| БрМЭЦМі: |
БОЮФжиЕуНщЩмСЫРэНт3жжЪ§ОнСїЗжЮіЕФКЌвхЃЌШчКЮЩшМЦРрЫЦЕФЫуЗЈЃЌШчКЮгХЛЏЃЌРэНтжжЪ§ОнСїЗжЮіЕФЙВадгыЧјБ№ЃЌРэНтжжЪ§ОнСїЗжЮіЕФЙВадгыЧјБ№ЁЃ
БОЮФРДздМђЪщЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ
|
|
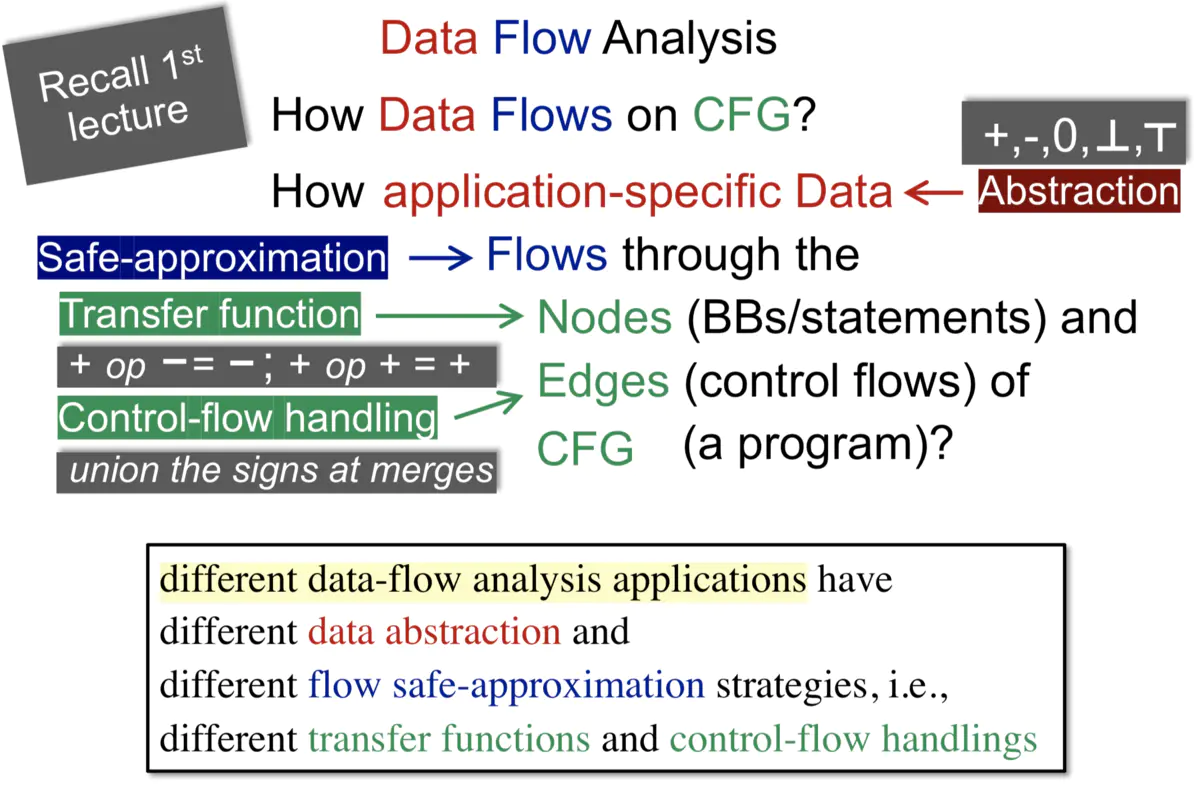
1.Ъ§ОнСїЗжЮізмРР
may analysisЃКЪфГіПЩФме§ШЗЕФаХЯЂЃЈашзіover-approximationгХЛЏЃЌВХФмГЩЮЊSafe-approximationАВШЋЕФНќЫЦЃЌПЩвдгаЮѓБЈ-completenessЃЉЃЌзЂвтДѓЖрЪ§ОВЬЌЗжЮіЖМЪЧmay
analysis
must analysisЃКЪфГіБиаые§ШЗЕФаХЯЂЃЈашзіunder-approximationгХЛЏЃЌВХФмГЩЮЊSafe-approximationАВШЋЕФНќЫЦЃЌПЩвдгаТЉБЈ-soundnessЃЉ
Nodes (BBs/statements)ЁЂEdges (control flows)ЁЂCFG (a
program)
Р§ШчЃК
application-specific Data <- abstraction (+/-/0)
Nodes <- Transfer function
Edges <- Control-flow handling
ВЛЭЌЕФЪ§ОнСїЗжЮі га ВЛЭЌЕФЪ§ОнГщЯѓБэДя КЭ ВЛЭЌЕФАВШЋНќЫЦВпТдЃЌШч
ВЛЭЌЕФ зЊЛЛЙцдђ КЭ ПижЦСїДІРэЁЃ
2-1-Ъ§ОнСїЗжЮізмРР.png
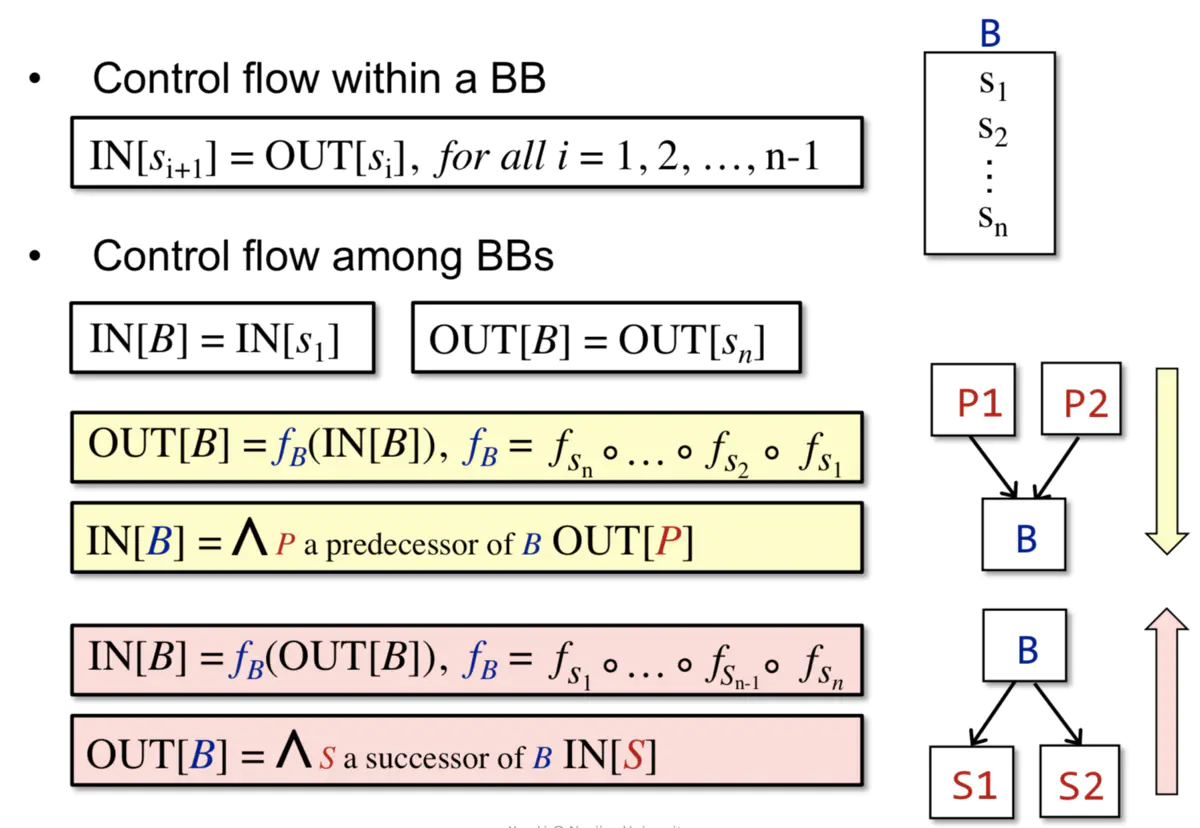
2.дЄБИжЊЪЖ
ЪфШы/ЪфГізДЬЌЃКГЬађжДааЧА/жДааКѓЕФзДЬЌЃЈБОжЪОЭЪЧГщЯѓБэДяЕФЪ§ОнЕФзДЬЌЃЌШчБфСПЕФзДЬЌЃЉЁЃ
Ъ§ОнСїЗжЮіЕФНсЙћЃКзюжеЕУЕНЃЌУПвЛИіГЬађЕуЖдгІвЛИіЪ§ОнСїжЕ(data-flow value)ЃЌБэЪОИУЕуЫљгаПЩФмГЬађзДЬЌЕФвЛИіГщЯѓЁЃР§ШчЃЌЮвжЛЙиаФxЁЂyЕФжЕЃЌЮвОЭгУГщЯѓРДБэЪОxЁЂyЫљгаПЩФмЕФжЕЕФМЏКЯЃЈЪфШы/ЪфГіЕФжЕгђ/дМЪјЃЉЃЌОЭДњБэСЫИУГЬађЕуЕФГЬађзДЬЌЁЃ
Forward AnalysisЧАЯђЗжЮіЃКАДГЬађжДааЫГађЕФЗжЮіЁЃOUT[s]=fs(IN[s])ЃЌs-statement
Backward AnalysisЗДЯђЗжЮіЃКФцЯђЗжЮіЁЃIN[s]=fs(OUT[s])
ПижЦСїдМЪјЃКдМЪјЧѓНтзіЕФЪТЧщЃЌЭЦЖЯМЦЫуЪфШыЕНЪфГіЃЌЛђЗДЯђЗжЮіЁЃ
2-2-ПижЦСїдМЪј.png
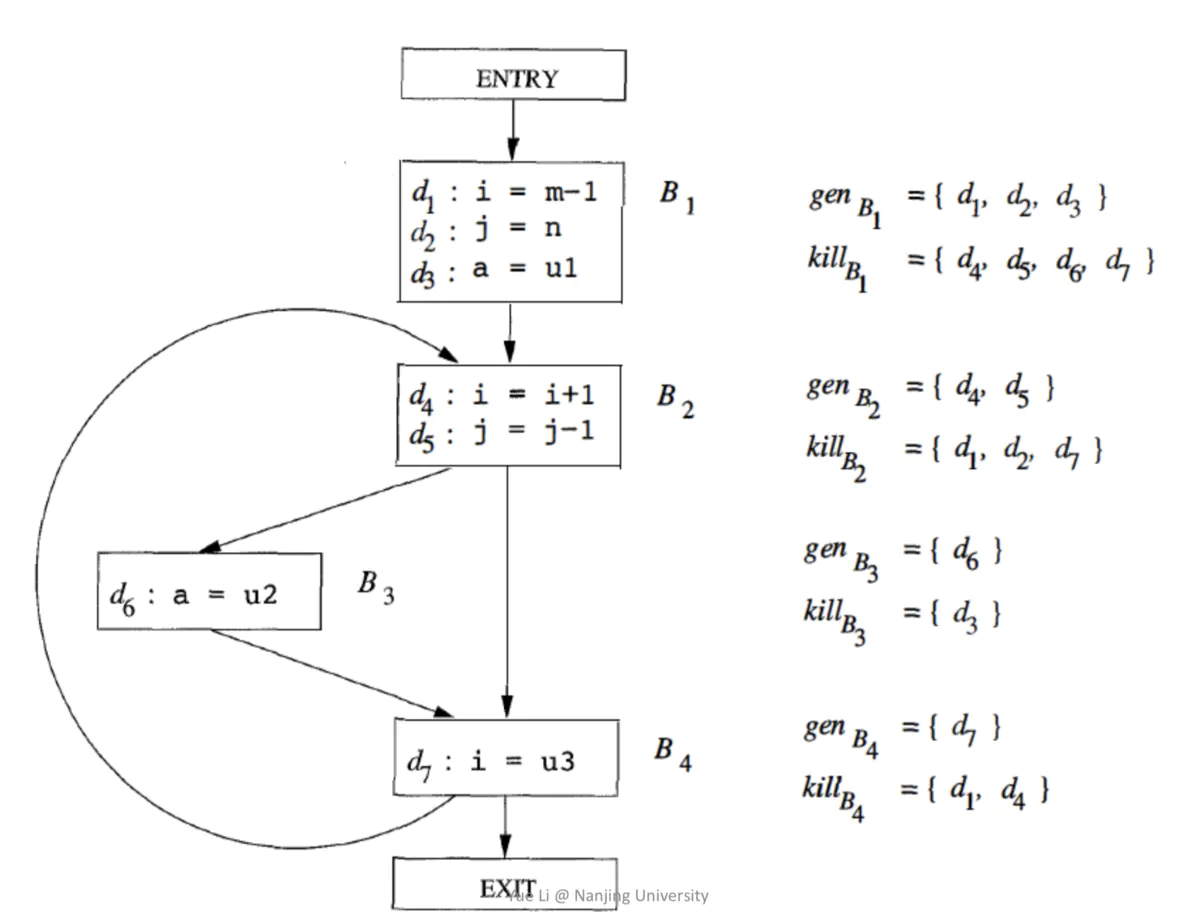
3.Reaching Definitions Analysis (may analysis)
ЮЪЬтЖЈвхЃКИјБфСПvвЛИіЖЈвхdЃЈИГжЕЃЉЃЌДцдквЛЬѕТЗОЖЪЙЕУГЬађЕуpФмЙЛЕНДяqЃЌЧвдкетИіЙ§ГЬжаВЛФмИФБфvЕФИГжЕЁЃ
гІгУОйР§ЃКМьВтЮДЖЈвхЕФБфСПЃЌШєvПЩДяpЧвvУЛгаБЛЖЈвхЃЌдђЮЊЮДЖЈвхЕФБфСПЁЃ
ГщЯѓБэЪОЃКЩшГЬађгаnЬѕИГжЕгяОфЃЌгУnЮЛЯђСПРДБэЪОФмreachгыВЛФмreachЁЃ
ЃЈ1ЃЉЙЋЪНЗжЮі
ЪВУДЪЧdefinitionЃП D: v = x op y РрЫЦгкИГжЕЁЃ
Transfer FunctionЃКOUT[B] = genB U (IN[B] - killB)
ЁЊЁЊдѕУДРэНтЃЌОЭЪЧЛљгкзЊЛЛЙцдђЖјЕУЕНЁЃ
НтЪЭЃКЛљБОПщBЕФЪфГі = ПщBФкЕФЫљгаБфСПvЕФЖЈвхЃЈИГжЕ/аоИФЃЉгяОф U ЃЈПщBЕФЪфШы - ГЬађжаЦфЫќЫљгаЖЈвхСЫБфСПvЕФгяОфЃЉЁЃБОжЪОЭЪЧБОПщгыЧАЧ§аоИФБфСПЕФгяОф
зїгУжЎКЭЃЈШЅЕєЧАЧ§ЕФжиИДаоИФгяОфЃЉЁЃ
Control FlowЃКIN[B] = Up a_predecesso_of_B Out[P] ЁЊЁЊдѕУДРэНтЃЌОЭЪЧЛљгкПижЦСїЖјЕУЕНЁЃ
НтЪЭЃКЛљБОПщBЕФЪфШы = ПщBЫљгаЧАЧ§ПщPЕФЪфГіЕФВЂМЏЁЃзЂвтЃЌЫљгаЧАЧ§ПщвтЮЖзХжЛвЊгавЛЬѕТЗОЖФмЙЛЕНДяПщBЃЌОЭЪЧЫќЕФЧАЧ§ЃЌАќРЈЬѕМўЬјзЊгыЮоЬѕМўЬјзЊЁЃ
2-3-1-Reaching_Definition.png
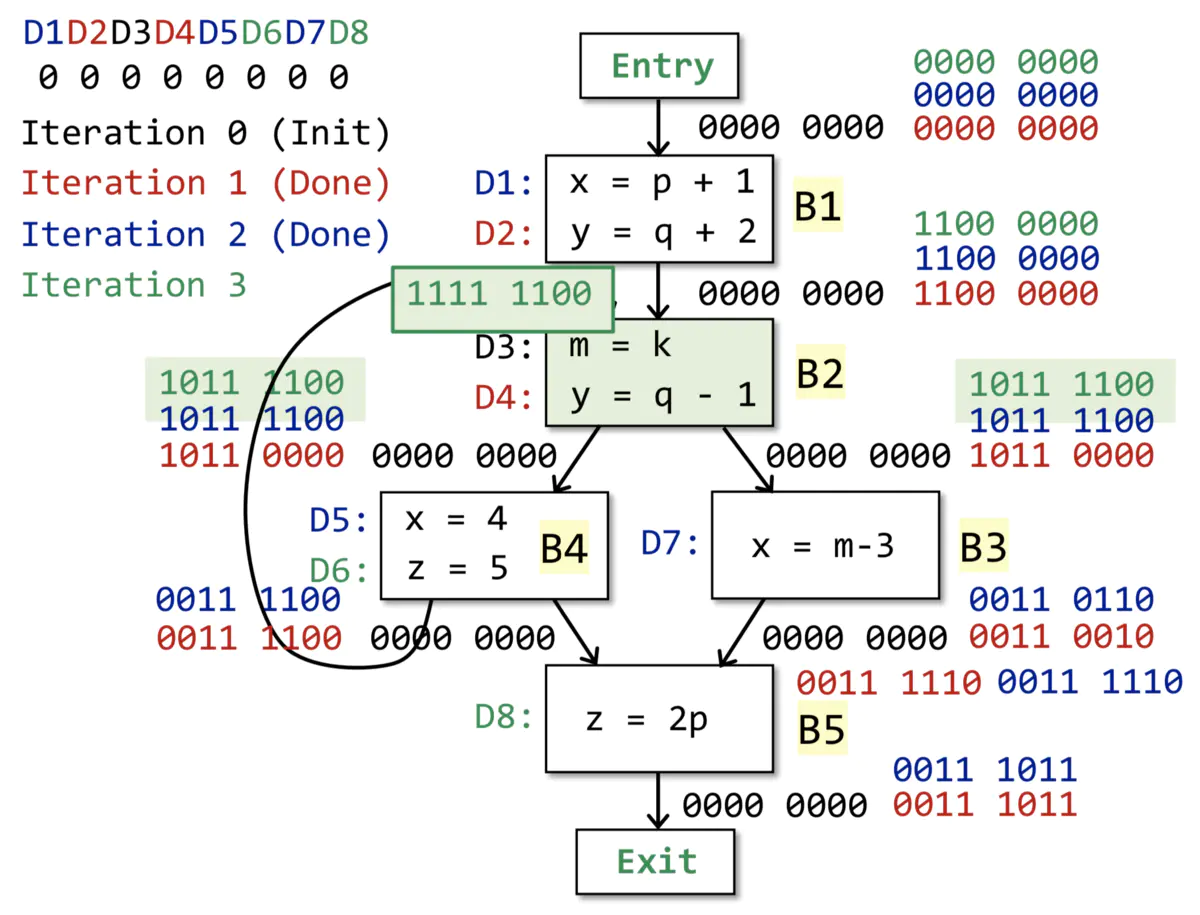
ЃЈ2ЃЉЫуЗЈ
ФПЕФЃКЪфШыCFGЃЌМЦЫуКУУПИіЛљБОПщЕФkillBЃЈГЬађжаЦфЫќПщжаЖЈвхСЫБфСПvЕФгяОфЃЉКЭgenBЃЈПщBФкЕФЫљгаБфСПvЕФЖЈвхгяОфЃЉЃЌЪфГіУПИіЛљБОПщЕФIN[B]КЭOUT[B]ЁЃ
ЗНЗЈЃКЪзЯШЫљгаЛљБОПщЕФOUT[B]ГѕЪМЛЏЮЊПеЁЃБщРњУПвЛИіЛљБОПщBЃЌАДвдЩЯСНИіЙЋЪНМЦЫуПщBЕФIN[B]КЭOUT[B]ЃЌжЛвЊетДЮБщРњЪБгаФГИіПщЕФOUT[B]ЗЂЩњБфЛЏЃЌдђжиаТБщРњвЛДЮЃЈвђЮЊГЬађжагабЛЗДцдкЃЌжЛвЊФГПщЕФOUT[B]БфСЫЃЌОЭвтЮЖзХКѓМЬПщЕФIN[B]БфСЫЃЉЁЃ

2-3-2-ПЩДяадЗжЮіЫуЗЈ.png
ЃЈ3ЃЉЪЕР§ЃК
ГщЯѓБэЪОЃКЩшГЬађгаnЬѕИГжЕгяОфЃЌгУnЮЛЯђСПРДБэЪОФмreachгыВЛФмreachЁЃ
ЫЕУїЃККьЩЋ-Ек1ДЮБщРњЃЛРЖЩЋ-Ек2ДЮБщРњЃЛТЬЩЋ-Ек3ДЮБщРњЁЃ
НсЙћЃК3ДЮБщРњжЎКѓЃЌУПИіЛљБОПщЕФOUT[B]ЖМВЛдйБфЛЏЁЃ
2-3-3БщРњЪЕР§.png
ЯждкЃЌЮвУЧПЩвдЛиЯывЛЯТЃЌЪ§ОнСїЗжЮіЕФФПБъЪЧЃЌзюКѓЕУЕНСЫЃЌУПИіГЬађЕуЙиСЊвЛИіЪ§ОнСїжЕЃЈИУЕуЫљгаПЩФмЕФГЬађзДЬЌЕФвЛИіГщЯѓБэЪОЃЌвВОЭЪЧетИіnЮЛЯђСПЃЉЁЃдкетИіЙ§ГЬжаЃЌЮвУЧЖдИіЛљБОПщЃЌВЛЖЯРћгУЛљгкзЊЛЛЙцдђЕФгявхЃЈвВОЭЪЧtransfer
functionsЃЌЙЙГЩЛљБОПщЕФгяОфМЏЃЉ-OUT[B]ЁЂПижЦСїЕФдМЪј-IN[B]ЃЌзюжеЕУЕНвЛИіЮШЖЈЕФАВШЋЕФНќЫЦдМЪјМЏЁЃ
ЃЈ4ЃЉЫуЗЈЛсЭЃжЙТ№ЃП
OUT[B] = genB U (IN[B] - killB)
ДѓжТРэНтЃКgenBКЭ killBЪЧВЛБфЕФЃЌжЛгаIN[B]дкБфЛЏЃЌЫљвдЫЕOUT[B]жЛЛсдіМгВЛЛсМѕЩйЃЌnЯђСПГЄЖШЪЧгаЯоЕФЃЌЫљвдзюжеПЯЖЈЛсЭЃжЙЁЃОпЬхЩцМАЕНВЛЖЏЕужЄУїЃЌКѓајПЮГЬЛсНВНтЁЃ
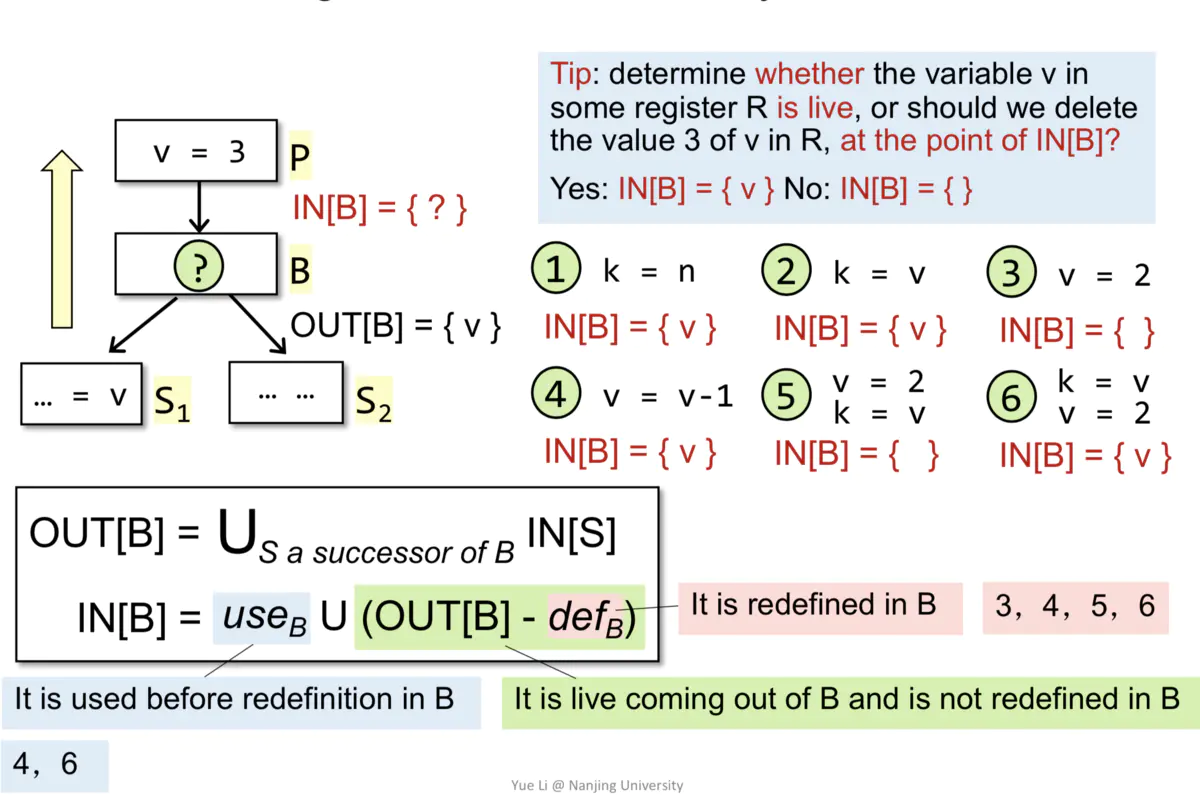
4.Live Variables Analysis (may analysis)
ЮЪЬтЖЈвхЃКФГГЬађЕуpДІЕФБфСПvЃЌДгpПЊЪМЕНexitПщЕФCFGжаЪЧЗёгаФГЬѕТЗОЖгУЕНСЫvЃЌШчЙћгУЕНСЫvЃЌдђvдкpЕуЮЊliveЃЌЗёдђЮЊdeadЁЃЦфжагавЛИівўКЌЬѕМўЃЌдкЕуpКЭв§гУЕужЎМфВЛФмжиЖЈвхvЁЃ

2-4-1-live_variablesЖЈвх.png
гІгУГЁОАЃКПЩгУгкМФДцЦїЗжХфЃЌШчЙћМФДцЦїТњСЫЃЌОЭашвЊЬцЛЛЕєВЛЛсБЛгУЕНЕФБфСПЁЃ
ГщЯѓБэЪОЃКГЬађжаЕФnИіБфСПгУГЄЖШЮЊn bitЕФЯђСПРДБэЪОЃЌЖдгІbitЮЊ1ЃЌдђИУБфСПЮЊliveЃЌЗДжЎЮЊ0дђЮЊdeadЁЃ
ЃЈ1ЃЉЙЋЪНЗжЮі
Control FlowЃКOUT[B] = US a_successor_of_BIN[S]
РэНтЃКЮвУЧЪЧЧАЯђЗжЮіЃЌжЛвЊгавЛЬѕзгТЗЪЧliveЃЌИИНкЕуОЭЪЧliveЁЃ
Transfer FunctionЃКIN[B] = useB U (OUT[B] - defB)
РэНтЃКIN[B] = БОПщжаuseГіЯждкdefineжЎЧАЕФБфСП U ЃЈOUT[B]ГіПкЕФliveЧщПі
- БОПщжаГіЯжСЫdefineЕФБфСПЃЉЁЃdefineжИЕФЪЧЖЈвх/ИГжЕЁЃ
ЬиР§ЗжЮіЃКШчвдЯТЭМЫљЪОЃЌЕк4жжЧщПіЃЌv=v-1ЃЌЪЕМЪЩЯuseГіЯждкdefineжЎЧАЃЌvЪЧЪЙгУЕФЁЃ
2-4-2-ЙЋЪНЭЦЕМ.png
ЃЈ2ЃЉЫуЗЈ
ФПЕФЃКЪфШыCFGЃЌМЦЫуКУУПИіЛљБОПщжаЕФdefBЃЈжиЖЈвхЃЉКЭuseBЃЈГіЯждкжиЖЈвхжЎЧАЕФЪЙгУЃЉЁЃЪфГіУПИіЛљБОПщЕФIN[B]КЭOUT[B]ЁЃ
ЗНЗЈЃКЪзЯШГѕЪМЛЏУПИіЛљБОПщЕФIN[B]ЮЊПеМЏЁЃБщРњУПвЛИіЛљБОПщBЃЌАДвдЩЯСНИіЙЋЪНМЦЫуПщBЕФOUT[B]КЭIN[B]ЃЌжЛвЊетДЮБщРњЪБгаФГИіПщЕФIN[B]ЗЂЩњБфЛЏЃЌдђжиаТБщРњвЛДЮЃЈвђЮЊгабЛЗЃЌжЛвЊФГПщЕФIN[B]БфСЫЃЌОЭвтЮЖЧАЧ§ПщЕФOUT[B]БфСЫЃЉЁЃ
ЮЪЬтЃКБщРњЛљБОПщЕФЫГађгавЊЧѓТ№ЃП УЛгавЊЧѓЃЌЕЋЪЧЛсгАЯьБщРњЕФДЮЪ§ЁЃ

2-4-3-live_variablesЫуЗЈ.png
ГѕЪМЛЏЙцТЩЃКвЛАуЧщПіЯТЃЌmay analysis ШЋВПГѕЪМЛЏЮЊПеЃЌmust analysisШЋВПГѕЪМЛЏЮЊallЁЃ
ЃЈ3ЃЉЪЕР§
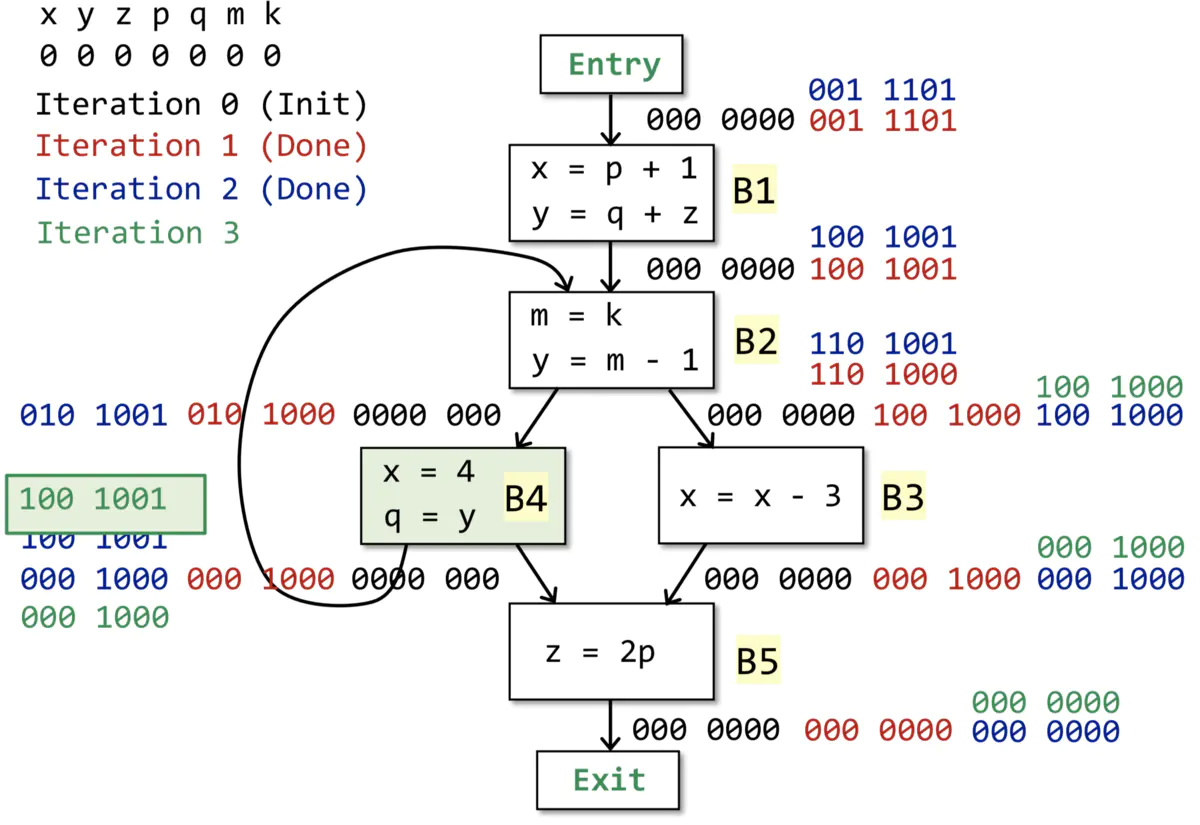
ГщЯѓБэЪОЃКГЬађжаЕФnИіБфСПгУГЄЖШЮЊn bitЕФЯђСПРДБэЪОЃЌЖдгІbitЮЊ1ЃЌдђИУБфСПЮЊliveЃЌЗДжЎЮЊ0дђЮЊdeadЁЃ
ЫЕУїЃКДгЯТЭљЩЯБщРњЛљБОПщЃЌКкЩЋ-ГѕЪМЛЏЃЛКьЩЋ-Ек1ДЮЃЛРЖЩЋ-Ек2ДЮЃЛТЬЩЋ-Ек3ДЮЁЃ
НсЙћЃК3ДЮБщРњКѓЃЌIN[B]ВЛдйБфЛЏЃЌБщРњНсЪјЁЃ
2-4-4-ЫуЗЈдЫааЪОР§.png
5.Available Expressions Analysis (must analysis)
ЮЪЬтЖЈвхЃКГЬађЕуpДІЕФБэДяЪНx op yПЩгУашТњзу2ИіЬѕМўЃЌвЛЪЧДгentryЕНpЕуБиаыОЙ§x op
yЃЌЖўЪЧзюКѓвЛДЮЪЙгУx op yжЎКѓЃЌУЛгажиЖЈвхВйзїЪ§xЁЂyЁЃЃЈШчЙћжиЖЈвхСЫx Лђ yЃЌШчx = a
op2 bЃЌдђдРДЕФБэДяЪНx op yжаЕФxЛђyОЭЛсБЛЬцДњЃЉЁЃ
гІгУГЁОАЃКгУгкгХЛЏЃЌМьВтШЋОжЙЋЙВзгБэДяЪНЁЃ
ГщЯѓБэЪОЃКГЬађжаЕФnИіБэДяЪНЃЌгУГЄЖШЮЊn bitЕФЯђСПРДБэЪОЃЌ1БэЪОПЩгУЃЌ0БэЪОВЛПЩгУЁЃ
ЫЕУїЃКЪєгкforwardЗжЮіЁЃ
ЃЈ1ЃЉЙЋЪНЗжЮі
Transfer FunctionЃКOUT[B] = genB U (IN[B] - killB)
РэНтЃКgenBЁЊЛљБОПщBжаЫљгааТЕФБэДяЪНЃЈВЂЧвдкетИіБэДяЪНжЎКѓЃЌВЛФмЖдБэДяЪНжаГіЯжЕФБфСПНјаажиЖЈвхЃЉ-->МгШыЕНOUTЃЛkillBЁЊДгINжаЩОГ§БфСПБЛжиаТЖЈвхЕФБэДяЪНЁЃ
Control FlowЃКIN[B] = P a_predecessor_of_B OUT[P]
РэНтЃКДгentryЕНpЕуЕФЫљгаТЗОЖЖМБиаыОЙ§ИУБэДяЪНЁЃ
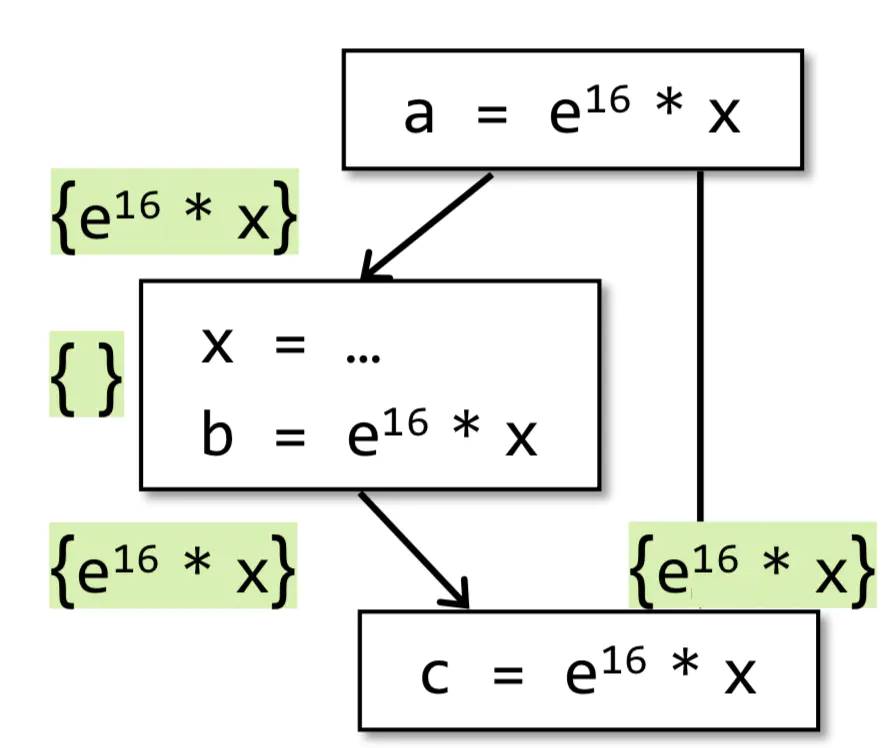
2-5-1-ПЩгУБэДяЪНЖЈвх.png
ЮЪЬтЃКИУЗжЮіЮЊЪВУДЪєгкmust analysisФиЃПвђЮЊЮвУЧдЪаэгаТЉБЈЃЌВЛФмгаЮѓБЈЃЌБШШчвдЩЯЪОР§жаЃЌИФЮЊx=3ЃЌШЅЕє
b=e16*xЃЌИУЙЋЪНЛсАбИУБэДяЪНЪЖБ№ЮЊВЛПЩгУЁЃЕЋЪТЪЕЪЧПЩгУЕФЃЌвђЮЊАбx=3ЬцЛЛЕНБэДяЪНжаВЂВЛгАЯьИУБэДяЪНЕФаЮЪНЁЃетРяЫфШЛТЉБЈСЫЃЌЕЋЪЧВЛгАЯьГЬађЗжЮіНсЙћЕФе§ШЗадЁЃ
ЃЈ2ЃЉЫуЗЈ
ФПЕФЃКЪфШыCFGЃЌЬсЧАМЦЫуКУgenBКЭkillBЁЃ
ЗНЗЈЃКЪзЯШНЋOUT[entry]ГѕЪМЛЏЮЊПеЃЌЫљгаЛљБОПщЕФOUT[B]ГѕЪМЛЏЮЊ1...1ЁЃБщРњУПвЛИіЛљБОПщBЃЌАДвдЩЯСНИіЙЋЪНМЦЫуПщBЕФIN[B]КЭOUT[B]ЃЌжЛвЊетДЮБщРњЪБгаФГИіПщЕФOUT[B]ЗЂЩњБфЛЏЃЌдђжиаТБщРњвЛДЮЃЈвђЮЊгабЛЗЃЌжЛвЊФГПщЕФOUT[B]БфСЫЃЌОЭвтЮЖКѓМЬПщЕФIN[B]БфСЫЃЉЁЃ

2-5-2-ПЩгУБэДяЪНЫуЗЈ.png
ЃЈ3ЃЉЪЕР§
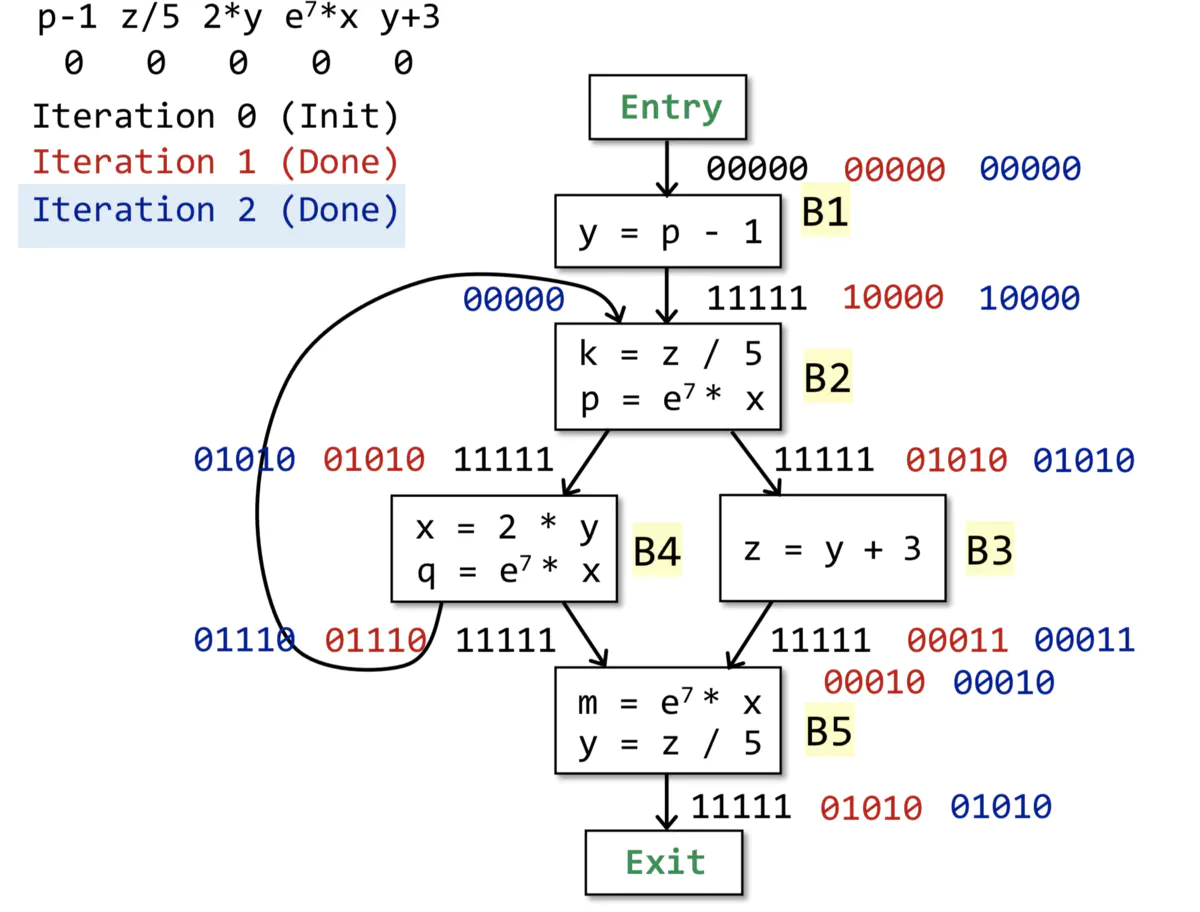
ГщЯѓБэЪОЃКГЬађжаЕФnИіБэДяЪНЃЌгУГЄЖШЮЊn bitЕФЯђСПРДБэЪОЃЌ1БэЪОПЩгУЃЌ0БэЪОВЛПЩгУЁЃ
ЫЕУїЃККкЩЋ-ГѕЪМЛЏЃЛКьЩЋ-Ек1ДЮЃЛРЖЩЋ-Ек2ДЮЁЃ
НсЙћЃК2ДЮБщРњКѓЃЌOUT[B]ВЛдйБфЛЏЃЌБщРњНсЪјЁЃ
2-5-3-ЫуЗЈдЫааЪОР§.png
6.Ш§жжЗжЮіММЪѕЖдБШ
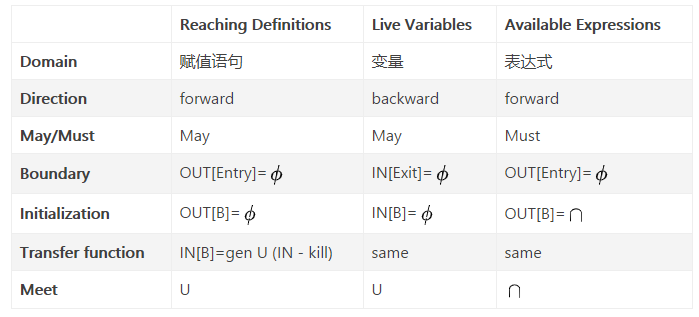
ЮЪЬтЃКдѕбљХаЖЯЪЧMayЛЙЪЧMustЃП
Reaching DefinitionsБэЪОжЛвЊДгИГжЕгяОфЕНЕуpДцдк1ЬѕТЗОЖЃЌдђЮЊreachingЃЌНсЙћВЛвЛЖЈе§ШЗЃЛLive
VariablesБэЪОжЛвЊДгЕуpЕНExitДцдк1ЬѕТЗОЖЪЙгУСЫБфСПvЃЌдђЮЊliveЃЌНсЙћВЛвЛЖЈе§ШЗЃЛAvailable
ExpressionsБэЪОДгEntryЕНЕуpЕФУПвЛЬѕТЗОЖЖМОЙ§СЫИУБэДяЪНЃЌдђЮЊavailableЃЌНсЙћПЯЖЈе§ШЗЁЃ
| 








