| Īŗľ≠Õ∆ľŲ: |
Īĺőń÷ų“™Ĺť…‹ŃňInnoDBŐŚŌĶľ‹ĻĻ°ĘCheckPointľľ ű°ĘInnoDBĻōľŁŐō–‘Ķ»ŌŗĻōńŕ»›°£
Īĺőńņī◊‘ľÚ ť£¨”…ĽūŃķĻŻ»ŪľĢAnnaĪŗľ≠°ĘÕ∆ľŲ°£
|
|
ī”Mysql5.5įśĪĺŅ™ ľ£¨InnoDB «ń¨»ŌĶńĪŪīśīĘ“ż«ś°£∆šŐōĶ„ «––ňÝ…Ťľ∆°Ę÷ß≥÷MVCC°Ę÷ß≥÷Õ‚ľŁ°ĘŐŠĻ©“Ľ÷¬–‘∑«ňÝ∂®∂Ń°ĘÕ¨ ĪĪĽ…Ťľ∆”√ņī◊Ó”––ßĶńņŻ”√“‘ľį Ļ”√ńŕīśļÕCPU°£
Īĺőń÷ų“™ńŕ»›£ļ
InnoDBŐŚŌĶľ‹ĻĻ
CheckPointľľ ű
InnoDBĻōľŁŐō–‘
“Ľ°ĘInnoDBŐŚŌĶľ‹ĻĻ
Ō¬ÕľľÚĶ•√Ť ŲŃňInnoDBīśīĘ“ż«śĶńŐŚŌĶĹŠĻĻ£ļ
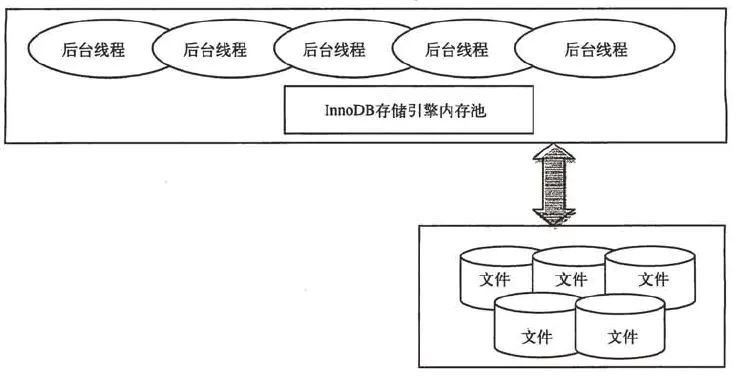
InnoDBīśīĘ“ż«ś”–∂ŗłŲńŕīśŅť£¨’‚–©ńŕīśŅť◊ť≥…Ńň“ĽłŲīůĶńńŕīś≥ō°£ļůŐ®ŌŖ≥Ő÷ų“™łļ‘ūňĘ–¬ńŕīś≥ō÷–Ķń żĺ›°ĘĹę“—–řłńĶń żĺ›ňĘ–¬ĶĹīŇŇŐĶ»Ķ»°£Ĺ”Ō¬ņīő“√«∑÷ĪūĹť…‹ļůŐ®ŌŖ≥ŐļÕńŕīś≥ō°£
1.1 ļůŐ®ŌŖ≥Ő
InnoDBļůŐ®”–∂ŗłŲ≤ĽÕ¨ĶńŌŖ≥Ő£¨”√ņīłļ‘ū≤ĽÕ¨Ķń»őőŮ°£÷ų“™”–»ÁŌ¬£ļ
Master Thread
’‚ «◊Óļň–ńĶń“ĽłŲŌŖ≥Ő,÷ų“™łļ‘ūĹęĽļ≥Ś≥ō÷–Ķń żĺ›“ž≤ĹňĘ–¬ĶĹīŇŇŐ,Ī£÷§ żĺ›Ķń“Ľ÷¬–‘,įŁņ®‘Ŗ“≥ĶńňĘ–¬°ĘļŌ≤Ę≤Ś»ŽĽļ≥Ś°ĘUNDO
“≥ĶńĽō ’Ķ».
IO Thread
‘ŕ InnoDB īśīĘ“ż«ś÷–īůŃŅ Ļ”√Ńň“ž≤Ĺ IO ņīī¶ņŪ–ī IO «Ž«ů, IO Thread ĶńĻ§◊ų÷ų“™ «łļ‘ū’‚–©
IO «Ž«ůĶńĽōĶųī¶ņŪ°£
Purge Thread
¬őŮĪĽŐŠĹĽ÷ģļů, undo log Ņ…ń‹≤Ľ‘Ŕ–Ť“™,“Úīň–Ť“™ Purge Thread ņīĽō ’“—ĺ≠ Ļ”√≤Ę∑÷ŇšĶń
undo“≥. InnoDB ÷ß≥÷∂ŗłŲ Purge Thread, ’‚—ý◊ŲŅ…“‘ľ”Ņž undo “≥ĶńĽō ’°£
Page Cleaner Thread
Page Cleaner Thread «‘ŕInnoDB 1.2.xįśĪĺ–¬“ż»ŽĶń,∆š◊ų”√ «Ĺę÷ģ«įįśĪĺ÷–‘ŗ“≥ĶńňĘ–¬≤Ŕ◊ų∂ľ∑Ň»ŽĶ•∂ņĶńŌŖ≥Ő÷–ņīÕÍ≥…,’‚—ýľű«ŠŃň
Master Thread ĶńĻ§◊ųľį∂‘”ŕ”√Ľß≤ť—ĮŌŖ≥ŐĶń◊Ť»Ż°£
1.2 ńŕīś
’‚“Ľ≤Ņ∑÷£¨ő“ĹęÕÝ…ŌĶńĪ»ĹŌļ√Ķń◊ ŃŌĺ°Ń¶»•◊ŘļŌ£¨÷ĪĻŘĶń√Ť Ų≥Ųņī°£
InnoDB īśīĘ“ż«ś «Ľý”ŕīŇŇŐīśīĘĶń,“≤ĺÕ «ňĶ żĺ›∂ľ «īśīĘ‘ŕīŇŇŐ…ŌĶń,”…”ŕ CPU ňŔ∂»ļÕīŇŇŐňŔ∂»÷ģľšĶńļŤĻĶ,
InnoDB “ż«ś Ļ”√Ľļ≥Ś≥ōľľ űņīŐŠłŖ żĺ›Ņ‚Ķń’ŻŐŚ–‘ń‹°£Ľļ≥Ś≥ōľÚĶ•ņīňĶĺÕ «“ĽŅťńŕīś«Ý”Ú.‘ŕ żĺ›Ņ‚÷–ĹÝ––∂Ń»°“≥Ķń≤Ŕ◊ų, ◊Ō»Ĺęī”īŇŇŐ∂ŃĶĹĶń“≥īś∑Ň‘ŕĽļ≥Ś≥ō÷–,Ō¬“Ľīő∂Ń»°ŌŗÕ¨Ķń“≥ Ī, ◊Ō»Ň–∂Ōł√“≥ «≤Ľ «‘ŕĽļ≥Ś≥ō÷–,»Ű‘ŕ,≥∆ł√“≥‘ŕĽļ≥Ś≥ō÷–ĪĽ√Ł÷–,÷ĪĹ”∂Ń»°ł√“≥°£∑Ů‘Ú,∂Ń»°īŇŇŐ…ŌĶń“≥°£∂‘”ŕ żĺ›Ņ‚÷–“≥Ķń–řłń≤Ŕ◊ų, ◊Ō»–řłń‘ŕĽļ≥Ś≥ō÷–“≥,»Ľļů‘Ŕ“‘“Ľ∂®Ķń∆Ķ¬ ňĘ–¬ĶĹīŇŇŐ,≤Ę≤Ľ «√Ņīő“≥∑Ę…ķłńĪšĺÕňĘ–¬ĽōīŇŇŐ°£
Ľļ≥Ś≥ō÷–ĽļīśĶń żĺ›“≥ņŗ–Õ”–:ňų“ż“≥°Ę żĺ›“≥°Ę undo “≥°Ę≤Ś»ŽĽļ≥Ś°Ę◊‘ ”¶ĻĢŌ£ňų“ż°Ę
InnoDB ĶńňÝ–ŇŌĘ°Ę żĺ›◊÷Ķš–ŇŌĘĶ»°£ňų“ż“≥ļÕ żĺ›“≥’ľĽļ≥Ś≥ōĶńļ‹īů“Ľ≤Ņ∑÷£®÷™Ķņ”–’‚–©“≥£¨į—’‚–©“≥ĶĪ◊Ų√Żī ľīŅ…£¨≤Ľ”√ł–ĶĹ√‘Ľů£©°£‘ŕInnoDB÷–£¨Ľļ≥Ś≥ō÷–Ķń“≥īů–°ń¨»Ōő™16KB°£
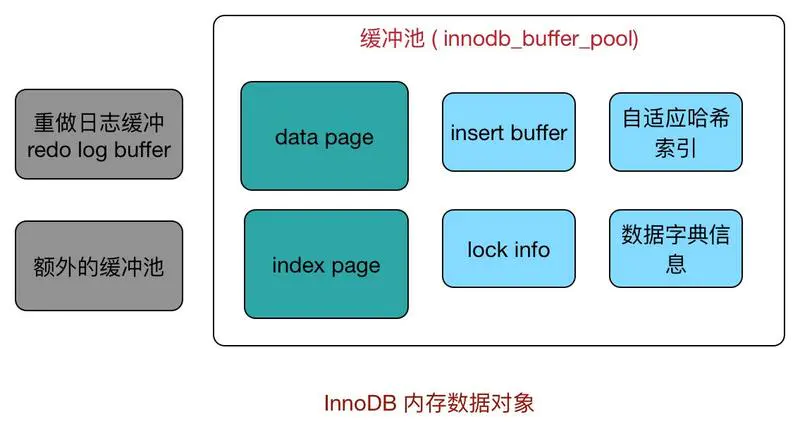
ő“√«“—ĺ≠÷™Ķņ’‚łŲBuffer Pool∆š Ķ «“Ľ∆¨Ń¨–ÝĶńńŕīśŅ’ľš£¨ń«Ō÷‘ŕĺÕ√śŃŔ’‚łŲő Ő‚Ńň£ļ‘ű√īĹęīŇŇŐ…ŌĶń“≥ĽļīśĶĹńŕīś÷–ĶńBuffer
Pool÷–ńō£Ņ÷ĪĹ”į—–Ť“™ĽļīśĶń“≥ŌÚBuffer PoolņÔ“ĽłŲ“ĽłŲÕýņÔŪ°√ī£Ņ≤Ľ≤Ľ≤Ľ£¨ő™ŃňłŁļ√ĶńĻ‹ņŪ’‚–©ĪĽĽļīśĶń“≥£¨InnoDBő™√Ņ“ĽłŲĽļīś“≥∂ľīīĹ®Ńň“Ľ–©ňýőĹĶńŅō÷∆–ŇŌĘ£¨’‚–©Ņō÷∆–ŇŌĘįŁņ®ł√“≥ňý ŰĶńĪŪŅ’ľšĪŗļŇ°Ę“≥ļŇ°Ę“≥‘ŕBuffer
Pool÷–ĶńĶō÷∑£¨“Ľ–©ňÝ–ŇŌĘ“‘ľįLSN–ŇŌĘ£®ňÝļÕLSN’‚ņÔŅ…“‘Ō»ļŲ¬‘£©£¨ĶĪ»ĽĽĻ”–“Ľ–©ĪūĶńŅō÷∆–ŇŌĘ°£
√ŅłŲĽļīś“≥∂‘”¶ĶńŅō÷∆–ŇŌĘ’ľ”√Ķńńŕīśīů–° «ŌŗÕ¨Ķń£¨ő“√«ĺÕį—√ŅłŲ“≥∂‘”¶ĶńŅō÷∆–ŇŌĘ’ľ”√Ķń“ĽŅťńŕīś≥∆ő™“ĽłŲŅō÷∆Ņťį…£¨Ņō÷∆ŅťļÕĽļīś“≥ «“Ľ“Ľ∂‘”¶Ķń£¨ňŁ√«∂ľĪĽīś∑ŇĶĹ
Buffer Pool ÷–£¨∆š÷–Ņō÷∆ŅťĪĽīś∑ŇĶĹ Buffer Pool Ķń«įĪŖ£¨Ľļīś“≥ĪĽīś∑ŇĶĹ Buffer
Pool ļůĪŖ£¨ňý“‘’ŻłŲBuffer Pool∂‘”¶ĶńńŕīśŅ’ľšŅī∆ūņīĺÕ «’‚—ýĶń£ļ

Ņō÷∆ŅťļÕĽļīś“≥÷ģľšĶńń«łŲňť∆¨ «łŲ ≤√īńō£Ņń„ŌŽŌŽį°£¨√Ņ“ĽłŲŅō÷∆Ņť∂ľ∂‘”¶“ĽłŲĽļīś“≥£¨ń«‘ŕ∑÷Ňš◊„ĻĽ∂ŗĶńŅō÷∆ŅťļÕĽļīś“≥ļů£¨Ņ…ń‹ £”ŗĶńń«Ķ„∂ýŅ’ľš≤ĽĻĽ“Ľ∂‘Ņō÷∆ŅťļÕĽļīś“≥Ķńīů–°£¨◊‘»ĽĺÕ”√≤ĽĶĹŗ∂£¨’‚łŲ”√≤ĽĶĹĶńń«Ķ„∂ýńŕīśŅ’ľšĺÕĪĽ≥∆ő™ňť∆¨Ńň°£ĶĪ»Ľ£¨»ÁĻŻń„į—Buffer
PoolĶńīů–°…Ť÷√Ķńł’ł’ļ√ĶńĽį£¨“≤Ņ…ń‹≤ĽĽŠ≤ķ…ķňť∆¨°ę
«į√śő“√«÷™ĶņŃňĽļ≥Ś≥ōĶńĹŠĻĻ°£Ĺ”Ō¬ņīňĶInnoDBīśīĘ“ż«ś «‘ű√ī∂‘Ľļ≥Ś≥ōĹÝ––Ļ‹ņŪĶń°£Ĺ≤Ō¬ő“ĶĪ ĪĶńņ߼ůį…£¨£®’‚≤Ņ∑÷Ņ…“‘≤ĽŅī£¨“Úő™”––©√Żī ĽĻ√Ľ…śľįĶĹ£©Ņī°∂Mysqlľľ űńŕńĽ°∑’‚Īĺ ť£¨Ĺ≤LRU
ListĪ»ĹŌ∂ŗ£¨Free List÷Ľ «ň≥īÝ“ĽĻż£¨√Ľ”–Ĺęfree list≥ű ľ Ī «‘ű√ī∑÷ŇšĶńĽÚ’Ŗ « ≤√ī—ýĶńĹŠĻĻ£¨Ķľ÷¬ő“∂‘Ľļ≥Ś≥ōĶńĻ‹ņŪ◊‹ «ŌŽŌů≤Ľ≥Ųņī£¨ļůņīĺ≠Ļż‘ŕÕÝ…Ō—į’“◊ ŃŌ£¨ň„ «Ň™√ųį◊Ńň°£ņīŅī“ĽŌ¬į…£ļ
ĶĪő“√«◊Ó≥ű∆Ű∂ĮMySQL∑ĢőŮ∆ųĶń ĪļÚ£¨–Ť“™ÕÍ≥…∂‘Buffer PoolĶń≥ű ľĽĮĻż≥Ő£¨ĺÕ «∑÷ŇšBuffer
PoolĶńńŕīśŅ’ľš£¨į—ňŁĽģ∑÷≥…»Űł…∂‘Ņō÷∆ŅťļÕĽļīś“≥°£Ķę «īň Ī≤Ę√Ľ”–’ś ĶĶńīŇŇŐ“≥ĪĽĽļīśĶĹBuffer
Pool÷–£®“Úő™ĽĻ√Ľ”–”√ĶĹ£©£¨÷ģļůňś◊Ň≥Ő–ÚĶń‘ň––£¨ĽŠ≤Ľ∂ŌĶń”–īŇŇŐ…ŌĶń“≥ĪĽĽļīśĶĹBuffer Pool÷–£¨ń«√īő Ő‚ņīŃň£¨ī”īŇŇŐ…Ō∂Ń»°“ĽłŲ“≥ĶĹBuffer
Pool÷–Ķń ĪļÚł√∑ŇĶĹńńłŲĽļīś“≥ĶńőĽ÷√ńō£ŅĽÚ’ŖňĶ‘ű√ī«Ý∑÷Buffer Pool÷–ńń–©Ľļīś“≥ «Ņ’Ō–Ķń£¨ńń–©“—ĺ≠ĪĽ Ļ”√Ńňńō£Ņő“√«◊Óļ√‘ŕń≥łŲĶō∑Ĺľ«¬ľ“ĽŌ¬ńń–©“≥ «Ņ…”√Ķń£¨ő“√«Ņ…“‘į—ňý”–Ņ’Ō–Ķń“≥įŁ◊į≥…“ĽłŲĹŕĶ„◊ť≥…“ĽłŲŃīĪŪ£¨’‚łŲŃīĪŪ“≤Ņ…“‘ĪĽ≥∆◊ųFreeŃīĪŪ£®ĽÚ’ŖňĶŅ’Ō–ŃīĪŪ£©°£“Úő™ł’ł’ÕÍ≥…≥ű ľĽĮĶńBuffer
Pool÷–ňý”–ĶńĽļīś“≥∂ľ «Ņ’Ō–Ķń£¨ňý“‘√Ņ“ĽłŲĽļīś“≥∂ľĽŠĪĽľ”»ŽĶĹFreeŃīĪŪ÷–£¨ľŔ…Ťł√Buffer Pool÷–Ņ…»›ń…ĶńĽļīś“≥ żŃŅő™n£¨ń«‘Ųľ”ŃňFreeŃīĪŪĶń–ßĻŻÕľĺÕ «’‚—ýĶń£ļ
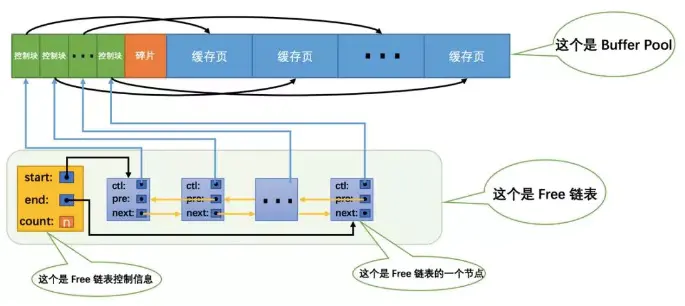
ī”Õľ÷–Ņ…“‘Ņī≥Ų£¨ő“√«ő™ŃňĻ‹ņŪļ√’‚łŲFreeŃīĪŪ£¨Őō“‚ő™’‚łŲŃīĪŪ∂®“ŚŃň“ĽłŲŅō÷∆–ŇŌĘ£¨ņÔĪŖ∂ýįŁļ¨◊ŇŃīĪŪĶńÕ∑ĹŕĶ„Ķō÷∑£¨ő≤ĹŕĶ„Ķō÷∑£¨“‘ľįĶĪ«įŃīĪŪ÷–ĹŕĶ„Ķń żŃŅĶ»–ŇŌĘ°£ő“√«‘ŕ√ŅłŲFreeŃīĪŪĶńĹŕĶ„÷–∂ľľ«¬ľŃňń≥łŲĽļīś“≥Ņō÷∆ŅťĶńĶō÷∑£¨∂Ý√ŅłŲĽļīś“≥Ņō÷∆Ņť∂ľľ«¬ľ◊Ň∂‘”¶ĶńĽļīś“≥Ķō÷∑£¨ňý“‘ŌŗĶĪ”ŕ√ŅłŲFreeŃīĪŪĹŕĶ„∂ľ∂‘”¶“ĽłŲŅ’Ō–ĶńĽļīś“≥°£
”–Ńň’‚łŲFreeŃīĪŪ ¬∂ýĺÕļ√įžŃň£¨√ŅĶĪ–Ť“™ī”īŇŇŐ÷–ľ”‘ō“ĽłŲ“≥ĶĹBuffer Pool÷– Ī£¨ĺÕī”FreeŃīĪŪ÷–»°“ĽłŲŅ’Ō–ĶńĽļīś“≥£¨≤Ę«“į—ł√Ľļīś“≥∂‘”¶ĶńŅō÷∆ŅťĶń–ŇŌĘŐÓ…Ō£¨»Ľļůį—ł√Ľļīś“≥∂‘”¶ĶńFreeŃīĪŪĹŕĶ„ī”ŃīĪŪ÷–“∆≥ż£¨ĪŪ ĺł√Ľļīś“≥“—ĺ≠ĪĽ Ļ”√Ńň°ę
ő“ĺűĶ√‘≠◊ų’Ŗ’‚≤Ņ∑÷Ĺ≤Ķń∑«≥£ļ√£¨Õľ“≤ļ‹”√–ń£¨÷ĪŔłĺŲŃňő“Ķń“…ő °£
≤Ľ“™“Úő™◊ŖĶńŐę‘∂∂ÝÕŁľ«ő™ ≤√ī≥Ų∑Ę°£
ľÚĶ•ĽōĻň“ĽŌ¬£¨ő™ ≤√īĹ≤free list£Ņ «ő™ŃňĹ≤‘ű√īĻ‹ņŪbuffer pool∂‘į…°£ń«free listĺÕŌŗĶĪ”ŕ « żĺ›Ņ‚∑ĢőŮł’ł’∆Ű∂Į√Ľ”– żĺ›“≥ Ī£¨ő¨Ľ§buffer
poolĶńŅ’Ō–Ľļīś“≥Ķń żĺ›ĹŠĻĻ°£
Ō¬√ś‘ŔņīľÚĶ•ĶōĽōĻňBuffer PoolĶńĻ§◊ųĽķ÷∆°£Buffer PoolŃĹłŲ◊Ó÷ų“™ĶńĻ¶ń‹£ļ“ĽłŲ «ľ”ňŔ∂Ń£¨“ĽłŲ «ľ”ňŔ–ī°£ľ”ňŔ∂Ńńō£Ņ
ĺÕ «ĶĪ–Ť“™∑√ő “ĽłŲ żĺ›“≥√śĶń ĪļÚ£¨»ÁĻŻ’‚łŲ“≥√ś“—ĺ≠‘ŕĽļīś≥ō÷–£¨ń«√īĺÕ≤Ľ‘Ŕ–Ť“™∑√ő īŇŇŐ£¨÷ĪĹ”ī”Ľļ≥Ś≥ō÷–ĺÕń‹ĽŮ»°’‚łŲ“≥√śĶńńŕ»›°£ľ”ňŔ–īńō£ŅĺÕ «ĶĪ–Ť“™–řłń“ĽłŲ“≥√śĶń ĪļÚ£¨Ō»Ĺę’‚łŲ“≥√ś‘ŕĽļ≥Ś≥ō÷–ĹÝ–––řłń£¨ľ«Ō¬ŌŗĻōĶń÷ō◊Ų»’÷ĺ£¨’‚łŲ“≥√śĶń–řłńĺÕň„“—ĺ≠ÕÍ≥…Ńň°£÷Ń”ŕ’‚łŲĪĽ–řłńĶń“≥√ś ≤√ī ĪļÚ’ś’żňĘ–¬ĶĹīŇŇŐ£¨’‚łŲ «ļůŐ®ňĘ–¬ŌŖ≥ŐņīÕÍ≥…Ķń°£
‘ŕ ĶŌ÷…Ō√śŃĹłŲĻ¶ń‹ĶńÕ¨ Ī£¨–Ť“™Ņľ¬«ŅÕĻŘŐűľĢĶńŌř÷∆£¨“Úő™Ľķ∆ųĶńńŕīśīů–° «”–ŌřĶń£¨ňý“‘MySQLĶńInnoDB
Buffer PoolĶńīů–°Õ¨—ý «”–ŌřĶń£¨»ÁĻŻ–Ť“™ĽļīśĶń“≥’ľ”√Ķńńŕīśīů–°≥¨ĻżŃňBuffer Poolīů–°£¨“≤ĺÕ «FreeŃīĪŪ÷–“—ĺ≠√Ľ”–∂ŗ”ŗĶńŅ’Ō–Ľļīś“≥Ķń ĪļÚ∆Ů≤Ľ «ļ‹řŌřő£¨∑Ę…ķŃň’‚—ýĶń ¬∂ýł√’¶įž£ŅĶĪ»Ľ «į—ń≥–©ĺ…ĶńĽļīś“≥ī”Buffer
Pool÷–“∆≥ż£¨»Ľļů‘Ŕį—–¬Ķń“≥∑ŇĹÝņīŗ∂°ę ń«√īő Ő‚ņīŃň£¨“∆≥żńń–©Ľļīś“≥ńō£Ņ
ő™ŃňĽōīū’‚łŲő Ő‚£¨ő“√«ĽĻ–Ť“™ĽōĶĹő“√«…ŤŃĘBuffer PoolĶń≥ű÷‘£¨ő“√«ĺÕ «ŌŽľű…ŔļÕīŇŇŐĶńI/OĹĽĽ•£¨◊Óļ√√Ņīő‘ŕ∑√ő ń≥łŲ“≥Ķń ĪļÚňŁ∂ľ“—ĺ≠ĪĽĽļīśĶĹBuffer
Pool÷–Ńň°£ľŔ…Ťő“√«“ĽĻ≤∑√ő Ńňnīő“≥£¨ń«√īĪĽ∑√ő Ķń“≥“—ĺ≠‘ŕĽļīś÷–Ķńīő ż≥ż“‘nĺÕ «ňýőĹĶńĽļīś√Ł÷–¬ £¨ő“√«Ķń∆ŕÕŻĺÕ «»√Ľļīś√Ł÷–¬ ‘ĹłŖ‘Ĺļ√°ę
‘ű√īŐŠłŖĽļīś√Ł÷–¬ ńō£ŅInnoDB Buffer Pool≤…”√ĺ≠ĶšĶńLRUň„∑®ņīĹÝ––“≥√śŐ‘Ő≠£¨“‘ŐŠłŖĽļīś√Ł÷–¬ °£ĶĪBuffer
Pool÷–≤Ľ‘Ŕ”–Ņ’Ō–ĶńĽļīś“≥ Ī£¨ĺÕ–Ť“™Ő‘Ő≠ĶŰ≤Ņ∑÷◊ÓĹŁļ‹…Ŕ Ļ”√ĶńĽļīś“≥°£≤ĽĻż£¨ő“√«‘ű√ī÷™Ķņńń–©Ľļīś“≥◊ÓĹŁ∆Ķ∑Ī Ļ”√£¨ńń–©◊ÓĹŁļ‹…Ŕ Ļ”√ńō£Ņļ«ļ«£¨…Ů∆śĶńŃīĪŪ‘Ŕ“ĽīőŇ……ŌŃň”√≥°£¨ő“√«Ņ…“‘‘ŔīīĹ®“ĽłŲŃīĪŪ£¨”…”ŕ’‚łŲŃīĪŪ «ő™Ńňįī’’◊ÓĹŁ◊Ó…Ŕ Ļ”√Ķń‘≠‘Ú»•Ő‘Ő≠Ľļīś“≥Ķń£¨ňý“‘’‚łŲŃīĪŪŅ…“‘ĪĽ≥∆ő™LRUŃīĪŪ£®Least
Recently Used£©°£ĶĪő“√«–Ť“™∑√ő ń≥łŲ“≥ Ī£¨Ņ…“‘’‚—ýī¶ņŪLRUŃīĪŪ£ļ
»ÁĻŻł√“≥≤Ľ‘ŕBuffer Pool÷–£¨‘ŕį—ł√“≥ī”īŇŇŐľ”‘ōĶĹBuffer Pool÷–ĶńĽļīś“≥ Ī£¨ĺÕį—ł√Ľļīś“≥įŁ◊į≥…ĹŕĶ„»ŻĶĹŃīĪŪĶńÕ∑≤Ņ°£
»ÁĻŻł√“≥‘ŕBuffer Po+ol÷–£¨‘Ú÷ĪĹ”į—ł√“≥∂‘”¶ĶńLRUŃīĪŪĹŕĶ„“∆∂ĮĶĹŃīĪŪĶńÕ∑≤Ņ°£
Ķę «’‚—ý◊ŲĽŠ”–“Ľ–©–‘ń‹…ŌĶńő Ő‚£¨Ī»»Áń„Ķń“Ľīő»ęĪŪ…®√ŤĽÚ“Ľīő¬Ŗľ≠Īł∑›ĺÕį—»» żĺ›łÝ≥ŚÕÍŃň£¨ĺÕĽŠĶľ÷¬Ķľ÷¬Ľļ≥Ś≥ōőŘ»ĺő Ő‚£°Buffer
Pool÷–Ķńňý”– żĺ›“≥∂ľĪĽĽĽŃň“Ľīő—™£¨∆šňŻ≤ť—Į”Ôĺš‘ŕ÷ī–– Ī”÷Ķ√÷ī––“Ľīőī”īŇŇŐľ”‘ōĶĹBuffer PoolĶń≤Ŕ◊ų£¨∂Ý’‚÷÷»ęĪŪ…®√ŤĶń”Ôĺš÷ī––Ķń∆Ķ¬ “≤≤ĽłŖ£¨√Ņīő÷ī––∂ľ“™į—Buffer
Pool÷–ĶńĽļīś“≥ĽĽ“Ľīő—™£¨’‚—Ō÷ōĶń”įŌžĶĹ∆šňŻ≤ť—Į∂‘ Buffer Pool Ķń Ļ”√£¨—Ō÷ōĶńĹĶĶÕŃňĽļīś√Ł÷–¬
£°
ňý“‘InnoDBīśīĘ“ż«ś∂‘īęÕ≥ĶńLRUň„∑®◊ŲŃň“Ľ–©”ŇĽĮ£¨‘ŕInnoDB÷–ľ”»ŽŃňmidpoint°£–¬∂ŃĶĹĶń“≥£¨ňš»Ľ «◊Ó–¬∑√ő Ķń“≥£¨Ķę≤Ę≤Ľ «÷ĪĹ”≤Ś»ŽĶĹLRUŃ–ĪŪĶń ◊≤Ņ£¨∂Ý «≤Ś»ŽLRUŃ–ĪŪĶńmidpointőĽ÷√°£’‚łŲň„∑®≥∆÷ģő™midpoint
insertion stategy°£ń¨»ŌŇš÷√≤Ś»ŽĶĹŃ–ĪŪ≥§∂»Ķń5/8ī¶°£midpoint”…≤ő żinnodb_old_blocks_pctŅō÷∆°£
midpoint÷ģ«įĶńŃ–ĪŪ≥∆÷ģő™newŃ–ĪŪ£¨÷ģļůĶńŃ–ĪŪ≥∆÷ģő™oldŃ–ĪŪ°£Ņ…“‘ľÚĶ•ĶńĹęnewŃ–ĪŪ÷–Ķń“≥ņŪĹ‚ő™◊Óő™ĽÓ‘ĺĶń»»Ķ„ żĺ›°£
Õ¨ ĪInnoDBīśīĘ“ż«śĽĻ“ż»ŽŃňinnodb_old_blocks_timeņīĪŪ ĺ“≥∂Ń»°ĶĹmidőĽ÷√÷ģļů–Ť“™Ķ»īż∂ŗĺ√≤ŇĽŠĪĽľ”»ŽĶĹLRUŃ–ĪŪĶń»»∂ň°£Ņ…“‘Õ®Ļż…Ť÷√ł√≤ő żĪ£÷§»»Ķ„ żĺ›≤Ľ«Š“◊ĪĽňĘ≥Ų°£
ļ√Ńň£¨ĽýĪĺń√Ō¬ŃňLRU listļů£¨ő“√«ľŐ–Ý°£«į√śő“√«Ĺ≤ĶĹ“≥√śłŁ–¬ «‘ŕĽļīś≥ō÷–Ō»ĹÝ––Ķń£¨ń«ňŁĺÕļÕīŇŇŐ…ŌĶń“≥≤Ľ“Ľ÷¬Ńň£¨’‚—ýĶńĽļīś“≥“≤ĪĽ≥∆ő™‘ŗ“≥£®”Ęőń√Ż£ļdirty
page£©°£ňý“‘–Ť“™Ņľ¬«’‚–©ĪĽ–řłńĶń“≥√ś ≤√ī ĪļÚňĘ–¬ĶĹīŇŇŐ£Ņ“‘ ≤√ī—ýĶńň≥–ÚňĘ–¬ĶĹīŇŇŐ£ŅĶĪ»Ľ£¨◊ÓľÚĶ•Ķń◊Ų∑®ĺÕ «√Ņ∑Ę…ķ“Ľīő–řłńĺÕŃĘľīÕ¨≤ĹĶĹīŇŇŐ…Ō∂‘”¶Ķń“≥…Ō£¨Ķę «∆Ķ∑ĪĶńÕýīŇŇŐ÷––ī żĺ›ĽŠ—Ō÷ōĶń”įŌž≥Ő–ÚĶń–‘ń‹£®ĪŌĺĻīŇŇŐ¬żĶńŌŮőŕĻÍ“Ľ—ý£©°£ňý“‘√Ņīő–řłńĽļīś“≥ļů£¨ő“√«≤Ę≤Ľ◊ŇľĪŃĘľīį—–řłńÕ¨≤ĹĶĹīŇŇŐ…Ō£¨∂Ý «‘ŕőīņīĶńń≥łŲ ĪľšĶ„ĹÝ––Õ¨≤Ĺ£¨”…ļůŐ®ňĘ–¬ŌŖ≥Ő“ņīőňĘ–¬ĶĹīŇŇŐ£¨ ĶŌ÷–řłń¬šĶōĶĹīŇŇŐ°£
Ķę «»ÁĻŻ≤ĽŃĘľīÕ¨≤ĹĶĹīŇŇŐĶńĽį£¨ń«÷ģļů‘ŔÕ¨≤ĹĶń ĪļÚő“√«‘ű√ī÷™ĶņBuffer Pool÷–ńń–©“≥ «‘ŗ“≥£¨ńń–©“≥ī”ņī√ĽĪĽ–řłńĻżńō£Ņ◊‹≤Ľń‹į—ňý”–ĶńĽļīś“≥∂ľÕ¨≤ĹĶĹīŇŇŐ…Ōį…£¨ľŔ»ÁBuffer
PoolĪĽ…Ť÷√Ķńļ‹īů£¨Ī»∑ĹňĶ300G£¨ń«“Ľīő–‘Õ¨≤Ĺ’‚√ī∂ŗ żĺ›∆Ů≤Ľ «“™¬żňņ£°ňý“‘£¨ő“√«≤ĽĶ√≤Ľ‘ŔīīĹ®“ĽłŲīśīĘ‘ŗ“≥ĶńŃīĪŪ£¨∑≤ «‘ŕLRUŃīĪŪ÷–ĪĽ–řłńĻżĶń“≥∂ľ–Ť“™ľ”»Ž’‚łŲŃīĪŪ÷–£¨“Úő™’‚łŲŃīĪŪ÷–Ķń“≥∂ľ «–Ť“™ĪĽňĘ–¬ĶĹīŇŇŐ…ŌĶń£¨ňý“‘“≤Ĺ–FLUSHŃīĪŪ£¨”– ĪļÚ“≤ĽŠĪĽľÚ–īő™FLUŃīĪŪ°£ŃīĪŪĶńĻĻ‘žļÕFreeŃīĪŪ≤Ó≤Ľ∂ŗ£¨’‚ĺÕ≤Ľ◊ł ŲŃň°£’‚ņÔĶń‘ŗ“≥–řłń÷łĶńīň“≥ĪĽľ”‘ōĹÝBuffer
PoolļůĶŕ“ĽīőĪĽ–řłń£¨÷Ľ”–Ķŕ“ĽīőĪĽ–řłń Ī≤Ň–Ť“™ľ”»ŽFLUSHŃīĪŪ£®īķ¬Ž÷– «łýĺ›PageÕ∑≤ŅĶńoldest_modification
== 0ņīŇ–∂Ō «∑Ů «Ķŕ“Ľīő–řłń£©£¨»ÁĻŻ’‚łŲ“≥ĪĽ‘Ŕīő–řłńĺÕ≤ĽĽŠ‘Ŕ∑ŇĶĹFLUSHŃīĪŪŃň£¨“Úő™“—ĺ≠īś‘ŕ°£–Ť“™◊Ę“‚Ķń «£¨‘ŗ“≥ żĺ› Ķľ ĽĻ‘ŕLRUŃīĪŪ÷–£¨∂ÝFLUSHŃīĪŪ÷–Ķń‘ŗ“≥ľ«¬ľ÷Ľ «Õ®Ļż÷ł’Ž÷łŌÚLRUŃīĪŪ÷–Ķń‘ŗ“≥°£≤Ę«“‘ŕFLUSHŃīĪŪ÷–Ķń‘ŗ“≥ «łýĺ›oldest_lsn£®’‚łŲ÷ĶĪŪ ĺ’‚łŲ“≥Ķŕ“ĽīőĪĽłŁłń ĪĶńlsnļŇ£¨∂‘”¶÷Ķoldest_modification£¨√ŅłŲ“≥Õ∑≤Ņľ«¬ľ£©ĹÝ––ŇŇ–ÚňĘ–¬ĶĹīŇŇŐĶń£¨÷Ķ‘Ĺ–°ĪŪ ĺ“™◊ÓŌ»ĪĽňĘ–¬£¨Ī‹√‚ żĺ›≤Ľ“Ľ÷¬°£
◊Ę“‚£ļ‘ŗ“≥ľ»īś‘ŕ”ŕLRUŃ–ĪŪ÷–£¨“≤īś‘ŕ”ŽFlushŃ–ĪŪ÷–°£LRUŃ–ĪŪ”√ņīĻ‹ņŪĽļ≥Ś≥ō÷–“≥ĶńŅ…”√–‘£¨FlushŃ–ĪŪ”√ņīĻ‹ņŪĹę“≥ňĘ–¬ĽōīŇŇŐ£¨∂Ģ’ŖĽ•≤Ľ”įŌž°£
’‚»żłŲ÷ō“™Ń–ĪŪ£®LRU list£¨ free list£¨flush
list£©ĶńĻōŌĶŅ…“‘”√Ō¬ÕľĪŪ ĺ£ļ
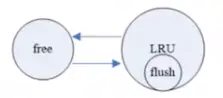
FreeŃīĪŪłķLRUŃīĪŪĶńĻōŌĶ «ŌŗĽ•ŃųÕ®Ķń£¨“≥‘ŕ’‚ŃĹłŲŃīĪŪľšņīĽō÷√ĽĽ°£∂ÝFLUSHŃīĪŪľ«¬ľŃň‘ŗ“≥ żĺ›£¨“≤ «Õ®Ļż÷ł’Ž÷łŌÚŃňLRUŃīĪŪ£¨ňý“‘Õľ÷–FLUSHŃīĪŪĪĽLRUŃīĪŪįŁĻŁ°£
∂Ģ°ĘCheckPointľľ ű
ňĶÕÍĽļ≥Ś≥ō£¨Ō¬√śňĶCheckPointľľ ű°£
CheckPointľľ ű «”√ņīĹ‚ĺŲ»ÁŌ¬ľłłŲő Ő‚£ļ
ňű∂Ő żĺ›Ņ‚Ľ÷łī Īľš
Ľļ≥Ś≥ō≤ĽĻĽ”√ Ī£¨Ĺę‘ŗ“≥ňĘ–¬ĶĹīŇŇŐ
÷ō◊Ų»’÷ĺ≤ĽŅ…”√ Ī£¨ňĘ–¬‘ŗ“≥
ňű∂Ő żĺ›Ņ‚Ľ÷łī Īľš£¨÷ō◊Ų»’÷ĺ÷–ľ«¬ľŃňĶńcheckpointĶńőĽ÷√£¨’‚łŲĶ„÷ģ«įĶń“≥“—ĺ≠ňĘ–¬ĽōīŇŇŐ£¨÷Ľ–Ť“™∂‘checkpoint÷ģļůĶń÷ō◊Ų»’÷ĺĹÝ––Ľ÷łī°£’‚—ýĺÕīůīůňű∂ŐŃňĽ÷łī Īľš°£
Ľļ≥Ś≥ō≤ĽĻĽ”√ Ī£¨łýĺ›LRUň„∑®£¨“Á≥Ų◊ÓĹŁ◊Ó…Ŕ Ļ”√Ķń“≥£¨»ÁĻŻ“≥ő™‘ŗ“≥£¨«Ņ÷∆÷ī––checkpoint£¨Ĺę‘ŗ“≥ňĘ–¬ĽōīŇŇŐ°£
÷ō◊Ų»’÷ĺ≤ĽŅ…”√£¨ «÷ł÷ō◊Ų»’÷ĺĶń’‚≤Ņ∑÷≤ĽŅ…“‘ĪĽł≤ł«£¨ő™ ≤√ī£Ņ“Úő™£ļ”…”ŕ÷ō◊Ų»’÷ĺĶń…Ťľ∆ «—≠Ľ∑ Ļ”√Ķń°£’‚≤Ņ∑÷∂‘”¶Ķń żĺ›ĽĻőīňĘ–¬ĶĹīŇŇŐ…Ō°£ żĺ›Ņ‚Ľ÷łī Ī£¨»ÁĻŻ≤Ľ–Ť“™’‚≤Ņ∑÷»’÷ĺ£¨ľīŅ…ĪĽł≤ł«£Ľ»ÁĻŻ–Ť“™£¨Īō–Ž«Ņ÷∆÷ī––checkpoint£¨ĹęĽļ≥Ś≥ō÷–Ķń“≥÷Ń…ŔňĘ–¬ĶĹĶĪ«į÷ō◊Ų»’÷ĺĶńőĽ÷√°£
checkpoint√ŅīőňĘ–¬∂ŗ…Ŕ“≥ĶĹīŇŇŐ£Ņ√Ņīőī”ńńņÔ»°‘ŗ“≥£Ņ ≤√ī Īľšī•∑Ęcheckpoint£Ņ
InnoDBīśīĘ“ż«śńŕ≤Ņ£¨ŃĹ÷÷checkpoint£¨∑÷Īūő™:
Sharp Checkpoint
Fuzzy Checkpoint
Sharp Checkpoint∑Ę…ķ‘ŕ żĺ›Ņ‚ĻōĪ’ Ī£¨Ĺęňý”–Ķń‘ŗ“≥∂ľňĘ–¬ĽōīŇŇŐ£¨’‚ «ń¨»ŌĶńĻ§◊ų∑Ĺ Ĺ£¨ľī≤ő ż£ļinnodb_fast_shutdown=1°£
≤Ľ ”√”ŕ żĺ›Ņ‚‘ň–– ĪĶńňĘ–¬°£
‘ŕ żĺ›Ņ‚‘ň–– Ī£¨InnoDBīśīĘ“ż«śńŕ≤Ņ≤…”√Fuzzy Checkpoint£¨÷ĽňĘ–¬“Ľ≤Ņ∑÷‘ŗ“≥°£
ľł÷÷∑Ę…ķFuzzy CheckpointĶń«ťŅŲ£ļ
ĘŔMasterThread Checkpoint
“ž≤ĹňĘ–¬£¨√Ņ√ŽĽÚ√Ņ10√Žī”Ľļ≥Ś≥ō‘ŗ“≥Ń–ĪŪňĘ–¬“Ľ∂®Ī»ņżĶń“≥ĽōīŇŇŐ°£“ž≤ĹňĘ–¬£¨ľīīň ĪInnoDBīśīĘ“ż«śŅ…“‘ĹÝ––∆šňŻ≤Ŕ◊ų£¨”√Ľß≤ť—ĮŌŖ≥Ő≤ĽĽŠ ‹◊Ť°£
ĘŕFLUSH_LRU_LIST Checkpoint
InnoDBīśīĘ“ż«ś–Ť“™Ī£÷§LRUŃ–ĪŪ÷–≤Ó≤Ľ∂ŗ”–100łŲŅ’Ō–“≥Ņ…Ļ© Ļ”√°£‘ŕInnoDB 1.1.xįśĪĺ÷ģ«į£¨”√Ľß≤ť—ĮŌŖ≥ŐĽŠľž≤ťLRUŃ–ĪŪ «∑Ů”–◊„ĻĽĶńŅ’ľš≤Ŕ◊ų°£»ÁĻŻ√Ľ”–£¨łýĺ›LRUň„∑®£¨“Á≥ŲLRUŃ–ĪŪő≤∂ňĶń“≥£¨»ÁĻŻ’‚–©“≥”–‘ŗ“≥£¨–Ť“™ĹÝ––checkpoint°£“ÚīňĹ–£ļflush_lru_list
checkpoint°£
InnoDB 1.2.xŅ™ ľ£¨’‚łŲľž≤ť∑Ň‘ŕŃňĶ•∂ņĶńĹÝ≥Ő£®Page Cleaner£©÷–ĹÝ––°£ļ√ī¶£ļ1.ľű…Ŕmaster
ThreadĶń—ĻѶ 2.ľű«Š”√ĽßŌŖ≥Ő◊Ť»Ż°£
…Ť÷√≤ő ż£ļinnodb_lru_scan_dept£ļŅō÷∆LRUŃ–ĪŪ÷–Ņ…”√“≥Ķń żŃŅ£¨ł√÷Ķń¨»Ō1024
ĘŘAsync/Sync Flush Checkpoint
÷ł÷ō◊Ų»’÷ĺ≤ĽŅ…”√Ķń«ťŅŲ£¨–Ť“™«Ņ÷∆ňĘ–¬“≥ĽōīŇŇŐ£¨īň ĪĶń“≥ Ī‘ŗ“≥Ń–ĪŪ—°»°Ķń°£
’‚÷÷«ťŅŲ «Ī£÷§÷ō◊Ų»’÷ĺĶńŅ…”√–‘£¨ňĶį◊ŃňĺÕ «£¨÷ō◊Ų»’÷ĺ÷–Ņ…“‘—≠Ľ∑ł≤ł«Ķń≤Ņ∑÷Ņ’ľšŐę…ŔŃň£¨ĽĽ÷÷ňĶ∑®£¨ĺÕ «ľę∂Ő Īľšńŕ≤ķ…ķŃňīůŃŅĶńredo
log°£
Ĺ”Ō¬ņīĽŠ”–ľłłŲĪšŃŅ£¨ÕľĹ‚“≤≤Ľń—£¨◊–ŌłŅīŅī°£
InnoDBīśīĘ“ż«ś£¨Õ®ĻżLSN£®Log Sequence Number£©ņīĪÍľ«įśĪĺ£¨LSN «8◊÷ĹŕĶń ż◊÷°£√ŅłŲ“≥”–LSN£¨÷ō◊Ų»’÷ĺ”–LSN£¨checkpoint”–LSN°£
–ī»Ž»’÷ĺĶńLSN:redo_lsn
ňĘ–¬ĽōīŇŇŐĶń◊Ó–¬“≥LSN:checkpoint_lsn
”–»ÁŌ¬∂®“Ś:
checkpoint_age = redo_lsn - checkpoint_lsn
async_water_mark = 75% * total_redo_file_size
sync_water_mark = 90% * total_redo_file_size
ňĘ–¬Ļż≥Ő»ÁŌ¬Õľňý ĺ£ļ
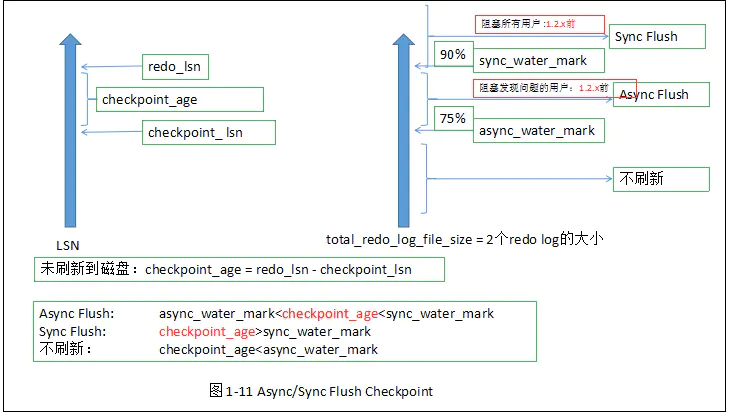
Ę‹Dirty Page too much Checkpoint
ľī‘ŗ“≥Őę∂ŗ£¨«Ņ÷∆checkpoint.Ī£÷§Ľļ≥Ś≥ō”–◊„ĻĽŅ…”√Ķń“≥°£
≤ő ż…Ť÷√£ļinnodb_max_dirty_pages_pct = 75 ĪŪ ĺ£ļĶĪĽļ≥Ś≥ō÷–‘ŗ“≥Ķń żŃŅ’ľ75% Ī£¨«Ņ÷∆checkpoint°£1.0.x÷ģļůń¨»Ō75
»ż°ĘInnoDBĻōľŁŐō–‘
3.1≤Ś»ŽĽļ≥Ś
Insert Buffer «InnoDBīśīĘ“ż«śĻōľŁŐō–‘÷–◊ÓŃÓ»ňľ§∂Į”Ž–ň∑‹Ķń“ĽłŲĻ¶ń‹°£≤ĽĻż’‚łŲ√Ż◊÷Ņ…ń‹ĽŠ»√»ň»Ōő™≤Ś»ŽĽļ≥Ś «Ľļ≥Ś≥ō÷–Ķń“ĽłŲ◊ť≥…≤Ņ∑÷°£∆š Ķ≤Ľ»Ľ£¨InnoDBĽļ≥Ś≥ō÷–”–Insert
Buffer–ŇŌĘĻŐ»Ľ≤ĽīŪ£¨Ķę «Insert BufferļÕ żĺ›“≥“Ľ—ý£¨“≤ «őÔņŪ“≥Ķń“ĽłŲ◊ť≥…≤Ņ∑÷°£
“Ľį„«ťŅŲŌ¬£¨÷ųľŁ «––ő®“ĽĶńĪÍ ∂∑Ż°£Õ®≥£”¶”√≥Ő–Ú÷–––ľ«¬ľĶń≤Ś»Žň≥–Ú «įī’’÷ųľŁĶ›‘ŲĶńň≥–ÚĹÝ––≤Ś»ŽĶń°£“Úīň£¨≤Ś»ŽĺŘľĮňų“ż“Ľį„ «ň≥–ÚĶń£¨≤Ľ–Ť“™īŇŇŐĶńňśĽķ∂Ń»°°£“Úő™£¨∂‘”ŕīňņŗ«ťŅŲŌ¬Ķń≤Ś»Ž£¨ňŔ∂»ĽĻ «∑«≥£ŅžĶń°££®»ÁĻŻ÷ųľŁņŗ «UUID’‚—ýĶńņŗ£¨ń«√ī≤Ś»ŽļÕł®÷ķňų“ż“Ľ—ý£¨“≤ «ňśĽķĶń°££©
»ÁĻŻňų“ż «∑«ĺŘľĮĶń«“≤Ľő®“Ľ°£‘ŕĹÝ––≤Ś»Ž≤Ŕ◊ų Ī£¨ żĺ›Ķńīś∑Ň∂‘”ŕ∑«ĺŘľĮňų“ż“∂◊”ĹŕĶ„Ķń≤Ś»Ž≤Ľ «ň≥–ÚĶń£¨’‚ Ī–Ť“™ņŽ…ĘĶō∑√ő ∑«ĺŘľĮňų“ż“≥£¨”…”ŕňśĽķ∂Ń»°Ķńīś‘ŕ∂ÝĶľ÷¬Ńň≤Ś»Ž≤Ŕ◊ų–‘ń‹Ō¬ĹĶ°£’‚ «“Úő™B+ ųĶńŐō–‘ĺŲ∂®Ńň∑«ĺŘľĮňų“ż≤Ś»ŽĶńņŽ…Ę–‘°£
Insert BufferĶń…Ťľ∆£¨∂‘”ŕ∑«ĺŘľĮňų“żĶń≤Ś»ŽļÕłŁ–¬≤Ŕ◊ų£¨≤Ľ «√Ņ“Ľīő÷ĪĹ”≤Ś»ŽĶĹňų“ż“≥÷–£¨∂Ý «Ō»Ň–∂Ō≤Ś»Ž∑«ĺŘľĮňų“ż“≥ «∑Ů‘ŕĽļ≥Ś≥ō÷–£¨»Űīś‘ŕ£¨‘Ú÷ĪĹ”≤Ś»Ž£¨≤Ľīś‘ŕ£¨‘ÚŌ»∑Ň»Ž“ĽłŲInsert
Buffer∂‘Ōů÷–°£ żĺ›Ņ‚’‚łŲ∑«ĺŘľĮĶńňų“ż“—ĺ≠≤ŚĶĹ“∂◊”ĹŕĶ„£¨∂Ý Ķľ ≤Ę√Ľ”–£¨÷Ľ «īś∑Ň‘ŕŃŪ“ĽłŲőĽ÷√°£»Ľļů‘Ŕ“‘“Ľ∂®Ķń∆Ķ¬ ļÕ«ťŅŲĹÝ––Insert
BufferļÕł®÷ķňų“ż“≥◊”ĹŕĶ„Ķńmerge£®ļŌ≤Ę£©≤Ŕ◊ų£¨’‚ ĪÕ®≥£ń‹Ĺę∂ŗłŲ≤Ś»ŽļŌ≤ĘĶĹ“ĽłŲ≤Ŕ◊ų÷–£®“Úő™‘ŕ“ĽłŲňų“ż“≥÷–£©£¨’‚ĺÕīůīůŐŠłŖŃň∂‘”ŕ∑«ĺŘľĮňų“ż≤Ś»ŽĶń–‘ń‹°£
–Ť“™¬ķ◊„ĶńŃĹłŲŐűľĢ£ļ
ňų“ż «ł®÷ķňų“ż£Ľ
ňų“ż≤Ľ «ő®“ĽĶń°£
ł®÷ķňų“ż≤Ľń‹ «ő®“ĽĶń£¨“Úő™‘ŕ≤Ś»ŽĽļ≥Ś Ī£¨ żĺ›Ņ‚≤Ę≤Ľ»•≤ť’“ňų“ż“≥ņīŇ–∂Ō≤Ś»ŽĶńľ«¬ľĶńő®“Ľ–‘°£»ÁĻŻ»•≤ť’“ŅŌ∂®”÷ĽŠ”–ņŽ…Ę∂Ń»°Ķń«ťŅŲ∑Ę…ķ£¨ī”∂ÝĶľ÷¬Insert
Buffer ß»•Ńň“‚“Ś°£
3.2ŃĹīő–ī
»ÁĻŻňĶ≤Ś»ŽĽļ≥Ś «ő™ŃňŐŠłŖ–ī–‘ń‹ĶńĽį£¨ń«√īŃĹīő–ī «ő™ŃňŐŠłŖŅ…ŅŅ–‘°£
Ĺť…‹ŃĹīő–ī÷ģ«į£¨ňĶ“ĽŌ¬≤Ņ∑÷–ī ߖߣļ
ŌŽŌů’‚√ī“ĽłŲ≥°ĺį£¨ĶĪ żĺ›Ņ‚’ż‘ŕī”ńŕīśŌÚīŇŇŐ–ī“ĽłŲ żĺ›“≥ Ī£¨ żĺ›Ņ‚ŚīĽķ£¨ī”∂ÝĶľ÷¬’‚łŲ“≥÷Ľ–īŃň≤Ņ∑÷ żĺ›£¨’‚ĺÕ «≤Ņ∑÷–ī ߖߣ¨ňŁĽŠĶľ÷¬ żĺ›∂™ ß°£’‚ Ī «őř∑®Õ®Ļż÷ō◊Ų»’÷ĺĽ÷łīĶń£¨“Úő™÷ō◊Ų»’÷ĺľ«¬ľĶń «∂‘“≥ĶńőÔņŪ–řłń£¨»ÁĻŻ“≥Īĺ…Ū“—ĺ≠ňūĽĶ£¨÷ō◊Ų»’÷ĺ“≤őřń‹ő™Ń¶°£
ī”…Ō√ś∑÷őŲő“√«÷™Ķņ£¨‘ŕ≤Ņ∑÷–ī ß–ßĶń«ťŅŲŌ¬£¨ő“√«‘ŕ”¶”√÷ō◊Ų»’÷ĺ÷ģ«į£¨–Ť“™‘≠ ľ“≥Ķń“ĽłŲłĪĪĺ£¨ŃĹīő–īĺÕ «ő™ŃňĹ‚ĺŲ’‚łŲő Ő‚£¨Ō¬√ś «ňŁĶń‘≠ņŪÕľ£ļimage.png
ŃĹīő–ī–Ť“™∂ÓÕ‚ŐŪľ”ŃĹłŲ≤Ņ∑÷£ļ
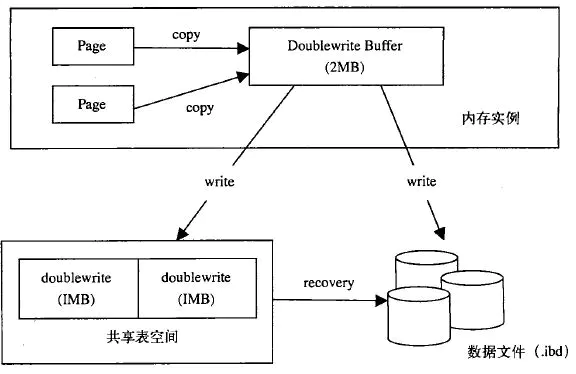
1£©ńŕīś÷–ĶńŃĹīő–īĽļ≥Ś£®doublewrite buffer£©£¨īů–°ő™2MB
2£©īŇŇŐ…ŌĻ≤ŌŪĪŪŅ’ľš÷–Ѩ–ÝĶń128“≥£¨īů–°“≤ő™2MB
∆š‘≠ņŪ «’‚—ýĶń£ļ
1£©ĶĪňĘ–¬Ľļ≥Ś≥ō‘ŗ“≥ Ī£¨≤Ę≤Ľ÷ĪĹ”–īĶĹ żĺ›őńľĢ÷–£¨∂Ý «Ō»ŅĹĪī÷Ńńŕīś÷–ĶńŃĹīő–īĽļ≥Ś«Ý°£
2£©Ĺ”◊Ňī”ŃĹīő–īĽļ≥Ś«Ý∑÷ŃĹīő–ī»ŽīŇŇŐĻ≤ŌŪĪŪŅ’ľš÷–£¨√Ņīő–ī»Ž1MB
3£©īżĶŕ2≤ĹÕÍ≥…ļů£¨‘ŔĹęŃĹīő–īĽļ≥Ś«Ý–ī»Ž żĺ›őńľĢ
’‚—ýĺÕŅ…“‘Ĺ‚ĺŲ…ŌőńŐŠĶĹĶń≤Ņ∑÷–ī ß–ßĶńő Ő‚£¨“Úő™‘ŕīŇŇŐĻ≤ŌŪĪŪŅ’ľš÷–“—”– żĺ›“≥łĪĪĺŅĹĪī£¨»ÁĻŻ żĺ›Ņ‚‘ŕ“≥–ī»Ž żĺ›őńľĢĶńĻż≥Ő÷–ŚīĽķ£¨‘ŕ ĶņżĽ÷łī Ī£¨Ņ…“‘ī”Ļ≤ŌŪĪŪŅ’ľš÷–’“ĶĹł√“≥łĪĪĺ£¨Ĺę∆šŅĹĪīł≤ł«‘≠”–Ķń żĺ›“≥£¨‘Ŕ”¶”√÷ō◊Ų»’÷ĺľīŅ…°£
∆š÷–Ķŕ2≤Ĺ «∂ÓÕ‚Ķń–‘ń‹Ņ™Ōķ£¨Ķę”…”ŕīŇŇŐĻ≤ŌŪĪŪŅ’ľš «Ń¨–ÝĶń£¨“ÚīňŅ™Ōķ≤Ľ «ļ‹īů°£Ņ…“‘Õ®Ļż≤ő żskip_innodb_doublewriteĹŻ”√ŃĹīő–īĻ¶ń‹£¨ń¨»Ō «Ņ™∆ŰĶń£¨«ŅŃ“Ĺ®“ťŅ™∆Űł√Ļ¶ń‹°£
MySQL InnoDBŐō–‘£ļŃĹīő–ī£®DoubleWrite£©
InnoDBŐō–‘÷ģ-ŃĹīő–ī
3.3◊‘ ”¶ĻĢŌ£ňų“ż
ĻĢŌ£ «“Ľ÷÷∑«≥£ŅžĶń≤ť’“∑Ĺ∑®£¨‘ŕ“Ľį„«ťŅŲ Īľšłī‘”∂»ő™O(1)°£∂ÝB+ ųĶń≤ť’“īő ż£¨»°ĺŲ”ŕB+ ųĶńłŖ∂»£¨‘ŕ…ķ≥…Ľ∑ĺ≥÷–£¨B+ ųĶńłŖ∂»“Ľį„ő™3-4≤„£¨≤Ľ–Ť“™≤ť—Į3-4īő°£
InnoDBīśīĘ“ż«śĽŠľŗŅō∂‘ĪŪ…Ōłųňų“ż“≥Ķń≤ť—Į°£»ÁĻŻĻŘ≤žĶĹĹ®ŃĘĻĢŌ£ňų“żŅ…“‘ŐŠ…żňŔ∂»£¨’‚ľÚņķĻĢŌ£ňų“ż£¨≥∆÷ģő™◊‘ ”¶ĻĢŌ£ňų“ż(Adaptive
Hash Index, AHI)°£AHI «Õ®ĻżĽļ≥Ś≥ōĶńB+ ų“≥ĻĻ‘ž∂ÝņīĶń°£“ÚīňĹ®ŃĘĶńňŔ∂»∑«≥£Ņž£¨«“≤Ľ“™∂‘’Ż’ŇĪŪĻĻĹ®ĻĢŌ£ňų“ż°£InnoDBīśīĘ“ż«śĽŠ◊‘∂Įłýĺ›∑√ő Ķń∆Ķ¬ ļÕń£ Ĺņī◊‘∂ĮĶńő™ń≥–©»»Ķ„“≥Ĺ®ŃĘĻĢŌ£ňų“ż°£
AHI”–“ĽłŲ“™«ů£¨∂‘’‚łŲ“≥ĶńѨ–Ý∑√ő ń£ Ĺ(≤ť—ĮŐűľĢ)Īō–Ž“Ľ—ýĶń°£ņż»ÁŃ™ļŌňų“ż(a,b)∆š∑√ő ń£ ĹŅ…“‘”–“‘Ō¬«ťŅŲ:
WHERE a=XXX;
WHERE a=xxx AND b=xxx°£
»ŰĹĽŐśĹÝ––…Ō ŲŃĹ’Ň≤ť—Į£¨InnoDBīśīĘ“ż«ś≤ĽĽŠ∂‘ł√“≥ĻĻ‘žAHI°£īňÕ‚AHIĽĻ”–»ÁŌ¬“™«ů£ļ
“‘ł√ń£ Ĺ∑√ő Ńň100īő£Ľ
“≥Õ®Ļżł√ń£ Ĺ∑√ő ŃňNīő£¨∆š÷–N=“≥÷–ľ«¬ľ/16°£
łýĺ›ĻŔ∑ĹőńĶĶŌ‘ ĺ£¨∆Ű”√AHIļů£¨∂Ń»°ļÕ–ī»ŽĶńňŔ∂»Ņ…“‘ŐŠłŖ2Ī∂£¨łļ‘ūňų“żĶńŃīĹ”≤Ŕ◊ų–‘ń‹Ņ…“‘ŐŠłŖ5Ī∂°£∆š…Ťľ∆ňľŌŽ « żĺ›Ņ‚◊‘”…ĽĮĶń£¨őř–ŤDBA∂‘ żĺ›Ņ‚ĹÝ––»ňő™Ķų’Ż°£
3.4“ž≤ĹIO(AIO)
ő™ŃňŐŠłŖīŇŇŐ≤Ŕ◊ų–‘ń‹£¨ĶĪ«įĶń żĺ›Ņ‚ŌĶÕ≥∂ľ≤…”√“ž≤ĹIOĶń∑Ĺ Ĺņīī¶ņŪīŇŇŐ≤Ŕ◊ų°£InnoDB“≤ «»Áīň°£
”ŽAIO∂‘”¶Ķń «Sync IO£¨ľī√ŅĹÝ––“ĽīőIO≤Ŕ◊ų£¨–Ť“™Ķ»īżīňīő≤Ŕ◊ųĹŠ Ý≤Ňń‹ľŐ–ÝĹ”Ō¬ņīĶń≤Ŕ◊ų°£Ķę «»ÁĻŻ”√Ľß∑Ę≥ŲĶń «“ĽŐűňų“ż…®√ŤĶń≤ť—Į£¨ń«√ī’‚ŐűSQL”ÔĺšŅ…ń‹–Ť“™…®√Ť∂ŗłŲňų“ż“≥£¨“≤ĺÕ «–Ť“™ĹÝ––∂ŗīőIO≤Ŕ◊ų°£‘ŕ√Ņ…®√Ť“ĽłŲ“≥≤ĘĶ»īż∆šÕÍ≥…‘ŔĹÝ––Ō¬“Ľīő…®√Ť£¨’‚ «√Ľ”–Īō“™Ķń°£”√ĽßŅ…“‘‘ŕ∑Ę≥Ų“ĽłŲIO«Ž«ůļůŃĘľī‘Ŕ∑Ę≥ŲŃŪÕ‚“ĽłŲIO«Ž«ů£¨ĶĪ»ę≤ŅIO«Ž«ů∑ĘňÕÕÍĪŌļů£¨Ķ»īżňý”–IO≤Ŕ◊ųÕÍ≥…£¨’‚ĺÕ «AIO°£
AIOĶńŃŪÕ‚“ĽłŲ”Ň ∆ «ĹÝ––IO Merge≤Ŕ◊ų£¨“≤ĺÕ «Ĺę∂ŗłŲIOļŌ≤Ęő™“ĽłŲIO≤Ŕ◊ų£¨’‚—ýŅ…“‘ŐŠłŖIOPSĶń–‘ń‹°£
‘ŕInnoDB 1.1.x÷ģ«į£¨AIOĶń ĶŌ÷ «Õ®ĻżInnoDBīśīĘ“ż«ś÷–Ķńīķ¬Žņīń£ń‚Ķń°£Ķę «ī”’‚÷ģļů£¨ŐŠĻ©Ńňńŕļňľ∂ĪūĶńAIOĶń÷ß≥÷£¨≥∆ő™Native
AIO°£Native AIO–Ť“™≤Ŕ◊ųŌĶÕ≥ŐŠĻ©÷ß≥÷°£WindowsļÕLinux∂ľ÷ß≥÷£¨∂ÝMac‘ÚőīŐŠĻ©°£‘ŕ—°‘ŮMySQL żĺ›Ņ‚∑ĢőŮ∆ųĶń≤Ŕ◊ųŌĶÕ≥ Ī£¨–Ť“™Ņľ¬«’‚∑Ĺ√śĶń“Úňō°£
MySQLŅ…“‘Õ®Ļż≤ő żinnodb_use_native_aioņīĺŲ∂® «∑Ů∆Ű”√Native AIO°£‘ŕInnoDBīśīĘ“ż«ś÷–£¨read
ahead∑Ĺ ĹĶń∂Ń»°∂ľ «Õ®ĻżAIOÕÍ≥…£¨‘ŗ“≥ĶńňĘ–¬£¨“≤ «Õ®ĻżAIOÕÍ≥…°£
3.5ňĘ–¬ŃŕĹ”“≥
InnoDBīśīĘ“ż«ś‘ŕňĘ–¬“ĽłŲ‘ŗ“≥ Ī£¨ĽŠľž≤‚ł√“≥ňý‘ŕ«Ý(extent)Ķńňý”–“≥£¨»ÁĻŻ «‘ŗ“≥£¨ń«√ī“Ľ∆ūňĘ–¬°£’‚—ý◊ŲĶńļ√ī¶ «Õ®ĻżAIOŅ…“‘Ĺę∂ŗłŲIO–ī≤Ŕ◊ųļŌ≤Ęő™“ĽłŲIO≤Ŕ◊ų°£ł√Ļ§◊ųĽķ÷∆‘ŕīęÕ≥Ľķ–ĶīŇŇŐŌ¬”–Ō‘÷Ý”Ň ∆°£Ķę «–Ť“™Ņľ¬«Ō¬į…ŃĹłŲő Ő‚:
«≤Ľ «Ĺę≤Ľ‘ű√ī‘ŗĶń“≥ĹÝ–––ī»Ž£¨∂Ýł√“≥÷ģļů”÷ĽŠļ‹ŅžĪš≥…‘ŗ“≥£Ņ
ĻŐŐ¨”≤ŇŐ”–ļ‹łŖIOPS£¨ «∑ŮĽĻ–Ť“™’‚łŲŐō–‘£Ņ
ő™īňInnoDBīśīĘ“ż«ś1.2.xįśĪĺŅ™ ľŐŠĻ©≤ő żinnodb_flush_neighborsņīĺŲ∂® «∑Ů∆Ű”√°£∂‘”ŕīęÕ≥Ľķ–Ķ”≤ŇŐĹ®“ť Ļ”√£¨∂Ý∂‘”ŕĻŐŐ¨”≤ŇŐŅ…“‘ĻōĪ’°£
| 








