| БрМЭЦМі: |
БОЮФЪзЯШНщЩмСЫPostgreSQL
ЯЕЭГЕФЛљБОЬхЯЕНсЙЙЁЂPotgres(ГЃзЄНјГЬ)ЁЂPostgres(згНјГЬ)ЁЂPostgres(згНјГЬ)вдМАКѓЖЫЕФДІРэСїГЬЁЃ
БОЮФРДздcsdnЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
PostgreSQL ЯЕЭГЕФЛљБОЬхЯЕНсЙЙ PostgreSQL ЪЙгУПЭЛЇЛњ/ЗўЮёЦїЃЈC/SЃЉЕФФЃЪНЬсЙЉЗўЮёЃЌвЛИіPostgreSQLЛсЛАгЩЯТСаЯрЙиЕФНјГЬЃЈГЬађЃЉзщГЩЃК
(1)вЛИіЗўЮёЦїЖЫНјГЬЁЃИУНјГЬЙмРэЪ§ОнПтЮФМўЃЌНгЪмПЭЛЇЖЫгыЪ§ОнПтЕФСЌНгЃЌЧвДњБэПЭЛЇЖЫЖдЪ§ОнПтНјааВйзїЁЃИУНјГЬЕФГЬађУћНазі
postgresЁЃ
(2)ЧАЖЫгІгУЃЌМДашвЊНјааЪ§ОнПтВйзїЕФПЭЛЇЖЫгІгУЁЃПЭЛЇЖЫгІгУПЩФмБОЩэОЭЪЧЖржжЖрбљЕФЃКЫќУЧПЩвдЪЧвЛИізжЗћНч
УцЕФЙЄОпЃЌ вВПЩвдЪЧвЛИіЭМаЮНчУцЕФгІгУЃЌЛђепЪЧвЛИіЭЈЙ§ЗУЮЪЪ§ОнПтРДЯдЪОЭјвГЕФ web ЗўЮёЦїЃЌЛђепЪЧвЛИіЬиЪтЕФЪ§ОнПтЙмРэЙЄОпЁЃ
вЛаЉПЭЛЇЖЫгІгУЪЧКЭ PostgreSQL ЗЂВМвЛЦ№ЬсЙЉЕФЃЌЕЋОјДѓВПЗжЪЧгУЛЇПЊЗЂЕФЁЃ
КЭЕфаЭЕФПЭЛЇЖЫ/ЗўЮёЦїгІгУЃЈC/SгІгУЃЉвЛбљЃЌПЭЛЇЖЫКЭЗўЮёЦїПЩвддкВЛЭЌЕФжїЛњЩЯЁЃДЫЪБЃЌЫќУЧЭЈЙ§TCP/IPНјааЭјТчСЌНгЃЌФугІИУМЧзЁетвЛЕуЃЌвђЮЊдкПЭЛЇЛњЩЯПЩвдЗУЮЪЕФЮФМўЮДБиФмЙЛдкЪ§ОнПтЗўЮёЦїЛњЦїЩЯЗУЮЪЃЈЛђепжЛФмгУВЛЭЌЕФЮФМўУћНјааЗУЮЪЃЉЁЃ
PostgreSQL ЗўЮёЦїПЩвдДІРэРДздПЭЛЇЖЫЕФЖрИіВЂЗЂЧыЧѓЁЃЮЊСЫФметбљДІРэЃЌЫќЛсЮЊУПИіЧыЧѓЦєЖЏЃЈЁАforksЁБЃЉвЛИіаТЕФНјГЬЃЌШЛКѓЃЌПЭЛЇЖЫКЭаТЗўЮёЦїЖЫНјГЬОЭВЛдйОЙ§зюГѕЕФpostgres
НјГЬЖјжБНгЭЈаХЁЃ вђДЫЃЌ ЗўЮёЦїЖЫЕФжїНјГЬвЛжБдЫааЃЌЕШД§зХРДздПЭЛЇЖЫЕФСЌНгЃЛЖјПЭЛЇЖЫКЭЯрЙиСЊЕФЗўЮёЦїЖЫНјГЬдђдкашвЊЕФЪБКђВХЛсдЫааЁЃЃЈЕБШЛЃЌетаЉЖдгУЛЇРДЫЕЪЧЭИУїЕФЃЌдкетРяЬИетаЉжївЊЪЧЮЊСЫЫЕУїЕФЭъећадЁЃЃЉ
PostgreSQLЪ§ОнПтЪЧвЛжжМЋКУПЩвддЫаадкИїжжЦНЬЈЩЯЕФУтЗбЕФПЊЗХдДТыЕФЖдЯѓЙиЯЕЪ§ОнПтЃЌЫќЪЧвЛжжвдЙиЯЕЪ§ОнПтКЭSQLЮЊЛљДЁЃЌРЉеЙСЫГщЯѓЪ§ОнРраЭЃЌДгЖјОпБИУцЯђЖдЯѓЬиадЕФЪ§ОнПтЁЃ
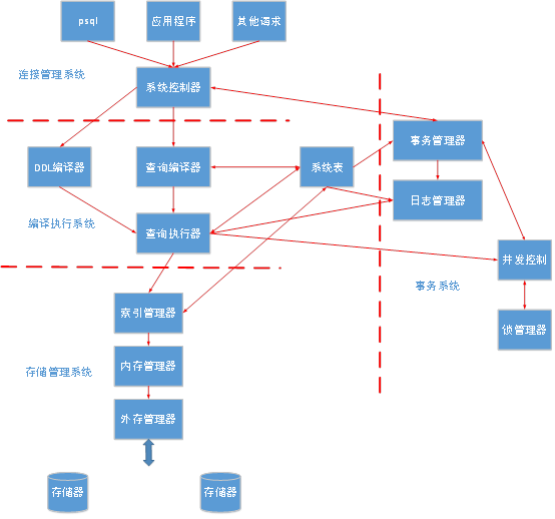
PostgreSQLЬхЯЕНсЙЙЭМЃЈзщГЩНсЙЙКЭЙиЯЕЃЉ
PostgreSQLгЩСЌНгЙмРэЯЕЭГЃЈЯЕЭГПижЦЦїЃЉЃЌБрвыжДааЯЕЭГЃЌДцДЂЙмРэЯЕЭГЃЌЪТЮёЯЕЭГЃЌЯЕЭГБэЮхДѓВПЗжзщГЩЁЃ
СЌНгЙмРэЯЕЭГНгЪмЭтВПВйзїЖдЯЕЭГЕФЧыЧѓЃЌЖдВйзїЧыЧѓНјаадЄДІРэКЭЗжЗЂЃЌЦ№ЯЕЭГТпМПижЦзїгУЃЛ
БрвыжДааЯЕЭГгЩВщбЏБрвыЦїЃЌВщбЏжДааЦїзщГЩЃЌЭъГЩВйзїЧыЧѓдкЪ§ОнПтжаЕФЗжЮіДІРэКЭзЊЛЏЙЄзїЃЌзюжеЪЕЯжЮяРэДцДЂНщжЪжаЪ§ОнЕФВйзїЃЛ
ДцДЂЙмРэЯЕЭГгЩЫїв§ЙмРэЦїЃЌФкДцЙмРэЦїЃЌЭтДцЙмРэЦїзщГЩЃЌИКд№ДцДЂКЭЙмРэЮяРэЪ§ОнЃЌЬсЙЉЖдБрвыВщбЏЯЕЭГЕФжЇГжЃЛ
ЪТЮёЯЕЭГгЩЪТЮёЙмРэЦїЃЌШежОЙмРэЦїЃЌВЂЗЂПижЦЃЌЫјЙмРэЦїзщГЩЃЌШежОЙмРэЦїКЭЪТЮёЙмРэЦїЭъГЩЖдВйзїЧыЧѓЕФЪТЮёвЛжТаджЇГжЃЌЫјЙмРэЦїКЭВЂЗЂПижЦЬсЙЉЖдВЂЗЂЗУЮЪЪ§ОнЕФвЛжТаджЇГжЃЛ
ЯЕЭГБэЪЧPostgreSQLЪ§ОнПтЕФдЊаХЯЂЙмРэжааФЃЌАќРЈЪ§ОнПтЖдЯѓаХЯЂКЭЪ§ОнПтЙмРэПижЦаХЯЂЁЃЯЕЭГБэЙмРэдЊЪ§ОнаХЯЂЃЌНЋPostgreSQLЪ§ОнПтЕФИїИіФЃПщгаЛњЕиСЌНгдквЛЦ№ЃЌаЮГЩвЛИіИпаЇЕФЪ§ОнЙмРэЯЕЭГЁЃ
ЯЕЭГБэ
дкЙиЯЕЪ§ОнПтжаЃЌЮЊСЫЪЕЯжЪ§ОнПтЯЕЭГЕФПижЦЃЌБиаыЬсЙЉЪ§ОнзжЕфЕФЙІФмЁЃЪ§ОнзжЕфВЛНіДцДЂИїжжЖдЯѓЕФУшЪіаХЯЂЃЌЖјЧвДцДЂЯЕЭГЙмРэЫљашЕФИїжжЖдЯѓЕФЯИНкаХЯЂЁЃЪ§ОнзжЕфАќКЌЪ§ОнПтЯЕЭГжаЫљгаЖдЯѓМАЦфЪєадЕФУшЪіаХЯЂЃЌЖдЯѓжЎМфЙиЯЕЕФУшЪіаХЯЂЃЌЖдЯѓЪєадЕФздШЛгябдКЌвхвдМАЪ§ОнзжЕфБфЛЏЕФРњЪЗЃЌЪ§ОнзжЕфЪЧЙиЯЕЪ§ОнПтЯЕЭГЙмРэПижЦаХЯЂЕФКЫаФЃЌдкPostgreSQLЪ§ОнПтЯЕЭГжаЯЕЭГБэАчбнзХЪ§ОнзжЕфЕФНЧЩЋЁЃ
ЯЕЭГБэЪЧPostgreSQLЪ§ОнПтДцЗХНсЙЙдЊЪ§ОнЕФЕиЗНЃЌЫћдкPostgreSQLжаБэЯжЮЊДцЗХгаЯЕЭГаХЯЂЕФЦеЭЈБэЛђепЪгЭМЃЈгУЛЇПЩвдЩОГ§ЃЌжиНЈЃЉЁЃ
ЯЕЭГБэБЃДцСЫЪ§ОнПтЕФЫљгадЊЪ§ОнЃЌЫљвдЯЕЭГдЫааЪБЖдЯЕЭГБэЕФЗУЮЪЪЧЗЧГЃЦЕЗБЕФЁЃЮЊСЫЬсИпЯЕЭГадФмЃЌдкФкДцжаНЈСЂСЫЙВЯэЕФЯЕЭГБэЃЌЪЙгУHashБэЬсИпВщбЏаЇТЪЁЃ
жївЊЯЕЭГБэЙІФм
1 pg_namespace ДцДЂУќУћПеМф
2 pg_tablespace ДцДЂПеМфаХЯЂ
3 pg_database ДцДЂЕБЧАЪ§ОнМЏДижаЪ§ОнПтЕФаХЯЂЁЃ
4 pg_class ДцДЂБэМАгыБэРрЫЦНсЙЙЕФЪ§ОнПтЖдЯѓаХЯЂЃЌАќКЌЃЌЫїв§ЃЌађСаЃЌЪгЭМЃЌИДКЯЪ§ОнРраЭЃЌTOASTБэЕШЁЃ
5 pg_type ДцДЂЪ§ОнРраЭаХЯЂЁЃ
6 pg_attribute ДцДЂБэЕФЪєадаХЯЂЁЃ
7 pg_index ДцДЂЫїв§ЕФОпЬхаХЯЂЁЃ
PostgreSQLЪ§ОнПтЯЕЭГЕФжївЊЙІФмЖММЏжагкPostgresГЬађЃЌЦфШыПкЪЧMainФЃПщжаЕФmainКЏЪ§ЃЌдкГѕЪМЛЏЪ§ОнМЏДиЃЌЦєЖЏЪ§ОнПтЗўЮёЦїЪЧЃЌЖМНЋДгетРяПЊЪМжДааЁЃMainФЃПщжївЊЕФЙЄзїЪБШЗЖЈЕБЧАЕФВйзїЯЕЭГЦНЬЈЃЌВЂОнДЫзівЛаЉЦНЬЈЯрЙиЕФЛЗОГБфСПЩшжУКЭГѕЪМЛЏЃЌШЛКѓЭЈЙ§ЖдУќСюааВЮЪ§ЕФХаЖЯЃЌНЋПижЦзЊЕНЯргІЕФФЃПщжаШЅЁЃЯТЭМЪЧmainКЏЪ§ЕФЕїгУСїГЬЁЃ
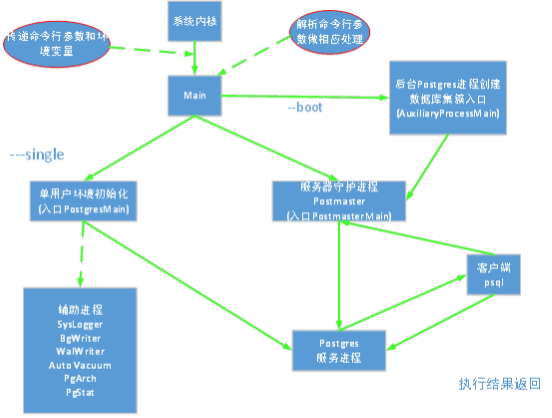
PostgreSQLЯЕЭГжїКЏЪ§mainЕФСїГЬ
PostgreSQLЪиЛЄНјГЬPostmasterЮЊгУЛЇСЌНгЧыЧѓЗжХфКѓЬЈPostgresЗўЮёНјГЬЃЌЛЙНЋЦєЖЏЯрЙиЕФКѓЬЈЗўЮёНјГЬЃКSysLogger(ЯЕЭГШежОНјГЬ),PgStat(ЭГМЦЪ§ОнЪеМЏНјГЬ),
AutoVacuum(ЯЕЭГздЖЏЧхРэНјГЬ).дкPostmasterНјШыЕНбЛЗМрЬ§жаЪБЦєЖЏШчЯТНјааЃКBgWriter(КѓЬЈаДНјГЬ),WalWriter(дЄаДЪНШежОаДНјГЬ),PgArch(дЄаДЪНШежОЙщЕЕНјГЬ)ЁЃетаЉНјГЬНЋдкКѓајЮФеТжаНщЩмЁЃ
ЯТЭМЪЧPostgreSQLЕФКѓЬЈСїГЬЭМЃК
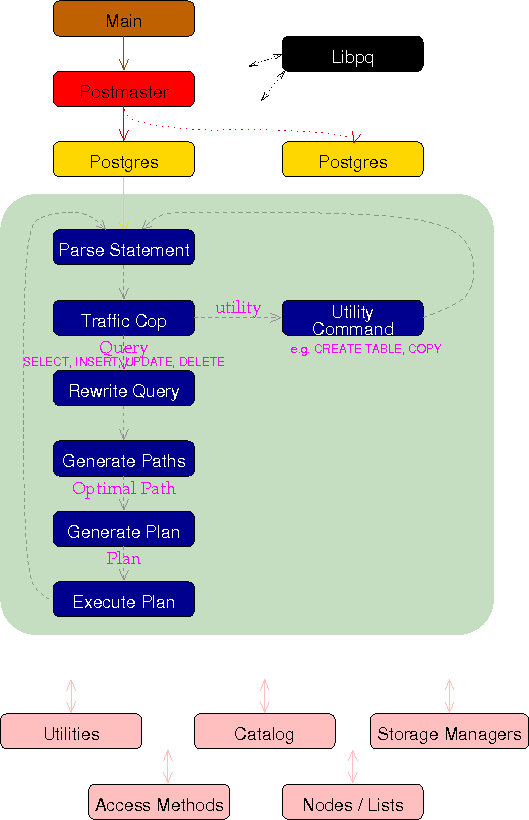
1.1 Potgres(ГЃзЄНјГЬ)
ЙмРэКѓЖЫЕФГЃзЄНјГЬЃЌвВГЦЮЊЁЏpostmasterЁЏЁЃЦфФЌШЯМрЬ§UNIXDomain SocketКЭTCP/IPЃЈWindowsЕШЃЌвЛВПЗжЕФЦНЬЈжЛМрЬ§tcp/ipЃЉЕФ5432ЖЫПкЃЌЕШД§РДздЧАЖЫЕФЕФСЌНгДІРэЁЃМрЬ§ЕФЖЫПкКХПЩвддкPostgreSQLЕФЩшжУЮФМўpostgresql.confРяУцПЩвдИФЁЃ
вЛЕЉгаЧАЖЫСЌНгЙ§РДЃЌpostgresЛсЭЈЙ§fork(2)ЩњГЩзгНјГЬЁЃУЛгаFork(2)ЕФwindowsЦНЬЈЕФЛАЃЌдђРћгУcreateProcess()ЩњГЩаТЕФНјГЬЁЃетжжЧщаЮЕФЛАЃЌКЭfork(2)ВЛЭЌЕФЪЧЃЌИИНјГЬЕФЪ§ОнВЛЛсБЛМЬГаЙ§РДЃЌЫљвдашвЊРћгУЙВЯэФкДцАбИИНјГЬЕФЪ§ОнМЬГаЙ§РДЁЃ
1.2 Postgres(згНјГЬ) згНјГЬИљОнpg_hba.confЖЈвхЕФАВШЋВпТдРДХаЖЯЪЧЗёдЪаэНјааСЌНгЃЌИљОнВпТдЃЌЛсОмОјФГаЉЬиЖЈЕФIPМАЭјТчЃЌЛђепвВПЩвджЛдЪаэФГаЉЬиЖЈЕФгУЛЇЛђепЖдФГаЉЪ§ОнПтНјааСЌНгЁЃ
PostgresЛсНгЪмЧАЖЫЙ§РДЕФВщбЏЃЌШЛКѓЖдЪ§ОнПтНјааМьЫїЃЌзюКУАбНсЙћЗЕЛиЃЌгаЪБвВЛсЖдЪ§ОнПтНјааИќаТЁЃИќаТЕФЪ§ОнЭЌЪБЛЙЛсМЧТМдкЪТЮёШежОРяУцЃЈPostgreSQLГЦЮЊWALШежОЃЉЃЌетИіжївЊЪЧЕБЭЃЕчЕФЪБКђЃЌЗўЮёЦїЕБЛњЃЌжиаТЦєЖЏЕФЪБКђНјааЛжИДДІРэЕФЪБКђЪЙгУЕФЁЃСэЭтЃЌАбШежОЙщЕЕБЃДцЦ№РДЃЌПЩдкашвЊНјааЛжИДЕФЪБКђЪЙгУЁЃдкPostgreSQL
9.0вдКѓЃЌЭЈЙ§АбWALШежОДЋЫЭЦфЫћЕФpostgreSQLЃЌПЩвдЪЕЪБЕУНјааЪ§ОнПтИДжЦЃЌетОЭЪЧЫљЮНЕФЁЎЪ§ОнПтИДжЦЁЏЙІФмЁЃ
1.3 ЦфЫћЕФНјГЬ PostgresжЎЭтЛЙгавЛаЉИЈжњЕФНјГЬЁЃетаЉНјГЬЖМЪЧгЩГЃзЄpostgresЦєЖЏЕФНјГЬЁЃ
(1) PostmasterжїНјГЬКЭЗўЮёНјГЬ ЕБPGЪ§ОнПтЦєЖЏЪБЃЌЪзЯШЛсЦєЖЏPostmasterжїНјГЬЁЃетИіНјГЬЪЧPGЪ§ОнПтЕФзмПижЦНјГЬЃЌИКд№ЦєЖЏКЭЙиБеЪ§ОнПтЪЕР§ЁЃЪЕМЪЩЯPostmasterНјГЬЪЧвЛИіжИЯђpostgresУќСюЕФСДНгЃЌШчЯТЃК
ll/opt/postgresql/bin/postmaster
/opt/postgresql/bin/postmaster-> postgres
ЕБгУЛЇКЭPGЪ§ОнПтНЈСЂСЌНгЪБЃЌвЊЯШгыPostmasterНјГЬНЈСЂСЌНгЃЌДЫЪБПЭЛЇЖЫНјГЬЛсЗЂЫЭЩэЗнбщжЄЯћЯЂИјPostmasterжїНјГЬЃЌPostmasterжїНјГЬИљОнЯћЯЂНјааЩэЗнбщжЄЃЌбщжЄЭЈЙ§КѓЃЌPostmasterжїНјГЬЛсforkГівЛИіЛсЛАЗўЮёНјГЬЮЊетИігУЛЇСЌНгЗўЮёЁЃПЩвдЭЈЙ§pg_stat_activityБэРДВщПДЗўЮёНјГЬЕФpidЃЌШчЯТЃК
test=# select pid,usename,client_addr, client_port
frompg_stat_activity;
(2) Writer process Writer processдкЪЪЕБЕФЪБМфЕуАбЙВЯэФкДцЩЯЕФЛКДцаДЭљДХХЬЁЃЭЈЙ§етИіНјГЬЃЌПЩвдЗРжЙдкМьВщЕуЕФЪБКђ(checkpoint),ДѓСПЕФЭљДХХЬаДЖјЕМжТадФмЖёЛЏЃЌЪЙЕУЗўЮёЦїПЩвдБЃГжБШНЯЮШЖЈЕФадФмЁЃBackground
writerЦ№РДвдКѓОЭвЛжБГЃзЄФкДцЃЌЕЋЪЧВЂЗЧвЛжБдкЙЄзїЃЌЫќЛсдкЙЄзївЛЖЮЪБМфКѓНјааанУпЃЌанУпЕФЪБМфМфИєЭЈЙ§postgresql.confРяУцЕФВЮЪ§bgwriter_delayЩшжУЃЌФЌШЯЪЧ200ЮЂУыЁЃ
етИіНјГЬЕФСэЭтвЛИіживЊЕФЙІФмЪЧЖЈЦкжДааМьВщЕу(checkpoint)ЁЃ
МьВщЕуЕФЪБКђЃЌЛсАбЙВЯэФкДцЩЯЕФЛКДцФкШнЭљЪ§ОнПтЮФМўаДЃЌЪЙЕУФкДцКЭЮФМўЕФзДЬЌвЛжТЁЃЭЈЙ§етбљЃЌПЩвддкЯЕЭГБРРЃЕФЪБКђПЩвдЫѕЖЬДгWALЛжИДЕФЪБМфЃЌСэЭтвВПЩвдЗРжЙWALЮоЯоЕФдіГЄЁЃ
ПЩвдЭЈЙ§postgresql.confЕФcheckpoint_segmentsЁЂcheckpoint_timeoutжИЖЈжДааМьВщЕуЕФЪБМфМфИєЁЃ
WriterНјГЬЪЧАбЙВЯэФкДцжаЕФдрвГаДЕНДХХЬЩЯЕФНјГЬЁЃЫќЕФзїгУгаСНИіЃКвЛЪЧЖЈЦкАбдрЪ§ОнДгФкДцЛКГхЧјЫЂГіЕНДХХЬжаЃЌМѕЩйВщбЏЪБЕФзшШћЃЛЖўЪЧPGдкЖЈЦкзїМьВщЕуЪБашвЊАбЫљгадрвГаДГіЕНДХХЬЃЌЭЈЙ§BgWriterдЄЯШаДГівЛаЉдрвГЃЌПЩвдМѕЩйЩшжУМьВщЕуЃЈCheckPointЃЌЪ§ОнПтЛжИДММЪѕЕФвЛжжЃЉЪБвЊНјааЕФIOВйзїЃЌЪЙЯЕЭГЕФIOИКдиЧїЯђЦНЮШЁЃBgWriterЪЧPostgreSQL8.0вдКѓаТМгЕФЬиадЃЌЫќЕФЛњжЦПЩвдЭЈЙ§postgresql.confЮФМўжавд"bgwriter_"ПЊЭЗХфжУВЮЪ§РДПижЦЃК
bgwriter_delay:
backgroud writerНјГЬСЌајСНДЮflushЪ§ОнжЎМфЕФЪБМфЕФМфИєЁЃФЌШЯжЕЪЧ200ЃЌЕЅЮЛЪЧКСУыЁЃ
bgwriter_lru_maxpagesЃК
backgroud writerНјГЬУПДЮаДЕФзюЖрЪ§ОнСПЃЌФЌШЯжЕЪЧ100ЃЌЕЅЮЛbuffersЁЃШчЙћдрЪ§ОнСПаЁгкИУЪ§жЕЪБЃЌаДВйзїШЋВПгЩbackgroud
writerНјГЬЭъГЩЃЛЗДжЎЃЌДѓгкИУжЕЪБЃЌДѓгкЕФВПЗжНЋгаserver processНјГЬЭъГЩЁЃЩшжУИУжЕЮЊ0ЪББэЪОНћгУbackgroud
writerаДНјГЬЃЌЭъШЋгаserver processРДЭъГЩЃЛХфжУЮЊ-1ЪББэЪОЫљгадрЪ§ОнЖМгЩbackgroud
writerРДЭъГЩЁЃ(етРяВЛАќРЈcheckpointВйзї)
bgwriter_lru_multiplierЃК
етИіВЮЪ§БэЪОУПДЮЭљДХХЬаДЪ§ОнПщЕФЪ§СПЃЌЕБШЛИУжЕБиаыаЁгкbgwriter_lru_maxpagesЁЃЩшжУЬЋаЁЪБашвЊаДШыЕФдрЪ§ОнСПДѓгкУПДЮаДШыЕФЪ§ОнСПЃЌетбљЪЃграшвЊаДШыДХХЬЕФЙЄзїашвЊserver
processНјГЬРДЭъГЩЃЌНЋЛсНЕЕЭадФмЃЛжЕХфжУЬЋДѓЫЕУїаДШыЕФдрЪ§ОнСПЖргкЕБЪБЫљашbufferЕФЪ§СПЃЌЗНБуСЫКѓУцдйДЮЩъЧыbufferЙЄзїЃЌЭЌЪБПЩФмГіЯжIOЕФРЫЗбЁЃИУВЮЪ§ЕФФЌШЯжЕЪЧ2.0ЁЃ
bgwriterЕФзюДѓЪ§ОнСПМЦЫуЗНЪНЃК
1000/bgwriter_delay * bgwriter_lru_maxpages*8K=зюДѓЪ§ОнСП
bgwriter_flush_afterЃК
Ъ§ОнвГДѓаЁДяЕНbgwriter_flush_afterЪБДЅЗЂBgWriterЃЌФЌШЯЪЧ512KBЁЃ
(3) WAL writer processЃЈдЄаДЪНШежОаДЃЉ WAL writer processАбЙВЯэФкДцЩЯЕФWALЛКДцдкЪЪЕБЕФЪБМфЕуЭљДХХЬаДЃЌЭЈЙ§етбљЃЌПЩвдМѕЧсКѓЖЫНјГЬдкаДздМКЕФWALЛКДцЪБЕФбЙСІЃЌЬсИпадФмЁЃСэЭтЃЌЗЧЭЌВНЬсНЛЩшЮЊtrueЕФЪБКђЃЌПЩвдБЃжЄдквЛЖЈЕФЪБМфМфИєФкЃЌАбWALЛКДцЩЯЕФФкШнаДШыWALШежОЮФМўЁЃ
дЄаДЪНШежОWALЃЈWrite Ahead LogЃЌвВГЦЮЊXlogЃЉЕФжааФЫМЯыЪЧЖдЪ§ОнЮФМўЕФаоИФБиаыЪЧжЛФмЗЂЩњдкетаЉаоИФвбОМЧТМЕНШежОжЎКѓЃЌвВОЭЪЧЯШаДШежОКѓаДЪ§ОнЃЈШежОЯШааЃЉЁЃЪЙгУетжжЛњжЦПЩвдБмУтЪ§ОнЦЕЗБЕФаДШыДХХЬЃЌПЩвдМѕЩйДХХЬI/OЁЃЪ§ОнПтдкхДЛњжиЦєКѓПЩвддЫгУетаЉWALШежОРДЛжИДЪ§ОнПтЁЃpostgresql.confЮФМўжагыWalWriterНјГЬЯрЙиЕФВЮЪ§ШчЯТЃК
wal_levelЃКПижЦwalДцДЂЕФМЖБ№ЁЃwal_levelОіЖЈгаЖрЩйаХЯЂБЛаДШыЕНWALжаЁЃ ФЌШЯжЕЪЧзюаЁЕФЃЈminimalЃЉЃЌЦфжажЛаДШыДгБРРЃЛђСЂМДЙиЛњжаЛжИДЕФЫљашаХЯЂЁЃreplica
діМг wal ЙщЕЕаХЯЂ ЭЌЪБАќРЈ жЛЖСЗўЮёЦїашвЊЕФаХЯЂЁЃЃЈ9.6 жааТдіЃЌНЋжЎЧААцБОЕФ archive
КЭ hot_standby КЯВЂЃЉ
logical жївЊгУгкlogical decoding ГЁОА
fsyncЃКИУВЮЪ§жБНгПижЦШежОЪЧЗёЯШаДШыДХХЬЁЃФЌШЯжЕЪЧONЃЈЯШаДШыЃЉЃЌБэЪОИќаТЪ§ОнаДШыДХХЬЪБЯЕЭГБиаыЕШД§WALЕФаДШыЭъГЩЁЃПЩвдХфжУИУВЮЪ§ЮЊOFFЃЌБэЪОИќаТЪ§ОнаДШыДХХЬЭъШЋВЛгУЕШД§WALЕФаДШыЭъГЩЁЃ
synchronous_commitЃКВЮЪ§ХфжУЪЧЗёЕШД§WALЭъГЩКѓВХЗЕЛиИјгУЛЇЪТЮёЕФзДЬЌаХЯЂЁЃФЌШЯжЕЪЧONЃЌБэУїБиаыЕШД§WALЭъГЩКѓВХЗЕЛиЪТЮёзДЬЌаХЯЂЃЛХфжУГЩOFFФмЙЛИќПьЕиЗДРЁЛиЪТЮёзДЬЌЁЃ
wal_sync_methodЃКWALаДШыДХХЬЕФПижЦЗНЪНЃЌФЌШЯжЕЪЧfsyncЃЌПЩбЁгУжЕАќРЈopen_datasyncЁЂfdatasyncЁЂfsync_writethroughЁЂfsyncЁЂopen_syncЁЃopen_datasyncКЭopen_syncЗжБ№БэЪОдкДђПЊWALЮФМўЪБЪЙгУO_DSYNCКЭO_SYNCБъжОЃЛfdatasyncКЭfsyncЗжБ№БэЪОдкУПДЮЬсНЛЪБЕїгУfdatasyncКЭfsyncКЏЪ§НјааЪ§ОнаДШыЃЌСНИіКЏЪ§ЖМЪЧАбВйзїЯЕЭГЕФДХХЬЛКДцаДЛиДХХЬЃЌЕЋЧАепжЛаДШыЮФМўЕФЪ§ОнВПЗжЃЌЖјКѓепЛЙЛсЭЌВНИќаТЮФМўЕФЪєадЃЛfsync_writethroughБэЪОдкУПДЮЬсНЛВЂаДЛиДХХЬЛсБЃжЄВйзїЯЕЭГДХХЬЛКДцКЭФкДцжаЕФФкШнвЛжТЁЃ
full_page_writesЃКБэУїЪЧЗёНЋећИіpageаДШыWALЁЃ
wal_buffersЃКгУгкДцЗХWALЪ§ОнЕФФкДцПеМфДѓаЁЃЌЯЕЭГФЌШЯжЕЪЧ64KЃЌИУВЮЪ§ЛЙЪмwal_writer_delayЁЂcommit_delayСНИіВЮЪ§ЕФгАЯьЁЃ
wal_writer_delayЃКWalWriterНјГЬЕФаДМфИєЪБМфЃЌФЌШЯжЕЪЧ200КСУыЃЌШчЙћЪБМфЙ§ГЄПЩФмдьГЩWALЛКГхЧјЕФФкДцВЛзуЃЛЪБМфЙ§ЖЬНЋЛсв§Ц№WALЕФВЛЖЯаДШыЃЌдіМгДХХЬI/OИКЕЃЁЃ
wal_writer_flush_afterЃК
commit_delayЃКБэЪОвЛИівбОЬсНЛЕФЪ§ОндкWALЛКГхЧјжаДцЗХЕФЪБМфЃЌФЌШЯжЕЪЧ0КСУыЃЌБэЪОВЛгУбгГйЃЛЩшжУЮЊЗЧ0жЕЪБЪТЮёжДааcommitКѓВЛЛсСЂМДаДШыWALжаЃЌЖјШдДцЗХдкWALЛКГхЧјжаЃЌЕШД§WalWriterНјГЬжмЦкадЕиаДШыДХХЬЁЃ
commit_siblingsЃКБэЪОЕБвЛИіЪТЮёЗЂГіЬсНЛЧыЧѓЪБЃЌШчЙћЪ§ОнПтжае§дкжДааЕФЪТЮёЪ§СПДѓгкcommit_siblingsжЕЃЌдђИУЪТЮёНЋЕШД§вЛЖЮЪБМфЃЈcommit_delayЕФжЕЃЉЃЛЗёдђИУЪТЮёдђжБНгаДШыWALЁЃЯЕЭГФЌШЯжЕЪЧ5ЃЌИУВЮЪ§ЛЙОіЖЈСЫcommit_delayЕФгааЇадЁЃ
wal_writer_flush_afterЃКЕБдрЪ§ОнГЌЙ§уажЕЪБЃЌЛсБЛЫЂГіЕНДХХЬЁЃ
(4) Archive process Archive processАбWALШежОзЊвЦЕНЙщЕЕШежОРяЁЃШчЙћБЃДцСЫЛљДЁБИЗнвдМАЙщЕЕШежОЃЌМДЪЙЪЕдкДХХЬЭъШЋЫ№ЛЕЕФЪБКђЃЌвВПЩвдЛиИДЪ§ОнПтЕНзюаТЕФзДЬЌЁЃ
РрЫЦгкOracleЪ§ОнПтЕФARCHЙщЕЕНјГЬЃЌВЛЭЌЕФЪЧARCHЪЧАЩredo logНјааЙщЕЕЃЌPgArchЪЧАбWALШежОНјааЙщЕЕЁЃдйЩюШыЕуЃЌWALШежОЛсБЛбЛЗЪЙгУЃЌвВОЭЪЧЫЕЃЌЙ§ШЅЕФWALШежОЛсБЛаТВњЩњЕФШежОИВИЧЃЌPgArchНјГЬОЭЪЧЮЊСЫдкИВИЧЧААбWALШежОБИЗнГіРДЁЃЙщЕЕШежОЕФзїгУЪЧЮЊСЫЪ§ОнПтФмЙЛЪЙгУШЋСПБИЗнКЭБИЗнКѓВњЩњЕФЙщЕЕШежОЃЌДгЖјШУЪ§ОнПтЛиЕНЙ§ШЅЕФШЮвЛЪБМфЕуЁЃPGДг8.XАцБОПЊЪМЬсЙЉЕФPITRЃЈPoint-In-Time-RecoveryЃЉММЪѕЃЌОЭЪЧдЫгУЕФЙщЕЕШежОЁЃ
PgArchНјГЬЭЈЙ§postgresql.confЮФМўжаЕФШчЯТВЮЪ§Нјаа
archive_modeЃК
БэЪОЪЧЗёНјааЙщЕЕВйзїЃЌПЩбЁдёЮЊoffЃЈЙиБеЃЉЁЂonЃЈЦєЖЏЃЉКЭalwaysЃЈзмЪЧПЊЦєЃЉЃЌФЌШЯжЕЮЊoffЃЈЙиБеЃЉЁЃ
archive_commandЃК
гЩЙмРэдБЩшжУЕФгУгкЙщЕЕWALШежОЕФУќСюЁЃдкгУгкЙщЕЕЕФУќСюжаЃЌдЄЖЈвхБфСПЁА%pЁБгУРДжИДњашвЊЙщЕЕЕФWALШЋТЗОЖЮФМўУћЃЌЁА%fЁББэЪОВЛДјТЗОЖЕФЮФМўУћЃЈетРяЕФТЗОЖЖМЪЧЯрЖдгкЕБЧАЙЄзїФПТМЕФТЗОЖЃЉЁЃУПИіWALЖЮЮФМўЙщЕЕЪБНЋЕїгУarchive_commandЫљжИЖЈЕФУќСюЁЃЕБЙщЕЕУќСюЗЕЛи0ЪБЃЌPostgreSQLОЭЛсШЯЮЊЮФМўБЛГЩЙІЙщЕЕЃЌШЛКѓОЭЛсЩОГ§ЛђбЛЗЪЙгУИУWALЖЮЮФМўЁЃЗёдђЃЌШчЙћЗЕЛивЛИіЗЧСужЕЃЌPostgreSQLЛсШЯЮЊЮФМўУЛгаБЛГЩЙІЙщЕЕЃЌБуЛсжмЦкадЕижиЪджБЕНГЩЙІЁЃ
archive_timeoutЃК
БэЪОЙщЕЕжмЦкЃЌдкГЌЙ§ИУВЮЪ§ЩшЖЈЕФЪБМфЪБЧПжЦЧаЛЛWALЖЮЃЌФЌШЯжЕЮЊ0ЃЈБэЪОНћгУИУЙІФмЃЉЁЃ
(5) stats collector process ЭГМЦаХЯЂЕФЪеМЏНјГЬЁЃЪеМЏКУЭГМЦБэЕФЗУЮЪДЮЪ§ЃЌДХХЬЕФЗУЮЪДЮЪ§ЕШаХЯЂЁЃЪеМЏЕНЕФаХЯЂГ§СЫФмБЛautovaccumРћгУЃЌЛЙПЩвдИјЦфЫћЪ§ОнПтЙмРэдБзїЮЊЪ§ОнПтЙмРэЕФВЮПМаХЯЂЁЃ
PgStatНјГЬЪЧPostgreSQLЪ§ОнПтЕФЭГМЦаХЯЂЪеМЏЦїЃЌгУРДЪеМЏЪ§ОнПтдЫааЦкМфЕФЭГМЦаХЯЂЃЌШчБэЕФдіЩОИФДЮЪ§ЃЌЪ§ОнПщЕФИіЪ§ЃЌЫїв§ЕФБфЛЏЕШЕШЁЃЪеМЏЭГМЦаХЯЂжївЊЪЧЮЊСЫШУгХЛЏЦїзіГіе§ШЗЕФХаЖЯЃЌбЁдёзюМбЕФжДааМЦЛЎЁЃpostgresql.confЮФМўжагыPgStatНјГЬЯрЙиЕФВЮЪ§ЃЌШчЯТЃК
track_activitiesЃКБэЪОЪЧЗёЖдЛсЛАжаЕБЧАжДааЕФУќСюПЊЦєЭГМЦаХЯЂЪеМЏЙІФмЃЌИУВЮЪ§жЛЖдГЌМЖгУЛЇКЭЛсЛАЫљгаепПЩМћЃЌФЌШЯжЕЮЊonЃЈПЊЦєЃЉЁЃ
track_countsЃКБэЪОЪЧЗёЖдЪ§ОнПтЛюЖЏПЊЦєЭГМЦаХЯЂЪеМЏЙІФмЃЌгЩгкдкAutoVacuumздЖЏЧхРэНјГЬжабЁдёЧхРэЕФЪ§ОнПтЪБЃЌашвЊЪ§ОнПтЕФЭГМЦаХЯЂЃЌвђДЫИУВЮЪ§ФЌШЯжЕЮЊonЁЃ
track_io_timingЃКЖЈЪБЕїгУЪ§ОнПщI/OЃЌФЌШЯЪЧoffЃЌвђЮЊЩшжУЮЊПЊЦєзДЬЌЛсЗДИДЕФЕїгУЪ§ОнПтЪБМфЃЌетИјЪ§ОнПтдіМгСЫКмЖрПЊЯњЁЃжЛгаГЌМЖгУЛЇПЩвдЩшжУ
track_functionsЃКБэЪОЪЧЗёПЊЦєКЏЪ§ЕФЕїгУДЮЪ§КЭЕїгУКФЪБЭГМЦЁЃ
track_activity_query_sizeЃКЩшжУгУгкИњзйУПвЛИіЛюЖЏЛсЛАЕФЕБЧАжДааУќСюЕФзжНкЪ§ЃЌФЌШЯжЕЮЊ1024ЃЌжЛФмдкЪ§ОнПтЦєЖЏКѓЩшжУЁЃ
stats_temp_directoryЃКЭГМЦаХЯЂЕФСйЪБДцДЂТЗОЖЁЃТЗОЖПЩвдЪЧЯрЖдТЗОЖЛђепОјЖдТЗОЖЃЌВЮЪ§ФЌШЯЮЊpg_stat_tmpЃЌЩшжУДЫВЮЪ§ПЩвдМѕЩйЪ§ОнПтЕФЮяРэI/OЃЌЬсИпадФмЁЃДЫВЮЪ§жЛФмдкpostgresql.confЮФМўЛђепЗўЮёЦїУќСюаажааоИФЁЃ
(6) Logger process АбpostgresqlЕФЛюЖЏзДЬЌаДЕНШежОаХЯЂЮФМўЃЈВЂЗЧЪТЮёШежОЃЉЃЌдкжИЖЈЕФЪБМфМфИєРяУцЃЌЖдШежОЮФМўНјааrotate.
(7) AutovacuumЃЈздЖЏЧхРэЃЉЦєЖЏНјГЬ autovacuum launcher processЪЧвРРЕгкpostmasterМфНгЦєЖЏvacuumНјГЬЁЃЖјЦфздЩэЪЧВЛжБНгЦєЖЏздЖЏvacuumНјГЬЕФЁЃЭЈЙ§етбљПЩвдЬсИпЯЕЭГЕФПЩППадЁЃ
дкPGЪ§ОнПтжаЃЌЖдЪ§ОнНјааUPDATEЛђепDELETEВйзїКѓЃЌЪ§ОнПтВЛЛсСЂМДЩОГ§ОЩАцБОЕФЪ§ОнЃЌЖјЪЧБъМЧЮЊЩОГ§зДЬЌЁЃетЪЧвђЮЊPGЪ§ОнПтОпгаЖрАцБОЕФЛњжЦЃЌШчЙћетаЉОЩАцБОЕФЪ§Оне§дкБЛСэЭтЕФЪТЮёДђПЊЃЌФЧУДднЪББЃСєЫћУЧЪЧКмгаБивЊЕФЁЃЕБЪТЮёЬсНЛКѓЃЌОЩАцБОЕФЪ§ОнвбОУЛгаМлжЕСЫЃЌЪ§ОнПташвЊЧхРэРЌЛјЪ§ОнЬкГіПеМфЃЌЖјЧхРэЙЄзїОЭЪЧAutoVacuumНјГЬНјааЕФЁЃpostgresql.confЮФМўжагыAutoVacuumНјГЬЯрЙиЕФВЮЪ§гаЃК
autovacuumЃКЪЧЗёЦєЖЏЯЕЭГздЖЏЧхРэЙІФмЃЌФЌШЯжЕЮЊonЁЃ
log_autovacuum_min_durationЃКетИіВЮЪ§гУРДМЧТМ autovacuum ЕФжДааЪБМфЃЌЕБ
autovaccum ЕФжДааЪБМфГЌЙ§ log_autovacuum_min_durationВЮЪ§ЩшжУЪБЃЌдђautovacuumаХЯЂМЧТМЕНШежОРяЃЌФЌШЯЮЊ
"-1", БэЪОВЛМЧТМЁЃ
autovacuum_max_workersЃКЩшжУЯЕЭГздЖЏЧхРэЙЄзїНјГЬЕФзюДѓЪ§СПЁЃ
autovacuum_naptimeЃКЩшжУСНДЮЯЕЭГздЖЏЧхРэВйзїжЎМфЕФМфИєЪБМфЁЃ
autovacuum_vacuum_thresholdКЭautovacuum_analyze_thresholdЃКЩшжУЕББэЩЯБЛИќаТЕФдЊзщЪ§ЕФуажЕГЌЙ§етаЉуажЕЪБЗжБ№ашвЊжДааvacuumКЭanalyzeЁЃ
autovacuum_vacuum_scale_factorКЭautovacuum_analyze_scale_factorЃКЩшжУБэДѓаЁЕФЫѕЗХЯЕЪ§ЁЃ
autovacuum_freeze_max_ageЃКЩшжУашвЊЧПжЦЖдЪ§ОнПтНјааЧхРэЕФXIDЩЯЯожЕЁЃ
autovacuum_vacuum_cost_delayЃКЕБautovacuumНјГЬМДНЋжДааЪБЃЌЖд
vacuum жДаа cost НјааЦРЙРЃЌШчЙћГЌЙ§ autovacuum_vacuum_cost_limitЩшжУжЕЪБЃЌдђбгГйЃЌетИібгГйЕФЪБМфМДЮЊ
autovacuum_vacuum_cost_delayЁЃШчЙћжЕЮЊ -1, БэЪОЪЙгУ vacuum_cost_delay
жЕЃЌФЌШЯжЕЮЊ 20 msЁЃ
autovacuum_vacuum_cost_limitЃКетИіжЕЮЊautovacuum НјГЬЕФЦРЙРЗЇжЕ,
ФЌШЯЮЊ -1, БэЪОЪЙгУ "vacuum_cost_limit " жЕЃЌШчЙћдкжДааautovacuum
НјГЬЦкМфЦРЙРЕФcost ГЌЙ§autovacuum_vacuum_cost_limit, дђ autovacuum
НјГЬдђЛсанУпЁЃ
(8) здЖЏvacuumНјГЬ autovacuum worker processНјГЬЪЕМЪжДааvacuumЕФШЮЮёЁЃгаЪБКђЛсЭЌЪБЦєЖЏЖрИіvacuumНјГЬЁЃ
(9) wal sender / wal receiver wal sender НјГЬКЭwal receiverНјГЬЪЧЪЕЯжpostgresqlИДжЦ(streaming
replication)ЕФНјГЬЁЃWal senderНјГЬЭЈЙ§ЭјТчДЋЫЭWALШежОЃЌЖјЦфЫћPostgreSQLЪЕР§ЕФwal
receiverНјГЬдђНгЪеЯргІЕФШежОЁЃWal receiverНјГЬЕФЫожїPostgreSQLЃЈвВГЦЮЊStandbyЃЉНгЪмЕНWALШежОКѓЃЌдкздЩэЕФЪ§ОнПтЩЯЛЙдЃЌЩњГЩвЛИіКЭЗЂЫЭЖЫЕФPostgreSQL(вВГЦЮЊMaster)ЭъШЋвЛбљЕФЪ§ОнПтЁЃ
(10) CheckPointЃЈМьВщЕуЃЉНјГЬ МьВщЕуЪЧЯЕЭГЩшжУЕФЪТЮёађСаЕуЃЌЩшжУМьВщЕуБЃжЄМьВщЕуЧАЕФШежОаХЯЂЫЂЕНДХХЬжаЁЃpostgresql.confЮФМўжагыжЎЯрЙиЕФВЮЪ§гаЃК
1.4 КѓЖЫЕФДІРэСїГЬ
ЯТУцПДПДЪ§ОнПтв§ЧцpostgresзгНјГЬЕФДІРэИХвЊЁЃЮЊСЫМђЕЅЦ№МћЯТУцЕФЫЕУїжаЃЌАбbackendprocessМђГЦЮЊbackendЁЃBackendЕФmainКЏЪ§ЪЧPostgresMain
(tcop/postgres.c)ЁЃ
НгЪеЧАЖЫЗЂЫЭЙ§РДЕФВщбЏ(SQLЮФ) SQLЮФЪЧЕЅДПЕФЮФзжЃЌЕчФдЪЧШЯЪЖВЛСЫЕФЃЌЫљвдвЊзЊЛЛГЩБШНЯШнвзДІРэЕФФкВПаЮЪНЙЙЮФЪїparser tree,етИіДІРэЕФГЦЮЊЙЙЮФНтЮіЁЃЙЙЮФНтЮіЕФФЃПщГЦЮЊparser.етИіНзЖЮжЛФмЙЛЪЙгУЮФзжзжУцЩЯЕУРДЕФаХЯЂЃЌЫљвджЛвЊУЛгяЗЈДэЮѓжЎРрЕФДэЮѓЃЌМДЪЙЪЧselectВЛДцдкЕФБэвВВЛЛсБЈДэЁЃетИіНзЖЮЕФЙЙЮФЪїБЛГЦЮЊraw
parse tree. ЙЙЮФДІРэЕФШыПкдкraw_parser (parser/parser.c)ЁЃ ЙЙЮФЪїНтЮіЭъвдКѓЃЌЛсзЊЛЛЮЊВщбЏЪї(Query tree)ЁЃетИіЪБКђЃЌЛсЗУЮЪЪ§ОнПтЃЌМьВщБэЪЧЗёДцдкЃЌШчЙћДцдкЕФЛАЃЌдђАбБэУћзЊЛЛЮЊOIDЁЃетИіДІРэГЦЮЊЗжЮіДІРэ(Analyze),
НјааЗжЮіДІРэЕФФЃПщЪЧanalyzerЁЃ СэЭтЃЌPostgreSQLЕФДњТыРяУцЬсЕНЙЙЮФЪїparser
treeЕФЪБКђЃЌИќЖрЕФЪБКђЪЧжИВщбЏЪїQuery treeЁЃЗжЮіДІРэЕФФЃПщЕФШыПкдкparse_analyze
(parser/analyze.c) PostgreSQLЛЙЭЈЙ§ВщбЏгяОфЕФжиаДЪЕЯжЪгЭМ(view)КЭЙцдђ(rule), ЫљвдашвЊЕФЪБКђЃЌдкетИіНзЖЮЛсЖдВщбЏгяОфНјаажиаДЁЃетИіДІРэГЦЮЊжиаД(rewrite)ЃЌжиаДЕФШыПкдкQueryRewrite
(rewrite/rewriteHandler.c)ЁЃ ЭЈЙ§НтЮіВщбЏЪїЃЌПЩвдЪЕМЪЩњГЩМЦЛЎЪїЁЃЩњГЩВщбЏЪїЕФДІРэГЦЮЊЁЎжДааМЦЛЎДІРэЁЏЃЌзюЙиМќЪЧвЊЩњГЩЙРМЦФмдкзюЖЬЕФЪБМфФкЭъГЩЕФМЦЛЎЪї(plan
tree)ЁЃетИіВНжшГЦЮЊЁЏВщбЏгХЛЏЁЏ(ВЛНаquery optimize, ЖјЪЧoptimize),
ЖјЭъГЩетИіДІРэЕФФЃПщГЦЮЊВщбЏгХЛЏЦї(ВЛНаquery optimizer,ЖјЪЧoptimizer, ЛђепГЦЮЊplanner)ЁЃжДааМЦЛЎДІРэЕФШыПкдкstandard_planner
(optimizer/plan/planner.c)ЁЃ АДеежДааМЦЛЎРяУцЕФВНжшПЩвдЭъГЩВщбЏвЊДяЕНЕФФПЕФЁЃдЫаажДааМЦЛЎЪїРяУцВНжшЕФДІРэГЦЮЊжДааДІРэЁЎexecuteЁЏ,
ЭъГЩетИіДІРэЕФФЃПщГЦЮЊжДааЦїЁЎExecutorЁЏ, жДааЦїЕФШыПкЕижЗЮЊЃЌExecutorRun (executor/execMain.c) жДааНсЙћЗЕЛиИјЧАЖЫЁЃ ЗЕЛиЕНВНжшвЛжиИДжДааЁЃ
| 







