| БрМЭЦМі: |
БОЮФМђЕЅНщЩмЪВУДЪЧЗжВМЪНЪ§ОнПтЃЌЗжВМЪНЪ§ОнПтРэТлЛљДЁвдМАPostgreSQLЗЂеЙЪБМфЯпМАЗжжЇЭМЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДзд51CTOЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
вЛЁЂ ЪВУДЪЧЗжВМЪНЪ§ОнПт
ЗжВМЪНЯЕЭГЪ§ОнПтЯЕЭГдРэ(ЕкШ§Ац)жаЕФУшЪіЃКЁАЮвУЧАбЗжВМЪНЪ§ОнПтЖЈвхЮЊвЛШКЗжВМдкМЦЫуЛњЭјТчЩЯЁЂТпМЩЯЯрЛЅЙиСЊЕФЪ§ОнПтЁЃЗжВМЪНЪ§ОнПтЙмРэЯЕЭГ(ЗжВМЪНDBMS)дђЪЧжЇГжЙмРэЗжВМЪНЪ§ОнПтЕФШэМўЯЕЭГЃЌЫќЪЙЕУЗжВМЖдгкгУЛЇБфЕУЭИУїЁЃгаЪБЃЌЗжВМЪНЪ§ОнПтЯЕЭГ(Distributed
Database System,DDBS)гУгкБэЪОЗжВМЪНЪ§ОнПтКЭЗжВМЪНDBMSетСНепЁЃЁБ

дквдЩЯБэЪіжаЃЌЁАвЛШКЗжВМдкЭјТчЩЯЁЂТпМЩЯЯрЛЅЙиСЊЁБЪЧЦфвЊвхЁЃдкЮяРэЩЯвЛШКТпМЩЯЯрЛЅЙиСЊЕФЪ§ОнПтПЩвдЗжВМЪНдквЛИіЛђЖрИіЮяРэНкЕуЩЯЁЃЕБШЛЃЌжївЊЛЙЪЧгІгУдкЖрИіЮяРэНкЕуЁЃетвЛЗНУцЪЧX86ЗўЮёЦїадМлБШЕФЬсЩ§гаЙиЃЌСэвЛЗНУцЪЧвђЮЊЛЅСЊЭјЕФЗЂеЙДјРДСЫИпВЂЗЂКЭКЃСПЪ§ОнДІРэЕФашЧѓЃЌдРДЕФЕЅЮяРэЗўЮёЦїНкЕуВЛзувдТњзуетИіашЧѓЁЃ
ЗжВМЪНВЛжЛЪЧЬхЯждкЪ§ОнПтСьгђЃЌвВгыЗжВМЪНДцДЂЁЂЗжВМЪНжаМфМўЁЂЗжВМЪНЭјТчгазХКмЖрЙиСЊЁЃзюжеФПЕФЖМЪЧЮЊСЫИќКУЕФЗўЮёгквЕЮёашЧѓЕФБфИќЁЃДгембЇвтвхЩЯРэНтЪЧвЛжжЩњВњСІЕФЬсЩ§ЁЃ
ЖўЁЂ ЗжВМЪНЪ§ОнПтРэТлЛљДЁ
1. CAPРэТл
ЪзЯШЃЌЗжВМЪНЪ§ОнПтЕФММЪѕРэТлЪЧЛљгкЕЅНкЕуЙиЯЕЪ§ОнПтЕФЛљБОЬиадЕФМЬГаЃЌжївЊЩцМАЪТЮёЕФACIDЬиадЁЂЪТЮёШежОЕФШнджЛжИДадЁЂЪ§ОнШпгрЕФИпПЩгУадМИИівЊЕуЁЃ
ЦфДЮЃЌЗжВМЪНЪ§ОнЕФЩшМЦвЊзёбCAPЖЈРэЃЌМДЃКвЛИіЗжВМЪНЯЕЭГВЛПЩФмЭЌЪБТњзу вЛжТад( Consistency
) ЁЂПЩгУад ( Availability ) ЁЂЗжЧјШн ШЬ ад ( Partition tolerance
) етШ§ИіЛљБОашЧѓЃЌзю ЖржЛФмЭЌЪБТњзуЦфжаЕФСНЯюЃЌ ЗжЧјШнДэад ЪЧВЛФмЗХЦњЕФЃЌвђДЫМмЙЙЪІЭЈГЃЪЧдкПЩгУадКЭвЛжТаджЎМфШЈКтЁЃетРяЕФШЈКтВЛЪЧМђЕЅЕФЭъШЋХзЦњЃЌЖјЪЧПМТЧвЕЮёЧщПізїГіЕФЮўЩќЃЌЛђепгУЛЅСЊЭјЕФвЛИіЪѕгяЁАНЕМЖЁБРДУшЪіЁЃ
еыЖдCAPРэТлЃЌВщдФСЫЙњЭтЕФЯрЙиЮФЕЕБэЪіЃЌCAPРэТлРДдДгк2002ФъТщЪЁРэЙЄбЇдКЕФSeth GilbertКЭNancy
LynchЗЂБэЕФЙигкBrewerВТЯыЕФе§ЪНжЄУїЁЃ

CAP Ш§ИіЬиадУшЪіШчЯТ ЃК
вЛжТадЃКШЗБЃЗжВМЪНШКМЏжаЕФУПИіНкЕуЖМЗЕЛиЯрЭЌЕФ ЁЂ зюНќ ИќаТЕФЪ§Он ЁЃвЛжТадЪЧжИУПИіПЭЛЇЖЫОпгаЯрЭЌЕФЪ§ОнЪгЭМЁЃгаЖржжРраЭЕФвЛжТадФЃаЭ
ЃЌ CAPжаЕФвЛжТадЪЧжИЯпадЛЏЛђЫГађвЛжТадЃЌЪЧЧПвЛжТадЁЃ
ПЩгУадЃКУПИіЗЧЪЇАмНкЕудкКЯРэЕФЪБМфФкЗЕЛиЫљгаЖСШЁКЭаДШыЧыЧѓЕФЯьгІЁЃЮЊСЫПЩгУЃЌЭјТчЗжЧјСНВрЕФУПИіНкЕуБиаыФмЙЛдкКЯРэЕФЪБМфФкзіГіЯьгІЁЃ
ЗжЧјШнШЬадЃКОЁЙмДцдкЭјТчЗжЧјЃЌЯЕЭГШдПЩМЬајдЫааВЂ БЃжЄ вЛжТадЁЃЭјТчЗжЧјвбГЩЪТЪЕЁЃБЃжЄЗжЧјШнШЬЖШЕФЗжВМЪНЯЕЭГПЩвддкЗжЧјаоИДКѓДгЗжЧјНјааЪЪЕБЕФЛжИДЁЃ
дЮФжївЊЙлЕугадкЧПЕїCAPРэТлВЛФмМђЕЅЕФРэНтЮЊШ§бЁЖўЁЃ
дкЗжВМЪНЪ§ОнПтЙмРэЯЕЭГжаЃЌЗжЧјШнШЬадЪЧБиаыЕФЁЃЭјТчЗжЧјКЭЖЊЦњЕФЯћЯЂвбГЩЪТЪЕЃЌБиаыНјааЪЪЕБЕФДІРэЁЃвђДЫЃЌЯЕЭГЩшМЦШЫдББиаыдквЛжТадКЭПЩгУаджЎМфНјааШЈКт
ЁЃМђЕЅЕиЫЕЃЌЭјТчЗжЧјЦШЪЙЩшМЦШЫдБбЁдёЭъУРЕФвЛжТадЛђЭъУРЕФПЩгУадЁЃдкИјЖЈЧщПіЯТЃЌ гХау ЕФЗжВМЪНЯЕЭГЛсИљОнвЕЮёЖдвЛжТадКЭПЩгУадашЧѓЕФживЊЕШМЖЬсЙЉзюМбЕФД№АИЃЌЕЋЭЈГЃвЛжТадашЧѓЕШМЖЛсИќИпЃЌвВЪЧзюгаЬєеНЕФ
ЁЃ
2. BASEРэТл
ЛљгкCAPЖЈРэЕФШЈКтЃЌбнНјГіСЫ BASEРэТл ЃЌBASEЪЧBasically Available(ЛљБОПЩгУ)ЁЂSoft
state(ШэзДЬЌ)КЭEventually consistent(зюжевЛжТад)Ш§ИіЖЬгяЕФЫѕаДЁЃBASEРэТлЕФКЫаФЫМЯыЪЧЃКМДЪЙЮоЗЈзіЕНЧПвЛжТадЃЌЕЋУПИігІгУЖМПЩвдИљОнздЩэвЕЮёЬиЕуЃЌВЩгУЪЪЕБЕФЗНЪНРДЪЙЯЕЭГДяЕНзюжевЛжТадЁЃ
BAЃКBasically Available ЛљБОПЩгУЃЌЗжВМЪНЯЕЭГдкГіЯжЙЪеЯЕФЪБКђЃЌдЪаэЫ№ЪЇВПЗжПЩгУадЃЌМДБЃжЄКЫаФПЩгУЁЃ
sЃКsoft State ШэзДЬЌЃЌдЪаэЯЕЭГДцдкжаМфзДЬЌЃЌЖјИУжаМфзДЬЌВЛЛсгАЯьЯЕЭГећЬхПЩгУадЁЃ
EЃКConsistency зюжевЛжТадЃЌЯЕЭГжаЕФЫљгаЪ§ОнИББООЙ§вЛЖЈЪБМфКѓЃЌзюжеФмЙЛДяЕНвЛжТЕФзДЬЌЁЃ
BASE РэТлБОжЪЩЯЪЧЖд CAP РэТлЕФбгЩьЃЌЪЧЖд CAP жа AP ЗНАИЕФвЛИіВЙГфЁЃ
етРяВЙГфЫЕУївЛЯТЪВУДЪЧЧПвЛжТадЃК
Strict Consistency ( ЧПвЛжТад ) вВГЦЮЊAtomic Consistency
( дзгвЛжТад) Лђ Linearizable Consistency(ЯпадвЛжТад) ЃЌБиаыТњзувдЯТ
СНИівЊЧѓЃК
1ЁЂШЮКЮвЛДЮЖСЖМФмЖСЕНФГИіЪ§ОнЕФзюНќвЛДЮаДЕФЪ§ОнЁЃ
2ЁЂЯЕЭГжаЕФЫљгаНјГЬЃЌПДЕНЕФВйзїЫГађЃЌЖМКЭШЋОжЪБжгЯТЕФЫГађвЛжТЁЃ
ЖдгкЙиЯЕаЭЪ§ОнПтЃЌвЊЧѓИќаТЙ§ЕФЪ§ОнФмБЛКѓајЕФЗУЮЪЖМФмПДЕНЃЌетЪЧЧПвЛжТадЁЃМђбджЎЃЌдкШЮвтЪБПЬЃЌЫљгаНкЕужаЕФЪ§ОнЪЧвЛбљЕФЁЃ
BASE РэТлЕФзюжевЛжТадЪєгкШѕвЛжТадЁЃ
НгЯТРДНщЩмСэвЛИіЗжВМЪНЪ§ОнПтживЊЕФИХФюЃКЗжВМЪНЪТЮёЁЃфЏРРСЫМИЦЊНщЩмЗжВМЪНЪТЮёЕФЮФеТЃЌЗЂЯжЛсгаВЛЭЌЕФУшЪіЃЌЕЋДѓжТКЌвхЪЧЯрЭЌЕФЁЃЗжВМЪНЪТЮёЪзЯШЪЧЪТЮёЃЌ
ашвЊТњзуЪТЮёЕФACIDЕФЬиадЁЃжївЊПМТЧвЕЮёЗУЮЪДІРэЕФЪ§ОнЗжЩЂдкЭјТчМфЕФЖрНкЕуЩЯЃЌЖдгкЗжВМЪНЪ§ОнПтЯЕЭГЖјбдЃЌ
дкБЃжЄЪ§ОнвЛжТадЕФвЊЧѓЯТЃЌНјааЪТЮёЕФЗжЗЂЁЂаЭЌЖрНкЕуЭъГЩвЕЮёЧыЧѓЁЃ
ЖрНкЕуФмЗёе§ГЃЁЂЫГРћЕФаЭЌзївЕЭъГЩЪТЮёЪЧЙиМќЃЌЫќжБНгОіЖЈСЫЗУЮЪЪ§ОнЕФвЛжТадКЭЖдЧыЧѓЯьгІЕФМАЪБадЁЃДгЖјОЭашвЊПЦбЇгааЇЕФвЛжТадЫуЗЈРДжЇГХЁЃ
3. вЛжТадЫуЗЈ
ФПЧАжївЊЕФ вЛжТадЫуЗЈ АќРЈ ЃК2PC ЁЂ 3pc ЁЂ paxos ЁЂ Raft ЁЃ
2PC ЃКTwo-Phase Commit ( ЖўНзЖЮЬсНЛ ) вВБЛШЯЮЊЪЧвЛжжвЛжТадавщЃЌгУРДБЃжЄЗжВМЪНЯЕЭГЪ§ОнЕФвЛжТадЁЃОјДѓВПЗжЕФЙиЯЕаЭЪ§ОнПтЖМЪЧВЩгУЖўНзЖЮЬсНЛавщРДЭъГЩЗжВМЪНЪТЮёДІРэЁЃ
жївЊАќРЈвдЯТСНИіНзЖЮЃК
ЕквЛНзЖЮЃКЬсНЛЪТЮёЧыЧѓ(ЭЖЦБНзЖЮ)
ЕкЖўНзЖЮЃКжДааЪТЮёЬсНЛ(жДааНзЖЮ)
гХЕуЃКдРэМђЕЅЁЂЪЕЯжЗНБу
ШБЕуЃКЭЌВНзшШћЁЂЕЅЕуЮЪЬтЁЂЪ§ОнВЛвЛжТЁЂЬЋЙ§БЃЪи
3PC ЃКThree- Phase Commi ( Ш§НзЖЮЬсНЛ )АќРЈ CanCommitЁЂPreCommitЁЂdoCommit
Ш§ИіНзЖЮЁЃ
ЮЊСЫБмУтдкЭЈжЊЫљгаВЮгыепЬсНЛЪТЮёЪБЃЌЦфжавЛИіВЮгыеп crash ВЛвЛжТЪБЃЌОЭГіЯжСЫШ§НзЖЮЬсНЛЕФЗНЪНЁЃ
Ш§НзЖЮЬсНЛдкСННзЖЮЬсНЛЕФЛљДЁЩЯдіМгСЫвЛИі preCommit ЕФЙ§ГЬЃЌЕБЫљгаВЮгыепЪеЕН preCommit
КѓЃЌВЂВЛжДааЖЏзїЃЌжБЕНЪеЕН commit ЛђГЌЙ§вЛЖЈЪБМфКѓВХЭъГЩВйзїЁЃ
гХЕуЃКНЕЕЭВЮгыепзшШћЗЖЮЇЃЌВЂФмЙЛдкГіЯжЕЅЕуЙЪеЯКѓМЬајДяГЩвЛжТ ШБЕуЃКв§Шы preCommit НзЖЮЃЌдкетИіНзЖЮШчЙћГіЯжЭјТчЗжЧјЃЌаЕїепЮоЗЈгыВЮгыепе§ГЃЭЈаХЃЌВЮгыепвРШЛЛсНјааЪТЮёЬсНЛЃЌдьГЩЪ§ОнВЛвЛжТЁЃ
2PC / 3PC авщгУгкБЃжЄЪєгкЖрИіЪ§ОнЗжЦЌЩЯВйзїЕФдзгадЁЃ
етаЉЪ§ОнЗжЦЌПЩФмЗжВМдкВЛЭЌЕФЗўЮёЦїЩЯЃЌ2PC / 3PC авщБЃжЄЖрЬЈЗўЮёЦїЩЯЕФВйзївЊУДШЋВПГЩЙІЃЌвЊУДШЋВПЪЇАмЁЃ
Paxos ЁЂ Raft ЁЂ Zab ЫуЗЈгУгкБЃжЄЭЌвЛИіЪ§ОнЗжЦЌЕФЖрИіИББОжЎМфЕФЪ§ОнвЛжТад ЁЃвдЯТЪЧШ§жжЫуЗЈЕФИХвЊУшЪі
ЁЃ
Paxos ЫуЗЈжївЊНтОіЪ§ОнЗжЦЌЕФЕЅЕуЮЪЬт ЃЌ ФПЕФЪЧШУећИіМЏШКЕФНсЕуЖдФГИіжЕЕФБфИќДяГЩвЛжТЁЃPaxos
(ЧПвЛжТад) ЪєгкЖрЪ§ХЩЫуЗЈ ЁЃШЮКЮвЛИіЕуЖМПЩвдЬсГівЊаоИФФГИіЪ§ОнЕФЬсАИЃЌЪЧЗёЭЈЙ§етИіЬсАИШЁОігкетИіМЏШКжаЪЧЗёгаГЌЙ§АыЪ§ЕФНсЕуЭЌвтЃЌЫљвд
Paxos ЫуЗЈашвЊМЏШКжаЕФНсЕуЪЧЕЅЪ§ ЁЃ
Raft ЫуЗЈЪЧМђЛЏАцЕФPaxosЃЌ Raft ЛЎЗжГЩШ§ИізгЮЪЬтЃКвЛЪЧLeader Election;ЖўЪЧ
Log Replication;Ш§ЪЧSafetyЁЃRaft ЖЈвхСЫШ§жжНЧЩЋ LeaderЁЂFollowerЁЂCandidateЃЌзюПЊЪМДѓМвЖМЪЧFollowerЃЌЕБFollowerМрЬ§ВЛЕНLeaderЃЌОЭПЩвдздМКГЩЮЊCandidateЃЌЗЂЦ№ЭЖЦБ
ЃЌбЁГіаТЕФleader ЁЃ
ЦфгаСНИіЛљБОЙ§ГЬЃК
Ђй LeaderбЁОйЃКУПИі C andidateЫцЛњОЙ§вЛЖЈЪБМфЖМЛсЬсГібЁОйЗНАИЃЌзюНќНзЖЮжа ЕУ
ЦБзюЖрепБЛбЁЮЊ L eaderЁЃ
Ђк ЭЌВНlogЃКL eaderЛсевЕНЯЕЭГжаlog(ИїжжЪТМўЕФЗЂЩњМЧТМ)зюаТЕФМЧТМЃЌВЂЧПжЦЫљгаЕФfollowРДЫЂаТЕНетИіМЧТМЁЃ
RaftвЛжТадЫуЗЈЪЧЭЈЙ§бЁГівЛИіleaderРДМђЛЏШежОИББОЕФЙмРэЃЌР§ШчЃЌШежОЯю(log entry)жЛдЪаэДгleaderСїЯђfollowerЁЃZABЛљБОгы
raft ЯрЭЌЁЃ
Ш§ЁЂPostgreSQL ЗжВМЪНМмЙЙвЛРР
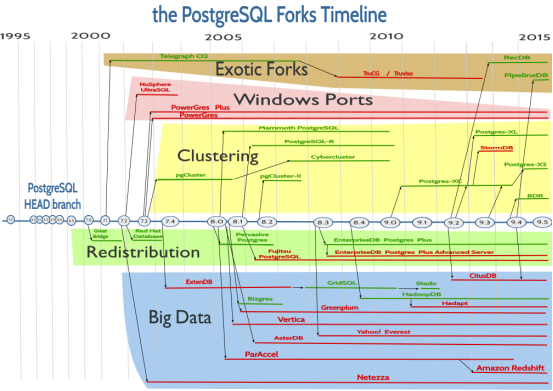
PostgreSQLЗЂеЙЪБМфЯпМАЗжжЇЭМ
1. ЛљгкФкКЫЗжВМЪНЗНАИ Postgres-XL
(1) ЪВУДЪЧPostgres-XL
Postgres-XLЪЧвЛПюПЊдДЕФPGМЏШКШэМўЃЌXLДњБэeXtensible LatticeЃЌМДПЩРЉеЙЕФPGЁАИёзгЁБжЎвтЃЌвдЯТМђГЦPGXLЁЃ
ЙйЗНГЦЦфМШЪЪКЯаДВйзїбЙСІНЯДѓЕФOLTPгІгУЃЌгжЪЪКЯЖСВйзїЮЊжїЕФДѓЪ§ОнгІгУЁЃЫќЕФЧАЩэЪЧPostgres-XC(МђГЦPGXC)ЃЌPGXCЪЧдкPGЕФЛљДЁЩЯМгШыСЫМЏШКЙІФмЃЌжївЊЪЪгУгкOLTPгІгУЁЃPGXLЪЧдкPGXCЕФЛљДЁЩЯЕФЩ§МЖВњЦЗЃЌМгШыСЫвЛаЉЪЪгУгкOLAPгІгУЕФЬиадЃЌШч
Massively Parallel Processing (MPP) ЬиадЁЃ
ЭЈЫзЕФЫЕPGXLЕФДњТыЪЧАќКЌPGДњТыЃЌЪЙгУPGXLАВзАPGМЏШКВЂВЛашвЊЕЅЖРАВзАPGЁЃетбљДјРДЕФвЛИіЮЪЬтЪЧЮоЗЈЫцвтбЁдёШЮвтАцБОЕФPGЃЌКУдкPGXLИњНјPGНЯМАЪБЃЌФПЧАзюаТАцБОPostgres-XL
10R1ЃЌЛљгкPG 10ЁЃ
ЩчЧјЗЂеЙЪЗЃК
2004~2008 ФъЃЌ NTT Data ЙЙНЈСЫФЃаЭ Rita-DB
2009 ФъЃЌ NTT Data гы EnterpriseDB КЯзїНјааЩчЧјЛЏПЊЗЂ
2012 ФъЃЌ Postgres-XC 1.0 е§ЪНЗЂВМ
2012 ФъЃЌ StormDB дк XC ЛљДЁЩЯдіМг MPP ЙІФм .
2013 ФъЃЌ XC 1.1 ЗЂВМ ;TransLattice ЪеЙК StormDB
2014 ФъЃЌ XC 1.2 ЗЂВМ ;StormDB ПЊдДЮЊ Postgres-XL.
2015 ФъЃЌСНИіЩчЧјКЯВЂЮЊ Postgres-X2
2016 Фъ 2 дТЃЌ Postgres-XL 9.5 R1
2017Фъ7дТ ЃЌ Postgres-XL 9.5 R1.6
2018Фъ10дТ ЃЌ Postgres-XL 10R1
2019 Фъ 2 дТ ЃЌ аћВМЭЦГіPostgres-XL 10R1 .1

PostgreSQLгыPGXCЖдБШЭМ(еуНвЦЖЏЬЗЗхЗжЯэ)
(2) ММЪѕМмЙЙ
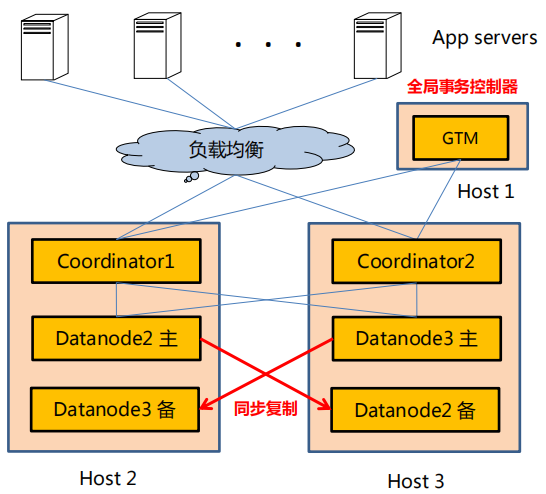
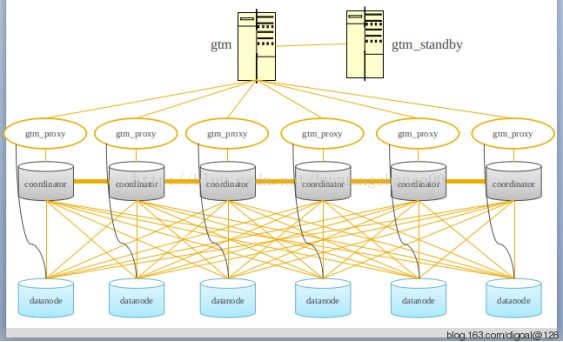
МмЙЙЭМ1
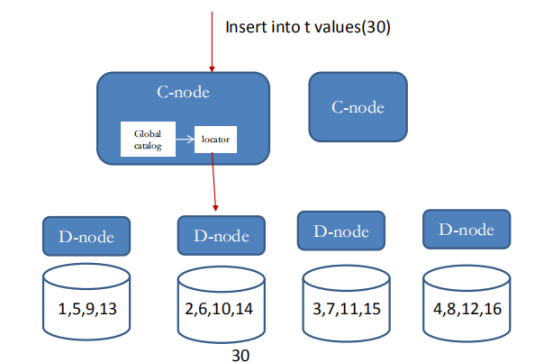
ДгЩЯЭМПЩвдПДГіCoordinatorКЭdatanodeНкЕуПЩвдХфжУЮЊЖрИіЃЌВЂЧвПЩвдЮЛгкВЛЭЌЕФжїЛњЩЯЁЃжЛгаCoordinatorНкЕужБНгЖдгІгУЗўЮёЃЌCoordinatorНкЕуНЋЪ§ОнЗжХфДцДЂдкЖрИіЪ§ОнНкЕуdatanodeЩЯЁЃ
Postgres-XCжївЊзщМўгаgtm(Global Transaction Manager) ЃЌ
gtm_standby ЃЌ gtm_proxy, Coordinator КЭDatanodeЁЃ
ШЋОжЪТЮёНкЕу ( GTM )ЃЌ ЪЧPostgres-XCЕФКЫаФзщМўЃЌгУгкШЋОжЪТЮёПижЦвдМАtupleЕФПЩМћадПижЦЁЃgtm
ЮЊЗжХфGXIDКЭЙмРэPGXC MVCCЕФФЃПщ ЃЌ дквЛИіCLUSTERжажЛФмгавЛЬЈжїЕФgtmЁЃgtm_standby
ЮЊgtmЕФБИЛњ ЁЃ
жївЊзїгУЃК
ЈC ЩњГЩШЋОжЮЈвЛЕФЪТЮёID
ЈC ШЋОжЕФЪТЮёЕФзДЬЌ
ЈC ађСаЕШШЋОжаХЯЂ
gtm_proxyЮЊНЕЕЭgtmбЙСІЖјЕЎЩњЕФ, гУгкЖдcoordinatorНкЕуЬсНЛЕФШЮЮёНјааЗжзщЕШВйзї.
ЛњЦїжаПЩвдДцдкЖрИіgtm_proxyЁЃ
аЕїНкЕу (Coordinator) ЪЧЪ§ОнНкЕу (Datanode) гыгІгУжЎМфЕФНгПкЃЌ ИКд№НгЪегУЛЇЧыЧѓЁЂЩњГЩВЂжДааЗжВМЪНВщбЏЁЂ
Аб SQL гяОфЗЂИјЯргІЕФЪ§ОнНкЕуЁЃ
Coordinator НкЕуВЂВЛЮяРэЩЯДцДЂБэЪ§ОнЃЌБэЪ§ОнвдЗжЦЌЛђепИДжЦЕФЗНЪНЗжВМЪНДцДЂЃЌБэЪ§ОнДцДЂдкЪ§ОнНкЕуЩЯЁЃЕБгІгУЗЂЦ№SQLЪБЃЌЛсЯШЕНДя
Coordinator НкЕуЃЌШЛКѓ CoordinatorНкЕуНЋ SQLЗжЗЂЕНИїИіЪ§ОнНкЕуЃЌЛузмЪ§ОнЃЌетвЛЯЕЭГЙ§ГЬЪЧЭЈЙ§GXID
КЭGlobal Snapshot дй РДПижЦЕФЁЃ
Ъ§ОнНкЕу(datanode)ЮяРэЩЯДцДЂБэЪ§ОнЃЌБэЪ§ОнДцДЂЗНЪНЗжЮЊЗжЦЌ(distributed)КЭЭъШЋИДжЦ(replicated)СНжжЁЃЪ§ОнНкЕужЛДцДЂБОЕиЕФЪ§ОнЁЃ
Ъ§ОнЗжВМ
replicated table ИДжЦБэ
ЈC БэдкЖрИіНкЕуИДжЦ
distributed table ЗжВМЪНБэ
ЈC Hash
ЈC Round robin
зЂЪЭЃКRound robin ТжСїЗХжУЪЧзюМђЕЅЕФЛЎЗжЗНЗЈЃКМДУПЬѕдЊзщЖМЛсБЛвРДЮЗХжУдкЯТвЛИіНкЕуЩЯЃЌШчЯТЭМЫљЪОЃЌвдДЫНјаабЛЗЁЃ
2. РЉеЙЗжВМЪНЗНАИCitus
(1) ЪВУДЪЧCitus
CitusЪЧвЛПюЛљгкPostgreSQLЕФПЊдДЗжВМЪНЪ§ОнПт ЃЌ здЖЏМЬГаСЫPostgreSQLЧПДѓЕФSQLжЇГжФмСІКЭгІгУЩњЬЌ(ВЛНіЪЧПЭЛЇЖЫавщЕФМцШнЛЙАќРЈЗўЮёЖЫРЉеЙКЭЙмРэЙЄОпЕФЭъШЋМцШн)ЁЃCitusЪЧPostgreSQLЕФРЉеЙ(not
a fork)ЃЌВЩгУshared nothingМмЙЙЃЌНкЕужЎМфЮоЙВЯэЪ§ОнЃЌгЩаЕїЦїНкЕуКЭWorkНкЕуЙЙГЩвЛИіЪ§ОнПтМЏШКЁЃзЈзЂгкИпадФмHTAPЗжВМЪНЪ§ОнПт
ЁЃ
ЯрБШЕЅЛњPostgreSQLЃЌCitusПЩвдЪЙгУИќЖрЕФCPUКЫаФЃЌИќЖрЕФФкДцЪ§СПЃЌБЃДцИќЖрЕФЪ§ОнЁЃЭЈЙ§ЯђМЏШКЬэМгНкЕуЃЌПЩвдЧсЫЩЕФРЉеЙЪ§ОнПтЁЃ
гыЦфЫћРрЫЦЕФЛљгкPostgreSQLЕФЗжВМЪНЗНАИЃЌБШШчGreenPlumЃЌPostgreSQL-XLЯрБШЃЌCitusзюДѓЕФВЛЭЌдкгкЫќЪЧвЛИіPostgreSQLРЉеЙЖјВЛЪЧвЛИіЖРСЂЕФДњТыЗжжЇЁЃCitusПЩвдгУКмаЁЕФДњМлКЭИќПьЕФЫйЖШНєИњPostgreSQLЕФАцБОбнНј;ЭЌЪБгжФмзюДѓГЬЖШЕФБЃжЄЪ§ОнПтЕФЮШЖЈадКЭМцШнадЁЃ
CitusжЇГжаТАцБОPostgreSQLЕФЬиадЃЌВЂБЃГжгыЯжгаЙЄОпЕФМцШн ЁЃCitusЪЙгУЗжЦЌКЭИДжЦдкЖрЬЈЛњЦїЩЯКсЯђРЉеЙPostgreSQLЁЃЫќЕФВщбЏв§ЧцНЋдкетаЉЗўЮёЦїЩЯжДааSQLНјааВЂааЛЏВщбЏЃЌвдБудкДѓаЭЪ§ОнМЏЩЯЪЕЯжЪЕЪБ(ВЛЕНвЛУы)ЕФЯьгІЁЃ
CitusФПЧАжївЊЗжЮЊвдЯТМИИіАцБОЃК
CitusЩчЧјАц
CitusЩЬвЕАц
Cloud [AWSЃЌcitus cloud]
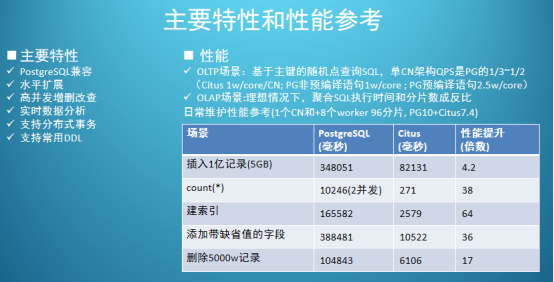
БОНиЭМв§гУ2020Фъ3дТЫеФўГТЛЊОќCitusЕФЪЕМљЗжЯэ
(2) ММЪѕМмЙЙ
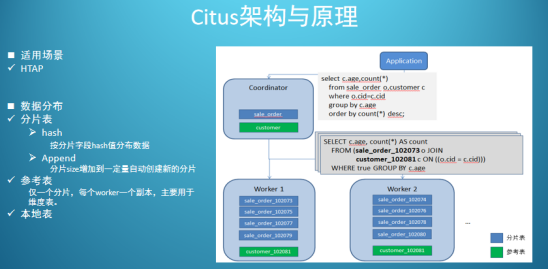
БОНиЭМв§гУ2020Фъ3дТЫеФўГТЛЊОќCitusЕФЪЕМљЗжЯэ
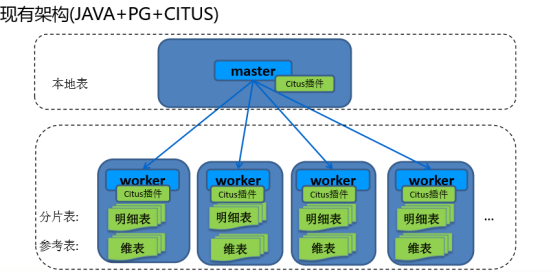
CitusМЏШКгЩвЛИіжааФЕФаЕїНкЕу(CN)КЭШєИЩИіЙЄзїНкЕу(Worker)ЙЙГЩЁЃ
CNжЛДцДЂКЭЪ§ОнЗжВМЯрЙиЕФдЊЪ§ОнЃЌЪЕМЪЕФБэЪ§ОнБЛЗжГЩMИіЗжЦЌЃЌДђЩЂЕНNИіWorkerЩЯЁЃетбљЕФБэБЛНазіЁАЗжЦЌБэЁБЃЌПЩвдЮЊЁАЗжЦЌБэЁБЕФУПвЛИіЗжЦЌДДНЈЖрИіИББОЃЌЪЕЯжИпПЩгУКЭИКдиОљКтЁЃ
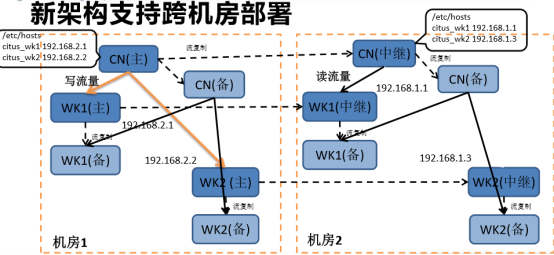
МмЙЙЭМ1(в§гУ2019ФъЫеФўCitusЪЕМљЗжЯэ)
CitusЙйЗНЮФЕЕИќНЈвщЪЙгУPostgreSQLдЩњЕФСїИДжЦзіHAЃЌЛљгкЖрИББОЕФHAвВаэжЛЪЪгУгкappend
onlyЕФЗжЦЌЁЃ
гІгУНЋВщбЏЗЂЫЭЕНаЕїЦїНкЕуЃЌаЕїЦїДІРэКѓЗЂЫЭжСworkНкЕуЁЃЖдгкУПИіВщбЏаЕїЦїНЋЦфТЗгЩЕНЕЅИіworkНкЕуЃЌЛђепВЂааЛЏжДааЃЌетШЁОігкЪ§ОнЪЧЗёдкЕЅИіНкЕуЩЯЛЙЪЧдкЖрИіНкЕуЩЯЁЃCitus
MXФЃЪНдЪаэжБНгЖдworkНкЕуНјааЗУЮЪЃЌНјааИќПьЕФЖСШЁКЭаДШыЫйЖШЁЃ
МмЙЙЭМ2(в§гУ2019ФъЫеФўCitusЪЕМљЗжЯэ)
CitusгаШ§жжРраЭБэ
ЗжЦЌБэ(зюГЃгУ)
ВЮПМБэ
БОЕиБэ
ЗжЦЌБэжївЊНтОіЕФЪЧДѓБэЕФЫЎЦНРЉШнЮЪЬтЃЌЖдЪ§ОнСПВЛЪЧЬиБ№ДѓгжОГЃашвЊКЭЗжЦЌБэJoinЕФЮЌБэПЩвдВЩгУвЛжжЬиЪтЕФЗжЦЌВпТдЃЌжЛЗж1ИіЦЌЧвУПИіWorkerЩЯВПЪ№1ИіИББОЃЌетбљЕФБэНазіЁАВЮПМБэЁБЁЃ
Г§СЫЗжЦЌБэКЭВЮПМБэЃЌЛЙЪЃЯТвЛжжУЛгаОЙ§ЗжЦЌЕФPostgreSQLдЩњЕФБэЃЌБЛГЦЮЊЁАБОЕиБэЁБЁЃЁАБОЕиБэЁБЪЪгУгквЛаЉЬиЪтЕФГЁОАЃЌБШШчИпВЂЗЂЕФаЁБэВщбЏЁЃ

БОНиЭМв§гУ2020Фъ3дТЫеФўГТЛЊОќCitusЕФЪЕМљЗжЯэ
ПЭЛЇЖЫгІгУЗУЮЪЪ§ОнЪБжЛКЭCNНкЕуНЛЛЅЁЃCNЪеЕНSQLЧыЧѓКѓЃЌЩњГЩЗжВМЪНжДааМЦЛЎЃЌВЂНЋИїИізгШЮЮёЯТЗЂЕНЯр
гІЕФWorkerНкЕуЃЌжЎКѓЪеМЏWorkerЕФНсЙћЃЌОЙ§ДІРэКѓЗЕЛизюжеНсЙћИјПЭЛЇЖЫЁЃ

БОНиЭМв§гУ2020Фъ3дТЫеФўГТЛЊОќCitusЕФЪЕМљЗжЯэ
ЫФЁЂ змНс
гІЖдДѓЪ§ОнСПЁЂИпВЂЗЂЛьКЯвЕЮёЪ§ОнЗУЮЪЃЌЪ§ОнЙмРэашвЊЗжВМЪНЪ§ОнПтМмЙЙЕФгааЇжЇГХЃЌвдЯТзмНсСЫМИИіжївЊЙиМќДЪЃК
1. вЕЮёШкКЯЁЊЁЊTP/APвЕЮёздЖЏЪЖБ№ЃЌжАФмЕїЖШдЫЫуНкЕу;ЪЕЪБСїДІРэ;ЙиЯЕгыЗЧЙиЯЕЪ§ОнЗУЮЪЁЂзЊЛЛ;
2. НкЕуаЭЌЁЊЁЊЖрИіМЦЫуНкЕуаЭЌзївЕ;Ъ§ОнЖрИББО;ЭЌГЧЁЂвьЕиЖрЛю;
3. РфШШЗжРыЁЊЁЊЖЈЦкЖЈЪБЭГМЦЃЌздЖЏБъМЧРфШШЪ§ОнЃЌИљОнДцДЂЫйЖШДцДЂВЛЭЌРфШШГЬЖШЕФЪ§Он;
4. МмЙЙНтёюЁЊЁЊЮЂЗўЮёЁЂМЦЫуДцДЂЗжРы;
5. ЕЏадЩьЫѕЁЊЁЊдкЯпЩьЫѕ;здЖЏЦНКтЪ§Он;
6. жЧФмдЫЮЌЁЊЁЊздЖЏЕїгХ;здЖЏЩ§НЕМЖ;дЫааПЩЪгЛЏЃЌздЖЏИцОЏЁЃ
| 








