| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫЙиЯЕаЭЪ§ОнПтКЭЗЧЙиЯЕаЭЪ§ОнПтЕФгХШБЕуЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздМђЪщЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ЙиЯЕаЭЪ§ОнПт
ЙиЯЕ ЕФИіШЫРэНтЃКЙиЯЕОЭЪЧБэФкЪ§ОнжЎМфЕФЁЂБэжЎМфЕФЙиЯЕЁЃБэФкЪ§ОнЪЧбЯИёЕФЖдгІЙиЯЕЃЌзжЖЮШБвЛВЛПЩЃЌжЕШБвЛВЛПЩЃЌвВОЭЪЧвЛжТЕФЪ§ОнНсЙЙЃЌетвВОЭЪЧ
django аТдізжЖЮЪБЃЌашвЊЩОЕєЪ§ОнЃЌжиаТ migrateЁЃБэжЎМфЕФЙиЯЕШ§жжЃКвЛЖдвЛЁЂвЛЖдЖрЁЂЖрЖдЖрЁЃЙиЯЕФЃаЭжИЕФОЭЪЧЖўЮЌБэИёФЃаЭЃЛ
ЙиЯЕаЭЪ§ОнПтвдааКЭСаЕФаЮЪНДцДЂЪ§ОнЃЌааКЭСаЕФаЮЪНБЛГЦЮЊБэЃЌБэЪЧгЩвЛзщЯрЙиЪЕЬхзщГЩЕФМЏКЯЁЃвЛзщБэзщГЩСЫЪ§ОнПтЁЃ
БэжаЕФвЛааГЦЮЊЙиЯЕЕФвЛИідЊзщЃЌгУРДДцДЂЪТЮяЕФвЛИіЪЕР§ЃЛ
БэжаЕФвЛСаГЦЮЊЙиЯЕЕФвЛИіЪєадЃЌгУРДУшЪіЪЕЬхЕФФГвЛЬиеїЁЃ
БэФкзжЖЮЕФзщГЩвЛбљЃЌМДБуФГИіЪ§ОнВЛашвЊФГИізжЖЮЃЌЯЕЭГвВЛсЧПМгЩЯетИізжЖЮМАФЌШЯжЕЃЌетжжНсЙЙБугкБэгыБэжЎМфНјааВйзїЃЌЕЋЫќвВЪЧЙиЯЕЪ§ОнПтадФмЦПОБЕФвЛИівђЫиЁЃ
1.ЙиЯЕаЭЪ§ОнПтРэТл - ACID
ACIDЃЌЪЧжИЪ§ОнПтЙмРэЯЕЭГЃЈDBMSЃЉдкаДШыЛђИќаТзЪСЯЕФЙ§ГЬжаЃЌЮЊБЃжЄЪТЮёЃЈtransactionЃЉЪЧе§ШЗПЩППЕФЃЌЫљБиаыОпБИЕФЫФИіЬиадЃКдзгадЃЈatomicityЃЌЛђГЦВЛПЩЗжИюадЃЉЁЂвЛжТадЃЈconsistencyЃЉЁЂИєРыадЃЈisolationЃЌгжГЦЖРСЂадЃЉЁЂГжОУадЃЈdurabilityЃЉЁЃ
A ЈC Atomicity ЈC дзгад
вЛИіЪТЮёЃЈtransactionЃЉжаЕФЫљгаВйзїЃЌвЊУДШЋВПЭъГЩЃЌвЊУДШЋВПВЛЭъГЩЃЌВЛЛсНсЪјдкжаМфФГИіЛЗНкЁЃЪТЮёдкжДааЙ§ГЬжаЗЂЩњДэЮѓЃЌЛсБЛЛиЙіЃЈRollbackЃЉЕНЪТЮёПЊЪМЧАЕФзДЬЌЃЌОЭЯёетИіЪТЮёДгРДУЛгаБЛжДааЙ§вЛбљЁЃ
C ЈC Consistency ЈC вЛжТад
дкЪТЮёПЊЪМжЎЧАКЭЪТЮёНсЪјвдКѓЃЌЪ§ОнПтЕФЭъећадУЛгаБЛЦЦЛЕЁЃетБэЪОаДШыЕФзЪСЯБиаыЭъШЋЗћКЯЫљгаЕФдЄЩшЙцдђЃЌетАќКЌзЪСЯЕФОЋШЗЖШЁЂДЎСЊадвдМАКѓајЪ§ОнПтПЩвдздЗЂадЕиЭъГЩдЄЖЈЕФЙЄзїЁЃ
I ЈC Isolation ЈC ИєРыад
Ъ§ОнПтдЪаэЖрИіВЂЗЂЪТЮёЭЌЪБЖдЦфЪ§ОнНјааЖСаДКЭаоИФЕФФмСІЃЌИєРыадПЩвдЗРжЙЖрИіЪТЮёВЂЗЂжДааЪБгЩгкНЛВцжДааЖјЕМжТЪ§ОнЕФВЛвЛжТЁЃЪТЮёИєРыЗжЮЊВЛЭЌМЖБ№ЃЌАќРЈЖСЮДЬсНЛЃЈRead
uncommittedЃЉЁЂЖСЬсНЛЃЈread committedЃЉЁЂПЩжиИДЖСЃЈrepeatable readЃЉКЭДЎааЛЏЃЈSerializableЃЉЁЃ
D ЈC Durability ЈC ГжОУад
ЪТЮёДІРэНсЪјКѓЃЌЖдЪ§ОнЕФаоИФЪЧгРОУЕФЃЌМДБуЯЕЭГЙЪеЯвВВЛЛсЖЊЪЇЁЃ
2.гХШБЕу
ЙиЯЕаЭЪ§ОнПтЕФгХЪЦЃК
ШнвзРэНтЃКЖўЮЌБэНсЙЙЪЧЗЧГЃЬљНќТпМЪРНчвЛИіИХФюЃЌЙиЯЕФЃаЭЯрЖдЭјзДЁЂВуДЮЕШЦфЫћФЃаЭРДЫЕИќШнвзРэНтЃЛ
БЃГжЪ§ОнЕФвЛжТадЃЈЪТЮёДІРэЃЉ
гЩгквдБъзМЛЏЮЊЧАЬсЃЌЪ§ОнИќаТЕФПЊЯњКмаЁЃЈЯрЭЌЕФзжЖЮЛљБОЩЯЖМжЛгавЛДІЃЉ
жЇГжSQLЃЌПЩвдНјааJoinЕШИДдгВщбЏЃЈМИеХБэжЎМфЃЉ
ЙиЯЕаЭЪ§ОнПтЕФВЛзуЃК
ВЛЩУГЄЕФДІРэ
ДѓСПЪ§ОнЕФаДШыДІРэ
ЮЊгаЪ§ОнИќаТЕФБэзіЫїв§ЛђБэНсЙЙЃЈschemaЃЉБфИќ
зжЖЮВЛЙЬЖЈЪБгІгУ
ЖдМђЕЅВщбЏашвЊПьЫйЗЕЛиНсЙћЕФДІРэ
ЗЧЙиЯЕЪ§ОнПт
НсЙЙВЛЙЬЖЈЃЌМЏКЯФкЪ§ОнзжЖЮПЩвдВЛвЛбљЃЌздгЩЖШИпЃЌПЩвдМѕЩйвЛаЉЪБМфКЭПеМфЕФПЊЯњЁЃ
ЫФДѓРраЭЃК
МќжЕЖдДцДЂЃЈkey-valueЃЉЃЌЮФЕЕДцДЂЃЈdocument storeЃКmongodbЃЉЃЌЛљгкСаЕФЪ§ОнПтЃЈcolumn-orientedЃЉЃЌЛЙгаОЭЪЧЭМаЮЪ§ОнПтЃЈgraph
databaseЃЉ
жїСїЕФЗЧЙиЯЕаЭЪ§ОнПтга NoSqlЁЂMongoDBЁЂCloudantЁЂ
ЬиеїЃК
1ЁЂЪЙгУМќжЕЖдДцДЂЪ§ОнЃЛ
2ЁЂЗжВМЪНЃЛ
3ЁЂвЛАуВЛжЇГжACIDЬиадЃЛ
4ЁЂЗЧЙиЯЕаЭЪ§ОнПтбЯИёЩЯВЛЪЧвЛжжЪ§ОнПтЃЌгІИУЪЧвЛжжЪ§ОнНсЙЙЛЏДцДЂЗНЗЈЕФМЏКЯЁЃ
гХЕуЃК
1ЁЂЮоашОЙ§sqlВуЕФНтЮіЃЌЖСаДадФмКмИпЃЛ
2ЁЂЛљгкМќжЕЖдЃЌЪ§ОнУЛгаёюКЯадЃЌШнвзРЉеЙЃЛ
3ЁЂДцДЂЪ§ОнЕФИёЪНЃКnosqlЕФДцДЂИёЪНЪЧkey,valueаЮЪНЁЂЮФЕЕаЮЪНЁЂЭМЦЌаЮЪНЕШЕШЃЌЮФЕЕаЮЪНЁЂЭМЦЌаЮЪНЕШЕШЃЌЖјЙиЯЕаЭЪ§ОнПтдђжЛжЇГжЛљДЁРраЭЁЃ
ШБЕуЃК
1ЁЂВЛЬсЙЉsqlжЇГжЃЌбЇЯАКЭЪЙгУГЩБОНЯИпЃЛ
2ЁЂЮоЪТЮёДІРэЃЌИНМгЙІФмbiКЭБЈБэЕШжЇГжвВВЛКУЃЛ
[ЙиЯЕгыЗЧЙиЯЕаЭЪ§ОнПт]
NoSQL,жИЕФЪЧЗЧЙиЯЕЪ§ОнПтЁЃгЩЩЯУцЕФа№ЪіПЩвдПДЕНЙиЯЕаЭЪ§ОнПтжаЕФБэЖМЪЧДцДЂвЛЯТИёЪНЛЏЕФЪ§ОнНсЙЙЃЌУПИідЊзщзжЖЮЕФзщГЩЖМЪЧвЛбљЕФЃЌМДЪЙВЛЪЧУПИідЊзщЖМашвЊЫљгаЕФзжЖЮЃЌЕЋЪ§ОнПтЛсЮЊУПИідЊзщЖМЗжХфЫљгаЕФзжЖЮЃЌетбљЕФНсЙЙПЩвдБугкБэгыБэжЎМфНјааСЌНгЕШВйзїЃЌЕЋДгСэвЛИіНЧЖШРДЫЕЫќвВЪЧЙиЯЕЪ§ОнПтадФмЦПОБЕФвЛИівђЫиЁЃЖјЗЧЙиЯЕЪ§ОнПтвдМќжЕЖдДцДЂЃЌЫќЕФНсЙЙВЛЙЬЖЈЃЌУПвЛИідЊзщПЩвдгаВЛвЛбљЕФзжЖЮЃЌУПИідЊзщПЩвдИљОнашвЊдіМгЛђМѕЩйвЛаЉздМКЕФМќжЕЖдЃЌетбљОЭВЛЛсОжЯогкЙЬЖЈЕФНсЙЙЃЌПЩвдМѕЩйвЛаЉЪБМфКЭПеМфЕФПЊЯњЁЃ
ЙиЯЕаЭЪ§ОнПтвдааКЭСаЕФаЮЪНДцДЂЪ§ОнЃЌвдБугкгУЛЇРэНтЁЃетвЛЯЕСаЕФааКЭСаБЛГЦЮЊБэЃЌвЛзщБэзщГЩСЫЪ§ОнПтЁЃгУЛЇгУВщбЏ(Query)РДМьЫїЪ§ОнПтжаЕФЪ§ОнЁЃвЛИіQueryЪЧвЛИігУгкжИЖЈЪ§ОнПтжаааКЭСаЕФSELECTгяОфЁЃЙиЯЕаЭЪ§ОнПтЭЈГЃАќКЌЯТСазщМўЃК ПЭЛЇЖЫгІгУГЬађ(Client) Ъ§ОнПтЗўЮёЦї(Server) Ъ§ОнПт(Database) Structured Query Language(SQL)ClientЖЫКЭServerЖЫЕФЧХСКЃЌClientгУSQLРДЯѓServerЖЫЗЂЫЭЧыЧѓЃЌServerЗЕЛиClientЖЫвЊЧѓЕФНсЙћЁЃЯждкСїааЕФДѓаЭЙиЯЕаЭЪ§ОнПтгаIBM
DB2ЁЂIBM UDBЁЂOracleЁЂSQL ServerЁЂSyBaseЁЂInformixЕШЁЃ
ЙиЯЕаЭЪ§ОнПтЙмРэЯЕЭГжаДЂДцгыЙмРэЪ§ОнЕФЛљБОаЮЪНЪЧЖўЮЌБэЁЃ
ЙиЯЕаЭЪ§ОнПтЪЧвЛзщвбОБЛзщжЏЮЊБэНсЙЙЕФаХЯЂЕФМЏКЯЁЃетаЉаХЯЂвдБэЕФаЮЪНБЛДцДЂгкДХХЬЁЂДХДјЕШЮяРэНщжЪжаЁЃУПИіБэПЩвдгаЖрааЃЌЖјУПаагжБЛВ№ЗжГЩЖрСаЁЃ
ЙиЯЕаЭЪ§ОнПтвЛећЬзЪ§бЇРэТлЛљДЁЃЌР§ШчЙиЯЕДњЪ§КЭЙиЯЕдЫЫуЪЧЙиЯЕаЭЪ§ОнПтЕФжЛвЊРэТлЛљДЁЁЃ
ШеГЃЩњЛюжаЮвУЧЖдБэНсЙЙЗЧГЃЪьЯЄЃЌР§ШчбЇЩњЕФГЩМЈБэЃЌПЮГЬБэЕШЃЌетаЉБэИёЖМЪЧвдааКЭСаЕФЖўЮЌЗНЪНРДНЋаХЯЂзщжЏдквЛЦ№ЁЃетаЉаХЯЂПЩвдвдИїжжаЮЪНДцдкЃЌР§ШчДђгЁдкжНЩЯЃЌЯдЪОдкЕчФдЕФЦСФЛЩЯЃЌМЧТМдкШЫУЧЕФФдКЃРяЃЌДцдкЗўЮёЦїЕФДХХЬРяЕШЕШЁЃ
ЯждкашвЊвЛжжЗНБуЕФЪжЖЮРДЙмРэетаЉаХЯЂЃЌзюКУЪЧЫцЪБФмВщбЏЃЌаТдіЃЌЩОГ§КЭИќаТЕФЃЌетОЭЪЧЪ§Он
ЙиЯЕЃК
ЁЄЙиЯЕЪЧТњзувЛЖЈЬѕМўЕФЖўЮЌБэЃЌБэжаЕФвЛааГЦЮЊЙиЯЕЕФвЛИідЊзщЃЌгУРДДцДЂЪТЮяЕФвЛИіЪЕР§ЃЛБэжа
ЕФвЛСаГЦЮЊЙиЯЕЕФвЛИіЪєадЃЌгУРДУшЪіЪЕЬхЕФФГвЛЬиеїЁЃБэЪЧгЩвЛзщЯрЙиЪЕЬхзщГЩЕФМЏКЯЁЃЫљвдБэКЭ
ЪЕЬхМЏетСНИіДЪГЃГЃПЩвдНЛЬцЪЙгУЁЃ
ЁЄЙиЯЕЪЧвЛИіаагыСаНЛВцЕФЖўЮЌБэЃЌУПвЛСаЃЈЪєадЃЉЕФЫљгаЪ§ОнЖМЪЧЭЌвЛжжЪ§ОнРраЭЃЌУПвЛСаЖМгаЮЈ
вЛЕФСаУћЃЌСадкБэжаЕФЫГађЮоЙиНєвЊЃЛБэжаЕФШЮвтСНааЃЈдЊзщЃЉВЛФмЯрЭЌЃЌаадкБэжаЕФЫГађвВЮоЙиНє
вЊ
ЙиЯЕЕФЬиеїЃК
ЁЄЙиЯЕЕФУПвЛааЖЈвхЪЕЬхМЏЕФвЛИіЪЕЬхЃЌУПвЛСаЖЈвхЪЕЬхЕФвЛИіЪєад
ЁЄУПвЛааБиаыгавЛИіжїТыЃЌжїТыЪЧвЛИіЪєадзщЃЈПЩвдЪЧвЛИіЪєадЃЉЃЌЫќФмЮЈвЛБъЪЖвЛИіЪЕЬх
ЁЄУПвЛСаБэЪОвЛИіЪєадЃЌЧвСаУћВЛФмжиИД
ЁЄСаЕФУПИіжЕБиаыгыЖдгІЪєадЕФРраЭЯрЭЌ
ЁЄСагаШЁжЕЗЖЮЇЃЌГЦЮЊгђ
ЁЄСаЪЧВЛПЩЗжИюЕФзюаЁЪ§ОнЯю
ЁЄааЁЂСаЕФЫГађЖдгУЛЇЮоЙиНєвЊ
ЙиЯЕаЭЪ§ОнПтгыNOSQL
ЙиЯЕаЭЪ§ОнПтАбЫљгаЕФЪ§ОнЖМЭЈЙ§ааКЭСаЕФЖўдЊБэЯжаЮЪНБэЪОГіРДЁЃ
ЙиЯЕаЭЪ§ОнПтЕФгХЪЦЃК
1. БЃГжЪ§ОнЕФвЛжТадЃЈЪТЮёДІРэЃЉ
2.гЩгквдБъзМЛЏЮЊЧАЬсЃЌЪ§ОнИќаТЕФПЊЯњКмаЁЃЈЯрЭЌЕФзжЖЮЛљБОЩЯЖМжЛгавЛДІЃЉ
3. ПЩвдНјааJoinЕШИДдгВщбЏ
ЦфжаФмЙЛБЃГжЪ§ОнЕФвЛжТадЪЧЙиЯЕаЭЪ§ОнПтЕФзюДѓгХЪЦЁЃ
ЙиЯЕаЭЪ§ОнПтЕФВЛзуЃК
ВЛЩУГЄЕФДІРэ
1. ДѓСПЪ§ОнЕФаДШыДІРэ
2. ЮЊгаЪ§ОнИќаТЕФБэзіЫїв§ЛђБэНсЙЙЃЈschemaЃЉБфИќ
3. зжЖЮВЛЙЬЖЈЪБгІгУ
4. ЖдМђЕЅВщбЏашвЊПьЫйЗЕЛиНсЙћЕФДІРэ
ДѓСПЪ§ОнЕФаДШыДІРэ
ЖСаДМЏжадквЛИіЪ§ОнПтЩЯШУЪ§ОнПтВЛПАжиИКЃЌДѓВПЗжЭјеОвбЪЙгУжїДгИДжЦММЪѕЪЕЯжЖСаДЗжРыЃЌвдЬсИпЖСаДадФмКЭЖСПтЕФПЩРЉеЙадЁЃ
ЫљвддкНјааДѓСПЪ§ОнВйзїЪБЃЌЛсЪЙгУЪ§ОнПтжїДгФЃЪНЁЃЪ§ОнЕФаДШыгЩжїЪ§ОнПтИКд№ЃЌЪ§ОнЕФЖСШыгЩДгЪ§ОнПтИКд№ЃЌПЩвдБШНЯМђЕЅЕиЭЈЙ§діМгДгЪ§ОнПтРДЪЕЯжЙцФЃЛЏЃЌЕЋЪЧЪ§ОнЕФаДШыШДЭъШЋУЛгаМђЕЅЕФЗНЗЈРДНтОіЙцФЃЛЏЮЪЬтЁЃ
ЕквЛЃЌвЊЯыНЋЪ§ОнЕФаДШыЙцФЃЛЏЃЌПЩвдПМТЧАбжїЪ§ОнПтДгвЛЬЈдіМгЕНСНЬЈЃЌзїЮЊЛЅЯрЙиСЊИДжЦЕФЖўдЊжїЪ§ОнПтЪЙгУЃЌШЗЪЕетбљПЩвдАбУПЬЈжїЪ§ОнПтЕФИККЩМѕЩйвЛАыЃЌЕЋЪЧИќаТДІРэЛсЗЂЩњГхЭЛЃЌПЩФмЛсдьГЩЪ§ОнЕФВЛвЛжТЃЌЮЊСЫБмУтетбљЕФЮЪЬтЃЌашвЊАбЖдУПИіБэЕФЧыЧѓЗжБ№ЗжХфИјКЯЪЪЕФжїЪ§ОнПтРДДІРэЁЃ
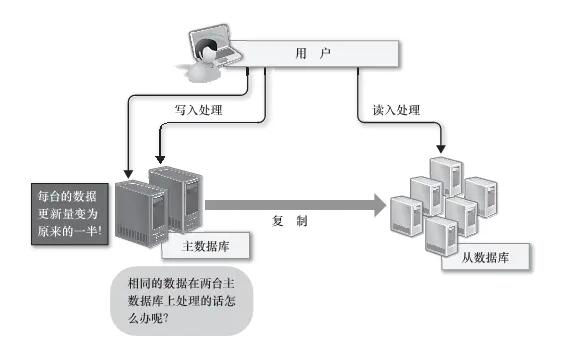
ЕкЖўЃЌПЩвдПМТЧАбЪ§ОнПтЗжИюПЊРДЃЌЗжБ№ЗХдкВЛЭЌЕФЪ§ОнПтЗўЮёЦїЩЯЃЌБШШчНЋВЛЭЌЕФБэЗХдкВЛЭЌЕФЪ§ОнПтЗўЮёЦїЩЯЃЌЪ§ОнПтЗжИюПЩвдМѕЩйУПЬЈЪ§ОнПтЗўЮёЦїЩЯЕФЪ§ОнСПЃЌвдБуМѕЩйгВХЬIOЕФЪфШыЁЂЪфГіДІРэЃЌЪЕЯжФкДцЩЯЕФИпЫйДІРэЁЃЕЋЪЧгЩгкЗжБ№ДцДЂзжВЛЭЌЗўЮёЦїЩЯЕФБэжЎМфЮоЗЈНјааJoinДІРэЃЌЪ§ОнПтЗжИюЕФЪБКђОЭашвЊдЄЯШПМТЧетаЉЮЪЬтЃЌЪ§ОнПтЗжИюжЎКѓЃЌШчЙћвЛЖЈвЊНјааJoinДІРэЃЌОЭБиаывЊдкГЬађжаНјааЙиСЊЃЌетЪЧЗЧГЃРЇФбЕФЁЃ
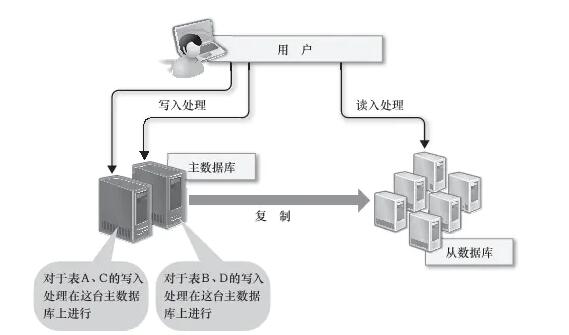
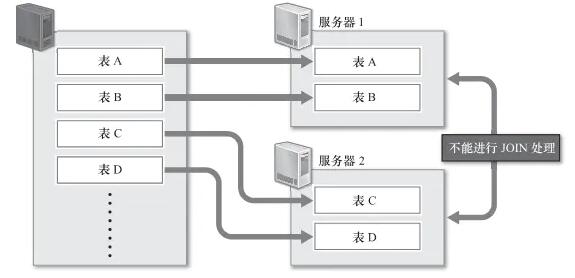
ЮЊгаЪ§ОнИќаТЕФБэзіЫїв§ЛђБэНсЙЙБфИќ
дкЪЙгУЙиЯЕаЭЪ§ОнПтЪБЃЌЮЊСЫМгПьВщбЏЫйЖШашвЊДДНЈЫїв§ЃЌЮЊСЫдіМгБивЊЕФзжЖЮОЭвЛЖЈвЊИФБфБэНсЙЙЃЌЮЊСЫНјааетаЉДІРэЃЌашвЊЖдБэНјааЙВЯэЫјЖЈЃЌетЦкМфЪ§ОнБфИќЁЂИќаТЁЂВхШыЁЂЩОГ§ЕШЖМЪЧЮоЗЈНјааЕФЁЃШчЙћашвЊНјаавЛаЉКФЪБВйзїЃЌР§ШчЮЊЪ§ОнСПБШНЯДѓЕФБэДДНЈЫїв§ЛђЪЧБфИќЦфБэНсЙЙЃЌОЭашвЊЬиБ№зЂвтЃЌГЄЪБМфФкЪ§ОнПЩФмЮоЗЈНјааИќаТЁЃ

зжЖЮВЛЙЬЖЈЪБЕФгІгУ
ШчЙћзжЖЮВЛЙЬЖЈЃЌРћгУЙиЯЕаЭЪ§ОнПтвВЪЧБШНЯРЇФбЕФЃЌгаШЫЛсЫЕЃЌашвЊЕФЪБКђМгИізжЖЮОЭПЩвдСЫЃЌетбљЕФЗНЗЈвВВЛЪЧВЛПЩвдЃЌЕЋдкЪЕМЪдЫгУжаУПДЮЖМНјааЗДИДЕФБэНсЙЙБфИќЪЧЗЧГЃЭДПрЕФЁЃФувВПЩвддЄЯШЩшЖЈДѓСПЕФдЄБИзжЖЮЃЌЕЋетбљЕФЛАЃЌЪБМфвЛГЄКмШнвзХЊВЛЧхГ§зжЖЮКЭЪ§ОнЕФЖдгІзДЬЌЃЌМДФФИізжЖЮБЃДцгаФФаЉЪ§ОнЁЃ
ЖдМђЕЅВщбЏашвЊПьЫйЗЕЛиНсЙћЕФДІРэ ЃЈетРяЕФЁАМђЕЅЁБжИЕФЪЧУЛгаИДдгЕФВщбЏЬѕМўЃЉ
етвЛЕуГЦВЛЩЯЪЧШБЕуЃЌЕЋВЛЙмдѕбљЃЌЙиЯЕаЭЪ§ОнПтВЂВЛЩУГЄЖдМђЕЅЕФВщбЏПьЫйЗЕЛиНсЙћЃЌвђЮЊЙиЯЕаЭЪ§ОнПтЪЧЪЙгУзЈУХЕФsqlгябдНјааЪ§ОнЖСШЁЕФЃЌЫќашвЊЖдsqlгыдНФЯНјааНтЮіЃЌЭЌЪБЛЙгаЖдБэЕФЫјЖЈКЭНтЫјЕШетбљЕФЖюЭтПЊЯњЃЌетРяВЂВЛЪЧЫЕЙиЯЕаЭЪ§ОнПтЕФЫйЖШЬЋТ§ЃЌЖјжЛЪЧЯыИцЫпДѓМвШєЯЃЭћЖдМђЕЅВщбЏНјааИпЫйДІРэЃЌдђУЛгаБивЊЗЧЪЙгУЙиЯЕаЭЪ§ОнПтВЛПЩЁЃ
NoSQLЪ§ОнПт
ЙиЯЕаЭЪ§ОнПтгІгУЙуЗКЃЌФмНјааЪТЮёДІРэКЭБэСЌНгЕШИДдгВщбЏЁЃЯрЖдЕиЃЌNoSQLЪ§ОнПтжЛгІгУдкЬиЖЈСьгђЃЌЛљБОЩЯВЛНјааИДдгЕФДІРэЃЌЕЋЫќЧЁЧЁУжВЙСЫжЎЧАЫљСаОйЕФЙиЯЕаЭЪ§ОнПтЕФВЛзужЎДІЁЃ
гХЕуЃК
взгкЪ§ОнЕФЗжЩЂ
ИїИіЪ§ОнжЎМфДцдкЙиСЊЪЧЙиЯЕаЭЪ§ОнПтЕУУћЕФжївЊдвђЃЌЮЊСЫНјааjoinДІРэЃЌЙиЯЕаЭЪ§ОнПтВЛЕУВЛАбЪ§ОнДцДЂдкЭЌвЛИіЗўЮёЦїФкЃЌетВЛРћгкЪ§ОнЕФЗжЩЂЃЌетвВЪЧЙиЯЕаЭЪ§ОнПтВЂВЛЩУГЄДѓЪ§ОнСПЕФаДШыДІРэЕФдвђЁЃЯрЗДNoSQLЪ§ОнПтдБООЭВЛжЇГжJoinДІРэЃЌИїИіЪ§ОнЖМЪЧЖРСЂЩшМЦЕФЃЌКмШнвзАбЪ§ОнЗжЩЂдкЖрИіЗўЮёЦїЩЯЃЌЙЪМѕЩйСЫУПИіЗўЮёЦїЩЯЕФЪ§ОнСПЃЌМДЪЙвЊДІРэДѓСПЪ§ОнЕФаДШыЃЌвВБфЕУИќМгШнвзЃЌЪ§ОнЕФЖСШыВйзїЕБШЛвВЭЌбљШнвзЁЃ
ЕфаЭЕФNoSQLЪ§ОнПт
СйЪБадМќжЕДцДЂЃЈmemcachedЁЂRedisЃЉЁЂгРОУадМќжЕДцДЂЃЈROMAЁЂRedisЃЉЁЂУцЯђЮФЕЕЕФЪ§ОнПтЃЈMongoDBЁЂCouchDBЃЉЁЂУцЯђСаЕФЪ§ОнПтЃЈCassandraЁЂHBaseЃЉ
вЛЁЂ МќжЕДцДЂ
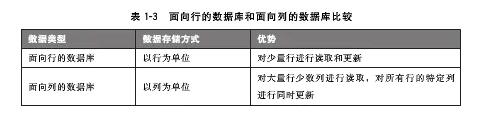
ЫќЕФЪ§ОнЪЧвдМќжЕЕФаЮЪНДцДЂЕФЃЌЫфШЛЫќЕФЫйЖШЗЧГЃПьЃЌЕЋЛљБОЩЯжЛФмЭЈЙ§МќЕФЭъШЋвЛжТВщбЏЛёШЁЪ§ОнЃЌИљОнЪ§ОнЕФБЃДцЗНЪНПЩвдЗжЮЊСйЪБадЁЂгРОУадКЭСНепМцОп
Ш§жжЁЃ
ЃЈ1ЃЉСйЪБад
ЫљЮНСйЪБадОЭЪЧЪ§ОнгаПЩФмЖЊЪЇЃЌmemcachedАбЫљгаЪ§ОнЖМБЃДцдкФкДцжаЃЌетбљБЃДцКЭЖСШЁЕФЫйЖШЗЧГЃПьЃЌЕЋЪЧЕБmemcachedЭЃжЙЪБЃЌЪ§ОнОЭВЛДцдкСЫЁЃгЩгкЪ§ОнБЃДцдкФкДцжаЃЌЫљвдЮоЗЈВйзїГЌГіФкДцШнСПЕФЪ§ОнЃЌОЩЪ§ОнЛсЖЊЪЇЁЃзмНсРДЫЕЃК
ЁЃдкФкДцжаБЃДцЪ§Он
ЁЃПЩвдНјааЗЧГЃПьЫйЕФБЃДцКЭЖСШЁДІРэ
ЁЃЪ§ОнгаПЩФмЖЊЪЇ
ЃЈ2ЃЉгРОУад
ЫљЮНгРОУадОЭЪЧЪ§ОнВЛЛсЖЊЪЇЃЌетРяЕФМќжЕДцДЂЪЧАбЪ§ОнБЃДцдкгВХЬЩЯЃЌгыСйЪБадБШЦ№РДЃЌгЩгкБиШЛвЊЗЂЩњЖдгВХЬЕФIOВйзїЃЌЫљвдадФмЩЯЛЙЪЧгаВюОрЕФЃЌЕЋЪ§ОнВЛЛсЖЊЪЇЪЧЫќзюДѓЕФгХЪЦЁЃзмНсРДЫЕЃК
ЁЃдкгВХЬЩЯБЃДцЪ§Он
ЁЃПЩвдНјааЗЧГЃПьЫйЕФБЃДцКЭЖСШЁДІРэЃЈЕЋЮоЗЈгыmemcachedЯрБШЃЉ
ЁЃЪ§ОнВЛЛсЖЊЪЇ
ЃЈ3ЃЉ СНепМцБИ
RedisЪєгкетжжРраЭЁЃRedisгааЉЬиЪтЃЌСйЪБадКЭгРОУадМцОпЁЃRedisЪзЯШАбЪ§ОнБЃДцдкФкДцжаЃЌдкТњзуЬиЖЈЬѕМўЃЈФЌШЯЪЧ
15ЗжжгвЛДЮвдЩЯЃЌ5ЗжжгФк10ИівдЩЯЃЌ1ЗжжгФк10000ИівдЩЯЕФМќЗЂЩњБфИќЃЉЕФЪБКђНЋЪ§ОнаДШыЕНгВХЬжаЃЌетбљМШШЗБЃСЫФкДцжаЪ§ОнЕФДІРэЫйЖШЃЌгжПЩвдЭЈЙ§аДШыгВХЬРДБЃжЄЪ§ОнЕФгРОУадЃЌетжжРраЭЕФЪ§ОнПтЬиБ№ЪЪКЯДІРэЪ§зщРраЭЕФЪ§ОнЁЃзмНсРДЫЕЃК
ЁЃЭЌЪБдкФкДцКЭгВХЬЩЯБЃДцЪ§Он
ЁЃПЩвдНјааЗЧГЃПьЫйЕФБЃДцКЭЖСШЁДІРэ
ЁЃБЃДцдкгВХЬЩЯЕФЪ§ОнВЛЛсЯћЪЇЃЈПЩвдЛжИДЃЉ
ЁЃЪЪКЯгкДІРэЪ§зщРраЭЕФЪ§Он
ЖўЁЂУцЯђЮФЕЕЕФЪ§ОнПт
MongoDBЁЂCouchDBЪєгкетжжРраЭЃЌЫќУЧЪєгкNoSQLЪ§ОнПтЃЌЕЋгыМќжЕДцДЂЯрвьЁЃ
ЃЈ1ЃЉВЛЖЈвхБэНсЙЙ
МДЪЙВЛЖЈвхБэНсЙЙЃЌвВПЩвдЯёЖЈвхСЫБэНсЙЙвЛбљЪЙгУЃЌЛЙЪЁШЅСЫБфИќБэНсЙЙЕФТщЗГЁЃ
ЃЈ2ЃЉПЩвдЪЙгУИДдгЕФВщбЏЬѕМў
ИњМќжЕДцДЂВЛЭЌЕФЪЧЃЌУцЯђЮФЕЕЕФЪ§ОнПтПЩвдЭЈЙ§ИДдгЕФВщбЏЬѕМўРДЛёШЁЪ§ОнЃЌЫфШЛВЛОпБИЪТЮёДІРэКЭJoinетаЉЙиЯЕаЭЪ§ОнПтЫљОпгаЕФДІРэФмСІЃЌЕЋГѕДЮвдЭтЕФЦфЫћДІРэЛљБОЩЯЖМФмЪЕЯжЁЃ
Ш§ЁЂ УцЯђСаЕФЪ§ОнПт
CassandraЁЂHBaeЁЂHyperTableЪєгкетжжРраЭЃЌгЩгкНќФъРДЪ§ОнСПГіЯжБЌЗЂаддіГЄЃЌетжжРраЭЕФNoSQLЪ§ОнПтгШЦфв§ШызЂФПЁЃ
ЦеЭЈЕФЙиЯЕаЭЪ§ОнПтЖМЪЧвдааЮЊЕЅЮЛРДДцДЂЪ§ОнЕФЃЌЩУГЄвдааЮЊЕЅЮЛЕФЖСШыДІРэЃЌБШШчЬиЖЈЬѕМўЪ§ОнЕФЛёШЁЁЃвђДЫЃЌЙиЯЕаЭЪ§ОнПтвВБЛГЩЮЊУцЯђааЕФЪ§ОнПтЁЃЯрЗДЃЌУцЯђСаЕФЪ§ОнПтЪЧвдСаЮЊЕЅЮЛРДДцДЂЪ§ОнЕФЃЌЩУГЄвдСаЮЊЕЅЮЛЖСШыЪ§ОнЁЃ
УцЯђСаЕФЪ§ОнПтОпгаИуРЉеЙадЃЌМДЪЙЪ§ОндіМгвВВЛЛсНЕЕЭЯргІЕФДІРэЫйЖШЃЈЬиБ№ЪЧаДШыЫйЖШЃЉЃЌЫљвдЫќжївЊгІгУгкашвЊДІРэДѓСПЪ§ОнЕФЧщПіЁЃСэЭтЃЌАбЫќзїЮЊХњДІРэГЬађЕФДцДЂЦїРДЖдДѓСПЪ§ОнНјааИќаТвВЪЧЗЧГЃгагУЕФЁЃЕЋгЩгкУцЯђСаЕФЪ§ОнПтИњЯжааЪ§ОнПтДцДЂЕФЫМЮЌЗНЪНгаКмДѓВЛЭЌЃЌЙЪгІгУЦ№РДЪЎЗжРЇФбЁЃ
змНсЃКЙиЯЕаЭЪ§ОнПтгыNoSQLЪ§ОнПтВЂЗЧЖдСЂЖјЪЧЛЅВЙЕФЙиЯЕЃЌМДЭЈГЃЧщПіЯТЪЙгУЙиЯЕаЭЪ§ОнПтЃЌдкЪЪКЯЪЙгУNoSQLЕФЪБКђЪЙгУNoSQLЪ§ОнПтЃЌШУNoSQLЪ§ОнПтЖдЙиЯЕаЭЪ§ОнПтЕФВЛзуНјааУжВЙЁЃ
| 







