| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫЪТЮёУшЪіЁЂ
redisЪТЮёДІРэЁЂredisЪТЮёЪОР§ЁЂredisГжОУЛЏЁЃ
БОЮФРДздВЉПЭдАЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ
|
|
1. ЪТЮёУшЪі ЃЈ1ЃЉЪВУДЪЧЪТЮё
ЪТЮёЃЌОЭЪЧАбвЛЖбЪТЧщАѓдквЛЦ№ЃЌАДЫГађЕФжДааЃЌЖМГЩЙІСЫВХЫуЭъГЩЃЌЗёдђЛжИДжЎЧАЕФбљзг
ЪТЮёБиаыЗўДгACIDддђЃЌACIDддђЗжБ№ЪЧдзгадЃЈatomicityЃЉЁЂвЛжТадЃЈconsistencyЃЉЁЂИєРыадЃЈisolationЃЉКЭГжОУадЃЈdurabilityЃЉ
дзгадЃКВйзїетаЉжИСюЪБЃЌвЊУДШЋВПжДааГЩЙІЃЌвЊУДШЋВПВЛжДааЁЃжЛвЊЦфжавЛИіжИСюжДааЪЇАмЃЌЫљгаЕФжИСюЖМжДааЪЇАмЃЌЪ§ОнНјааЛиЙіЃЌЛиЕНжДаажИСюЧАЕФЪ§ОнзДЬЌ
вЛжТадЃКЪТЮёЕФжДааЪЙЪ§ОнДгвЛИізДЬЌзЊЛЛЮЊСэвЛИізДЬЌЃЌЕЋЪЧЖдгкећИіЪ§ОнЕФЭъећадБЃГжЮШЖЈ
ИєРыадЃКдкИУЪТЮёжДааЕФЙ§ГЬжаЃЌЮоТлЗЂЩњЕФШЮКЮЪ§ОнЕФИФБфЖМгІИУжЛДцдкгкИУЪТЮёжЎжаЃЌЖдЭтНчВЛДцдкгАЯьЃЌжЛгадкЪТЮёШЗШЯЬсНЛжЎКѓУЧВХЛсЯдЪОИУЪТЮёЖдЪ§ОнЕФИФБфЃЌЦфЫћЪТЮёВХФмЛёШЁЕНетаЉИФБфКѓЕФЪ§Он
ГжОУадЃКЕБЪТЮёе§ШЗЭъГЩКѓЃЌЫќЖдгкЪ§ОнЕФИФБфЪЧгРОУадЕФ
ЃЈ2ЃЉВЂЗЂЪТЮёЕМжТЕФГЃМћДэЮѓ
ЕквЛРрЖЊЪЇИќаТЃКГЗЯњвЛИіЪТЮёЪБЃЌАбЦфЫћЪТЮёвбЬсНЛЕФИќаТЪ§ОнИВИЧ
дрЖСЃКвЛИіЪТЮёЖСШЁЕНСэвЛИіЪТЮёЮДЬсНЛЕФИќаТЪ§Он
ЛУЖСвВНаащЖСЃКвЛИіЪТЮёжДааСНДЮВщбЏЃЌЕкЖўДЮНсЙћМЏАќКЌЕквЛДЮжаУЛгаЛђФГаЉаавбОБЛЩОГ§ЕФЪ§ОнЃЌдьГЩСНДЮНсЙћВЛвЛжТЃЌжЛЪЧСэвЛИіЪТЮёдкетСНДЮВщбЏжаМфВхШыЛђЩОГ§СЫЪ§ОндьГЩЕФ
ВЛПЩжиИДЖСЃКвЛИіЪТЮёСНДЮЖСШЁЭЌвЛааЕФЪ§ОнЃЌНсЙћЕУЕНВЛЭЌзДЬЌЕФНсЙћЃЌжаМфе§КУСэвЛИіЪТЮёИќаТСЫИУЪ§ОнЃЌСНДЮНсЙћЯрвьЃЌВЛПЩБЛаХШЮ
ЕкЖўРрЖЊЪЇИќаТЃКЪЧВЛПЩжиИДЖСЕФЬиЪтЧщПіЁЃШчЙћСНИіЪТЮяЖМЖСШЁЭЌвЛааЃЌШЛКѓСНИіЖМНјаааДВйзїЃЌВЂЬсНЛЃЌЕквЛИіЪТЮяЫљзіЕФИФБфОЭЛсЖЊЪЇ
2. redisЪТЮёДІРэ redisЪТЮёЭЈЙ§MULTIЁЂWATCHЁЂUNWAYCHЁЂEXECЁЂDISCARDЮхИіУќСюЪЕЯж
MUTILУќСюЃКгУгкПЊЦєвЛИіЪТЮёЃЌПЭЛЇЖЫПЩвдМЬајЯђЗўЮёЦїЗЂЫЭШЮвтЖрЬѕУќСюЃЌетаЉУќСюВЛЛсСЂМДБЛжДааЃЌЖјЪЧБЛЗХЕНвЛИіЖгСажаЃЌЕБEXECУќСюБЛЕїгУЪБЃЌЫљгаЖгСажаЕФУќСюВХЛсБЛжДааЃЌЫќзмЪЧЗЕЛиOK
WATCHУќСюЃКЖдМќНјааМрЪгЃЌжБЕНгУЛЇжДааEXECУќСюЕФетЖЮЪБМфРяУцЃЌШчЙћЦфЫћПЭЛЇЖЫЧРЯШЖдШЮКЮБЛМрЪгЕФМќНјааСЫЬцЛЛЁЂИќаТЛђЩОГ§ЕШВйзїЃЌФЧУДЕБгУЛЇВеЪвжДааEXECУќСюЕФЪБКђЃЌЪТЮёНЋЪЇАмВЂЗЕЛивЛИіДэЮѓЃЈжЎКѓгУЛЇПЩвдбЁдёжиЪдЛђепЗХЦњЪТЮёЃЉ
UNWATCHУќСюЃКдкWATCHУќСюжДаажЎКѓЃЌEXECУќСюжДаажЎЧАЖдСДНгНјаажижУ
EXECУќСюЃКжДааЪТЮёУќСю
DISCARDУќСюЃКПЭЛЇЖЫПЩвдШЁЯћWATCHУќСюУћЧхПеЫљгавбШыЖгУќСю
3. redisЪТЮёЪОР§ ЯТУцНЋгУЩЬЦЗНЛвзЪОР§ЫЕУїЪТЮёДІРэЙ§ГЬ
ЃЈ1ЃЉНЋЩЬЦЗЭЖЗХЕНЪаГЁ
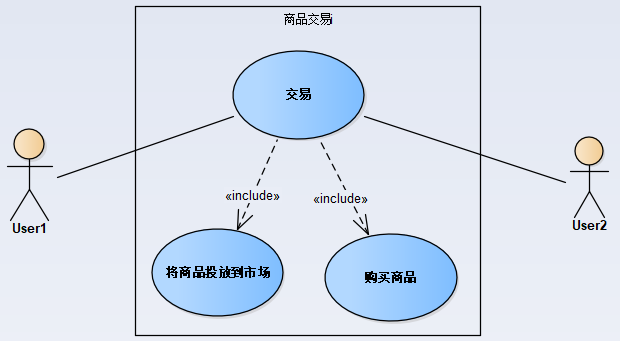
a. ЪЙгУЩЂСаЃЈusers:ЃЉРДЙмРэЪаГЁжаЕФЫљгагУЛЇаХЯЂЃЌАќРЈгУЛЇУћЁЂгУЛЇгЕгаЕФЧЎ
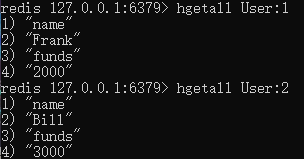
b. ЪЙгУМЏКЯЃЈinventory:ЃЉРДЙмРэУПИігУЛЇЕФЫљгаЩЬЦЗаХЯЂЃЌАќРЈЩЬЦЗУћУћ
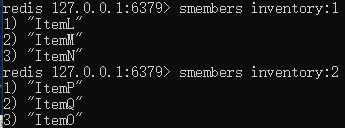
inventory:1ЖдгІгУЛЇUser:1ЕФБЈИц
c. ЪЙгУгаађМЏКЯЃЈmarket:ЃЉРДЙмРэЭЖЗХЕНЪаГЁжаЕФЩЬЦЗ
СїГЬЃКМьВщinventory:1АќЙќжаЪЧЗёКЌгаItemLЩЬЦЗ----->НЋinventory:1АќЙќжаЕФItemLЩЬЦЗЬэМгЕННЛвзЪаГЁ----->ЩОГ§inventory:1АќЙќжаЕФItemLЩЬЦЗ
def list_item(conn,userid,goodsname,price):
#ЪЙгУгаађМЏКЯЃЈmarket:ЃЉРДЙмРэЭЖЗХЕНЪаГЁжаЕФЩЬЦЗ
#ЩЬЦЗЕФkeyЮЊuserid:goodsid
inventory = 'inventory:%s' %(userid)
user = 'User:%s' %(userid)
goodsitem = '%s:%s' %(userid,goodsname)
end = time.time() + 5
pipe = conn.pipeline()
while time.time() < end:
try:
pipe.watch(inventory) #МрЪгАќЙќЗЂЩњЕФБфЛЏ
if not pipe.sismember(inventory,goodsname): #МьВщгУЛЇЪЧЗёШдШЛГжгаНЋвЊБЛЗХШыЪаГЁЕФЩЬЦЗ
pipe.unwatch()
return None
pipe.multi()
pipe.zadd('market:',{goodsitem:price}) #НЋЩЬЦЗЭЖЗХЕНЪаГЁ
pipe.srem(inventory, goodsname) #ДггУЛЇАќЙќжаЩОГ§ИУЩЬЦЗ
pipe.execute()
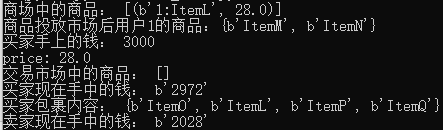
print('ЩЬГЁжаЕФЩЬЦЗЃК',conn.zrange('market:', 0, -1,withscores=True))
print('ЩЬЦЗЭЖЗХЪаГЁКѓгУЛЇ{} ЕФЩЬЦЗЃК{}'.format (userid, conn.smembers(inventory)))
return True
except redis.exceptions.WatchError as e:
print(e)
return False |
ВтЪдЃК

ЃЈ2ЃЉНЛвзЃКUser:2ЙКТђНЛвзЪаГЁжаЕФжаЕФItemLЩЬЦЗ
ЫМЯыЃКЪЙгУwatchЖдЪаГЁвдМАТђМвЕФИіШЫаХЯЂНјааМрЪгЃЌШЛКѓЛёШЁТђМвгЕгаЕФЧЎЪ§вдМАЩЬЦЗЪаГЁЕФЪлМлЃЌВЂМьВщТђМвЪЧЗёгазуЙЛЕФЧЎРДЙКТђЩЬЦЗЃЌШчЙћТђМвУЛгазуЙЛЕФЧЎЃЌФЧУДГЬађЛсШЁЯћЪТЮёЃЌШчЙћТђМвЧЎзуЙЛЃЌФЧУДГЬађЪзЯШЛсНЋТђМвжЇИЖЕФЧЎзЊвЦИјТєМвЃЌШЛКѓНЋЪлГіЕФЩЬЦЗвЦГ§ЩЬЦЗНЛвзЪаГЁЁЃ
def purchase_item(conn,
buyerid, goodsname, sellerid):
buyer = 'User:{}'.format(buyerid) #ТђМвkey
seller = 'User:{}'.format(sellerid) #ТєМвkey
buy_inventory = 'inventory:{}'.format(buyerid)
#ТђМвАќЙќkey
sell_inverntory = 'inventory:{}'.format(sellerid)
#ТєМвАќЙќkey
goodsitem = '{}:{ }'.format(sellerid,goodsname)
#ЪаГЁжаЕФЩЬЦЗkey
end = time.time() + 5
pipe = conn.pipeline()
while time.time() < end:
try:
pipe.watch('market:',buyer) #ЖдЩЬЦЗТђТєЪаГЁвдМАТђМвЕФИіШЫаХЯЂНјааМрЪг
funds = int(pipe.hget(buyer,'funds')) #ЕУЕНТђМвгЕгаЕФЧЎ
print('ТђМвЪжЩЯЕФЧЎЃК', funds)
price = pipe.zscore('market:', goodsitem) #ЕУЕНЩЬЦЗЕФМлИё
print('price:',price)
if funds < price:
pipe.unwatch()
return None
pipe.multi()
pipe.hincrby(buyer, 'funds', int(-price)) #ТђМвЕФЧЎМѕЩй
pipe.hincrby(seller, 'funds', int(price)) #ТєМвЕФЧЎдіМг
pipe.sadd(buy_inventory,goodsname)
pipe.zrem('market:', goodsitem)
pipe.execute()
print('НЛвзЪаГЁжаЕФЩЬЦЗЃК', conn.zrange('market:', 0, -1,
withscores=True))
print('ТђМвЯждкЪжжаЕФЧЎЃК',conn.hget(buyer, 'funds'))
print('ТђМвАќЙќФкШнЃК', conn.smembers(buy_inventory))
print('ТєМвЯждкЪжжаЕФЧЎЃК',conn.hget(seller, 'funds'))
return True
except redis.exceptions.WatchError as e:
print(e)
return False |
ВтЪдЃК
if __name__
== '__main__':
conn = redis.Redis()
#create_users(conn)
#create_user_inventory(conn)
list_item(conn,1,'ItemL',28)
purchase_item(conn, 2, 'ItemL', 1) |
4. redisГжОУЛЏ redisЬсЙЉСЫСНжжВЛЭЌЕФГжОУЛЏЗНЪНРДНЋЪ§ОнДгФкДцДцДЂЕНгВХЬРяУцЃЌвЛжжЪЧRDBГжОУЛЏЃЌдРэЪЧНЋredisФкДцжаЕФЪ§ОнПтМЧТМЖЈЪБdumpЕНДХХЬЩЯЕФRDBГжОУЛЏЃЌСэЭтвЛжжЪЧAOF(append
only file)ГжОУЛЏЃЌдРэЪЧБЛжДааЕФаДУќСюИДжЦЕНДХХЬРяЁЃ
ЃЈ1ЃЉRDBГжОУЛЏХфжУ
# Save the DB
on disk:
# ЩшжУsedisНјааЪ§ОнПтОЕЯёЕФЦЕТЪЁЃ
# 900УыЃЈ15ЗжжгЃЉФкжСЩй1ИіkeyжЕИФБфЃЈдђНјааЪ§ОнПтБЃДц--ГжОУЛЏЃЉЁЃ
# 300УыЃЈ5ЗжжгЃЉФкжСЩй10ИіkeyжЕИФБфЃЈдђНјааЪ§ОнПтБЃДц--ГжОУЛЏЃЉЁЃ
# 60УыЃЈ1ЗжжгЃЉФкжСЩй10000ИіkeyжЕИФБфЃЈдђНјааЪ§ОнПтБЃДц--ГжОУЛЏЃЉЁЃ
save 900 1
save 300 10
save 60 10000
stop-writes-on -bgsave-error yes
# дкНјааОЕЯёБИЗнЪБ,ЪЧЗёНјаабЙЫѕЁЃyesЃКбЙЫѕЃЌЕЋЪЧашвЊвЛаЉcpuЕФЯћКФЁЃnoЃКВЛбЙЫѕЃЌашвЊИќЖрЕФДХХЬПеМфЁЃ
rdbcompression yes
# вЛИіCRC64ЕФаЃбщОЭБЛЗХдкСЫЮФМўФЉЮВЃЌЕБДцДЂЛђепМгдиrbdЮФМўЕФЪБКђЛсгавЛИі10%зѓгвЕФадФмЯТНЕЃЌЮЊСЫДяЕНадФмЕФзюДѓЛЏЃЌФуПЩвдЙиЕєетИіХфжУЯюЁЃ
rdbchecksum yes
# ПьееЕФЮФМўУћ
dbfilename dump.rdb
# ДцЗХПьееЕФФПТМ
dir ./ |
ЃЈ2ЃЉДДНЈПьееЕФЗНЗЈ
a. ПЭЛЇЖЫПЩвдЭЈЙ§ЯыredisЗЂЫЭbesaveУќСюРДДДНЈвЛИіПьееЃЌЖдгкжЇГжbgsaveУќСюЕФЦНЬЈРДЫЕЃЈЛљБОЩЯЫљгаЦНЬЈЖМжЇГжЃЌГ§СЫwindowsЦНЬЈЃЉЃЌredisЛсЕїгУforkРДДДНЈвЛИізгНјГЬЃЌШЛКѓзгНјГЬИКд№НЋПьееаДШыДХХЬЃЌЖјИИНјГЬМЬајДІРэУќСюЧыЧѓ
b. ПЭЛЇЖЫЛЙПЩвдЯђredisЗЂЫЭsaveУќСюРДДДНЈвЛИіПьееЃЌНгЕНsaveУќСюЕФredisЗўЮёЦїдкПьееДДНЈЭъБЯжЎЧАВЛдйЯьгІШЮКЮЦфЫћУќСюЃЌsaveУќСюВЛГЃгУЃЌЮвУЧЭЈГЃжЛЛсдкУЛгазуЙЛФкДцШЅжЇГжbgsaveЕФЧщПіЯТЃЌгжЛђепМДЪЙЕШД§ГжОУЛЏВйзїжДааЭъБЯвВЮоЫљЮНЕФЧщПіЯТЃЌВХЛсЪЙгУетИіУќСю
c. ЕБredisЭЈЙ§shutdownУќСюНгЪеЕНЙиБеЗўЮёЦїЧыЧѓЪБЃЌЛђепНгЪеЕНБъзМtermУќСюЪБЃЌЛсжДаавЛИіsaveУќСюЃЌзшШћЫљгаПЭЛЇЖЫЃЌВЛдйжДааПЭЛЇЖЫЗЂЫЭЕФШЮКЮУќСюЃЌВЂдкsaveУќСюжДааЭъБЯжЎКѓЙиБеЗўЮёЦї
d. ЕБвЛИіredisЗўЮёЦїСДНгСэвЛИіredisЗўЮёЦїЃЌВЂЯђЖдЗНЗЂЫЭsyncЭЌВНУќСюРДПЊЪМвЛДЮИДжЦВйзїЪБЃЌШчЙћжїЗўЮёЦїФПЧАУЛгажДааbgsaveВйзїЃЌЛђепжїЗўЮёЦїВЂЗЧИеИежДааЭъbgsaveВйзїЃЌФЧУДжїЗўЮёЦїОЭЛсжДааbgsave
ЃЈ3ЃЉAOFГжОУЛЏХфжУ
# ЪЧЗёПЊЦєAOFЃЌФЌШЯЙиБеЃЈnoЃЉ
appendonly yes
# жИЖЈ AOF ЮФМўУћ
appendfilename appendonly.aof
# RedisжЇГжШ§жжВЛЭЌЕФЫЂаДФЃЪНЃК
# appendfsync always #УПДЮЪеЕНаДУќСюОЭСЂМДЧПжЦаДШыДХХЬЃЌЪЧзюгаБЃжЄЕФЭъШЋЕФГжОУЛЏЃЌЕЋЫйЖШвВЪЧзюТ§ЕФЃЌвЛАуВЛЭЦМіЪЙгУЁЃ
appendfsync everysec #УПУыжгЧПжЦаДШыДХХЬвЛДЮЃЌдкадФмКЭГжОУЛЏЗНУцзіСЫКмКУЕФелжаЃЌЪЧЪмЭЦМіЕФЗНЪНЁЃ
# appendfsync no #ЭъШЋвРРЕOSЕФаДШыЃЌвЛАуЮЊ30УызѓгввЛДЮЃЌадФмзюКУЕЋЪЧГжОУЛЏзюУЛгаБЃжЄЃЌВЛБЛЭЦМіЁЃ
#дкШежОжиаДЪБЃЌВЛНјааУќСюзЗМгВйзїЃЌЖјжЛЪЧНЋЦфЗХдкЛКГхЧјРяЃЌБмУтгыУќСюЕФзЗМгдьГЩDISK
IOЩЯЕФГхЭЛЁЃ
#ЩшжУЮЊyesБэЪОrewriteЦкМфЖдаТаДВйзїВЛfsync,днЪБДцдкФкДцжа,ЕШrewriteЭъГЩКѓдйаДШыЃЌФЌШЯЮЊnoЃЌНЈвщyes
no-appendfsync-on-rewrite yes
#ЕБЧАAOFЮФМўДѓаЁЪЧЩЯДЮШежОжиаДЕУЕНAOFЮФМўДѓаЁЕФЖўБЖЪБЃЌздЖЏЦєЖЏаТЕФШежОжиаДЙ§ГЬЁЃ
auto-aof-rewrite-percentage 100
#ЕБЧАAOFЮФМўЦєЖЏаТЕФШежОжиаДЙ§ГЬЕФзюаЁжЕЃЌБмУтИеИеЦєЖЏReidsЪБгЩгкЮФМўГпДчНЯаЁЕМжТЦЕЗБЕФжиаДЁЃ
auto-aof-rewrite-min-size 64mb |
ЃЈ4ЃЉAOFжиаДдРэ
AOF жиаДКЭ RDB ДДНЈПьеевЛбљЃЌЖМЧЩУюЕиРћгУСЫаДЪБИДжЦЛњжЦ:
a. Redis жДаа fork() ЃЌЯждкЭЌЪБгЕгаИИНјГЬКЭзгНјГЬ
b. згНјГЬПЊЪМНЋаТ AOF ЮФМўЕФФкШнаДШыЕНСйЪБЮФМў
c . ЖдгкЫљгааТжДааЕФаДШыУќСюЃЌИИНјГЬвЛБпНЋЫќУЧРлЛ§ЕНвЛИіФкДцЛКДцжаЃЌвЛБпНЋетаЉИФЖЏзЗМгЕНЯжга
AOF ЮФМўЕФФЉЮВЃЌетбљбљМДЪЙдкжиаДЕФжаЭОЗЂЩњЭЃЛњЃЌЯжгаЕФ AOF ЮФМўвВЛЙЪЧАВШЋЕФ
d. ЕБзгНјГЬЭъГЩжиаДЙЄзїЪБЃЌЫќИјИИНјГЬЗЂЫЭвЛИіаХКХЃЌИИНјГЬдкНгЪеЕНаХКХжЎКѓЃЌНЋФкДцЛКДцжаЕФЫљгаЪ§ОнзЗМгЕНаТ
AOF ЮФМўЕФФЉЮВ
зЂвтЃКдкНЋФкДцЛКДцжаЕФЪ§ОнзЗМгЕНаТAOFЮФМўФЉЮВКЭrenameЪБЃЌжїНјГЬЪЧзшШћЕФ
| 








