| БрМЭЦМі: |
БОЮФжиЕуНщЩмСЫЮЊЪВУДжиИДдьТжзгЃЌДгЮяСЊЭјаавЕЕФЪ§ОнЬиЕуЕН
IoTDB ЕФЗЂеЙЙ§ГЬ,етИіТжзгдьЕФдѕУДбљЃЌIoTDB КЭОКЦЗВтЪдЖдБШЁЃ
БОЮФРДздгкПЊдДВЉПЭЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ
|
|
IoTDB ЪЧвЛПюЪБађЪ§ОнПтЃЌЯрЙиОКЦЗга KairosdbЃЌInfluxDBЃЌTimescaleDBЕШЃЌжївЊЪЙгУГЁОАЪЧдкЮяСЊЭјЯрЙиаавЕЃЌШчЃКГЕСЊЭјЁЂЗчСІЗЂЕчЁЂЕиЬњЁЂЗЩЛњМрПиЕШЕШЃЌОпЬхгІгУАИР§МАЙЋЫОЯъЧщПЩвдВщПДЃКIoTDBдкЪЕМЪЙЋЫОжаЕФЪЙгУаХЯЂЪеМЏ
IoTDB ФЃПщжївЊЗжЮЊClientЃЌJDBCЃЌServerЃЌTsFileЃЌGrafanaЃЌDistribution
вдМАИїжжЩњЬЌЕФСЌНгЦїЁЃећИіЯЕСаЕФЮФеТЛсДгаавЕБГОАПЊЪМНВЦ№ЃЌСЫНтвЛИіаавЕОпЬхЕФЪЙгУГЁОАЃЌШЛКѓНщЩм TsFile
ЪЧвдЪВУДбљЕФИёЪНРДБЃДцЪ§ОнЕФЃЌдйНщЩм Server РядѕбљЭъГЩвЛДЮВщбЏЃЌзюКѓдкНщЩмвЛЬѕЭъ ећЕФ SQLЪЧдѕбљДг
Client ЪЙгУ JDBC ЕН Server жБжСЗЕЛиОпЬхНсЙћЁЃШчЙћгаФмСІЕФЛАдйНщЩмвЛЯТМЏШКЕФвЛаЉФкШнКЭЙЄзїЗНЪНЁЃ
ЪБађЪ§Он
ЮвИіШЫРэНтЪБађЪ§ОнЪЧЛљгкЪБМфЮЌЖШЕФЭЌвЛИіЮяЬхЛђИХФюЕФжЕЙЙГЩЕФвЛИіађСаЪ§ОнЁЃдкДЋЭГЙиЯЕаЭЪ§ОнПтжаЃЌР§Шч
MySQLЃЌЮвУЧЭЈГЃЛсЗХжУвЛИізддіЕФ Id СазїЮЊжїМќБъЪЖЃЌШчЯТЃК
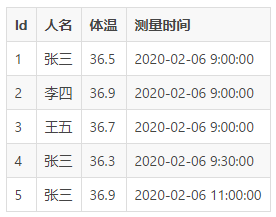
ЩЯУцЕФБэНсЙЙОЭЪЧвЛИіЪБађЪ§ОнЃЌНЋБэНсЙЙзіИіБфаЮИќШнвзРэНт:
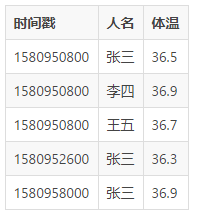
ШчЙћАбЪБМфзїЮЊвЛИіЮЈвЛМќЖдЦыеЙЪОЃЌФмЙЛИќЯёЪБађЪ§ОнвЛаЉЃЌетвВЪЧ IoTDB
жаВщбЏНсЙћЕФеЙЪОЗНЪНЃК
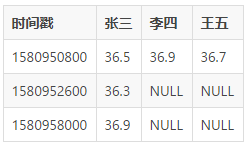
етРяПЩФмЛсДцдквЩЮЪОЭЪЧМйШчШЫЪ§ЪЧж№НЅдіМгЕФЃЌФЧУДЪЧЖЏЬЌДДНЈСаФиЃПЛЙЪЧЬсЧАДДНЈзуЙЛЖрЕФСаЃПетИіЮЪЬтЕШКѓУцЮФеТгаЛњЛсМЬајНщЩм
ЮяСЊЭј
ЮяСЊЭјЕФЬиЕуЪЧЖМЛсДцдквЛИіЛђЖрИіЩшБИЃЌЫћУЧвдИїжжИїбљЕФаЮЪНзщжЏЕНвЛЦ№ЃЌгУРДЙлВтЛђМЧТМЭЌвЛЪБМфРяЯрЭЌЛЗОГЫљВњЩњЕФЪ§ОнЁЃЯТУцЕФНщЩмжаЃЌЪЙгУгЩМђЕЅЕНИДдгЕФЪ§Онж№ВННщЩмдкЮяСЊЭјаавЕжаЃЌЭЈгУЕФвЛаЉЮЪЬтКЭЗНЯђЁЃ
1.ЛљБОДцДЂ
МйШчЮвЪЧвЛИіЙЋЫОЃЌЖдЭтВЅБЈББОЉЁЂЬьНђЁЂЩЯКЃШ§ЕиЕФЮТЖШЪ§ОнЃЌДгЖјЪЕЯжгЏРћЁЃ
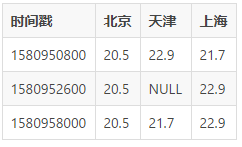
2.БЃжЄЪ§ОнжЪСП
Ъ§ОнБЃжЄЕФжЪСПЪЧЖрЗНУцЕФЃЌвЛВНвЛВННщЩмЁЃ
2.1 ИќЖрЩшБИ
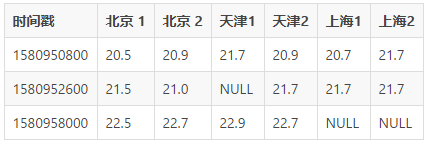
ЪзЯШПЩвдПДЕНЩЯУцЪ§ОнЪЧДцдк NULL жЕЕФЃЌетИі NULL жЕгаПЩФмЪЧвђЮЊЕБЪБЩшБИЫљдкЕФЧјгђЭЃЕчСЫЃЌЫљвдВЂУЛгаАьЗЈЩЯБЈЕБЪБЕФЧщПіЃЌетбљПЭЛЇШчЙћЯыЛёШЁ1580952600
етИіЪБМфДСЖдгІЕФЬьНђЕФЪ§ОнЕФЪБКђЃЌПЯЖЈЪЧФУВЛЕНСЫЃЌЫљвдДЋЭГЫМЮЌЩЯЃЌЮвУЧгІИУдіМгвЛИіШнджЩшБИЃЌБЃжЄвЛИіЩшБИдкЛЕЕєЁЂЭЃЕчЁЂШЫЮЊЫ№ЛЕЕШЕШЕФЧщПіЕФЪБКђЃЌвРШЛФмЙЛгаЪ§ОнЩЯБЈЛиРДЁЃ
ЛљгкетбљЕФЫМЯыЃЌвдЩЯЕФБэНсЙЙОЭЛсБфГЩЃК
2.2 ИќИпВЩбљЦЕТЪ
етЪБКђвРШЛДцдкЮЪЬтЃЌ 1580958000 етвЛПЬСНИіЩшБИЖМУЛгаЪ§ОнЃЌгаПЩФмЪЧЗХжУЩшБИЕФЧјгђЭЌЪБГіЯжСЫЖЯЭјЛђепЖЯЕчЃЌетжжЧщПіЯТЃЌЮвУЧПЩвдВЩгУЬсИпВЩМЏЪ§ОнЕФЦЕТЪЛђепВЙДЋЪ§ОнРДНтОі(ВЙДЋднВЛЬжТл)ЁЃ
ЮвУЧНЋУПЬьЪ§ОнЗжЮЊ3зщЃЌУПзщВЩбљ3ДЮЃЌМфИєЮЊ1ИіаЁЪБЃЌМйШчЪБМфЗжВМЮЊЃКЩЯЮчЃЈ7ЁЂ8ЁЂ9ЃЉЁЂжаЮчЃЈ12ЁЂ13ЁЂ14ЃЉЁЂЯТЮчЃЈ18ЁЂ19ЁЂ20ЃЉЁЃЕБдіМгСЫВЩбљЦЕТЪжЎКѓЃЌМДБуФГвЛПЬГіЯжСЫ
NULL Ъ§ОнЃЌЮвУЧвВПЩвдВЩгУСйНќЪБМфзіЮЊВЙГфЁЃЮЊСЫЗНБуЖдгІЃЌЯТБэЪ§ОнжадіМгЪБМфЕуСаИЈжњВщПДЁЃ
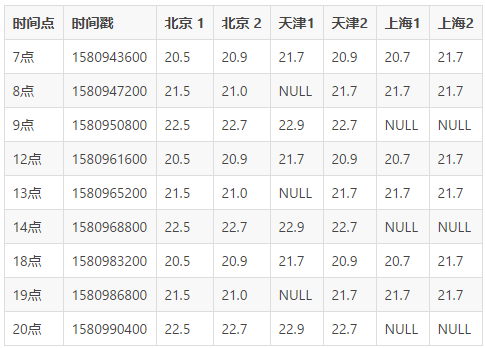
ПЩвдПДЕНОЙ§ИїжжИїбљЕФашЧѓжЎКѓЃЌЩЯДЋЕФЪ§ОнЪЧГЩБЖдіГЄЕФЃЌВЛФбЯыЯѓШчЙћетИіЮТЖШЪ§ОнЯЃЭћОЋзМЕФЛёШЁЕНУПИіЯиГЧЕФЮТЖШЃЌФЧУДжаЙњга
2854 ИіЯиГЧ * 2 ИіЮТЖШЩшБИ * 9 ЬѕЪ§Он = 1 ЬьВњЩњЕФЪ§ОнзмСП = 51372 ЬѕЃЌФЧУДвЛИідТОЭЪЧ
1541160 ЬѕЁЃ
Ъ§ОнЪЕЪБадМАзмСП
МйШчЩЯУцЕФЪ§ОнЮвУЧМЬајЬсИпЦЕТЪЕНУП1ЗжжгУПИіЩшБИЩЯБЈвЛДЮЃЌФЧУДЪ§ОнСПОЭЛсГЩЮЊ 2854 * 2 *
60 * 24 = 246585600 Ьѕ/ЬьЁЃ
дкетбљЕФЪ§ОнСПЯТЃЌЪЕЪБВхШыЪЕЪБзівЛаЉОлКЯМЦЫуЃЌгІИУДЋЭГЪ§ОнПтОЭгааЉДІРэВЛЙ§РДСЫЁЃ
IoTDB ЕФЧАЩэ
ФГЙЋЫОдкЪЕМЪвЕЮёжаЃЌ20 ЭђЩшБИБЃДцСЫ 3 ФъЕФЪ§ОнЃЌTBМЖБ№ЕФЪ§ОнЪЙЕУ Oracle БЛЭЯЕФИљБОГдВЛЯћЁЃЙиМќЕФЮЪЬтЕуЛЙВЛНіНіЪЧДцСПЪ§ОнДѓЃЌаТдіЪ§ОнвРШЛвдЗЧГЃПьЕФЫйЖШдкдіГЄЁЃКѓРДЙЋЫОСЊЯЕЕНСЫ
IoTDB ЕФЕквЛХњПЊЗЂепЃЌЕЋЪЧЕБЪБЕФЗНАИЛЙЪЧЛљгк Cassandra РДзіЩшМЦЃЌЕБЪБЙцЛЎСЫ 5 ЬЈЛњЦїЕФМЏШКЃЌадФмИеТњзуЃЌЕЋЫцзХЪБМфЭЦвЦЩшБИзмСПдкдіМгЃЌвЕЮёЯЕЭГЕФВщбЏЧыЧѓСПдкдіМгЁЃCassandra
дкОЙ§ДѓСПЕФХЌСІжЎКѓЃЌзюКѓЗЂЯжШчЙћдйИФПЩФмОЭашвЊДѓУцЛ§ЕФжиЙЙ Cassandra Ъ§ОнЕФДњТыСЫЃЌзюжеОіЖЈжиаТЩшМЦвЛИіДцДЂЗНЪНЃЌРДНтОіЮяСЊЭјГЁОАЯТЕФЪБађЪ§ОнИпаЇаДШыЁЂЕЭбгГйЖСШЁЁЂИпбЙЫѕБШГжОУЛЏЁЃ
PS: вдЩЯЖМЪЧЛЦЯђЖЋ (IoTDB PPMC) ЃЌдк meetup жаНВЕНЕФЃЌЮвжЛЪЧдкФджаДцСєСЫвЛВПЗжЃЌОпЬхЕФЯИНкДѓМвПЩвдЕН
IoTDB ЩчЧјНЛСїЁЃ
адФмЖдБШ
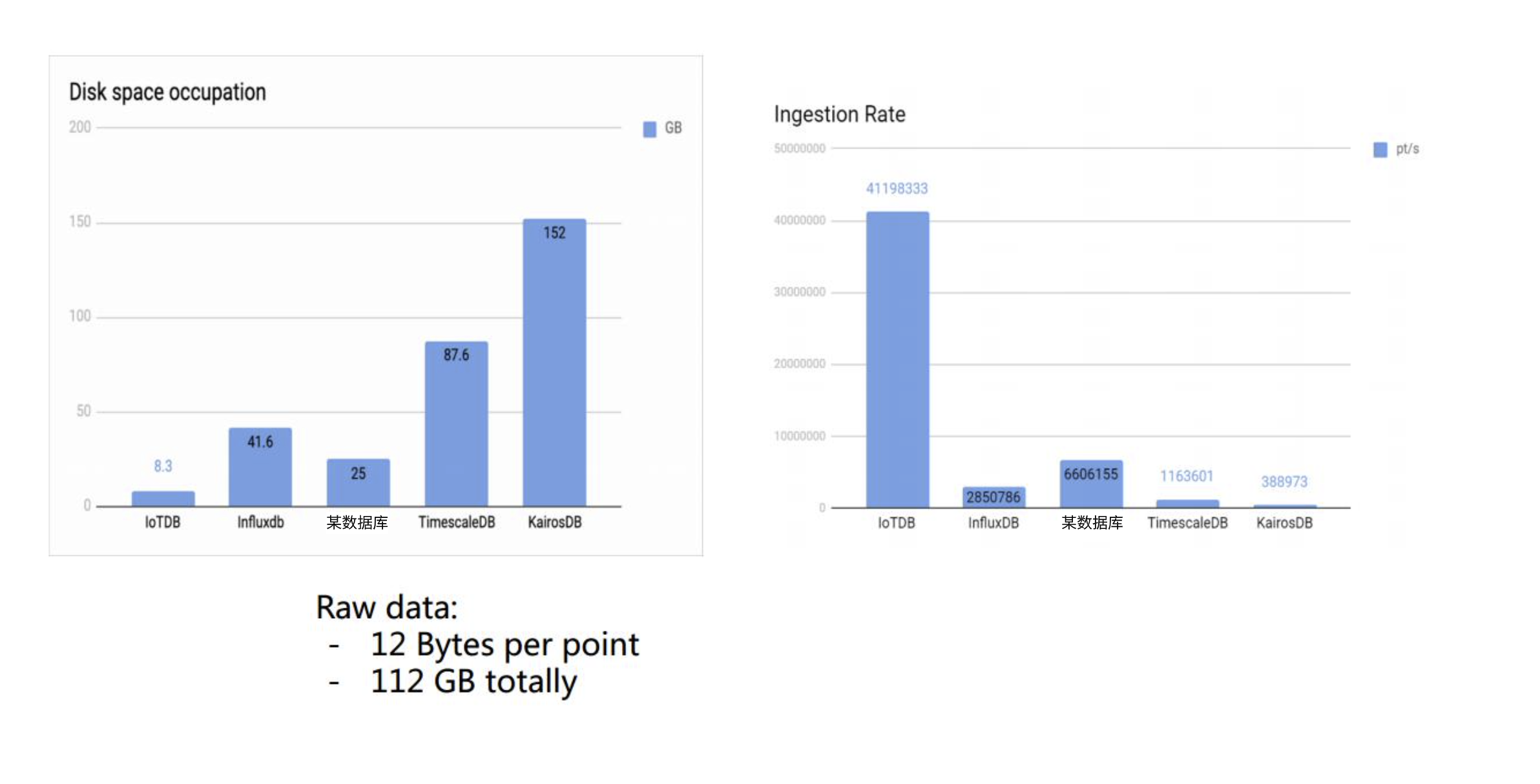
ВтЪдЙЄОпЪЙгУЕФЪЧгЩЧхЛЊДѓбЇДѓЪ§ОнЪЕбщЪвПЊЗЂЕФiotdb-benchmark
1.аДШыадФмЖдБШ

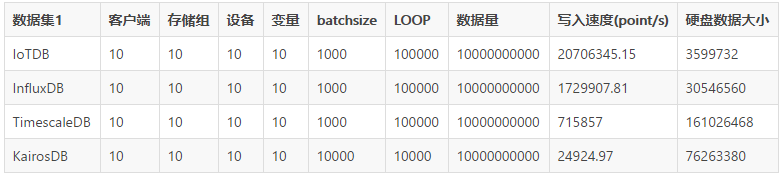
ЩЯУцвЛзщЪ§ОнПЩвдПДГіаДШыадФмИпгкЭЌПюЪ§ОнПт10БЖгагрЃЌЕЅЛњаДШыЫйЖШИпДяЕНУПУы2ЧЇЭђЁЃЧвгВХЬеМгУЪЧзюаЁЕФЃЌетдкЪ§ОнБШНЯДѓЕФЯпЩЯвЕЮёжаЃЌПЩФмУПИідТЛсВюГіРД
1 ЕН 2 ПщгВХЬЁЃ
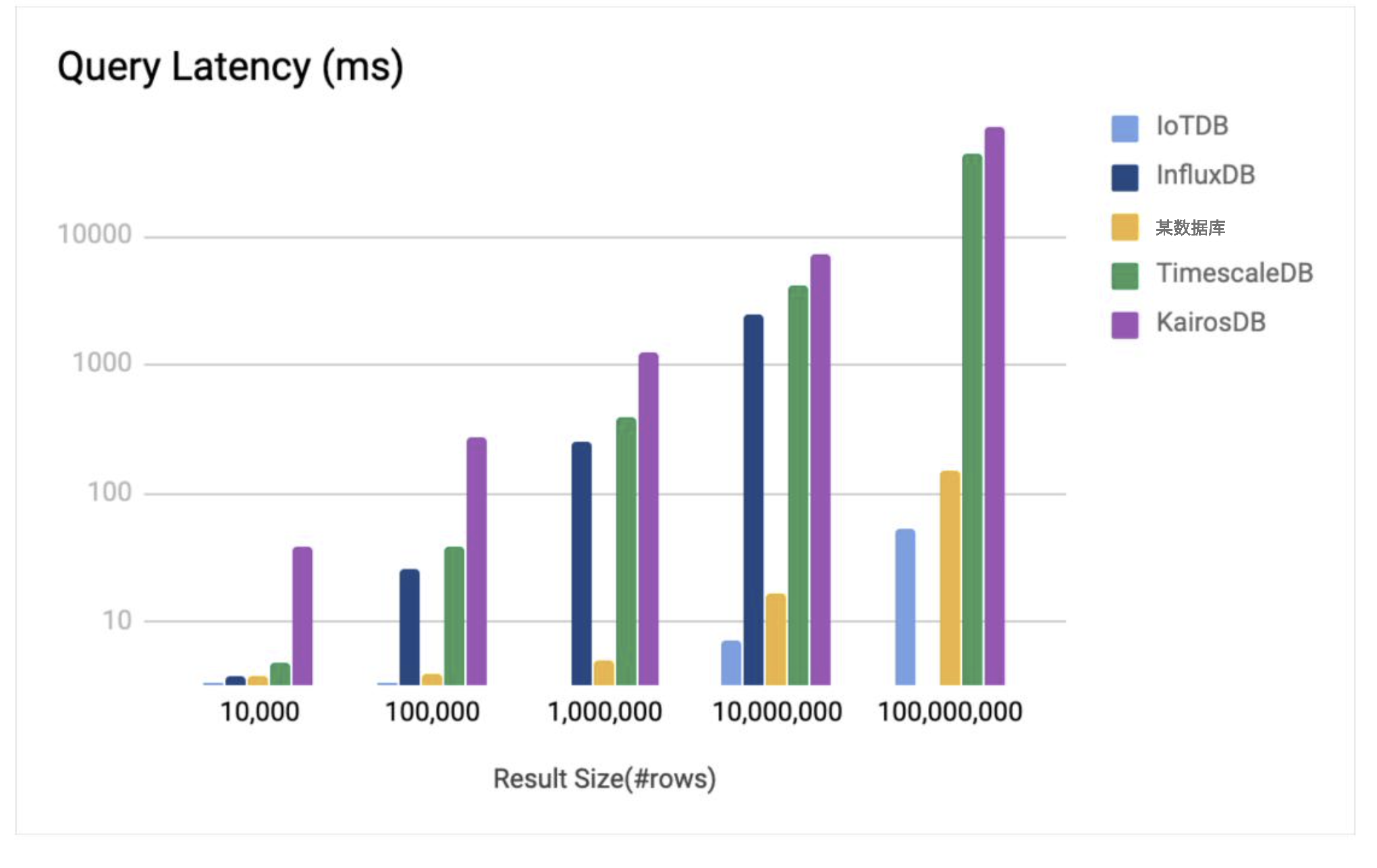
2. ВщбЏадФмЖдБШ
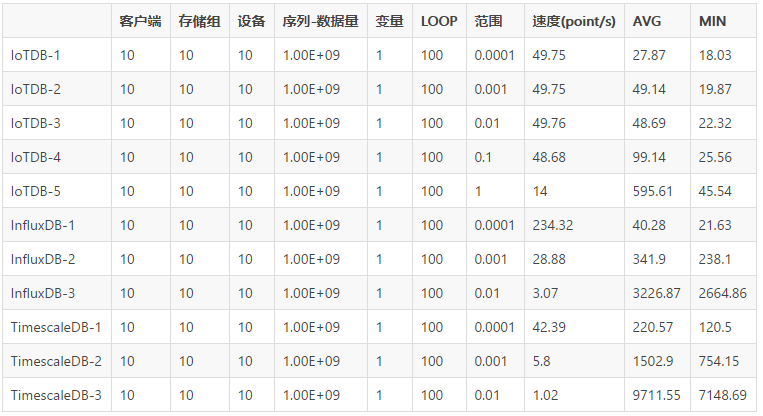
дЪМЪ§ОнВщбЏ

ОлКЯЪ§ОнВщбЏ
3. ЖдБШЭМ
гВХЬеМгУМАЫйЖШЖдБШ
ВщбЏЯьгІбгГйЖдБШ
ећЬхРДПД IoTDB ЮоТлдкаДШыЁЂдЪМЪ§ОнВщбЏЛЙЪЧОлКЯВщбЏЃЌЖММИКѕЪЧ10БЖЕФадФмгкОКЦЗЪ§ОнПтЃЌЖјЧвгВХЬеМгУгжаЁгкЭЌПюЪ§ОнПт10БЖЃЌФЧУД
IoTDB ЪЧдѕбљЭъГЩШчДЫИпЕФбЙЫѕБШЁЂШчДЫПжВРЕФаДШыЫйЖШЁЂШчДЫИпаЇЕФВщбЏФиЃПЛЖгМЬајЙизЂЁЃЁЃЁЃ
| 








