| Īŗľ≠Õ∆ľŲ: |
Īĺőń÷ų“™Ĺť…‹ŃňTiDBľ‹ĻĻļÕPD «»Áļő”√Go ĶŌ÷Ķń£¨TiKV «»Áļő”√Rust ĶŌ÷Ķń£¨Ō£ÕŻ∂‘ńķĶń—ßŌį”–ňýįÔ÷ķ°£
Īĺőńņī◊‘Ņ™‘ī÷–Ļķ…Á«Ý£¨”…ĽūŃķĻŻ»ŪľĢAliceĪŗľ≠°ĘÕ∆ľŲ°£ |
|
ő™ ≤√īľ”»ŽPingCAPńō£Ņ
‘ŕ360Ķń ĪļÚ£¨łļ‘ūAtlasĶńSharding(«–∆¨ľľ ű)Ķń ĶŌ÷°£‘ŕ’‚łŲĻż≥Ő÷–£¨∑ĘŌ÷÷–ľšľĢ’‚łŲ żĺ›Ņ‚∑Ĺįłīś‘ŕŃň÷Ó∂ŗŌř÷∆°£Ī»»ÁňĶ żĺ›«®“∆Ķń≥°ĺį£¨ĶĪ≤ŘőĽ–Ť“™‘ŕ‘≠”–…Ť∂®÷ĶĶńĽýī°…Ō‘Ŕ‘Ųľ”£¨’ŻłŲ≤Ŕ◊ųĻż≥Ő–Ť“™»ňĻ§Ĺť»Ž∂Ý«“ľę∆šłī‘”£¨Õ¨ Ī“≤Ī‹√‚≤ĽŃňŌĶÕ≥Õ£Ľķ°£Ī»»ÁňĶ∑÷≤ľ Ĺ ¬őŮ£¨’‚‘ŕŅÁShardingĶńĹŕĶ„…Ōľłļű≤ĽŅ…ń‹÷ß≥÷Ķń°£
ő™ ≤√ī“™◊Ų“ĽłŲ–¬Ķń żĺ›Ņ‚?
Ļō”ŕ żĺ›Ņ‚∑Ę’ĻĶńņķ ∑£¨»ÁÕľ“Ľňý ĺ‘ŕ‘Á∆ŕ£¨īůľ“÷ų“™ « Ļ”√Ķ•Ľķ żĺ›Ņ‚£¨»ÁMysqlĶ»°£’‚–© żĺ›Ņ‚Ķń–‘ń‹ÕÍ»ęŅ…“‘¬ķ◊„ĶĪ Ī“ĶőŮĶń–Ť«ů°£Ķę «◊‘2005ńÍŅ™ ľ£¨“≤ĺÕ «Ľ•Ń™ÕÝņň≥ĪĶĹņīĶń ĪļÚ£¨’‚–©‘Á∆ŕĶńĶ•Ľķ żĺ›Ņ‚ĺÕ¬ż¬żŅ™ ľŃ¶≤Ľī”–ńŃň°£ĶĪ ĪGoogle∑ĘĪŪŃňľł∆™¬Řőń£¨Őł¬ŘŃň∆šńŕ≤Ņ Ļ”√ĶńBigtable
Mapreduce°£»ĽļůĺÕ”–ŃňRedis°ĘHBase Ķ»∑«ĻōŌĶ–Õ żĺ›Ņ‚£¨’‚–© żĺ›Ņ‚ Ķľ …Ō“—ĺ≠◊„“‘¬ķ◊„ĶĪ Ī“ĶőŮĶń–Ť«ů°£
Õľ 1
÷ĪĶĹ◊ÓĹŁĶńőŚŃýńÍ£¨ő“√«∑ĘŌ÷ĺ°Ļ‹łų÷÷NoSQL≤ķ∆∑īů––∆šĶņ£¨Ķę «Mysql“ņ»Ľ «≤ĽŅ…ĽÚ»ĪĶń°£ľī Ļ «Google£¨‘ŕń≥“Ľ–©≤Ľń‹∂™ żĺ›Ķń≥°ĺį÷–£¨∂‘“Ľ–© żĺ›Ķńī¶ņŪ“ņ»Ľ–Ť“™”√ĶĹACID£¨–Ť“™”√ĶĹŅÁ–– ¬őŮ°£“ÚīňGoogle‘ŕ12ńÍĶń ĪļÚ∑ĘĪŪŃň“Ľ∆™√Żő™°∂Google
Spanner°∑Ķń¬Řőń(◊Ę£ļSpanner «‘ŕBigtable÷ģ…Ō£¨”√2PC ĶŌ÷Ńň∑÷≤ľ Ĺ ¬őŮ)°£»ĽļůĽý”ŕSpanner£¨GoogleĶńÕŇ∂”◊ŲŃňF1(◊Ę£ļF1 Ķľ …Ō «“ĽłŲSQL≤„£¨÷ß≥÷SQLĶń”Ô∑®)£¨F1”√Ńň“Ľ–©÷–ľš◊īŐ¨ņī∆ŃĪőŃňĶ•ĽķMysqlŅ…ń‹ŇŲĶĹĶń◊Ť»ŻĶń≥°ĺį°£
‘ŕPingCAP≥…ŃĘ÷ģ«į£¨ĶĪ ĪĽĻ‘ŕÕ„∂Ļľ‘ĶńPingCAPĶńīī ľ»ň£¨‘ŕĹ”ī• żĺ›Ņ‚Ķń÷–ľšľĢ∑ĹįłĻż≥Ő÷–“≤ «…Ó ‹∆šļ¶°£“Úīň‘ŕ ‹ĶĹGoogle…Ō ŲĶńŃĹ∆™¬ŘőńĶń∆Ű∑Ęļů£¨ĺÕ≥…ŃĘŃňPingCAP£¨Ņ™ ľTiDBĶń—–∑Ę°£
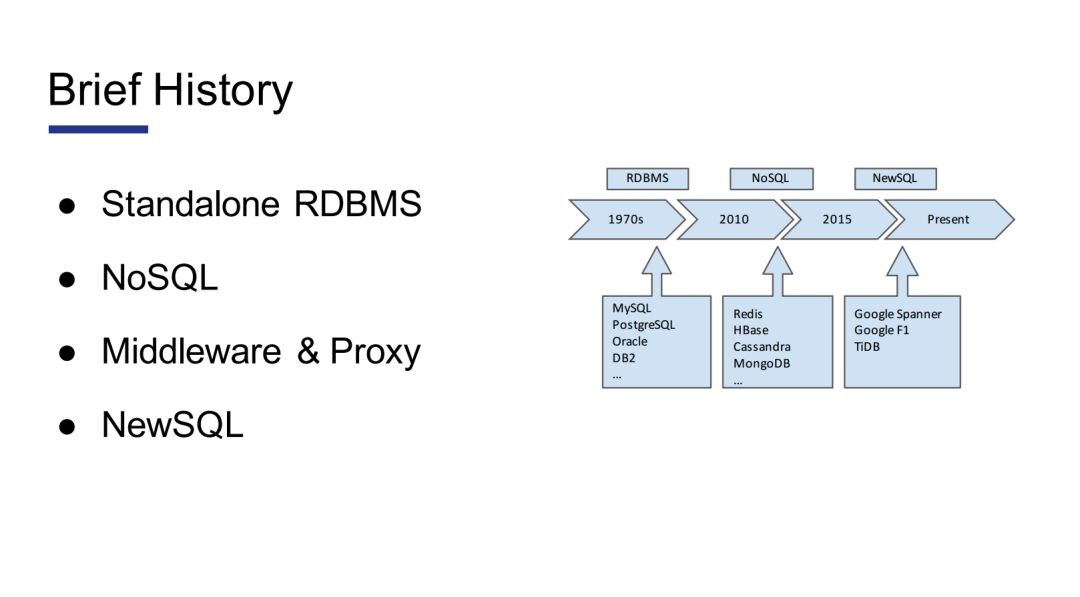
TiDBĶńľ‹ĻĻ
Õľ 2
TiDBĶńľ‹ĻĻ»ÁÕľ2ňý ĺ°£TiDB÷ų“™∑÷ő™»żłŲ≤Ņ∑÷£ļłļ‘ū∂‘Ĺ”SQL”ÔĺšĶńSQL Layer°Ęłļ‘ūĶ◊≤„īśīĘĶńTiKVļÕłļ‘ū‘™ żĺ›Ļ‹ņŪĶńPlacement
Driver(PD£¨Ō¬őń“‘īňľÚ≥∆)°£
∆š÷–TiDBļÕPD «”√Go ĶŌ÷Ķń£¨TiKV «”√Rust ĶŌ÷Ķń°£ňŁ√«ĶńĺŖŐŚĻ¶ń‹‘ŕļůőńĽŠŐŠĶĹ°£
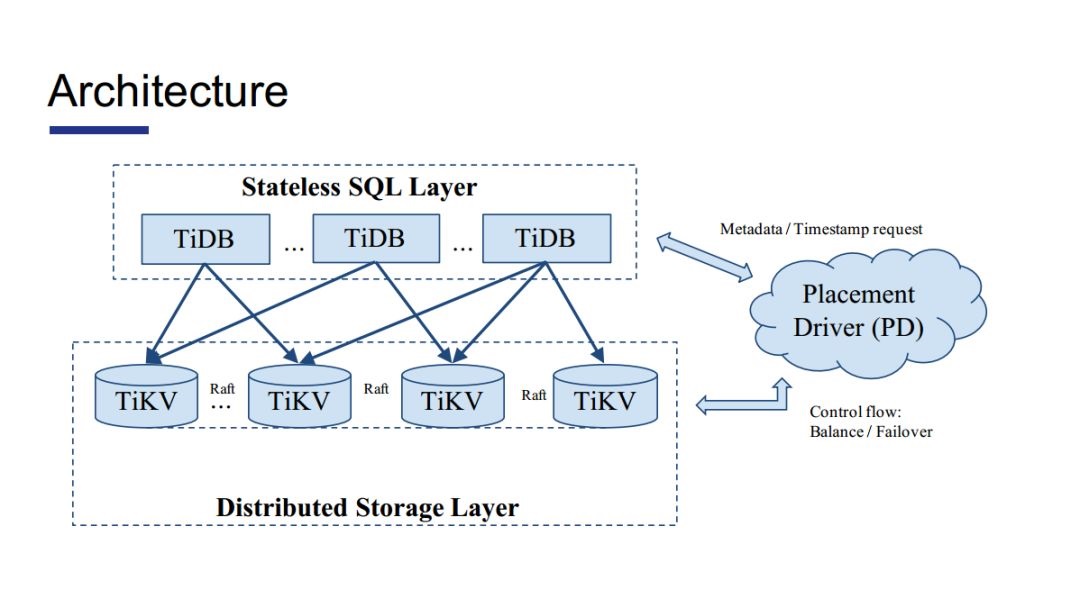
TiKVĶńłŇ Ų
Õľ 3
◊Ō» «RegionĶńłŇńÓ£¨ňŁ «÷ł“Ľ∂őѨ–ÝkeyĶńkey-value∂‘ĶńľĮļŌ°£ňý”–Ķń żĺ›∂ľ «“‘Regionő™“ĽłŲĽýĪĺĶ•őĽņī◊ť÷ĮĶų∂»Ķń°£
Region «łŖ∂»∑÷≤„Ķń°£◊ÓĶ◊≤„Ķń «RocksDB£¨’‚“Ľ≤„łļ‘ūľŁ÷Ķ∂‘ĶńīśīĘ°£÷ģ…Ō «Raft◊īŐ¨Ľķ£¨√Ņ“ĽłŲRegion∂ľ « «Õ®ĻżRaft–≠“ťņīĪ£÷§ żĺ›ĶńÕ‚≤Ņ“Ľ÷¬–‘Ķń(ő“√«Ķń…Ťľ∆Ī£÷§Ńňľī Ļ‘ŕ–ī żĺ›ĶńĻż≥Ő÷–ŚīĽķ“≤≤ĽĽŠ∂™ żĺ›)£¨◊„“‘÷ß≥÷Ĺū»ŕľ∂ĪūĶń≥°ĺį°£»Ľļů « żĺ›Ņ‚÷–Ī»ĹŌ≥£”√ĶńMVCC≤„£¨ňŁŅ…“‘ ĶŌ÷łŰņŽľ∂ĪūĶ»ļ‹∂ŗĻ¶ń‹°£‘Ŕ÷ģ…Ō£¨ĺÕ « ¬őŮ£¨’‚ņÔĶń ¬őŮ «”√2PCĶńĪš÷÷Ķń∑Ĺ Ĺ ĶŌ÷Ķń°£(Ņ…ń‹īůľ“ĺűĶ√2PC◊Ų∑÷≤ľ Ĺ ¬őŮĽŠ≥ŲŌ÷◊Ť»ŻĶń«ťŅŲ°£Ķę «ő“√«“≤÷™Ķņ£¨2PC÷ĽĽŠ‘ྣ∑Ę…ķ≥ŚÕĽ Ī◊Ť»Żī”∂Ý“ż∆ū Ī—”°£Ķę «’‚ «“Ľ÷÷ľę∂ň«ťŅŲ£¨ Ķľ Ķń“ĶőŮ≥°ĺį£¨Ī»»Á”√ĽßID£¨÷Ľ“™ő“√«Ĺękeyĺý‘»∑÷≤ľ£¨’‚÷÷≥ŚÕĽ«ťŅŲ «ľłļűļ‹…Ŕ∑Ę…ķ…ű÷ŃŅ…“‘ÕÍ»ęĪ‹√‚Ķń)°£
Ō÷‘ŕ“ĽłŲRegionĶńīů–° «96MB£¨ĶĪRegionŅž“™ŐÓ¬ķ Ī£¨RegionĽŠ∑Ę…ķ∑÷Ń—£¨’ŻłŲ∑÷Ń—ĶńĻż≥Ő∂ľ «”…PDņīĶų∂»£¨ÕÍ»ę≤Ľ–Ť“™»ňő™ł…‘§°£
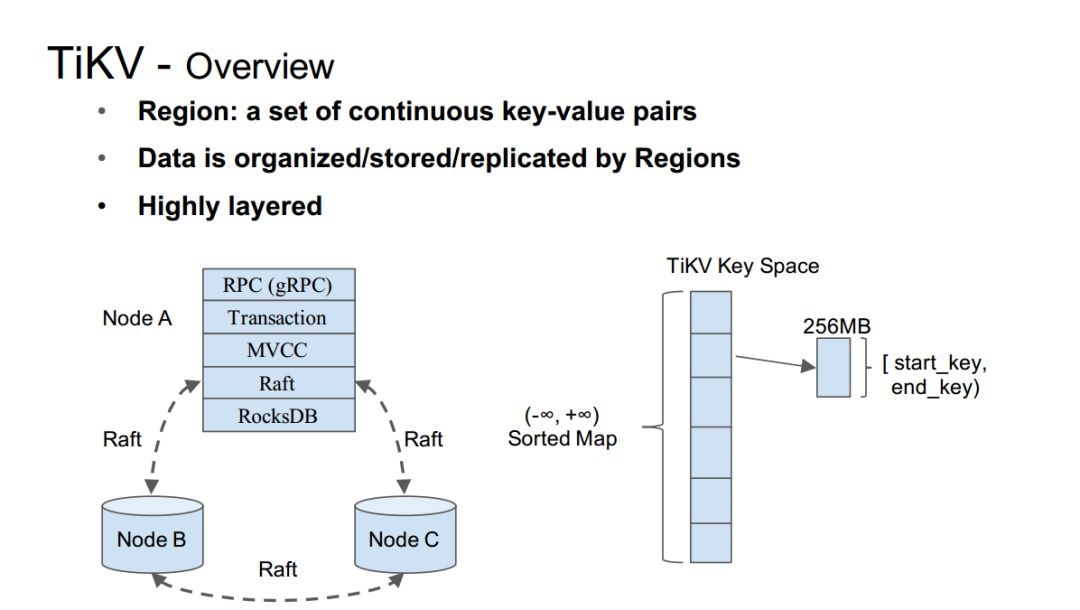
PDĶńłŇ Ų
PD÷ų“™łļ‘ū‘™ żĺ›ĶńĻ‹ņŪ°£PDĶń÷ų“™◊ų”√£ļ1°ĘĻ‹ņŪTiKV(“Ľ∂ő∑∂őßkeyĶń żĺ›)£¨Õ®ĻżPD,Ņ…“‘ĽŮ»°√Ņ“Ľ∂ő żĺ›ĺŖŐŚĶńőĽ÷√£Ľ2°ĘF1÷–ŐŠĶĹĶń ŕ Ī£¨ľī”√”ŕĪ£÷§∑÷≤ľ Ĺ żĺ›Ņ‚ĶńÕ‚≤Ņ“Ľ÷¬–‘°£
Õľ 4
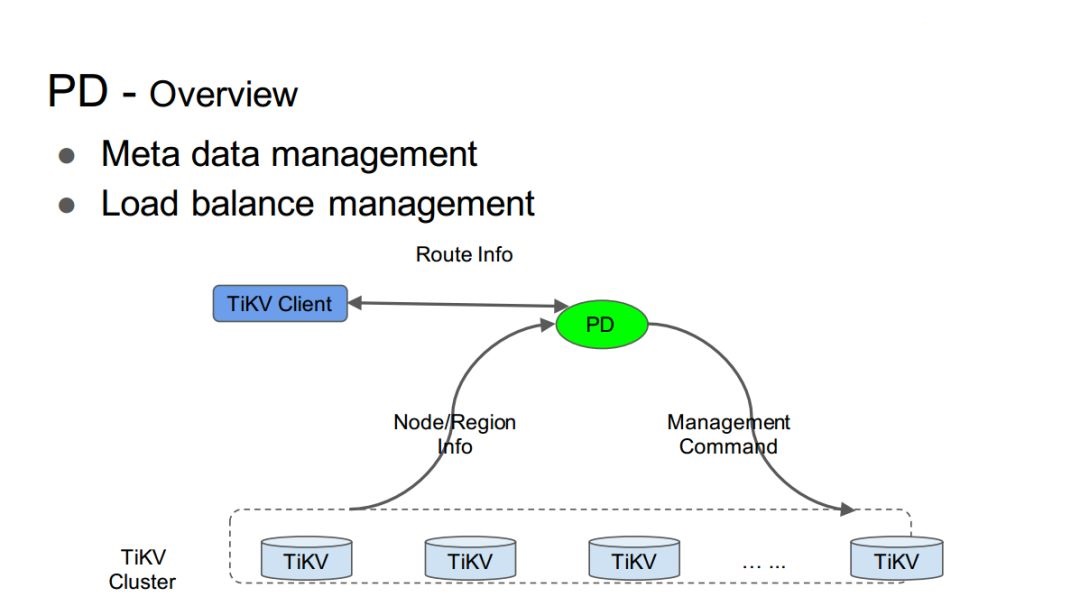
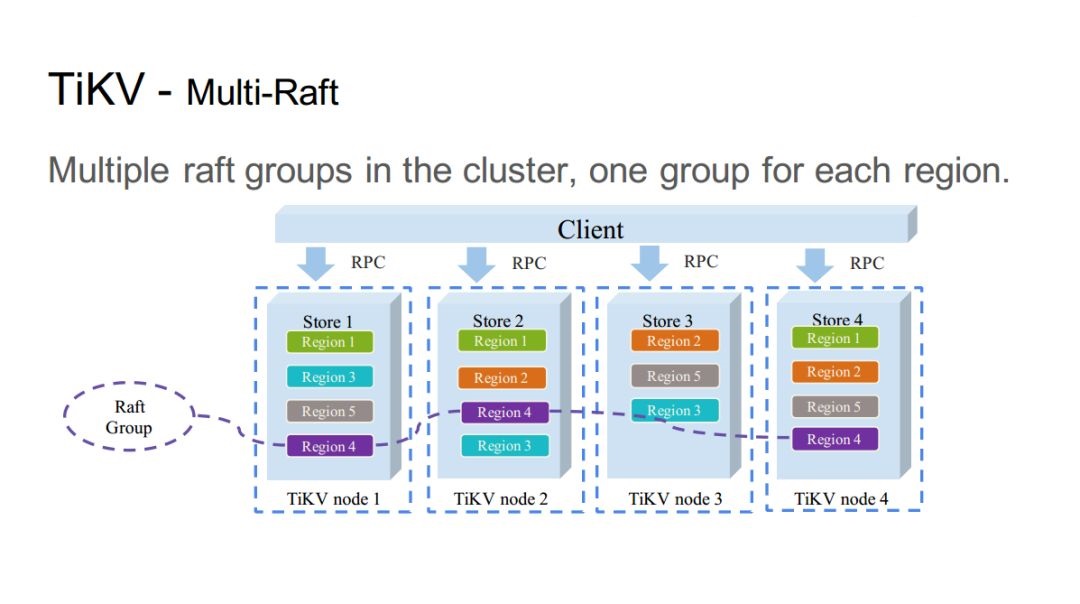
TiKV÷–ĶńMulti-Raft
»ÁÕľőŚňý ĺ£¨√Ņ“ĽłŲRegion∂ľ «“Ľ◊ťRaft◊īŐ¨Ľķ°£
ľŔ…ŤĹŕĶ„“Ľ÷–≥ŲŌ÷RegionĶń◊Ť»Ż£¨’‚÷÷…Ťľ∆ń‹ĻĽĪ£÷§∆šňŁĹŕĶ„≤Ę≤ĽĽŠ“Úīň∂Ý ‹”įŌž∑Ę…ķ◊Ť»Ż°£
Õľ 5
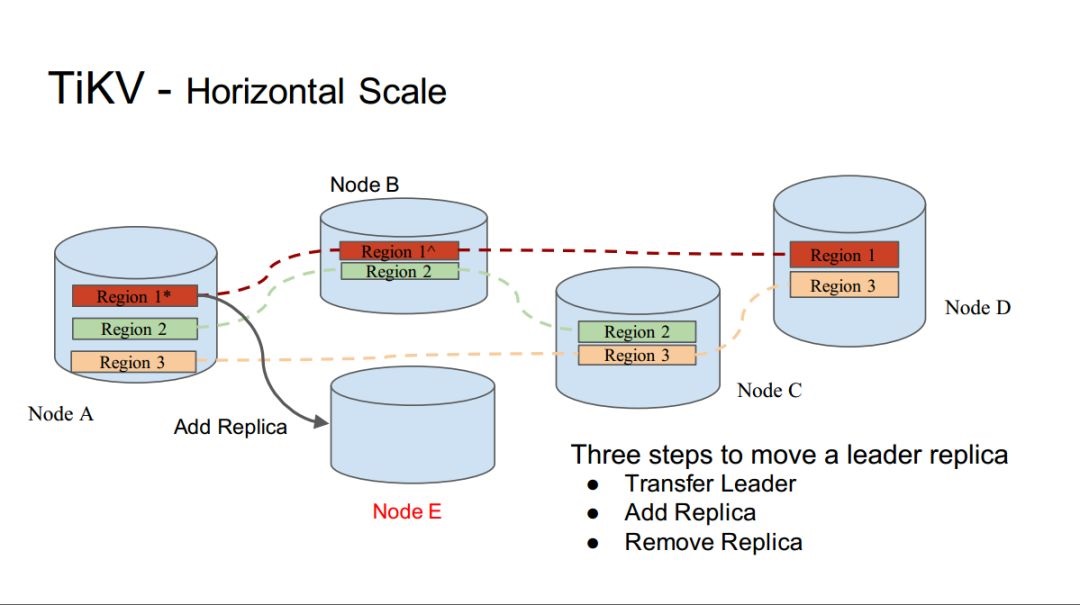
TiKVĶńňģ∆Ĺņ©»›
TiKVĶńņ©»›£¨ő®“Ľ–Ť“™»ňĻ§≤Ŕ◊ųĶńĺÕ «į—Ľķ∆ųľ”»ŽĶĹ’‚łŲľĮ»ļľīŅ…°£ £Ō¬ĶńÕͻ꼊”…PDņī ĶŌ÷’ŻłŲņ©»›ĶńŃų≥Ő£¨Õ¨ ĪPDĽĻĪ£÷§RegionĽŠĺý‘»Ķō∑÷≤ľ‘ŕłųłŲĹŕĶ„…Ō°£
Õľ 6
Ķľ …Ō£¨‘ŕ–¬ĹŕĶ„ł’ł’ľ”»ŽľĮ»ļ Ī£¨īś‘ŕ“Ľ÷÷«Ī‘ŕĶńŅ…ń‹∑Ę…ķ◊Ť»ŻĶń«ťŅŲ£¨ľī‘ŕł√ĹŕĶ„ĽĻ√Ľ”–»őļő żĺ›ľ”»Ž ĪĺÕ–Ť“™ĹÝ––"Raft"÷–ĶńÕ∂∆ĪĽ∑Ĺŕ°£ő“√«łÝ≥ŲĶńĹ‚ĺŲ∑Ĺįł «£¨‘ŕł√ĹŕĶ„ĽĻ√Ľ”–ĽŮ»°ĶĹ żĺ› Ī£¨≤Ľ»√∆š≤ő”ŽÕ∂∆ĪĶńĻż≥Ő£¨»Ľļů÷ĪĶĹ żĺ›«®“∆ÕÍ≥…ļů‘Ŕ»√∆šľ”»ŽÕ∂∆ĪĶńĻż≥Ő°£
SQL Layer
’ŻłŲ’‚“Ľ≤„∂ľ «”√Go”Ô—‘Ņ™∑ĘĶń°£
‘ŕő“Ņīņī£¨»őļőĶńľŁ÷Ķ∂‘ŌĶÕ≥£¨÷Ľ“™ «ļÕSQL”–Ļō£¨ń«√ī∆šłī‘”∂»ĽŠ“‘÷ł żľ∂…Ō…ż°£“Úő™ żĺ›Ņ‚÷–◊Óń—ĶńĺÕ «≤ť—Į”ŇĽĮ∆ų°£īůľ“”–√Ľ”–ŌŽĻż£¨ő™ ≤√īMysqlő Ő‚ļ‹∂ŗ£¨Ķę «’‚√ī∂ŗńÍ»ī“ņĺ…√Ľ”–»ň∂‘∆šĹÝ––łńĹÝļÕ”ŇĽĮ°£ Ķľ …ŌĺÕ «“Úő™’‚“ĽŅťĶń ĶŌ÷ń—∂»ŐęīůŃň°£
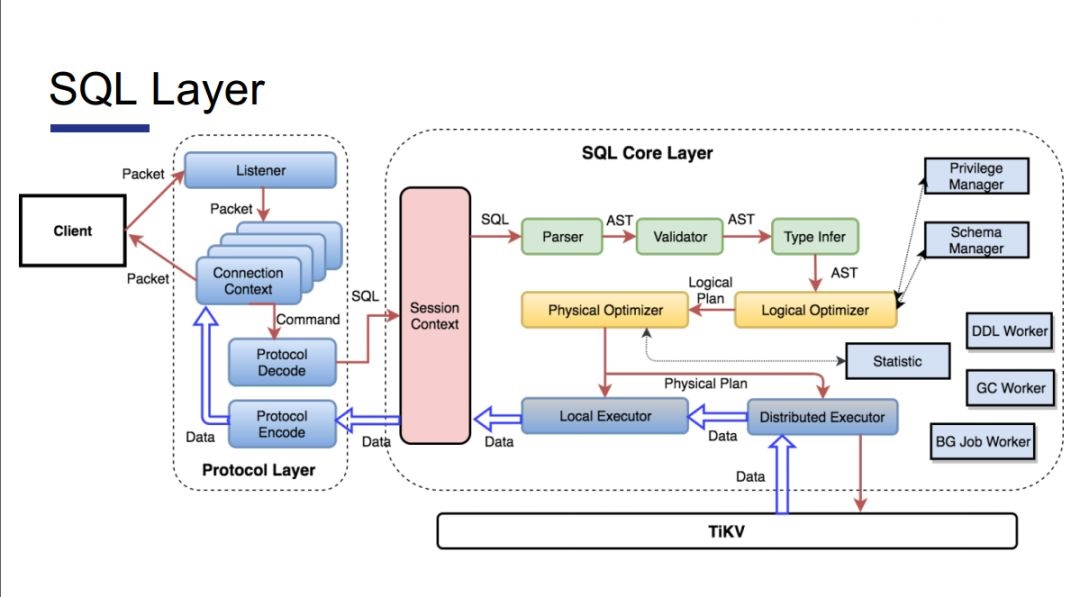
Õľ 7
SQLĪĺ…Ū Ķľ …ŌĺÕ «“Ľīģ◊÷∑Żīģ£¨ňý“‘ő“√« ◊Ō»ĽŠ”–“ĽłŲĹ‚őŲ∆ų°£”Ô∑®Ĺ‚őŲ∆ų(Parser)Ķń ĶŌ÷Īĺ…Ū≤Ľń—£¨Ķę «»īľę∆š∑ĪňŲ°£’‚÷ų“™ «“Úő™MysqlĪ»ĹŌ∆ś›‚Ķń”Ô∑®£¨Mysql‘ŕSQLĪÍ◊ľĶńĽýī°…Ō‘Ųľ”Ńňļ‹∂ŗ◊‘ľļĶń”Ô∑®£¨“Úīň’‚“Ľń£ŅťĶń ĶŌ÷ļń Īľę≥§£¨”–“ĽŃĹłŲ‘¬÷ģĺ√°£
Ķę”…”ŕParser÷Ľ◊Ų”Ô∑®Ļś‘ÚĶńľž≤ť£¨SQL”ÔĺšĪĺ…ŪĶń¬Ŗľ≠»ī√Ľ∑®Ī£÷§£¨“Úīň‘ŕParserļůĹŰłķŃňValidateń£Ņťņīľž≤ťSQL”ÔĺšĶń¬Ŗľ≠“‚“Ś°£
‘ŕValidateń£Ņťļů «“ĽłŲņŗ–ÕÕ∆∂Ō°£÷ģňý“‘”–’‚łŲń£Ņť£¨÷ų“™ «“Úő™Õ¨“ĽłŲSQL”Ôĺš‘ŕ≤ĽÕ¨Ķń…ŌŌ¬őńĽ∑ĺ≥”–≤ĽÕ¨Ķń”Ô“Ś£¨“Úīňő“√«≤ĽĶ√≤Ľłýĺ›…ŌŌ¬őńņīĹÝ––ņŗ–ÕÕ∆∂Ō°£
Ĺ”Ō¬ņī «”ŇĽĮ∆ų£¨’‚łŲń£Ņťő“√«”–“ĽłŲ◊®√ŇĶńÕŇ∂”ņīłļ‘ū°£”ŇĽĮ∆ų÷ų“™∑÷ő™¬Ŗľ≠”ŇĽĮ∆ųļÕőÔņŪ”ŇĽĮ∆ų°£¬Ŗľ≠”ŇĽĮ∆ų÷ų“™ «Ľý”ŕĻōŌĶīķ ż£¨Ī»»Á◊”≤ť—Į»•ĻōŃ™Ķ»°£»Ľļů «ļÕĶ◊≤„ĶńőÔņŪīśīĘ≤„īÚĹĽĶņĶńőÔņŪ”ŇĽĮ∆ų£¨ňų“żĶ»ĺÕ «‘ŕ’‚“ĽŅť ĶŌ÷Ķń°£
ļů√śĽĻ”–“ĽłŲ∑÷≤ľ Ĺ÷ī––∆ų£¨ňŁ÷ų“™ «ņŻ”√MPPń£–Õņī ĶŌ÷Ķń£¨’‚“≤ «∑÷≤ľ Ĺ żĺ›Ņ‚Ī»Ķ•Ľķ żĺ›Ņ‚“™ŅžĶń÷ų“™‘≠“Ú°£
ő™ ≤√ī—°”√go£Ņ
»ÁÕľ∆Ŗ Õľįňňý ĺ£¨÷ų“™ «Ľý”ŕ∑÷≤ľ Ĺ żĺ›Ņ‚ňýīÝņīĶńŐŰ’Ĺ“‘ľįGo”Ô—‘‘ŕ’‚“ĽŅťňý”Ķ”–Ķń”Ň ∆Ķ»ŅľŃŅ£¨“Ú∂Ýő“√«≤…”√Go”Ô—‘ņī ĶŌ÷TiDB°£
◊Ō» «∑÷≤ľ Ĺ żĺ›Ņ‚Ķń ĶŌ÷Īĺ…Ū»∑ Ķľę∆šłī‘”£ĽTiDBĶ◊≤„Õ®—∂…śľįīůŃŅRPCĻż≥Ő£¨»ÁĻŻ «”√÷Ó»Ác++”Ô—‘ņī ĶŌ÷ĶńĽį£¨≤Ľ «ňĶ≤Ľń‹£¨∂Ý «ŐęĻżłī‘”Ńň£¨Go”Ô—‘ļÕc++ŌŗĪ»£¨ňŁ∑‚◊įŃňĶ◊≤„Ķńļ‹∂ŗŌłĹŕ£¨∂Ý«“Go”Ô—‘Īĺ…Ū“≤“◊—ß»›“◊…Ō ÷£¨…ķ≥…–߬ łŖ£¨łŁļőŅŲő“√«’ŻłŲÕŇ∂”∂ľ «“‘Go”Ô—‘ő™÷ų£ĽÕ¨ ĪGo”Ô—‘“≤◊„“‘¬ķ◊„–‘ń‹∑Ĺ√śĶń–Ť«ů£¨”»∆š «‘ŕłŖ≤Ę∑Ę°Ę żĺ›ŃŅīůļÕOLTP≤ť—ĮĶ»≥°ĺį£¨…ű÷Ń”– Ī”√Ľß š»ŽĶń≤ĽļŌņŪłī‘”ĶńOLAP≤ť—Į“≤≤Ľ «ő Ő‚£ĽÕ‚≤Ņ“Ľ÷¬–‘£¨ľīSpanner÷–ŐŠĶĹĶń»ęĺ÷“Ľ÷¬–‘ĶńĪ£÷§£ĽSQLīÝņīĶńłī‘”∂»£Ľ“◊”ŕBugĶń∑ĘŌ÷£¨“‘ľįProfileĶ»Ļ§ĺŖ“‘ľįĻĽ”√ĶńGC–‘ń‹°£

Õľ 8

Õľ 9
Go‘ŕTiDB÷–Ķń◊ų”√

Õľ 10
”…ÕľĺŇňý ĺ£¨TiDB÷–GolangĶń”Ô—‘ ĶŌ÷’ľĶ√Ī»ņżŌŗĶĪīů£¨“‘ľįįŁņ®–Ľīů‘ŕńŕĶń138łŲŅ™‘īĻĪŌ◊’Ŗ°£
GoĶńĶų”Ň
Ķľ …Ō÷ų“™ «…śľįńŕīś∑Ĺ√śĶń°£

Õľ 11
∂‘Ōů÷ō”√

Õľ 12
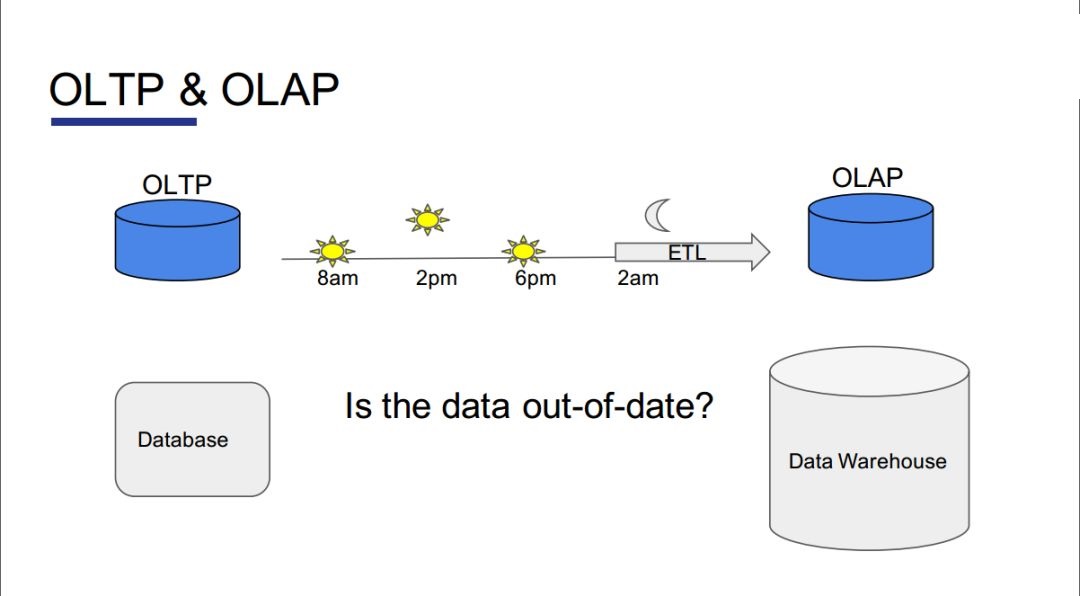
OLTPļÕOLAPĶń»ŕļŌ
Õľ 13
“Ľ–©īů–ÕĻęňĺ‘ŕ◊Ųīů żĺ›∑÷őŲ Ī£¨ĽýĪĺ «‘ŕÕŪ…Ōį— żĺ›ī” żĺ›Ņ‚Õ®ĻżETLĶľ»ŽĶĹHive°ĘODPSĶ»£¨“≤ĺÕ «ňĶ“™ĶĹĶŕ∂ĢŐž≤Ňń‹ÕÍ≥…∂‘’‚≤Ņ∑÷ żĺ›Ķń≤ť—Į°£
“Úīňő“√«ÕŇ∂”Ņľ¬«£¨ «∑ŮŅ…“‘÷ĪĹ”‘ŕOLTP…ŌŇ‹“ĽłŲīů żĺ›≤ť—ĮĶń“ż«ś£¨’‚—ýĺÕŅ…“‘Ī‹√‚…Ō ŲŐŠĶĹĶń’‚łŲĻż≥Ő£¨∂Ý«“ żĺ›Īĺ…Ū“≤Ņ…“‘Ī»ĹŌ Ķ ĪĶō≥ŲŌ÷‘ŕĪ®ĪŪ÷–°£TiSparkŌÓńŅĺÕ «ņī ĶŌ÷’‚łŲĻ¶ń‹Ķń°£
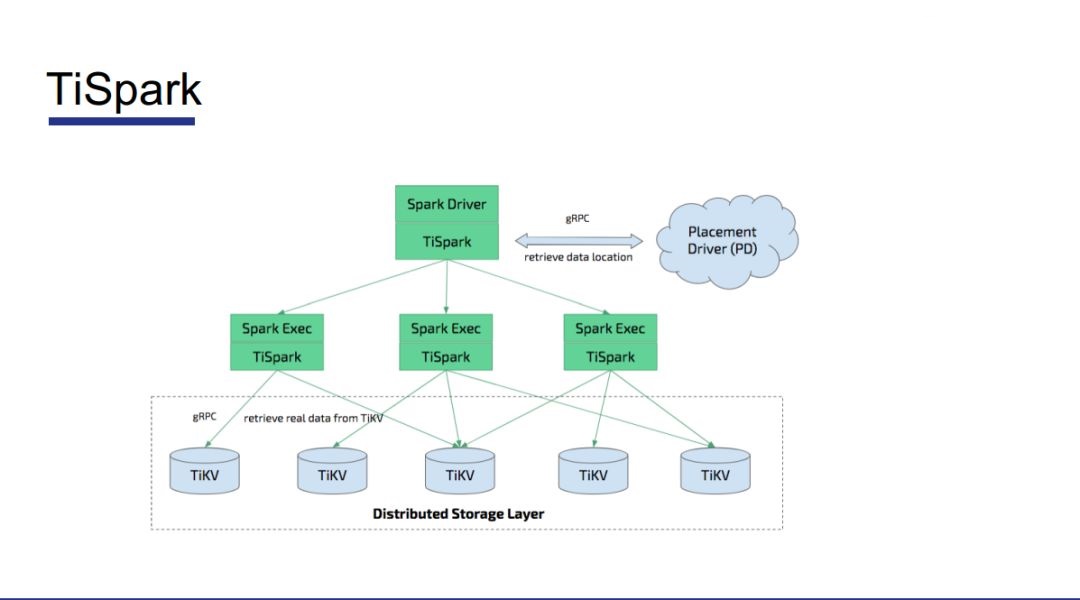
Õľ 14
TiSpark «”√ĶńSparkĶń“ż«ś£¨»Ľļů”√Scala”Ô—‘–īŃň“ĽłŲCoProcessorņī ĶŌ÷SparkŌŗĻōĶń“Ľ–©≤Ŕ◊ų°£
’‚—ý◊”ĶńĽį£¨ļÕŐŠĻ©∑÷≤ľ Ĺ ¬őŮĻ¶ń‹ĶńTiDB≤ĽÕ¨£¨TiSpark÷ų“™ «”√”ŕ–Ť“™∑÷őŲļÕŇ‹Ķ√ŅžĶń≥°ĺį°£ | 








