导读:对于Android开发者来说,成系列的技术文章对他们的技术成长帮助最大。如下是我们向您强烈推荐的主题为Android开发的第一个系列文章。
《Android核心分析》整理如下:
24.Android GDI之显示缓冲管理
Android GDI之屏幕设备管理-动态链接库
万丈高楼从地起,从最根源的硬件帧缓冲区开始。我们知道显示FrameBuffer在系统中就是一段内存,GDI的工作就是把需要输出的内容放入到该段内存的某个位置。我们从基本的点(像素点)和基本的缓冲区操作开始。
1 基本知识
1.1点的格式
对于不同的LCD来讲,FrameBuffer的二进制格式不一样,并且可以分为两部分:
1)点的格式:通常将Depth,即表示多少位表示一个点。
1位表示一个点
2位表示一个点
16位表示一个点
32位表示一个点(Alpha通道)
2) 点内格式:RGB分量分布表示。
例如对于我们常见的16位表示一个点

1.2.格式之间的转换
所以屏幕输出实际上是一个值映射的关系。我们可以有如下的点格式转换,
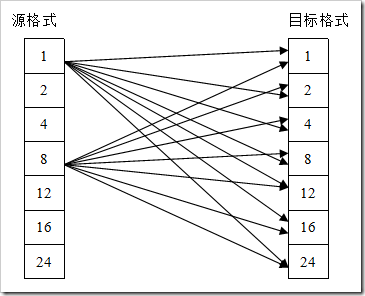
源格式可能来自单色位图和彩色位图,对于具体的目标机来讲,我们的目标格式可能就是一种,例如16位(5/6/5)格式。其实就只存在一种格式的转换,即从目标格式都是16位格式。
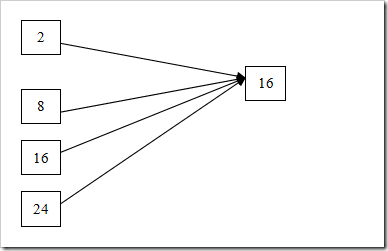
但是,在设计GDI时,基本要求有一个可移植性好,所以我们还是必须考虑对于不同点格式LCD之间的转换操作。所以在GDI的驱动程序中涉及到如下几类主要操作:
区域操作(Blit):我们在显示缓冲区上做的最多的操作就是区块搬运。由此,很多的应用处理器使用了硬件图形加速器来完成区域搬运:blit.从我们的主要操作的对象来看,可以分为两个方向:
1)内存区域到屏幕区域
2)屏幕区域到屏幕区域
3)屏幕区域到内存区域
4)内存区域到内存区域
在这里我们需要特别提出的是,由于在Linux不同进程之间的内存不能自由的访问,使得我们的每个Android应用对于内存区域和屏幕缓冲区的使用变得很复杂。在Android的设计中,在屏幕缓冲区和显示内存缓冲区的管理分类很多的层次,最上层的对象是可以在进程间自由传递,但是对于缓冲区内容则使用共享内存的机制。
基于以上的基础知识,我们可以知道:
(1)代码中Config及其Format的意义所在了。也就理解了兼容性的意义:采用同硬件相同的点的描述对象
(2)所有屏幕上图形的移动都是显示缓冲区搬运的结果。
1.2图形加速器
应用处理器都可能带有图形加速器,对于不同的应用处理器对其图形加速器可能有不同的处理方式,对于2D加速来讲,都可归结为Blit。多为数据的搬运,放大缩小,旋转等。
2 Android的缓冲区抽象定义
不同的硬件有不同的硬件图形加速设备和缓冲内存实现方法。Android
Gralloc动态库抽象的任务就是消除不同的设备之间的差别,在上层看来都是同样的方法和对象。在Moudle层隐藏缓冲区操作细节。Android使用了动态链接库gralloc.xxx.so,来完成底层细节的封装。
2.1 本地定义@hardware/libhandware/modules/gralloc
每个动态链接库都是用相同名称的调用接口:
1)硬件图形加速器的抽象:BlitEngine,CopyBit的加速操作。
2)硬件FrameBuffer内存管理
3)共享缓存管理
从数据关系上我们来考察..动态链接库的抽象行为:在层次:Hardware.c@hardware/libhardware
中对动态链接库中的内容作了全新的包装。/system/lib/hw/gralloc.xxx.so动态库文件。从文件Gralloc.h(handware/libhardware/include/hardware)是抽象的结果:hw_get_module从gralloc.xxx.so提取了HAL_MODULE_INFO_SYM(SYM变量)

从展露在外部的数据结构,我们在@Gralloc.cpp看到到了这样的布局:
static struct hw_module_methods_t gralloc_module_methods
= {
open: gralloc_device_open
};
struct private_module_t HAL_MODULE_INFO_SYM
= {
base: {
common: {
tag: HARDWARE_MODULE_TAG,
…
id: GRALLOC_HARDWARE_MODULE_ID,
name: "Graphics Memory Allocator
Module",
author: "The Android Open Source
Project",
methods: &gralloc_module_methods
},
registerBuffer: gralloc_register_buffer,
unregisterBuffer: gralloc_unregister_buffer,
lock: gralloc_lock,
unlock: gralloc_unlock,
},
framebuffer: 0,
flags: 0,
numBuffers: 0,
bufferMask: 0,
…
};
我们建立了什么对象来支撑缓冲区的操作?
buffer_handle_t:外部接口。
methods.open,registerBuffer,unregisterBuffer,lock,unlock
下面是外部接口和内部对象的结构关系,该类型的结构充分利用C Struct的数据排列特性:基本结构体放置在最前面,本地私有放置在后面,满足了抽象的需要。
typedef const native_handle* buffer_handle_t;
private_module_t HAL_MODULE_INFO_SYM
向往暴露的动态链接库接口,通过该接口,我们直接可以使用该对象。
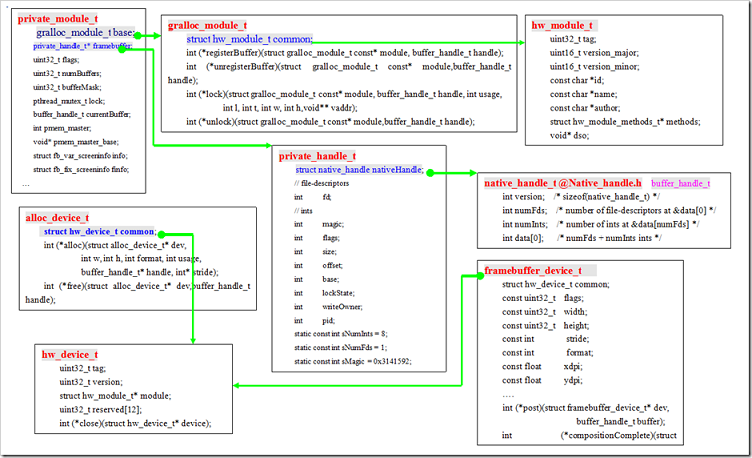
看不清楚上面图,可以偏一下头横着看:
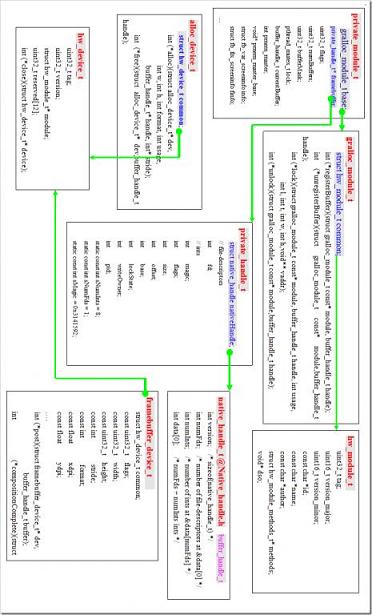
几个接口函数的解释:
(1)fb_post
对于帧缓冲区实际地址并不需要向上层报告,所有的操作都是通过fb_post了完成。
fp_post的任务就是将一个Buffer的内容传递到硬件缓冲区。其实现方式有两种:
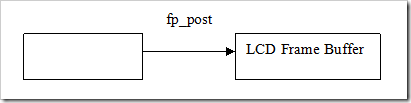
(方式1)无需拷贝动作,是把Framebuffer的后buffer切为前buffer,然后通过IOCTRL机制告诉FB驱动切换DMA源地地址。这个实现方式的前提是Linux内核必须分配至少两个缓冲区大小的物理内存和实现切换的ioctrol,这个实现快速切换。
(方式2)利用Copy的方式。不修改内核,则在适配层利用从拷贝的方式进行,但是这个是费时了。
(2)gralloc的主要功能是要完成:
1)打开屏幕设备 "/dev/fb0",,并映射硬件显示缓冲区。
2)提供分配共享显示缓存的接口
3)提供BiltEngine接口(完成硬件加速器的包装)
(3)gralloc_alloc输出buffer_handle_t句柄。
这个句柄是共享的基本依据,其基本原理在后面的章节有详细描述。
3 总结
总结一下,/system/lib/hw/gralloc.xxx.so是跟硬件体系相关的一个动态链接库,也可以叫做Android的硬件抽象层。他实现了Android的硬件抽象接口标准,提供显示内存的分配机制和CopyBit等的加速实现。而如何具体实现这些功能,则跟硬件平台的配备有关系,所以我们看到了对于与不同的硬件架构,有不同的配置关系。
25.Android GDI之共享缓冲区机制
1 native_handle_t对private_handle_t
的包裹
private_handle_t是gralloc.so使用的本地缓冲区私有的数据结构,而Native_handle_t是上层抽象的可以在进程间传递的数据结构。在客户端是如何还原所传递的数据结构呢?首先看看native_handle_t对private_handle_t的抽象包装。

numFds= sNumFds=1;
numInts= sNumInts=8;
这个是Parcel中描述句柄的抽象模式。实际上是指的Native_handle所指向句柄对象的具体内容:
numFds=1表示有一个文件句柄:fd/
numInts= 8表示后面跟了8个INT型的数据:magic,flags,size,offset,base,lockState,writeOwner,pid;
由于在上层系统不要关心buffer_handle_t中data的具体内容。在进程间传递buffer_handle_t(native_handle_t)句柄是其实是将这个句柄内容传递到Client端。在客户端通过Binder读取readNativeHandle
@Parcel.cpp新生成一个native_handle。
native_handle* Parcel::readNativeHandle()
const
{
…
native_handle* h = native_handle_create(numFds,
numInts);
for (int i=0 ; err==NO_ERROR &&
i
h->data[i] = dup(readFileDescriptor());
if (h->data[i] < 0) err = BAD_VALUE;
}
err = read(h->data + numFds, sizeof(int)*numInts);
….
return h;
}
这里需要提到的是为在构造客户端的native_handle时,对于对方传递过来的文件句柄的处理。由于不是在同一个进程中,所以需要dup(…)一下为客户端使用。这样就将Native_handle句柄中的,客户端感兴趣的从服务端复制过来。这样就将Private_native_t的数据:magic,flags,size,offset,base,lockState,writeOwner,pid;复制到了客户端。
客户端利用这个新的Native_buffer被Mapper传回到gralloc.xxx.so中,获取到native_handle关联的共享缓冲区映射地址,从而获取到了该缓冲区的控制权,达到了客服端和Server间的内存共享。从SurfaceFlinger来看就是作图区域的共享。
2 Graphic Mapper是干什么的?
服务端(SurfaceFlinger)分配了一段内存作为Surface的作图缓冲,客户端怎样在这个作图缓冲区上工作呢?这个就是Mapper(GraphicBufferMapper)y要干的事情。两个进程间如何共享内存,如何获取到共享内存?Mapper就是干这个得。需要利用到两个信息:共享缓冲区设备句柄,分配时的偏移量。Mapper利用这样的原理:
客户端只有lock,unlock,实质上就是mmap和ummap的操作。对于同样一个共享缓冲区,偏移量才是总要的,起始地址不重要。实际上他们操作了同一物理地址的内存块。我们在上面讨论了native_handle_t对private_handle_t
的包裹过程,从中知道服务端给客户端传递了什么东西。
进程1在共享内存设备上预分配了8M的内存。以后所有的分配都是在这个8M的空间进行。对以该文件设备来讲,8M物理内存提交后,就实实在在的占用了8M内存。每个每个进程都可以同个该内存设备共享该8M的内存,他们使用的工具就会mmap。由于在mmap都是用0开始获取映射地址,所以所有的客户端进程都是有了同一个物理其实地址,所以此时偏移量和size就可以标识一段内存。而这个偏移量和size是个数值,从服务进程传递到客户端直接就可以使用。

3 GraphicBuffer(缓冲区代理对象)
typedef struct android_native_buffer_t
{
struct android_native_base_t common;
int width;
int height;
int stride;
int format;
int usage;
…
buffer_handle_t handle;
…
} android_native_buffer_t;
关系图表:
GraphicBuffer :EGLNativeBase :android_native_buffer_t
GraphicBuffer(parcel &)建立本地的GraphicBuffer的数据native_buffer_t。在通过接收对方的传递的native_buffer_t
构建GraphicBuffer。我们来看看在客户端Surface::lock获取操作缓冲区的函数调用:
Surface::lock(SurfaceInfo* other, Region*
dirtyIn, bool blocking)
{int Surface::dequeueBuffer(android_native_buffer_t**
buffer)(Surface)
{status_t Surface::getBufferLocked(int
index, int usage)
{
sp buffer = s->requestBuffer(index,
usage);
{
virtual sp requestBuffer(int bufferIdx,
int usage)
{ remote()->transact(REQUEST_BUFFER,
data, &reply);
sp buffer = new GraphicBuffer(reply);
Surface::Lock建立一个在Client端建立了一个新的GraphicBuffer
对象,该对象通过(1)描述的原理将SurfaceFlinger的buffer_handle_t相关数据构成新的客户端buffer_handle_t数据。在客户端的Surface对象就可以使用GraphicMapper对客户端buffer_handle_t进行mmap从而获取到共享缓冲区的开始地址了。
4 总结
Android在该节使用了共享内存的方式来管理与显示相关的缓冲区,他设计成了两层,上层是缓冲区管理的代理机构GraphicBuffer,及其相关的native_buffer_t,下层是具体的缓冲区的分配管理及其缓冲区本身。上层的对象是可以在经常间通过Binder传递的,而在进程间并不是传递缓冲区本身,而是使用mmap来获取指向共同物理内存的映射地址。
26.Android GDI之SurfaceFlinger
Android GDI之SurfaceFlinger
SurfaceFinger按英文翻译过来就是Surface投递者。SufaceFlinger的构成并不是太复杂,复杂的是他的客户端建构。SufaceFlinger主要功能是:
1) 将Layers (Surfaces) 内容的刷新到屏幕上
2) 维持Layer的Zorder序列,并对Layer最终输出做出裁剪计算。
3) 响应Client要求,创建Layer与客户端的Surface建立连接
4) 接收Client要求,修改Layer属性(输出大小,Alpha等设定)
但是作为投递者的实际意义,我们首先需要知道的是如何投递,投掷物,投递路线,投递目的地。
1 SurfaceFlinger的基本组成框架
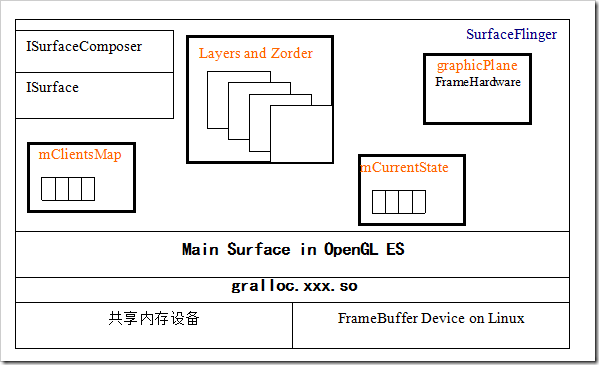
SurfaceFlinger管理对象为:
mClientsMap:管理客户端与服务端的连接。
ISurface,IsurfaceComposer:AIDL调用接口实例
mLayerMap:服务端的Surface的管理对象。
mCurrentState.layersSortedByZ :以Surface的Z-order序列排列的Layer数组。
graphicPlane 缓冲区输出管理
OpenGL ES:图形计算,图像合成等图形库。
gralloc.xxx.so这是个跟平台相关的图形缓冲区管理器。
pmem Device:提供共享内存,在这里只是在gralloc.xxx.so可见,在上层被gralloc.xxx.so抽象了。
2 SurfaceFinger Client和服务端对象关系图

Client端与SurfaceFlinger连接图:
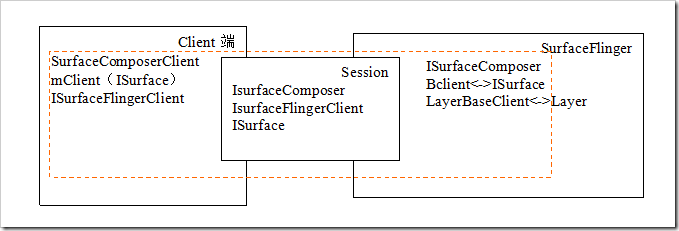
Client对象:一般的在客户端都是通过SurfaceComposerClient来跟SurfaceFlinger打交道。
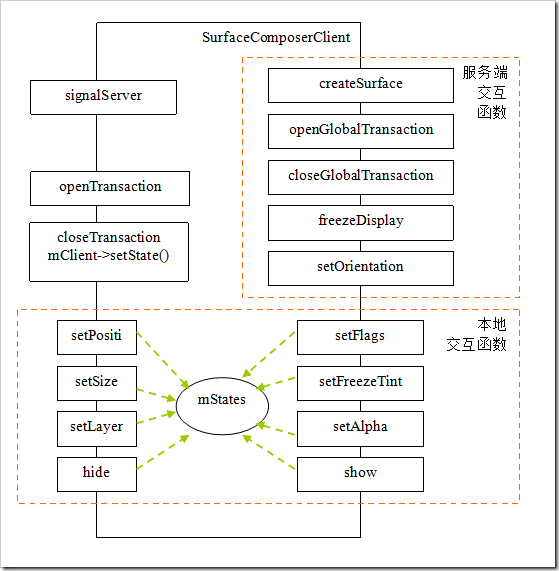

3 主要对象说明
3.1 DisplayHardware &FrameBuffer
首先SurfaceFlinger需要操作到屏幕,需要建立一个屏幕硬件缓冲区管理框架。Android在设计支持时,考虑多个屏幕的情况,引入了graphicPlane的概念。在SurfaceFlinger上有一个graphicPlane数组,每一个graphicPlane对象都对应一个DisplayHardware.在当前的Android(2.1)版本的设计中,系统支持一个graphicPlane,所以也就支持一个DisplayHardware。
SurfaceFlinger,Hardware硬件缓冲区的数据结构关系图。
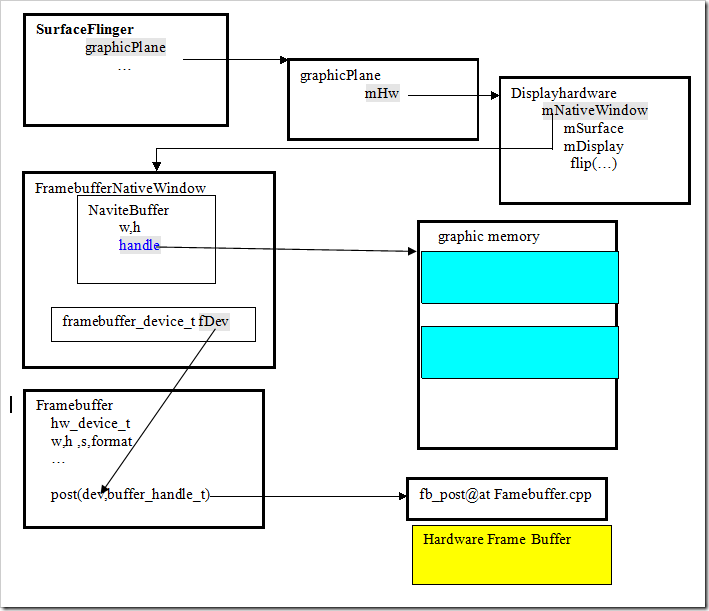
3.2 Layer
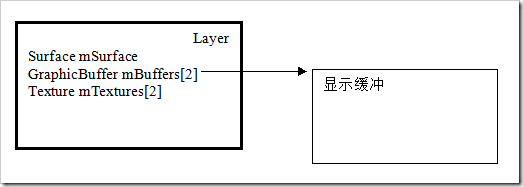
method:setBuffer 在SurfaceFlinger端建立显示缓冲区。这里的缓冲区是指的HW性质的,PMEM设备文件映射的内存。
1) layer的绘制
void Layer::onDraw(const Region&
clip) const
{
int index = mFrontBufferIndex;
GLuint textureName = mTextures[index].name;
…
drawWithOpenGL(clip, mTextures[index]);
}
3.2 mCurrentState.layersSortedByZ
以Surface的Z-order序列排列的LayerBase数组,该数组是层显示遮挡的依据。在每个层计算自己的可见区域时,从Z-order
顶层开始计算,是考虑到遮挡区域的裁减,自己之前层的可见区域就是自己的不可见区域。而绘制Layer时,则从Z-order底层开始绘制,这个考虑到透明层的叠加。
4 SurfaceFlinger的运行框架
我们从前面的章节<Android Service>的基本原理可以知道,SurfaceFlinger的运行框架存在于:threadLoop,他是SurfaceFlinger的主循环体。SurfaceFlinger在进入主体循环之前会首先运行:SurfaceFlinger::readyToRun()。
4.1 SurfaceFlinger::readyToRun()
(1)建立GraphicPanle
(2)建立FrameBufferHardware(确定输出目标)
初始化:OpenGL ES
建立兼容的mainSurface.利用eglCreateWindowSurface。
建立OpenGL ES进程上下文。
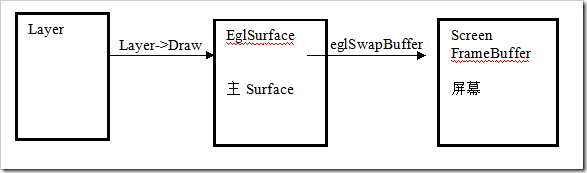
建立主Surface(OpenGL ES)。 DisplayHardware的Init()@DisplayHardware.cpp函数对OpenGL做了初始化,并创建立主Surface。为什么叫主Surface,因为所有的Layer在绘制时,都需要先绘制在这个主Surface上,最后系统才将主Surface的内容”投掷”到真正的屏幕上。
(3) 主Surface的绑定
1)在DisplayHandware初始完毕后,hw.makeCurrent()将主Surface,OpenGL
ES进程上下文绑定到SurfaceFlinger的上下文中,
2)之后所有的SurfaceFlinger进程中使用EGL的所有的操作目的地都是mSurface@DisplayHardware。
这样,在OpenGL绘制图形时,主Surface被记录在进程的上下文中,所以看不到显示的主Surfce相关参数的传递。下面是Layer-Draw,Hardware.flip的动作示意图:
4.2 ThreadLoop
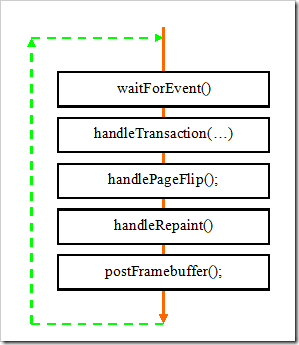
(1)handleTransaction(…):主要计算每个Layer有无属性修改,如果有修改着内用需要重画。
(2)handlePageFlip()
computeVisibleRegions:根据Z-Order序列计算每个Layer的可见区域和被覆盖区域。裁剪输出范围计算-
在生成裁剪区域的时候,根据Z_order依次,每个Layer在计算自己在屏幕的可显示区域时,需要经历如下步骤:
1)以自己的W,H给出自己初始的可见区域
2)减去自己上面窗口所覆盖的区域
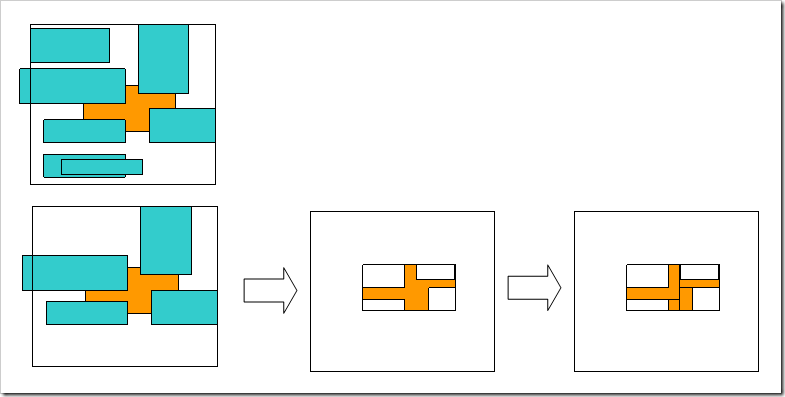
在绘制时,Layer将根据自己的可将区域做相应的区域数据Copy。
(3)handleRepaint()
composeSurfaces(需要刷新区域):
根据每个Layer的可见区域与需要刷新区域的交集区域从Z-Order序列从底部开始绘制到主Surface上。
(4)postFramebuffer()
(DisplayHardware)hw.flip(mInvalidRegion);
eglSwapBuffers(display,mSurface) :将mSruface投递到屏幕。
5 总结
现在SurfaceFlinger干的事情利用下面的示意图表示出来:
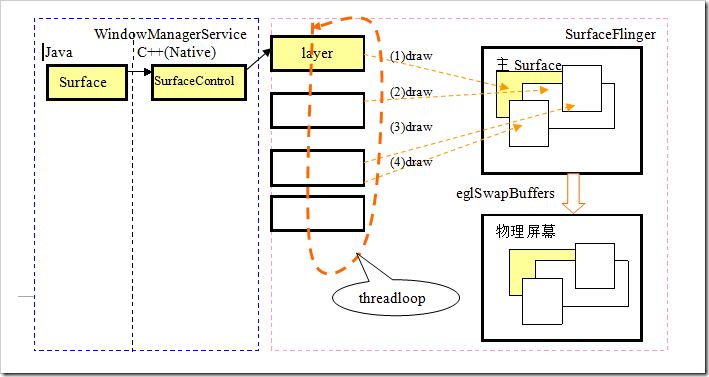
27.Android GDI 之SurfaceFlinger之动态结构示意图
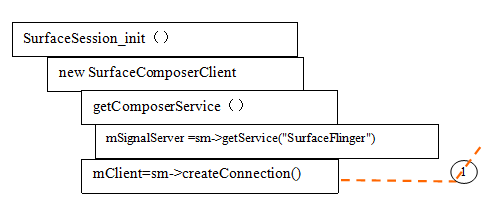
1 SurfaceSession的建立
客户端请求建立Surface时,首先在要与SurfaceFlinger建立一个Session,然后再Session上建立一个Connection通过概念返回Bclient对象。WindowManagerService在添加第一个窗口前会检查SurfaceSession是否建立,如何没有建立,将会新建立一个实例来代表与SurfaceFlinger的一个连接。
new SurfaceSession()@windowAddedLocked()
@WindowManagerService.java。
SurfaceSession的建立过程大部分是在C++ Native空间中完成的,表现在SurfaceSession的初始化函数:init()本地函数上。从下面的初始化函数可以看到:
Init()<->SurfaceSession_init@android_view_Surface.cpp
new SurfaceComposerClient
SurfaceSession在C++Native空间建立一个SurfaceComposerClient实例。而该实例的建立实现了如下的与SurfaceFlinger通讯基础:
(1)建立了代理SurfaceFlinger服务的代理服务端
(2)建立了IsurfaceFlingerClient连接,在SurfaceFlinger端建立了对应的Client,并将BClient返回给WindowManagerService。
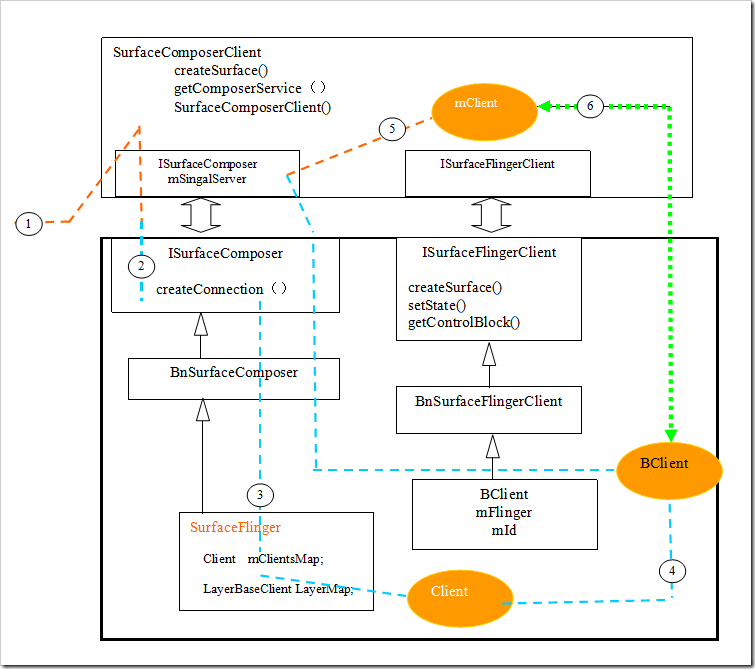
2 Surface的建立
在WindowManagerService中WindowState类中,我们知道每个主窗口子啊需要是都需要建立一个Surface与之对应。win.createSurfaceLocked()@relayoutWindow
Surface.java
Init()< -- >Surface_init(….,session,pid,dpy,w,h,format)@android_view_Surface.cpp
SurfaceControl surface(client->createSurface
在mClient的连接上:建立ISurface接口:
M_Client->greateSurface(...)@
Bclient ::createSurface(mId...)@SurfaceFlinger.cpp
mFlinger->createSurface(clientid....)
createNormalSurfaceLocked
*createNormalSurfaceLocked:建立一个Layer分配显示内存
*createPushBuffersSurfaceLocked:建立一个LayBuffer但是不分配显示内存。
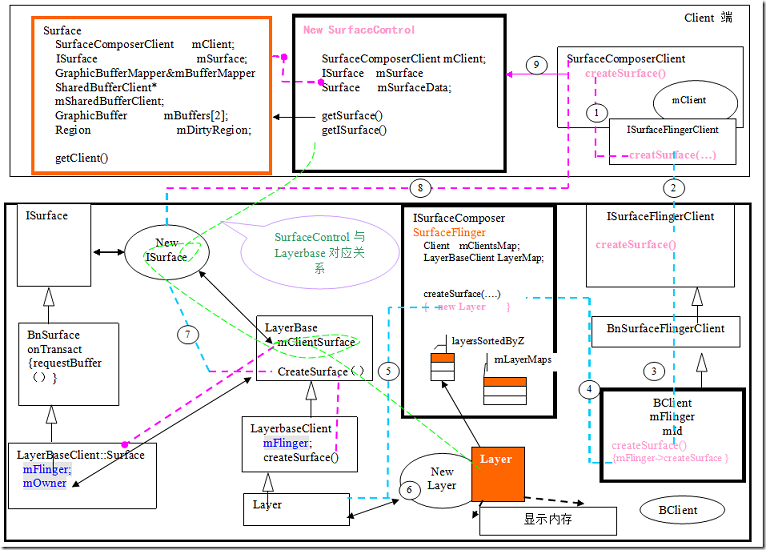
28.Android GDI之Surface&Canvas
Canvas为在画布的意思。Android上层的作图几乎都通过Canvas实例来完成,其实Canvas更多是一种接口的包装。drawPaints
,drawPoints,drawRect,drawBitmap ...
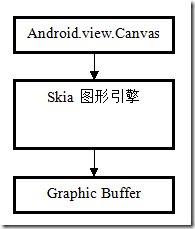
1 Canvas与Surface之间本质关系
对于本节,我们不去研究Skia图形引擎本身,我们需要了解的我们的所做的图形到底放置到了那个地方,并且这个Canvas如何与Surface连接在一起的。
Canvas(Java)在C++Native层有一个Native Canvas的C++对象所对应。
lockCanvas()@java
Surface_lockCanvas@android_view_Surface.cpp
SurfaceControl->new Surface(control)
@Surface.cpp
Surface: lock操作:
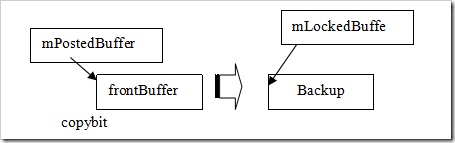
GraphicBuffer :lock
getBufferMapper().lock<-> GraphicBufferMapper
::lock
mAllocMod->lock<->gralloc_module_t::lock
通过SurfaceLock可取得Surface(mLockedBuffe)所对应的图形缓冲区地址。
(1) 建立与SkCanvas连接的位图设备,而该位图使用上面取得的图形缓冲区地址做自己的位图内存。
(2) 设置SkCanvas的作图目标设备为该位图。
通过该过程就建立起了SurfaceControl与Canvas之间的联系。
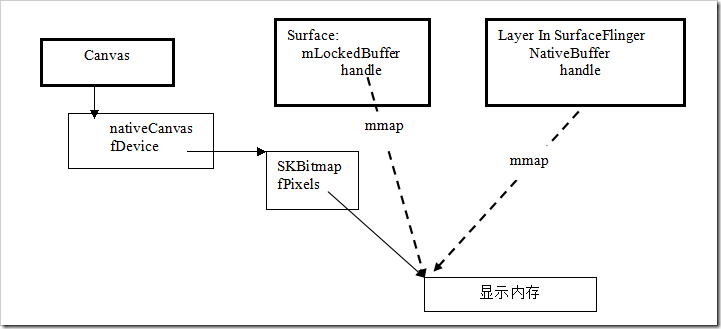
2 View:OnDraw的本源
不是使用OpenGL绘制时,Android在View属性发生变化,新建View时,或者Z-order发生变化时,需要对系统屏幕上的View重新绘制,此时我们的View会执行OnDraw(canvas),这个根源在哪里呢?
ViewRoot.Java
performTraversals(..)
…
draw()
canvas = surface.lockCanvas(dirty);
…
mView.draw(canvas);
draw(cavas)@view.java
background.draw(canvas);
onDraw(cavas)
dispatchDraw(cavas)
onDrawScrolbars(cavas)
surface.unlockCanvasAndPost(canvas); | 

