| БрМЭЦМі: |
БОЮФНВСЫЪ§ОнКЯВЂЃЌжиЕўЪ§ОнКЯВЂЃЌЪ§ОнжиЫмКЭжсЯђа§зЊЃЌЪ§ОнзЊЛЛЃЌЯЃЭћЖдДѓМвгаАяжњЁЃ
БОЮФРДздгкcnblogsЃЌгЩЛ№СњЙћШэМўDeloresБрМЃЌЭЦМіЁЃ |
|
ЧАУцЮвУЧгУpandasзіСЫвЛаЉЛљБОЕФВйзїЃЌНгЯТРДНјвЛВНСЫНтЪ§ОнЕФВйзїЃЌ
Ъ§ОнЧхЯДвЛжБЪЧЪ§ОнЗжЮіжаМЋЮЊживЊЕФвЛИіЛЗНкЁЃ
Ъ§ОнКЯВЂ
дкpandasжаПЩвдЭЈЙ§mergeЖдЪ§ОнНјааКЯВЂВйзїЁЃ
import numpy
as np
import pandas as pd
data1 = pd.DataFrame
({'level':['a','b','c','d'],
'numeber':[1,3,5,7]})
data2=pd.DataFrame
({'level':['a','b','c','e'],
'numeber':[2,3,6,10]})
print(data1) |
НсЙћЮЊЃК

НсЙћЮЊЃК
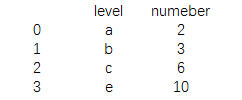
| print(pd.merge(data1,data2)) |
НсЙћЮЊЃК
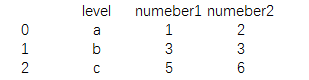
ПЩвдПДЕНdata1КЭdata2жагУгкЯрЭЌБъЧЉЕФзжЖЮЯдЪОЃЌЖјЦфЫћзжЖЮдђБЛЩсЦњЃЌетЯрЕБгкSQLжазіinner joinСЌНгВйзїЁЃ
ДЫЭтЛЙгаouter,ringt,leftЕШСЌНгЗНЪНЃЌгУЙиМќДЪhowЕФНјааБэЪОЁЃ
data3 = pd.DataFrame
({'level1':['a','b','c','d'],
'numeber1':[1,3,5,7]})
data4=pd.DataFrame
({'level2':['a','b','c','e'],
'numeber2':[2,3,6,10]})
print(pd.merge(data3,data4,left_on
='level1',right_on='level2')) |
НсЙћЮЊЃК

СНИіЪ§ОнПђжаШчЙћСаУћВЛЭЌЕФЧщПіЯТЃЌЮвУЧПЩвдЭЈЙ§жИЖЈletf_on КЭright_onСНИіВЮЪ§АбЪ§ОнСЌНгдквЛЦ№
print(pd.merge
(data3,data4,left_on='level1',
right_on='level2',how='left')) |
НсЙћЮЊЃК

ЦфЫћЯъЯИВЮЪ§ЫЕУї
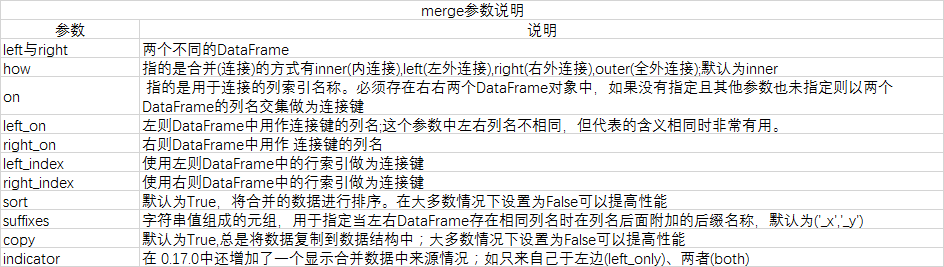
жиЕўЪ§ОнКЯВЂ
гаЪБКђЮвУЧЛсгіЕНжиЕўЪ§ОнашвЊНјааКЯВЂДІРэЃЌДЫЪБПЩвдгУcomebine_firstКЏЪ§ЁЃ
data3 = pd.DataFrame
({'level':['a','b','c','d'],
'numeber1':[1,3,5,np.nan]})
data4=pd.DataFrame
({'level':['a','b','c','e'],
'numeber2':[2,np.nan,6,10]})
print(data3.combine_first(data4)) |
НсЙћЮЊЃК
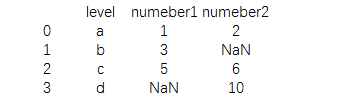
ПЩвдПДЕНЯрЭЌБъЧЉЯТЕФФкШнгХЯШЯдЪОdata3ЕФФкШнЃЌШчЙћвЛИіЪ§ОнПђжаЕФФГвЛИіЪ§ОнЪЧШБЪЇЕФЃЌДЫЪБСэЭтвЛИіЪ§ОнПђжаЕФдЊЫиОЭЛсВЙЩЯ
етРяЕФгУЗЈРрЫЦгкnp.where(isnull(a),b,a)
Ъ§ОнжиЫмКЭжсЯђа§зЊ
етИіФкШнЮвУЧдкЩЯвЛЦЊpandasЮФеТгаЬсЕНЙ§ЁЃЪ§ОнжиЫмжївЊЪЙгУreshapeКЏЪ§ЃЌа§зЊжївЊЪЙгУunstackКЭstackСНИіКЏЪ§ЁЃ
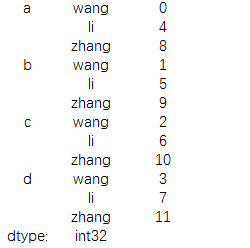
data=pd.DataFrame
(np.arange(12).reshape(3,4),
columns=['a','b','c','d'],
index=['wang','li','zhang'])
print(data) |
НсЙћЮЊЃК

Ъ§ОнзЊЛЛ
ЩОГ§жиИДааЪ§Он
data=pd.DataFrame({'a':[1,3,3,4],
'b':[1,3,3,5]})
print(data) |
НсЙћЮЊЃК

НсЙћЮЊЃК
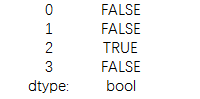
ПЩвдПДГіЕкШ§ааЪЧжиИДЕкЖўааЕФЪ§ОнЫљвдЃЌЯдЪОНсЙћЮЊTrue
СэЭтгУdrop_duplicatesЗНЗЈПЩвдШЅГ§жиИДаа
| print(data.drop_duplicates()) |
НсЙћЮЊЃК
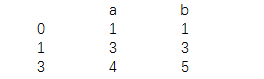
ЬцЛЛжЕ
Г§СЫЪЙгУЮвУЧЩЯвЛЦЊЮФеТжаЬсЕНЕФfillnaЕФЗНЗЈЭтЃЌЛЙПЩвдгУreplaceЗНЗЈЃЌЖјЧвИќМђЕЅПьНн
data=pd.DataFrame({'a':[1,3,3,4],
'b':[1,3,3,5]})
print(data.replace(1,2)) |
НсЙћЮЊЃК

ЖрИіЪ§ОнвЛЦ№ЛЛ
| print(data.replace([1,4],np.nan)) |

Ъ§ОнЗжЖЮ
data=[11,15,18,20,25,26,27,24]
bins=[15,20,25]
print(data)
print(pd.cut(data,bins)) |
НсЙћЮЊЃК
[11, 15, 18, 20, 25, 26, 27, 24]
[NaN, NaN, (15, 20], (15, 20], (20, 25], NaN, NaN, (20, 25]]
Categories (2, object): [(15, 20] < (20, 25]]
ПЩвдПДГіЗжЖЮКѓЕФНсЙћЃЌВЛдкЗжЖЮФкЕФЪ§ОнЯдЪОЮЊnaжЕЃЌЦфЫћдђЯдЪОЪ§ОнЫљдкЕФЗжЖЮЁЃ
| print(pd.cut(data,bins).labels) |
НсЙћЮЊЃК
[-1 -1 0 0 1 -1 -1 1]
ЯдЪОЫљдкЗжЖЮХХађБъЧЉ
| print(pd.cut(data,bins).levels) |
НсЙћЮЊЃК
Index(['(15, 20]', '(20, 25]'], dtype='object')
ЯдЪОЫљвдЗжЖЮБъЧЉ
| print(value_counts(pd.cut(data,bins))) |
НсЙћЮЊЃК

ЯдЪОУПИіЗжЖЮжЕЕУИіЪ§
ДЫЭтЛЙгавЛИіqcutЕФКЏЪ§ПЩвдЖдЪ§ОнНјаа4ЗжЮЛЧаИюЃЌгУЗЈКЭcutРрЫЦЁЃ
ХХСаКЭВЩбљ
ЮвУЧжЊЕРХХађЕФЗНЗЈгаКУМИИіЃЌБШШчsortЃЌorderЃЌrankЕШКЏЪ§ЖМФмЖдЪ§ОнНјааХХађ
ЯждквЊЫЕЕФетИіЪЧЖдЪ§ОнНјааЫцЛњХХађЃЈpermutationЃЉ
data=np.random.permutation(5)
print(data) |
НсЙћЮЊЃК
[1 0 4 2 3]
етРяЕФpeemutationКЏЪ§Жд0-4ЕФЪ§ОнНјааЫцЛњХХађЕФНсЙћЁЃ
вВПЩвдЖдЪ§ОнНјааВЩбљ
df=pd.DataFrame(np.arange(12).reshape(4,3))
samp=np.random.permutation(3)
print(df) |
НсЙћЮЊЃК
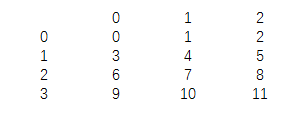
print(samp)
НсЙћЮЊЃК
[1 0 2]
print(df.take(samp))
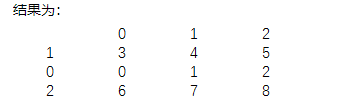
етРяЪЙгУtakeЕФНсЙћЪЧЃЌАДееsampЕФЫГађДгdfжаЬсШЁбљБОЁЃ
|









