| Īŗľ≠Õ∆ľŲ: |
Īĺőń÷ų“™ľŘ…‹ŃňPostgreSQLĶńńŕ≤Ņľ‹ĻĻ£¨“‘ľįłųłŲ◊ťľĢ÷ģľš»ÁļőĹĽĽ•°£
Īĺőńņī◊‘ľÚ ť£¨”…ĽūŃķĻŻ»ŪľĢAnnaĪŗľ≠°ĘÕ∆ľŲ°£
|
|
“Ľ°ĘPostgreSQLĶńľ‹ĻĻ
PostgreSQLĶńőÔņŪľ‹ĻĻ∑«≥£ľÚĶ•£¨ňŁ”…Ļ≤ŌŪńŕīś°Ę“ĽŌĶŃ–ļůŐ®ĹÝ≥ŐļÕ żĺ›őńľĢ◊ť≥…°£ (»ÁŌ¬Õľ)
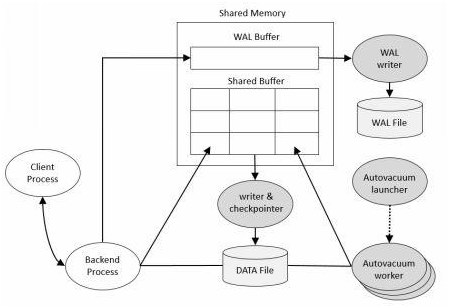
∂Ģ°ĘShared Memory
Ļ≤ŌŪńŕīś «∑ĢőŮ∆ų∑ĢőŮ∆ųő™ żĺ›Ņ‚ĽļīśļÕ ¬őŮ»’÷ĺĽļīś‘§ŃŰĶńńŕīśĽļīśŅ’ľš°£∆š÷–◊Ó÷ō“™Ķń◊ť≥…≤Ņ∑÷ «Shared
BufferļÕWAL Buffer°£
Shared Buffer
Shared BufferĶńńŅĶń «ľű…ŔīŇŇŐIO°£ő™ŃňīÔĶĹ’‚łŲńŅĶń£¨Īō–Ž¬ķ◊„“‘Ō¬Ļś‘Ú£ļ
ĶĪ–Ť“™ŅžňŔ∑√ő ∑«≥£īůĶńĽļīś Ī£®10G°Ę100GĶ»£©
»ÁĻŻ”–ļ‹∂ŗ”√ĽßÕ¨ Ī Ļ”√Ľļīś£¨–Ť“™Ĺęńŕ»›ĺ°ŃŅňű–°
∆Ķ∑Ī∑√ő ĶńīŇŇŐŅťĪō–Ž≥§∆ŕ∑Ň‘ŕĽļīś÷–
WAL Buffer
WAL Buffer «”√ņīŃŔ ĪīśīĘ żĺ›Ņ‚ĪšĽĮĶńĽļīś«Ý”Ú°£īśīĘ‘ŕWAL Buffer÷–Ķńńŕ»›ĽŠłýĺ›ŐŠ«į∂®“Śļ√Ķń ĪľšĶ„≤ő ż“™«ů–ī»ŽĶĹīŇŇŐĶńWALőńľĢ÷–°£‘ŕĪł∑›ļÕĽ÷łīĶń≥°ĺįŌ¬£¨WAL
BufferļÕWALőńľĢ «ľę∆š÷ō“™Ķń°£
»ż°ĘPostgreSQL ĹÝ≥Őņŗ–Õ
PostgreSQL”–ňń÷÷ĹÝ≥Őņŗ–Õ
Postmaster (Daemon) Process£®÷ųļůŐ®◊§ŃŰĹÝ≥Ő£©
Background Process£®ļůŐ®ĹÝ≥Ő£©
Backend Process£®ļů∂ňĹÝ≥Ő£©
Client Process£®ŅÕĽß∂ňĹÝ≥Ő£©
Postmaster Process
÷ųļůŐ®◊§ŃŰĹÝ≥Ő «PostgreSQL∆Ű∂Į ĪĶŕ“ĽłŲ∆Ű∂ĮĶńĹÝ≥Ő°£∆Ű∂Į Ī£¨ňŻĽŠ÷ī––Ľ÷łī°Ę≥ű ľĽĮĻ≤ŌŪńŕīśįģń„Ķń‘ň––ļůŐ®ĹÝ≥Ő≤Ŕ◊ų°£’ż≥£∑Ģ“Ř∆ŕľš£¨ĶĪ”–ŅÕĽß∂ň∑Ę∆ūŃīĹ”«Ž«ů Ī£¨ňŁĽĻłļ‘ūīīĹ®ļů∂ňĹÝ≥Ő°£
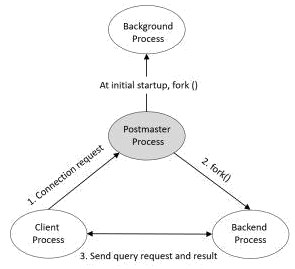
»ÁĻŻÕ®Ļżpstree√ŁŃÓ≤ťŅīĹÝ≥Ő÷ģľšĶńĻōŌĶ£¨ń„ĽŠ∑ĘŌ÷PostmasterĹÝ≥Ő «∆šňŻňý”–ĹÝ≥ŐĶńłłĹÝ≥Ő°£

Background Process
PostgreSQL≤Ŕ◊ų–Ť“™ĶńļůŐ®ĹÝ≥ŐŃ–ĪŪ»ÁŌ¬£ļ
| ĹÝ≥Ő |
◊ų”√ |
| logger |
ĹęīŪőů–ŇŌĘ–īĶĹlog»’÷ĺ÷– |
| checkpointer |
ĶĪľž≤ťĶ„≥ŲŌ÷ Ī£¨Ĺę‘ŗńŕīśŅť–īĶĹ żĺ›őńľĢ |
| writer |
÷‹∆ŕ–‘ĶńĹę‘ŗńŕīśŅť–ī»ŽőńľĢ |
| wal writer |
ĹęWALĽļīś–ī»ŽWALőńľĢ |
| Autovacuum launcher |
ĶĪ◊‘∂ĮvacuumĪĽ∆Ű”√ Ī£¨”√ņīŇ……ķautovacuumĻ§◊ųĹÝ≥Ő°£autovacuumĹÝ≥ŐĶń◊ų”√ «‘ŕ–Ť“™ Ī◊‘∂Į∂‘ŇÚ’ÕĪŪ÷ī––vacuum≤Ŕ◊ų°£ |
| archiver |
‘ŕĻťĶĶń£ ĹŌ¬ Ī£¨łī÷∆WALőńľĢĶĹŐō∂®Ķń¬∑ĺ∂Ō¬°£ |
| stats collector |
”√ņī ’ľĮ żĺ›Ņ‚Õ≥ľ∆–ŇŌĘ£¨ņż»ÁĽŠĽį÷ī–––ŇŌĘÕ≥ľ∆£® Ļ”√pg_stat_activity ”Õľ£©ļÕĪŪ Ļ”√–ŇŌĘÕ≥ľ∆£®pg_stat_all_tables ”Õľ£© |
Backend Process
◊ÓīůļůŐ®ŃīĹ” żÕ®Ļżmax_connections≤ő ż…Ť∂®£¨ń¨»Ō÷Ķő™100°£ļů∂ňĹÝ≥Ő”√”ŕī¶ņŪ«į∂ň”√Ľß«Ž«ů≤Ę∑ĶĽōĹŠĻŻ°£≤ť—Į‘ň–– Ī–Ť“™“Ľ–©ńŕīśĹŠĻĻ£¨ĺÕ «ňýőĹĶńĪĺĶōńŕīś£®local
memory£©°£ĪĺĶōńŕīś…śľįĶń÷ų“™≤ő ż”–£ļ
work_mem£ļ”√”ŕŇŇ–Ú°ĘőĽÕľňų“ż°ĘĻĢŌ£ŃīĹ”ļÕļŌ≤ĘŃīĹ”≤Ŕ◊ų°£ń¨»Ō÷Ķő™4MB°£
maintenance_work_mem£ļ”√”ŕvacuumļÕīīĹ®ňų“ż≤Ŕ◊ų°£ń¨»Ō÷Ķő™64MB°£
temp_buffers£ļ”√”ŕŃŔ ĪĪŪ°£ń¨»Ō÷Ķő™8MB°£
Client Process
ŅÕĽß∂ňĹÝ≥Ő–Ť“™ļÕļů∂ňĹÝ≥ŐŇšļŌ Ļ”√£¨ī¶ņŪ√Ņ“ĽłŲŅÕĽßŃīĹ”°£Õ®≥£«ťŅŲŌ¬£¨PostmasterĹÝ≥ŐĽŠŇ……ķ“ĽłŲ◊ŌĹŻ≥«”√ņīī¶ņŪ”√ĽßŃīĹ”°£
ňń°Ę żĺ›Ņ‚ĹŠĻĻ
ŌŽ“™ņŪĹ‚PostgreSQLĶń żĺ›Ņ‚ĹŠĻĻ£¨–Ť“™Ō»ŃňĹ‚“Ľ–©÷ō“™ĶńłŇńÓ°£
żĺ›Ņ‚ŌŗĻōłŇńÓ£ļ
PostgreSQL”…“ĽŌĶŃ– żĺ›Ņ‚◊ť≥…°£“ĽŐ◊PostgreSQL≥Ő–Ú≥∆÷ģő™“ĽłŲ żĺ›Ņ‚»ļľĮ°£
ĶĪinitdb()√ŁŃÓ÷ī––ļů£¨template0 , template1 , ļÕpostgres żĺ›Ņ‚ĪĽīīĹ®°£
template0ļÕtemplate1 żĺ›Ņ‚ «īīĹ®”√Ľß żĺ›Ņ‚ Ī Ļ”√Ķńń£įś żĺ›Ņ‚£¨ňŻ√«įŁļ¨ŌĶÕ≥‘™ żĺ›ĪŪ°£
initdb()ł’ÕÍ≥…ļů£¨template0ļÕtemplate1 żĺ›Ņ‚÷–ĶńĪŪ «“Ľ—ýĶń°£Ķę «template1 żĺ›Ņ‚Ņ…“‘łýĺ›”√Ľß–Ť“™īīĹ®∂‘Ōů°£
”√Ľß żĺ›Ņ‚ «Õ®ĻżŅň¬°template1 żĺ›Ņ‚ņīīīĹ®Ķń£Ľ
ĪŪŅ’ľšŌŗĻōłŇńÓ£ļ
initdb()ļů¬Ū…ŌīīĹ®pg_defaultļÕpg_globalĪŪŅ’ľš°£
Ĺ®ĪŪ Ī»ÁĻŻ√Ľ”–÷ł∂®Őō∂®ĶńĪŪŅ’ľš£¨ĪŪń¨»ŌĪĽīś‘ŕpg_defaultĪŪŅ’ľš÷–°£
”√”ŕĻ‹ņŪ’ŻłŲ żĺ›Ņ‚ľĮ»ļĶńĪŪń¨»ŌĪĽīśīĘ‘ŕpg_globalĪŪŅ’ľš÷–°£
pg_defaultĪŪŅ’ľšĶńőÔņŪőĽ÷√ő™$PGDATA\baseńŅ¬ľ°£
pg_globalĪŪŅ’ľšĶńőÔņŪőĽ÷√ő™$PGDATA\globalńŅ¬ľ°£
“ĽłŲĪŪŅ’ľšŅ…“‘ĪĽ∂ŗłŲ żĺ›Ņ‚Õ¨ Ī Ļ”√°£īň Ī£¨√Ņ“ĽłŲ żĺ›Ņ‚∂ľĽŠ‘ŕĪŪŅ’ľš¬∑ĺ∂Ō¬īīĹ®ő™“ĽłŲ–¬Ķń◊”¬∑ĺ∂°£
īīĹ®“ĽłŲ”√ĽßĪŪŅ’ľšĽŠ‘ŕ$PGDATA\pg_tblspcńŅ¬ľŌ¬√śīīĹ®“ĽłŲ»ŪѨŔ£¨Ń¨Ĺ”ĶĹĪŪŅ’ľš÷∆∂®ĶńńŅ¬ľőĽ÷√°£
ĪŪŌŗĻōłŇńÓ£ļ
√ŅłŲĪŪ”–»żłŲ żĺ›őńľĢ°£
“ĽłŲőńľĢ”√”ŕīśīĘ żĺ›£¨őńľĢ√Ż «ĪŪĶńOID°£
“ĽłŲőńľĢ”√”ŕĻ‹ņŪĪŪĶńŅ’Ō–Ņ’ľš£¨őńľĢ√Ż «OID_fsm°£
“ĽłŲőńľĢ”√”ŕĻ‹ņŪĪŪĶńŅť «∑ŮŅ…ľŻ£¨őńľĢ√Ż «OID_vm°£
ňų“ż√Ľ”–_vmőńľĢ£¨÷Ľ”–OIDļÕOID_fsmŃĹłŲőńľĢ
∆šňŻ–Ť“™◊Ę“‚ĶńĶō∑Ĺ
ĪŪļÕňų“żīīĹ® ĪőńľĢ√Ż «OID£¨īň ĪĶńOIDļÕpg_class.relfilenodeĶń÷Ķ «“Ľ—ýĶń°£≤ĽĻ‹‘ű—ý£¨ĶĪő“√«÷ī––÷ō–ī≤Ŕ◊ų Ī£®truncate£¨cluster£¨vacuum
full£¨reindexĶ»£©£¨ĪĽ–řłń∂‘ŌůĶńrelfilenode÷Ķ“≤ĽŠĪĽ–řłń£¨őńľĢ√Ż“≤ĽŠňś◊Ňreffilenode÷Ķ“Ľ∆ūłńĪš°£ő“√«Ņ…“‘Õ®Ļżpg_relation_filepath('<object_name>') ”Õľļ‹»›“◊Ķńľž≤ťőńľĢőĽ÷√ļÕ√Ż≥∆°£
őŚ°Ę‘ň––≤‚ ‘
initdb()ÕÍ≥…ļů£¨»ÁĻŻĶ«¬ľ żĺ›Ņ‚≤ť—Į ”Õľpg_database£¨ő“√«Ņ…“‘ŅīĶĹtemplate0
, template1ļÕ postgres żĺ›Ņ‚“—ĺ≠ĪĽīīĹ®ļ√Ńň°£
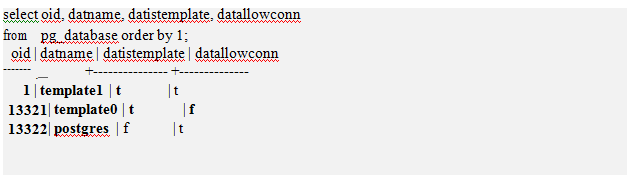
Õ®ĻżdatistemplateŃ–£¨ő“√«Ņ…“‘ŅīĶĹtemplate0ļÕtemplate1 «”√ĽßīīĹ® żĺ›Ņ‚ Ī Ļ”√Ķńń£įś żĺ›Ņ‚£¨∆šňŻĶń∂ľ≤Ľ «ń£įś żĺ›Ņ‚°£
Õ®ĻżdatlowconnŃ–£¨Ņ…“‘Ņī≥Ųł√ żĺ›Ņ‚ «∑Ů‘ –Ū∑√ő °£“Úő™template0 żĺ›Ņ‚≤Ľń‹ĪĽ∑√ő £¨ňý“‘ł√ żĺ›Ņ‚Ķńńŕ»›≤Ľń‹ĪĽ–řłń°£
…Ť÷√ŃĹłŲń£įś żĺ›Ņ‚Ķń‘≠“Ú «template0 «≥ű ľ◊īŐ¨£¨∂Ýtemplate1 żĺ›Ņ‚‘Ú «Ņ…“‘ľĮ≥…”√Ľßń≥–©–Ť«ůĶńń£įś żĺ›Ņ‚°£
postgres żĺ›Ņ‚ Ī Ļ”√ń£įśtemplate1īīĹ®Ķńń¨»Ō żĺ›Ņ‚£¨»ÁĻŻŃīĹ” Ī≤Ľ÷ł∂® żĺ›Ņ‚√Ż≥∆£¨ń¨»ŌѨŔĶĹpostgres żĺ›Ņ‚°£
żĺ›Ņ‚īśīĘ‘ŕ$PGDATA\baseńŅ¬ľŌ¬°£¬∑ĺ∂Ķń√Ż≥∆ļÕ żĺ›Ņ‚OIDĶń√Ż≥∆“Ľ÷¬°£

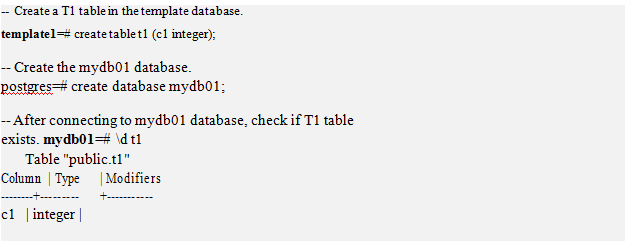
Ńý°ĘīīĹ®”√Ľß żĺ›Ņ‚
…ŌőńŐŠĻż£¨”√Ľß żĺ›Ņ‚īīĹ® «Õ®ĻżŅň¬°template1 żĺ›Ņ‚°£ő™Ńň—ť÷§’‚łŲĻś‘Ú£¨ő“√«Ō÷‘ŕtemplate1÷–īīĹ®“ĽłŲĪŪt1£¨ĹŰĹ”◊ŇīīĹ®“ĽłŲmydb01 żĺ›Ņ‚£¨ľž≤ťt1ĪŪ «∑Ů‘ŕmydb01÷–īś‘ŕ°£
pg_default tablespace
initdb()ļů£¨»ÁĻŻĶ«¬ľ żĺ›Ņ‚≤ť—Įpg_tablespace ”Õľ£¨ĽŠ∑ĘŌ÷pg_globalļÕpg_defaultĪŪŅ’ľš“—ĺ≠īīĹ®ļ√°£

pg_defaultĪŪŅ’ľšĶńőĽ÷√ő™$PGDATA\base°£√Ņ“ĽłŲ żĺ›Ņ‚∂ľ”Ķ”–“ĽłŲ“‘◊‘ľļOID√ŁŃÓĶń◊”¬∑ĺ∂°£

pg_globalĪŪŅ’ľš
pg_globalĪŪŅ’ľš”√”ŕīśīĘľĮ»ļľ∂ĪūĶń żĺ›°£
ņż»Ápg_Ņ™Õ∑ĶńĪŪ
pg_globalĪŪŅ’ľš¬∑ĺ∂ő™$PGDATA\global.
∆Ŗ°ĘīīĹ®”√ĽßĪŪŅ’ľš
pg_tablespace ”ÕľŌ‘ ĺmyts01ĪŪŅ’ľš“—ĺ≠ĪĽīīĹ®ļ√°£

$PGDATA/pg_tblspc¬∑ĺ∂Ō¬”–“ĽłŲ∑ŻļŇŃīĹ”÷łĶĹńŅĪÍńŅ¬ľ°£

Ō¬√ś∑÷ĪūѨŔĶĹpostgresļÕmydb01 żĺ›Ņ‚£¨īīĹ®ĪŪ°£

»ÁĻŻ≤ťŅī/data01¬∑ĺ∂Ō¬Ķńńŕ»›£¨ĽŠ∑ĘŌ÷…Ō√śīīĹ®ĶńŃĹłŲ żĺ›Ņ‚÷–Ķńt1ĪŪ£¨∑÷Īū‘ŕŌ¬√ś”–“ĽłŲ∂‘”¶OIDĶńőńľĢľ–īś‘ŕ°£
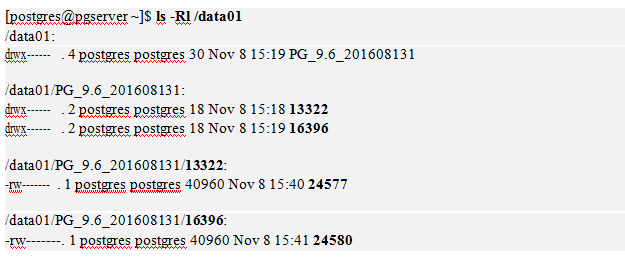
–řłńĪŪŅ’ľšőĽ÷√
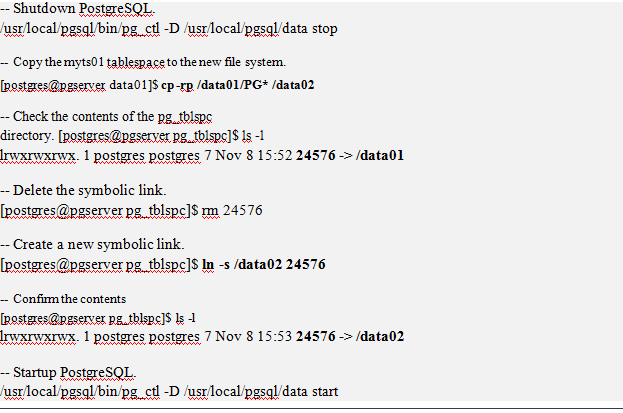
PostgreSQL‘ŕīīĹ®ĪŪŅ’ľš Ī÷ł∂®“ĽłŲŐō∂®Ķń¬∑ĺ∂°£“Úīň£¨»ÁĻŻł√Őō∂®¬∑ĺ∂“—ĺ≠¬ķŃň£¨ żĺ›ĺÕ≤Ľń‹‘ŕŌÚņÔ√śīśīĘŃň°£ő™ŃňĹ‚ĺŲł√ő Ő‚£¨ő“√«Ņ…“‘ Ļ”√īŇŇŐĻ‹ņŪ≥Ő–Úņ©’ĻŅ’ľš°£Ķę «»ÁĻŻ≤ĽŌŽ Ļ”√īŇŇŐĻ‹ņŪ≥Ő–Ú£¨ő“√«Ņ…“‘Õ®Ļżł√ĪŪĪŪŅ’ľšĶńőĽ÷√ņīĹ‚ĺŲł√ő Ő‚°£√ŁŃÓ»ÁŌ¬£ļ
įň°ĘVacuum « ≤√ī?
vacuum÷ī––»ÁŌ¬≤Ŕ◊ų£ļ
’ľĮĪŪļÕňų“żĶńÕ≥ľ∆–ŇŌĘ
’ŻņŪĪŪ
«ŚņŪĪŪļÕňų“ż÷–ĶńňņÕŲŅť
ĪĽXID∂≥ĹŠ£¨∑ņ÷ĻXIDĽō»∆
#1 ļÕ #2 « żĺ›Ņ‚Ļ‹ņŪ–Ť“™Ķń°£#3 ļÕ #4 PostgreSQL MVCC Őō–‘Ķń“™«ů°£
ĺŇ°ĘPostgreSQLļÕOracle MySQL÷ģľšĶń«ÝĪū
∂Ģ’Ŗ÷ģľš◊ÓīůĶń≤ĽÕ¨ «MVCCń£–ÕļÕĻ≤ŌŪ≥ō£®shared pool£©°£
| ÷łĪÍ |
ORACLE |
PostgreSQL |
| MVCCń£–Õ
|
UNDO |
Store
previous |
| ĶŌ÷∑Ĺ∑® |
Segment |
record
within block |
| Ļ≤ŌŪ≥ō |
exists |
it
does not exist |
MVCCń£–ÕĶń«ÝĪū
ő™Ńň‘Ųľ”≤Ę∑Ę£¨Īō–Ž◊Ů—≠°į∂Ń≤Ŕ◊ų≤Ľ◊Ť»Ż–ī≤Ŕ◊ų£¨–ī≤Ŕ◊ų≤Ľ◊Ť»Ż∂Ń≤Ŕ◊ų°ĪĶń‘≠‘Ú°£ő™Ńň ĶŌ÷’‚łŲ‘≠‘Ú£¨∂ŗįśĪĺ≤Ę∑ĘŅō÷∆£®MVCC£©ņŪ¬ŘĪĽ“ż»Ž°£Oracle Ļ”√UNDO∂ő ĶŌ÷MVCC°£∂ÝPostgreSQLīśīĘ÷ģ«įĶńľ«¬ľ‘ŕ żĺ›Ņť÷–£¨ňŁÕ®Ļż ¬őŮXIDļÕ ¬őŮĶńxmin°ĘxmaxņīŅō÷∆ ¬őŮįśĪĺ°£
Shared Pool
PostgreSQL≤ĽŐŠĻ©Ļ≤ŌŪ≥ō°£’‚∂‘”ŕ žŌ§OracleĶń”√ĽßņīňĶ”–Ķ„řŌřő°£Ļ≤ŌŪ≥ō «Oracle÷–◊ÓĽýĪĺļÕ◊Ó÷ō“™Ķń◊ťľĢ°£PostgreSQL‘ŕĹÝ≥Őľ∂ĪūŐŠĻ©SQL–ŇŌĘĶńĻ≤ŌŪń‹Ń¶£¨∂Ý≤Ľ «Ļ≤ŌŪ≥ō°£ĽĽĺšĽįňĶ£¨»ÁĻŻő“√«‘ŕÕ¨“ĽłŲĹÝ≥Ő÷–∂ŗīő÷ī––ŌŗÕ¨ĶńSQL£¨ňŁ÷ĽĽŠ”≤Ĺ‚őŲ“Ľīő°£
| 








