| БрМЭЦМі: |
БОЮФжївЊНщЩм
SQL Server ИпПЩгУОЕЯёЪЕЯждРэЃЌОЕЯёМЏШКЬсЙЉСЫШ§жждЫааФЃЪНЃЌЯЃЭћЖдДѓМвЕФбЇЯАгаАяжњЁЃ
БОЮФРДздЫбКќЭјЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
SQL Server ЪЧ windows ЦНЬЈ .NET МмЙЙЯТБъХфЪ§ОнПтНтОіЗНАИЃЌгы
OracleЁЂMySQL ЙВЭЌЙЙГЩСЫ DB-Engines Ranking ЕФЕквЛеѓгЊЃЌдкЙњФкЭтЦѓвЕЪаГЁжагазХЙуЗКЕФгІгУЁЃ
Mirroring ЪЧ SQL Server зюГЃгУЕФИпПЩгУНтОіЗНАИЃЌОпгаздЖЏЙЪеЯзЊвЦЃЌИпАВШЋФЃЪНЯТОпгаЪ§ОнЁАСуЁБЖЊЪЇЃЌЖдПЭЛЇЖЫЭИУїЕШгХЪЦЃЌФПЧАЖрМвДѓЕФдЦМЦЫуГЇЩЬОљВЩгУИУММЪѕЪЕЯждЦЖЫ
SQL Server ИпПЩгУВПЪ№ЁЃНёЬьЃЌЮвУЧОЭРДСФСФ SQL Server ИпПЩгУОЕЯёЪЕЯждРэЁЃ
Ъ§ОнИББО
ОЕЯёММЪѕЪЕЯжСЫЮЛгкВЛЭЌЮяРэЗўЮёЦїЩЯЕФСНИі SQL Server ЪЕР§Ъ§ОнЭЌВНЃЌдкОЕЯёМЏШКжаЃЌ SQL
Server ЪЕР§ОпгаШ§жжНЧЩЋЃЛ
PrincipalЃКОпгаЭъећЕФЪ§ОнИББОЃЌЖдЭтЬсЙЉЪ§ОнПтЖСаДЗўЮёЃЛ
MirrorЃКОпгаЭъећЕФЪ§ОнИББОЃЌБОЩэВЛЬсЙЉЖСаДЗўЮёЃЌЭЈЙ§НгЪеРДзд Principal ЕФИќаТШежОЪЕЯжЪ§ОнЭЌВНЃЌдЪаэДДНЈПьееЪЕЯжБЈБэЃЛ
WitnessЃКБОЩэВЛДцДЂЪ§ОнЃЌжЛИКд№дкИпАВШЋдЫааФЃЪНЯТЬсЙЉздЖЏЙЪеЯЧаЛЛЕФФмСІЃЌШЗБЃСНИі SQL
Server ЪЕР§жЛгавЛИіЖдЭтЬсЙЉЗўЮёЃЌБмУтФдСбЧщПіГіЯжЃЛ
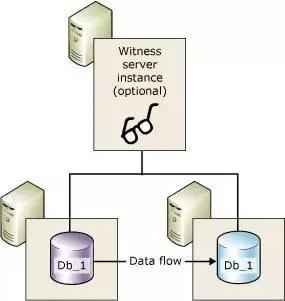
дкОЕЯёМЏШКжаЃЌprincipal КЭ mirror ЕФЪ§ОнЭЌВНЪЧвРППЪТЮёШежОРДЪЕЯжЕФЃЌгы Oracle
КЭ MySQL ВЛЭЌЃЌSQL Server ЕФЪТЮёШежОЪЧ Database МЖБ№ЕФЃЌВЛЪЧЪЕР§МЖБ№ЕФЃЌУПИі
Database ЖМЕЅЖРЕФЪТЮёШежОЃЌетвВОЭЪЙЕУ SQL Server ЕФОЕЯёЪЧПЩвдЛљгк Database
ВуУцЪЕЯжЁЃ
вЛИі SQL Server ЪЕР§жаЕФСНИі DatabaseЃЌвЛИіПЩвдзїЮЊ principalЃЌвЛИіПЩвдзїЮЊ
mirrorЃЌЗжБ№гыЦфЫћ SQL Server ЪЕР§зщНЈОЕЯёЙиЯЕЃЛСэЭтЃЌSQL Server вЛИі
Database жЛФмгавЛИі mirror НкЕуЃЌвЛИі mirror ЕФ database ВЛПЩвддйга
mirror НкЕуЃЌетЕугы MySQL МЖСЊИДжЦВЛЭЌЃЛ
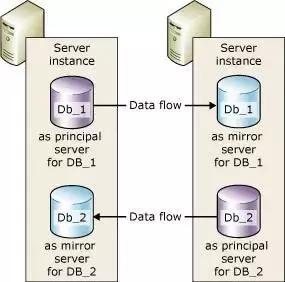
SQL Server ЕФЪТЮёШежОЪЧЮяРэМЧТММЖБ№ЕФЃЌМЧТМСЫЖдЪ§ОнПтФГИівГЕФФГааМЧТМЃЈslotЃЉЕФВйзїЃЌprincipal
ДДНЈОЕЯёКѓЃЌЛсЦєЖЏвЛИіЕЅЖРЕФЪТЮёШежОЗЂЫЭЯпГЬЃЌЮЌЛЄвЛИіащФтЕФЗЂЫЭЖгСаЃЌШЛКѓЖСШЁЪТЮёШежОЃЌНЋЦфНјаабЙЫѕЃЌИљОнЙйЗНЙЋВМЕФВтЪдЪ§ОнЃЌбЙЫѕБШВЛЕЭгк12.5%ЃЌШЛКѓЗЂЫЭИј
mirror НкЕуЃЌmirror НкЕуНгЪеЕНвдКѓЃЌЛсНЋЦфаДШыБОЕидкДХХЬЩЯЕФвЛИіжизіЖгСаЮФМўжаЃЌШЛКѓдйЭЈЙ§СэЭтЕФвЛИіЯпГЬвьВНЕФЗНЪНЃЌДгжизіЖгСажаЛёШЁЪТЮёШежОЃЌШЛКѓЗжЗЂИјгІгУЯпГЬЃЈprocess
unitЃЉНјааЛиЗХЁЃ
ВЛЭЌгк MySQL BinlogЃЌгЩгк SQL Server ЕФЪТЮёШежОдк principal ЩЯЪТЮёжДааЙ§ГЬжаОЭвбОдДдДВЛЖЯЕФаДШыЃЈMySQL
Binlog НідкЪТЮёЬсНЛНзЖЮЩњГЩЃЉЃЌдк principal ЪТЮёжДааЕФЭЌЪБЪТЮёШежООЭвбОДЋЕнИјСЫ
mirrorЃЌЫљвдЛљгкЪТЮёШежОЕФ SQL Server ЕФИДжЦадФмЛсИќРэЯыЁЃЭЌЪБЃЌдк mirror
ЛиЗХЕФЙ§ГЬжаЃЌПЩвдЛљгквГЃЈpageЃЉМЖБ№НјааВЂЗЂИќаТЃЈredo parallelЃЉЃЌдк SQL Server
ЕФБъзМАцжаЃЌНіЬсЙЉвЛИіЯпГЬНјааЪТЮёШежОЛиЗХЃЈroll forwardЃЉЃЌдкЦѓвЕАцжаЃЌШчЙћЕБЧАЗўЮёЦї
CPU Дѓгк5КЫЃЌдђУП4ИіКЫЃЌдіМгвЛИіВЂааЯпГЬЃЌШчЙћЕЭгк5ИіКЫЃЌдђШдШЛЪЙгУЕЅЯпГЬЛиЗХЁЃЭЌЪБЃЌЛљгквГЕФЪТЮёШежОЕФВЂЗЂжДааЃЌЛЙгавЛИіКУДІОЭЪЧЖдгкЭЌвЛИівГУцЕФИќаТПЩвдКЯВЂЫЂаТЃЌМѕЩйдрвГЫЂаТЪ§СПЁЃ
дЫааФЃЪН
ОЕЯёМЏШКЬсЙЉСЫШ§жждЫааФЃЪНЃК
ИпадФмФЃЪНЃКprincipal гы mirror жЎМфЪ§ОнвьВНДЋЪфЃЌprincipal ЩЯЕФЪТЮёЬсНЛЮоашЕШД§
mirror ЕФЯьгІЃЌprincipal хДЛњКѓЃЌДцдкЪ§ОнИќаТЖЊЪЇЕФПЩФмЃЌВЛжЇГжздЖЏЙЪеЯзЊвЦЃЌПЩвдЭЈЙ§ЧПжЦЗўЮёЕФЗНЪНЪЙЕУ
mirror ЬсЙЉЗўЮёЁЃЪЪКЯЖдЪ§ОнПЩППадвЊЧѓВЛИпЃЌадФмвЊЧѓНЯИпЕФвЕЮёГЁОАЃЌгы MySQL ЕФвьВНИДжЦФЃЪНЃЌOracle
DataGuard зюДѓадФмФЃЪНЯрНќЃЛ
ВЛДјЙЪеЯзЊвЦЕФИпАВШЋФЃЪНЃКprincipal ЩЯЫљгаЕФЪТЮёЬсНЛЃЌЖМБиаывЊШЗШЯИУЪТЮёЩцМАЕФЪТЮёШежООљвбОДЋЫЭЕНЕФ
mirror ЩЯЃЌВЂаДШы mirror ЕФжизіЖгСажаЃЌГжОУЛЏЃЈЪЧЗёГжОУЛЏЕНЭтДцЩшБИЛЙгы windows
ВйзїЯЕЭГаДШыЛКДцВпТдЯрЙиЃЉЃЌmirror ЗЕЛиШЗШЯКѓЃЌВХПЩЬсНЛЃЌПЩвдЪЕЯж principal хДЛњЯТЪ§ОнЁАСуЁБЖЊЪЇЃЌВЛжЇГжздЖЏЙЪеЯзЊвЦЃЌПЩвдЭЈЙ§ЪжЖЏзЊвЦЛђепЧПжЦЗўЮёЗНЪНЪЙЕУ
mirror ЬсЙЉЗўЮёЁЃгы MySQL 5.7 Loss-less replicationЁЂOracle
DataGuard зюДѓПЩгУФЃЪНЯрНќЃЛ
ДјЙЪеЯзЊвЦЕФИпАВШЋФЃЪНЃКгыВЛДјЙЪеЯзЊвЦЕФИпАВШЋФЃЪНЯрБШЃЌдіМгСЫ witness (МћжЄЗўЮёЦї)ЃЌПЩвдЪЕЯжздЖЏЕФЙЪеЯзЊвЦЃЌЭЈЙ§
witnessЃЌПЩвдШЗБЃжЛгавЛИіНкЕуГЩЮЊ principalЃЌЖдЭтЬсЙЉЗўЮёЃЌЪЕМЪЩЯ witness
зюживЊЕФвЛИізїгУОЭЪЧбЁжїЃЛ
ЙЪеЯзЊвЦ
ОЕЯёМЏШКЙЪеЯзЊвЦзюИДдгГЁОАОЭЪЧДјМћжЄЗўЮёЦїЕФжЇГжздЖЏЙЪеЯзЊвЦЕФИпАВШЋФЃЪНЃЌЫљвдЮвУЧжиЕуЬжТлИУФЃЪНЯТЕФЙЪеЯДІРэСїГЬЁЃ
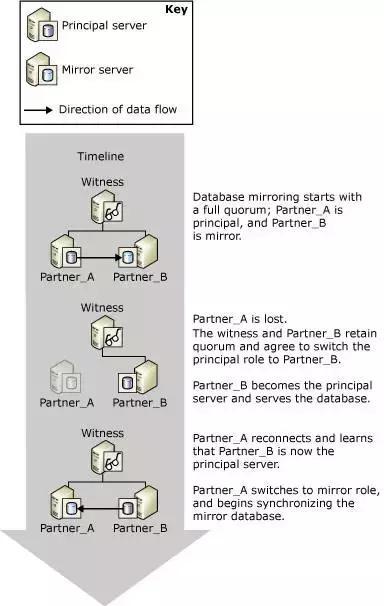
ГѕЪМзДЬЌЯТЃЌwitnessЁЂprincipal КЭ mirror Ш§ИіНкЕуСНСНжЎМфОљБЃГжГЄСЌНгЛсЛАЃЌЯждкЬжТлЦфжавЛЗНСЌНгжаЖЯЕФЧщПіЃК
Principal гы witness СЌНгжаЖЯЃК
ДЫЪБ witness гы mirror СЌНге§ГЃЃЌДЅЗЂздЖЏЙЪеЯЛжИДСїГЬЃЌprincipal
ЖЊЪЇ witness СЌНгЛсЛАЃЌШчЙћ principal ШддкдЫаазДЬЌЃЌдђНЋзДЬЌБъМЧЮЊ disconnectedЃЌБэЪОЪЇШЅгы
mirror СЌНгЃЌЧаЖЯЫљгаПЭЛЇЖЫСЌНгЃЌЭЃжЙЖСаДЗўЮёЃЌЕШД§ЙЪеЯЧаЛЛЁЃЮЊСЫЗРжЙЭјТчЖЖЖЏв§Ц№ВЛБивЊЕФЧаЛЛЃЌЛсЛАГЌЪБФЌШЯЪБМфЮЊ
10УыЃЛwitness КЭ mirror НЋ principal БъМЧЮЊВЛПЩгУЃЌЕШД§ mirror
ЩЯЕФжизіЖгСажаЕФЪТЮёШежОЛиЗХЃЈroll forwardЃЉЭъГЩКѓЃЌmirror ГЩЮЊаТЕФ principalЃЌПЊЪМЖдЭтЬсЙЉЖСаДЗўЮёЁЃ
зюКѓ mirror ЛсЭЈЙ§КѓЬЈЯпГЬЃЌНЋЮДЬсНЛЕФЪТЮёЛиЙіЃЈЛљгк binlog ЕФ MySQL ИДжЦЃЌгЩгк
binlog ЪЧдкЪТЮёЬсНЛНзЖЮЩњГЩЕФЃЌЫљвдВЛДцдкЪТЮёЛиЙіЕФНзЖЮЃЉЁЃ
ДгећИіЙЪеЯЧаЛЛЕФСїГЬРДПДЃЌЙЪеЯЧаЛЛЪБМфжївЊАќРЈШ§ИіВПЗжЃКМьВтЕН principal
хДЛњЕФЪБМфЁЂmirror ЩЯжизіЖгСажаЪТЮёШежОЕФЛиЗХЪБМфвдМАЛиЙіЮДЬсНЛЪТЮёЕФЪБМфЃЌЦфжаЧАУцСНЖЮЪБМфЗўЮёВЛПЩгУЃЌгШЦфЪЧжизіЖгСаЕФЛиЗХЪБМфЃЌжБНгОіЖЈСЫЗўЮёВЛПЩгУЪБМфЁЃ
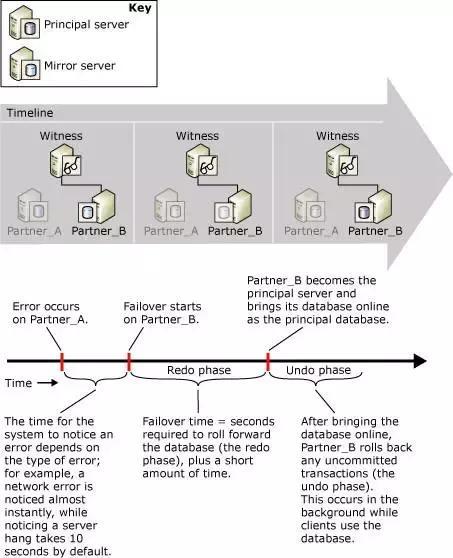
mirror гы witness СЌНгжаЖЯЃК
ДЫЪБЃЌprincipal гы witness СЌНге§ГЃЃЌprincipal зДЬЌБфЮЊ DisconectedЃЌБэЪОжежЙгы
mirror СЌНгЃЌmirror зДЬЌБфЮЊ suspendЃЌprincipal ВЛдйЯђmirror
ЗЂЫЭЪТЮёШежОЃЌЕШД§ mirror жиаТНЈСЂЕН witness СЌНгКѓЃЌprincipal ВХЛсЛжИДгы
mirror НјааЪ§ОнЭЌВНЁЃ
Principal гы mirror СЌНгжаЖЯЃК
principal гы mirror ЭЌЪББЃГж witness ЕФСЌНгЛсЛАЃЌЕЋЪЧ principal
гы mirror жЎМфЛсЛАжаЖЯЃЌwitness ЛсЭЈжЊ mirrorЃЌprincipal вРШЛБЃГжСЌНгзДЬЌЃЌВЛЛсДЅЗЂЙЪеЯЧаЛЛЃЛДЫЪБ
principal гЩгкБЃГжга witness ЕФСЌНгЛсЛАЃЌЗўЮёе§ГЃЁЃ
ЯТУцРДПМТЧШ§ЗНЛсЛАСНИіЛсЛАЭЌЪБжаЖЯЧщПіЃК
principal гыЫљгаНкЕуЛсЛАжаЖЯЃК
жЛвЊ mirror гы witness ЛсЛАе§ГЃЃЌМДПЩЭъГЩе§ГЃЕФЙЪеЯзЊвЦЃЛШчЙћ
mirror гы witness СЌНгвВжаЖЯЃЌдђЮоЗЈЭъГЩЃЌМДБуЪЧКѓРД mirror гы witness
ЕФЛсЛАгХЯШЛжИДЃЌдђвВЮоЗЈЙЪеЯЧаЛЛЃЌвђЮЊвбШЛВЛШЗЖЈ mirror ЪЧЗёгЕгаШЋВП principal ЕФЪ§ОнЃЌДЫЪБМДБу
principal ДІгкдЫаазДЬЌЃЌвВЮоЗЈЬсЙЉЗўЮёЃЌЕШД§ principal гыШЮвтНкЕуЛсЛАЛжИДе§ГЃЃЌМДПЩЛжИДЖСаДЗўЮёЃЛ
mirror гы ЫљгаНкЕуЛсЛАжаЖЯЃК
ВЛЛсДЅЗЂЙЪеЯЧаЛЛЃЌprincipal ЧаШыЙЋПЊдЫааФЃЪНЃЈвьВНЃЉЃЌМДВЛЛсдйЯђ mirror ЗЂЫЭЪТЮёШежОЃЌвВВЛдйашвЊЕШД§
mirror ЕФЯьгІЃЌжБЕН mirror жиаТЛжИДЛсЛАЁЃ
witness гыЫљгаНкЕуЛсЛАжаЖЯЃК
ВЛЛсДЅЗЂЙЪеЯЧаЛЛЃЌprincipal МЬајЬсЙЉЖСаДЗўЮёЃЌгы mirror Ъ§ОнМЬајЭЌВНЃЌОЕЯёМЏШКЩЅЪЇздЖЏЙЪеЯзЊвЦФмСІЃЌЭЫЛЏЮЊВЛДјЙЪеЯзЊвЦЕФИпАВШЋФЃЪНЃЛ
ШчЙћШ§ЗНЛсЛАЭЌЪБСЌНгжаЖЯЃЌдђ principal ЮоЗЈЬсЙЉЗўЮёЃЌжБЕН principal гыШЮвтНкЕуЭЈаХЛжИДе§ГЃЁЃ
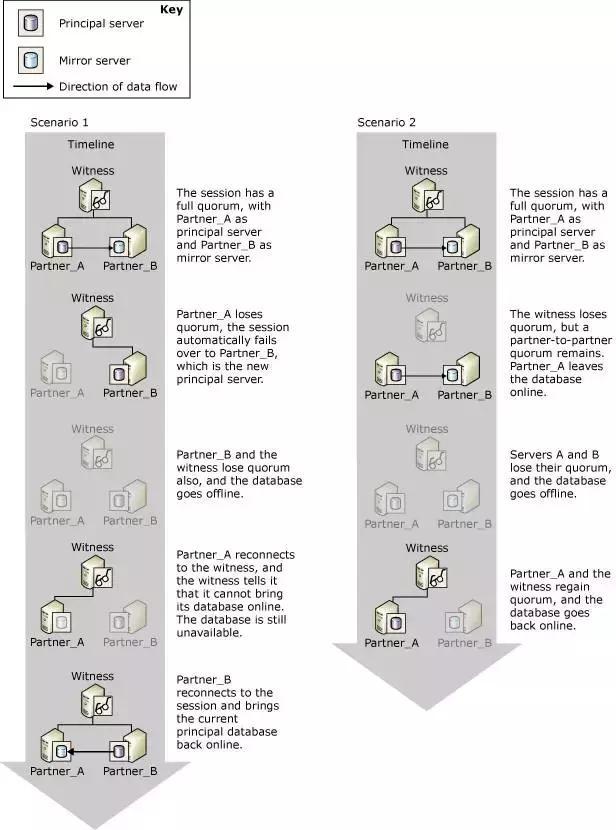
ГЁОА1жаЃЌГѕЪМзДЬЌЪЕР§ AЁЂB КЭ witness БЃГжЛсЛАСЌНгЃЌЦфКѓЃЌA ЪЕР§хДЛњЃЌЪЇШЅгыЦфЫћГЩдБЕФЛсЛАЃЌЪЕР§
B гы witness БЃГжЛсЛАЃЌДЅЗЂЙЪеЯЧаЛЛЃЌЪЕР§ B Щ§МЖЮЊ principalЁЃЦфКѓЪЕР§ B
вВхДЛњЃЌЗўЮёЭЃжЙЁЃШЛКѓЪЕР§ A ЛжИДЃЌЕЋЪЧгЩгкДЫЪБЪЕР§ A вбОЪЧ mirrorЃЌВЛФмШЗЖЈЪЕР§ A
гЕгаЪЕР§ B ЕФЫљгаИќаТЪ§ОнЃЌЫљвдЮоЗЈЙЪеЯЧаЛЛЃЌзюКѓЪЕР§ B ЛжИДЃЌЗўЮёЛжИДе§ГЃЁЃ
ГЁОА2 жаЃЌЪЕР§ A КЭ B ЭЌЪБЪЇШЅСЫгы witness ЕФЛсЛАЃЌЕЋЪЧЗўЮёвбШЛе§ГЃЃЌA гы B
жЎМфЪ§ОнМЬајЭЌВНЃЌЦфКѓ A гы B ЭЌЪБхДЛњЃЌЗўЮёЭЃжЙЁЃзюКѓ A ЛжИДЗўЮёЃЌгы witness ЛжИДЛсЛАЃЌA
МЬајЬсЙЉЗўЮёЁЃ
ЭИУїЧаЛЛ
вЛИіЭъећЕФИпПЩгУЛњжЦГ§СЫКѓЖЫНкЕуЕФЧаЛЛЃЌЛЙАќРЈЗЂЩњЙЪеЯзЊвЦКѓЃЌПЭЛЇЖЫШчКЮФмЙЛПьЫйЕиСЌНгЕНШпгрНкЕуЃЌМЬајвЕЮёЖСаДЁЃГЃгУЕФЪЕЯжЃЌАќРЈ
Driver ВуНтОіЗНАИЃЌР§Шч mongoDB replication setЃЌвВгаЭЈЙ§ЖўВуФкЕФЙуВЅЗНЪНЪЕЯж
vipЃЌР§Шч keepalivedЃЌЕБШЛЛЙАќРЈ proxyЃЌвдМАШ§Ву DNS ЕФЪЕЯжЁЃ
SQL Server ЕФЪЕЯжВЩгУСЫ Driver ВуДІРэЕФЗНЪНЃЌПЊЗЂепвЊЪЕЯжздЖЏЕФЙЪеЯзЊвЦЃЌдкСЌНгЪ§ОнПтЪБЃЌГ§СЫБиаывЊжИЖЈГѕЪМНкЕуЕФ
IP КЭЖЫПкЃЌЛЙвЊжИЖЈЙЪеЯзЊвЦЕФНкЕуЕФ IP КЭЖЫПкЁЃПЭЛЇЖЫЪзЯШГЂЪдЪЙгУГѕЪМНкЕуДДНЈСЌНгЃЌШчЙћГѕЪМНкЕужИЯђЕФЪЕР§ЕБЧАЮЊ
principalЃЌдђСЌНгЛсНЈСЂГЩЙІЃЌПЩвде§ГЃЕФЖСаДЁЃЕБЗЂЩњЙЪеЯЧаЛЛЪБЃЌprincipal ЛсЧаЖЯЫљгавбгаПЭЛЇЖЫСЌНгЃЌШЛКѓПЭЛЇЖЫНЈСЂЕНГѕЪМНкЕуСЌНгвВЛсЪЇАмЃЌЭЈЙ§вЛЖЈЕФжиЪдВпТдЪЇАмКѓЃЌЛсГЂЪдСЌНгжЎЧАжИЖЈЕФЙЪеЯзЊвЦНкЕуЃЌДгЖјЪЕЯжЗўЮёШыПкЕФЧаЛЛЁЃ
SQL Server ГЃгУЕФЗУЮЪНгПкЃКOLE DBЁЂODBCЁЂADO ОљжЇГжжИЖЈЙЪеЯзЊвЦНкЕуЃЌИёЪНШчЯТЃК
Server=250.65.43.21,4734; Failover_Partner=250.65.43.22,4734;
МЏШКМрПи
ОЕЯёМЏШКЕФМрПиПЩвдЭЈЙ§ SQL Server Management stdio ЦєЖЏОЕЯёМрЪгЦїЃЌЛђепЯЕЭГФкжУЕФДцДЂЙ§ГЬРДЪЕЯжЃЌМрПиЕФжївЊжИБъАќРЈЃК
ЮДЗЂЫЭШежОЃКprincipal ЩЯЮДЗЂЫЭЕФШежОГЌЙ§жИЖЈЕФуажЕЃЌЛсдк principal ЩЯЩњГЩвЛИіОЏИцЃЌдкИпадФмФЃЪНЯТЃЌЧПжЦЗўЮёЪБПЩвдзїЮЊЦРЙР
principal ЩЯЪТЮёЖЊЪЇЪ§СПЕФвРОнЃЌЭЌбљвВЪЪгУгкдкИпАВШЋФЃЪНЧаЛЛГЩвьВНФЃЪНзДЬЌЯТЃЈmirror
ЪЇШЅСЌНгЃЉ
ЮДЛЙдШежОЃКжизіЖгСажаЕФЮДБЛгІгУЕФЪТЮёШежОЪ§СПЃЈKBЃЉЃЌГЌЙ§уажЕЃЌЛсдк mirror ЩЯЩњГЩвЛИіОЏИцЃЌИУжЕПЩвдзїЮЊЦРЙРЙЪеЯзЊвЦЪБМфЕФжївЊвђЫиЁЃ
зюдчЮДБЛЗЂЫЭЕФЪТЮёЃКprincipal ЗЂЫЭЖгСажаЃЌзюдчЮДБЛЗЂЫЭЕФЪТЮёОрРыЯждкЕФЪБМфЃЌЕЅЮЛЪБЗжжгЃЌГЌЙ§уажЕЃЌЛсдк
principal ЩЯЩњГЩОЏИцЃЌгыЮДЗЂЫЭШежОСПвЛЦ№ЃЌДгЪБМфЮЌЖШЃЌКтСПИпадФмФЃЪНЯТКЭИпАВШЋвьВНФЃЪНЯТЃЌЪ§ОнЖЊЪЇЪ§СПЃЛ
ОЕЯёЬсНЛПЊЯњЃКИпАВШЋФЃЪНЯТЃЌprincipal ЩЯЪТЮёДгЬсНЛЕНЕШЕН mirror ЯьгІЕФЪБМфПЊЯњЕФЦНОљжЕЃЌШчЙћГЌЙ§уажЕЃЌдђдк
principal ЩЯЩњГЩвЛИіОЏИцЃЌдкЭЌВНФЃЪНЯТЃЌИУжЕПЩвдКтСПЭЌВНПЊЯњЁЃ
| 








