| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫУРЭХЭМЪ§ОнПтЕФбЁаЭЃЌЭМЪ§ОнПтЦНЬЈНЈЩшвдМАвЕЮёЪЕМљЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздВЉПЭдАЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
НёЬьЗжЯэЯТУРЭХЭМЪ§ОнПтЦНЬЈЕФНЈЩшвдМАвЕЮёЪЕМљЁЃ

етЪЧБОДЮБЈИцЕФЬсИйЃЌжївЊАќРЈвдЯТСљЗНУцФкШнЁЃ
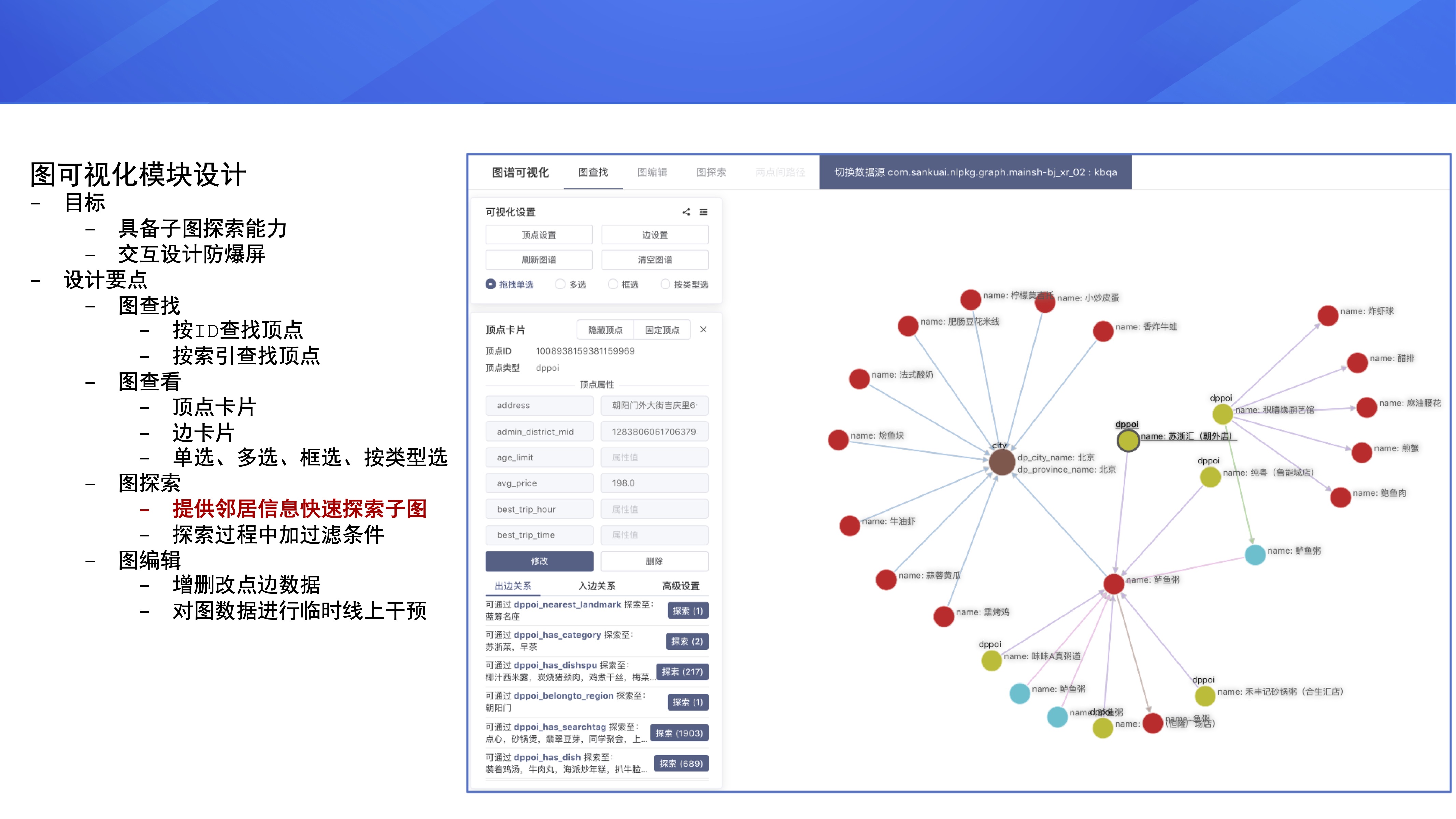
БГОАНщЩм

ЪзЯШНщЩмЯТУРЭХдкЭМЪ§ОнЗНУцЕФвЕЮёашЧѓЁЃ

УРЭХФкВПгаБШНЯЖрЕФЭМЪ§ОнДцДЂвдМАЖрЬјВщбЏашЧѓЃЌзмЬхРДЫЕгавдЯТ 4 ИіЗНУцЃК
ЕквЛИіЗНУцЪЧжЊЪЖЭМЦзЗНЯђЃЌУРЭХФкВПгаУРЪГЭМЦзЁЂЩЬЦЗЭМЦзЁЂТУгЮЭМЦздкФкЕФНќ 10 ИіСьгђжЊЪЖЭМЦзЃЌЪ§ОнСПМЖДѓИХдкЧЇвкМЖБ№ЁЃдкЕќДњЁЂЭкОђЪ§ОнЕФЙ§ГЬжаЃЌашвЊвЛжжзщМўЖдетаЉЭМЦзЪ§ОнНјааЭГвЛЙмРэЁЃ
ЕкЖўИіЗНУцЪЧАВШЋЗчПиЁЃвЕЮёВПУХгаФкШнЗчПиЕФашЧѓЃЌЯЃЭћдкЩЬЛЇЁЂгУЛЇЁЂЦРТлжаЭЈЙ§ЖрЬјВщбЏРДЪЖБ№ащМйЦРМлЃЛдкжЇИЖЪБНјааН№ШкЗчПибщжЄЃЌЪЕЪБЖрЬјВщбЏЗчЯеЕуЁЃ
ЕкШ§ИіЗНУцЪЧСДТЗЗжЮіЃЌБШШчЫЕЃКЪ§ОнбЊдЕЙмРэЃЌЙЋЫОЪ§ОнЦНЬЈЩЯгаКмЖр ETL JobЃЌJob КЭ Job
жЎМфДцдкЧПШѕвРРЕЙиЯЕЃЌетаЉЧПШѕвРРЕЙиЯЕаЮГЩСЫвЛеХЭМЃЌдкНјаа ETL Job ЕФгХЛЏЛђепЙЪеЯДІРэЪБЃЌашвЊЖдетИіЭМНјааЗжЮіЁЃРрЫЦЕФашЧѓЛЙгаДњТыЗжЮіЁЂЗўЮёжЮРэЕШЁЃ
ЕкЫФИіЗНУцЪЧзщжЏМмЙЙЙмРэЃЌАќРЈЃКЙЋЫОзщжЏМмЙЙЕФЙмРэЃЌЪЕЯпЛуБЈСДЁЂащЯпЛуБЈСДЁЂащФтзщжЏЕФЙмРэЃЌвдМАЩЬМвСЌЫјУХЕъЕФЙмРэЁЃБШШчЃЌашвЊЙмРэвЛИіЩЬМвдкВЛЭЌЧјгђЖМгаФФаЉУХЕъЃЌФмЙЛНјааЖрВуЙиЯЕВщевЛђепФцЯђЙиЯЕЫбЫїЁЃ
змЬхРДЫЕЃЌЮвУЧашвЊвЛжжзщМўРДЙмРэЧЇвкМЖБ№ЕФЭМЪ§ОнЃЌНтОіЭМЪ§ОнДцДЂвдМАЖрЬјВщбЏЮЪЬтЁЃ
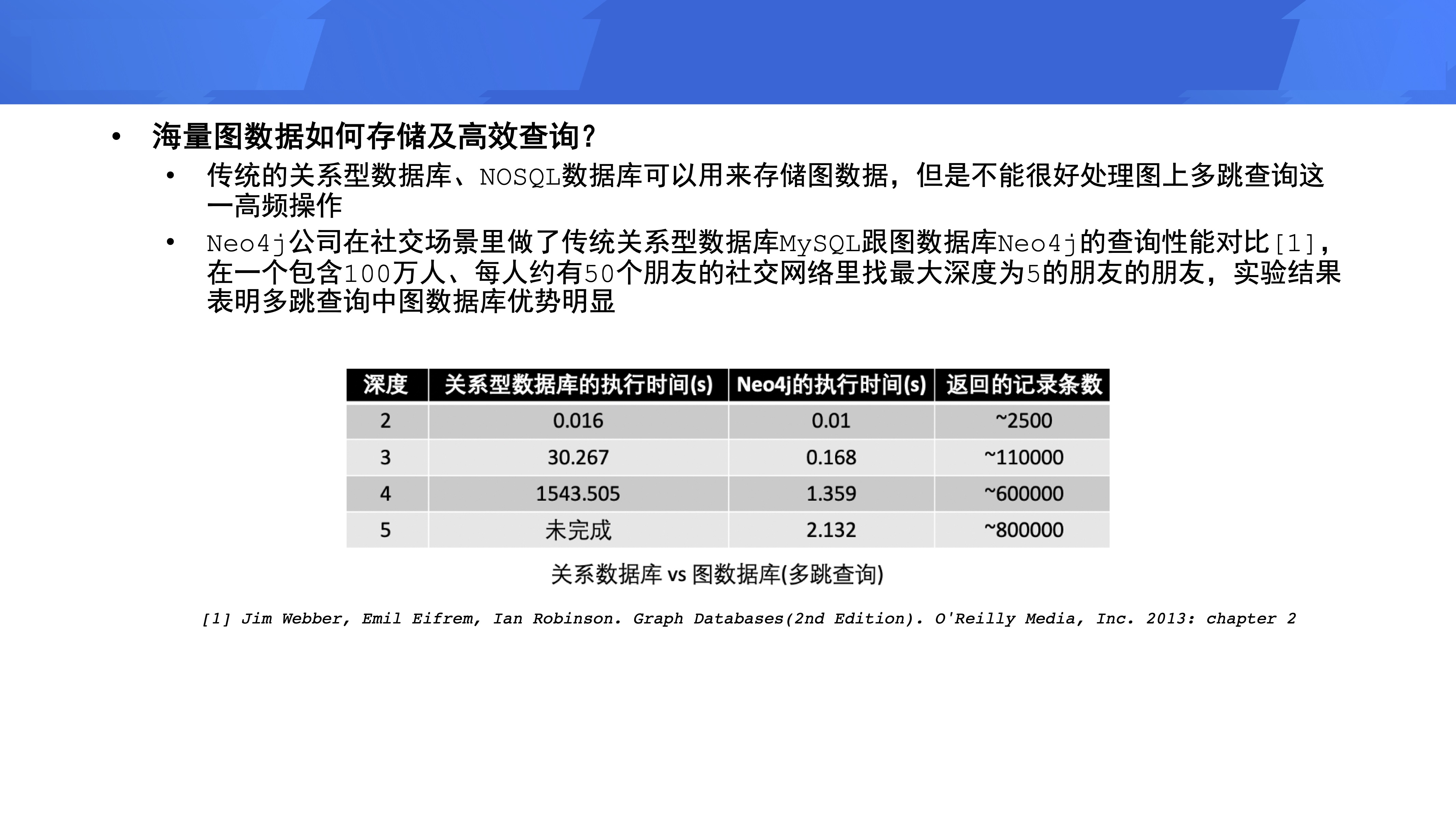
ДЋЭГЕФЙиЯЕаЭЪ§ОнПтЁЂNoSQL Ъ§ОнПтПЩвдгУРДДцДЂЭМЪ§ОнЃЌЕЋЪЧВЛФмКмКУДІРэЭМЩЯЖрЬјВщбЏетвЛИпЦЕВйзїЁЃNeo4j
ЙЋЫОдкЩчНЛГЁОАзіСЫ MySQL КЭ Neo4j ЕФЖрЬјВщбЏадФмЖдБШЃЌОпЬхВтЪдГЁОАЪЧЃЌдквЛИі 100
ЭђШЫЁЂУПИіШЫДѓИХга 50 ИіХѓгбЕФЩчНЛЭјТчРяевзюДѓЩюЖШЮЊ 5 ЕФХѓгбЕФХѓгбЁЃДгВтЪдНсЙћПДЃЌВщбЏЩюЖШдіДѓЕН
5 ЪБЃЌ MySQL вбОВщВЛГіНсЙћСЫЃЌЕЋ Neo4j вРШЛФмдкУыМЖЗЕЛиЪ§ОнЁЃЪЕбщНсЙћБэУїЖрЬјВщбЏжаЭМЪ§ОнПтгХЪЦУїЯдЁЃ
ЭМЪ§ОнПтбЁаЭ 
ЯТУцНщЩмЮвУЧЕФЭМЪ§ОнПтбЁаЭЙЄзїЁЃ

ЮвУЧжївЊгавдЯТ 5 ИіЭМЪ§ОнПтбЁаЭвЊЧѓ
A. ЯюФППЊдДЃЌднЪБВЛПМТЧашвЊИЖЗбЕФЭМЪ§ОнПтЃЛ
B. ЗжВМЪНЕФМмЙЙЩшМЦЃЌОпБИСМКУЕФПЩРЉеЙадЃЛ
C. КСУыМЖЕФЖрЬјВщбЏбгГйЃЛ
D. жЇГжЧЇвкСПМЖЕуБпДцДЂЃЛ
E. ОпБИХњСПДгЪ§ВжЕМШыЪ§ОнЕФФмСІЁЃ
ЮвУЧЗжЮіСЫ DB-Engine ЩЯХХУћ Top30 ЕФЭМЪ§ОнПтЃЌЬоГ§ВЛПЊдДЕФЯюФПКѓЃЌАбЪЃЯТЕФЭМЪ§ОнПтЗжГЩШ§РрЁЃ
ЕквЛРрАќРЈ Neo4jЁЂArangoDBЁЂVirtuosoЁЂTigerGraphЁЂRedisGraphЁЃДЫРрЭМЪ§ОнПтжЛгаЕЅЛњАцБОПЊдДПЩгУЃЌадФмБШНЯгХауЃЌЕЋЪЧВЛФмгІЖдЗжВМЪНГЁОАжаЪ§ОнЕФЙцФЃдіГЄЃЌМДВЛТњзубЁаЭвЊЧѓ
BЁЂDЃЛ
ЕкЖўРрАќРЈ JanusGraphЁЂHugeGraphЁЃДЫРрЭМЪ§ОнПтдкЯжгаДцДЂЯЕЭГжЎЩЯаТдіСЫЭЈгУЕФЭМгявхНтЪЭВуЃЌЭМгявхВуЬсЙЉСЫЭМБщРњЕФФмСІЃЌЕЋЪЧЪмЕНДцДЂВуЛђепМмЙЙЯожЦЃЌВЛжЇГжЭъећЕФМЦЫуЯТЭЦЃЌЖрЬјБщРњЕФадФмНЯВюЃЌКмФбТњзу
OLTP ГЁОАЯТЖдЕЭбгЪБЕФвЊЧѓЃЌМДВЛТњзубЁаЭвЊЧѓ CЃЛ
ЕкШ§РрАќРЈ DgraphЁЂNebula GraphЁЃДЫРрЭМЪ§ОнПтИљОнЭМЪ§ОнЕФЬиЕуЖдЪ§ОнДцДЂФЃаЭЁЂЕуБпЗжВМЁЂжДаав§ЧцНјааСЫШЋаТЩшМЦЃЌЖдЭМЕФЖрЬјБщРњНјааСЫЩюЖШгХЛЏЃЌЛљБОТњзуЮвУЧЖдЭМЪ§ОнПтЕФбЁаЭвЊЧѓ

жЎКѓЮвУЧдквЛИіЙЋПЊЩчНЛЪ§ОнМЏЩЯЃЈДѓдМ 200 вкЕуБпЃЉЖд Nebula Graph ЁЂDgraph
ЁЂHugeGraph НјааСЫЩюЖШадФмВтЦРЁЃжївЊДгШ§ИіЗНУцНјааЦРВтЃК
ХњСПЪ§ОнЕФЕМШы
ЪЕЪБаДШыадФмВтЪд
Ъ§ОнЖрЬјВщбЏадФмВтЪд

ДгВтЪдНсЙћПД Nebula Graph дкЪ§ОнЕМШыЁЂЪЕЪБаДШыМАЖрЬјВщбЏЗНУцадФмОљгХгкОКЦЗЁЃДЫЭтЃЌNebula
Graph ЩчЧјЛюдОЃЌЮЪЬтЕФЯьгІЫйЖШПьЃЌЫљвдЭХЖгзюжебЁдёСЫЛљгк Nebula Graph РДДюНЈЭМЪ§ОнПтЦНЬЈЁЃ
ЭМЪ§ОнПтЦНЬЈНЈЩш

ЯТУцНщЩмУРЭХЭМЪ§ОнПтЦНЬЈЕФНЈЩшЃЌећИіЭМЪ§ОнПтЦНЬЈАќРЈ 4 ВуЁЃ
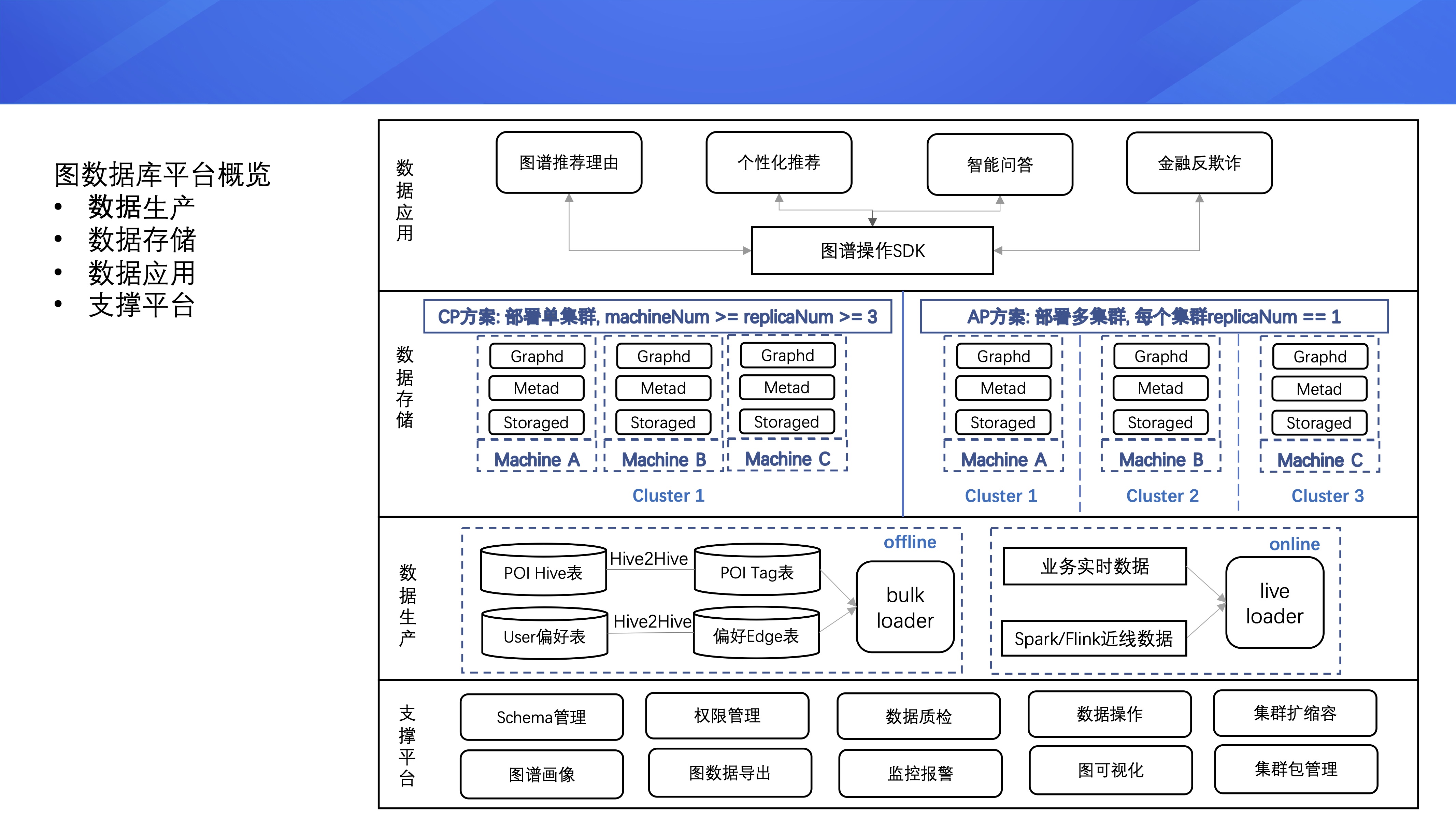
ЕквЛВуЪЧЪ§ОнЩњВњВуЃЌЦНЬЈЕФЭМЪ§ОнжївЊгаСНжжРДдДЃЌЕквЛжжЪЧвЕЮёЗНАбЪ§ВжжаЪ§ОнЭЈЙ§ ETL Job зЊГЩЕуКЭБпЕФ
Hive БэЃЌШЛКѓРыЯпЕМШыЕНЭМЪ§ОнПтжаЃЛЕкЖўжжЪЧвЕЮёЯпЩЯЪЕЪБВњЩњЕФЪ§ОнЁЂЛђепЭЈЙ§ SparkЁЂFlink
ЕШСїЪНДІРэВњЩњЕФНќЯпЪ§ОнЃЌЪЕЪБЕиЭЈЙ§ Nebula Graph ЬсЙЉЕФдкЯпХњСПНгПкЙрЕНЭМЪ§ОнПтжаЁЃ
ЕкЖўВуЪЧЪ§ОнДцДЂВуЃЌЦНЬЈжЇГжСНжжЭМЪ§ОнПтМЏШКЕФВПЪ№ЗНЪНЁЃ
ЕквЛжжЪЧ CP ЗНАИЃЌМД Consistency & Partition toleranceЃЌетЪЧ
Nebula Graph дЩњжЇГжЕФМЏШКВПЪ№ЗНЪНЁЃЕЅМЏШКВПЪ№ЃЌМЏШКжаЛњЦїЪ§СПДѓгкЕШгкИББОЕФЪ§СПЃЌИББОЪ§СПДѓгкЕШгк
3 ЁЃжЛвЊМЏШКжагаДѓгкИББОЪ§вЛАыЕФЛњЦїДцЛюЃЌећИіМЏШКОЭПЩвдЖдЭте§ГЃЬсЙЉЗўЮёЁЃCP ЗНАИБЃжЄСЫЪ§ОнЖСаДЕФЧПвЛжТадЃЌЕЋетжжВПЪ№ЗНЪНЯТМЏШКПЩгУадВЛИпЁЃ
ЕкЖўжжВПЪ№ЗНЪНЪЧ AP ЗНАИЃЌМД Availability & Partition toleranceЃЌдквЛИігІгУжаВПЪ№ЖрИіЭМЪ§ОнПтМЏШКЃЌУПИіМЏШКЪ§ОнИББОЪ§ЮЊ
1 ЃЌЖрМЏШКжЎМфНјааЛЅБИЁЃетжжВПЪ№ЗНЪНЕФКУДІдкгкећИігІгУЖдЭтЕФПЩгУадИпЃЌЕЋЪ§ОнЖСаДЕФвЛжТадвЊВюЕуЁЃ
ЕкШ§ВуЪЧЪ§ОнгІгУВуЃЌвЕЮёЗНПЩвддквЕЮёЗўЮёжав§ШыЦНЬЈЬсЙЉЕФЭМЦз SDKЃЌЪЕЪБЕиЖдЭМЪ§ОнНјаадіЩОИФВщЁЃ
ЕкЫФВуЪЧжЇГХЦНЬЈЃЌЬсЙЉСЫ Schema ЙмРэЁЂШЈЯоЙмРэЁЂЪ§ОнжЪМьЁЂЪ§ОндіЩОИФВщЁЂМЏШКРЉЫѕШнЁЂЭМЦзЛЯёЁЂЭМЪ§ОнЕМГіЁЂМрПиБЈОЏЁЂЭМПЩЪгЛЏЁЂМЏШКАќЙмРэЕШЙІФмЁЃ
ОЙ§етЫФВуМмЙЙЩшМЦЃЌФПЧАЭМЪ§ОнПтЦНЬЈЛљБООпБИСЫЖдЭМЪ§ОнЕФвЛеОЪНзджњЙмРэЙІФмЁЃШчЙћФГИівЕЮёЗНвЊЪЙгУетжжЭМЪ§ОнПтФмСІЃЌФЧУДвЕЮёЗНПЩвддкетИіЦНЬЈЩЯзджњЕиДДНЈЭМЪ§ОнПтМЏШКЁЂДДНЈЭМЕФ
SchemaЁЂЕМШыЭМЪ§ОнЁЂХфжУЕМШыЪ§ОнЕФжДааМЦЛЎЁЂв§ШыЦНЬЈЬсЙЉЕФ SDK ЖдЪ§ОнНјааВйзїЃЛЦНЬЈВржївЊИКд№ИївЕЮёЗНЭМЪ§ОнПтМЏШКЕФЮШЖЈадЁЃФПЧАгаШ§ЁЂЫФЪЎИівЕЮёдкЦНЬЈЩЯеце§ТфЕиЃЌЛљБОФмТњзуИїИівЕЮёЗНашЧѓЁЃ
дйНщЩмЯТЭМЪ§ОнПтЦНЬЈжаМИИіКЫаФФЃПщЕФЩшМЦЁЃ
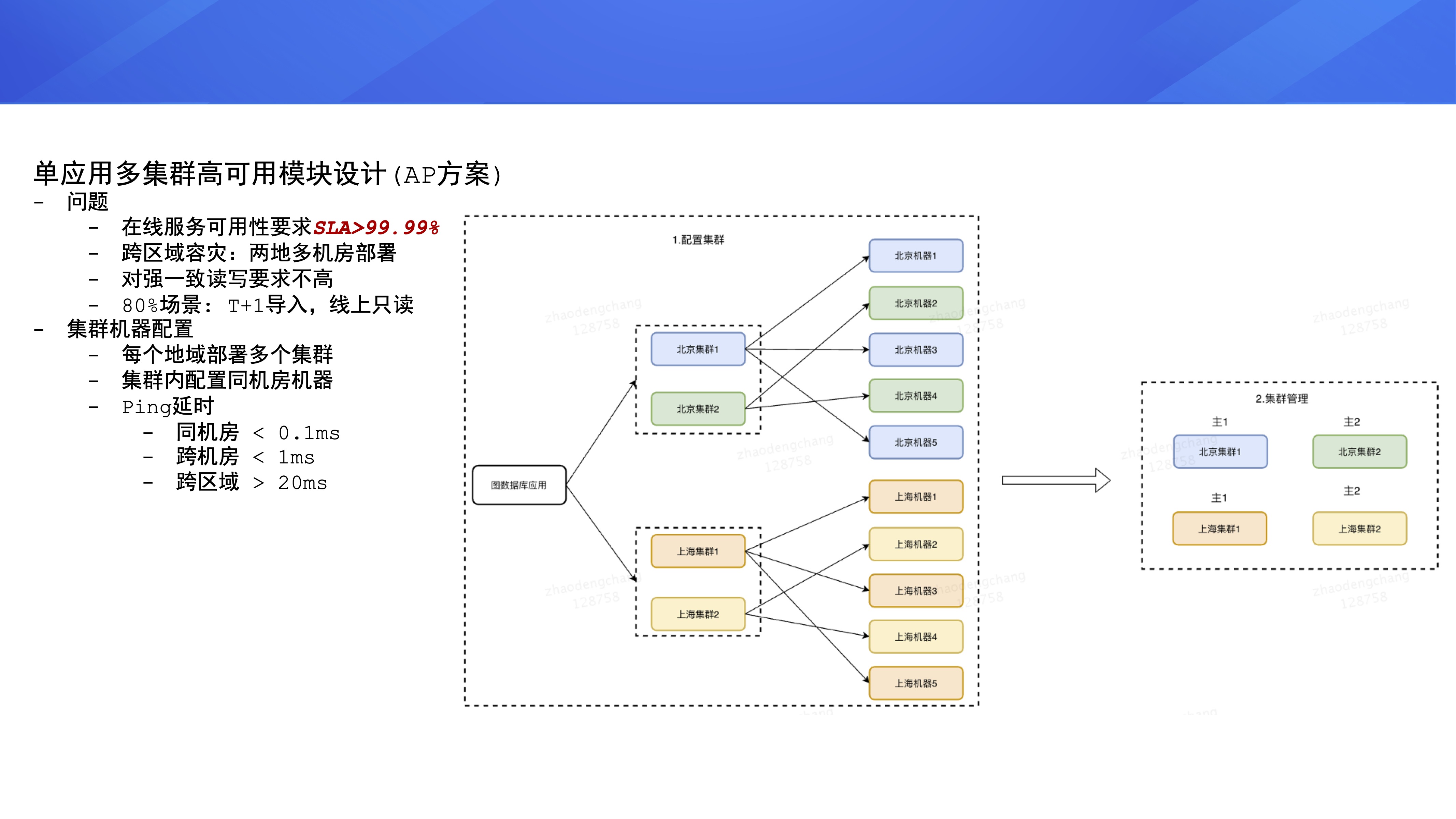
ИпПЩгУФЃПщЩшМЦ
ЪзЯШЪЧЕЅгІгУЖрМЏШКИпПЩгУФЃПщЕФЩшМЦЃЈAP ЗНАИЃЉЁЃЮЊЪВУДга AP ЗНАИЕФЩшМЦФиЃПвђЮЊНгШыетИіЭМЪ§ОнПтЦНЬЈЕФвЕЮёЗНБШНЯдквтЕФжИБъЪЧМЏШКПЩгУадЁЃдкЯпЗўЮёЖдМЏШКЕФПЩгУадвЊЧѓЗЧГЃИпЃЌзюЛљДЁЕФвЊЧѓЪЧМЏШКПЩгУадФмДяЕН
4 Иі 9ЃЌМДвЛФъРяМЏШКЕФВЛПЩгУЪБМфвЊаЁгквЛИіаЁЪБЃЌЖдгкдкЯпЗўЮёРДЫЕЃЌЗўЮёЛђепМЏШКЕФПЩгУадЪЧећИівЕЮёЕФЩњУќЯпЃЌШчЙћетЕуБЃжЄВЛСЫЃЌМДЪЙМЏШКЬсЙЉЕФФмСІдйЖрдйЗсИЛЃЌФЧУДвЕЮёЗНвВВЛЛсПМТЧЪЙгУЃЌПЩгУадЪЧвЕЮёбЁаЭЕФЛљДЁЁЃ
СэЭтЙЋЫОвЊЧѓжаМфМўвЊгаПчЧјгђШнджФмСІЃЌМДвЊОпБИдкЖрИіЕигђВПЪ№ЖрМЏШКЕФФмСІЁЃЮвУЧЗжЮіСЫЦНЬЈНгШыЗНЕФвЕЮёашЧѓЃЌДѓдМ
80% ЕФГЁОАЪЧ T+1 ШЋСПЕМШыЪ§ОнЁЂЯпЩЯжЛЖСЃЛдкетжжГЁОАЯТЖдЭМЪ§ОнЕФЖСаДЧПвЛжТадвЊЧѓВЂВЛИпЃЌвђДЫЮвУЧЩшМЦСЫЕЅгІгУЖрМЏШКетжжВПЪ№ЗНАИЁЃ
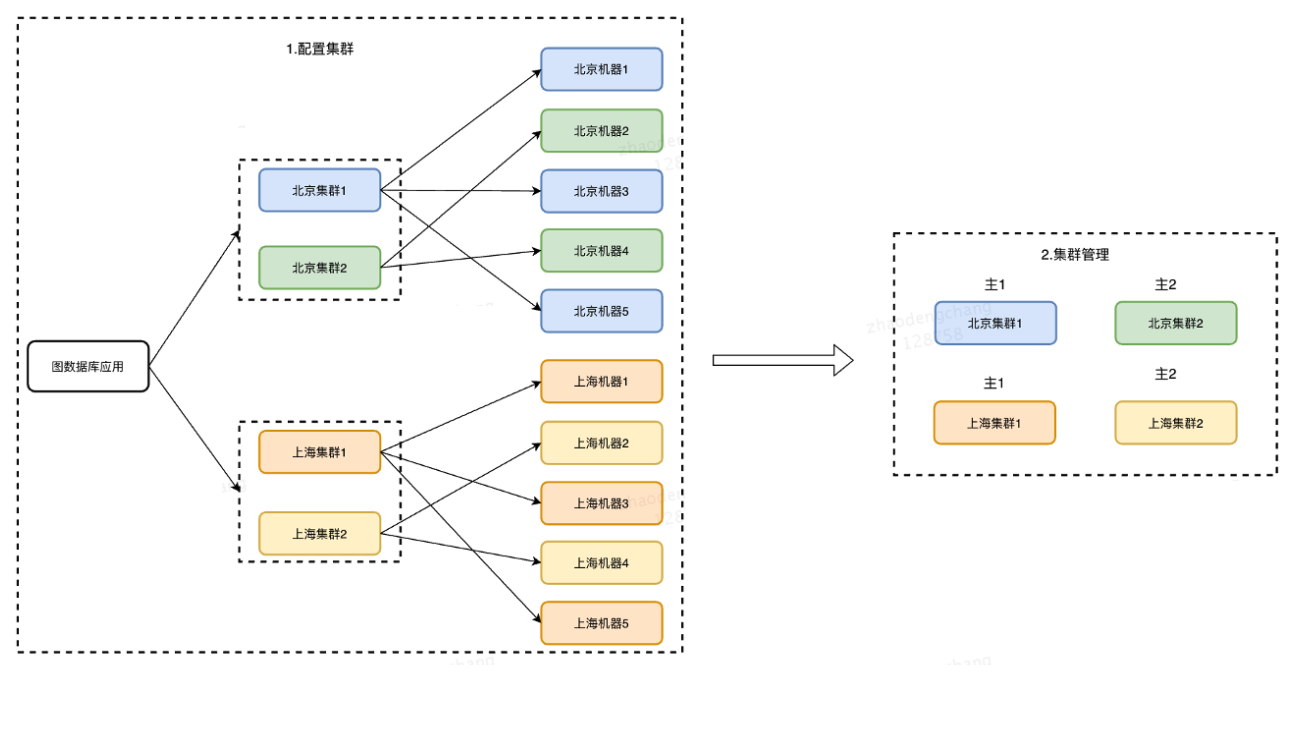
ВПЪ№ЗНЪНПЩвдВЮПМЩЯЭМЃЌвЛИівЕЮёЗНдкЭМЪ§ОнПтЦНЬЈЩЯДДНЈСЫ 1 ИігІгУВЂВПЪ№СЫ 4 ИіМЏШКЃЌЦфжаББОЉ
2 ИіЁЂЩЯКЃ 2 ИіЃЌЦНЪБет 4 ИіМЏШКЭЌЪБЖдЭтЬсЙЉЗўЮёЁЃМйШчЯждкББОЉМЏШК 1 ЙвСЫЃЌФЧУДББОЉМЏШК
2 ПЩвдЬсЙЉЗўЮёЁЃШчЙћЫЕецФЧУДВЛЧЩЃЌББОЉМЏШКЖМЙвСЫЃЌЛђепЖдЭтЕФЭјТчВЛПЩгУЃЌФЧУДЩЯКЃЕФМЏШКПЩвдЬсЙЉЗўЮёЃЌетжжВПЪ№ЗНЪНЯТЃЌЦНЬЈЛсОЁПЩФмЕиЭЈЙ§вЛаЉЗНЪНРДБЃжЄећИігІгУЕФПЩгУадЁЃШЛКѓУПИіМЏШКФкВПОЁСПВПЪ№ЭЌЛњЗПЕФЛњЦїЃЌвђЮЊЭМЪ§ОнМЏШКФкВП
RPC ЪЧЗЧГЃЖрЕФЃЌШчЙћгаПчЛњЗПЛђепПчЧјгђЕФЦЕЗБЕїгУЃЌећИіМЏШКЖдЭтЕФадФмЛсБШНЯЕЭЁЃ
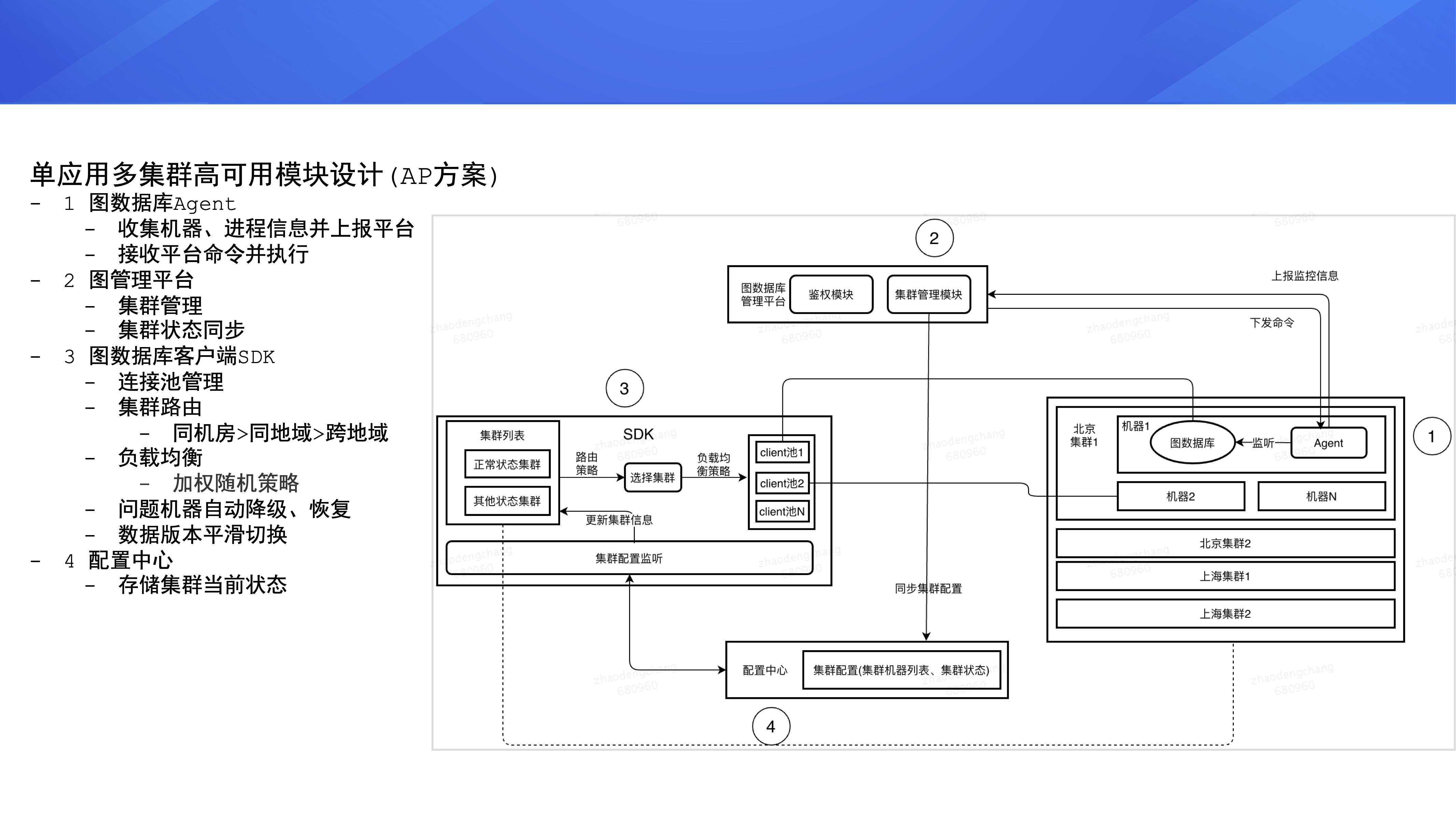
етИі AP ФЃПщЕФЩшМЦжївЊАќКЌЯТУц 4 ИіВПЗжЃК
ЕквЛВПЗжЪЧгвВрЕФЭМЪ§ОнПт AgentЃЌЫќЪЧВПЪ№дкЭМЪ§ОнПтМЏШКЕФвЛИіНјГЬЃЌгУРДЪеМЏЛњЦїКЭNebula
Graph Ш§ИіКЫаФФЃПщЕФаХЯЂЃЌВЂЩЯБЈЕНЭМЪ§ОнПтЦНЬЈЁЃAgent ФмЙЛНгЪеЭМЪ§ОнПтЦНЬЈЕФУќСюВЂЖдЭМЪ§ОнПтНјааВйзїЁЃ
ЕкЖўВПЗжЪЧЭМЙмРэЦНЬЈЃЌЫќжївЊЪЧЖдМЏШКНјааЙмРэЃЌВЂЭЌВНЭМЪ§ОнПтМЏШКЕФзДЬЌЕНХфжУжааФЁЃ
ЕкШ§ВПЗжЪЧЭМЪ§ОнПт SDKЃЌЫќжївЊзіЕФЪТЧщЪЧЙмРэСЌНгЕНЭМЪ§ОнПтМЏШКЕФСЌНгЁЃШчЙћвЕЮёЗНЗЂЫЭСЫФГИіВщбЏЧыЧѓЃЌSDK
ЛсНјааМЏШКЕФТЗгЩКЭИКдиОљКтЃЌбЁдёГівЛЬѕИпжЪСПЕФСЌНгРДЗЂЫЭЧыЧѓЁЃДЫЭтЃЌSDK ЛЙЛсДІРэЭМЪ§ОнПтМЏШКжаЮЪЬтЛњЦїЕФздЖЏНЕМЖвдМАЛжИДЃЌВЂЧввЊжЇГжЦНЛЌЧаЛЛМЏШКЕФЪ§ОнАцБОЁЃ
ЕкЫФВПЗжЪЧХфжУжааФЃЌРрЫЦ ZooKeeperЃЌДцДЂМЏШКЕФЕБЧАзДЬЌЁЃ
УПаЁЪБАйвкМЖЪ§ОнЕМШыФЃПщЩшМЦ
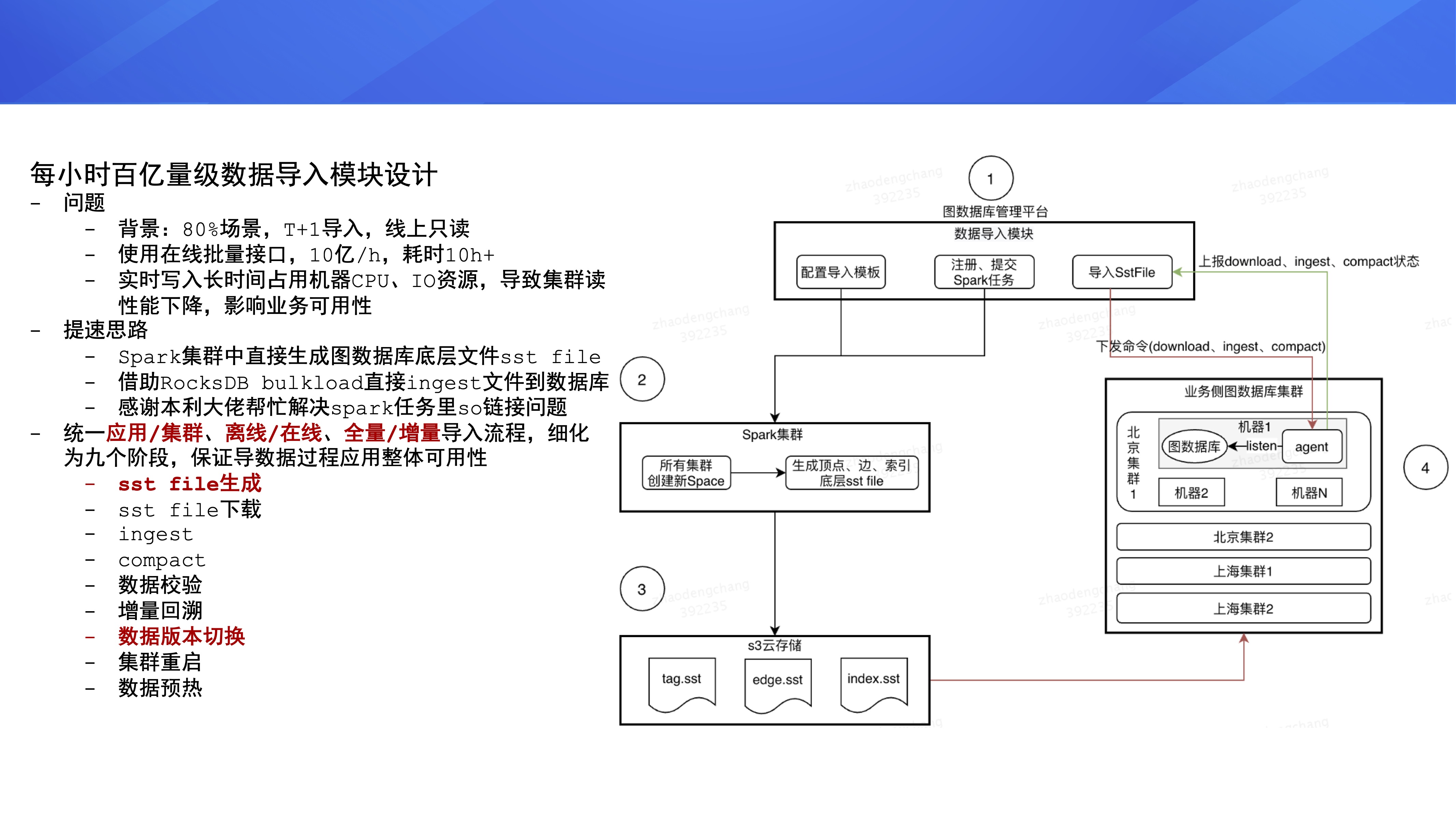
ЕкЖўИіФЃПщЪЧУПаЁЪБАйвкСПМЖЪ§ОнЕМШыФЃПщЃЌЩЯУцЫЕСЫвЕЮёГЁОАРя 80% ЪЧ T+1 ШЋСПЕМШыЪ§ОнЃЌШЛКѓЯпЩЯжЛЖСЁЃЦНЬЈдк
19 ФъЕз / 20 ФъГѕШЋСПЕМШыЪ§ОнЕФЗНЪНЪЧЕїгУ Nebula Graph ЖдЭтЬсЙЉЕФХњСПЪ§ОнЕМШыНгПкЃЌетжжЗНЪНЕФЪ§ОнаДШыЫйТЪДѓИХЪЧУПаЁЪБ
10 вкМЖБ№ЃЌЕМШыАйвкЪ§ОнДѓИХвЊКФЗб 10 ИіаЁЪБЃЌетИіЪБМфгаЕуОУЁЃДЫЭтЃЌдквдМИЪЎЭђУПУыЕФЫйЖШЕМЪ§ОнЕФЙ§ГЬжаЃЌЛсГЄЦкеМгУЛњЦїЕФ
CPUЁЂIO зЪдДЃЌвЛЗНУцЛсЖдЛњЦїдьГЩЫ№КФЃЌСэвЛЗНУцЪ§ОнЕМШыЙ§ГЬжаМЏШКЖдЭтЬсЙЉЕФЖСадФмЛсБфШѕЁЃ
ЮЊСЫНтОіЩЯУцСНИіЮЪЬтЃЌЦНЬЈНјааСЫШчЯТгХЛЏЃКдк Spark МЏШКжажБНгЩњГЩЭМЪ§ОнПтЕзВуЮФМў sst
fileЃЌдйНшжњ RocksDB ЕФ bulkload ЙІФмжБНг ingest ЮФМўЕНЭМЪ§ОнПтЁЃетВПЗжЬсЫйгХЛЏЙЄзїдк
19 ФъЕзЕФЪБКђОЭПЊЪМСЫЃЌЕЋЪЧжаМфгіЕН core dump ЮЪЬтУЛгаЩЯЯпЁЃдк 20 ФъСљЁЂЦпдТЗнЕФЪБКђЃЌЮЂаХЕФБОРћДѓРаЯђЩчЧјЬсНЛСЫетЗНУцЕФ
prЃЌКЭЫћдкЯпЙЕЭЈжЎКѓНтОіСЫЮвУЧЕФЮЪЬтЃЌдкетРяИааЛвЛЯТБОРћДѓРа ?? ЁЃ
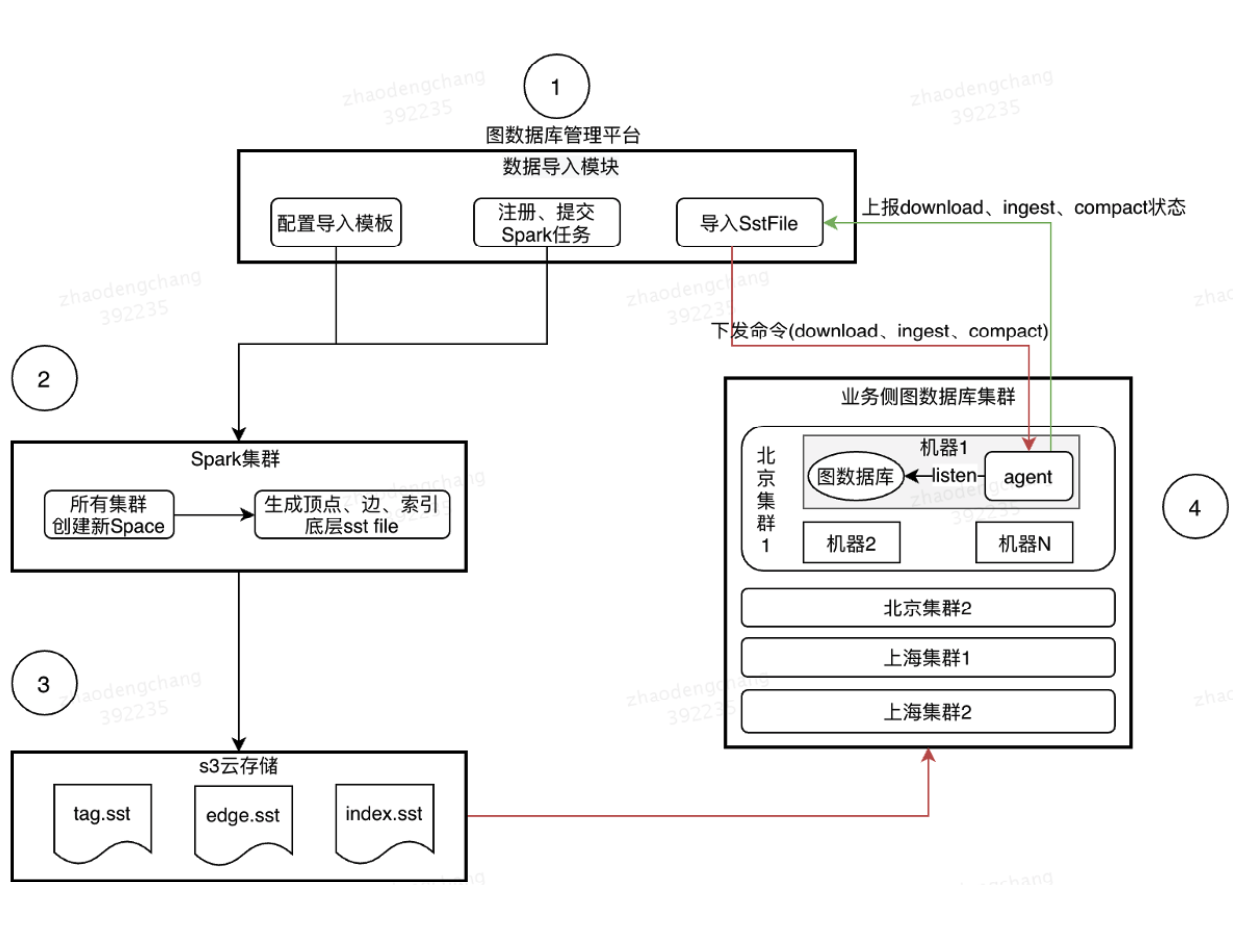
ЭМЪ§ОнПтЦНЬЈЪ§ОнЕМШыЕФКЫаФСїГЬПЩвдПДгвБпетеХЭМЃЌЕБгУЛЇдкЦНЬЈЩЯЬсНЛСЫЕМЪ§ОнВйзїКѓЃЌЭМЪ§ОнПтЦНЬЈЛсЯђЙЋЫОЕФ
Spark МЏШКЬсНЛвЛИі Spark ШЮЮёЃЌдк Spark ШЮЮёжаЛсЩњГЩЭМЪ§ОнПтРяЯрЙиЕФЕуЁЂБпвдМАЕуЫїв§ЁЂБпЫїв§ЯрЙиЕФ
sst ЮФМўЃЌВЂЩЯДЋЕНЙЋЫОЕФ S3 дЦДцДЂЩЯЁЃЮФМўЩњГЩКѓЃЌЭМЪ§ОнПтЦНЬЈЛсЭЈжЊгІгУРяЕФЖрИіМЏШКШЅЯТдиетаЉДцДЂЮФМўЃЌжЎКѓЭъГЩ
ingest Ињ compact ВйзїЃЌзюКѓЭъГЩЪ§ОнАцБОЕФЧаЛЛЁЃ
ЦНЬЈЗНЮЊМцЙЫИїИівЕЮёЗНЕФВЛЭЌашЧѓЃЌЭГвЛСЫгІгУЕМШыЁЂМЏШКЕМШыЁЂРыЯпЕМШыЁЂдкЯпЕМШывдМАШЋСПЕМШыЁЂдіСПЕМШыетаЉГЁОАЃЌШЛКѓЯИЗжГЩЯТУцОХИіНзЖЮЃЌДгСїГЬЩЯБЃжЄдкЕМЪ§ОнЙ§ГЬжагІгУећЬхЕФПЩгУадЁЃ
sst fileЩњГЩ
sst fileЯТди
ingest
compact
Ъ§ОнаЃбщ
діСПЛиЫн
Ъ§ОнАцБОЧаЛЛ
МЏШКжиЦє
Ъ§ОндЄШШ
ЪЕЪБаДШыЖрМЏШКЪ§ОнЭЌВНФЃПщЩшМЦ
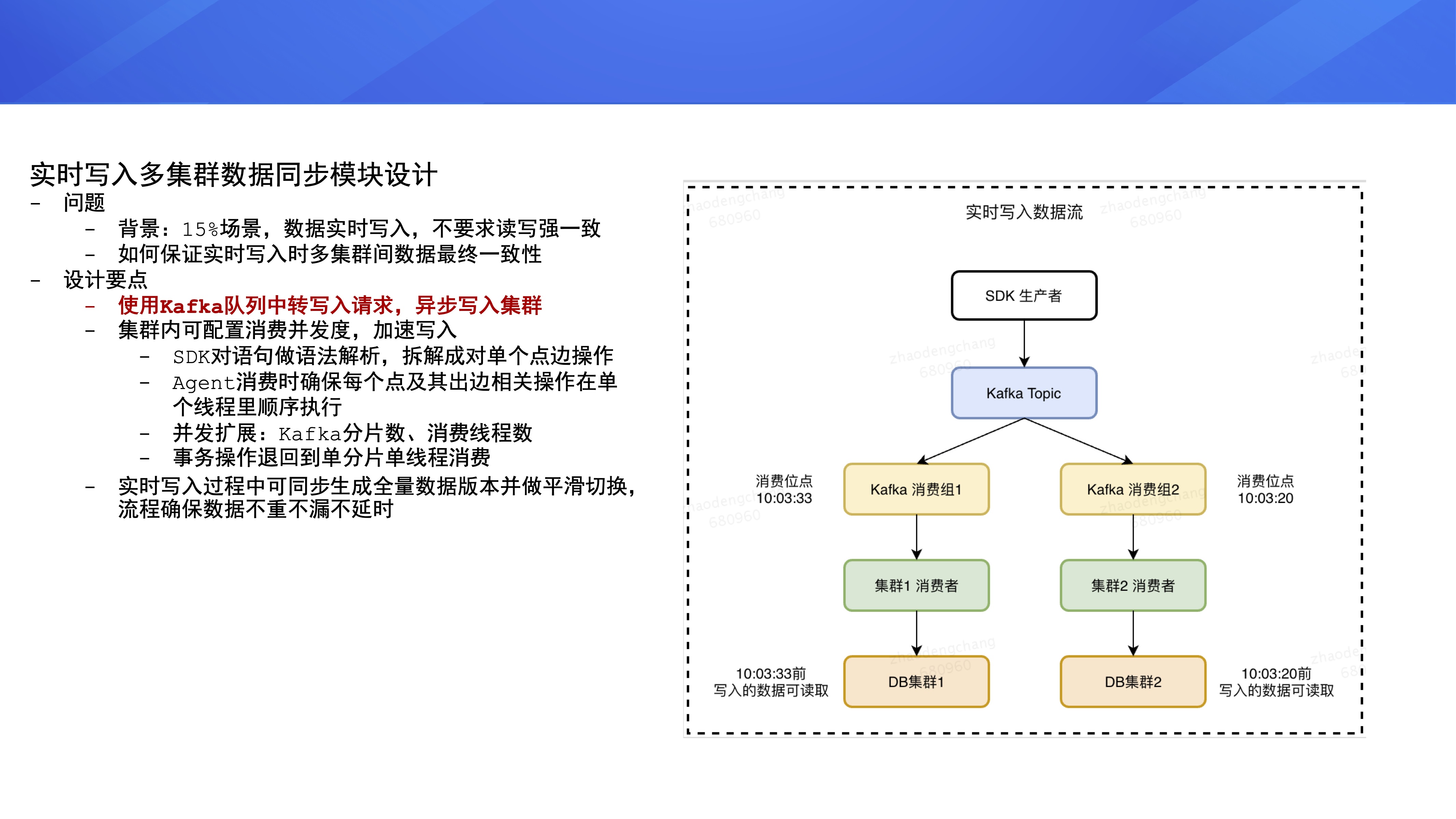
ЕкШ§ИіФЃПщЪЧЪЕЪБаДШыЖрМЏШКЪ§ОнЭЌВНЃЌЦНЬЈга 15% ЕФашЧѓГЁОАЪЧдкЪЕЪБЖСШЁЪ§ОнЪБЃЌЛЙвЊАбаТВњЩњЕФвЕЮёЪ§ОнЪЕЪБаДШыМЏШКЃЌВЂЧвЖдЪ§ОнЕФЖСаДЧПвЛжТадвЊЧѓВЛИпЃЌОЭЪЧЫЕвЕЮёЗНаДЕНЭМЪ§ОнПтРяЕФЪ§ОнЃЌВЛашвЊСЂТэФмЖСЕНЁЃ
еыЖдЩЯЪіГЁОАЃЌвЕЮёЗНдкЪЙгУЕЅгІгУЖрМЏШКетжжВПЪ№ЗНАИЪБЃЌЖрМЏШКРяЕФЪ§ОнашвЊБЃжЄзюжевЛжТадЁЃЦНЬЈзіСЫвдЯТЩшМЦЃЌЕквЛВПЗжЪЧв§Шы
Kafka зщМўЃЌвЕЮёЗНдкЗўЮёжаЭЈЙ§ SDK ЖдЭМЪ§ОнПтНјаааДВйзїЪБЃЌSDK ВЂВЛжБНгаДЭМЪ§ОнПтЃЌЖјЪЧАбаДВйзїаДЕН
Kafka ЖгСаРяЃЌжЎКѓгЩИУгІгУЯТЕФЖрИіМЏШКвьВНЯћЗбетИі Kafka ЖгСаЁЃ

ЕкЖўВПЗжЪЧМЏШКдкгІгУМЖБ№ПЩХфжУЯћЗбВЂЗЂЖШЃЌРДПижЦЪ§ОнаДШыМЏШКЕФЫйЖШЁЃОпЬхСїГЬЪЧ
SDK ЖдгУЛЇаДВйзїгяОфзігяЗЈНтЮіЃЌНЋЦфжаЕуБпЕФХњСПВйзїВ№НтГЩЖдЕЅИіЕуБпВйзїЃЌМДЖдаДгяОфзівЛДЮИФаД
Agent ЯћЗб Kafka ЪБШЗБЃУПИіЕуМАЦфГіБпЯрЙиВйзїдкЕЅИіЯпГЬРяЫГађжДааЃЌБЃжЄетЕуОЭФмБЃжЄИїИіМЏШКжДааЭъаДВйзїКѓзюжеЕФНсЙћЪЧвЛжТЕФЁЃ
ВЂЗЂРЉеЙЃКЭЈЙ§ИФБф Kafka ЗжЦЌЪ§ЁЂAgent жаЯћЗб Kafka ЯпГЬЪ§РДБфИќКЭЕїећ Kafka
жаВйзїЕФЯћЗбЫйЖШЁЃ
ШчЙћЮДРД Nebula Graph жЇГжЪТЮёЕФЛАЃЌЩЯУцЕФХфжУашвЊЕїећГЩЕЅЗжЦЌЕЅЯпГЬЯћЗбЃЌЦНЬЈашвЊЖдЩшМЦЗНАИдйзігХЛЏЕїећЁЃ

ЕкШ§ВПЗжЪЧдкЪЕЪБаДШыЪ§ОнЙ§ГЬжаЃЌЭМЪ§ОнПтЦНЬЈПЩвдЭЌВНЩњГЩвЛИіШЋСПЪ§ОнАцБОЃЌВЂзіЦНЛЌЧаЛЛЃЌЭЈЙ§гвЭМРяЕФСїГЬРДШЗБЃЪ§ОнЕФВЛжиВЛТЉВЛбгГйЁЃ
ЭМПЩЪгЛЏФЃПщЩшМЦ
ЕкЫФИіФЃПщЪЧЭМПЩЪгЛЏФЃПщЃЌЦНЬЈдк 2020 ФъЩЯАыФъЕїбаСЫ Nebula Graph ЙйЗНЕФЭМПЩЪгЛЏЩшМЦИњвЛаЉЕкШ§ЗНПЊдДЕФПЩЪгЛЏзщМўЃЌШЛКѓдкЭМЪ§ОнПтЦНЬЈЩЯдіМгСЫЭЈгУЕФЭМПЩЪгЛЏЙІФмЃЌжївЊЪЧгУгкНтОізгЭМЬНЫїЮЪЬтЃЛЕБгУЛЇдкЭМЪ§ОнПтЦНЬЈЭЈЙ§ПЩЪгЛЏзщМўВщПДЭМЪ§ОнЪБЃЌФмОЁСПЭЈЙ§ЧЁЕБЕФНЛЛЅЩшМЦРДБмУтвђЮЊНкЕуЙ§ЖрЖјв§ЗЂБЌЦСЁЃ
ФПЧАЃЌЦНЬЈЩЯЕФПЩЪгЛЏФЃПщгаЯТУцМИИіЙІФмЁЃ
ЕквЛИіЪЧЭЈЙ§ ID ЛђепЫїв§ВщевЖЅЕуЁЃ
ЕкЖўИіЪЧФмВщПДЖЅЕуКЭБпЕФПЈЦЌЃЈПЈЦЌжаеЙЪОЕуБпЪєадКЭЪєаджЕЃЉЃЌПЩвдЕЅбЁЁЂЖрбЁЁЂПђбЁвдМААДРраЭбЁдёЖЅЕуЁЃ

ЕкШ§ИіЪЧЭМЬНЫїЃЌЕБгУЛЇЕуЛїФГИіЖЅЕуЪБЃЌЯЕЭГЛсеЙЪОЫќЕФвЛЬјСкОгаХЯЂЃЌАќРЈЃКИУЖЅЕугаФФаЉГіБпЃПЭЈЙ§етИіБпЫќФм
Touch ЕНМИИіЕуЃПИУЖЅЕуЕФШыБпгжЪЧЪВУДЧщПіЃПЭЈЙ§етжжвЛЬјаХЯЂЕФеЙЪОЃЌгУЛЇдкЦНЬЈЩЯЬНЫїзгЭМЕФЪБКђЃЌПЩПьЫйСЫНтЕНжмБпЕФСкОгаХЯЂЃЌИќПьЕиНјаазгЭМЬНЫїЁЃдкЬНЫїЙ§ГЬжаЃЌЦНЬЈвВжЇГжЖдБпНјааЙ§ТЫЁЃ
ЕкЫФИіЪЧЭМБрМФмСІЃЌШУЦНЬЈгУЛЇдкВЛЪьЯЄ Nebula Graph гяЗЈЕФЧщПіЯТвВФмдіЩОИФЕуБпЪ§ОнЃЌЖдЯпЩЯЪ§ОнНјааСйЪБЕФИЩдЄЁЃ
вЕЮёЪЕМљ

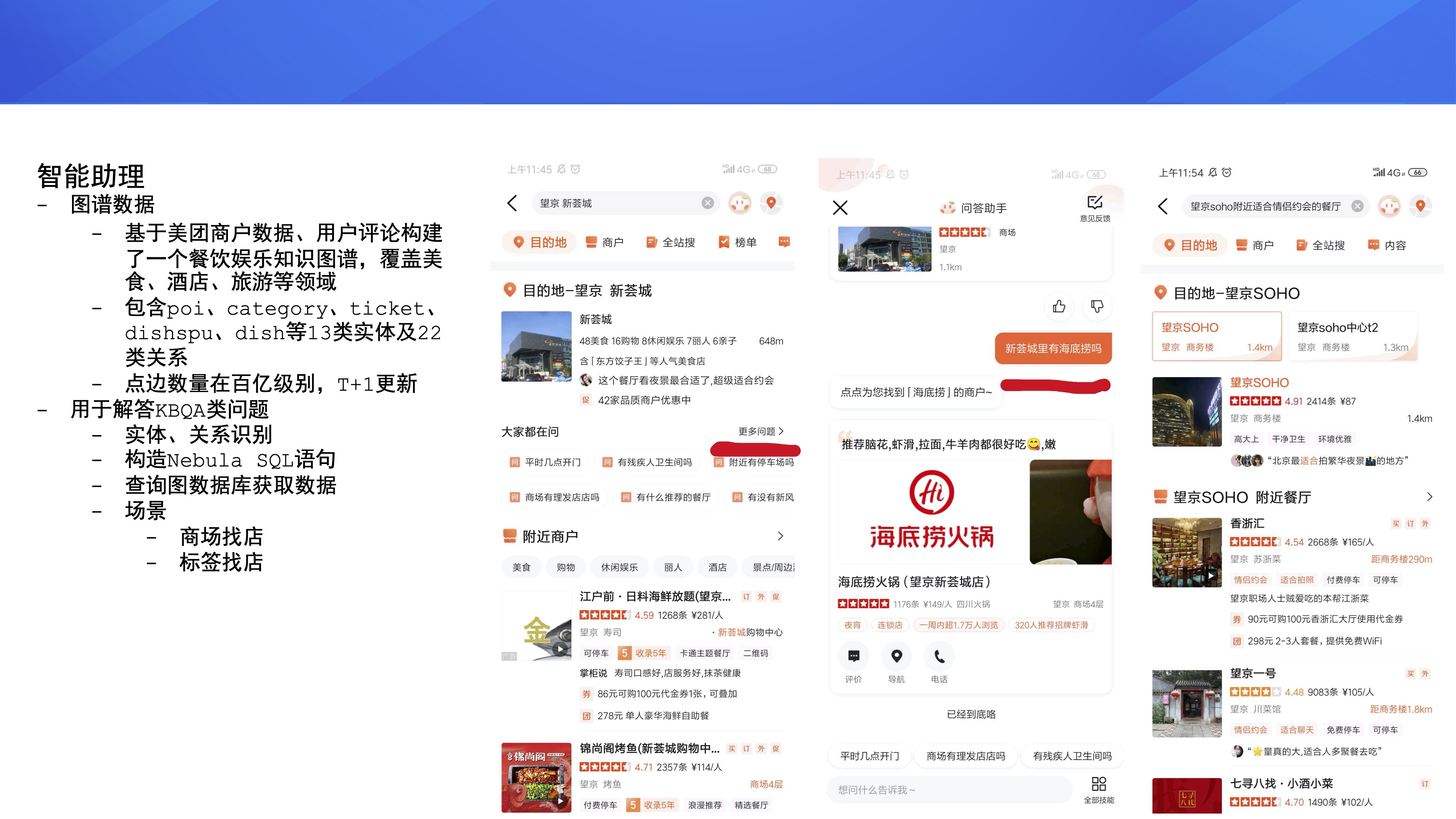
ЯТУцРДНщЩмЯТНгШыЮвУЧЦНЬЈЕФвЛаЉТфЕиЯюФПЁЃ
ЕквЛИіЯюФПЪЧжЧФмжњРэЃЌЫќЕФЪ§ОнЪЧЛљгкУРЭХЩЬЛЇЪ§ОнЁЂгУЛЇЦРТлЙЙНЈЕФВЭвћгщРжжЊЪЖЭМЦзЃЌИВИЧУРЪГЁЂОЦЕъЁЂТУгЮЕШСьгђЃЌАќКЌ
13 РрЪЕЬхКЭ 22 РрЙиЯЕЁЃФПЧАЕуБпЪ§СПДѓИХдкАйвкМЖБ№ЃЌЪ§ОнЪЧ T+1 ШЋСПИќаТЃЌжївЊгУгкНтОіЫбЫїЛђепжЧФмжњРэРя
KBQAЃЈШЋГЦЃКKnowledge Based Question AnswerЃЉРрЕФЮЪЬтЁЃКЫаФДІРэСїГЬЪЧЭЈЙ§
NLP ЫуЗЈЪЖБ№ЙиЯЕКЭЪЕЬхКѓЙЙдьГі Nebula Graph SQL гяОфЃЌдйЕНЭМЪ§ОнПтЛёШЁЪ§ОнЁЃ
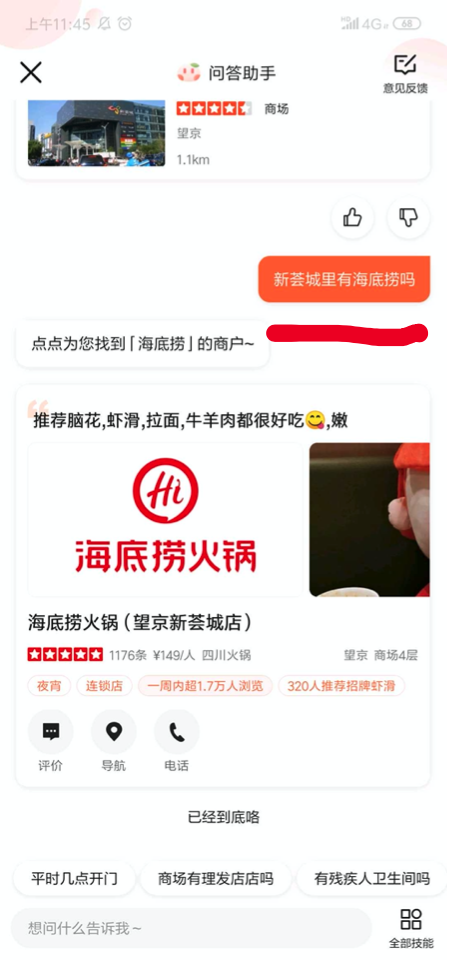
ЕфаЭЕФгІгУГЁОАгаЩЬГЁевЕъЃЌБШШчЃЌФГИігУЛЇЯыжЊЕРЭћОЉаТміГЧетИіЩЬГЁгаУЛгаКЃЕзРЬЃЌжЧФмжњРэОЭФмПьЫйВщГіНсЙћИцЫпгУЛЇЁЃ
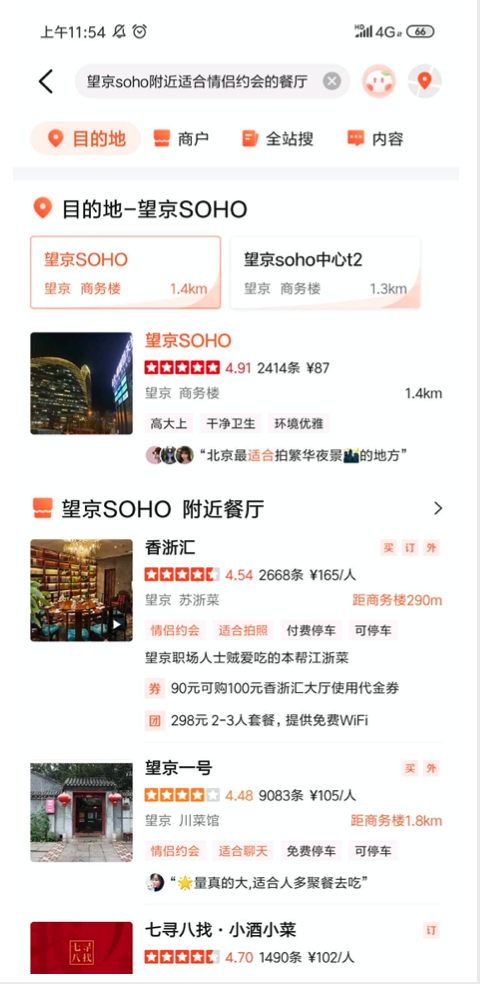
ЛЙгавЛИіЕфаЭГЁОАЪЧБъЧЉевЕъЃЌЯыжЊЕРЭћОЉ SOHO ИННќгаУЛгаЪЪКЯЧщТТдМЛсЕФВЭЬќЃЌЛђепФуПЩвдЖрМгМИИіГЁОАБъЧЉЃЌЯЕЭГЖМФмИјФуВщевГіРДЁЃ

ЕкЖўИіЪЧЫбЫїейЛиЃЌЪ§ОнжївЊЪЧЛљгквНУРЩЬМваХЯЂЙЙНЈЕФвНУРжЊЪЖЭМЦзЃЌАќКЌ 9 РрЪЕЬхКЭ 13 РрЙиЯЕЃЌЕуБпЪ§СПдкАйЭђМЖБ№ЃЌЭЌбљвВЪЧ
T+1 ШЋСПИќаТЃЌжївЊгУгкДѓЫбЕзВуЪЕЪБейЛиЃЌЗЕЛигы query ЯрЙиЕФЩЬЛЇЁЂВњЦЗЛђвНЩњаХЯЂЃЌНтОівНУРРрЫбЫїДЪЩйНсЙћЁЂЮоНсЙћЮЪЬтЁЃБШШчЃЌФГИігУЛЇЫбЁАЦЁОЦЖЧЁБетжжжЂзДЁЂЛђепЁАШѓАйбеЁБетРрЦЗХЦЃЌЯЕЭГЖМФмИјЫћейЛиЯрЙиЕФвНУРУХЕъЁЃ
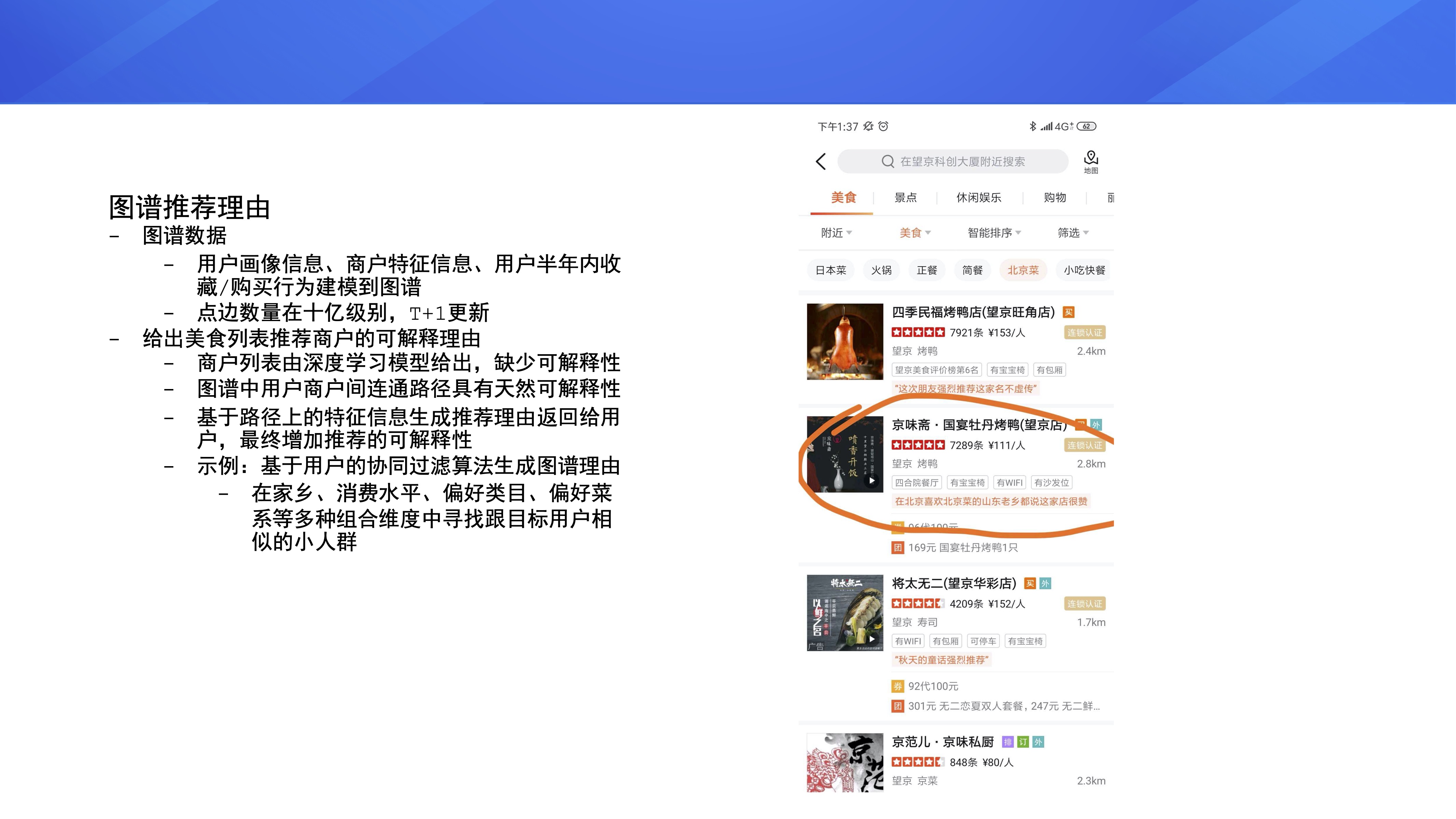
ЕкШ§ИіЪЧЭМЦзЭЦМіРэгЩЃЌЪ§ОнРДздгУЛЇЕФЛЯёаХЯЂЁЂЩЬЛЇЕФЬиеїаХЯЂЁЂгУЛЇАыФъФкЪеВи/ЙКТђааЮЊЃЌЯждкЕФЪ§ОнСПМЖЪЧ
10 вкМЖБ№ЃЌ T+1 ШЋСПИќаТЁЃетИіЯюФПЕФФПБъЪЧИјГіУРЪГСаБэЭЦМіЩЬЛЇЕФПЩНтЪЭРэгЩЁЃЮЊЪВУДЛсзіетИіЪТФиЃПЯждкУРЭХ
App КЭЕуЦР App ЩЯФЌШЯЕФЩЬЛЇЭЦМіСаБэЪЧгЩЩюЖШбЇЯАФЃаЭЩњГЩЕФЃЌЕЋФЃаЭВЂВЛЛсИјГіЩњГЩетИіСаБэЕФРэгЩЃЌШБЩйПЩНтЪЭадЁЃШЛЖјдкЭМЦзРягУЛЇИњЩЬЛЇжЎМфЬьШЛДцдкЖрЬѕСЌЭЈТЗОЖЃЌЮвУЧЯЃЭћФмбЁГівЛЬѕКЯЪЪТЗОЖРДЩњГЩЭЦМіРэгЩЃЌдк
App НчУцЩЯеЙЪОИјгУЛЇЭЦМіФГМвЕъЕФдвђЁЃБШШчЮвУЧПЩвдЛљгкгУЛЇЕФаЭЌЙ§ТЫЫуЗЈРДЩњГЩЭЦМіРэгЩЃЌдкМвЯчЁЂЯћЗбЫЎЦНЁЂЦЋКУРрФПЁЂЦЋКУВЫЯЕЕШЖрИізщКЯЮЌЖШжаевГіЖрЬѕТЗОЖЃЌШЛКѓИјетаЉТЗОЖДђЗжЃЌбЁГівЛЬѕЗжжЕНЯИпЕФТЗОЖЃЌжЎКѓАДееЬиЖЈ
pattern ВњГіЭЦМіРэгЩЁЃЭЈЙ§ЩЯЪіЗНЪНЃЌОЭПЩвдЛёЕУдкББОЉЯВЛЖББОЉВЫЕФЩНЖЋРЯЯчЖМЫЕетМвЕъКмдоЃЌЛђепЙужнРЯЯчЖМжавтЫћМвЕФе§зкББОЉеЈНДУцетРрРэгЩЁЃ
ЕкЫФИіЪЧДњТывРРЕЗжЮіЃЌЪЧАбЙЋЫОРяЕФДњТыПтжаДњТывРРЕЙиЯЕаДЕНЭМЪ§ОнПтЁЃЙЋЫОДњТыПтРягаКмЖрЗўЮёДњТыЃЌетаЉЗўЮёЖМЛсгаЖдЭтЬсЙЉЕФНгПкЃЌетаЉНгПкЕФЪЕЯжвРРЕгкИУЗўЮёжаФГаЉРрЕФГЩдБКЏЪ§ЃЌетаЉРрЕФГЩдБКЏЪ§гжвРРЕСЫБОРрЕФГЩдББфСПЁЂГЩдБКЏЪ§ЁЂЛђепЦфЫќРрЕФГЩдБКЏЪ§ЃЌФЧУДЫќУЧжЎМфЕФвРРЕЙиЯЕОЭаЮГЩСЫвЛеХЭМЃЌЮвУЧАбетИіЭМаДЕНЭМЪ§ОнПтРяЃЌзіЪВУДЪТФиЃП
ЕфаЭГЁОАЪЧ QA ЕФОЋзМВтЪдЃЌЕБ RD ЭъГЩашЧѓВЂЯђЙЋЫОЕФДњТыВжПтЬсНЛСЫЫћЕФ pr КѓЃЌетаЉИќИФЛсЪЕЪБЕиаДЕНЭМЪ§ОнПтжаЃЌЫљвд
RD ОЭФмВщЕНЫћЫљаДЕФДњТыгАЯьСЫФФаЉЭтВПНгПкЃЌВЂЧвФмеЙЪОГіЕїгУТЗОЖРДЁЃШчЙћ RD БОРДЪЧвЊИФНгПк A
ЕФааЮЊЃЌЫћИФСЫКмЖрЖЋЮїЃЌЕЋЪЧЫћПЩФмВЂВЛжЊЕРЫћИФЕФЖЋЮївВЛсгАЯьЕНЖдЭтНгПк BЁЂCЁЂDЃЌетЪБКђОЭПЩвдгУДњТывРРЕЗжЮіРДзіИі
CheckЁЃ
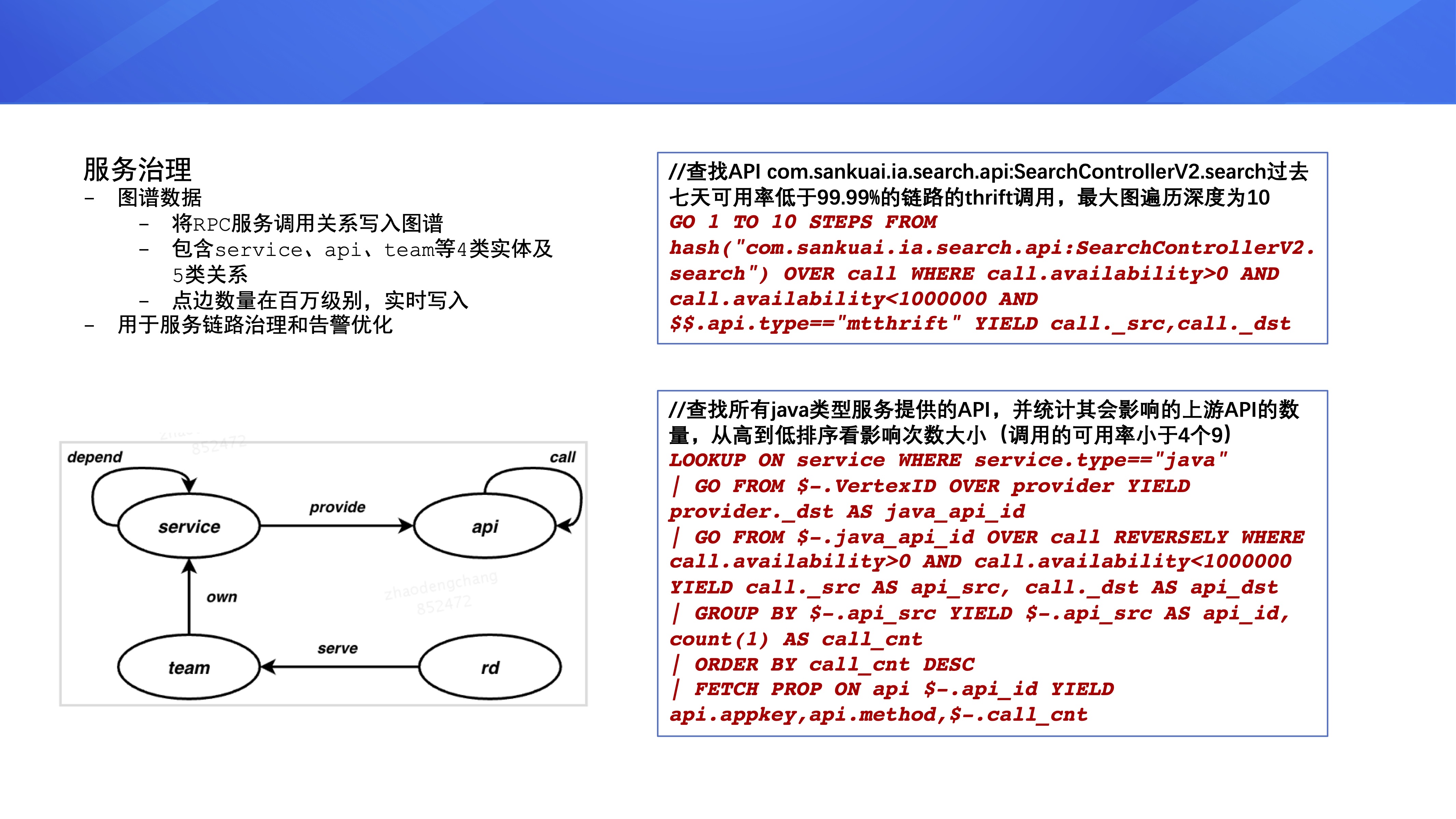
ЕкЮхИіЪЧЗўЮёжЮРэЃЌУРЭХФкВПгаМИЪЎЭђИіЮЂЗўЮёЃЌетаЉЮЂЗўЮёжЎМфДцдкЛЅЯрЕїгУЙиЯЕЃЌетаЉЕїгУЙиЯЕаЮГЩСЫвЛеХЭМЁЃЮвУЧАбетаЉЕїгУЙиЯЕЪЕЪБаДШыЭМЪ§ОнПтРяЃЌШЛКѓзівЛаЉЗўЮёСДТЗжЮРэКЭИцОЏгХЛЏЙЄзїЁЃ

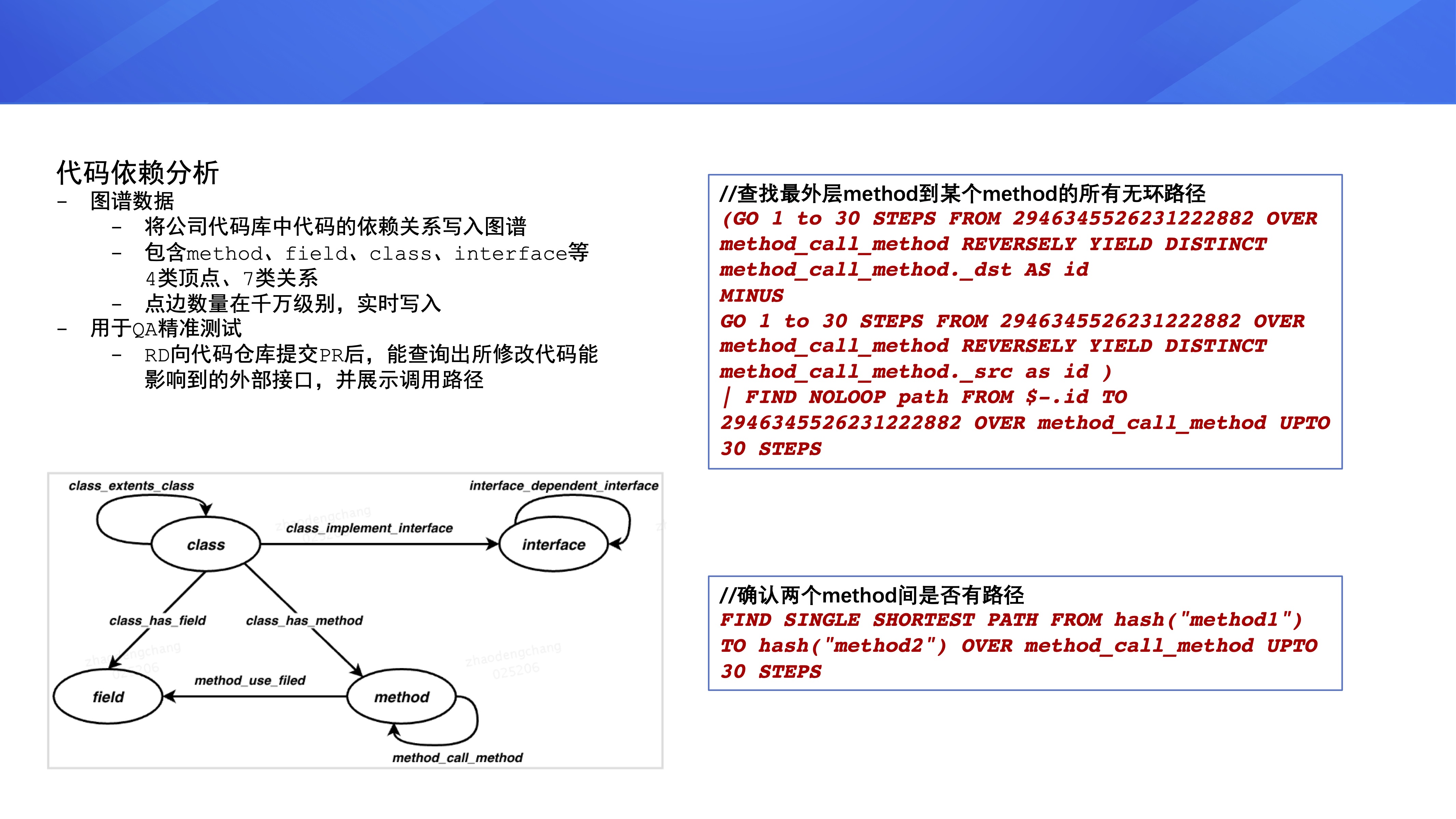
ЕкСљИіЯюФПЪЧЪ§ОнбЊдЕЃЌАбЪ§Вжжа ETL ШЮЮёЕФвРРЕЙиЯЕаДЕНСЫЭМЪ§ОнПтжаЃЌДѓИХЪЧЧЇЭђМЖБ№ЕФЪ§ОнСПМЖЃЌЪ§ОнЪЕЪБаДШыЃЌУПЬьСшГПзівЛДЮШЋСП
reloadЃЌжївЊЪЧгУРДВщевЪ§ОнШЮЮёЕФЩЯЯТгЮвРРЕЁЃБШШчЫЕЃЌЭЈЙ§етИі FIND NOLOOP PATH
FROM hash('task1') OVER depend WHERE depend.type ==
'ЧПвРРЕ' UPTO 50 STEPS гяОфевГі task1 етИіШЮЮёЕФЫљгаЧПвРРЕТЗОЖЁЃетРяЃЌЮвУЧеыЖд
Nebula Graph ЙйЗНЕФ FIND PATH ЙІФмзіСЫвЛаЉМгЧПЃЌЬэМгСЫЮоЛЗТЗОЖЕФМьЫїИњ WHERE
гяОфЙ§ТЫЁЃ
УРЭХКЭ Nebula
УРЭХЭМЪ§ОнПтЦНЬЈНЈЩшМАвЕЮёЪЕМљ
зюКѓЃЌРДНщЩмЯТЭХЖгЖдЩчЧјЕФЙБЯзЁЃ

ЮЊСЫИќКУЕиТњзуЭМЪ§ОнПтЦНЬЈЩЯгУЛЇЕФашЧѓЃЌЮвУЧЖд Nebula Graph 1.0ЕФФкКЫзіСЫВПЗжЙІФмЕФРЉГфКЭВПЗжадФмЕФгХЛЏЃЌВЂАбЯрЖдРДЫЕБШНЯЭЈгУЕФЙІФмИј
Nebula Graph ЩчЧјЬсСЫ PRЃЌвВЯђЩчЧјЙЋжкКХЭЖИхСЫвЛЦЊ жїСїПЊдДЗжВМЪНЭМЪ§ОнПтBenchmark
?? ЁЃ
ЕБШЛЃЌЮвУЧЭЈЙ§ Nebula Graph НтОіСЫЙЋЫОФкЕФКмЖрвЕЮёЮЪЬтЃЌФПЧАЖд Nebula Graph
ЩчЧјзіЕФЙБЯзЛЙБШНЯЩйЃЌКѓајЛсМгЧПдкЩчЧјММЪѕЙВЯэЗНУцЕФЙЄзїЃЌЯЃЭћФмЙЛХрбјГідНРДдНЖрЕФ Nebula CommitterЁЃ
УРЭХЭМЪ§ОнПтЦНЬЈЕФЮДРДЙцЛЎ


ЮДРДЙцЛЎжївЊгаСНИіЗНУцЃЌЕквЛЗНУцЪЧЕШ Nebula Graph 2.0 ЕФФкКЫЯрЖдЮШЖЈКѓЃЌдкЮвУЧЭМЪ§ОнПтЦНЬЈЩЯЪЪХф
Nebula Graph 2.0 ФкКЫЁЃЕкЖўЗНУцЪЧШЅЭкОђИќЖрЕФЭМЪ§ОнМлжЕЁЃЯждкУРЭХЭМЪ§ОнПтЦНЬЈжЇГжСЫЭМЪ§ОнДцДЂМАЖрЬјВщбЏетжжЛљБОФмСІЃЌКѓајЮвУЧДђЫуЛљгк
Nebula Graph ШЅЬНЫївЛЯТЭМбЇЯАЁЂЭММЦЫуЕФФмСІЃЌИјЦНЬЈгУЛЇЬсЙЉИќЖрЭкОђЭМЪ§ОнМлжЕЕФЙІФмЁЃ | 








