| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫЗЧЙиЯЕаЭЪ§ОнПтredisЕФЪЙгУГЁОА,redisКЭmemcachedЕФБШНЯЃЌвдМАredisЕФШеГЃВйзїЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздМђЪщЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
redisНЬГЬЃК
ИХЪі
redisЪЧвЛжжnosqlЪ§ОнПт,ЫћЕФЪ§ОнЪЧБЃДцдкФкДцжаЃЌЭЌЪБredisПЩвдЖЈЪБАбФкДцЪ§ОнЭЌВНЕНДХХЬЃЌМДПЩвдНЋЪ§ОнГжОУЛЏЃЌВЂЧвЫћБШmemcachedжЇГжИќЖрЕФЪ§ОнНсЙЙ(string,listСаБэ[ЖгСаКЭеЛ],set[МЏКЯ],sorted
set[гаађМЏКЯ],hash(hashБэ))ЁЃ
redisЪЙгУГЁОАЃК
ЕЧТМЛсЛАДцДЂЃКДцДЂдкredisжаЃЌгыmemcachedЯрБШЃЌЪ§ОнВЛЛсЖЊЪЇЁЃ
ХХааАц/МЦЪ§ЦїЃКБШШчвЛаЉауГЁРрЕФЯюФПЃЌОГЃЛсгавЛаЉЧАЖрЩйУћЕФжїВЅХХУћЁЃЛЙгавЛаЉЮФеТдФЖССПЕФММЪѕЃЌЛђепаТРЫЮЂВЉЕФЕудоЪ§ЕШЁЃ
зїЮЊЯћЯЂЖгСаЃКБШШчceleryОЭЪЧЪЙгУredisзїЮЊжаМфШЫЁЃ
ЕБЧАдкЯпШЫЪ§ЃКЛЙЪЧжЎЧАЕФауГЁР§згЃЌЛсЯдЪОЕБЧАЯЕЭГгаЖрЩйдкЯпШЫЪ§ЁЃ
вЛаЉГЃгУЕФЪ§ОнЛКДцЃКБШШчЮвУЧЕФBBSТлЬГЃЌАхПщВЛЛсОГЃБфЛЏЕФЃЌЕЋЪЧУПДЮЗУЮЪЪзвГЖМвЊДгmysqlжаЛёШЁЃЌПЩвддкredisжаЛКДцЦ№РДЃЌВЛгУУПДЮЧыЧѓЪ§ОнПтЁЃ
АбЧА200ЦЊЮФеТЛКДцЛђепЦРТлЛКДцЃКвЛАугУЛЇфЏРРЭјеОЃЌжЛЛсфЏРРЧАУцвЛВПЗжЮФеТЛђепЦРТлЃЌФЧУДПЩвдАбЧАУц200ЦЊЮФеТКЭЖдгІЕФЦРТлЛКДцЦ№РДЁЃгУЛЇЗУЮЪГЌЙ§ЕФЃЌОЭЗУЮЪЪ§ОнПтЃЌВЂЧввдКѓЮФеТГЌЙ§200ЦЊЃЌдђАбжЎЧАЕФЮФеТЩОГ§ЁЃ
КУгбЙиЯЕЃКЮЂВЉЕФКУгбЙиЯЕЪЙгУredisЪЕЯжЁЃ
ЗЂВМКЭЖЉдФЙІФмЃКПЩвдгУРДзіСФЬьШэМўЁЃ
redisКЭmemcachedЕФБШНЯЃК
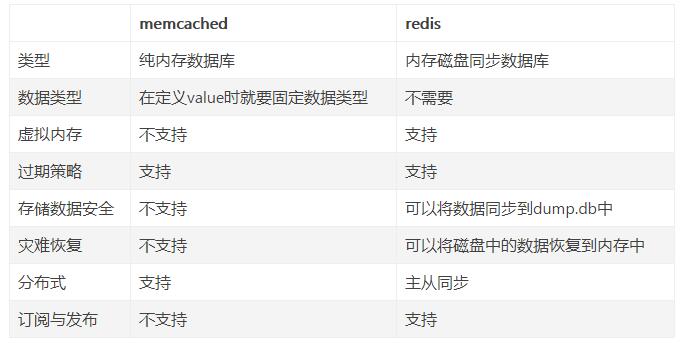
redisШеГЃВйзї
1.АВзАЃКcentos7
wget http://download.redis.io/releases/redis-5.0.0.tar.gz
tar -zxvf redis-5.0.0.tar.gz
yum install gcc
yum install gcc-c++
make
cp src/redis-server /usr/bin/
cp src/redis-cli /usr/bin/ |
2.ЦєЖЏredisЪ§ОнПтЗўЮё
ЦєЖЏУќСю:
redis-server redis.conf
3.ЭЃжЙredisЪ§ОнПтЗўЮё
service redis stop
4.СЌНгЩЯredis-serverЃК
redis-cli -p 6379 -h 127.0.0.1
5.ЬэМг:
set key value
ШчЃК
set username balabala
НЋзжЗћДЎжЕvalueЙиСЊЕНkeyЁЃШчЙћkeyвбОГжгаЦфЫћжЕЃЌsetУќСюОЭИВаДОЩжЕЃЌЮоЪгЦфРраЭЁЃВЂЧвФЌШЯЕФЙ§ЦкЪБМфЪЧгРОУЃЌМДгРдЖВЛЛсЙ§ЦкЁЃ
6.ЩОГ§:
del key
ШчЃК
del username
7.ЩшжУЙ§ЦкЪБМф
expire key timeout(ЕЅЮЛЮЊУы)
вВПЩвддкЩшжУжЕЕФЪБКђЃЌвЛЭЌжИЖЈЙ§ЦкЪБМфЃК
set key value EX timeout
ЛђЃК
setex key timeout value
8.ВщПДЙ§ЦкЪБМф
ttl key
ШчЃК
ttl username
9.ВщПДЕБЧАredisЫљгаЕФkey
keys *
10.СаБэВйзї
дкСаБэзѓБпЬэМгдЊЫиЃК
lpush key value
НЋжЕvalueВхШыЕНСаБэkeyЕФБэЭЗЁЃШчЙћkeyВЛДцдкЃЌвЛИіПеСаБэЛсБЛДДНЈВЂжДааlpushВйзїЁЃЕБkeyДцдкЕЋВЛЪЧСаБэРраЭЪБЃЌНЋЗЕЛивЛИіДэЮѓЁЃ
дкСаБэгвБпЬэМгдЊЫиЃК
rpush key value
НЋжЕvalueВхШыЕНСаБэkeyЕФБэЮВЁЃШчЙћkeyВЛДцдкЃЌвЛИіПеСаБэЛсБЛДДНЈВЂжДааRPUSHВйзїЁЃЕБkeyДцдкЕЋВЛЪЧСаБэРраЭЪБЃЌЗЕЛивЛИіДэЮѓЁЃ
ВщПДСаБэжаЕФдЊЫиЃК
lrange key start stop
ЗЕЛиСаБэkeyжажИЖЈЧјМфФкЕФдЊЫиЃЌЧјМфвдЦЋвЦСПstartКЭstopжИЖЈ,ШчЙћвЊзѓБпЕФЕквЛИіЕНзюКѓЕФвЛИіlrange
key 0 -1ЁЃ
вЦГ§СаБэжаЕФдЊЫиЃК
вЦç€ЗЕЛиСаБэkeyЕФЭЗдЊЫиЃК
lpop key
вЦç€ЗЕЛиСаБэЕФЮВдЊЫиЃК
rpop key
жИЖЈЗЕЛиЕкМИИідЊЫиЃК
lindex key index
НЋЗЕЛиkeyетИіСаБэжаЃЌЫїв§ЮЊindexЕФетИідЊЫиЁЃ
ЛёШЁСаБэжаЕФдЊЫиИіЪ§ЃК
llen key
ШчЃК
llen languages
ЩОГ§жИЖЈЕФдЊЫиЃК
lrem key count value
ШчЃК
lrem languages 0 php
ИљОнВЮЪ§ count ЕФжЕЃЌвЦГ§СаБэжагыВЮЪ§ value ЯрЕШЕФдЊЫиЁЃcountЕФжЕПЩвдЪЧвдЯТМИжжЃК
count > 0ЃКДгБэЭЗПЊЪМЯђБэЮВЫбЫїЃЌвЦГ§гыvalueЯрЕШЕФдЊЫиЃЌЪ§СПЮЊcountЁЃ
count < 0ЃКДгБэЮВПЊЪМЯђБэЭЗЫбЫїЃЌвЦГ§гы valueЯрЕШЕФдЊЫиЃЌЪ§СПЮЊcountЕФОјЖджЕЁЃ
count = 0ЃКвЦГ§БэжаЫљгагыvalue ЯрЕШЕФжЕЁЃ
11.setМЏКЯЕФВйзїЃК
ЬэМгдЊЫиЃК
sadd set value1 value2....
ШчЃК
sadd team xiaotuo datuo
ВщПДдЊЫиЃК
smembeers set
ШчЃК
smembers team
вЦГ§дЊЫиЃК
srem set member...
ШчЃК
srem team xiaotuo datuo
ВщПДМЏКЯжаЕФдЊЫиИіЪ§ЃК
scard set
ШчЃК
scard team1
ЛёШЁЖрИіМЏКЯЕФНЛМЏЃК
sinter set1 set2
ШчЃК
sinter team1 team2
ЛёШЁЖрИіМЏКЯЕФВЂМЏЃК
sunion set1 set2
ШчЃК
sunion team1 team2
ЛёШЁЖрИіМЏКЯЕФВюМЏЃК
sdiff set1 set2
ШчЃК
sdiff team1 team2 |
12.hashЃЌЙўЯЃВйзїЃК
ЬэМгвЛИіаТжЕЃК
hset key field value
ШчЃК
hset website baidu baidu.com
НЋЙўЯЃБэkeyжаЕФгђfieldЕФжЕЩшЮЊvalueЁЃ
ШчЙћkeyВЛДцдкЃЌвЛИіаТЕФЙўЯЃБэБЛДДНЈВЂНјаа HSETВйзїЁЃШчЙћгђ field
вбОДцдкгкЙўЯЃБэжаЃЌОЩжЕНЋБЛИВИЧЁЃ
ЛёШЁЙўЯЃжаЕФfieldЖдгІЕФжЕЃК
hget key field
ШчЃК
hget website baidu
ЩОГ§fieldжаЕФФГИіfieldЃК
hdel key field
ШчЃК
hdel website baidu
ЛёШЁФГИіЙўЯЃжаЫљгаЕФfieldКЭvalueЃК
hgetall key
ШчЃК
hgetall website
ЛёШЁФГИіЙўЯЃжаЫљгаЕФfieldЃК
hkeys key
ШчЃК
hkeys website
ЛёШЁФГИіЙўЯЃжаЫљгаЕФжЕЃК
hvals key
ШчЃК
hvals website
ХаЖЯЙўЯЃжаЪЧЗёДцдкФГИіfieldЃК
hexists key field
ШчЃК
hexists website baidu
ЛёШЁЙўЯЃжазмЙВЕФМќжЕЖдЃК
hlen field
ШчЃК
hlen website |
12.ЪТЮяВйзїЃКRedisЪТЮёПЩвдвЛДЮжДааЖрИіУќСюЃЌЪТЮёОпгавдЯТЬиеїЃК
ИєРыВйзїЃКЪТЮёжаЕФЫљгаУќСюЖМЛсађСаЛЏЁЂАДЫГађЕижДааЃЌВЛЛсБЛЦфЫћУќСюДђШХЁЃ
дзгВйзїЃКЪТЮёжаЕФУќСювЊУДШЋВПБЛжДааЃЌвЊУДШЋВПЖМВЛжДааЁЃ
ПЊЦєвЛИіЪТЮёЃК
multi
вдКѓжДааЕФЫљгаУќСюЃЌЖМдкетИіЪТЮёжажДааЕФЁЃ
жДааЪТЮёЃКexecЛсНЋдкmultiКЭexecжаЕФВйзївЛВЂЬсНЛЁЃ
ШЁЯћЪТЮёЃКdiscardЛсНЋmultiКѓЕФЫљгаУќСюШЁЯћЁЃМрЪгвЛИіЛђепЖрИіkeyЃК
watch key...
МрЪгвЛИі(ЛђЖрИі)keyЃЌШчЙћдкЪТЮёжДаажЎЧАетИі(ЛђетаЉ) keyБЛЦфЫћУќСюЫљИФЖЏЃЌФЧУДЪТЮёНЋБЛДђЖЯЁЃ
ШЁЯћЫљгаkeyЕФМрЪгЃК
unwatch
13.ЗЂВМ/ЖЉдФВйзїЃК
ИјФГИіЦЕЕРЗЂВМЯћЯЂЃК
publish channel message
ЖЉдФФГИіЦЕЕРЕФЯћЯЂЃК
subscribe channel
14.ГжОУЛЏ
redisЬсЙЉСЫСНжжЪ§ОнБИЗнЗНЪНЃЌвЛжжЪЧRDBЃЌСэЭтвЛжжЪЧAOFЃЌвдЯТНЋЯъЯИНщЩметСНжжБИЗнВпТдЃК
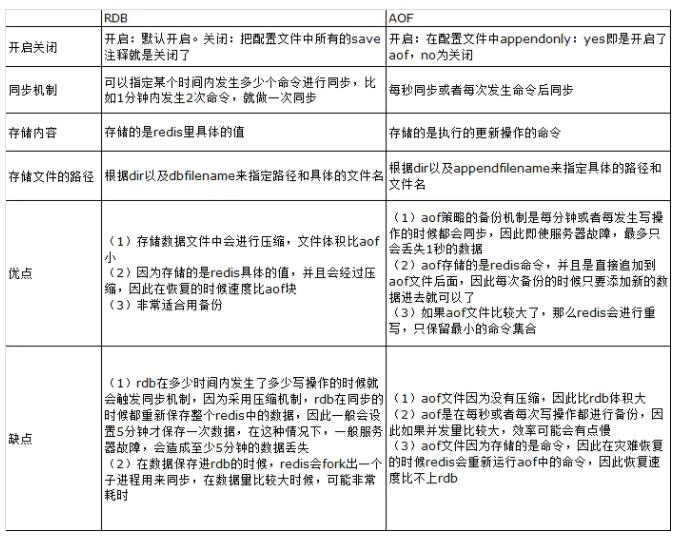
Python Вйзїredis
АВзАpython-redisЃК
pip install redis
2.аТНЈвЛИіЮФМўБШШчredis_test.pyЃЌШЛКѓГѕЪМЛЏвЛИіredisЪЕР§БфСПЃЌВЂЧв
дкubuntuащФтЛњжаПЊЦєredisЁЃБШШчащФтЛњЕФipЕижЗЮЊ192.168.174.130ЁЃ
ЪОР§ДњТыШчЯТЃК
# ДгredisАќжаЕМШыRedisРр
from redis import Redis
# ГѕЪМЛЏredisЪЕР§БфСП
xtredis = Redis(host='192.168.174.130',port=6379)
|
3.ЖдзжЗћДЎЕФВйзїЃКВйзїredisЕФЗНЗЈУћГЦЃЌИњжЎЧАЪЙгУredis-cliвЛбљЃЌЯжОЭ
вЛаЉГЃгУЕФРДзіИіМђЕЅНщЩмЃЌЪОР§ДњТыШчЯТ(ГаНгвдЩЯЕФДњТы)ЃК
# ЬэМгвЛИіжЕНјШЅЃЌВЂЧвЩшжУЙ§ЦкЪБМфЮЊ60УыЃЌШчЙћВЛЩшжУЃЌдђгРдЖВЛЛсЙ§Цк
xtredis.set('username','xiaotuo',ex=60)
# ЛёШЁвЛИіжЕ
xtredis.get('username')
# ЩОГ§вЛИіжЕ
xtredis.delete('username') |
4.ЖдСаБэЕФВйзїЃКЭЌзжЗћДЎВйзїЃЌЫљгаЗНЗЈЕФУћГЦИњЪЙгУredis-cliВйзїЪЧвЛбљЕФЃК
# ИјlanguagesетИіСаБэЭљзѓБпЬэМгвЛИіpython
xtredis.lpush('languages','python') # ИјlanguagesетИіСаБэЭљзѓБпЬэМгвЛИіphp
xtredis.lpush('languages','php') # ИјlanguagesетИіСаБэЭљзѓБпЬэМгвЛИіjavascript
xtredis.lpush('languages','javascript') # ЛёШЁlanguagesетИіСаБэжаЕФЫљгажЕ
print xtredis.lrange('languages',0,-1) > ['javascript','php','python']
|
5.ЖдМЏКЯЕФВйзїЃК
# ИјМЏКЯteamЬэМгвЛИідЊЫиxiaotuo
xtredis.sadd('team','xiaotuo')
# ИјМЏКЯteamЬэМгвЛИідЊЫиdatuo
xtredis.sadd('team','datuo')
# ИјМЏКЯteamЬэМгвЛИідЊЫиslice
xtredis.sadd('team','slice')
# ЛёШЁМЏКЯжаЕФЫљгадЊЫи
xtredis.smembers('team')
> ['datuo','xiaotuo','slice'] # ЮоађЕФ |
6.ЖдЙўЯЃ(hash)ЕФВйзїЃК
# ИјwebsiteетИіЙўЯЃжаЬэМгbaidu
xtredis.hset('website','baidu','baidu.com')
# ИјwebsiteетИіЙўЯЃжаЬэМгgoogle
xtredis.hset('website','google','google.com')
# ЛёШЁwebsiteетИіЙўЯЃжаЕФЫљгажЕ
print xtredis.hgetall('website')
> {"baidu":"baidu.com","google":"google.com"}
|
7.ЪТЮё(ЙмЕР)ВйзїЃКredisжЇГжЪТЮёВйзїЃЌвВМДвЛаЉВйзїжЛгаЭГвЛЭъГЩЃЌВХ
ФмЫуЭъГЩЁЃЗёдђЖМжДааЪЇАмЃЌгУpythonВйзїredisвВЪЧЗЧГЃМђЕЅЃЌЪОР§ДњТыШчЯТЃК
# ЖЈвхвЛИіЙмЕРЪЕР§
pip = xtredis.pipeline()
pip = xtredis.pipeline()
pip.set('username', 'xiaomei')
pip.set('school', 'qinghua')
pip.execute() |
8.ЪТЮё(ЙмЕР)ВйзїЃКredisжЇГжЪТЮёВйзїЃЌвВМДвЛаЉВйзїжЛгаЭГвЛЭъГЩЃЌВХ
ФмЫуЭъГЩЁЃЗёдђЖМжДааЪЇАмЃЌгУpythonВйзїredisвВЪЧЗЧГЃМђЕЅЃЌЪОР§ДњТыШчЯТЃК
#ЖЉдФ
from redis import Redis
ps = xtredis.pubsub()
ps.subscribe('email')
while True:
for item in ps.listen():
if item['type'] == 'message':
data = item.get('data')
print(data.decode('utf-8'))
#ЗЂВМ
from redis import Redis
xtredis = Redis(host='192.168.254.41', port=6379)
xtredis.publish('email', 'xxx@qq.com') |
вдЩЯБуеЙЪОСЫpython-redisЕФвЛаЉГЃгУЗНЗЈЃЌШчЙћЯыЩюШыСЫНтЦфЫћЕФЗН
ЗЈЃЌПЩвдВЮПМpython-redisЕФдДДњТыЃЈВщПДдДДњТыpycharmПьНнМќЬсЪОЃКАб
ЪѓБъЙтБъЗХдкimport RedisЕФRedisЩЯЃЌШЛКѓАДctrl+bМДПЩНјШыЃЉЁЃ
redisДюНЈжїДг
1.ПНБДвЛЗнredisХфжУЮФМўЮЊslave-6380.conf
cp redis.conf slave.conf
2.БрМslave-6380.confЮФМў
vim slave-6380.conf
bind 192.168.254.41
slaveof 192.168.254.41 6379
port 6380 |
redisМЏШК
redisМЏШК
redisМЏШКЮветРяВПдк2ИіЛњЦїЩЯ
ЕквЛЬЈЃК192.168.254.41
ЕкЖўЬЈЃК192.168.254.45
УПвЛЬЈЛњЦїДДНЈ3ИіredisХфжУЮФМў
ЕквЛЬЈЛњЦїХфжУЃК
mkdir conf
touch 7000.conf 7001.conf 7002.conf
vim 7000.conf#БрМЮФМўВЂЧвАбШчЯТФкШнПНБДНјШЅ
ЃЈЪЃЯТЕФ7001.confКЭ7002.confвВЪЧШчДЫЃЌАбвЛЯТ7000ИФГЩ7001КЭ7002МДПЩЃЉ
port 7000 #АѓЖЈЖЫПк
bind 192.168.254.41 #АѓЖЈЖдЭтСЌНгЬсЙЉЕФip
daemonize yes #ПЊЦєЪиЛЄНјГЬ
pidfile 7000.pid #НјГЬЮФМўУћ
cluster-enabled yes #ЪЧЗёЪЧМЏШК
cluster-config-file 7000_node.conf #МЏШКХфжУЮФМў
cluster-node-timeout 15000 #МЏШКСЌНгГЌЪБЪБМф
appendonly yes #Ъ§ОнГжОУЛЏРраЭ
ЕкЖўЬЈЛњЦїХфжУ
mkdir conf
touch 7003.conf 7004.conf 7005.conf
vim 7000.conf#БрМЮФМўВЂЧвАбШчЯТФкШнПНБДНјШЅ
ЃЈЪЃЯТЕФ7004.confКЭ7005.confвВЪЧШчДЫЃЌАбвЛЯТ7000ИФГЩ7004КЭ7005МДПЩЃЉ
port 7000 #АѓЖЈЖЫПк
bind 192.168.254.45 #АѓЖЈЖдЭтСЌНгЬсЙЉЕФip
daemonize yes #ПЊЦєЪиЛЄНјГЬ
pidfile 7000.pid #НјГЬЮФМўУћ
cluster-enabled yes #ЪЧЗёЪЧМЏШК
cluster-config-file 7000_node.conf #МЏШКХфжУЮФМў
cluster-node-timeout 15000 #МЏШКСЌНгГЌЪБЪБМф
appendonly yes #Ъ§ОнГжОУЛЏРраЭ
дкСНЬЈЛњЦїЩЯЗжБ№жДаает3ИіХфжУЮФМў
#192.168.254.41
redis-server 7000.conf
redis-server 7001.conf
redis-server 7002.conf
#192.168.254.45
redis-server 7003.conf
redis-server 7004.conf
redis-server 7005.conf
redisашвЊЕФRubyАцБОзюЕЭЪЧ2.2.2ЃЌЕЋЪЧCentOS7 yumПтжаrubyЕФАцБОжЇ
ГжЕН 2.0.0ЃЌПЩgem АВзАredisашвЊзюЕЭЪЧ2.2.2ЃЌВЩгУrvmРДИќаТrubyЃК
АВзАRVM
1.curl -L get.rvm.io | bash -s stable
2.find / -name rvm -printЃЈДЫЪБПЩФмГіЯжЮЪЬтЃЉ
3.ШчЙћБЈДэжДааЃЈ4,5ВНЃЉ
4.curl -sSL https://rvm.io/mpapis.asc | gpg2
--import -
5.curl -sSL https://rvm.io/pkuczynski.asc
| gpg2 --import -
6.ГіЯжШчЯТФкШнДњБэГЩЙІ
ЁЁЁЁЁЁЁЁ/usr/local/rvm
ЁЁЁЁЁЁЁЁ/usr/local/rvm/src/rvm
ЁЁЁЁЁЁЁЁ/usr/local/rvm/src/rvm/bin/rvm
ЁЁЁЁЁЁЁЁ/usr/local/rvm/src/rvm/lib/rvm
ЁЁЁЁЁЁЁЁ/usr/local/rvm/src/rvm/scripts/rvm
ЁЁЁЁЁЁЁЁ/usr/local/rvm/bin/rvm
ЁЁЁЁЁЁЁЁ/usr/local/rvm/lib/rvm
ЁЁЁЁЁЁЁЁ/usr/local/rvm/scripts/rvm
7.ЪЙИеАВзАЕФrvmСЂМДЩњаЇ
ЁЁЁЁsource /usr/local/rvm/scripts/rvm8.АВзАвЛИіrubyАцБО
ЁЁЁЁrvm install 2.4.1
9.ЪЙгУвЛИіrubyАцБО
ЁЁЁЁrvm use 2.4.1
10.ЩшжУФЌШЯrubyАцБО
rvm use 2.4.1 --default
11.gem install redis
12.redis-cli --cluster create 192.168.93.10:7001
192.168.93.11:7002 192.168.93.13:7003 --cluster-replicas
1
13.СЌНгУќСюЃК
redis-cli -c -h 192.168.93.11 -p 7001
|
BeansDBВЩгУKey-ValueДцДЂМмЙЙЃЌЦфзюДѓЕФЬиЕуЪЧОпгаИпЖШЕФПЩЩьЫѕад;дкBeansDBЕФМмЙЙЯТЃЌдкДѓЪ§ОнСПЯТЃЌРЉеЙЪ§ОнНкЕуНЋЧсЖјвзОйЃЌжЛашвЊЬэМггВМўЃЌАВзАШэМўЃЌаоИФЯргІЕФХфжУЮФМўМДПЩЁЃ
BeansDBЯюФППЩвдЫЕЪЧвЛИіМђЛЏАцЕФAWS DynamoDBЁЃBeansDBЖдkeyзіЙўЯЃдЫЫуевЕННкЕуРДЪЕЯжЗжВМКЭШпгрЃЌ
вЛИіаДВйзїЛсаДКУМИИіНкЕуЃЌЖјЯждкЕФХфжУЪЧаДШ§ЗнЖСвЛЗнЁЃBeansDBжївЊЕФЬиЕуЪЧжЇГжКЃСПKVЪ§ОнПтЁЊЁЊЯрБШRedisетжжжЇГжМИЪЎИіGЕНМИАйИіGЕФФкДцKVЪ§ОнПтЃЌBeansDBПЩвджЇГжЕНЩЯАйTЕФЪ§ОнЁЃСэЭтBeansDBзюДѓЕФКУДІОЭЪЧдЫЮЌКмМђЕЅЃЌадФмЁЂРЉШнЖМКмКУЃЌвВЪЕЯжСЫзюжевЛжТадЁЃ
BeansDBдкПЩгУадЗНУцвВгаКмДѓЕФгХЪЦЃЌШЮКЮвЛИіНкЕухДЛњЖМВЛЛсЪмЕНгАЯьЃЌЪ§ОнЪЧздЖЏЩьЫѕШпгрЕФЁЃдкдЫЮЌЗНУцвВКмМђЕЅЃЌЛљБОЩЯУЛгаЪВУДгУЛЇЪ§ОнЕФШпгрВагрЃЌЫљгаЪ§ОнЭЈЙ§вЛИіЭЌВННХБОПЩвдПьЫйЭЌВНЁЃ
| 








