| БрМЭЦМі: |
БОЮФЗжЯэвЛЯТ
Nebula Graph дкЮЂжквјаа WeDataSphere ЕФЪЕМљЧщПіЃЌNebula
Graph дкДѓЪ§ОнЦНЬЈ WeDataSphere Ъ§ОнжЮРэЯЕЭГжаЕФгІгУ,ЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздЮЂаХЙЋжкКХЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|

ЯШРДЫЕЯТЭМЪ§ОнПтгІгУБГОАЁЃ

WeDataSphere ЭМЪ§ОнПтМмЙЙЪЧЛљгк JanusGraph ДюНЈЃЌе§ШчлЁЫЇдкбнНВЁЖNebulaGraph
- WeDataSphere ПЊдДНщЩмЁЗжаЬсМАЕФФЧбљЃЌжївЊгУгкНтОіЮЂжквјааЪ§ОнжЮРэжаЕФЪ§ОнбЊдЕЮЪЬтЁЃдкЪЙгУ
JanusGraph Й§ГЬжаЃЌЮЂжквјааЗЂЯж JanusGraph БОЩэвРРЕзщМўНЯЖрЃЌЪ§ОнДцДЂдк HBase
жаЃЌЫїв§ДцДЂдк Eleasticsearch жаЃЌЖјвђЮЊЪмЗжВМЪНИпПЩгУКЭСНЕиШ§жааФМмЙЙЙцЗЖвЊЧѓЃЌвЊДюНЈвЛЬзЭъећЕФЭМЪ§ОнПтЯЕЭГЩцМАММЪѕЕуНЯЖрЃЌБШШчИпПЩгУЮЪЬтЃЌдйМгЩЯШ§ИізщМўДЎСЊЃЌашвЊНтОіКмЖрММЪѕЮЪЬтЁЃЖјЧвЃЌБОЩэ
JanusGraph етПщЪ§ОнаДШыадФмвВДцдкЮЪЬтЃЌЕБШЛБОЩэЮвУЧЖд JanusGraph ЕФгХЛЏвВНЯЩйЃЌжївЊМЏжадкВЮЪ§ЕїећКЭАВШЋадФмЬсЩ§ЁЃ
ЕБЪБгУетЬзЯЕЭГДІРэЕФЪ§ОнСПДѓИХЪЧУПЬь 60 ЭђИіЕуЃЌАйЭђМЖЕФБпЃЌВюВЛЖрвЛЬьвЊЛЈ 5 ИіаЁЪБзѓгвВХФмЭъГЩаДШыЁЃетОЭЕМжТвЕЮёЗНашвЊЪЙгУбЊдЕЪ§ОнЪБЃЌДѓЪ§ОнЦНЬЈВЛФмМАЪБЬсЙЉЁЃ

жСгкЮЂжквјааДѓЪ§ОнЦНЬЈЮЊЪВУДбЁгУ Nebula GraphЃЌЮЂжквјаадчЦкЕїбаЙ§вЛаЉЩЬгУЁЂПЊдДЕФЭМЪ§ОнПтНтОіЗНАИЃЌВтЪдВПЗжетРяВЛзізИЪіЁЃ
етРяЫЕЯТИеВХ 60 ЭђИіЕуЁЂАйЭђМЖБ№БпетИіГЁОАЕФЧщПіЃЌдкЕЅНкЕуЕЭХфЛњЦїВПЪ№ЧщПіЯТЃЌЮЂжквјааЕМШыЪ§ОнЛљБОЩЯдк
20 ЗжжгФкЭъГЩЁЃNebula Graph ЕФаДШыадФмЗЧГЃКУЃЌЮЂжквјааДѓЪ§ОнЦНЬЈетПщвЕЮёЖдВщбЏЕФадФмвЊЧѓВЂВЛИпЃЌNebula
Graph вВФмТњзуДѓЪ§ОнЦНЬЈетПщЕФВщбЏвЊЧѓЁЃ
ЮЂжквјааЕФЭМЪ§ОнПтбЁдёЛЙгавЛИіжиСППМКЫЕуЃЌИпПЩгУКЭШнджЕФМмЙЙжЇГжЁЃетИіПМКЫЯюЃЌNebula Graph
БОЩэЕФМмЙЙДцдквЛЖЈгХЪЦЃЌЗћКЯЮЂжквјааааФкгВадЕФМмЙЙвЊЧѓКЭЙцЗЖЁЃМгЩЯДѓЪ§ОнЦНЬЈБОЩэжМдкЙЙНЈвЛИіЭъећЕФЪ§ОнСїЩњЬЌЃЌNebula
Graph ЬсЙЉСЫвЛаЉДѓЪ§ОнЯрЙиПЊдДзщМўЃЌБШШчЃКConnectorЃЌExchangeЃЌетаЉЙЄОпФмКмКУЕиЭЌДѓЪ§ОнЦНЬЈНјааНсКЯЁЃ

OKЃЌЯТУцРДНВНтЯТ WeDataSphere МмЙЙЃЌжївЊМЏжадкМмЙЙЩшМЦжаЫљПМТЧЕФЕуЁЃ
ЩЯЭМКЭДѓЖрЪ§гІгУЕФВуМЖЛЎЗжРрЫЦЃЌДгЩЯЭљЯТПДЃЌгІгУВуВњЩњЪ§ОнЃЌЭЈЙ§Ъ§ОнНЛЛЛВуЕФИїжжЙЄОпЃЌЭЌЕзВуЕФЭМЪ§ОнПтЯЕЭГНЛЛЛЪ§ОнЁЃгІгУГЁОАЗНУцетРяВЛзїЯъЯИНщЩмЃЌдкБОЮФКѓУцЛсЯъЯИЕиНВНтН№ШкаавЕЕФгІгУЧщПіЁЃ
ДгаавЕРДПДЃЌжаМфЕФЪ§ОнВувЛАуЗжЮЊШ§ИіВПЗжЃКХњСПЪ§ОнЁЂСїЪНЪ§ОнКЭдкЯпЪ§ОнЁЃЖјЪ§ОнНЛЛЛЗНУцЃЌЮЂжквјааДѓЪ§ОнЦНЬЈЛљгк
Nebula ЬсЙЉЕФПЊдДЗНАИзіСЫНгШыгХЛЏЃЌЕзВудђЪЙгУ Nebula Graph ЭМЪ§ОнПтЯЕЭГЁЃДЫЭтЃЌЮЂжквјааДѓЪ§ОнЦНЬЈЛЙгавЛЬздЫЮЌздЖЏЛЏЯЕЭГНа
ManagisЃЌЛљгк Managis ЙЙНЈСЫздЖЏЛЏВПЪ№ЙЄОпЃЌNebula ХфжУвВЪЧдкРр CMDB ЯЕЭГжаЙмРэЁЃ
ЗўЮёМрПиФЃПщЃЌЮЂжквјааДѓЪ§ОнЦНЬЈФкВПЪЙгУ Zabbix МрПиЃЌЭЈЙ§аДНХБОЕїгУ Metric HTTP
НгПкЃЌНЋМрПижИБъДЋЪфЕН Managis Monitor (Zabbix) ЯЕЭГжаЁЃ
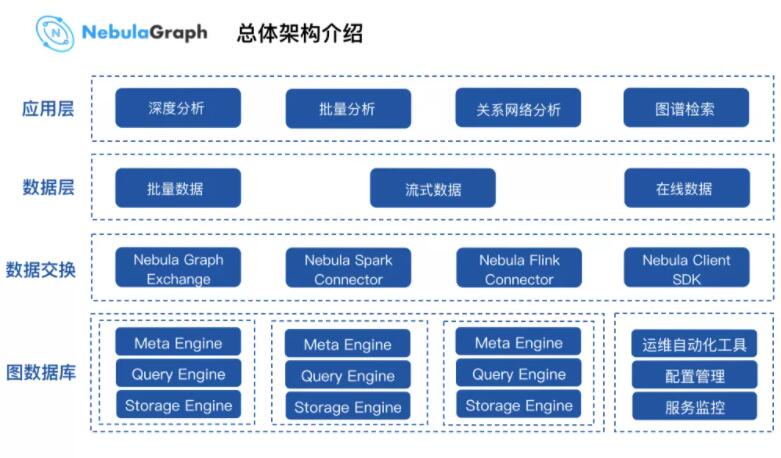
змЬхЕФМмЙЙШчЩЯЭМЫљЪОЃЌДгЩЯжСЯТЕФ 4 ВуМмЙЙЬхЯЕЁЃ
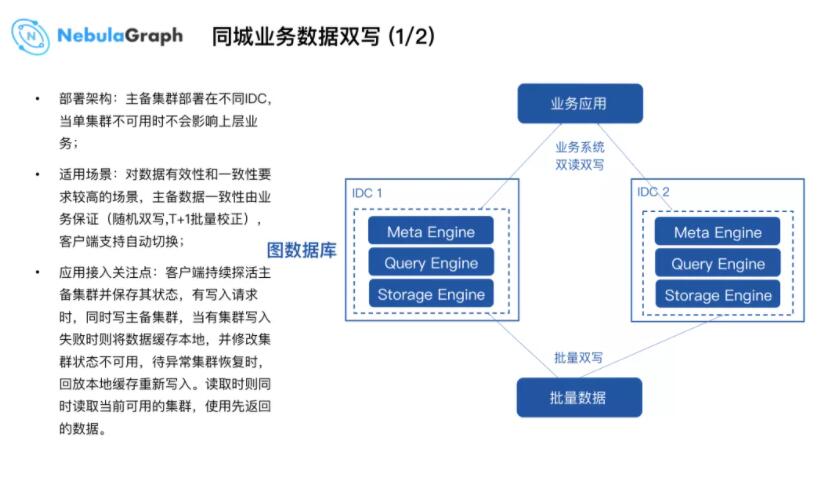
ЛиЕНгУЛЇВуУцЃЌДюНЈетЬзЯЕЭГдквјааМмЙЙЙцЗЖЯТШчКЮЬсЙЉИјгУЛЇЪЙгУЃЌБЃжЄЗўЮёЮШЖЈадвдМАПЩгУТЪЃЌЪЧДѓЪ§ОнЦНЬЈЕФЪзвЊПМТЧЬѕМўЁЃЭЈЙ§НшМј
WeDataSphere жЎЧАМЦЫуДцДЂзщМўЕФГЩЙІОбщЃЌР§Шч HBaseЁЂES ЕШзщМўЃЌШчЙћвЕЮёЗНЕФЯЕЭГЖдЮШЖЈадКЭвЛжТадгаЫљвЊЧѓЃЌвЕЮёНгШыЖЫашвЊЪЕЯжЫЋаДЙІФмЃЛеыЖдЪ§ОнвЛжТадЗНУцЃЌДѓЪ§ОнЦНЬЈзіСЫ
T+1 ЕФЪ§ОнаДШыаЃе§ЁЃЕБШЛетжжЫЋаДЗНЪННгШыЃЌвЕЮёЖЫЛсДцдкИФдьКЭПЊЗЂГЩБОЁЃ
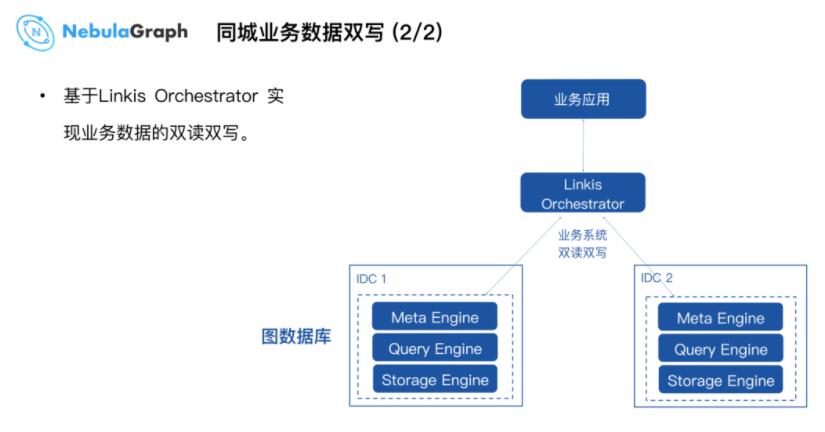
КѓЦкЃЌЛљгкДѓЪ§ОнЦНЬЈПЊдДЕФНтОіЗНАИ Linkis ЬсЙЉЕФ Orchestrator ФЃПщЪЕЯжБрХХЁЂЛиЗХЁЂИпПЩгУЁЃвЕЮёЖЫЮоашСЫНтОпЬхЕФММЪѕЪЕЯжЯИНкЃЌЭЈЙ§ЕїгУДѓЪ§ОнЦНЬЈЕФ
SDK НгШы Linkis ЕФ Orchestrator НтОіЗНАИЪЕЯжИпПЩгУКЭЪ§ОнЕФЫЋЖСЫЋаДЙІФмЁЃФПЧАетПщЙІФмЩадкПЊЗЂжаЃЌЛсдкНќЦкПЊдДЁЃ
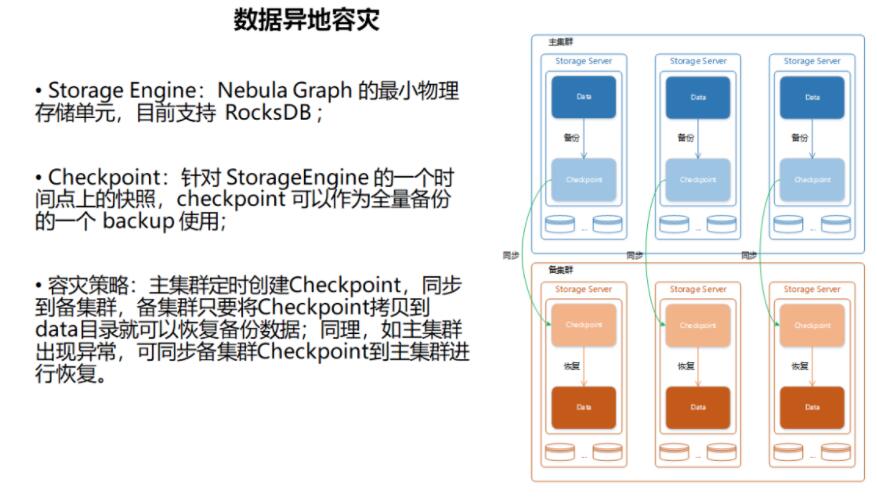
ЩЯЭМЮЊвьЕиШнджЙ§ГЬЃЌжївЊвРРЕгк Nebula Graph БОЩэЬсЙЉЕФШнджЬиадЃЌБШШчЃКCheckpointЁЃФПЧАЃЌДѓЪ§ОнЦНЬЈЕФОпЬхВйзїЪЧУПЬьНЋ
Checkpoint зіЪ§ОнБИЗнЭЌВНЕНЩЯКЃЕФШнджМЏШКЁЃвЛЕЉжїМЏШКГіЮЪЬтЃЌМДПЬЧаЛЛЯЕЭГЕНЩЯКЃджБИМЏШКЃЌЕШжїМЏШКЛжИДКѓЃЌНЋЪ§ОнЭЌВНЕНжїМЏШКЁЃ

ЯТУцРДНщЩмЯТ Nebula Graph дкДѓЪ§ОнЦНЬЈ WeDataSphere Ъ§ОнжЮРэЯЕЭГжаЕФгІгУЁЃ
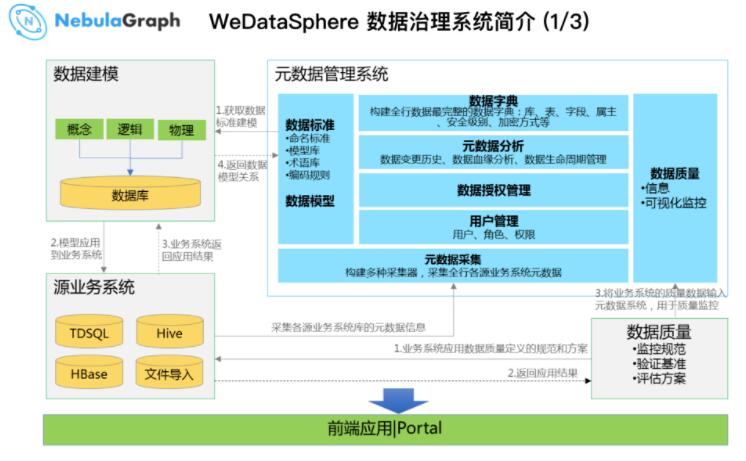
ЯШМђЕЅЕиНщЩмвЛЯТ WeDataSphere Ъ§ОнжЮРэЯЕЭГЃЌЫќАќРЈ
1.Ъ§ОнНЈФЃЙЄОп
2.дЊЪ§ОнЙмРэЯЕЭГ
3.Ъ§ОнЭбУєЯЕЭГ
4.Ъ§ОнжЪСПЙмРэЯЕЭГ
дЊЪ§ОнЙмРэЯЕЭГЛсЖдНгЪ§ОнНЈФЃЙЄОпЁЂЪ§ОнжЪСПЙмПиЯЕЭГЁЂвдМАЪ§ОнЭбУєЯЕЭГЃЌзюжеЬсЙЉИјгУЛЇвЛЬзЧАЖЫЕФВйзїНчУцЁЃ

ЕБжаБШНЯЙиМќЕФзщМўНаЪ§ОнЕиЭМЃЌжївЊЮЊећИівјааЕФЪ§ОнзЪВњФПТМЃЌЫќВЩМЏИїИіЪ§ОндДЕФЪ§ОнЃЌЭЈЙ§ WeDataSphere
ЖдЪ§ОнНјааМгЙЄДцДЂЃЌзюКѓЗЕЛивЛЗнШЋааЭъећЕФЪ§ОнзЪВњ / Ъ§ОнзжЕфЁЃдкетИіЙ§ГЬжаЃЌДѓЪ§ОнЦНЬЈЙЙНЈСЫЪ§ОнжЮРэЕФЙцЗЖКЭвЊЧѓЁЃ
етЬзЪ§ОнЯЕЭГНЕЕЭСЫгУЛЇЪЙгУУХМїЃЌжБЙлЕиИцЫпгУЛЇЪ§ОндкФФЃЌШчЙћФГИігУЛЇвЊЩѓХњЪ§ОнЃЌЬсНЛвЛИіЪ§ОнЧыЧѓЕЅБуПЩЬсШЁЫћЯывЊЕФЪ§ОнЃЌЩѕжСдкЪ§ОнЬсШЁжЎЧАЃЌЯЕЭГИцжЊгУЛЇЪ§ОндДЪЧЫЃЌПЩвдевЕНЫвЊЪ§ОнЁЃетвВЬхЯжСЫетЬзЪ§ОнжЮРэЯЕЭГжаЪ§ОнбЊдЕЕФФмСІЃКЪ§ОндДЪЧФФРяЃЌЯТгЮгжЪЧФФРяЁЃ
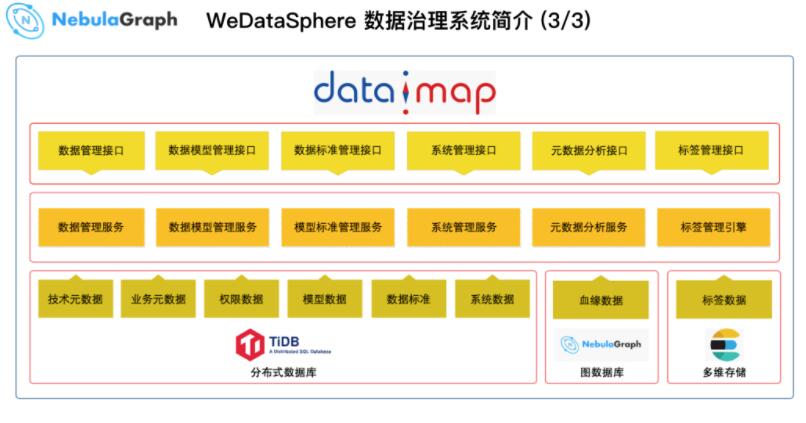
ЩЯЭМЮЊЪ§ОнжЮРэЯЕЭГЕФЙІФмМмЙЙЃЌзюЯТВуЮЊЯЕЭГашвЊВЩМЏЕФЪ§ОнЃЌвдМАЫќЖдгІЕФЪ§ОнДцДЂЕиЗНЁЃдкетИіМмЙЙжаЃЌДѓЪ§ОнЦНЬЈВЩгУ
3 ИіЕзВуДцДЂв§ЧцЃКжївЊДцДЂдЊЪ§ОнЕФ TiDBЁЂДцДЂЭМЪ§ОнЕФ Nebula GraphЁЂДцДЂЫїв§Ъ§ОнЕФ
ESЁЃдкЕзВуДцДЂЕФЩЯУцЃЌЪ§ОнЕиЭМЬсЙЉСЫЖрИіЮЂЗўЮёЬсЙЉИјЭтВПЪЙгУЕФЧыЧѓНгПкЁЃ

ЯТУцНВНтЯТ WeDataSphere Ъ§ОнжЮРэЯЕЭГжабЊдЕЪ§ОнЕФДІРэЙ§ГЬЁЃЮвУЧЭЈЙ§ИїжжзщМў Hook
Дг HiveЁЂSparkЁЂSqoop ЕШШЮЮёНХБОжаНтЮіЪфШыЪ§ОнКЭЪфГіЪ§ОнЙЙНЈбЊдЕЪ§ОнЁЃР§ШчЃКЕБжаЕФ
Hive Hook жївЊДІРэДѓЪ§ОнЦНЬЈФкВПЕФБэгыБэжЎМфЕФЙиЯЕЃЌЮвУЧЭЈЙ§ Hive БОЩэЬсЙЉЕФ Lineage
SDK АќзАСЫЪ§ОнНгПкЃЌЙЙНЈвЛИі Hook ШЅНтЮі SQL гяОфЕФЪфШыЪ§ОнКЭЪфГіЪ§ОнЃЌДгЖјНЈСЂбЊдЕЙиЯЕМЧТМдк
Log жаЁЃSpark РрЫЦЃЌВЛЙ§ЮЂжквјааЪЧздба Spark дк Drive ВуЕФ HookЁЃSqoop
етПщЪЕЯжЪЧЛљгк Sqoop ЕФ Patch НтЮіЪ§Ондк importer КЭ exporter job
Й§ГЬжаЬсЙЉЕФ Public DataЃЌзюжеЙЙНЈЙиЯЕаЭЪ§ОнПтЃЈБШШчЃКMySQLЁЂOracleЁЂDB2ЃЉКЭДѓЪ§ОнЦНЬЈ
Hive Ъ§ОнжЎМфЕФСїЯђЙиЯЕЁЃбЊдЕЪ§ОнЩњГЩжЎКѓаДШыжДааНкЕуЃЌМД Driver ЫљдкНкЕуЃЌДгЖјаЮГЩ Lineage
LogЁЃ
дйгУЮЂжквјааФкВПЕФздЖЏЛЏдЫЮЌЙЄОп AOMP УПШеДгИїИіНкЕуЕМШыЪ§ОнДцДЂЕН Hive ODS DBЁЃдкетИіЙ§ГЬжаЃЌДѓЪ§ОнЦНЬЈЖд
Hive Нјаа ETL МгЙЄЭЌЯжгаЪ§ОнНјааЙиСЊЗжЮіЕУЕНЕМШыЭМЪ§ОнПтЕФ DM БэЁЃзюКѓЪЙгУ Nebula
Graph ЬсЙЉЕФ Spark Writer Дг Hive жаНЋЕуКЭБпЕФЪ§ОнаДШыЭМЪ§ОнПтЖдгІ Schema
жаЁЃ
вдЩЯБуЪЧЪ§ОнМгЙЄЙ§ГЬЁЃ
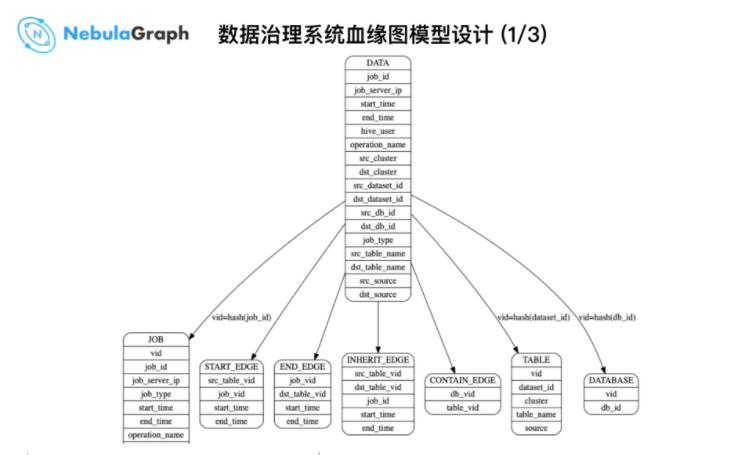
ЩЯЭМЮЊДѓЪ§ОнЦНЬЈЕФећЬхЪ§ОнФЃаЭЃЌжаМфЕФ DATA ДѓБэЮЊ Hive МгЙЄКѓЕФгІгУБэЃЌНЋЩЯУцЕФЕуЁЂБпаХЯЂаДШы
Nebula Graph Schema жаЃЌАќРЈДІРэФГИі SQL гяОфЕФ job_id ЃЌЪ§ОндД src_db_id
ЃЌЪ§ОнЯТгЮ dst_db_id ЕШЕШЪ§ОнаХЯЂЁЃ
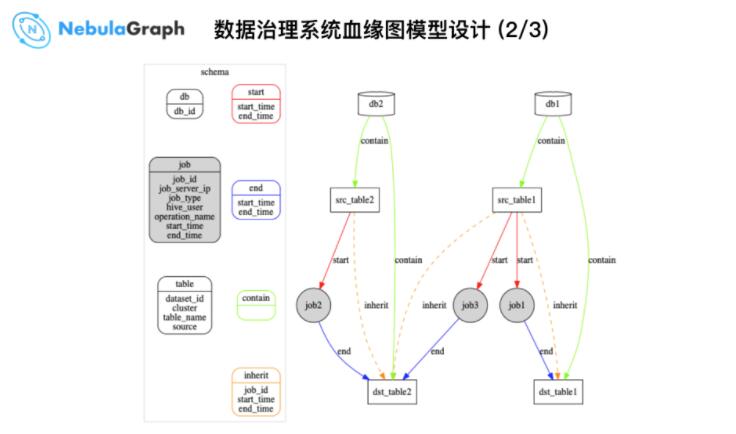
ЯрЖдЖјбдЩЯЭМБШЁИЪ§ОнжЮРэЯЕЭГбЊдЕЭМФЃаЭЩшМЦ 1/3ЁЙЭМИќжБЙлЃЌSchema зѓВрЮЊЕуЃЌгвВрЮЊБпЃЌвЛИі
job ЖдгІФГИі SQL гяОфЛђ Sqoop ШЮЮёЁЃОйИіР§згЃЌвЛИі SQL гяОфЛсДцдкЖрИіЪфШыБэЃЌзюжеаДШыЕНвЛИіЪфГіБэЃЌдкЭМНсЙЙжаГЪЯжБуЪЧ
job ШыБпКЭ job ГіБпЃЌЖдгІ source table КЭ destination tableЁЃБэКЭ
DB БОЩэДцдк Contain ЙиЯЕЃЌЖјЮЂжквјааЛљгкздМКЕФвЕЮёдіМгСЫБэКЭБэЕФжБНг Join ЙиЯЕЃЌПЩВщбЏБэКЭБэжЎМфЙиЯЕЃЌБШШчЃКвЛЖШЙиЯЕЁЃ
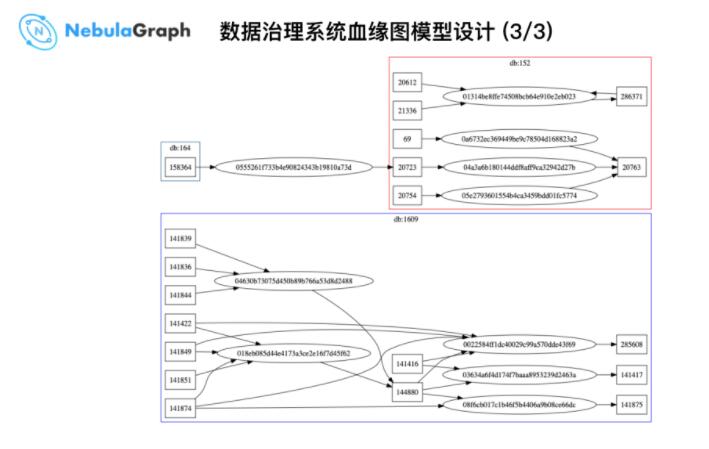
ЩЯЭМЪЧвЛИіЪ§ОнЙ§ГЬЃЌЩЯУцгаИі db_id ЃЌБШШчЃК158364ЃЌЭЈЙ§вЛИі job_id ЃЌР§ШчЃК0555261f733b4e90824343b19810a73d
ЙЙНЈЦ№СЫвЛИіЭМНсЙЙЁЃ
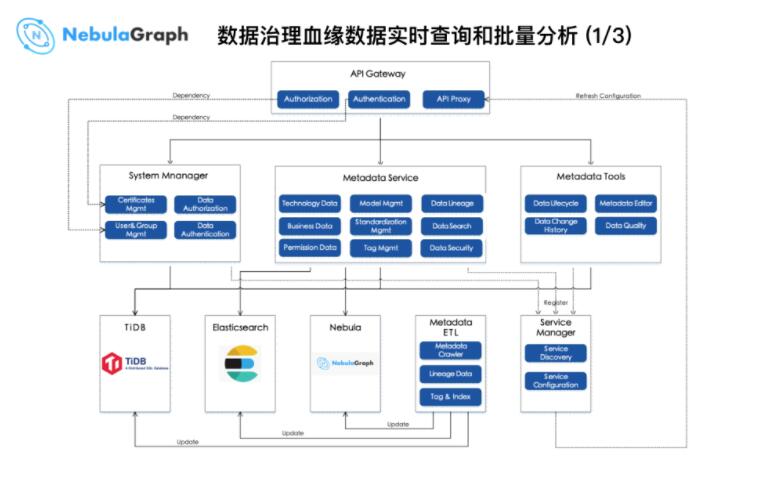
етЪЧЪ§ОнжЮРэЕФЪЕЪБВщбЏКЭХњСПЗжЮіМмЙЙЃЌжївЊЭЈЙ§ ETL МгЙЄбЊдЕЪ§ОндйаДШыЕНЪ§ОнДцДЂЯЕЭГжаЁЃЖјЩЯЭМжаЕФ
Metadata Service ЛсИљОнЪЕЪБЗжЮіашЧѓЭЈЙ§ SDK ЕїгУЭМЪ§ОнПтЃЌНЋВщбЏЕФЗЕЛиНсЙћДЋИјЧАЖЫзіеЙЪОЁЃ

дкгІгУГЁОАетПщЃЌжївЊгаСНИіГЁОАЃЌвЛЪЧЪЕЪБВщбЏЃЌвдФГИіБэЮЊЦ№ЪМНкЕуЃЌБщРњЩЯгЮКЭЯТгЮБэЃЌБщРњЭъГЩКѓдк
UI жаеЙЪОЁЃОпЬхЕФММЪѕЪЕЯжЪЧЕїгУ Nebula Java Client СЌНг Nebula Graph
ВщбЏЕУЕНбЊдЕЙиЯЕЁЃЖўЪЧХњСПВщбЏЃЌЕБШЛХњСПВщбЏЫљашЕФбЊдЕЪ§ОнвбЙЙНЈКУВЂДцДЂдк Nebula Graph
жаЁЃеыЖдХњСПВщбЏЃЌетРяОйИіР§згЃКгавЛИіВПУХЕФБэЃЌдкФГИіЪБПЬДІгкГіЯжвьГЃЃЌЛсгАЯьвЛХњБэЃЌвЊевЕНетИіВПУХЕФБэЃЌЪзЯШЮвУЧЕУевЕНЫќЕНЕзгАЯьСЫФФаЉЯТгЮБэЃЌАбетИіЭъећЕФСДТЗзЗзйГіРДКѓАЄИіШЗШЯетаЉБэЪЧЗёаоИДЁЃФЧУДетЪБКђОЭашвЊзіХњСПВщбЏЁЃОпЬхММЪѕЪЕЯжЪЧЭЈЙ§
Nebula Spark Connector СЌНг Nebula Graph ХњСПНЋЕуКЭБпЪ§ОнЕМШыЕН
Spark ЗтзАЮЊ DataFrameЃЌдйЭЈЙ§ GraphX ЕШЭМЫуЗЈХњСПЗжЮіЕУЕНЭъећЕФбЊдЕСДТЗЁЃ
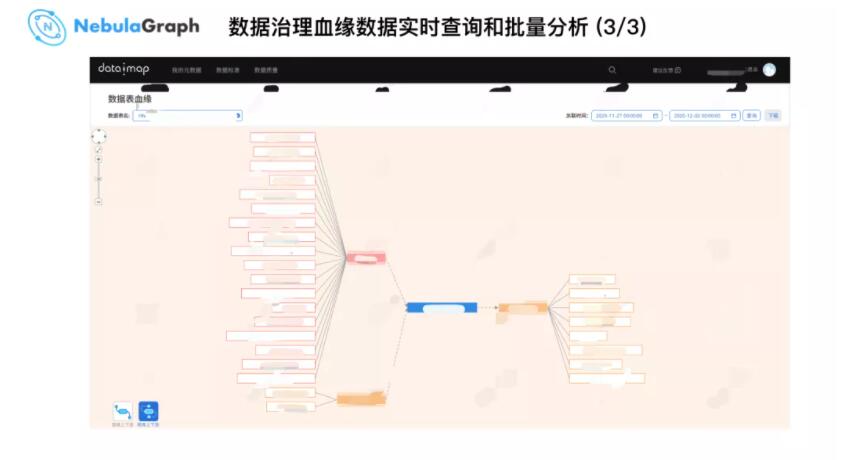
ЩЯЭМЮЊ WeDataSphere ЪЕЪБВщбЏНчУцЃЌвђЮЊЩцМАЕНУєИааХЯЂДђСЫИіТэШќПЫЃЌвдЩЯЭМЕФРЖЩЋБэЮЊжааФЪ§ОнЃЌВщбЏЯТгЮЕФвЛЖШЙиЯЕБэКЭЩЯгЮЕФвЛЖШЙиЯЕБэЃЌДѓЪ§ОнЦНЬЈЙЙНЈЭМЪ§ОнПтЪ§ОнФЃаЭЪБМгШыСЫЪБМфЪєадЃЌПЩвдВщбЏЬиЖЈЪБМфЃЌБШШчЃКФГеХБэзђЬьЕННёЬьЕФбЊдЕЙиЯЕЃЌПЩЛљгкЪБМфЮЌЖШНјааЪ§ОнЙ§ТЫКЭМьЫїЁЃ
вдЩЯЃЌNebula Graph дк WeDataSphere Ъ§ОнжЮРэЙ§ГЬжаЕФгІгУЧщПіНщЩмЭъБЯЁЃ

е§ШчлЁЫЇдкбнНВЁЖNebulaGraph - WeDataSphere ПЊдДНщЩмЁЗжаЫЕЕФФЧбљЃЌWeDataSphere
ЬсЙЉСНВуЪ§ОнСЌНгКЭРЉеЙФмСІЃЌЧАепЪЧвЛеОЪНЪ§ОнвЕЮёПЊЗЂЙмРэЬзМў WeDataSphereЃЌКѓепЪЧМЦЫужаМфМў
Linkis гУгкСЌНгЕзВуЕФЛљДЁзщМўЁЃЖј Nebula Graph вВЛљгк WeDataSphere
етСНВуЙІФмЭЌЯжгаЪ§ОнвЕЮёНјааНсКЯЃЌДђЭЈЪ§ОнПЊЗЂСїГЬЁЃ
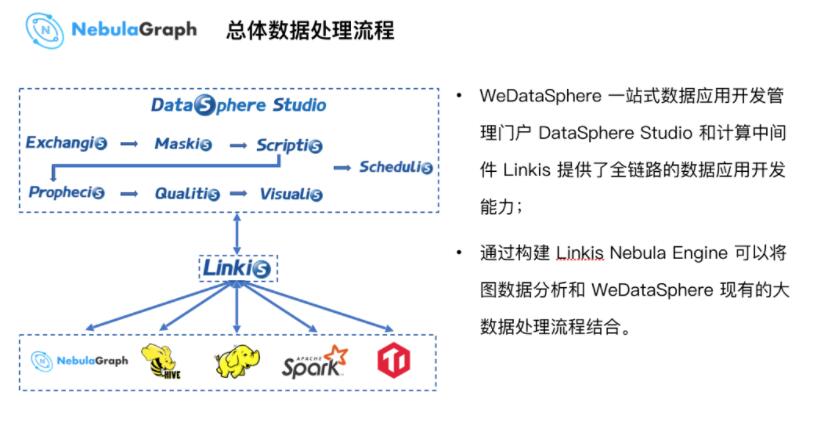
ЩЯЭМЮЊ WeDataSphere вЛеОЪНЪ§ОнгІгУПЊЗЂЙмРэУХЛЇ Studio ЕФЪ§ОнДІРэСїГЬЁЃЩЯЭМЕФ
Exchangis ЮЊЪ§ОнНЛЛЛЯЕЭГЃЌЖСШЁВЛЭЌвьЙЙЪ§ОндДЕФЪ§ОнЕМЕНДѓЪ§ОнЦНЬЈЃЌдйЭЈЙ§ Maskis ЯЕЭГзіЧАжУЭбУєЃЌекЕВУєИаЪ§ОнЛђНјаа
Hash зЊЛЛЬсЙЉИјвЕЮёЗжЮіШЫдБЪЙгУЁЃетИіЯЕЭГжагавЛИі Online аД SQL ЛЗОГ ScriptisЃЌЯрЙибаЗЂШЫдБПЩвдаДаЉ
SQL ЗжЮігяОфзіЧАжУЪ§ОнДІРэЃЌШЛКѓЪ§ОнДЋЪфИјЯЕЭГжаЕФЛњЦїбЇЯАЙЄОп Prophecis зіНЈФЃДІРэЁЃзюКѓЃЌЪ§ОнДІРэЭъГЩКѓНЛИЖИј
Qualitis ЯЕЭГзіЪ§ОнжЪСПаЃбщЃЌЕУЕНАВШЋЁЂПЩППЪ§ОнжЎКѓдйгЩПЩЪгЛЏЯЕЭГ Visualis НјааНсЙћеЙЪОКЭЗжЮіЃЌзюжеЗЂЫЭгЪМўИјБЈБэНгЪеЗНЁЃ
ЩЯЭМЮЊгУЛЇПЩИажЊЕФвЛИіСїГЬЃЌЕЋећИіДІРэСїГЬЛсЪЙгУЕНЕзВуММЪѕзщМўЃЌдк WeDataSphere ФкВПжївЊЭЈЙ§
Linkis етИіМЦЫужаМфМўШЅНтОіКЭЕзВузщМўСЌНгЁЂДЎСЊЮЪЬтЁЃГ§ДЫжЎЭтЃЌLinkis ЛЙЬсЙЉСЫЭЈгУЕФЖрзтЛЇИєРыЁЂЗжСїЁЂШЈЯоЙмПиЕФФмСІЁЃЛљгк
Linkis етИіМЦЫужаМфМўЃЌДѓЪ§ОнЦНЬЈЪЕЯжСЫ Linkis Nebula Engine ЭМЗжЮів§ЧцЃЌКЭ
WeDataSphere ЯжгаЕФДѓЪ§ОнДІРэСїГЬНсКЯЁЃ
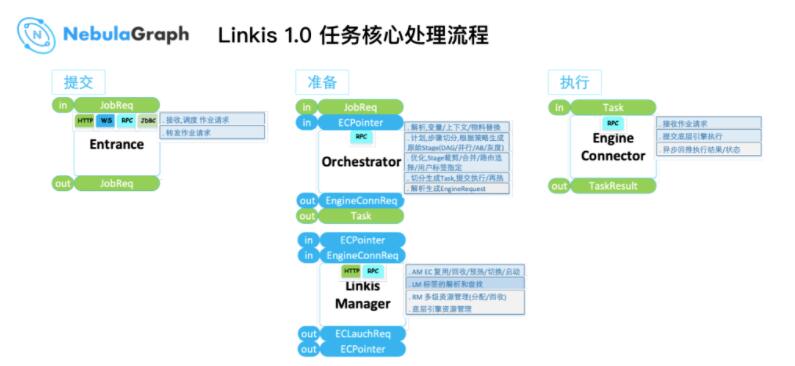
ЯждкРДНщЩмЯТ Linkis Ъ§ОнДІРэСїГЬЃК
ЕквЛНзЖЮЃКвЛИіШЮЮёдк DataSphere Studio ЬсНЛКѓЃЌНјШыЩЯЭМЫљЪО EntranceЃЌетИізщМўжївЊгУгкШЮЮёНтЮіКЭВЮЪ§НгЪеЁЃ
ЕкЖўИіНзЖЮЃКвВЪЧвЛИіЙиМќЕФзМБИНзЖЮЃЌНјШы Orchestrator ФЃПщЃЌдкЩЯУц PPT ЕФЁИЭЌГЧвЕЮёЪ§ОнЫЋаДЁЙеТНкЫЕЙ§
Orchestrator ФЃПщЪЕЯжБрХХЁЂЗжСїЁЂЛиЗХЁЂИпПЩгУЁЃБрХХЛсНЋвЛИі Job В№ЗжГЩ N ИіЯИаЁЕФ
TaskЃЌЖјетаЉ Task ЖдгІЕФзЪдДЩъЧыашвЊСЌНгЕзВу Linkis ManagerЃЌLinkis
Manager ЛсАб Task ЗжЗЂЁЂгГЩфЕНЖдгІЕФжДаав§ЧцзіЪ§ОнДІРэЃЌзюКѓЃЌЭЈЙ§ EngineConn
Manger СЌНгЕНЖдгІжДаав§ЧцЃЌПЩМћКЭ Nebula Graph НјааЪ§ОнНЛЛЅЕФжївЊЪЧ EngineConn
MangerЁЃ
ЕкШ§ИіНзЖЮЃКжДааЁЃ
ЩЯУцећИіЙ§ГЬЕФЪЕЯжТпМЪЧПЩИДгУЕФЃЌзіЪ§ОнгІгУНгШыЪБЃЌжЛашНЈСЂжаМфМўЭЌЕзВув§ЧцЕФСЌНгЃЌЪ§ОнОЙ§ Orchestrator
ФЃПщЛсздЖЏЗжЗЂЕНЖдгІЕФжДаав§ЧцзіЪ§ОнДІРэЁЃ
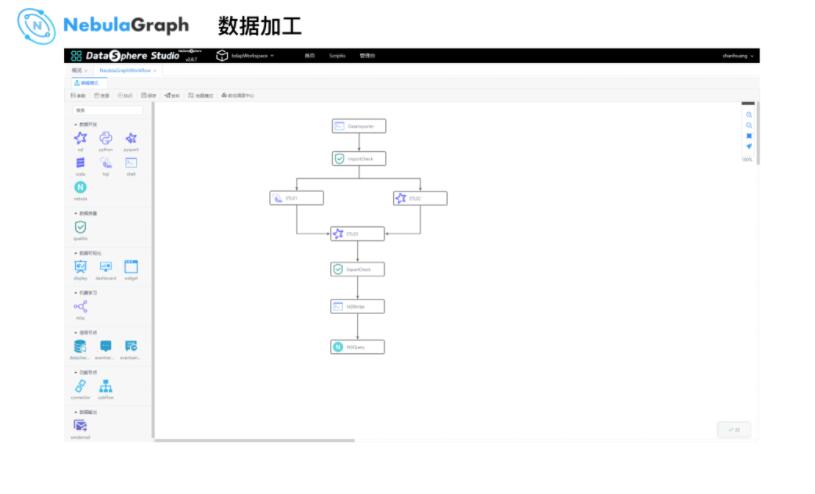
Ъ§ОнМгЙЄДІРэСїГЬШчЩЯЫљЪОЃЌКЭ WeDataSphere вЛеОЪНЪ§ОнгІгУПЊЗЂЙмРэУХЛЇ Studio
ЕФЪ§ОнДІРэСїГЬРрЫЦЃКРЬЪ§Он -> ДѓЪ§ОнЦНЬЈ -> Qualitis Ъ§ОнжЪСПаЃбщ ->
аД SQL -> Hive / Spark зіИДдгЕФЪ§ОнМгЙЄДІРэЃЌзюжеЪфГіжЎЧАНјааЪ§ОнжЪСПаЃбщЃЌЭЈЙ§
Nebula Graph ЕФ Spark Writer аДЕН NebulaЁЃ
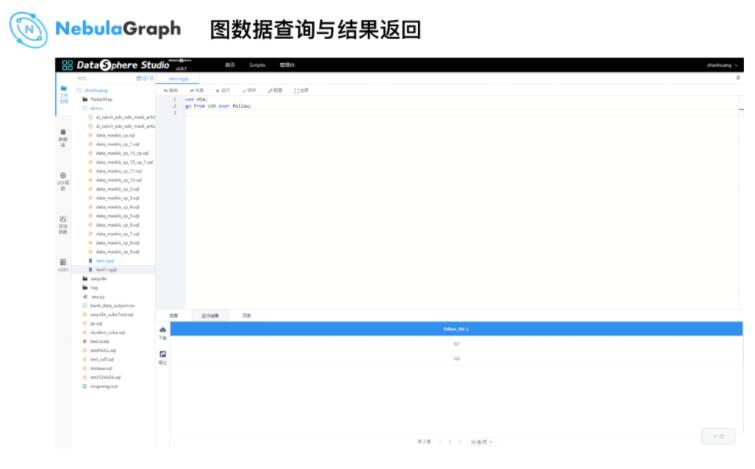
етРяЃЌДѓЪ§ОнЦНЬЈЬсЙЉСЫвЛИі nGQL БрГЬНчУцЃЌвђЮЊетЪБЪ§ОнвбаДШы Nebula GraphЃЌНјШы
nGQL НчУцКѓжДааШчЯТВщбЏгяОфЃК
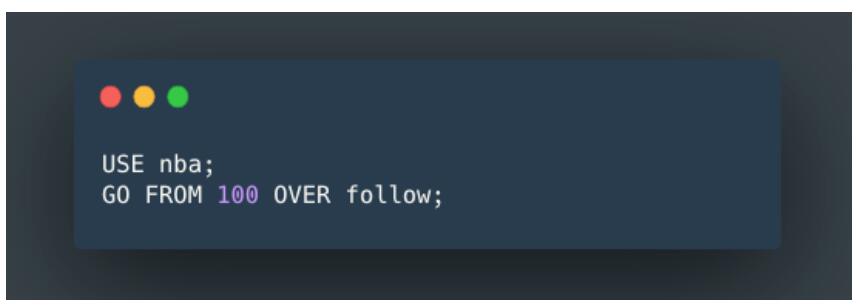
МДПЩдкНчУцЗЕЛиЭМЪ§ОнПт Nebula Graph ЕФВщбЏНсЙћЃЌЭЌ Nebula Graph ЙйЗНЬсЙЉЕФПЩЪгЛЏЙЄОп
Studio ВЛЭЌЃЌWeDataSphere ЕФ nGQL НчУцжївЊЪЧДІРэЪ§ОнСїГЬЕФДЎСЊЮЪЬтЃЌВЛЩцМАОпЬхЕФПЩЪгЛЏЙІФмЃЌКѓЦкЮЂжквјааДѓЪ§ОнЭХЖгвВЛсПМТЧКЭЙйЗННјааПЩЪгЛЏЗНУцЕФКЯзїЁЃ

зюКѓвЛВПЗжЪЧЮДРДеЙЭћЃЌЯШРДНВЯТ WeDataSphere етЬзЭМЪ§ОнПтЯЕЭГдкЮЂжквјааФкВПЕФгІгУЃЌФПЧАЮвУЧДѓЪ§ОнЦНЬЈФкВПжївЊЪЧгІгУ
Nebula Graph зібЊдЕЪ§ОнДцДЂКЭЗжЮіЃЛЦфЫћвЕЮёВПУХвВгаЪЕМЪгІгУЃЌР§ШчЃКзЪЙмЯЕЭГДІРэЦѓвЕЙиЯЕЪБгагУЕН
NebulaЃЛЮвУЧЕФ AIOPS ЯЕЭГФПЧАвВдкзіетПщвЕЮёВтЪдЃЌжївЊЪЧЙЙНЈдЫЮЌжЊЪЖЭМЦзШЅЪЕЯжЙЪеЯЕФИљвђЗжЮіКЭНтОіЗНАИЗЂЯжЃЛДЫЭтЃЌЮвУЧЕФЩѓМЦЯЕЭГвВдкЛљгкЭМЪ§ОнПтзіжЊЪЖЭМЦзЙЙНЈЃЌЯрЙиВПУХФПЧАдкГЂЪдНгШыетЬзЭМЪ§ОнПтЯЕЭГЃЛЮвУЧЗчПиГЁОАвЕЮёвВвбНгШы
WeDataSphere ЭМЪ§ОнПтЯЕЭГНјааВтЪдЃЌНгЯТРДЛсгаИќЖрЕФвЕЮёЗНРДзіетвЛПщЕФГЂЪдЁЃ

ЮДРДЕФЛАЃЌДѓЪ§ОнЦНЬЈетБпЛсЛљгк Nebula Graph 2.0 ПЊЗХЕФЙІФмКЭМмЙЙДюНЈИќМгздЖЏЛЏЁЂИќМгЮШЖЈЕФММЪѕМмЙЙЃЌЗўЮёКУИќМгЙиМќЕФвЕЮёЁЃ
ЛЙгаЭЌ Nebula Graph вЛЦ№ЭиеЙЭМЗжЮіетПщФмСІЃЌНгШыЕНећИіДѓЪ§ОнЦНЬЈ WeDataSphere
етЬзЪ§ОнДІРэСїГЬжаЁЃ
зюКѓЃЌзюживЊЕФЃЌЯЃЭћгаИќЖрКЯЪЪЕФвЕЮёГЁОАФмЙЛНгШыЕН WeDataSphere етЬзЭМЪ§ОнДІРэЕФСїГЬКЭЯЕЭГжаЃЌвдЩЯЪЧЮЂжквјааДѓЪ§ОнЦНЬЈЁЊЁЊжмПЩЕФММЪѕЗжЯэЃЌаЛаЛЁЃ

| 








