| БрМЭЦМі: |
БОЮФжївЊНщЩм
Nebula Graph ЕФЪ§ОнФЃаЭКЭЯЕЭГМмЙЙЩшМЦ ЁЃ
БОЮФРДздТыЖДЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
Nebula Graph ЪЧФПЧАЮЈвЛФмЙЛДцДЂЭђвкИіДјЪєадЕФНкЕуКЭБпЕФдкЯпЭМЪ§ОнПтЁЃNebula
Graph ВЛНіФмЙЛдкИпВЂЗЂГЁОАЯТТњзуКСУыМЖЕФЕЭЪБбгВщбЏвЊЧѓЃЌЖјЧвФмЙЛЬсЙЉМЋИпЕФЗўЮёПЩгУадКЭЪ§ОнАВШЋадЁЃNebulaGraph
вВЪЧвЛИіПЊдДЕФВњЦЗЃЌФуПЩвддк GitHub ЩЯВщПДЁЂЗжЗЂКЭЙБЯзДњТыЁЃ
БОЦЊжївЊНщЩм Nebula Graph ЕФЪ§ОнФЃаЭКЭЯЕЭГМмЙЙЩшМЦЁЃ
гаЯђЪєадЭМ DirectedPropertyGraph
Nebula Graph ВЩгУвзРэНтЕФгаЯђЪєадЭМРДНЈФЃЃЌвВОЭЪЧЫЕЃЌдкТпМЩЯЃЌЭМгЩСНжжЭМдЊЫиЙЙГЩЃКЖЅЕуКЭБпЁЃ
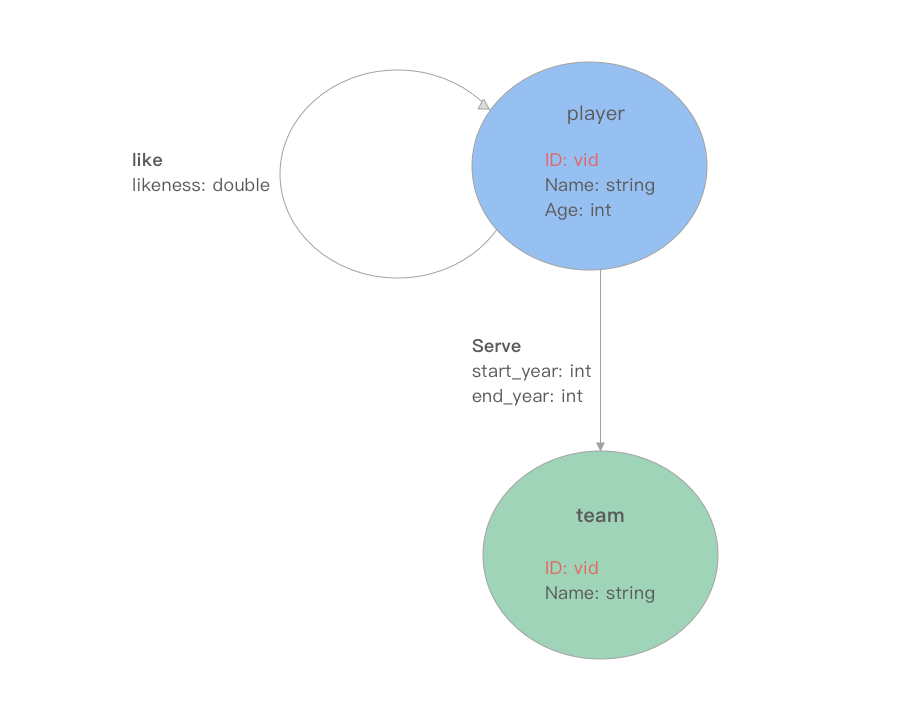
ЖЅЕу Vertex
дк Nebula Graph жаЖЅЕугЩБъЧЉ tag КЭЖдгІ tag ЕФЪєадзщЙЙГЩЃЌ tag ДњБэЖЅЕуЕФРраЭЃЌЪєадзщДњБэ
tag гЕгаЕФвЛжжЛђЖржжЪєадЁЃвЛИіЖЅЕуБиаыжСЩйгавЛжжРраЭЃЌМДБъЧЉЃЌвВПЩвдгаЖржжРраЭЁЃУПжжБъЧЉгавЛзщЯрЖдгІЕФЪєадЃЌЮвУЧГЦжЎЮЊ
schema ЁЃ
ШчЩЯЭМЫљЪОЃЌгаСНжж tag ЖЅЕуЃКplayer КЭ teamЁЃplayer ЕФ schema гаШ§жжЪєад
ID ЃЈvidЃЉЃЌName ЃЈstingЃЉКЭ Age ЃЈintЃЉЃЛteam ЕФ schema гаСНжжЪєад
ID ЃЈvidЃЉКЭ Name ЃЈstringЃЉЁЃ
КЭ Mysql вЛбљЃЌNebula Graph ЪЧвЛжжЧП schema ЕФЪ§ОнПтЃЌЪєадЕФУћГЦКЭЪ§ОнРраЭЖМЪЧдкЪ§ОнаДШыЧАШЗЖЈЕФЁЃ
Бп Edge
дк Nebula Graph жаБпгЩРраЭКЭБпЪєадЙЙГЩЃЌЖј Nebula Graph жаБпОљЪЧгаЯђБпЃЌгаЯђБпБэУївЛИіЖЅЕуЃЈ
Ц№Еу src ЃЉжИЯђСэвЛИіЖЅЕуЃЈ жеЕу dst ЃЉЕФЙиСЊЙиЯЕЁЃДЫЭтЃЌдк Nebula Graph жаЮвУЧНЋБпРраЭГЦЮЊ
edgetype ЃЌУПвЛЬѕБпжЛгавЛжж edgetype ЃЌУПжж edgetype ЯргІЖЈвхСЫетжжБпЩЯЪєадЕФ
schema ЁЃ
ЛиЕНЩЯУцЕФЭМР§ЃЌЭМжагаСНжжРраЭЕФБпЃЌвЛжжЮЊ player жИЯђ player ЕФ like ЙиЯЕЃЌЪєадЮЊ
likeness (double)ЃЛСэвЛжжЮЊ player жИЯђ team ЕФ serve ЙиЯЕЃЌСНИіЪєадЗжБ№ЮЊ
start_year (int) КЭ end_year (int)ЁЃ
зЂЃКашвЊЫЕУїЕФЪЧЃЌЦ№Еу1 КЭжеЕу2 жЎМфЃЌПЩвдЭЌЪБДцдкЖрЬѕЯрЭЌЛђепВЛЭЌРраЭЕФБпЁЃ
ЭМЗжИю GraphPartition
гЩгкГЌДѓЙцФЃЙиЯЕЭјТчЕФНкЕуЪ§СПИпДяАйвкЕНЧЇвкЃЌЖјБпЕФЪ§СПИќЛсИпДяЭђвкЃЌМДЪЙНіДцДЂЕуКЭБпСНепвВдЖДѓгквЛАуЗўЮёЦїЕФШнСПЁЃвђДЫашвЊгаЗНЗЈНЋЭМдЊЫиЧаИюЃЌВЂДцДЂдкВЛЭЌТпМЗжЦЌ
partition ЩЯЁЃNebula Graph ВЩгУБпЗжИюЕФЗНЪНЃЌФЌШЯЕФЗжЦЌВпТдЮЊЙўЯЃЩЂСаЃЌpartition
Ъ§СПЮЊОВЬЌЩшжУВЂВЛПЩИќИФЁЃ
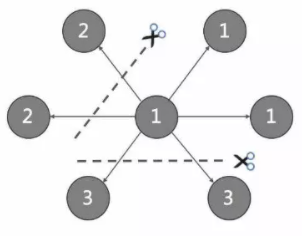
Ъ§ОнФЃаЭ DataModel
дк Nebula Graph жаЃЌУПИіЖЅЕуБЛНЈФЃЮЊвЛИі key-value ЃЌИљОнЦф vertexIDЃЈЛђМђГЦ
vidЃЉЙўЯЃЩЂСаКѓЃЌДцДЂЕНЖдгІЕФ partition ЩЯЁЃ

вЛЬѕТпМвтвхЩЯЕФБпЃЌдк Nebula Graph жаНЋЛсБЛНЈФЃЮЊСНИіЖРСЂЕФ key-value ЃЌЗжБ№ГЦЮЊ
out-key КЭ in-key ЁЃout-key гыетЬѕБпЫљЖдгІЕФЦ№ЕуДцДЂдкЭЌвЛИі partition
ЩЯЃЌin-key гыетЬѕБпЫљЖдгІЕФжеЕуДцДЂдкЭЌвЛИі partition ЩЯЁЃ

ЙигкЪ§ОнФЃаЭЕФЯъЯИЩшМЦЛсдкКѓајЕФЯЕСаЮФеТжаНщЩмЁЃ
ЯЕЭГМмЙЙArchitecture
Nebula Graph АќРЈЫФИіжївЊЕФЙІФмФЃПщЃЌЗжБ№ЪЧДцДЂВуЁЂдЊЪ§ОнЗўЮёЁЂМЦЫуВуКЭПЭЛЇЖЫЁЃ
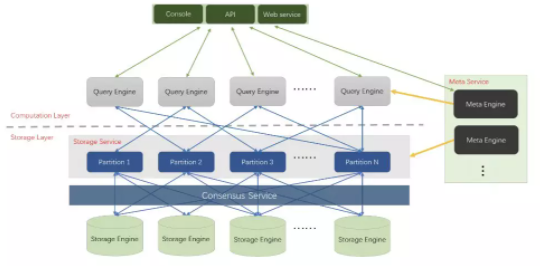
ДцДЂВу Storage
дк Nebula Graph жаДцДЂВуЖдгІНјГЬЪЧ nebula-storaged ЃЌЦфКЫаФЮЊЛљгк RaftЃЈгУРДЙмРэШежОИДжЦЕФвЛжТадЫуЗЈЃЉ
авщЕФЗжВМЪН Key-valueStorage ЁЃ
ФПЧАжЇГжЕФжївЊДцДЂв§ЧцЮЊЁИRocksdbЁЙКЭЁИHBaseЁЙЁЃ
Raft авщЭЈЙ§ leader/follower ЕФЗНЪНЃЌРДБЃГжЪ§ОнжЎМфЕФвЛжТадЁЃNebula
Storage жївЊдіМгСЫвдЯТЙІФмКЭгХЛЏЃК
Parallel RaftЃКдЪаэЖрЬЈЛњЦїЩЯЕФЯрЭЌ partiton-id зщГЩвЛИі Raft group
ЁЃЭЈЙ§Жрзщ Raft group ЪЕЯжВЂЗЂВйзїЁЃ
Write Path & batchЃКRaft авщЕФЖрЛњЦїМфЭЌВНвРРЕгкШежО id ЫГађадЃЌетбљЕФЭЬЭТСП
throughput НЯЕЭЁЃЭЈЙ§ХњСПКЭТвађЬсНЛЕФЗНЪНПЩвдЪЕЯжИќИпЕФЭЬЭТСПЁЃ
LearnerЃКЛљгквьВНИДжЦЕФ learnerЁЃЕБМЏШКжадіМгаТЕФЛњЦїЪБЃЌПЩвдНЋЦфЯШБъМЧЮЊ learnerЃЌВЂвьВНДг
leader/follower РШЁЪ§ОнЁЃЕБИУ learner зЗЩЯ leader КѓЃЌдйБъМЧЮЊ followerЃЌВЮгы
Raft авщЁЃ
Load-balanceЃКЖдгкВПЗжЗУЮЪбЙСІНЯДѓЕФЛњЦїЃЌНЋЦфЫљЗўЮёЕФ partition ЧЈвЦЕННЯРфЕФЛњЦїЩЯЃЌвдЪЕЯжИќКУЕФИКдиОљКтЁЃ
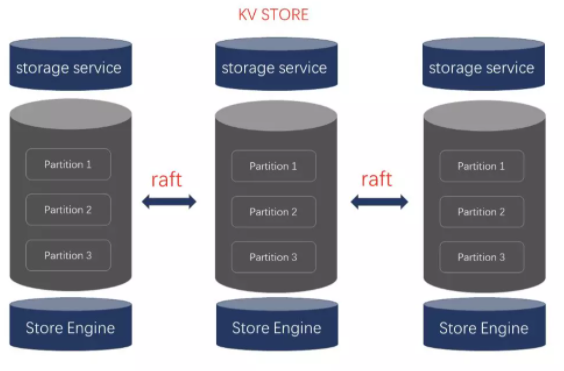
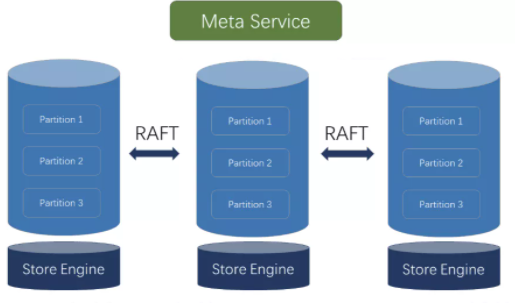
дЊЪ§ОнЗўЮёВу Metaservice
Metaservice ЖдгІЕФНјГЬЪЧ nebula-metad ЃЌЦфжївЊЕФЙІФмгаЃК
гУЛЇЙмРэЃКNebula Graph ЕФгУЛЇЬхЯЕАќРЈ Goduser ЃЌ Admin ЃЌ User
ЃЌ Guest ЫФжжЁЃУПжжгУЛЇЕФВйзїШЈЯоВЛвЛЁЃ
МЏШКХфжУЙмРэЃКжЇГжЩЯЯпЁЂЯТЯпаТЕФЗўЮёЦїЁЃ
ЭМПеМфЙмРэЃКдіГждіМгЁЂЩОГ§ЭМПеМфЃЌаоИФЭМПеМфХфжУЃЈRaftИББОЪ§ЃЉ
Schema ЙмРэЃКNebula Graph ЮЊЧП schema ЩшМЦЁЃ
ЭЈЙ§ Metaservice МЧТМ Tag КЭ Edge ЕФЪєадЕФИїзжЖЮЕФРраЭЁЃжЇГжЕФРраЭгаЃКећаЭ
int, ЫЋОЋЖШРраЭ double, ЪБМфЪ§ОнРраЭ timestamp, СаБэРраЭ listЕШЃЛ
ЖрАцБОЙмРэЃЌжЇГждіМгЁЂаоИФКЭЩОГ§ schemaЃЌВЂМЧТМЦфАцБОКХ
TTL ЙмРэЃЌЭЈЙ§БъЪЖЕНЦкЛиЪе time-to-live зжЖЮЃЌжЇГжЪ§ОнЕФздЖЏЩОГ§КЭПеМфЛиЪе
MetaService ВуЮЊгазДЬЌЕФЗўЮёЃЌЦфзДЬЌГжОУЛЏЗНЗЈгы Storage ВувЛбљЭЈЙ§ KVStore
ЗНЪНДцДЂЁЃ
МЦЫуВу Query Engine & Query Language(nGQL)
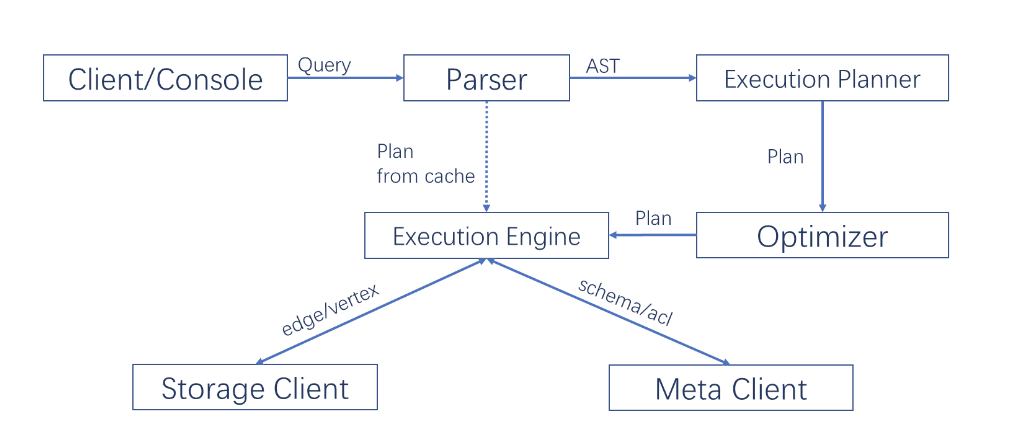
МЦЫуВуЖдгІЕФНјГЬЪЧ nebula-graphd ЃЌЫќгЩЭъШЋЖдЕШЮозДЬЌЮоЙиСЊЕФМЦЫуНкЕузщГЩЃЌМЦЫуНкЕужЎМфЯрЛЅЮоЭЈаХЁЃ
Query Engine ВуЕФжївЊЙІФмЃЌЪЧНтЮіПЭЛЇЖЫЗЂЫЭ nGQL ЮФБОЃЌЭЈЙ§ДЪЗЈНтЮі Lexer
КЭгяЗЈНтЮі Parser ЩњГЩжДааМЦЛЎЃЌВЂЭЈЙ§гХЛЏКѓНЋжДааМЦЛЎНЛгЩжДаав§ЧцЃЌжДаав§ЧцЭЈЙ§ MetaService
ЛёШЁЭМЕуКЭБпЕФ schemaЃЌВЂЭЈЙ§ДцДЂв§ЧцВуЛёШЁЕуКЭБпЕФЪ§ОнЁЃ
Query Engine ВуЕФжївЊгХЛЏгаЃК
вьВНКЭВЂЗЂжДааЃКгЩгк IO КЭЭјТчОљЮЊГЄЪБбгВйзїЃЌашВЩгУвьВНМАВЂЗЂВйзїЁЃДЫЭтЃЌЮЊБмУтЕЅИіГЄ query
гАЯьКѓај queryЃЌQuery Engine ЮЊУПИі query ЩшжУЕЅЖРЕФзЪдДГивдБЃжЄЗўЮёжЪСП
QoSЁЃ
МЦЫуЯТГСЃКЮЊБмУтДцДЂВуНЋЙ§ЖрЪ§ОнЛиДЋЕНМЦЫуВуеМгУБІЙѓЕФДјПэЃЌЬѕМўЙ§ТЫ where ЕШЫузгЛсЫцВщбЏЬѕМўвЛЭЌЯТЗЂЕНДцДЂВуНкЕуЁЃ
жДааМЦЛЎгХЛЏЃКЫфШЛдкЙиЯЕЪ§ОнПт SQL жажДааМЦЛЎгХЛЏвбООРњСЫГЄЪБМфЕФЗЂеЙЃЌЕЋвЕНчЖдЭМВщбЏгябдЕФгХЛЏбаОПНЯЩйЁЃNebula
Graph ЖдЭМВщбЏЕФжДааМЦЛЎгХЛЏНјааСЫвЛЖЈЕФЬНЫїЃЌАќРЈжДааМЦЛЎЛКДцКЭЩЯЯТЮФЮоЙигяОфВЂЗЂжДааЁЃ
ПЭЛЇЖЫ API & Console
Nebula Graph ЬсЙЉ C++ЁЂJavaЁЂGolang Ш§жжгябдЕФПЭЛЇЖЫЃЌгыЗўЮёЦїжЎМфЕФЭЈаХЗНЪНЮЊ
RPCЃЌВЩгУЕФЭЈаХавщЮЊ Facebook-ThriftЁЃгУЛЇвВПЩЭЈЙ§ Linux ЩЯ console
ЪЕЯжЖд Nebula Graph ВйзїЁЃWeb ЗУЮЪЗНЪНФПЧАдкПЊЗЂЙ§ГЬжаЁЃ
| 








