| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫЗЧЙиЯЕаЭЪ§ОнПтЃЈNoSQLЃЉЗжВМЪНЯЕЭГЕФЬиЕуЃЌЗжВМЪНДцДЂЫуЗЈ,ЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздМђЪщЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
NoSQL(NoSQL = Not Only SQL )ЃЌвтМД"ВЛНіНіЪЧSQL"ЁЃ
ЯжДњМЦЫуЯЕЭГУПЬьдкЭјТчЩЯЖМЛсВњЩњХгДѓЕФЪ§ОнСПЁЃетаЉЪ§ОнгаКмДѓвЛВПЗжЪЧгЩЙиЯЕаЭЪ§ОнПтЙмРэЯЕЭГЃЈRDBMSsЃЉРДДІРэЃЌЦфбЯНїГЩЪьЕФЪ§бЇРэТлЛљДЁЪЙЕУЪ§ОнНЈФЃКЭгІгУГЬађБрГЬИќМгМђЕЅЁЃ
ЕЋЫцзХаХЯЂЛЏЕФРЫГБКЭЛЅСЊЭјЕФаЫЦ№ЃЌДЋЭГЕФRDBMSдквЛаЉвЕЮёЩЯПЊЪМГіЯжЮЪЬтЁЃЪзЯШЃЌЖдЪ§ОнПтДцДЂЕФШнСПвЊЧѓдНРДдНИпЃЌЕЅЛњЮоЗЈТњзуашЧѓЃЌКмЖрЪБКђашвЊгУМЏШКРДНтОіЮЪЬтЃЌЖјRDBMSгЩгквЊжЇГжjoinЃЌunionЕШВйзїЃЌвЛАуВЛжЇГжЗжВМЪНМЏШКЁЃЦфДЮЃЌдкДѓЪ§ОнДѓааЦфЕРЕФНёЬьЃЌКмЖрЕФЪ§ОнЖМЁАЦЕЗБЖСКЭдіМгЃЌВЛЦЕЗБаоИФЁБЃЌЖјRDBMSЖдЫљгаВйзївЛЪгЭЌШЪЃЌетОЭДјРДСЫгХЛЏЕФПеМфЁЃСэЭтЃЌЛЅСЊЭјЪБДњвЕЮёЕФВЛШЗЖЈадЕМжТЪ§ОнПтЕФДцДЂФЃЪНвВашвЊЦЕЗББфИќЃЌВЛздгЩЕФДцДЂФЃЪНдіДѓСЫдЫЮЌЕФИДдгадКЭРЉеЙЕФФбЖШЁЃ
NoSQL ЪЧвЛЯюШЋаТЕФЪ§ОнПтИяУќаддЫЖЏЃЌдчЦкОЭгаШЫЬсГіЃЌЗЂеЙжС2009ФъЧїЪЦдНЗЂИпеЧЁЃетРрЪ§ОнПтжївЊгаетаЉЬиЕуЃКЗЧЙиЯЕаЭЕФЁЂЗжВМЪНЕФЁЂПЊдДЕФЁЂЫЎЦНПЩРЉеЙЕФЁЃзюГѕЕФФПЕФЪЧЮЊСЫДѓЙцФЃweb
гІгУЁЃNoSQL ЕФгЕЛЄепУЧЬсГЋдЫгУЗЧЙиЯЕаЭЕФЪ§ОнДцДЂЃЌЭЈГЃЕФгІгУШчЯТЬиЕуЃКФЃЪНздгЩЁЂжЇГжМђвзИДжЦЁЂМђЕЅЕФAPIЁЂзюжеЕФвЛжТадЃЈЗЧACIDЃЉЁЂДѓШнСПЪ§ОнЕШЁЃ
БЪепЪЧMongoDBгУЛЇЃЌвВЪЙгУЙ§RedisЁЃЙиЯЕаЭЪ§ОнПтЪЙгУЙ§MySQLгыOracleЃЌЖдСНепЕФЧјБ№гавЛЖЈЕФЬхЛсЁЃMongoКЭRedisЕФВйзїЖМЗЧГЃМђЕЅЃЌЫйЖШКмПьЃЌКмЖргУSQLашвЊКмЖрЬѕгяОфЕФВйзїдкNoSQLЪ§ОнПтжаЖМЪЧ2ОфвдФкЭъГЩЁЃСэЭтNoSQLХфжУclusterвВКмШнвзЃЌЧвПЩвдЫцЪБИќИФpartitionКЭreplicationЕФЪ§СПЃЌMongoЕФаТАцБОЛЙФкжУСЫMapReduceВйзїЃЌЪЙЦфгаСЫзіДѓЪ§ОнЗжЮіЕФФмСІЁЃ
NoSQLРэТлЛљДЁ
1.ЙиЯЕаЭЪ§ОнПтРэТл - ACID

ACIDЃЌЪЧжИЪ§ОнПтЙмРэЯЕЭГЃЈDBMSЃЉдкаДШыЛђИќаТзЪСЯЕФЙ§ГЬжаЃЌЮЊБЃжЄЪТЮёЃЈtransactionЃЉЪЧе§ШЗПЩППЕФЃЌЫљБиаыОпБИЕФЫФИіЬиадЃКдзгадЃЈatomicityЃЌЛђГЦВЛПЩЗжИюадЃЉЁЂвЛжТадЃЈconsistencyЃЉЁЂИєРыадЃЈisolationЃЌгжГЦЖРСЂадЃЉЁЂГжОУадЃЈdurabilityЃЉЁЃ
A ЈC Atomicity ЈC дзгад
вЛИіЪТЮёЃЈtransactionЃЉжаЕФЫљгаВйзїЃЌвЊУДШЋВПЭъГЩЃЌвЊУДШЋВПВЛЭъГЩЃЌВЛЛсНсЪјдкжаМфФГИіЛЗНкЁЃЪТЮёдкжДааЙ§ГЬжаЗЂЩњДэЮѓЃЌЛсБЛЛиЙіЃЈRollbackЃЉЕНЪТЮёПЊЪМЧАЕФзДЬЌЃЌОЭЯёетИіЪТЮёДгРДУЛгаБЛжДааЙ§вЛбљЁЃ
C ЈC Consistency ЈC вЛжТад
дкЪТЮёПЊЪМжЎЧАКЭЪТЮёНсЪјвдКѓЃЌЪ§ОнПтЕФЭъећадУЛгаБЛЦЦЛЕЁЃетБэЪОаДШыЕФзЪСЯБиаыЭъШЋЗћКЯЫљгаЕФдЄЩшЙцдђЃЌетАќКЌзЪСЯЕФОЋШЗЖШЁЂДЎСЊадвдМАКѓајЪ§ОнПтПЩвдздЗЂадЕиЭъГЩдЄЖЈЕФЙЄзїЁЃ
I ЈC Isolation ЈC ИєРыад
Ъ§ОнПтдЪаэЖрИіВЂЗЂЪТЮёЭЌЪБЖдЦфЪ§ОнНјааЖСаДКЭаоИФЕФФмСІЃЌИєРыадПЩвдЗРжЙЖрИіЪТЮёВЂЗЂжДааЪБгЩгкНЛВцжДааЖјЕМжТЪ§ОнЕФВЛвЛжТЁЃЪТЮёИєРыЗжЮЊВЛЭЌМЖБ№ЃЌАќРЈЖСЮДЬсНЛЃЈRead
uncommittedЃЉЁЂЖСЬсНЛЃЈread committedЃЉЁЂПЩжиИДЖСЃЈrepeatable readЃЉКЭДЎааЛЏЃЈSerializableЃЉЁЃ
D ЈC Durability ЈC ГжОУад
ЪТЮёДІРэНсЪјКѓЃЌЖдЪ§ОнЕФаоИФОЭЪЧгРОУЕФЃЌМДБуЯЕЭГЙЪеЯвВВЛЛсЖЊЪЇЁЃ
ЙиЯЕаЭЪ§ОнПтбЯИёзёбACIDРэТлЁЃЕЋЕБЪ§ОнПтвЊПЊЪМТњзуКсЯђРЉеЙЁЂИпПЩгУЁЂФЃЪНздгЩЕШашЧѓЪБЃЌашвЊЖдACIDРэТлНјааШЁЩсЃЌВЛФмбЯИёзёбACIDЁЃвдCAPРэТлКЭBASEРэТлЮЊЛљДЁЕФNoSQLЪ§ОнПтПЊЪМГіЯжЁЃ
2.ЗжВМЪНЯЕЭГРэТл
2.1 ЗжВМЪНЯЕЭГНщЩм
ЗжВМЪНЯЕЭГЕФКЫаФРэФюЪЧШУЖрЬЈЗўЮёЦїаЭЌЙЄзїЃЌЭъГЩЕЅЬЈЗўЮёЦїЮоЗЈДІРэЕФШЮЮёЃЌгШЦфЪЧИпВЂЗЂЛђепДѓЪ§ОнСПЕФШЮЮёЁЃЗжВМЪНЪЧNoSQLЪ§ОнПтЕФБивЊЬѕМўЁЃ
ЗжВМЪНЯЕЭГгЩЖРСЂЕФЗўЮёЦїЭЈЙ§ЭјТчЫЩЩЂёюКЯзщГЩЕФЁЃУПИіЗўЮёЦїЖМЪЧвЛЬЈЖРСЂЕФPCЛњЃЌЗўЮёЦїжЎМфЭЈЙ§ФкВПЭјТчСЌНгЃЌФкВПЭјТчЫйЖШвЛАуБШНЯПьЁЃвђЮЊЗжВМЪНМЏШКРяЕФЗўЮёЦїЪЧЭЈЙ§ФкВПЭјТчЫЩЩЂёюКЯЃЌИїНкЕужЎМфЕФЭЈбЖгавЛЖЈЕФЭјТчПЊЯњЃЌвђДЫЗжВМЪНЯЕЭГдкЩшМЦЩЯОЁПЩФмМѕЩйНкЕуМфЭЈбЖЁЃДЫЭтЃЌвђЮЊЭјТчДЋЪфЦПОБЃЌЕЅИіНкЕуЕФадФмИпЕЭЖдЗжВМЪНЯЕЭГећЬхадФмгАЯьВЛДѓЁЃБШШчЃЌЖдЗжВМЪНгІгУРДЫЕЃЌВЩгУВЛЭЌБрГЬгябдПЊЗЂДјРДЕФЕЅИігІгУЗўЮёЕФадФмВювьЃЌИњЭјТчПЊЯњБШЦ№РДЖМПЩвдКіТдВЛМЦЁЃ
вђДЫЃЌЗжВМЪНЯЕЭГУПИіНкЕувЛАуВЛВЩгУИпадФмЕФЗўЮёЦїЃЌЖјЪЧЪЙгУадФмЯрЖдвЛАуЕФЦеЭЈPCЗўЮёЦїЁЃЬсЩ§ЗжВМЪНЯЕЭГЕФећЬхадФмЪЧЭЈЙ§КсЯђРЉеЙЃЈдіМгИќЖрЕФЗўЮёЦїЃЉЃЌЖјВЛЪЧзнЯђРЉеЙЃЈЬсЩ§УПИіНкЕуЕФЗўЮёЦїадФмЃЉЪЕЯжЁЃ
ЗжВМЪНЯЕЭГзюДѓЕФЬиЕуЪЧПЩРЉеЙадЃЌЫќФмЙЛЪЪгІашЧѓБфЛЏЖјРЉеЙЁЃЦѓвЕМЖгІгУашЧѓОГЃЫцЪБМфЖјВЛЖЯБфЛЏЃЌетвВЖдЦѓвЕМЖгІгУЦНЬЈЬсГіСЫКмИпЕФвЊЧѓЁЃЦѓвЕМЖгІгУЦНЬЈБиаывЊФмЪЪгІашЧѓЕФБфЛЏЃЌМДОпгаПЩРЉеЙадЁЃБШШчвЦЖЏЛЅСЊЭј2CгІгУЃЌЫцзХЛЅСЊЭјЦѓвЕЕФвЕЮёЙцФЃВЛЖЯдіДѓЃЌвЕЮёБфЕУдНРДдНИДдгЃЌВЂЗЂгУЛЇЧыЧѓдНРДдНЖрЃЌвЊДІРэЕФЪ§ОнвВдНРДдНЖрЃЌетИіЪБКђЦѓвЕМЖгІгУЦНЬЈБиаыФмЙЛЪЪгІетаЉБфЛЏЃЌжЇГжИпВЂЗЂЗУЮЪКЭКЃСПЪ§ОнДІРэЁЃЗжВМЪНЯЕЭГгаСМКУЕФПЩРЉеЙадЃЌПЩвдЭЈЙ§діМгЗўЮёЦїЪ§СПРДдіЧПЗжВМЪНЯЕЭГећЬхЕФДІРэФмСІЃЌвдгІЖдЦѓвЕЕФвЕЮёдіГЄДјРДЕФМЦЫуашЧѓдіМгЁЃ
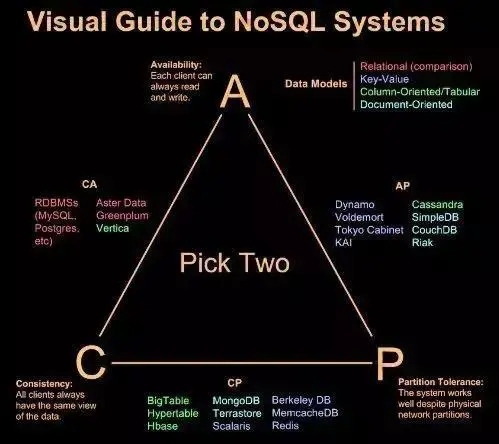
2.2 ЗжВМЪНДцДЂЕФЮЪЬт ЈC CAPРэТл
ШчЙћЮвУЧЦкД§ЪЕЯжвЛЬзбЯИёТњзуACIDЕФЗжВМЪНЪТЮёЃЌКмПЩФмГіЯжЕФЧщПіОЭЪЧЯЕЭГЕФПЩгУадКЭбЯИёвЛжТадЗЂЩњГхЭЛЁЃдкПЩгУадКЭвЛжТаджЎМфгРдЖЮоЗЈДцдквЛИіСНШЋЦфУРЕФЗНАИЁЃгЩгкNoSQLЕФЛљБОашЧѓОЭЪЧжЇГжЗжВМЪНДцДЂЃЌбЯИёвЛжТадгыПЩгУадашвЊЛЅЯрШЁЩсЃЌгЩДЫбгЩьГіСЫCAPРэТлРДЖЈвхЗжВМЪНДцДЂгіЕНЕФЮЪЬтЁЃ
CAPРэТлИцЫпЮвУЧЃКвЛИіЗжВМЪНЯЕЭГВЛПЩФмЭЌЪБТњзувЛжТад(C:Consistency)ЁЂПЩгУад(A:Availability)ЁЂЗжЧјШнДэад(P:Partitiontolerance)етШ§ИіЛљБОашЧѓЃЌВЂЧвзюЖржЛФмТњзуЦфжаЕФСНЯюЁЃ
ЖдгквЛИіЗжВМЪНЯЕЭГРДЫЕЃЌЗжЧјШнДэЪЧЛљБОашЧѓЃЌЗёдђВЛФмГЦжЎЮЊЗжВМЪНЯЕЭГЁЃвђДЫМмЙЙЪІашвЊдкCКЭAжЎМфбАЧѓЦНКтЁЃ
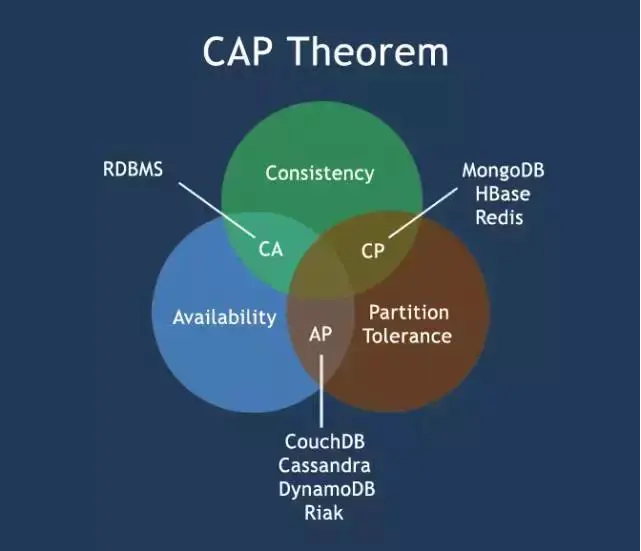
C ЈC Consistency ЈC вЛжТадЃЈгыACIDЕФCЭъШЋВЛЭЌЃЉ
вЛжТадЪЧжИЁАall nodes see the same data at the same timeЁБЃЌМДИќаТВйзїГЩЙІВЂЗЕЛиПЭЛЇЖЫЭъГЩКѓЃЌЫљгаНкЕудкЭЌвЛЪБМфЕФЪ§ОнЭъШЋвЛжТЁЃ
ЖдгквЛжТадЃЌПЩвдЗжЮЊДгПЭЛЇЖЫКЭЗўЮёЖЫСНИіВЛЭЌЕФЪгНЧЁЃ
ДгПЭЛЇЖЫРДПДЃЌвЛжТаджївЊжИЕФЪЧЖрВЂЗЂЗУЮЪЪБИќаТЙ§ЕФЪ§ОнШчКЮЛёШЁЕФЮЪЬтЁЃ
ДгЗўЮёЖЫРДПДЃЌдђЪЧИќаТШчКЮИДжЦЗжВМЕНећИіЯЕЭГЃЌвдБЃжЄЪ§ОнзюжевЛжТЁЃвЛжТадЪЧвђЮЊгаВЂЗЂЖСаДВХгаЕФЮЪЬтЃЌвђДЫдкРэНтвЛжТадЕФЮЪЬтЪБЃЌвЛЖЈвЊзЂвтНсКЯПМТЧВЂЗЂЖСаДЕФГЁОАЁЃ
ДгПЭЛЇЖЫНЧЖШЃЌЖрНјГЬВЂЗЂЗУЮЪЪБЃЌИќаТЙ§ЕФЪ§ОндкВЛЭЌНјГЬШчКЮЛёШЁЕФВЛЭЌВпТдЃЌОіЖЈСЫВЛЭЌЕФвЛжТадЁЃЖдгкЙиЯЕаЭЪ§ОнПтЃЌвЊЧѓИќаТЙ§ЕФЪ§ОнФмБЛКѓајЕФЗУЮЪЖМФмПДЕНЃЌетЪЧЧПвЛжТадЁЃШчЙћФмШнШЬКѓајЕФВПЗжЛђепШЋВПЗУЮЪВЛЕНЃЌдђЪЧШѕвЛжТадЁЃШчЙћОЙ§вЛЖЮЪБМфКѓвЊЧѓФмЗУЮЪЕНИќаТКѓЕФЪ§ОнЃЌдђЪЧзюжевЛжТадЁЃ
A ЈC Availability ЈC ПЩгУад
ПЩгУадЪЧжИЁАReads and writes always succeedЁБЃЌМДЗўЮёвЛжБПЩгУЃЌЖјЧвЪЧе§ГЃЯьгІЪБМфЁЃ
ЖдгквЛИіПЩгУадЕФЗжВМЪНЯЕЭГЃЌУПвЛИіЗЧЙЪеЯЕФНкЕуБиаыЖдУПвЛИіЧыЧѓзїГіЯьгІЁЃвВОЭЪЧЫЕЃЌИУЯЕЭГЪЙгУЕФШЮКЮЫуЗЈБиаызюжежежЙЁЃЕБЭЌЪБвЊЧѓЗжЧјШнШЬадЪБЃЌетЪЧвЛИіКмЧПЕФЖЈвхЃКМДЪЙЪЧбЯжиЕФЭјТчДэЮѓЃЌУПИіЧыЧѓБиаыЭъГЩЁЃ
КУЕФПЩгУаджївЊЪЧжИЯЕЭГФмЙЛКмКУЕФЮЊгУЛЇЗўЮёЃЌВЛГіЯжгУЛЇВйзїЪЇАмЛђепЗУЮЪГЌЪБЕШгУЛЇЬхбщВЛКУЕФЧщПіЁЃдкЭЈГЃЧщПіЯТЃЌПЩгУадгыЗжВМЪНЪ§ОнШпгрЁЂИКдиОљКтЕШгазХКмДѓЕФЙиСЊЁЃ
P ЈC Partition tolerance ЈC ЗжЧјШнДэад
ЗжЧјШнДэадЪЧжИЁАthe system continues to operate despite arbitrary
message loss or failureof part of the systemЁБЃЌМДЗжВМЪНЯЕЭГдкгіЕНФГНкЕуЛђЭјТчЗжЧјЙЪеЯЕФЪБКђЃЌШдШЛФмЙЛЖдЭтЬсЙЉТњзувЛжТадКЭПЩгУадЕФЗўЮёЁЃ
ЗжЧјШнДэадКЭРЉеЙадНєУмЯрЙиЁЃдкЗжВМЪНгІгУжаЃЌПЩФмвђЮЊвЛаЉЗжВМЪНЕФдвђЕМжТЯЕЭГЮоЗЈе§ГЃдЫзЊЁЃКУЕФЗжЧјШнДэадвЊЧѓФмЙЛЪЙгІгУЫфШЛЪЧвЛИіЗжВМЪНЯЕЭГЃЌЕЋПДЩЯШЅШДКУЯёЪЧвЛИіПЩвддЫзЊе§ГЃЕФећЬхЁЃБШШчЯждкЕФЗжВМЪНЯЕЭГжагаФГвЛИіЛђепМИИіЛњЦїхДЕєСЫЃЌЦфЫќЪЃЯТЕФЛњЦїЛЙФмЙЛе§ГЃдЫзЊТњзуЯЕЭГашЧѓЃЌЛђепЪЧЛњЦїжЎМфгаЭјТчвьГЃЃЌНЋЗжВМЪНЯЕЭГЗжИєГЩЮДЖРСЂЕФМИИіВПЗжЃЌИїИіВПЗжЛЙФмЮЌГжЗжВМЪНЯЕЭГЕФдЫзїЃЌетбљОЭОпгаКУЕФЗжЧјШнДэадЁЃ
CA without P
ШчЙћВЛвЊЧѓPЃЈВЛдЪаэЗжЧјЃЉЃЌдђCЃЈЧПвЛжТадЃЉКЭAЃЈПЩгУадЃЉЪЧПЩвдБЃжЄЕФЁЃЕЋЦфЪЕЗжЧјВЛЪЧФуЯыВЛЯыЕФЮЪЬтЃЌЖјЪЧЪМжеЛсДцдкЃЌвђДЫCAЕФЯЕЭГИќЖрЕФЪЧдЪаэЗжЧјКѓИїзгЯЕЭГвРШЛБЃГжCAЁЃ
CP without A
ШчЙћВЛвЊЧѓAЃЈПЩгУЃЉЃЌЯрЕБгкУПИіЧыЧѓЖМашвЊдкServerжЎМфЧПвЛжТЃЌЖјPЃЈЗжЧјЃЉЛсЕМжТЭЌВНЪБМфЮоЯобгГЄЃЌШчДЫCPвВЪЧПЩвдБЃжЄЕФЁЃКмЖрДЋЭГЕФЪ§ОнПтЗжВМЪНЪТЮёЖМЪєгкетжжФЃЪНЁЃ
AP without C
вЊИпПЩгУВЂдЪаэЗжЧјЃЌдђашЗХЦњвЛжТадЁЃвЛЕЉЗжЧјЗЂЩњЃЌНкЕужЎМфПЩФмЛсЪЇШЅСЊЯЕЃЌЮЊСЫИпПЩгУЃЌУПИіНкЕужЛФмгУБОЕиЪ§ОнЬсЙЉЗўЮёЃЌЖјетбљЛсЕМжТШЋОжЪ§ОнЕФВЛвЛжТадЁЃЯждкжкЖрЕФNoSQLЖМЪєгкДЫРрЁЃ
CAPРэТлЖЈвхСЫЗжВМЪНДцДЂЕФИљБОЮЪЬтЃЌЕЋВЂУЛгажИГівЛжТадКЭПЩгУаджЎМфЕНЕзгІИУШчКЮШЈКтЁЃгкЪЧГіЯжСЫBASEРэТлЃЌИјГіСЫШЈКтAгыCЕФвЛжжПЩааЗНАИЁЃ
2.3 ШЈКтвЛжТадгыПЩгУад - BASEРэТл
Base = Basically Available + Soft state + Eventuallyconsistent
ЛљБОПЩгУад+ШэзДЬЌ+зюжевЛжТадЃЌгЩeBayМмЙЙЪІDanPritchettЬсГіЁЃBaseЪЧЖдCAPжавЛжТадAКЭПЩгУадCШЈКтЕФНсЙћЃЌдДгкЬсГіепздМКдкДѓЙцФЃЗжВМЪНЯЕЭГЩЯЪЕМљЕФзмНсЁЃКЫаФЫМЯыЪЧЮоЗЈзіЕНЧПвЛжТадЃЌЕЋУПИігІгУЖМПЩвдИљОнздЩэЕФЬиЕуЃЌВЩгУЪЪЕБЗНЪНДяЕНзюжевЛжТадЁЃ
BA - Basically Available - ЛљБОПЩгУ
ЛљБОПЩгУЁЃетРяЪЧжИЗжВМЪНЯЕЭГдкГіЯжЙЪеЯЕФЪБКђЃЌдЪаэЫ№ЪЇВПЗжПЩгУадЃЌМДБЃжЄКЫаФЙІФмЛђепЕБЧАзюживЊЙІФмПЩгУЁЃЖдгкгУЛЇРДЫЕЃЌЫћУЧЕБЧАзюЙизЂЕФЙІФмЛђепзюГЃгУЕФЙІФмЕФПЩгУадНЋЛсЛёЕУБЃжЄЃЌЕЋЪЧЦфЫћЙІФмЛсБЛЯїШѕЁЃ
S ЈC Soft State - ШэзДЬЌ
дЪаэЯЕЭГЪ§ОнДцдкжаМфзДЬЌЃЌЕЋВЛЛсгАЯьЕНЯЕЭГЕФећЬхПЩгУадЃЌМДдЪаэЯЕЭГдкВЛЭЌНкЕуЕФЪ§ОнИББОжЎМфНјааЪ§ОнЭЌВНЪБДцдкбгЪБЁЃ
E - Eventually Consistent - зюжевЛжТад
вЊЧѓЯЕЭГЪ§ОнИББОзюжеФмЙЛвЛжТЃЌЖјВЛашвЊЪЕЪББЃжЄЪ§ОнИББОвЛжТЁЃзюжевЛжТадЪЧШѕвЛжТадЕФвЛжжЬиЪтЧщПіЁЃзюжевЛжТадга5ИіБфжжЃК
1.вђЙћвЛжТад
2.ЖСМКжЎЫљаД(вђЙћвЛжТадЬиР§)
3.ЛсЛАвЛжТад
4.ЕЅЕїЖСвЛжТад
5.ЕЅЕїаДвЛжТад
3.ЗжВМЪНДцДЂЫуЗЈ
3.1вЛжТадЫуЗЈ ЈC Paxos
Paxos ЫуЗЈНтОіЕФЮЪЬтЪЧвЛИіЗжВМЪНЯЕЭГШчКЮОЭФГИіжЕЃЈОівщЃЉДяГЩвЛжТЁЃвЛИіЕфаЭЕФГЁОАЪЧЃЌдквЛИіЗжВМЪНЪ§ОнПтЯЕЭГжаЃЌШчЙћИїНкЕуЕФГѕЪМзДЬЌвЛжТЃЌУПИіНкЕужДааЯрЭЌЕФВйзїађСаЃЌФЧУДЫћУЧзюКѓФмЕУЕНвЛИівЛжТЕФзДЬЌЁЃЮЊБЃжЄУПИіНкЕужДааЯрЭЌЕФУќСюађСаЃЌашвЊдкУПвЛЬѕжИСюЩЯжДаавЛИіЁАвЛжТадЫуЗЈЁБвдБЃжЄУПИіНкЕуПДЕНЕФжИСювЛжТЁЃвЛИіЭЈгУЕФвЛжТадЫуЗЈПЩвдгІгУдкаэЖрГЁОАжаЃЌЪЧЗжВМЪНМЦЫужаЕФживЊЮЪЬтЁЃвђДЫДг20ЪРМЭ80ФъДњЦ№ЖдгквЛжТадЫуЗЈЕФбаОПОЭУЛгаЭЃжЙЙ§ЁЃНкЕуЭЈаХДцдкСНжжФЃаЭЃКЙВЯэФкДцЃЈShared
memoryЃЉКЭЯћЯЂДЋЕнЃЈMessages passingЃЉЁЃPaxos ЫуЗЈОЭЪЧвЛжжЛљгкЯћЯЂДЋЕнФЃаЭЕФвЛжТадЫуЗЈЁЃ
ВЛНіНіЪЧдкЗжВМЪНЯЕЭГжаЃЌЗВЪЧЖрИіЙ§ГЬашвЊДяГЩФГжжвЛжТЕФГЁКЯЖМПЩвдЪЙгУPaxos ЫуЗЈЁЃвЛжТадЫуЗЈПЩвдЭЈЙ§ЙВЯэФкДцЃЈашвЊЫјЃЉЛђепЯћЯЂДЋЕнЪЕЯжЃЌPaxos
ЫуЗЈВЩгУЕФЪЧКѓепЁЃPaxos ЫуЗЈЪЪгУЕФМИжжЧщПіЃКвЛЬЈЛњЦїжаЖрИіНјГЬ/ЯпГЬДяГЩЪ§ОнвЛжТЃЛЗжВМЪНЮФМўЯЕЭГЛђепЗжВМЪНЪ§ОнПтжаЖрПЭЛЇЖЫВЂЗЂЖСаДЪ§ОнЃЛЗжВМЪНДцДЂжаЖрИіИББОЯьгІЖСаДЧыЧѓЕФвЛжТадЁЃ
3.2ЗжЧјЃЈPartitioningЃЉ
дРДЫљгаЕФЪ§ОнЖМЪЧдквЛИіЪ§ОнПтЩЯЕФЃЌЭјТчIOМАЮФМўIOЖММЏжадквЛИіЪ§ОнПтЩЯЕФЃЌвђДЫCPUЁЂФкДцЁЂЮФМўIOЁЂЭјТчIOЖМПЩФмЛсГЩЮЊЯЕЭГЦПОБЁЃЖјЗжЧјЕФЗНАИОЭЪЧАбФГвЛИіБэЛђФГМИИіЯрЙиЕФБэЕФЪ§ОнЗХдквЛИіЖРСЂЕФЪ§ОнПтЩЯЃЌетбљОЭПЩвдАбCPUЁЂФкДцЁЂЮФМўIOЁЂЭјТчIOЗжНтЕНЖрИіЛњЦїжаЃЌДгЖјЬсЩ§ЯЕЭГДІРэФмСІЁЃ
3.3ЗжЦЌЃЈReplicationЃЉ
ЗжЧјгаСНжжФЃЪНЃЌвЛжжЪЧжїДгФЃЪНЃЌгУгкзіЖСаДЗжРыЃЛСэЭтвЛжжФЃЪНЪЧЗжЦЌФЃЪНЃЌвВОЭЪЧЫЕАбвЛИіБэжаЕФЪ§ОнЗжНтЕНЖрИіБэжаЁЃвЛИіЗжЧјжЛФмЪЧЦфжаЕФвЛжжФЃЪНЁЃ
3.4вЛжТадЙўЯЃЃЈConsistent HashingЃЉ
вЛжТадЙўЯЃЫуЗЈЪЧЗжВМЪНЯЕЭГжаГЃгУЕФЫуЗЈЁЃБШШчЃЌвЛИіЗжВМЪНЕФДцДЂЯЕЭГЃЌвЊНЋЪ§ОнДцДЂЕНОпЬхЕФНкЕуЩЯЃЌШчЙћВЩгУЦеЭЈЕФhashЗНЗЈЃЌНЋЪ§ОнгГЩфЕНОпЬхЕФНкЕуЩЯЃЌШчkey%NЃЌkeyЪЧЪ§ОнЕФkeyЃЌNЪЧЛњЦїНкЕуЪ§ЃЌШчЙћгавЛИіЛњЦїМгШыЛђЭЫГіетИіМЏШКЃЌдђЫљгаЕФЪ§ОнгГЩфЖМЮоаЇСЫЃЌШчЙћЪЧГжОУЛЏДцДЂдђвЊзіЪ§ОнЧЈвЦЃЌШчЙћЪЧЗжВМЪНЛКДцЃЌдђЦфЫћЛКДцОЭЪЇаЇСЫЁЃ
вЛжТадЙўЯЃЛљБОНтОіСЫдкP2PЛЗОГжазюЮЊЙиМќЕФЮЪЬтЁЊЁЊШчКЮдкЖЏЬЌЕФЭјТчЭиЦЫжаЗжВМДцДЂКЭТЗгЩЁЃУПИіНкЕуНіашЮЌЛЄЩйСПЯрСкНкЕуЕФаХЯЂЃЌВЂЧвдкНкЕуМгШы/ЭЫГіЯЕЭГЪБЃЌНігаЯрЙиЕФЩйСПНкЕуВЮгыЕНЭиЦЫЕФЮЌЛЄжаЁЃЫљгаетвЛЧаЪЙЕУвЛжТадЙўЯЃГЩЮЊЕквЛИіЪЕгУЕФDHTЫуЗЈЁЃ
4.NoSQLЕФгХЕу/ШБЕу
гХЕу
1.взРЉеЙ
2.ИпадФм
3.Ъ§ОнРраЭСщЛю
4.ИпПЩгУ
ШБЕу
1.УЛгаБъзМ
2.УЛгаДцДЂЙ§ГЬ
3.ВЛжЇГжsql
4.ЙІФмВЛЙЛЭъЩЦ
4.1гХЕу
взРЉеЙ
NoSQLЪ§ОнПтжжРрЗБЖрЃЌЕЋЪЧгавЛИіЙВЭЌЕФЬиЕуЃЌЖМЪЧШЅЕєСЫЙиЯЕаЭЪ§ОнПтЕФЙиЯЕаЭЬиадЁЃЪ§ОнжЎМфЮоЙиЯЕЃЌетбљОЭЗЧГЃШнвзРЉеЙЁЃвВЮоаЮжЎМфЃЌдкМмЙЙЕФВуУцЩЯДјРДСЫПЩРЉеЙЕФФмСІЁЃ
ДѓЪ§ОнСПЃЌИпадФм
NoSQLЪ§ОнПтЖМОпгаЗЧГЃИпЕФЖСаДадФмЃЌгШЦфдкДѓЪ§ОнСПЯТЃЌЭЌбљБэЯжгХауЁЃетЕУвцгкЫќЕФЮоЙиЯЕадЃЌЪ§ОнПтЕФНсЙЙМђЕЅЁЃвЛАуMySQLЪЙгУQuery
CacheЃЌУПДЮБэИќаТCacheОЭЪЇаЇЃЌЪЧвЛжжДѓСЃЖШЕФCacheЃЌеыЖдweb2.0ЕФНЛЛЅЦЕЗБЕФгІгУЃЌCacheадФмВЛИпЁЃЖјNoSQLЕФCacheЪЧМЧТММЖЕФЃЌЪЧвЛжжЯИСЃЖШЕФCacheЃЌЫљвдNoSQLдкетИіВуУцЩЯРДЫЕадФмОЭвЊИпКмЖрСЫЁЃ
СщЛюЕФЪ§ОнФЃаЭ
NoSQLЮоашЪТЯШЮЊвЊДцДЂЕФЪ§ОнНЈСЂзжЖЮЃЌЫцЪБПЩвдДцДЂздЖЈвхЕФЪ§ОнИёЪНЁЃЖјдкЙиЯЕаЭЪ§ОнПтРяЃЌдіЩОзжЖЮЪЧвЛМўЗЧГЃТщЗГЕФЪТЧщЁЃШчЙћЪЧЗЧГЃДѓЪ§ОнСПЕФБэЃЌдіМгзжЖЮМђжБОЭЪЧвЛИіиЌУЮЁЃетЕудкДѓЪ§ОнСПЕФweb2.0ЪБДњгШЦфУїЯдЁЃ
ИпПЩгУ
NoSQLдкВЛЬЋгАЯьадФмЕФЧщПіЯТЃЌОЭПЩвдЗНБуЕиЪЕЯжИпПЩгУЕФМмЙЙЁЃБШШчCassandraЁЂHBaseФЃаЭЃЌЭЈЙ§ИДжЦФЃаЭвВФмЪЕЯжИпПЩгУЁЃ
4.1ШБЕу
УЛгаБъзМ
УЛгаЖдNoSQLЪ§ОнПтЖЈвхЕФБъзМЃЌЫљвдУЛгаСНИіNoSQLЪ§ОнПтЪЧЦНЕШЕФЁЃ
УЛгаДцДЂЙ§ГЬ
NoSQLЪ§ОнПтжаДѓЖрУЛгаДцДЂЙ§ГЬЁЃ
ВЛжЇГжSQL
NoSQLДѓЖрВЛЬсЙЉЖдSQLЕФжЇГжЃКШчЙћВЛжЇГжSQLетбљЕФЙЄвЕБъзМЃЌНЋЛсЖдгУЛЇВњЩњвЛЖЈЕФбЇЯАКЭгІгУЧЈвЦЩЯЕФГЩБОЁЃ
жЇГжЕФЬиадВЛЙЛЗсИЛЃЌВњЦЗВЛЙЛГЩЪь
ЯжгаВњЦЗЫљЬсЙЉЕФЙІФмЖМБШНЯгаЯоЃЌВЛЯёMS SQL ServerКЭOracleФЧбљФмЬсЙЉИїжжИНМгЙІФмЃЌБШШчBIКЭБЈБэЕШЁЃДѓЖрЪ§ВњЦЗЖМЛЙДІгкГѕДДЦкЃЌКЭЙиЯЕаЭЪ§ОнПтМИЪЎФъЕФЭъЩЦВЛПЩЭЌШеЖјгяЁЃ
NoSQLгыSQLЕФЖдБШ
RDBMSNoSQL
ФЃЪНдЄЖЈвхЕФФЃЪНУЛгадЄЖЈвхЕФФЃЪН
ВщбЏгябдНсЙЙЛЏВщбЏгябдЃЈSQLЃЉУЛгаЩљУїадВщбЏгябд
вЛжТадбЯИёЕФвЛжТадзюжевЛжТад
ЪТЮёжЇГжВЛжЇГж
РэТлЛљДЁACIDCAP, BASE
РЉеЙзнЯђРЉеЙКсЯђРЉеЙ(ЗжВМЪН)
NoSQLЪ§ОнПтЕФЗжРр
1.МќжЕ(Key-Value)ДцДЂЪ§ОнПт
етвЛРрЪ§ОнПтжївЊЛсЪЙгУЕНЙўЯЃБэЃЌдкетИіБэжагавЛИіЬиЖЈЕФМќКЭвЛИіжИеыжИЯђЬиЖЈЕФЪ§ОнЁЃKey/valueФЃаЭЖдгкITЯЕЭГРДЫЕгХЪЦдкгкМђЕЅЁЂвзВПЪ№ЁЃЕЋЪЧШчЙћDBAжЛЖдВПЗжжЕНјааВщбЏЛђИќаТЕФЪБКђЃЌKey/valueОЭЯдЕУаЇТЪЕЭЯТСЫЁЃ
E. g:
TokyoCabinet/Tyrant
Redis
Voldemort
OracleBDB
СаДцДЂЪ§ОнПт
етВПЗжЪ§ОнПтЭЈГЃЪЧгУРДгІЖдЗжВМЪНДцДЂЕФКЃСПЪ§ОнЁЃМќШдШЛДцдкЃЌЕЋЪЧЫќУЧЕФЬиЕуЪЧжИЯђСЫЖрИіСаЁЃетаЉСаЪЧгЩСаМвзхРДАВХХЕФЁЃ
E. g:
Cassandra
HBase
Riak
ЮФЕЕаЭЪ§ОнПт
ЮФЕЕаЭЪ§ОнПтЕФСщИаРДздгкLotus NotesАьЙЋШэМўЃЌЫќЭЌЕквЛжжМќжЕДцДЂЯрРрЫЦЁЃИУРраЭЕФЪ§ОнФЃаЭЪЧАцБОЛЏЕФЮФЕЕЃЌАыНсЙЙЛЏЕФЮФЕЕвдЬиЖЈЕФИёЪНДцДЂЃЌБШШчJSONЁЃЮФЕЕаЭЪ§ОнПтПЩвдПДзїЪЧМќжЕЪ§ОнПтЕФЩ§МЖАцЃЌдЪаэжЎМфЧЖЬзМќжЕЁЃЖјЧвЮФЕЕаЭЪ§ОнПтБШМќжЕЪ§ОнПтЕФВщбЏаЇТЪИќИпЁЃ
E. g:
CouchDB
MongoDB
SequoiaDB
ЭМаЮ(Graph)Ъ§ОнПт
ЭМаЮНсЙЙЕФЪ§ОнПтЭЌЦфЫќааСавдМАИеадНсЙЙЕФSQLЪ§ОнПтВЛЭЌЃЌЫќЪЧЪЙгУСщЛюЕФЭМаЮФЃаЭЃЌВЂЧвФмЙЛРЉеЙЕНЖрИіЗўЮёЦїЩЯЁЃNoSQLЪ§ОнПтУЛгаБъзМЕФВщбЏгябд(SQL)ЃЌвђДЫНјааЪ§ОнПтВщбЏашвЊжЦЖЈЪ§ОнФЃаЭЁЃаэЖрNoSQLЪ§ОнПтЖМгаRESTЪНЕФЪ§ОнНгПкЛђепВщбЏAPIЁЃ
E. g:
Neo4J
InfoGrid
InfiniteGraph
жїСїNoSQLЪ§ОнПтНщЩмМАЦфЪЪгУГЁОА
1. Redis
1.1 НщЩм
RedisЪЧвЛИіПЊдДЕФЪЙгУANSI CгябдБраДЁЂжЇГжЭјТчЁЂПЩЛљгкФкДцврПЩГжОУЛЏЕФШежОаЭЁЂKey-ValueЪ§ОнПтЃЌВЂЬсЙЉЖржжгябдЕФAPIЁЃДг2010Фъ3дТ15ШеЦ№ЃЌRedisЕФПЊЗЂЙЄзїгЩVMwareжїГжЁЃДг2013Фъ5дТПЊЪМЃЌRedisЕФПЊЗЂгЩPivotalдожњЁЃ
1.2 ЪЪгУГЁОА
Ъ§ОнБфЛЏНЯЩйЃЌжДаадЄЖЈвхВщбЏЃЌНјааЪ§ОнЭГМЦЕФгІгУГЬађ
ашвЊЬсЙЉЪ§ОнАцБОжЇГжЕФгІгУГЬађ
Р§ШчЃКЙЩЦБМлИёЁЂЪ§ОнЗжЮіЁЂЪЕЪБЪ§ОнЫбМЏЁЂЪЕЪБЭЈбЖЁЂЗжВМЪНЛКДц
2. MongoDB
2.1 НщЩм
MongoDB ЪЧвЛИіЛљгкЗжВМЪНЮФМўДцДЂЕФЪ§ОнПтЁЃгЩ C++ гябдБраДЁЃжМдкЮЊ WEB гІгУЬсЙЉПЩРЉеЙЕФИпадФмЪ§ОнДцДЂНтОіЗНАИЁЃ
MongoDB ЪЧвЛИіНщгкЙиЯЕаЭЪ§ОнПтКЭЗЧЙиЯЕаЭЪ§ОнПтжЎМфЕФВњЦЗЃЌЪЧЗЧЙиЯЕаЭЪ§ОнПтЕБжаЙІФмзюЗсИЛЃЌзюЯёЙиЯЕаЭЪ§ОнПтЕФЗЧЙиЯЕаЭЪ§ОнПтЁЃ
2.2 ЪЪгУГЁОА
ашвЊЖЏЬЌВщбЏжЇГж
ашвЊЪЙгУЫїв§ЖјВЛЪЧ map/reduceЙІФм
ашвЊЖдДѓЪ§ОнПтгаадФмвЊЧѓ
ашвЊЪЙгУ CouchDBЕЋвђЮЊЪ§ОнИФБфЬЋЦЕЗБЖјеМТњФкДц
3.Neo4j
3.1 НщЩм
Neo4jЪЧвЛИіИпадФмЕФNoSQLЭМаЮЪ§ОнПтЃЌЫќНЋНсЙЙЛЏЪ§ОнДцДЂдкЭјТчЩЯЖјВЛЪЧБэжаЁЃЫќЪЧвЛИіЧЖШыЪНЕФЁЂЛљгкДХХЬЕФЁЂОпБИЭъШЋЕФЪТЮёЬиадЕФJavaГжОУЛЏв§ЧцЃЌЕЋЪЧЫќНЋНсЙЙЛЏЪ§ОнДцДЂдкЭјТч(ДгЪ§бЇНЧЖШНазіЭМ)ЩЯЖјВЛЪЧБэжаЁЃNeo4jвВПЩвдБЛПДзїЪЧвЛИіИпадФмЕФЭМв§ЧцЃЌИУв§ЧцОпгаГЩЪьЪ§ОнПтЕФЫљгаЬиадЁЃ
3.2 ЪЪгУГЁОА
ЪЪгУгкЭМаЮвЛРрЪ§Он
етЪЧ Neo4jгыЦфЫћNoSQLЪ§ОнПтЕФзюЯджјЧјБ№
Р§ШчЃКЩчЛсЙиЯЕЃЌЙЋЙВНЛЭЈЭјТчЃЌЕиЭММАЭјТчЭиЦз
4.Cassandra
4.1 НщЩм
Apache Cassandra ЪЧвЛЬзПЊдДЗжВМЪН Key-Value ДцДЂЯЕЭГЁЃЫќзюГѕгЩ Facebook
ПЊЗЂЃЌгУгкДЂДцЬиБ№ДѓЕФЪ§ОнЁЃ Cassandra ВЛЪЧвЛИіЪ§ОнПтЃЌЫќЪЧвЛИіЛьКЯаЭЕФЗЧЙиЯЕЕФЪ§ОнПтЃЌРрЫЦгкGoogle
ЕФ BigTableЁЃCassandra ЕФЪ§ОнФЃаЭЪЧЛљгкСазхЃЈColumn FamilyЃЉЕФЫФЮЌЛђЮхЮЌФЃаЭЁЃ
4.2ЪЪгУГЁОА
вјаавЕЃЌН№ШквЕ
аДБШЖСИќПь
5. HBase
5.1 НщЩм
HBaseЪЧвЛИіЗжВМЪНЕФЁЂУцЯђСаЕФПЊдДЪ§ОнПтЃЌИУММЪѕРДдДгкGoogleТлЮФЁАBigtableЃКвЛИіНсЙЙЛЏЪ§ОнЕФЗжВМЪНДцДЂЯЕЭГЁБЁЃОЭЯёBigtableРћгУСЫGoogleЮФМўЯЕЭГЃЈFile
SystemЃЉЫљЬсЙЉЕФЗжВМЪНЪ§ОнДцДЂвЛбљЃЌHBaseдкHadoopжЎЩЯЬсЙЉСЫРрЫЦгкBigtableЕФФмСІЁЃЫќЪЧвЛИіЪЪКЯгкЗЧНсЙЙЛЏЪ§ОнДцДЂЕФЪ§ОнПтЁЃСэвЛИіВЛЭЌЕФЪЧHBaseЛљгкСаЕФЖјВЛЪЧЛљгкааЕФФЃЪНЁЃ
5.2ЪЪгУГЁОА
ЖдДѓЪ§ОнНјааЫцЛњЁЂЪЕЪБЗУЮЪЕФГЁКЯ
Р§ШчЃК FacebookЯћЯЂЪ§ОнПт
6.CouchDB
6.1 НщЩм
CouchDB ЪЧвЛИіПЊдДЕФУцЯђЮФЕЕЕФЪ§ОнПтЙмРэЯЕЭГЃЌПЩвдЭЈЙ§ RESTful JavaScript
Object Notation (JSON) API ЗУЮЪЁЃЪѕгя ЁАCouchЁБ ЪЧ ЁАCluster
Of Unreliable CommodityHardwareЁБ ЕФЪззжФИЫѕаДЃЌЫќЗДгГСЫ CouchDB
ЕФФПБъОпгаИпЖШПЩЩьЫѕадЃЌЬсЙЉСЫИпПЩгУадКЭИпПЩППадЃЌМДЪЙдЫаадкШнвзГіЯжЙЪеЯЕФгВМўЩЯвВЪЧШчДЫЁЃ
6.2ЪЪгУГЁОА
Ъ§ОнБфЛЏНЯЩйЃЌжДаадЄЖЈвхВщбЏЃЌНјааЪ§ОнЭГМЦЕФгІгУГЬађ
ашвЊЬсЙЉЪ§ОнАцБОжЇГжЕФгІгУГЬађЁЃ
Р§ШчЃК CRMЁЂCMSЯЕЭГЁЃ master-masterИДжЦЖдгкЖреОЕуВПЪ№ЪЧЗЧГЃгагУЕФЁЃ
NoSQLгХаугІгУЪЕР§
1. аТРЫЮЂВЉ - Redis
аТРЫЮЂВЉДгММЪѕЩЯРДЫЕЃЌУПЬьгУЛЇЗЂБэЮЂВЉЬиБ№ШнвзЃЌетдьГЩУПЬьаТдіЕФЪ§ОнСПЖМЪЧАйЭђМЖЁЂЩЯЧЇЭђМЖЕФетбљвЛИіСПЁЃФуОГЃвЊУцЖдЕФвЛИіЮЪЬтОЭЪЧдіМгЗўЮёЦїЃЌвђЮЊвЛАувЛЬЈMySQLЗўЮёЦїЃЌЫќПЩФмжЇГХЕФЙцФЃвВОЭЪЧМИЧЇЭђЃЌЛђепЫЕИДдгвЛЕужЛгаМИАйЭђЃЌетбљЃЌПЩФмУПЬьЖМвЊдіМгЗўЮёЦїЃЌДгЖјНтОіЫљФуУцЖдЕФетаЉЮЪЬтЁЃ
ФПЧАаТРЫЮЂВЉЪЧRedisШЋЧђзюДѓЕФгУЛЇЃЌдкаТРЫга200ЖрЬЈЮяРэЛњЃЌ400ЖрИіЖЫПке§дкдЫаазХRedis,
га4GЕФЪ§ОнХмдкRedisЩЯРДЮЊЮЂВЉгУЛЇЬсЙЉЗўЮёЁЃ
аТРЫЮЂВЉУцСйЕФЮЪЬтШчЯТЃК
Ъ§ОнНсЙЙ(Data Structure)ашЧѓдНРДдНЖр, ЕЋmemcacheжаУЛга, гАЯьПЊЗЂаЇТЪ
ЫцзХЖСВйзїЕФСПЕФЩЯЩ§ЃЌадФмЮЪЬташвЊНтОіЃЌОРњЕФЙ§ГЬга:
Ъ§ОнПтЖСаДЗжРы(M/S)-->Ъ§ОнПтЪЙгУЖрИіSlave-->діМгCache (memcache)-->зЊЕНRedis
НтОіаДЕФЮЪЬтЃК
ЫЎЦНВ№ЗжЃЌЖдБэЕФВ№ЗжЃЌНЋгаЕФгУЛЇЗХдкетИіБэЃЌгаЕФгУЛЇЗХдкСэЭтвЛИіБэЁЃ
ПЩППадашЧѓ
CacheЕФ"бЉБР"ЮЪЬтФбвдНтОіЃЌУцСйзХПьЫйЛжИДЕФЬєеНЁЃ
ПЊЗЂГЩБОашЧѓ
CacheКЭDBЕФвЛжТадЮЌЛЄГЩБОдНРДдНИпЃЌЕЋПЊЗЂашвЊИњЩЯВЛЖЯгПШыЕФВњЦЗашЧѓЁЃЧвгВМўГЩБОзюЙѓЕФОЭЪЧЪ§ОнПтВуУцЕФЛњЦїЃЌЛљБОЩЯБШЧАЖЫЕФЛњЦївЊЙѓМИБЖЃЌжївЊЪЧIOУмМЏаЭЃЌКмКФгВМўЁЃ
ЮЌЛЄадИДдг
вЛжТадЮЌЛЄГЩБОдНРДдНИп
BerkeleyDBЪЙгУBЪїЃЌЛсвЛжБаДаТЕФЃЌФкВПВЛЛсгаЮФМўжиаТзщжЏЃЛетбљЛсЕМжТЮФМўдНРДдНДѓЃЛДѓЕФЪБКђашвЊНјааЮФМўЙщЕЕЃЌЙщЕЕЕФВйзївЊЖЈЦкзіЃЌетбљЃЌОЭашвЊгавЛЖЈЕФdown
timeЁЃ
ЛљгквдЩЯПМТЧЃЌаТРЫЮЂВЉбЁдёСЫRedisЁЃ
дкаТРЫNoSQLКЭMySQLдкДѓЖрЪ§ЧщПіЯТЪЧНсКЯЪЙгУЕФЃЌИљОнгІгУЕФЬиЕубЁдёКЯЪЪЕФДцДЂЗНЪНЁЃЦЉШчЃКЙиЯЕаЭЪ§ОнЃЌР§ШчЃКЫїв§ЪЙгУMySQLДцДЂЃЛЗЧЙиЯЕаЭЪ§ОнЃЌР§ШчЃКвЛаЉK/VашЧѓЕФЃЌЖдВЂЗЂвЊЧѓБШНЯИпЕФЗХШыRedisДцДЂЁЃ
аТРЫЮЂВЉЭХЖгЭЈЙ§аоИФRedisдДТыТњзуздМКЕФвЕЮёашЧѓЃКЭъЩЦЫќЕФreplicationЛњжЦЃЌМгШыpositionЕФИХФюЃЌШУЮЌЛЄИќШнвзЃЌЭЌЪБfailoverФмСІвВДѓДѓдіЧПЁЃИФЩЦHashsetдкRDBРяУцЕФДцДЂЗНЪНЃЌЬсЩ§ИДдгЪ§ОнРраЭЕФМгдиЫйЖШЁЃ
вЕЮёГЁОАШчЯТЃК
1. вЕЮёЪЙгУЗНЪНЃК
hash sets: ЙизЂСаБэ, ЗлЫПСаБэ, ЫЋЯђЙизЂСаБэ(key-value(field), ХХађ)
string(counter): ЮЂВЉЪ§, ЗлЫПЪ§, ...(БмУтСЫselect count(*)
from ...)
sort sets(здЖЏХХађ): TopN, ШШУХЮЂВЉЕШ, здЖЏХХађ
lists(queue): push/subЬсаб,...
ЩЯЪіЫФжж, ДгОЋЯИЛЏПижЦЗНУцЃЌhash setsКЭstring(counter)ЭЦМіЪЙгУ, sort
setsКЭlists(queue)ВЛЭЦМіЪЙгУ
ЛЙПЩЭЈЙ§ЖўДЮПЊЗЂЃЌНјааОЋМђЁЃБШШч: ДцДЂзжЗћИФЮЊДцДЂећаЮ, 16вкЪ§Он,жЛашвЊ16GФкДц
ДцДЂРраЭБЃДцдк3жжвдФкЃЌНЈвщВЛвЊГЌЙ§3жжЃЛ
НЋmemcache +mysql ЬцЛЛЮЊRedisЃК
RedisзїЮЊДцДЂВЂЬсЙЉВщбЏЃЌКѓЬЈВЛдйЪЙгУmysqlЃЌНтОіЪ§ОнЖрЗнжЎМфЕФвЛжТадЮЪЬтЃЛ
2. ЖдДѓЪ§ОнБэЕФДцДЂЃЈegЃК140зжЮЂВЉЕФДцДЂЃЉ
вЛИіПтОЭДцЮЈвЛадidКЭ140ИізжЃЛ
СэвЛИіПтДцidКЭгУЛЇУћЃЌЗЂВМШеЦкЁЂЕуЛїЪ§ЕШаХЯЂЃЌгУРДМЦЫуЁЂХХађЕШЃЌЕШМЦЫуГізюКѓашвЊеЙЪОЕФЪ§ОнЪБдйЕНЕквЛИіПтжаЬсШЁЮЂВЉФкШнЃЛ
3. вЛаЉММЧЩ
КмЖргІгУ, ПЩвдГаЪмЪ§ОнПтСЌНгЪЇАм, ЕЋВЛФмГаЪмДІРэТ§
вЛЗнЪ§Он, ЖрЗнЫїв§(еыЖдВЛЭЌЕФВщбЏГЁОА)
НтОіIOЦПОБЕФЮЈвЛЭООЖ: гУФкДц
дкЪ§ОнСПБфЛЏВЛДѓЕФЧщПіЯТЃЌгХЯШбЁгУRedis
4. ЬдБІЪ§ОнЦНЬЈ ЈC Oceanbase,TairЃЈОљЮЊздбаЃЉ
Ъ§ОнВњЦЗЕФвЛИізюДѓЬиЕуЪЧЪ§ОнЕФЗЧЪЕЪБаДШыЃЌе§вђЮЊШчДЫЃЌПЩвдШЯЮЊдквЛЖЈЕФЪБМфЖЮФкЃЌећИіЯЕЭГЕФЪ§ОнЪЧжЛЖСЕФЁЃетЮЊЩшМЦЛКДцЕьЖЈСЫЗЧГЃживЊЕФЛљДЁЁЃвЛаЉЖдЪЕаЇадвЊЧѓКмИпЕФЪ§ОнЃЌР§ШчеыЖдЫбЫїДЪЕФЭГМЦЪ§ОнЃЌЯЃЭћФмОЁПьЭЦЫЭЕНЪ§ОнВњЦЗЧАЖЫЃЌЫљвддкФкДцжазіЪЕЪБМЦЫуЃЌВЂАбМЦЫуНсЙћдкОЁПЩФмЖЬЕФЪБМфФкЫЂаТЕН
NoSQLДцДЂЩшБИжаЃЌЙЉЧАЖЫВњЦЗЕїгУЁЃ
ЬдБІOceanbaseЕФЩшМЦжЎГѕЃЌЪЧетбљЕФЁЃЙЋЫОЭЈЙ§ЖдЬдБІЕФдкЯпДцДЂашЧѓНјааЗжЮіЗЂЯжЃК
ЬдБІЕФЪ§ОнзмСПБШНЯДѓЃЌЮДРДвЛЖЮЪБМфЃЌБШШчЮхФъжЎФкЕФЪ§ОнЙцФЃЮЊАйTBМЖБ№ЃЌЧЇвкЬѕМЧТМЃЌСэЭтЃЌЪ§ОнХђеЭКмПьЃЌДЋЭГЕФЗжПтЗжБэЖдвЕЮёдьГЩКмДѓЕФбЙСІЃЌБиаыЩшМЦздЖЏЛЏЕФЗжВМЪНЯЕЭГЁЃЫљвдгаСЫЬдБІOceanbaseЃЌЫќвдвЛжжКмМђЕЅЕФЗНЪНТњзуСЫЮДРДвЛЖЮЪБМфЕФдкЯпДцДЂашЧѓЃЌВЂЧвЛЙЛёЕУСЫвЛаЉЦфЫќЬиадЃЌШчИпаЇжЇГжПчааПчБэЪТЮёЃЌетЖдгкЬдБІЕФвЕЮёЪЧЗЧГЃживЊЕФЁЃ
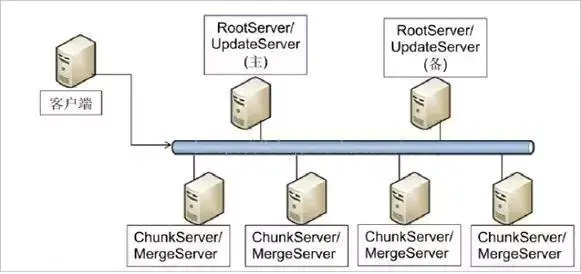
OceanBaseгЩШчЯТМИИіВПЗжзщГЩЃК
ПЭЛЇЖЫЃКгУЛЇЪЙгУOceanBaseЕФЗНЪНКЭMySQLЪ§ОнПтЭъШЋЯрЭЌЃЌжЇГжJDBCЁЂ CПЭЛЇЖЫЗУЮЪЃЌЕШЕШЁЃЛљгкMySQLЪ§ОнПтПЊЗЂЕФгІгУГЬађЁЂЙЄОпФмЙЛжБНгЧЈвЦЕНOceanBaseЁЃ
RootServerЃКЙмРэМЏШКжаЕФЫљгаЗўЮёЦїЃЌзгБэЃЈtabletЃЉЪ§ОнЗжВМвдМАИББОЙмРэЁЃ RootServerвЛАуЮЊвЛжївЛБИЃЌжїБИжЎМфЪ§ОнЧПЭЌВНЁЃ
UpdateServerЃКДцДЂOceanBaseЯЕЭГЕФдіСПИќаТЪ§ОнЁЃUpdateServerвЛАуЮЊвЛжївЛБИЃЌжїБИжЎМфПЩвдХфжУВЛЭЌЕФЭЌВНФЃЪНЁЃВПЪ№ЪБЃЌUpdateServerНјГЬКЭRootServerНјГЬЭљЭљЙВгУЮяРэЗўЮёЦїЁЃ
ChunkServerЃКДцДЂOceanBaseЯЕЭГЕФЛљЯпЪ§ОнЁЃЛљЯпЪ§ОнвЛАуДцДЂСНЗнЛђепШ§ЗнЃЌПЩХфжУЁЃ
Merge ServerЃКНгЪеВЂНтЮігУЛЇЕФSQLЧыЧѓЃЌОЙ§ДЪЗЈЗжЮіЁЂгяЗЈЗжЮіЁЂВщбЏгХЛЏЕШвЛЯЕСаВйзїКѓзЊЗЂИјЯргІЕФChunkServerЛђепUpdateServerЁЃШчЙћЧыЧѓЕФЪ§ОнЗжВМдкЖрЬЈChunkServerЩЯЃЌMergeServerЛЙашвЊЖдЖрЬЈChunkServerЗЕЛиЕФНсЙћНјааКЯВЂЁЃПЭЛЇЖЫКЭMergeServerжЎМфВЩгУдЩњЕФMySQLЭЈаХавщЃЌMySQLПЭЛЇЖЫПЩвджБНгЗУЮЪMergeServerЁЃ
ЬдБІTairЪЧгЩЬдБІзджїПЊЗЂЕФKey/ValueНсЙЙЪ§ОнДцДЂЯЕЭГЃЌВЂЧвгк
2010Фъ6дТ30КХдкЬдБІПЊдДЦНЬЈЩЯе§ЪНЖдЭтПЊдДЃЌдкЬдБІЭјгазХДѓЙцФЃЕФгІгУЁЃгУЛЇдкЕЧТМЬдБІЁЂВщПДЩЬЦЗЯъЧщвГУцЛђепдкЬдНКўКЭКУгбЁАЕЗНЌК§ЁБЕФЪБКђЃЌЖМдкжБНгЛђМфНгЕиКЭTairНЛЛЅЁЃЬдБІНЋTairПЊдДЃЌЯЃЭћгаИќЖрЕФгУЛЇФмДгЮвУЧПЊЗЂЕФВњЦЗжаЪмвцЃЌИќЯЃЭћвРЭаЩчЧјЕФСІСПЃЌЪЙTairгаИќЙуРЋЕФЗЂеЙПеМфЁЃ
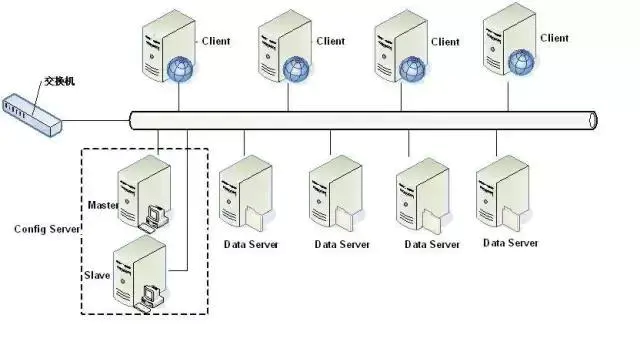
Tair ЕФЗжВМВЩгУЕФЪЧвЛжТадЙўЯЃЫуЗЈ, ЖдгкЫљгаЕФkey, ЗжЕНQИіЭАжа,
ЭАЪЧИКдиОљКтКЭЪ§ОнЧЈвЦЕФЛљБОЕЅЮЛ. config server ИљОнвЛЖЈЕФВпТдАбУПИіЭАжИХЩЕНВЛЭЌЕФdata
serverЩЯ. вђЮЊЪ§ОнАДееkeyзіhashЫуЗЈ, ЫљвдПЩвдШЯЮЊУПИіЭАжаЕФЪ§ОнЛљБОЪЧЦНКтЕФ. БЃжЄСЫЭАЗжВМЕФОљКтад,
ОЭБЃжЄСЫЪ§ОнЗжВМЕФОљКтадЁЃ
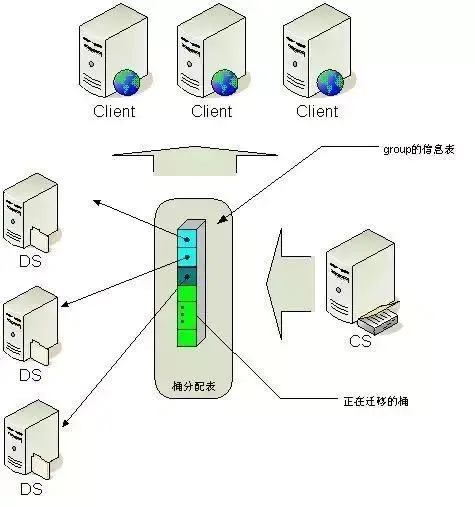
3. гХПсдЫгЊЪ§ОнЗжЮі ЈC HBase,MongoDB, Redis
гХПсзїЮЊвЛМвДѓаЭЪгЦЕЭјеОЃЌгЕгаКЃСПВЅЗХСїГЉЕФЪгЦЕЁЃЫќБќГазЂжигУЛЇЬхбщетвЛВњЦЗММЪѕРэФюЃЌНЋОјДѓВПЗжДцДЂгУдкЪгЦЕзЪдДЩЯЁЃЭЈЙ§НЈЩшзЈгУЕФЪгЦЕCDNЃЌНЈСЂСЫПЩздгЩРЉеЙЁЂадФмгХвьЕФМмЙЙЃЌдкЬсЙЉИќКУгУЛЇЬхбщЕФЭЌЪБгХЛЏСЫДцДЂзЪдДЁЃдкГ§ЪгЦЕзЪдДЭтЕФЦфЫќЗНУцЃЌгХПсвВРлЛ§СЫКЃСПЪ§ОнЃКНідЫгЊЪ§ОнЃЌУПЬьЪеМЏЕНЕФЭјеОИїРрЗУЮЪШежОзмСПвбОДяЕНTBМЖЃЌОЗжЮіМАбЙЫѕДІРэКѓСєДцЯТРДЕФРњЪЗдЫгЊЪ§ОнвбДяЪ§АйTBЃЌКмПьНЋЛсДяЕН
PBМЖЃЌ5ФъКѓЪ§ОнСПНЋЛсДяЕНМИЪЎPBМЖЁЃ
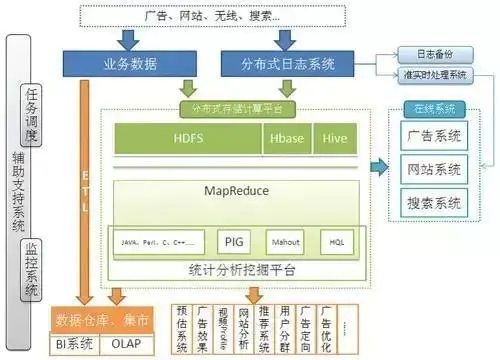
ФПЧАгХПсЕФдкЯпЦРТлвЕЮёвбВПЗжЧЈвЦЕНMongoDBЃЌдЫгЊЪ§ОнЗжЮіМАЭкОђДІРэФПЧАдкЪЙгУHadoop/HBase;дкKey-ValueВњЦЗЗНУцЃЌЫќвВдкбАевИќгХЕФ
MemcachedЬцДњЦЗЃЌШчRedisЃЌЯрЖдгкMemcachedЃЌГ§СЫЖдValueЕФДцДЂжЇГжШ§жжВЛЭЌЕФЪ§ОнНсЙЙЭтЃЌЭЌвЛИіKeyЕФValueНјааВПЗжИќаТвВЛсИќЪЪКЯвЛаЉЖдValueЦЕЗБаоИФЕФдкЯпвЕЮё;ЭЌЪБдкЫбЫїВњЦЗжагІгУСЫTokyo
Tyrant;ЖдгкCassandraЕШВњЦЗвВНјааЙ§баОПЁЃ
ЖдгкгХПсРДЫЕЃЌШдДІгкЗЩЫйЗЂеЙНзЖЮЃЌвбОдкПМТЧЮДРДздНЈЪ§ОнжааФЃЌЬсИпЪ§ОнДІРэФмСІЃЌДгЭјеОЕФдЫгЊжаЗЂОђГіИќЖраХЯЂЃЌЮЊгУЛЇЬсЙЉИќКУЕФЪгЦЕЗўЮёЁЃ
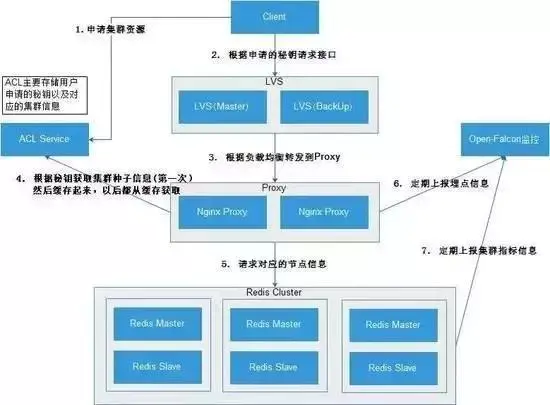
4. ЖЙАъЩчЧј ЈC BeansDBЃЈздбаKVЪ§ОнПтЃЉ
ЫќВЩгУРрЫЦmemcachedЕФШЅжааФЛЏНсЙЙЃЌдкПЭЛЇЖЫЪЕЯжЪ§ОнТЗгЩЁЃФПЧАжЛЬсЙЉСЫPythonАцБОЕФПЭЛЇЖЫЃЌЦфЫќгябдЕФПЭЛЇЖЫПЩвдгЩmemcachedЕФПЭЛЇЖЫЩдМгИФдьЕУЕНЁЃЫќОпгаШчЯТЬиадЃК
ИпПЩгУЃКЭЈЙ§ЖрИіПЩЖСаДЕФгУгкБИЗнЪЕЯжИпПЩгУ
зюжевЛжТадЃКЭЈЙ§ЙўЯЃЪїЪЕЯжПьЫйЭъећЪ§ОнЭЌВН(ЖЬЪБМфФкЪ§ОнПЩФмВЛвЛжТ)
ШнвзРЉеЙЃКПЩвддкВЛжаЖЯЗўЮёЕФЧщПіЯТНјааШнСПРЉеЙЁЃ
ИпадФмЃКвьВНЭјТчIO, ШежОНсЙЙЕФДцДЂЗНЪНBitcask.
МђЕЅавщЃКMemcacheМцШнавщЃЌДѓСППЩгУПЭЛЇЖЫ
ФПЧАЃЌBeansDBдкЖЙАъжївЊВПЪ№СЫСНИіМЏШКЃКвЛИіМЏШКгУгкДцДЂЪ§ОнПтжаЕФДѓЮФБОЪ§ОнЃЌБШШчШеМЧЁЂЬћзгвЛРр;СэЭтвЛИіЖЙАъFSМЏШКЃЌжївЊгУгкДцДЂУНЬхЮФМўЃЌБШШчгУЛЇЩЯДЋЕФЭМЦЌЁЂЖЙАъЕчЬЈЩЯЕФвєРжЕШЁЃ
BeansDBВЩгУKey-ValueДцДЂМмЙЙЃЌЦфзюДѓЕФЬиЕуЪЧОпгаИпЖШЕФПЩЩьЫѕад;дкBeansDBЕФМмЙЙЯТЃЌдкДѓЪ§ОнСПЯТЃЌРЉеЙЪ§ОнНкЕуНЋЧсЖјвзОйЃЌжЛашвЊЬэМггВМўЃЌАВзАШэМўЃЌаоИФЯргІЕФХфжУЮФМўМДПЩЁЃ
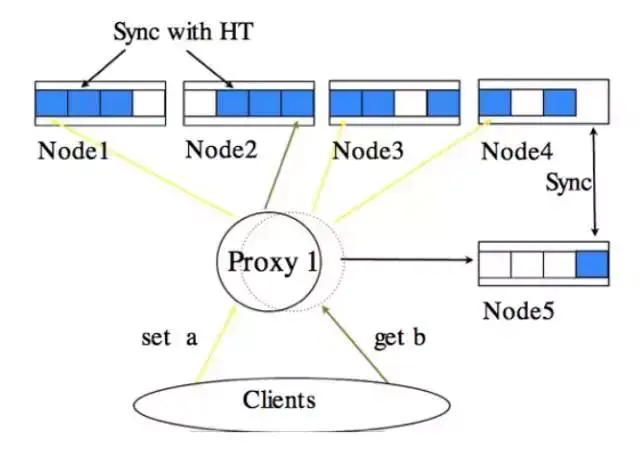
BeansDBЯюФППЩвдЫЕЪЧвЛИіМђЛЏАцЕФAWS DynamoDBЁЃBeansDBЖдkeyзіЙўЯЃдЫЫуевЕННкЕуРДЪЕЯжЗжВМКЭШпгрЃЌ
вЛИіаДВйзїЛсаДКУМИИіНкЕуЃЌЖјЯждкЕФХфжУЪЧаДШ§ЗнЖСвЛЗнЁЃBeansDBжївЊЕФЬиЕуЪЧжЇГжКЃСПKVЪ§ОнПтЁЊЁЊЯрБШRedisетжжжЇГжМИЪЎИіGЕНМИАйИіGЕФФкДцKVЪ§ОнПтЃЌBeansDBПЩвджЇГжЕНЩЯАйTЕФЪ§ОнЁЃСэЭтBeansDBзюДѓЕФКУДІОЭЪЧдЫЮЌКмМђЕЅЃЌадФмЁЂРЉШнЖМКмКУЃЌвВЪЕЯжСЫзюжевЛжТадЁЃ
BeansDBдкПЩгУадЗНУцвВгаКмДѓЕФгХЪЦЃЌШЮКЮвЛИіНкЕухДЛњЖМВЛЛсЪмЕНгАЯьЃЌЪ§ОнЪЧздЖЏЩьЫѕШпгрЕФЁЃдкдЫЮЌЗНУцвВКмМђЕЅЃЌЛљБОЩЯУЛгаЪВУДгУЛЇЪ§ОнЕФШпгрВагрЃЌЫљгаЪ§ОнЭЈЙ§вЛИіЭЌВННХБОПЩвдПьЫйЭЌВНЁЃ
| 








