| БрМЭЦМі: |
БОЮФНВСЫЪ§ОнЧхЯДЃЌ
Ъ§ОнШБЪЇЃЌЕУЕН"District"СаШБжЕЭГМЦЪ§ЃЌЬцЛЛШЋВПЗЧЪ§жЕаЭжЕЃЌЬцЛЛвЛИіжИЖЈЕФЗЧЪ§жЕаЭжЕЃЌЯЃЭћЖдДѓМвгаАяжњЁЃ
БОЮФРДздгкЬкбЖдЦЃЌгЩЛ№СњЙћШэМўDeloresБрМЃЌЭЦМіЁЃ |
|

в§бд

ЁАЪ§ОнПЦбЇМвУЧ80%ЕФОЋСІЯћКФдкВщевЁЂЪ§ОнЧхРэЁЂЪ§ОнзщжЏЩЯЃЌжЛЪЃгк20%ЪБМфгУгкЪ§ОнЗжЮіЕШЁЃЁБЁЊЁЊIBMЪ§ОнЗжЮі
Ъ§ОнЧхЯДЪЧДІРэШЮКЮЪ§ОнЧАЕФБиБИЛЗНкЁЃдкФуПЊЪМЙЄзїЧАЃЌФугІИУгаФмСІДІРэЪ§ОнШБЪЇЁЂЪ§ОнВЛвЛжТЛђвьГЃжЕЕШЪ§ОнЛьТвЧщПіЁЃдкПЊЪМзіЪ§ОнЧхЯДЧАЃЌашвЊЖдNumpyКЭPandasПтгаЛљБОЕФРэНтЁЃ
Ъ§ОнЧхЯД
Ъ§ОнЧхЯДУћШчЦфвтЃЌЦфЙ§ГЬЮЊБъЪЖВЂаое§Ъ§ОнМЏжаВЛзМШЗЕФМЧТМЃЌЪЖБ№Ъ§ОнжаВЛПЩППЛђИЩШХВПЗжЃЌШЛКѓжиНЈЛђвЦГ§етаЉЪ§ОнЁЃ
Ъ§ОнЧхЯДЪЧЪ§ОнПЦбЇжаКмЩйЬсМАЕФвЛЕуЃЌвђЮЊЫќУЛгабЕСЗЩёОЭјТчЛђЭМЯёЪЖБ№ФЧУДживЊЃЌЕЋЪЧЪ§ОнЧхЯДШДАчбнзХЗЧГЃживЊЕФНЧЩЋЁЃУЛгаЫќЃЌЛњЦїбЇЯАдЄВтФЃаЭНЋВЛМАЮвУЧдЄЦкФЧбљгааЇКЭОЋзМЁЃ
ЯТУцЮвНЋЬжТлетаЉВЛвЛжТЕФЪ§ОнЃК
Ъ§ОнШБЪЇ
СажЕЭГвЛДІРэ
ЩОГ§Ъ§ОнжаВЛашвЊЕФзжЗћДЎ
Ъ§ОнШБЪЇ
Ъ§ОнШБЪЇдвђЃП
дкЬюаДЮЪОэЪБЃЌШЫУЧЭљЭљЮДЬюШЋЫљгаБиЬюаХЯЂЃЌЛђгУДэЪ§ОнРраЭЁЃЮЪОэНсЙћжаШБЪЇЕФЪ§ОндкЪЙгУЧАБиаызіЯргІЕФНтЪЭМАДІРэЁЃ
ЯТУцЃЌЮвУЧНЋПДЕНвЛЗнЙигкВЛЭЌВуДЮбЇЩњШыбЇПМЪдЕФЪ§ОнМЏЃЌАќРЈЕУЗжЁЂбЇаЃЦЋКУКЭЦфЫћЯИНкЁЃ
ЭЈГЃЃЌЮвУЧЯШЕМШыPandasВЂЖСШыЪ§ОнМЏЁЃ
1import pandas
as pd
data = pd.read_csv('Responses.csv') |
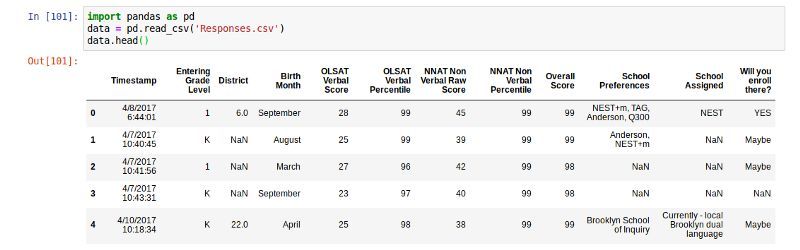
дкашвЊЕФЕиЗНЃЌФуПЩвдгУNaNЕФЗЧБъзМРраЭ(Р§ЃК'n/a','na','-')РДЬцДњШБЪЇЕФжЕЁЃ
missing_values
= ['n/a', 'na', '--']
data =pd.read_csv('Responses.csv',
na_values =
missing_values)
data.head() |
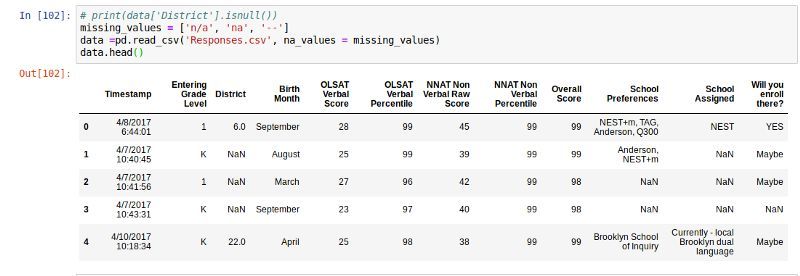
ЕУЕН"District"СаШБжЕЭГМЦЪ§
ПДDistrictСаЃЌЮвУЧЯыМьВтИУСаЪЧЗёгаПежЕВЂЭГМЦПежЕЕФзмЪ§ЁЃ
data['District'].isnull().values.any()
#To know if there is any missing values
#Returns True
data['District'].isnull().sum()
#Returns 16 |

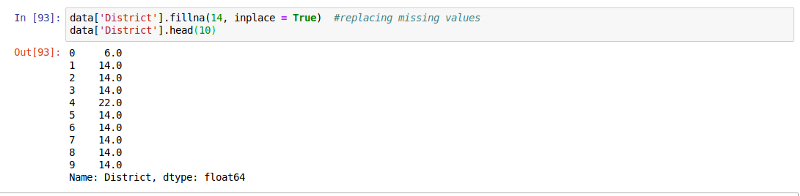
ЬцЛЛШЋВПЗЧЪ§жЕаЭжЕ
ЮвУЧПЩвдгУашвЊЕФжЕРДЬцЛЛШЋВПЗЧЪ§жЕаЭжЕЃЌЯТУцЯШЪЙгУ14етИіжЕЁЃ
data['District'].fillna(14,
inplace = True)
#replacing missing #values
data['District'] |
ЬцЛЛвЛИіжИЖЈЕФЗЧЪ§жЕаЭжЕ
ЮвУЧвВПЩвдЬцЛЛжИЖЈЮЛжУЕФжЕЃЌЯТУцР§згЪЧааЫїв§ЮЊ3ЁЃ
data.loc[3, 'District']
= 32
# data |
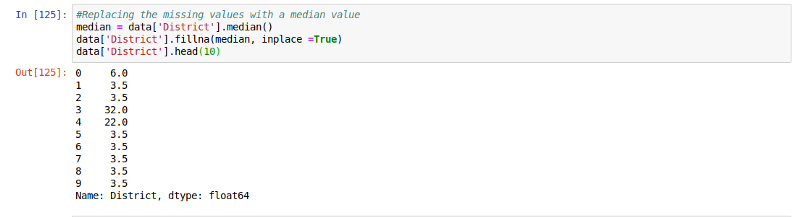
ЪЙгУжаЮЛЪ§ЬцЛЛШБЪЇжЕ
ЮвУЧПЩвдЪЙгУЗЧЪ§жЕаЭжЕЫљдкСаЕФжаЮЛЪ§НјааЬцЛЛЃЌЯТСажаЕФжаЮЛЪЧЮЊ3.5ЁЃЃЈВЙГфЫЕУїЃКжаЮЛЪ§етРяжИЗЧЪ§жЕаЭжЕЫљдкСаЕФШЋВПжЕЃЌАДИпЕЭХХађКѓевГіе§жаМфЕФвЛИізїЮЊжаЮЛЪ§ЃЉ
median = data['District'].median()
median
data['District'].fillna(median, inplace =True)
data['District'] |
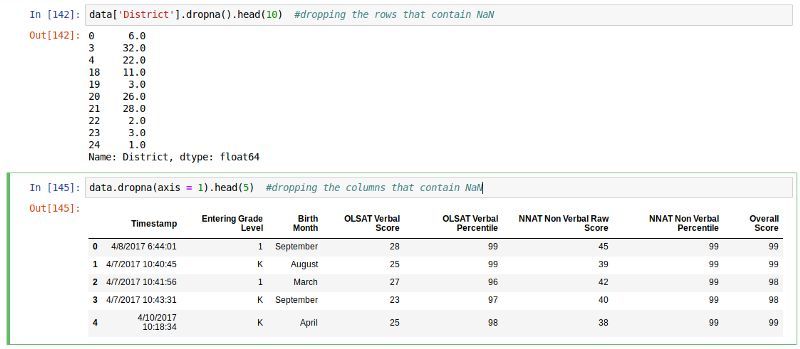
ЩОГ§ШБжЕЯю
ШчЙћФужЛЪЧЯыМђЕЅЕиХХГ§ШБжЕЯюЃЌПЩвдгУdropnaКЏЪ§ХфКЯaxisВЮЪ§НјааЁЃШБЪЁЧщПіЯТЃЌaxis=0БэЪОбиКсжсЃЈааЃЉЩОГ§КЌгагаЗЧЪ§жЕаЭзжЖЮЕФШЮКЮааЁЃ
# Drop any rows
which have any NaNs
data.dropna()
# Drop columns that have any NaNs
data.dropna(axis=1) |
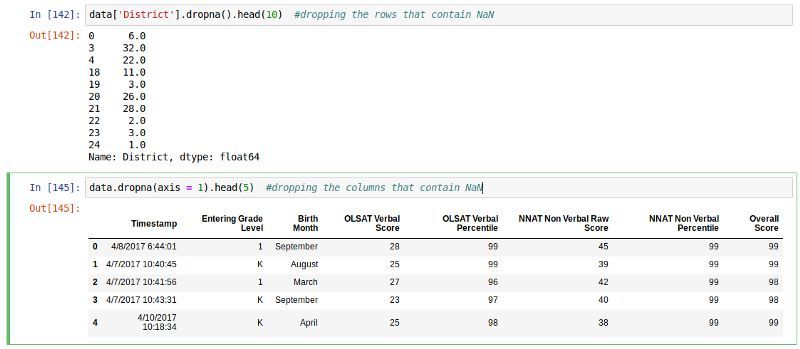
ШчЙћЪ§СажаГЌЙ§90%ЕФЪ§ОнЪЧЁАЗЧЪ§ЁБЃЌЮвУЧНЋЦфЩОГ§
етЪЧЮвзюНќбЇЕНЕФвЛИігаШЄЕФЙІФмЁЃВЮЪ§ thresh = NвЊЧѓЪ§СажажСЩйКЌгаNИіЗЧЪ§ВХФмЕУвдБЃДцЁЃдкНЋЫќУЧЪгЮЊФЃаЭЕФКђбЁепжЎЧАЃЌФужЛашвЊОпга90ЃЅПЩгУЙІФмЕФМЧТМЁЃ
# Only drop columns
which do not
have at least 90% non-NaNs
data.dropna(thresh=int
(data.shape[0] * .9), axis=1)
#Returns a data with the shape of
117rows and
8 columns
#Recall that the original data
117rows and 12columns |
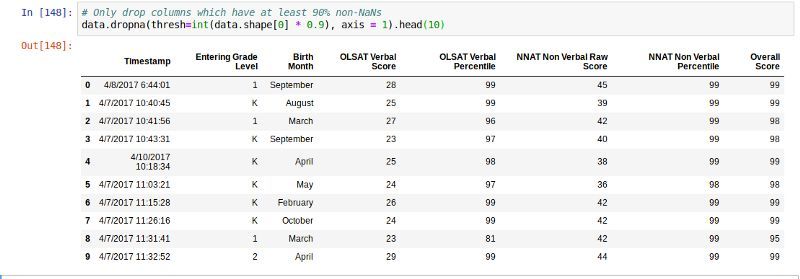
ЫљвдЃЌетвтЮЖзХ4СаГЌЙ§90ЃЅЕФЪ§ОнЯрЕБгкЁАЗЧЪ§ЁБЁЃетаЉЖдЮвУЧЕФНсЙћМИКѕУЛгагАЯьЁЃ
жДааЩЯЪіВйзїЕФСэвЛжжЗНЗЈЪЧЪжЖЏЩЈУш/ЖСШЁСаЃЌВЂЩОГ§ЖдЮвУЧЕФНсЙћгАЯьВЛДѓЕФСаЁЃ
to_drop = ['District',
'School Preferences',
'School Assigned' 'Will
you enroll there?']
data.drop(columns=to_drop, inplace=True)
#we will have the same result as the above |
ЩОГ§зжЗћДЎжаЕФФГаЉзжЗћ
МйЩшЮвУЧЯывЊДІРэвЛИіДѓаЭЪ§ОнМЏЃЌЫќАќКЌвЛаЉЮвУЧВЛЯЃЭћАќКЌдкФЃаЭжаЕФзжЗћДЎЃЌЮвУЧПЩвдЪЙгУЯТУцЕФКЏЪ§РДЩОГ§УПИізжЗћДЎЕФФГаЉзжЗћЁЃ
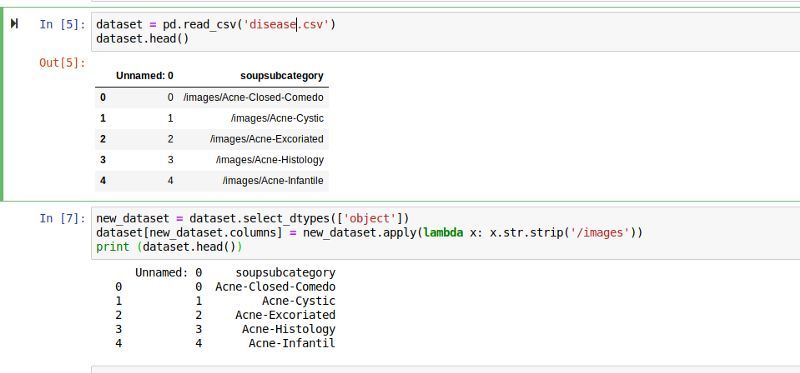
ЩЯУцЕФЦСФЛНиЭМЯдЪОСЫШчКЮДгзжЗћДЎжаЩОГ§вЛаЉзжЗћ
soupsubcategoryЪЧЮЈвЛвЛИіЪ§ОнРраЭЮЊ'object'ЕФСаЃЌЫљвдЮвУЧбЁдёСЫselect_dtypesЃЈ['object']ЃЉЃЌЮвУЧе§дкЪЙгУlambdaКЏЪ§ДгИУСажаЕФУПИі
new_dataset =
dataset.select_dtypes
([ЁЎobjectЁЏ])
dataset[new_dataset.columns]
= new_dataset.apply
(lambda
x: x.str.strip(ЁЎ/imagesЁЏ))
print (dataset) |
НсТл
ЭјТчЩЯгаДѓСПзЪдДПЩвдАяжњФњИќЩюШыЕиСЫНтPython for Data ScienceЁЃвдЩЯжЛЪЧЪ§ОнПЦбЇЫљашвЊЕФвЛаЁВПЗжЁЃЧхРэЭъЪ§ОнКѓЃЌФњПЩвддкДІРэЪ§ОнжЎЧАЖдЦфНјааПЩЪгЛЏЃЈЪ§ОнПЩЪгЛЏЃЉЃЌВЂИљОнНсЙћНјаадЄВтЁЃ
|









