбЏСП
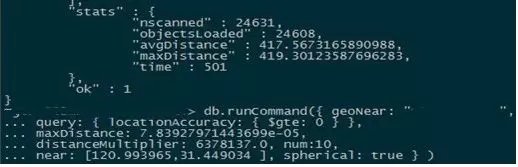
ВтЪдЛЗОГИДЯжгыЖЈЮЛХХВщЪ§ОнПтЕФадФмЮЪЬтЃЌжївЊДгЫјЕШД§,IOЕШД§,CPUЯћКФШ§ЗтУцЗжЮіЁЃЩЯУцЕФНиЭМЩЈУшСЫЙ§ЖрЕФМЧТМЃЌжБОѕЩЯЪЧCPUЛђепIOЯћКФадЕФЦПОБЁЃЮЊСЫбЯНїЦ№МћЃЌЮвУЧдкВтЪдЛЗОГИДЯжКѓЃЌЗЂЯжТ§ШежОжаЮоУїЯдЕФtimeAcquiringMicrosecondsЯюХХГ§СЫMongoDBжДааВуУцЕФЫјОКељЮЪЬтЃЌВЂбЁгУНЯДѓФкДцЕФЛњЦїЪЙЕУЪ§ОнГЃзЄФкДцЃЌЗЂЯжЩЯЪігУР§вРОЩашвЊ200msвдЩЯЕФжДааЪБМфЁЃ10КЫЕФCPUзЪдДеыЖдНиЭМжаЕФcaseЃЌжЛФмжЇГж50QPSЁЃ
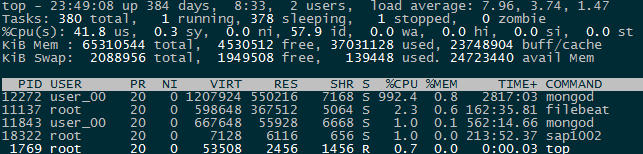
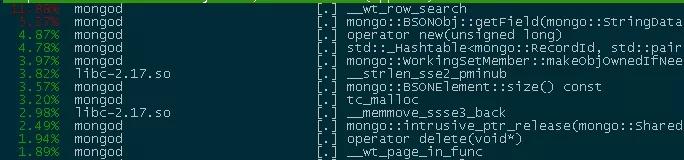
ЮЊКЮЩЈУшМЏШчДЫДѓЩЯУцЮвУЧЫЕЙ§ЃЌMongoDBЫбЫїОрРызюНќЕФЕуЕФЙ§ГЬЪЧвЛИіЛЗаЮРЉеХЕФЙ§ГЬЃЌШчЙћФкЛЗТњзуЬѕМўЕФЕуВЛЙЛЖрЃЌУПДЮЕФРЉеХАыОЖЖМЛсБЖдіЁЃвђДЫдкгіЕНФкЛЗЕуЯЁЩйЃЌЭтЛЗгаУмМЏЕуЕФГЁОАЪБЃЌШнвзЯнШыBadCaseЁЃШчЯТЭМЃЌЮвУЧЯЃЭћевЕНРыжааФЕуОрРызюНќЕФШ§ИіЕуЁЃгЩгкдВЛЗРЉеХЬЋПьЃЌЭтЛЗзіСЫКмЖрЕФЮогУЩЈУшгыХХађЁЃ
етбљЕФгУР§КмЗћКЯЪЕМЪГЁОАЃЌдчИпЗхГЕСООлМЏдкЕиЬњжмЮЇЃЌФуДгМвГіЗЂвЛТЗЯђЕиЬњЃЌБпзпБпевЃЌЙВЯэЕЅГЕШэМўЩЯЖЏЬЌЫбЫїОрФузюНќЕФ10СОГЕЃЌИННќжЛгаШ§СНСОЃЌгкЪЧРЉДѓЫбЫїАыОЖЕНЕиЬњжмЮЇЃЌНЋЕиЬњжмЮЇЕФЫљгаМИЧЇСОГЕЖМЩЈУшМЦЫувЛБщЃЌЗЕЛиОрРыФузюНќЕФЦфгрЕФЦпАЫСО
ЮЪЬтЕФНтОі
ЮЪЬтЮвУЧвбОжЊЕРСЫЃЌЮвУЧЖдДЫЕФгХЛЏЗНЪНЪЧПижЦУПвЛШІЕФЫбЫїСПЃЌЮЊДЫЮвУЧЮЊgeoNearУќСюдіМгСЫСНИіВЮЪ§ЃЌНЋЦфДЋШыNearStageжаЁЃhintCorrectNumПЩвдПижЦНсЙћЦЗжЪЕФЯТЯоЃЌЗЕЛиЕФЧАNИівЛЖЈЪЧзюППНќжааФЕуЕФNИіЕуЁЃhintScanгУвдПижЦЩЈУшМЏЕФДѓаЁЕФЩЯЯоЁЃ
hintScan: вбОЩЈУшЕФЕуМЏДѓаЁДѓгкhintScanКѓЃЌзіФЃК§ДІРэЁЃ
hintCorrectNum:вбОЗЕЛиЕФНсЙћЪ§ДѓгкhintCorrectNumКѓЃЌзіФЃК§ДІРэЁЃ
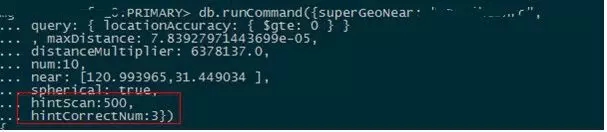
ИУгХЛЏБОжЪЩЯЪЧЭЈЙ§ЮўЩќЦЗжЪРДОЁПьЗЕЛиНсЙћЁЃЖдгкЙњФкДѓВПЗжLBSЗўЮёРДЫЕЃЌЭъШЋЕФбЯИёзюНќВЂВЛЪЧБивЊЕФЁЃЧвПЩвдЭЈЙ§ПижЦВЮЪ§ЛёЕУбЯИёзюНќЕФаЇЙћЁЃдкЫбЫїЙ§ГЬжаЃЌУмМЏЕФЕуТфЕНвЛИіЛЗФкЃЌБОЩэОрРыЯрВювВВЛЛсВЛДѓЁЃИУгХЛЏдкЩЯЯпКѓЃЌНЋВПЗжДѓПЭЛЇЕФMongoDBадФмЩЯЯоДгЕЅЛњ1000QPSЬсЩ§СЫ10БЖЕН10000QPSвдЩЯЁЃ
КЭRedis3.2ЕФЖдБШ
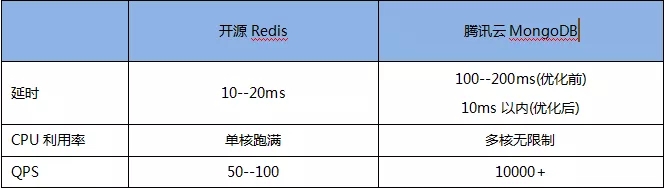
Redis3.2вВМгШыСЫЕиРэЮЛжУВщбЏЕФЙІФмЃЌЮвУЧвВНЋПЊдДRedisКЭдЦЪ§ОнПтMongoDBНјааЖдБШЁЃ
RedisЪЙгУЗНЪНЃКGEORADIUS appname 120.993965 31.449034 500
m count 30 ascЁЃдкУмМЏЪ§ОнМЏГЁОАЯТЃЌЪЙгУЬкбЖдЦMongoDBКЭПЊдДЕФRedisНјааСЫадФмЖдБШЁЃЯТЭМЪЧдкУмМЏЪ§ОнМЏЩЯЃЌдк24КЫCPUЛњЦїЩЯЃЌMongoDBЕЅЪЕР§гыRedisЕЅЪЕР§ЕФВтЪдЖдБШЁЃашвЊзЂвтЕФЪЧRedisБОЩэЪЧЕЅЯпГЬЕФФкДцЛКДцЪ§ОнПтЁЃMongoDBЪЧЖрЯпГЬЕФИпПЩгУГжОУЛЏЕФЪ§ОнПтЃЌСНепЕФЪЙгУГЁОАгаНЯДѓВЛЭЌЁЃ
змНс
MongoDBдЩњЕФgeoNearНгПкЪЧЙњФкИїДѓLBSгІгУЕФжїСїбЁдёЁЃдЩњMongoDBдкЕуМЏГэУмЕФЧщПіЯТЃЌgeoNearНгПкаЇТЪЛсМБОчЯТНЕЃЌЕЅЛњЩѕжСВЛЕН1000QPSЁЃЬкбЖдЦMongoDBЭХЖгЖдДЫНјааСЫГжајЕФгХЛЏЃЌдкВЛгАЯьаЇЙћЕФЧАЬсЯТЃЌgeoNearЕФаЇТЪга10БЖвдЩЯЕФЬсЩ§ЃЌЮЊЮвУЧЕФПЭЛЇШчФІАнЬсЙЉСЫЧПСІЕФжЇГжЃЌЭЌЪБЯрБШRedis3.2вВгаНЯДѓЕФадФмгХЪЦЁЃ
| 








