| БрМЭЦМі: |
БОЮФжївЊЖд
Nebula GraphЕФЫїв§ЙІФмзівЛИіЯъЯИНщЩмЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздВЉПЭдАЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
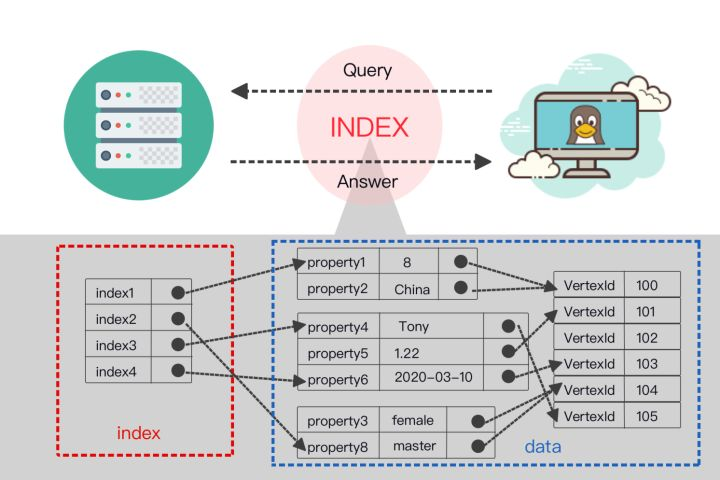
ЕМЖС
Ыїв§ЪЧЪ§ОнПтЯЕЭГжаВЛПЩЛђШБЕФвЛИіЙІФмЃЌЪ§ОнПтЫїв§КУБШЪЧЪщЕФФПТМЃЌФмМгПьЪ§ОнПтЕФВщбЏЫйЖШЃЌЦфЪЕжЪЪЧЪ§ОнПтЙмРэЯЕЭГжавЛИіХХађЕФЪ§ОнНсЙЙЁЃВЛЭЌЕФЪ§ОнПтЯЕЭГгаВЛЭЌЕФХХађНсЙЙЃЌФПЧАГЃМћЕФЫїв§ЪЕЯжРраЭШч
B-Tree indexЁЂB+-Tree indexЁЂB*-Tree indexЁЂHash indexЁЂBitmap
indexЁЂInverted index ЕШЕШЃЌИїжжЫїв§РраЭЖМгаИїздЕФХХађЫуЗЈЁЃ
ЫфШЛЫїв§ПЩвдДјРДИќИпЕФВщбЏадФмЃЌЕЋЪЧвВДцдквЛаЉШБЕуЃЌР§ШчЃК
ДДНЈЫїв§КЭЮЌЛЄЫїв§вЊКФЗбЖюЭтЕФЪБМф,ЭљЭљЪЧЫцзХЪ§ОнСПЕФдіМгЖјЮЌЛЄГЩБОдіДѓ
Ыїв§ашвЊеМгУЮяРэПеМф
дкЖдЪ§ОнНјаадіЩОИФЕФВйзїЪБашвЊКФЗбИќЖрЕФЪБМф,вђЮЊЫїв§вВвЊНјааЭЌВНЕФЮЌЛЄ
Nebula Graph зїЮЊвЛИіИпадФмЕФЗжВМЪНЭМЪ§ОнПтЃЌЖдгкЪєаджЕЕФИпадФмВщбЏЃЌЭЌбљвВЪЕЯжСЫЫїв§ЙІФмЁЃБОЮФНЋЖд
Nebula GraphЕФЫїв§ЙІФмзівЛИіЯъЯИНщЩмЁЃ
ЭМЪ§ОнПт Nebula Graph Ъѕгя
ПЊЪМжЎЧАЃЌетРяТоСавЛаЉПЩФмЛсЪЙгУЕНЕФЭМЪ§ОнПтКЭ Nebula Graph зЈгаЪѕгяЃК
1.TagЃКЕуЕФЪєадНсЙЙЃЌвЛИі Vertex ПЩвдИНМгЖржж tagЃЌвд
TagID БъЪЖЁЃЃЈШчЙћРрБШ SQLЃЌПЩвдРэНтЮЊвЛеХЕуБэЃЉ
2.EdgeЃКРрЫЦгк TagЃЌEdgeType ЪЧБпЩЯЕФЪєадНсЙЙЃЌвд
EdgeType БъЪЖЁЃЃЈШчЙћРрБШ SQLЃЌПЩвдРэНтЮЊвЛеХБпБэЃЉ
3.PropertyЃКtag / edge ЩЯЕФЪєаджЕЃЌЦфЪ§ОнРраЭгЩ
tag / edge ЕФНсЙЙШЗЖЈЁЃ
4.PartitionЃКNebula Graph ЕФзюаЁТпМДцДЂЕЅдЊЃЌвЛИі
StorageEngine ПЩАќКЌЖрИі PartitionЁЃPartition ЗжЮЊ leader
КЭ follower ЕФНЧЩЋЃЌRaftex БЃжЄСЫ leader КЭ follower жЎМфЕФЪ§ОнвЛжТадЁЃ
5.Graph spaceЃКУПИі Graph Space ЪЧвЛИіЖРСЂЕФвЕЮё
Graph ЕЅдЊЃЌУПИі Graph Space гаЦфЖРСЂЕФ tag КЭ edge МЏКЯЁЃвЛИі Nebula
Graph МЏШКжаПЩАќКЌЖрИі Graph SpaceЁЃ
6.IndexЃКБОЮФжаГіЯжЕФ Index жИ nebula graph
жаЕуКЭБпЩЯЕФЪєадЫїв§ЁЃЦфЪ§ОнРраЭвРРЕгк tag / edgeЁЃ
7.TagIndexЃКЛљгк tag ДДНЈЕФЫїв§ЃЌвЛИі tag ПЩвдДДНЈЖрИіЫїв§ЁЃФПЧАЃЈ2020.3ЃЉднВЛжЇГжПч
tag ЕФИДКЯЫїв§ЃЌвђДЫвЛИіЫїв§жЛПЩвдЛљгквЛИі tagЁЃ
8.EdgeIndexЃКЛљгк Edge ДДНЈЕФЫїв§ЁЃЭЌбљЃЌвЛИі Edge
ПЩвдДДНЈЖрИіЫїв§ЃЌЕЋвЛИіЫїв§жЛПЩвдЛљгквЛИі edgeЁЃ
9.Scan PolicyЃКIndex ЕФЩЈУшВпТдЃЌЭљЭљвЛЬѕВщбЏгяОфПЩвдгаЖржжЫїв§ЕФЩЈУшЗНЪНЃЌЕЋОпЬхЪЙгУФФжжЩЈУшЗНЪНашвЊ
Scan Policy РДОіЖЈЁЃ
10.OptimizerЃКЖдВщбЏЬѕМўНјаагХЛЏЃЌР§ШчЖд where
згОфЕФБэДяЪНЪїНјаазгБэДяЪННкЕуЕФХХађЁЂЗжСбЁЂКЯВЂЕШЁЃЦфФПЕФЪЧЛёШЁИќИпЕФВщбЏаЇТЪЁЃ
Ыїв§ашЧѓЗжЮі
Nebula Graph ЪЧвЛИіЭМЪ§ОнПтЯЕЭГЃЌВщбЏГЁОАвЛАуЪЧгЩвЛИіЕуГіЗЂЃЌевГіжИЖЈБпРраЭЕФЯрЙиЕуЕФМЏКЯЃЌвдДЫРрЭЦНјааЃЈЙуЖШгХЯШБщРњЃЉN
ЖШВщбЏЁЃСэвЛжжВщбЏГЁОАЪЧИјЖЈвЛИіЪєаджЕЃЌевГіЗћКЯетИіЪєаджЕЕФЫљгаЕФЕуЛђБпЁЃдкКѓУцетжжГЁОАжаЃЌашвЊЖдЪєаджЕНјааИпадФмЕФЩЈУшЃЌВщГігыДЫЪєаджЕЖдгІЕФБпЛђЕуЃЌвдМАБпЛђЕуЩЯЕФЦфЫќЪєадЁЃЮЊСЫЬсИпЪєаджЕЕФВщбЏаЇТЪЃЌдкетРяв§ШыСЫЫїв§ЕФЙІФмЁЃЖдБпЛђЕуЕФЪєаджЕНјааХХађЃЌвдБуПьЫйЕФЖЈЮЛЕНФГИіЪєадЩЯЁЃвдДЫБмУтСЫШЋБэЩЈУшЁЃ
ПЩвдПДЕНЖдЭМЪ§ОнПт Nebula Graph ЕФЫїв§вЊЧѓЃК
1.жЇГж tag КЭ edge ЕФЪєадЫїв§
2.жЇГжЫїв§ЕФЩЈУшВпТдЕФЗжЮіКЭЩњГЩ
3.жЇГжЫїв§ЕФЙмРэЃЌШчЃКаТНЈЫїв§ЁЂжиНЈЫїв§ЁЂЩОГ§Ыїв§ЁЂlist |
show Ыїв§ЕШЁЃ
ЯЕЭГМмЙЙИХРР
ЭМЪ§ОнПт Nebula Graph ДцДЂМмЙЙ
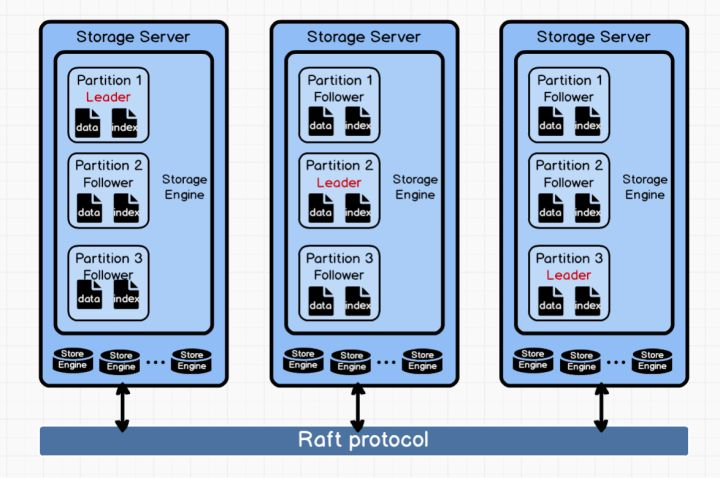
ДгМмЙЙЭМПЩвдПДЕНЃЌУПИіStorage Server жаПЩвдАќКЌЖрИі Storage Engine,
УПИі Storage EngineжаПЩвдАќКЌЖрИіPartition, ВЛЭЌЕФPartitionжЎМфЭЈЙ§
Raft авщНјаавЛжТадЭЌВНЁЃУПИі Partition жаМШАќКЌСЫ dataЃЌвВАќКЌСЫ indexЃЌЭЌвЛИіЕуЛђБпЕФ
data КЭ index НЋБЛДцДЂЕНЭЌвЛИі Partition жаЁЃ
вЕЮёОпЬхЗжЮі
Ъ§ОнДцДЂНсЙЙ
ЮЊСЫИќКУЕФУшЪіЫїв§ЕФДцДЂНсЙЙЃЌетРяНЋЭМЪ§ОнПт Nebula Graph дЪМЪ§ОнЕФДцДЂНсЙЙвЛЦ№ФУГіРДЗжЮіЯТЁЃ
ЕуЕФДцДЂНсЙЙ
ЕуЕФ Data НсЙЙ

ЕуЕФ Index НсЙЙ

Vertex ЕФЫїв§НсЙЙШчЩЯБэЫљЪОЃЌЯТУцРДЯъЯИЕиНВЪіЯТзжЖЮЃК
PartitionIdЃКвЛИіЕуЕФЪ§ОнКЭЫїв§дкТпМЩЯЪЧДцЗХЕНЭЌвЛИіЗжЧјжаЕФЁЃжЎЫљвдетУДзіЕФдвђжївЊгаСНЕуЃК
ЕБЩЈУшЫїв§ЪБЃЌИљОнЫїв§ЕФ key ФмПьЫйЕиЛёШЁЕНЭЌвЛИіЗжЧјжаЕФЕу dataЃЌетбљОЭПЩвдЗНБуЕиЛёШЁетИіЕуЕФШЮКЮвЛжжЪєаджЕЃЌМДЪЙетИіЪєадСаВЛЪєгкБОЫїв§ЁЃ
ФПЧА edge ЕФДцДЂЪЧгЩЦ№ЕуЕФ ID Hash ЗжВМЃЌЛЛОфЛАЫЕЃЌвЛИіЕуЕФГіБпДцДЂдкФФЪЧгЩИУЕуЕФ VertexId
ОіЖЈЕФЃЌетИіЕуКЭЫќЕФГіБпШчЙћБЛДцДЂЕНЭЌвЛИі partition жаЃЌЕуЕФЫїв§ЩЈУшФмПьЫйЕиЖЈЮЛИУЕуЕФГіБпЁЃ
IndexIdЃКindex ЕФЪЖБ№ТыЃЌЭЈЙ§ indexId ПЩЛёШЁжИЖЈ index ЕФдЊЪ§ОнаХЯЂЃЌР§ШчЃКindex
ЫљЙиСЊЕФ TagIdЃЌindex ЫљдкСаЕФаХЯЂЁЃ
Index binaryЃКindex ЕФКЫаФДцДЂНсЙЙЃЌЪЧЫљга index ЯрЙиСаЪєаджЕЕФзжНкБрТыЃЌЯъЯИНсЙЙНЋдкБОЮФЕФ
#Index binary# еТНкжаНВНтЁЃ
VertexIdЃКЕуЕФЪЖБ№ТыЃЌдкЪЕМЪЕФ data жаЃЌвЛИіЕуПЩФмЛсгаВЛЭЌ version ЕФЖрааЪ§ОнЁЃЕЋЪЧдк
index жаЃЌindex УЛга Version ЕФИХФюЃЌindex ЪМжегызюаТ Version ЕФ
Tag ЫљЖдгІЁЃ
ЩЯУцНВЭъзжЖЮЃЌЮвУЧРДМђЕЅЕиЪЕМљЗжЮівЛВЈЃК
МйЩш PartitionId ЮЊ _100ЃЌTagId га tag_1 КЭ tag_2ЃЌ_Цфжа tag_1
АќКЌШ§Са ЃКcol_t1_1ЁЂcol_t1_2ЁЂcol_t1_3ЃЌtag_2 АќКЌСНСаЃКcol_t2_1ЁЂcol_t2_2ЁЃ
ЯждкЮвУЧРДДДНЈЫїв§ЃК
i1 = tag_1 (col_t1_1, col_t1_2) ЃЌМйЩш i1 ЕФ ID ЮЊ 1ЃЛ
i2 = tag_2(col_t2_1, col_t2_2), МйЩш i2 ЕФ ID ЮЊ 2ЃЛ
ПЩвдПДЕНЫфШЛ tag_1 жага col_t1_3 етСаЃЌЕЋЪЧНЈСЂЫїв§ЕФЪБКђВЂУЛгаЪЙгУЕН col_t1_3ЃЌвђЮЊдкЭМЪ§ОнПт
Nebula Graph жаЫїв§ПЩвдЛљгк Tag ЕФвЛСаЛђЖрСаНјааДДНЈЁЃ
ВхШыЕу
// VertexId =
hash("v_t1_1")ЃЌМйШчЮЊ 50
INSERT VERTEX tag_1(col_t1_1, col_t1_2, col_t1_3),
tag_2(col_t2_1, col_t2_2) \
VALUES hash("v_t1_1"):("v_t1_1",
"v_t1_2", "v_t1_3", "v_t2_1",
"v_t2_2"); |
ДгЩЯПЩвдПДЕН VertexId ПЩгЩ ID БъЪЖЖдгІЕФЪ§жЕОЙ§ Hash ЕУЕНЃЌШчЙћБъЪЖЖдгІЕФЪ§жЕБОЩэвбОЮЊ
int64ЃЌдђЮоашНјаа Hash ЛђепЦфЫћзЊЛЏЪ§жЕЮЊ int64 ЕФдЫЫуЁЃЖјДЫЪБЪ§ОнДцДЂШчЯТЃК
ДЫЪБЕуЕФ Data НсЙЙ

ДЫЪБЕуЕФ Index НсЙЙ

ЫЕУїЃКindex жа row КЭ key ЪЧвЛИіИХФюЃЌЮЊЫїв§ЕФЮЈвЛБъЪЖЃЛ
БпЕФДцДЂНсЙЙ
БпЕФЫїв§НсЙЙКЭЕуЫїв§НсЙЙдРэРрЫЦЃЌетРяВЛдйзИЪіЁЃЕЋгавЛЕуашвЊЫЕУїЃЌЮЊСЫЪЙЫїв§ key ЕФЮЈвЛадГЩСЂЃЌЫїв§ЕФ
key ЕФЩњГЩНшжњСЫВЛЩй data жаЕФдЊЫиЃЌР§Шч VertexIdЁЂSrcVertexIdЁЂRank
ЕШЃЌетвВЪЧЮЊЪВУДЕуЫїв§жаВЂУЛга TagId зжЖЮЃЈБпЫїв§жавВУЛга EdgeType зжЖЮЃЉЃЌетЪЧвђЮЊ**
IndexId БОЩэДјга VertexId ЕШаХЯЂПЩжБНгЧјЗжОпЬхЕФ tagId Лђ EdgeType**ЁЃ
БпЕФ Data НсЙЙ

БпЕФ Index НсЙЙ

Index binary НщЩм

Index binary ЪЧ index ЕФКЫаФзжЖЮЃЌдк index binary жаЧјЗжЖЈГЄзжЖЮКЭВЛЖЈГЄзжЖЮЃЌintЁЂdoubleЁЂbool
ЮЊЖЈГЄзжЖЮЃЌstring дђЮЊВЛЖЈГЄзжЖЮЁЃгЩгк** index binary ЪЧНЋЫљга index
column ЕФЪєаджЕБрТыСЌНгДцДЂ**ЃЌЮЊСЫОЋШЗЕиЖЈЮЛВЛЖЈГЄзжЖЮЃЌNebula Graph дк index
binary ФЉЮВгУ int32 МЧТМСЫВЛЖЈГЄзжЖЮЕФГЄЖШЁЃ
ОйИіР§згЃК
ЮвУЧЯждкгавЛИі index binary ЮЊ index1ЃЌЪЧгЩ int РраЭЕФЫїв§Са1 c1ЁЂstring
РраЭЕФЫїв§Са c2ЃЌstring РраЭЕФЫїв§Са c3 зщГЩЃК
| index1 (c1:int,
c2:string, c3:string) |
МйШчЫїв§Са c1ЁЂc2ЁЂc3 ФГвЛааЖдгІЕФ property жЕЗжБ№ЮЊЃК23ЁЂ"abc"ЁЂ"here"ЃЌдђдк
index1 жаетаЉЫїв§СаНЋБЛДцДЂЮЊШчЯТЃЈдкЪОР§жаЮЊСЫБугкРэНтЃЌЮвУЧжБНггУджЕЃЌЪЕМЪДцДЂжаЪЧджЕЛсОЙ§БрТыдйДцДЂЃЉЃК
length = sizeof("abc") = 3
length = sizeof("here") = 4

Ыљвд index1 ИУ row ЖдгІЕФ key дђЮЊ 23abchere34ЃЛ
ЛиЕНЮвУЧ Index binary еТНкПЊЦЊЫЕЕФ index binary ИёЪНжаДцдк Variable-length
field lenght зжЖЮЃЌФЧУДетИізжЖЮЕФЕФОпЬхзїгУЪЧЪВУДФиЃПЮвУЧРДМђЕЅЕиОйИіР§ЃК
ЯждкЮвУЧгжгаСЫвЛИі index binaryЃЌЮвУЧИјЫќШЁУћЮЊ index2ЃЌЫќгЩ string РраЭЕФЫїв§Са1
c1ЁЂstring РраЭЕФЫїв§Са c2ЃЌstring РраЭЕФЫїв§Са c3 зщГЩЃК
| index2 (c1:string,
c2:string, c3:string) |
МйЩшЮвУЧЯждк c1ЁЂc2ЁЂc3 ЗжБ№гаСНзщШчЯТЕФЪ§жЕЃК
row1 : ("ab", "ab", "ab")
row2: ("aba", "ba", "b")
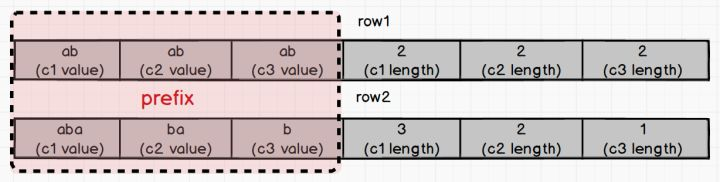
ПЩвдПДЕНетСНааЕФ prefixЃЈЩЯЭМКьЩЋВПЗжЃЉЪЧЯрЭЌЃЌЖМЪЧ "ababab"ЃЌетЪБКђдѕУДЧјЗжетСНИі
row ЕФ index binary ЕФ key ФиЃПБ№ЕЃаФЃЌЮвУЧга Variable-length
field lenght ЁЃ
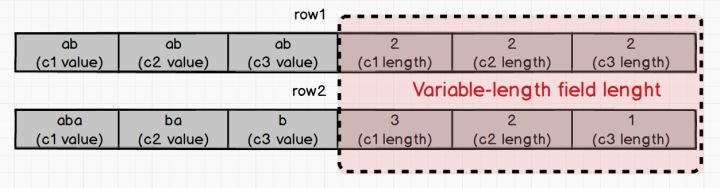
ШєгіЕН where c1 == "ab" етбљЕФЬѕМўВщбЏгяОфЃЌдк Variable-length
field length жаПЩжБНгИљОнЫГађЖСШЁГі c1 ЕФГЄЖШЃЌдйИљОнетИіГЄЖШШЁГі row1 КЭ row2
жа c1 ЕФжЕЃЌЗжБ№ЪЧ "ab" КЭ "aba" ЃЌетбљЮвУЧОЭОЋзМЕиХаЖЯГіжЛга
row1 жаЕФ "ab" ЪЧЗћКЯВщбЏЬѕМўЕФЁЃ
Ыїв§ЕФДІРэТпМ
Index write
ЕБ Tag / EdgeжаЕФвЛСаЛђЖрСаДДНЈСЫЫїв§КѓЃЌвЛЕЉЩцМАЕН Tag / Edge ЯрЙиЕФаДВйзїЪБЃЌЖдгІЕФЫїв§БиаыСЌЭЌЪ§ОнвЛЦ№БЛаоИФЁЃЯТУцНЋЖдЫїв§ЕФwriteВйзїдкstorageВуЕФДІРэТпМНјааМђЕЅНщЩмЃК
INSERTЁЊЁЊВхШыЪ§Он
ЕБгУЛЇВњЩњВхШыЕу/БпВйзїЪБЃЌinsertProcessor ЪзЯШЛсХаЖЯЫљВхШыЕФЪ§ОнЪЧЗёгаДцдкЫїв§ЕФ
Tag Ъєад / Edge ЪєадЁЃШчЙћУЛгаЙиСЊЕФЪєадСаЫїв§ЃЌдђАДГЃЙцЗНЪНЩњГЩаТ VersionЃЌВЂНЋЪ§Он
put ЕН Storage EngineЃЛШчЙћгаЙиСЊЕФЪєадСаЫїв§ЃЌдђЭЈЙ§дзгВйзїаДШы Data КЭ
IndexЃЌВЂХаЖЯЕБЧАЕФ Vertex / Edge ЪЧЗёгаОЩЕФЪєаджЕЃЌШчЙћгаЃЌдђвЛВЂдкдзгВйзїжаЩОГ§ОЩЪєаджЕЁЃ
DELETEЁЊЁЊЩОГ§Ъ§Он
ЕБгУЛЇЗЂЩњ Drop Vertex / Edge ВйзїЪБЃЌdeleteProcessor ЛсНЋ Data
КЭ IndexЃЈШчЙћДцдкЃЉвЛВЂЩОГ§ЃЌдкЩОГ§ЕФЙ§ГЬжаЭЌбљашвЊЪЙгУдзгВйзїЁЃ
UPDATEЁЊЁЊИќаТЪ§Он
Vertex / Edge ЕФИќаТВйзїЖдгк Index РДЫЕЃЌдђЪЧ drop КЭ insert ЕФВйзїЃКЩОГ§ОЩЕФЫїв§ЃЌВхШыаТЕФЫїв§ЃЌЮЊСЫБЃжЄЪ§ОнЕФвЛжТадЃЌЭЌбљашвЊдкдзгВйзїжаНјааЁЃЕЋЪЧЖдгІЦеЭЈЕФ
Data РДЫЕЃЌНіНіЪЧ insert ВйзїЃЌЪЙгУзюаТ Version ЕФ Data ИВИЧОЩ Version
ЕФ data МДПЩЁЃ
Index scan
дкЭМЪ§ОнПт Nebula Graph жаЪЧгУ LOOKUP гяОфРДДІРэ index scan ВйзїЕФЃЌLOOKUP
гяОфПЩЭЈЙ§ЪєаджЕзїЮЊХаЖЯЬѕМўЃЌВщГіЫљгаЗћКЯЬѕМўЕФЕу/БпЃЌЭЌбљ LOOKUP гяОфжЇГж WHERE КЭ
YIELD згОфЁЃ
LOOKUP ЪЙгУММЧЩ
е§ШчИљОнБОЮФ#Ъ§ОнДцДЂНсЙЙ#еТНкЫљУшЪіФЧбљЃЌindex жаЕФЫїв§СаЪЧАДееДДНЈ index ЪБЕФСаЫГађОіЖЈЁЃ
ОйИіР§згЃЌЮвУЧЯждкга tag (col1, col2)ЃЌИљОнетИі tag ЮвУЧПЩвдДДНЈВЛЭЌЕФЫїв§ЃЌР§ШчЃК
index1 on tag(col1)
index2 on tag(col2)
index3 on tag(col1, col2)
index4 on tag(col2, col1)
ЮвУЧПЩвдЖд clo1ЁЂcol2 НЈСЂЖрИіЫїв§ЃЌЕЋдк scan index ЪБЃЌЩЯЪіЫФИі index
ЗЕЛиНсЙћДцдкВювьЃЌЩѕжСЪЧЭъШЋВЛЭЌЃЌдкЪЕМЪвЕЮёжаОпЬхЪЙгУФФИі indexЃЌМА index ЕФзюгХжДааВпТдЃЌдђЪЧЭЈЙ§Ыїв§гХЛЏЦїОіЖЈЁЃ
ЯТУцЮвУЧдйРДИљОнИеВХ 4 Иі index ЕФР§згЩюШыЗжЮівЛВЈЃК
lookup on tag
where tag.col1 ==1 # зюгХЕФ index ЪЧ index1
lookup on tag where tag.col2 == 2 # зюгХЕФ index
ЪЧindex2
lookup on tag where tag.col1 > 1 and tag.col2
== 1
# index3 КЭ index4 ЖМЪЧгааЇЕФ indexЃЌЖј index1 КЭ index2
дђЮоаЇ |
дкЩЯЪіЕкШ§ИіР§згжаЃЌindex3 КЭ index4 ЖМЪЧгааЇ indexЃЌЕЋзюжеБиаывЊДгСНепжабЁГіРДвЛИізїЮЊ
indexЃЌИљОнгХЛЏЙцдђЃЌвђЮЊ tag.col2 == 1 ЪЧвЛИіЕШМлВщбЏЃЌвђДЫгХЯШЪЙгУ tag.col2
ЛсИќИпаЇЃЌЫљвдгХЛЏЦїгІИУбЁГі index4 ЮЊзюгХ indexЁЃ
ЪЕВйвЛЯТЭМЪ§ОнПт Nebula Graph Ыїв§
дкетВПЗжЮвУЧОЭВЛОпЬхНВНтФГИігяОфЕФгУЭОЪЧЪВУДСЫЃЌШчЙћФуЖдгяОфВЛЧхГўЕФЛАПЩвдШЅЭМЪ§ОнПт Nebula
Graph ЕФЙйЗНТлЬГНјааЬсЮЪЃКhttps://discuss.nebula-graph.io/
CREATEЁЊЁЊЫїв§ЕФДДНЈ
(user@127.0.0.1:6999)
[(none)]> CREATE SPACE my_space(partition_num=3,
replica_factor=1);
Execution succeeded (Time spent: 15.566/16.602
ms)
Thu Feb 20 12:46:38 2020
(user@127.0.0.1:6999) [(none)]> USE my_space;
Execution succeeded (Time spent: 7.681/8.303
ms)
Thu Feb 20 12:46:51 2020
(user@127.0.0.1:6999) [my_space]> CREATE
TAG lookup_tag_1(col1 string, col2 string, col3
string);
Execution succeeded (Time spent: 12.228/12.931
ms)
Thu Feb 20 12:47:05 2020
(user@127.0.0.1:6999) [my_space]> CREATE
TAG INDEX t_index_1 ON lookup_tag_1(col1, col2,
col3);
Execution succeeded (Time spent: 1.639/2.271
ms)
Thu Feb 20 12:47:22 2020 |
DROPЁЊЁЊЩОГ§Ыїв§
(user@127.0.0.1:6999)
[my_space]> DROP TAG INDEX t_index_1;
Execution succeeded (Time spent: 4.147/5.192 ms)
Sat Feb 22 11:30:35 2020 |
REBUILDЁЊЁЊжиНЈЫїв§
ШчЙћФуЪЧДгНЯРЯАцБОЕФ Nebula Graph Щ§МЖЩЯРДЃЌЛђепгУ Spark Writer ХњСПаДШыЙ§ГЬжаЃЈЮЊСЫадФмЃЉУЛгаДђПЊЫїв§ЃЌФЧУДетаЉЪ§ОнЛЙУЛгаНЈСЂЙ§Ыїв§ЃЌетЪБПЩвдЪЙгУ
REBUILD INDEX УќСюРДжиаТШЋСПНЈСЂвЛДЮЫїв§ЁЃетИіЙ§ГЬПЩФмЛсКФЪББШНЯОУЃЌдк rebuild
index ЭъГЩЧАЃЌПЭЛЇЖЫЕФЖСаДЫйЖШЖМЛсБфТ§ЁЃ
| REBUILD {TAG
| EDGE} INDEX <index_name> [OFFLINE] |
LOOKUPЁЊЁЊЪЙгУЫїв§
ашвЊЫЕУївЛЯТЃЌЪЙгУ LOOKUP гяОфЧАЃЌЧыШЗБЃвбОНЈСЂЙ§Ыїв§ЃЈCREATE INDEX Лђ REBUILD
INDEXЃЉЁЃ
(user@127.0.0.1:6999)
[my_space]> INSERT VERTEX
lookup_tag_1(col1,
col2, col3) VALUES 200:("col1_200",
"col2_200", "col3_200"), 201:("col1_201",
"col2_201",
"col3_201"), 202:("col1_202",
"col2_202", "col3_202");
Execution succeeded (Time spent: 18.185/19.267
ms)
Thu Feb 20 12:49:44 2020
(user@127.0.0.1:6999) [my_space]> LOOKUP
ON
lookup_tag_1 WHERE lookup_tag_1.col1 == "col1_200";
============
| VertexID |
============
| 200 |
------------
Got 1 rows (Time spent: 12.001/12.64 ms)
Thu Feb 20 12:49:54 2020
(user@127.0.0.1:6999) [my_space]> LOOKUP
ON lookup_tag_1
WHERE lookup_tag_1.col1 == "col1_200"
YIELD lookup_tag_1.col1,
lookup_tag_1.col2,
lookup_tag_1.col3;
====================================================
====================
| VertexID | lookup_tag_1.col1 | lookup_tag_1.col2
|
lookup_tag_1.col3 |
==================================================
======================
| 200 | col1_200 | col2_200 | col3_200 |
--------------------------------------------------
----------------------
Got 1 rows (Time spent: 3.679/4.657 ms)
Thu Feb 20 12:50:36 2020 |
| 








