| БрМЭЦМі: |
БОЮФНЋНщЩмApache
HudiЕФЛљБОИХФюЁЂЩшМЦвдМАзмЬхЛљДЁМмЙЙЁЃ
БОЮФРДздгкЮЂаХ FlinkЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
1.МђНщ
Apache Hudi(МђГЦЃКHudi)ЪЙЕУФњФмдкhadoopМцШнЕФДцДЂжЎЩЯДцДЂДѓСПЪ§ОнЃЌЭЌЪБЫќЛЙЬсЙЉСНжждгяЃЌЪЙЕУГ§СЫОЕфЕФХњДІРэжЎЭтЃЌЛЙПЩвддкЪ§ОнКўЩЯНјааСїДІРэЁЃ
етСНжждгяЗжБ№ЪЧЃК
Update/DeleteМЧТМЃКHudiЪЙгУЯИСЃЖШЕФЮФМў/МЧТММЖБ№Ыїв§РДжЇГжUpdate/DeleteМЧТМЃЌЭЌЪБЛЙЬсЙЉаДВйзїЕФЪТЮёБЃжЄЁЃВщбЏЛсДІРэзюКѓвЛИіЬсНЛЕФПьееЃЌВЂЛљгкДЫЪфГіНсЙћЁЃ
БфИќСїЃКHudiЖдЛёШЁЪ§ОнБфИќЬсЙЉСЫвЛСїЕФжЇГжЃКПЩвдДгИјЖЈЕФЪБМфЕуЛёШЁИјЖЈБэжавбupdated/inserted/deletedЕФЫљгаМЧТМЕФдіСПСїЃЌВЂНтЫјаТЕФВщбЏзЫЪЦЃЈРрБ№ЃЉЁЃ
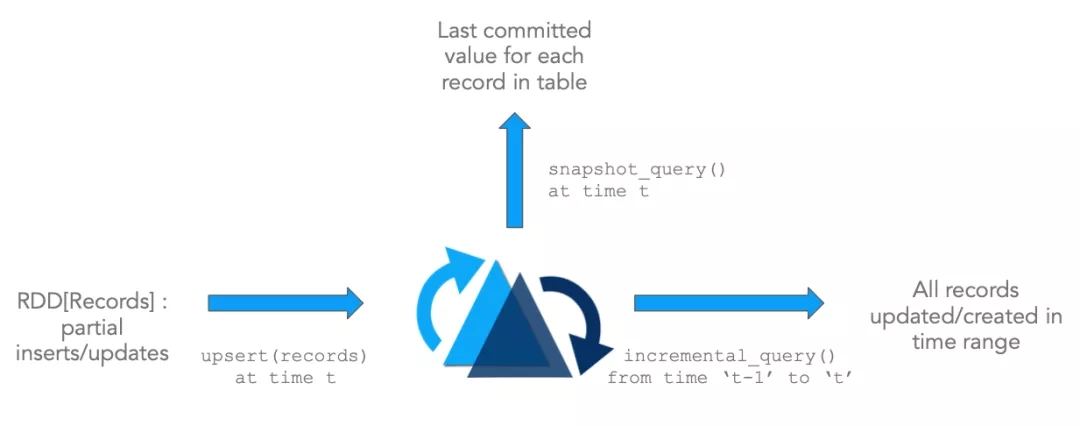
етаЉдгяНєУмНсКЯЃЌНтЫјСЫЛљгкDFSГщЯѓЕФСї/діСПДІРэФмСІЁЃШчЙћФњЪьЯЄСїДІРэЃЌФЧУДетКЭДгkafkaжїЬтЯћЗбЪТМўЃЌШЛКѓЪЙгУзДЬЌДцДЂж№ВНРлМгжаМфНсЙћРрЫЦЁЃ
етдкМмЙЙЩЯЛсгавдЯТМИЕугХЪЦЃК
1ЃЉ аЇТЪЕФЬсЩ§ЃКЩуШЁЪ§ОнЭЈГЃашвЊДІРэИќаТЁЂЩОГ§вдМАЧПжЦЮЈвЛМќдМЪјЁЃШЛЖјЃЌгЩгкШБЗІЯёHudiетбљФмЖдетаЉЙІФмЬсЙЉБъзМжЇГжЕФЯЕЭГЃЌЪ§ОнЙЄГЬЪІУЧЭЈГЃЛсВЩгУДѓХњСПЕФзївЕРДжиаТДІРэвЛећЬьЕФЪТМўЃЌЛђепУПДЮдЫааЖМжиаТМгдиећИіЩЯгЮЪ§ОнПтЃЌДгЖјЕМжТДѓСПЕФМЦЫузЪдДРЫЗбЁЃгЩгкHudiжЇГжМЧТММЖИќаТЃЌЫќЭЈЙ§жЛДІРэгаБфИќЕФМЧТМВЂЧвжЛжиаДБэжавбИќаТ/ЩОГ§ЕФВПЗжЃЌЖјВЛЪЧжиаДећИіБэЗжЧјЩѕжСећИіБэЃЌЮЊетаЉВйзїДјРДвЛИіЪ§СПМЖЕФадФмЬсЩ§ЁЃ
2ЃЉ ИќПьЕФETL/ХЩЩњPipelinesЃКДгЭтВПЯЕЭГЩуШыЪ§ОнКѓЃЌЯТвЛВНашвЊЪЙгУApache Spark/Apache
HiveЛђепШЮКЮЦфЫћЪ§ОнДІРэПђМмРДETLетаЉЪ§ОнгУгкжюШчЪ§ОнВжПтЁЂЛњЦїбЇЯАЛђепНіНіЪЧЪ§ОнЗжЮіЕШвЛаЉгІгУГЁОАЁЃЭЈГЃЃЌетаЉДІРэдйДЮвРРЕвдДњТыЛђSQLБэЪОЕФХњДІРэзївЕЃЌетаЉзївЕНЋХњСПДІРэЫљгаЪфШыЪ§ОнВЂжиаТМЦЫуЫљгаЪфГіНсЙћЁЃЭЈЙ§ЪЙгУдіСПВщбЏЖјВЛЪЧПьееВщбЏРДВщбЏвЛИіЛђЖрИіЪфШыБэЃЌПЩвдДѓДѓМгЫйДЫРрЪ§ОнЙмЕРЃЌДгЖјдйДЮЯёЩЯУцвЛбљНіДІРэРДздЩЯгЮБэЕФдіСПИќИФЃЌШЛКѓupsertЛђепdeleteФПБъХЩЩњБэЁЃ
3ЃЉ аТЯЪЪ§ОнЕФЛёШЁЃКМѕЩйзЪдДЛЙФмЛёШЁадФмЩЯЕФЬсЩ§ВЂВЛЪЧГЃМћЕФЪТЁЃБЯОЙЮвУЧЭЈГЃЛсЪЙгУИќЖрЕФзЪдДЃЈР§ШчФкДцЃЉРДЬсЩ§адФмЃЈР§ШчВщбЏбгГйЃЉЁЃHudiЭЈЙ§ДгИљБОЩЯАкЭбЪ§ОнМЏЕФДЋЭГЙмРэЗНЪНЃЌНЋХњСПДІРэдіСПЛЏДјРДСЫвЛИіИНМгЕФКУДІЃКгывдЧАЕФЪ§ОнКўЯрБШЃЌpipelineдЫааЕФЪБМфЛсИќЖЬЃЌЪ§ОнНЛИЖЛсИќПьЁЃ
4ЃЉ ЭГвЛДцДЂЃКЛљгквдЩЯШ§ИігХЕуЃЌдкЯжгаЪ§ОнКўжЎЩЯНјааИќПьЫйЁЂИќЧсСПЕФДІРэвтЮЖзХНіГігкЗУЮЪНќЪЕЪБЪ§ОнЕФФПЕФЪБВЛдйашвЊзЈУХЕФДцДЂЛђЪ§ОнМЏЪаЁЃ
2.ЩшМЦддђ
СїЪНЖС/аД:HudiНшМјСЫЪ§ОнПтЩшМЦЕФдРэЃЌДгСуЩшМЦЃЌгІгУгкДѓаЭЪ§ОнМЏМЧТМСїЕФЪфШыКЭЪфГіЁЃЮЊДЫЃЌHudiЬсЙЉСЫЫїв§ЪЕЯжЃЌПЩвдНЋМЧТМЕФМќПьЫйгГЩфЕНЦфЫљдкЕФЮФМўЮЛжУЁЃЭЌбљЃЌЖдгкСїЪНЪфГіЪ§ОнЃЌHudiЭЈЙ§ЦфЬиЪтСаЬэМгВЂИњзйМЧТММЖЕФдЊЪ§ОнЃЌДгЖјПЩвдЬсЙЉЫљгаЗЂЩњБфИќЕФОЋШЗдіСПСїЁЃ
здЙмРэЃКHudiзЂвтЕНгУЛЇПЩФмЖдЪ§ОнаТЯЪЖШЃЈаДгбКУЃЉгыВщбЏадФмЃЈЖС/ВщбЏгбКУЃЉгаВЛЭЌЕФЦкЭћЃЌЫќжЇГжСЫШ§жжВщбЏРраЭЃЌетаЉРраЭЬсЙЉЪЕЪБПьееЃЌдіСПСївдМАЩддчЕФДПСаЪ§ОнЁЃдкУПвЛВНЃЌHudiЖМХЌСІзіЕНздЮвЙмРэЃЈР§ШчздЖЏгХЛЏБраДГЬађЕФВЂааадЃЌБЃГжЮФМўДѓаЁЃЉКЭздЮваоИДЃЈР§ШчЃКздЖЏЛиЙіЪЇАмЕФЬсНЛЃЉЃЌМДЪЙетбљзіЛсЩдЮЂдіМгдЫааЪБГЩБОЃЈР§ШчЃКдкФкДцжаЛКДцЪфШыЪ§ОнвбЗжЮіЙЄзїИКдиЃЉЁЃШчЙћУЛгаетаЉФкжУЕФВйзїИмИЫ/здЮвЙмРэЙІФмЃЌетаЉДѓаЭСїЫЎЯпЕФдЫгЊГЩБОЭЈГЃЛсЗБЖЁЃ
ЭђЮяНдШежО:HudiЛЙОпга append onlyЁЂдЦЪ§ОнгбКУЕФЩшМЦЃЌИУЩшМЦЪЕЯжСЫШежОНсЙЙЛЏДцДЂЯЕЭГЕФдРэЃЌПЩвдЮоЗьЙмРэЫљгадЦЬсЙЉЩЬЕФЪ§ОнЁЃ
Мќ-жЕЪ§ОнФЃаЭЃКдкаДЗНУцЃЌHudiБэБЛНЈФЃЮЊМќжЕЖдЪ§ОнМЏЃЌЦфжаУПЬѕМЧТМЖМгавЛИіЮЈвЛЕФМЧТММќЁЃДЫЭтЃЌвЛИіМЧТММќЛЙПЩвдАќРЈЗжЧјТЗОЖЃЌдкИУТЗОЖЯТЃЌПЩвдЖдМЧТМНјааЗжЧјКЭДцДЂЁЃетЭЈГЃгажњгкМѕЩйЫїв§ВщбЏЕФЫбЫїПеМфЁЃ
3. БэЩшМЦ
СЫНтСЫHudiЯюФПЕФЙиМќММЪѕЖЏЛњКѓЃЌЯждкШУЮвУЧИќЩюШыЕибаОПHudiЯЕЭГБОЩэЕФЩшМЦЁЃдкНЯИпЕФВуДЮЩЯЃЌгУгкаДHudiБэЕФзщМўЪЙгУСЫвЛжжЪмжЇГжЕФЗНЪНЧЖШыЕНApache
SparkзївЕжаЃЌЫќЛсдкжЇГжDFSЕФДцДЂЩЯЩњГЩДњБэHudiБэЕФвЛзщЮФМўЁЃШЛКѓЃЌдкОпгавЛЖЈБЃжЄЕФЧщПіЯТЃЌжюШчApache
SparkЁЂPrestoЁЂApache HiveжЎРрЕФВщбЏв§ЧцПЩвдВщбЏИУБэЁЃ
HudiБэЕФШ§ИіжївЊзщМўЃК
1ЃЉ гаађЕФЪБМфжсдЊЪ§ОнЁЃРрЫЦгкЪ§ОнПтЪТЮёШежОЁЃ
2ЃЉ ЗжВуВМОжЕФЪ§ОнЮФМўЃКЪЕМЪаДШыБэжаЕФЪ§ОнЁЃ
3ЃЉ Ыїв§ЃЈЖржжЪЕЯжЗНЪНЃЉЃКгГЩфАќКЌжИЖЈМЧТМЕФЪ§ОнМЏЁЃ
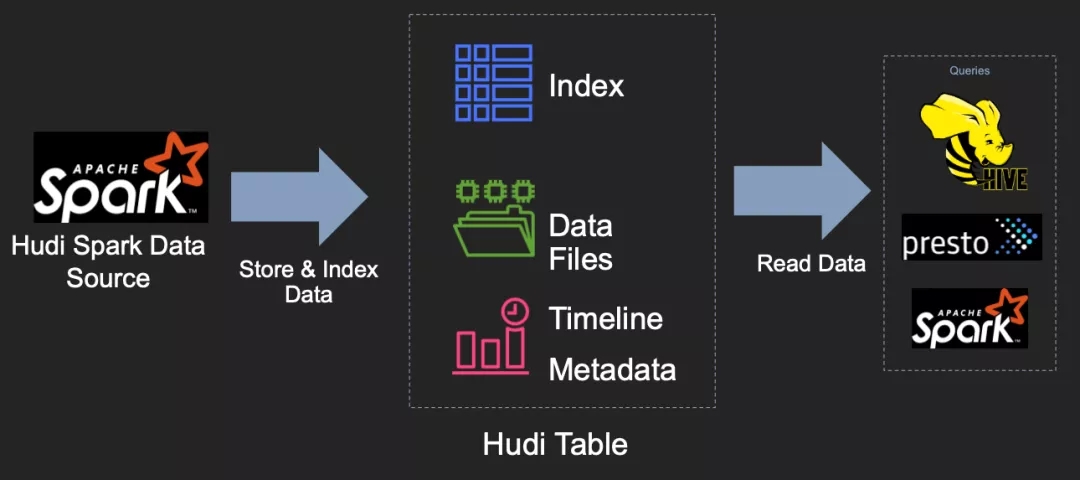
HudiЬсЙЉСЫвдЯТЙІФмРДЖдЛљДЁЪ§ОнНјаааДШыЁЂВщбЏЃЌетЪЙЦфГЩЮЊДѓаЭЪ§ОнКўЕФживЊФЃПщЃК
1ЃЉ жЇГжПьЫйЃЌПЩВхАЮЫїв§ЕФupsert();
2ЃЉ ИпаЇЁЂжЛЩЈУшаТЪ§ОнЕФдіСПВщбЏЃЛ
3ЃЉ дзгадЕФЪ§ОнЗЂВМКЭЛиЙіЃЌжЇГжЛжИДЕФSavepointЃЛ
4ЃЉ ЪЙгУmvcc(ЖрАцБОВЂЗЂПижЦ)ЗчИёЩшМЦЕФЖСКЭаДПьееИєРыЃЛ
5ЃЉ ЪЙгУЭГМЦаХЯЂЙмРэЮФМўДѓаЁЃЛ
6ЃЉ вбгаМЧТМupdate/deltaЕФздЙмРэбЙЫѕЃЛ
7ЃЉ ЩѓКЫЪ§ОнаоИФЕФЪБМфжсдЊЪ§ОнЃЛ
8ЃЉ ТњзуGDPR(ЭЈгУЪ§ОнБЃЛЄЬѕР§)ЁЂЪ§ОнЩОГ§ЙІФмЁЃ
3.1 ЪБМфжс
дкЦфКЫаФЃЌHudiЮЌЛЄСЫвЛЬѕАќКЌдкВЛЭЌЕФМДЪБЪБМфЃЈinstant timeЃЉЖдЪ§ОнМЏзіЕФЫљгаinstantВйзїЕФtimelineЃЌДгЖјЬсЙЉБэЕФМДЪБЪгЭМЃЌЭЌЪБЛЙгааЇжЇГжАДЕНДяЫГађНјааЪ§ОнМьЫїЁЃЪБМфжсРрЫЦгкЪ§ОнПтЕФredo/transactionШежОЃЌгЩвЛзщЪБМфжсЪЕР§зщГЩЁЃHudiБЃжЄдкЪБМфжсЩЯжДааЕФВйзїЕФдзгадКЭЛљгкМДЪБЪБМфЕФЪБМфжсвЛжТадЁЃЪБМфжсБЛЪЕЯжЮЊБэЛљДЁТЗОЖЯТ.hoodieдЊЪ§ОнЮФМўМаЯТЕФвЛзщЮФМўЁЃОпЬхРДЫЕЃЌзюаТЕФinstantБЛБЃДцЮЊЕЅИіЮФМўЃЌЖјНЯОЩЕФinstantБЛДцЕЕЕНЪБМфжсЙщЕЕЮФМўМажаЃЌвдЯожЦwritersКЭqueriesСаГіЕФЮФМўЪ§СПЁЃ
вЛИіHudi ЪБМфжсinstantгЩЯТУцМИИізщМўЙЙГЩЃК
1ЃЉ ВйзїРраЭЃКЖдЪ§ОнМЏжДааЕФВйзїРраЭЃЛ
2ЃЉ МДЪБЪБМфЃКМДЪБЪБМфЭЈГЃЪЧвЛИіЪБМфДС(Р§ШчЃК20190117010349)ЃЌИУЪБМфДСАДВйзїПЊЪМЪБМфЕФЫГађЕЅЕїдіМгЃЛ
3ЃЉ МДЪБзДЬЌЃКinstantЕФЕБЧАзДЬЌ;
УПИіinstantЖМгаavroЛђепjsonИёЪНЕФдЊЪ§ОнаХЯЂЃЌЯъЯИЕФУшЪіСЫИУВйзїЕФзДЬЌвдМАетИіМДЪБЪБПЬinstantЕФзДЬЌЁЃ
ЙиМќЕФInstantВйзїРраЭгаЃК
1ЃЉ COMMITЃКвЛДЮЬсНЛБэЪОНЋвЛзщМЧТМдзгаДШыЕНЪ§ОнМЏжаЃЛ
2ЃЉ CLEAN: ЩОГ§Ъ§ОнМЏжаВЛдйашвЊЕФОЩЮФМўАцБОЕФКѓЬЈЛюЖЏ;
3ЃЉ DELTA_COMMIT:НЋвЛХњМЧТМдзгаДШыЕНMergeOnReadДцДЂРраЭЕФЪ§ОнМЏжаЃЌЦфжавЛаЉ/ЫљгаЪ§ОнЖМПЩвджЛаДЕНдіСПШежОжа;
4ЃЉ COMPACTION: аЕїHudiжаВювьЪ§ОнНсЙЙЕФКѓЬЈЛюЖЏЃЌР§ШчЃКНЋИќаТДгЛљгкааЕФШежОЮФМўБфГЩСаИёЪНЁЃдкФкВПЃЌбЙЫѕБэЯжЮЊЪБМфжсЩЯЕФЬиЪтЬсНЛ;
5ЃЉ ROLLBACK: БэЪОЬсНЛ/діСПЬсНЛВЛГЩЙІЧввбЛиЙіЃЌЩОГ§дкаДШыЙ§ГЬжаВњЩњЕФЫљгаВПЗжЮФМў;
6ЃЉ SAVEPOINT: НЋФГаЉЮФМўзщБъМЧЮЊ"вбБЃДц"ЃЌвдБуЧхРэГЬађВЛЛсНЋЦфЩОГ§ЁЃдкЗЂЩњджФб/Ъ§ОнЛжИДЕФЧщПіЯТЃЌЫќгажњгкНЋЪ§ОнМЏЛЙдЕНЪБМфжсЩЯЕФФГИіЕу;
ШЮКЮИјЖЈЕФМДЪБЖМЛсДІгквдЯТзДЬЌжЎвЛЃК
1ЃЉ REQUESTED:БэЪОвбЕїЖШЕЋЩаЮДГѕЪМЛЏЃЛ
2ЃЉ INFLIGHT: БэЪОЕБЧАе§дкжДааИУВйзї;
3ЃЉ COMPLETED: БэЪОдкЪБМфжсЩЯЭъГЩСЫИУВйзї.
3.2 Ъ§ОнЮФМў
HudiНЋБэзщжЏГЩDFSЩЯЛљБОТЗОЖЯТЕФЮФМўМаНсЙЙжаЁЃШчЙћБэЪЧЗжЧјЕФЃЌдђдкЛљБОТЗОЖЯТЛЙЛсгаЦфЫћЕФЗжЧјЃЌетаЉЗжЧјЪЧАќКЌИУЗжЧјЪ§ОнЕФЮФМўМаЃЌгыHiveБэЗЧГЃРрЫЦЁЃУПИіЗжЧјОљгЩЯрЖдгкЛљБОТЗОЖЕФЗжЧјТЗОЖЮЈвЛБъЪЖЁЃдкУПИіЗжЧјФкЃЌЮФМўБЛзщжЏГЩЮФМўзщЃЌгЩЮФМўIDЮЈвЛБъЪЖЁЃЦфжаУПИіЧаЦЌАќКЌдкФГИіЬсНЛ/бЙЫѕМДЪБЪБМфЩњГЩЕФЛљБОСаЮФМўЃЈ*.parquetЃЉвдМАвЛзщШежОЮФМўЃЈ*.log*ЃЉЃЌИУЮФМўАќКЌздЩњГЩЛљБОЮФМўвдРДЖдЛљБОЮФМўЕФВхШы/ИќаТЁЃHudiВЩгУСЫMVCCЩшМЦЃЌбЙЫѕВйзїЛсНЋШежОКЭЛљБОЮФМўКЯВЂвдВњЩњаТЕФЮФМўЦЌЃЌЖјЧхРэВйзїдђНЋЮДЪЙгУЕФ/НЯОЩЕФЮФМўЦЌЩОГ§вдЛиЪеDFSЩЯЕФПеМфЁЃ
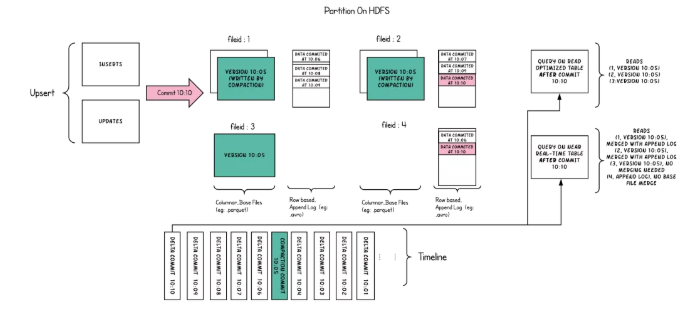
3.3 Ыїв§
HudiЭЈЙ§Ыїв§ЛњжЦЬсЙЉИпаЇЕФupsertВйзїЃЌИУЛњжЦЛсНЋвЛИіМЧТММќ+ЗжЧјТЗОЖзщКЯвЛжТадЕФгГЩфЕНвЛИіЮФМўID.етИіМЧТММќКЭЮФМўзщ/ЮФМўIDжЎМфЕФгГЩфздМЧТМБЛаДШыЮФМўзщПЊЪМОЭВЛЛсдйИФБфЁЃМђЖјбджЎЃЌетИігГЩфЮФМўзщАќКЌСЫвЛзщЮФМўЕФЫљгаАцБОЁЃHudiЕБЧАЬсЙЉСЫ3жжЫїв§ЪЕЯжЃЈHBaseIndex,ЁЂHoodieBloomIndexЃЈHoodieGlobalBloomIndexЃЉЁЂInMemoryHashIndexЃЉРДгГЩфвЛИіМЧТММќЕНАќКЌИУМЧТМЕФЮФМўIDЁЃетНЋЪЙЮвУЧЮоашЩЈУшБэжаЕФУПЬѕМЧТМЃЌОЭПЩЯджјЬсИпupsertЫйЖШЁЃ
HudiЫїв§ПЩвдИљОнЦфВщбЏЗжЧјМЧТМЕФФмСІНјааЗжРрЃК
1ЃЉ ШЋОжЫїв§ЃКВЛашвЊЗжЧјаХЯЂМДПЩВщбЏМЧТММќгГЩфЕФЮФМўIDЁЃБШШчЃЌаДГЬађПЩвдДЋШыnullЛђепШЮКЮзжЗћДЎзїЮЊЗжЧјТЗОЖЃЈpartitionPathЃЉ,ЕЋЫїв§ШдШЛЛсВщевЕНИУМЧТМЕФЮЛжУЁЃШЋОжЫїв§дкМЧТММќдкећеХБэжаБЃжЄЮЈвЛЕФЧщПіЯТЗЧГЃгагУЃЌЕЋЪЧВщбЏЕФЯћКФЫцзХБэЕФДѓаЁГЪКЏЪ§ЪНдіМгЁЃ
2ЃЉ ЗЧШЋОжЫїв§ЃКгыШЋОжЫїв§ВЛЭЌЃЌЗЧШЋОжЫїв§вРРЕЗжЧјТЗОЖ(partitionPath),ЖдгкИјЖЈЕФМЧТММќЃЌЫќжЛЛсдкИјЖЈЗжЧјТЗОЖЯТВщевИУМЧТМЁЃетБШНЯЪЪКЯзмЪЧЭЌЪБЩњГЩЗжЧјТЗОЖКЭМЧТММќЕФГЁОАЃЌЭЌЪБЛЙФмЯэЪмЕНИќКУЕФРЉеЙадЃЌвђЮЊВщбЏЫїв§ЕФЯћКФжЛгыаДШыЕНИУЗжЧјЯТЪ§ОнМЏДѓаЁгаЙиЯЕЁЃ
4. БэРраЭ
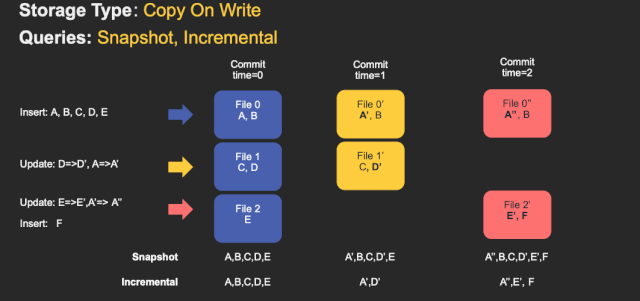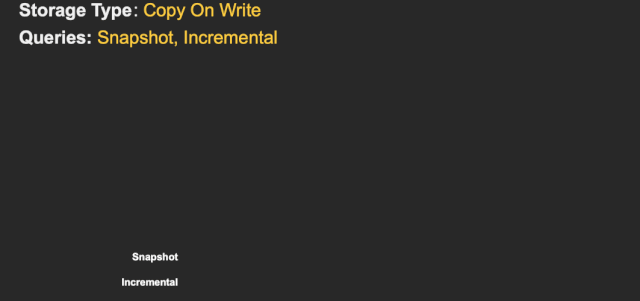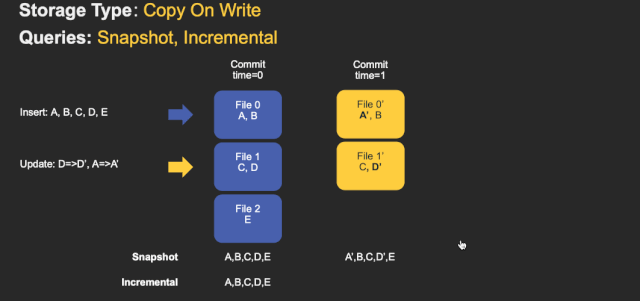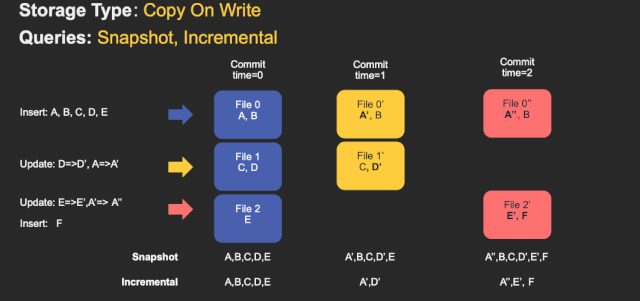
4.1 Copy On WriteБэ
COWБэаДЕФЪБКђЪ§ОнжБНгаДШыbasefile,ЃЈparquetЃЉВЛаДlogЮФМўЁЃЫљвдCOWБэЕФЮФМўЦЌжЛАќКЌbasefile(вЛИіparquetЮФМўЙЙГЩвЛИіЮФМўЦЌ)ЁЃ
етжжЕФДцДЂЗНЪНЕФSpark DAGЯрЖдМђЕЅЁЃЙиМќФПБъЪЧЪЧЪЙгУpartitionerНЋtagged HudiМЧТМRDDЃЈЫљЮНЕФtaggedЪЧжИвбОЭЈЙ§Ыїв§ВщбЏЃЌБъМЧУПЬѕЪфШыМЧТМдкБэжаЕФЮЛжУЃЉЗжГЩвЛаЉСаЕФupdatesКЭinserts.ЮЊСЫЮЌЛЄЮФМўДѓаЁЃЌЮвУЧЯШЖдЪфШыНјааВЩбљЃЌЛёЕУвЛИіЙЄзїИКдиprofile,етИіprofileМЧТМСЫЪфШыМЧТМЕФinsertКЭupdateЁЂвдМАдкЗжЧјжаЕФЗжВМЕШаХЯЂЁЃАбЪ§ОнДгаТДђАќЃЌетбљЃК
1ЃЉ Ждгкupdates, ИУЮФМўIDЕФзюаТАцБОЖМНЋБЛжиаДвЛДЮЃЌВЂЖдЫљгавбИќИФЕФМЧТМЪЙгУаТжЕ
2ЃЉ Ждгкinserts.МЧТМЪзЯШДђАќЕНУПИіЗжЧјТЗОЖжаЕФзюаЁЮФМўжаЃЌжБЕНДяЕНХфжУЕФзюДѓДѓаЁЁЃжЎКѓЕФЫљгаЪЃгрМЧТМНЋдйДЮДђАќЕНаТЕФЮФМўзщЃЌаТЕФЮФМўзщвВЛсТњзузюДѓЮФМўДѓаЁвЊЧѓЁЃ
4.2 Merge On ReadБэ
MORБэаДЪ§ОнЪБЃЌМЧТМЪзЯШЛсБЛПьЫйЕФаДНјШежОЮФМўЃЌЩдКѓЛсЪЙгУЪБМфжсЩЯЕФбЙЫѕВйзїНЋЦфгыЛљДЁЮФМўКЯВЂЁЃИљОнВщбЏЪЧЖСШЁШежОжаЕФКЯВЂПьееСїЛЙЪЧБфИќСїЃЌЛЙЪЧНіЖСШЁЮДКЯВЂЕФЛљДЁЮФМўЃЌMORБэжЇГжЖржжВщбЏРраЭЁЃ
дкИпВуДЮЩЯЃЌMOR writerдкЖСШЁЪ§ОнЪБЛсОРњгыCOW writer ЯрЭЌЕФНзЖЮЁЃетаЉИќаТНЋзЗМгЕНзюаТЮФМўЦЊЕФзюаТШежОЮФМўжаЃЌЖјВЛЛсКЯВЂЁЃ
Ждгкinsert,HudiжЇГжСНжжФЃЪНЃК
1ЃЉ ВхШыЕНШежОЮФМўЃКгаПЩЫїв§ШежОЮФМўЕФБэЛсжДааДЫВйзїЃЈHBaseЫїв§ЃЉЃЛ
2ЃЉ ВхШыparquetЮФМўЃКУЛгаЫїв§ЮФМўЕФБэЃЈР§ШчВМТЁЫїв§ЃЉ
гыаДЪБИДжЦЃЈCOWЃЉвЛбљЃЌЖдвбБъМЧЮЛжУЕФЪфШыМЧТМНјааЗжЧјЃЌвдБуНЋЫљгаЗЂЭљЯрЭЌЮФМўidЕФupsertЗжЕНвЛзщЁЃетХњupsertЛсзїЮЊвЛИіЛђЖрИіШежОПщаДШыШежОЮФМўЁЃHudiдЪаэПЭЛЇЖЫПижЦШежОЮФМўДѓаЁЁЃЖдгкаДЪБИДжЦЃЈCOWЃЉКЭЖСЪБКЯВЂЃЈMORЃЉwriterРДЫЕЃЌHudiЕФWriteClientЪЧЯрЭЌЕФЁЃМИТжЪ§ОнЕФаДШыНЋЛсРлЛ§вЛИіЛђЖрИіШежОЮФМўЁЃетаЉШежОЮФМўгыЛљБОЕФparquetЮФМўЃЈШчгаЃЉвЛЦ№ЙЙГЩвЛИіЮФМўЦЌЃЌЖјетИіЮФМўЦЌДњБэИУЮФМўЕФвЛИіЭъећАцБОЁЃ
етжжБэЪЧгУЭОзюЙуЁЂзюИпМЖЕФБэЁЃЮЊаДЃЈПЩвджИЖЈВЛЭЌЕФбЙЫѕВпТдЃЌЮќЪеЭЛЗЂаДСїСПЃЉКЭВщбЏЃЈР§ШчШЈКтЪ§ОнЕФаТЯЪЖШКЭВщбЏадФмЃЉЬсЙЉСЫКмДѓЕФСщЛюадЁЃЭЌЪБЫќАќКЌвЛИібЇЯАЧњЯпЃЌвдБудкВйзїЩЯеЦПиЫћЁЃ

5. аДЩшМЦ
5.1 аДВйзї
СЫНтHudiЪ§ОндДЛђепdeltastreamerЙЄОпЬсЙЉЕФ3жжВЛЭЌаДВйзївдМАШчКЮзюКУЕФРћгУЫћУЧПЩФмЛсгаЫљАяжњЁЃетаЉВйзїПЩвддкЖдЪ§ОнМЏЗЂГіЕФУПИіcommit/delta
commitжаНјаабЁдё/ИќИФЁЃ
1ЃЉ upsertВйзїЃКетЪЧФЌШЯВйзїЃЌдкИУВйзїжаЃЌЪзЯШЭЈЙ§ВщбЏЫїв§НЋЪ§ОнМЧТМБъМЧЮЊВхШыЛђИќаТЃЌШЛКѓдйдЫааЪдЬНЗЈШЗЖЈШчКЮзюКУЕиНЋЫћУЧДђАќЕНДцДЂЃЌвдЖдЮФМўДѓаЁНјаагХЛЏЃЌзюжеНЋМЧТМаДШыЁЃЖдгкжюШчЪ§ОнПтИќИФВЖЛёжЎРрЕФгУР§ЃЌНЈвщдкЪфШыМИКѕПЯЖЈАќКЌИќаТЕФЧщПіЯТЪЙгУДЫВйзїЁЃ
2ЃЉ insertВйзїЃКгыupsertЯрБШЃЌinsertВйзївВЛсдЫааЪдЬНЗЈШЗЖЈДђАќЗНЪНЃЌгХЛЏЮФМўДѓаЁЃЌЕЋЛсЭъШЋЬјЙ§Ыїв§ВщбЏЁЃвђДЫЖдгкжюШчШежОжиИДЪ§ОнЩОГ§ЃЈНсКЯЯТУцЬсЕНЕФЙ§ТЫжиИДЯюбЁЯюЃЉЕФгУР§ЖјбдЃЌЫќБШupsertЕФЫйЖШПьЕУЖрЁЃетвВЪЪгУгкЪ§ОнМЏПЩвдШнШЬжиИДЯюЃЌЕЋжЛашвЊHudiОпгаЪТЮёадаД/діСПРШЁ/ДцДЂЙмРэЙІФмЕФгУР§ЁЃ
3ЃЉ bulk insertВйзїЃКupsert КЭinsertВйзїЖМЛсНЋЪфШыМЧТМБЃСєдкФкДцжаЃЌвдМгПьДцДЂЦєЗЂЪНМЦЫуЫйЖШЃЌвђДЫЖдгкзюГѕМгди/в§ЕМHudiЪ§ОнМЏЕФгУР§ЖјбдПЩФмЛсКмТщЗГЁЃBulk
insertЬсЙЉСЫгыinsertЯрЭЌЕФгявхЃЌЭЌЪБЪЕЯжСЫЛљгкХХађЕФЪ§ОнаДШыЫуЗЈЃЌИУЫуЗЈПЩвдКмКУЕФРЉеЙЪ§АйTBЕФГѕЪМИКдиЁЃЕЋЪЧетжЛЪЧдкЕїећЮФМўДѓаЁЗНУцНјааЕФзюДѓХЌСІЃЌЖјВЛЪЧЯёinsert/updateФЧбљБЃжЄЮФМўДѓаЁЁЃ
5.2 бЙЫѕ
бЙЫѕЪЧвЛИі instantВйзїЃЌЫќНЋвЛзщЮФМўЦЌзїЮЊЪфШыЃЌНЋУПИіЮФМўЧаЦЌжаЕФЫљгаШежОЮФМўгыЦфbasefileЮФМўЃЈparquetЮФМўЃЉКЯВЂЃЌвдЩњГЩаТЕФбЙЫѕЮФМўЦЌЃЌВЂаДЮЊЪБМфжсЩЯЕФвЛИіcommitЁЃбЙЫѕНіЪЪгУгкЖСЪБКЯВЂЃЈMORЃЉБэРраЭЃЌВЂЧвгЩбЙЫѕВпТдЃЈФЌШЯбЁдёОпгазюДѓЮДбЙЫѕШежОЕФЮФМўЦЌЃЉОіЖЈбЁдёвЊНјаабЙЫѕЕФЮФМўЦЌЁЃетИібЙЫѕВпТдЛсдкУПИіаДВйзїжЎКѓЦРЙРЁЃ
ДгИпВуДЮЩЯНВЃЌбЙЫѕгаСНжжЗНЪНЃК
1ЃЉЭЌВНбЙЫѕЃКетРяЕФбЙЫѕгЩаДГЬађНјГЬБОЩэдкУПДЮаДШыжЎКѓЭЌВНжДааЕФЃЌМДжБЕНбЙЫѕЭъГЩКѓВХФмПЊЪМЯТвЛИіаДВйзїЁЃОЭВйзїЖјбдЃЌетИіЪЧзюМђЕЅЕФЃЌвђЮЊЮоашАВХХЕЅЖРЕФбЙЫѕЙ§ГЬЃЌЕЋБЃжЄЕФЪ§ОнаТЯЪЖШзюЕЭЁЃВЛЙ§ЃЌШчЙћПЩвддкУПДЮаДВйзїжабЙЫѕзюаТЕФБэЗжЧјЃЌЭЌЪБгжФмбгГйГйЕН/НЯОЩЗжЧјЕФбЙЫѕЃЌетжжЗНЪНШдШЛЗЧГЃгагУЁЃ
2ЃЉвьВНбЙЫѕЃКЪЙгУетжжЗНЪНЃЌбЙЫѕЙ§ГЬПЩвдгыБэЕФаДВйзїЭЌЪБвьВНдЫааЁЃетбљОпгаУїЯдЕФКУДІЃЌМДбЙЫѕВЛЛсзшШћЯТвЛХњЪ§ОнаДШыЃЌДгЖјВњЩњНќЪЕЪБЕФЪ§ОнаТЯЪЖШЁЃHudi
DeltaStreamerжЎРрЕФЙЄОпжЇГжБпНчЕФСЌајФЃЪНЃЌЦфжаЕФбЙЫѕКЭаДШыВйзїОЭЪЧвдетжжЗНЪНдкЕЅИіSparkдЫааЪБМЏШКжаНјааЕФЁЃ
5.3 ЧхРэ
ЧхРэЪЧвЛЯюЛљБОЕФМДЪБВйзїЃЌЦфжДааЕФФПЕФЪЧЩОГ§ОЩЕФЮФМўЦЌЃЌВЂЯожЦБэеМгУЕФДцДЂПеМфЁЃЧхРэЛсдкУПДЮаДВйзїжЎКѓздЖЏжДааЃЌВЂРћгУЪБМфжсЗўЮёЦїЩЯЛКДцЕФЪБМфжсдЊЪ§ОнРДБмУтЩЈУшећИіБэРДЦРЙРЧхРэЪБЛњЁЃ
HudiжЇГжСНжжЧхРэЗНЪНЃК
1ЃЉ АДcommits / deltacommitsЧхРэЃКетЪЧдіСПВщбЏжазюГЃМћЧвБиаыЪЙгУЕФФЃЪНЁЃвдетжжЗНЪНЃЌCleanerЛсБЃСєзюНќNДЮcommit/delta
commitЬсНЛжааДШыЕФЫљгаЮФМўЧаЦЌЃЌДгЖјгааЇЬсЙЉдкШЮКЮМДЪБЗЖЮЇФкНјаадіСПВщбЏЕФФмСІЁЃОЁЙметЖдгкдіСПВщбЏКмгаАяжњЃЌЕЋгЩгкБЃСєСЫХфжУЗЖЮЇФкЫљгаАцБОЕФЮФМўЦЌЃЌвђДЫЃЌдкФГаЉИпаДШыИКдиЕФГЁОАЯТПЩФмашвЊИќДѓЕФДцДЂПеМфЁЃ
2ЃЉ АДБЃСєЕФЮФМўЦЌЧхРэЃКетЪЧвЛжжИќЮЊМђЕЅЕФЧхРэЗНЪНЃЌетРяЮвУЧНіБЃДцУПИіЮФМўзщжаЕФзюКѓNИіЮФМўЦЌЁЃжюШчApache
HiveжЎРрЕФФГаЉВщбЏв§ЧцЛсДІРэЗЧГЃДѓЕФВщбЏЃЌетаЉВщбЏПЩФмашвЊМИИіаЁЪБВХФмЭъГЩЃЌдкетжжЧщПіЯТЃЌНЋNЩшжУЮЊзуЙЛДѓвджСгкВЛЛсЩОГ§ВщбЏШдШЛПЩвдЗУЮЪЕФЮФМўЦЌЪЧКмгагУЕФЁЃ
ДЫЭтЃЌЧхРэВйзїЛсБЃжЄУПИіЮФМўзщЯТУцЛсвЛжБжЛгавЛИіЮФМўЦЌЃЈзюаТЕФвЛЦЌЃЉЁЃ
5.4 DFSЗУЮЪгХЛЏ
HudiЛЙЖдБэжаДцДЂЕФЪ§ОнжДааСЫМИжжУидПДцДЂЙмРэЙІФмЁЃдкDFSЩЯДцДЂЪ§ОнЕФЙиМќЪЧЙмРэЮФМўДѓаЁКЭМЦЪ§вдМАЛиЪеДцДЂПеМфЁЃР§ШчЃЌHDFSдкДІРэаЁЮФМўЮЪЬтЩЯГєУћебжј--дкNameNodeЩЯЪЉМгФкДц/RPCбЙСІЃЌПЩФмЦЦЛЕећИіМЏШКЕФЮШЖЈадЁЃЭЈГЃЃЌВщбЏв§ЧцПЩдкЪЪЕБДѓаЁЕФСаЮФМўЩЯЬсЙЉИќКУЕФадФмЃЌвђЮЊЫќУЧПЩвдгааЇЕиЬЏЯњЛёШЁСаЭГМЦаХЯЂЕШЕФГЩБОЁЃМДЪЙдкФГаЉдЦЪ§ОнДцДЂЩЯЃЌСаГіАќКЌДѓСПаЁЮФМўЕФФПТМвВЛсВњЩњГЩБОЁЃ
ЯТУцЪЧвЛаЉHudiИпаЇаДЃЌЙмРэЪ§ОнДцДЂЕФЗНЗЈЃК
1ЃЉаЁЮФМўДІРэЬиадЛсЦЪЮіЪфШыЕФЙЄзїИКдиЃЌВЂНЋФкШнЗжХфЕНЯжгаЕФЮФМўзщЃЌЖјВЛЪЧДДНЈаТЮФМўзщЃЈетЛсЕМжТЩњГЩаЁЮФМўЃЉЁЃ
2ЃЉдкwriterжаЪЙгУвЛИіЪБМфжсЛКДцЃЌетбљжЛвЊSparkМЏШКВЛУПДЮЖМжиЦєЃЌКѓајЕФаДВйзїОЭВЛашвЊСаГіDFSФПТМРДЛёШЁжИЖЈЗжЧјТЗОЖЯТЕФЮФМўЦЌСаБэЁЃ
3ЃЉгУЛЇЛЙПЩвдЕїећЛљБОЮФМўКЭШежОЮФМўДѓаЁжЎМфЕФБШжЕЯЕЪ§вдМАЦкЭћЕФбЙЫѕТЪЃЌвдБуНЋзуЙЛЪ§СПЕФinsertЗжЕНЭГвЛЮФМўзщЃЌДгЖјЩњГЩДѓаЁКЯЪЪЕФЛљБОЮФМўЁЃ
4ЃЉжЧФмЕїећbulk insertВЂааЖШЃЌПЩвддйДЮЕїећДѓаЁКЯЪЪЕФГѕЪМЮФМўзщЁЃЪЕМЪЩЯЃЌе§ШЗжДааДЫВйзїЗЧГЃЙиМќЃЌвђЮЊЮФМўзщвЛЕЉДДНЈОЭВЛФмБЛЩОГ§ЃЌЖјжЧФмШчЧАУцЫљЪіЖдЦфНјааРЉеЙЁЃ
6.ВщбЏ
МјгкетжжСщЛюЖјШЋУцЕФЪ§ОнВМОжКЭЗсИЛЕФЪБМфЯпЃЌHudiФмЙЛжЇГжШ§жжВЛЭЌЕФВщбЏБэЗНЪНЃЌОпЬхШЁОігкБэЕФРраЭЁЃ
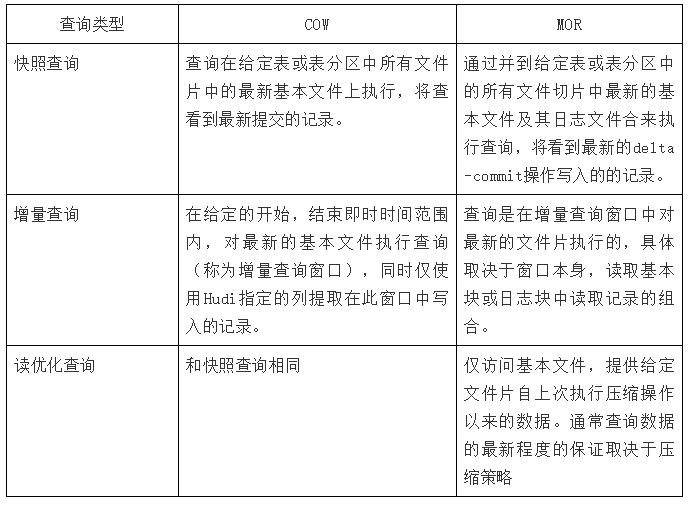
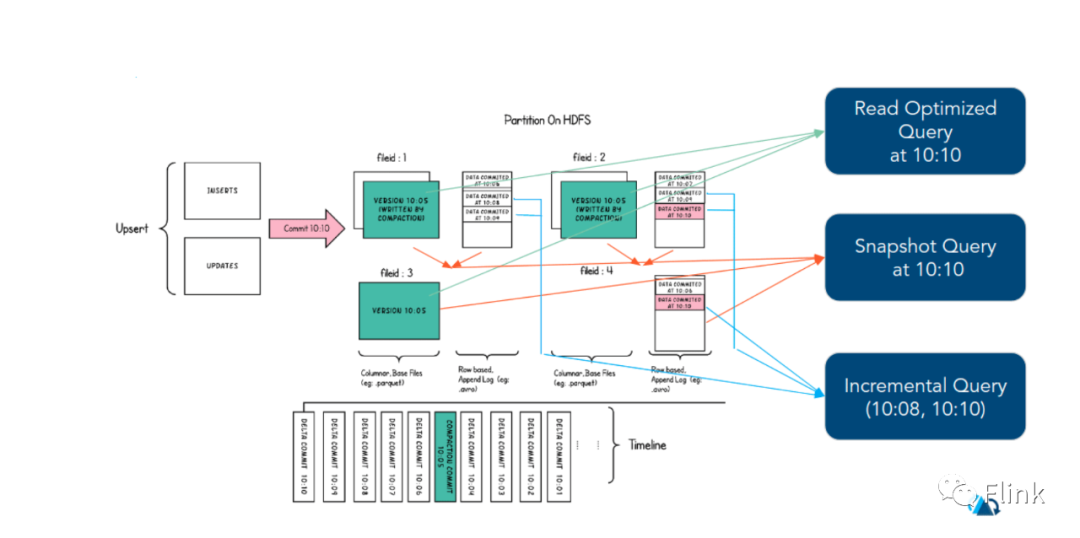
6.1 ПьееВщбЏ
ПЩВщПДИјЖЈdelta commitЛђепcommitМДЪБВйзїКѓБэЕФзюаТПьееЁЃдкЖСЪБКЯВЂЃЈMORЃЉБэЕФЧщПіЯТЃЌЫќЭЈЙ§МДЪБКЯВЂзюаТЮФМўЦЌЕФЛљБОЮФМўКЭдіСПЮФМўРДЬсЙЉНќЪЕЪББэЃЈМИЗжжгЃЉЁЃЖдгкаДЪБИДжЦЃЈCOWЃЉЃЌЫќПЩвдЬцДњЯжгаЕФparquetБэЃЈЛђЯрЭЌЛљБОЮФМўРраЭЕФБэЃЉЃЌЭЌЪБЬсЙЉupsert/deleteКЭЦфЫћаДШыЗНУцЕФЙІФмЁЃ
6.2 діСПВщбЏ
ПЩВщПДздИјЖЈcommit/delta commitМДЪБВйзївдРДаТаДШыЕФЪ§ОнЁЃгааЇЕФЬсЙЉБфИќСїРДЦєгУдіСПЪ§ОнЙмЕРЁЃ
6.3 ЖСгХЛЏВщбЏ
ПЩВщПДИјЖЈЕФcommit/compactМДЪБВйзїЕФБэЕФзюаТПьееЁЃНіНЋзюаТЮФМўЦЌЕФЛљБО/СаЮФМўБЉТЖИјВщбЏЃЌВЂБЃжЄгыЗЧHudiБэЯрЭЌЕФСаВщбЏадФмЁЃ

| 








