| БрМЭЦМі: |
БОЮФжївЊЪЙгУKaggleЬсЙЉЕФЖэТоЫЙЗПЕиВњЪ§ОнМЏРДдЄВтЖэТоЫЙНќЦкЕФЗПМлВЈЖЏЃЌДгЖјбЇЯАЕНШчКЮНјааЪ§ОнВщевКЭЧхРэЕФвЛаЉЗНЗЈЃЌЯЃЭћЖдФњФмгаЫљАяжњЁЃ
БОЮФРДздгкcsdn ЃЌгЩЛ№СњЙћШэМўLucaБрМЃЌЭЦМіЁЃ |
|
вЛАуРДЫЕЃЌЮвУЧдкФтКЯвЛИіЛњЦїбЇЯАФЃаЭЛђЪЧЭГМЦФЃаЭжЎЧАЃЌзмЪЧвЊНјааЪ§ОнЧхРэЕФЙЄзїЁЃвђЮЊУЛгавЛИіФЃаЭФмгУвЛаЉдгТвЮоеТЕФЪ§ОнРДВњЩњЖдЯюФПгавтвхЕФНсЙћЁЃ
Ъ§ОнЧхРэЛђЧхГ§ЪЧжИДгвЛИіМЧТММЏЁЂБэЛђЪЧЪ§ОнПтжаМьВтКЭаоИФЃЈЛђЩОГ§ЃЉЫ№ЛЕЛђВЛзМШЗЕФЪ§ОнМЧТМЕФЙ§ГЬЃЌЫќгУгкЪЖБ№Ъ§ОнжаВЛЭъећЕФЁЂВЛе§ШЗЕФЁЂВЛзМШЗЕФЛђепгыЯюФПБОЩэВЛЯрЙиЕФВПЗжЃЌШЛКѓЖдетаЉЮоаЇЕФЪ§ОнНјааЬцЛЛЁЂаоИФЛђепЩОГ§ЕШВйзїЁЃ
етЪЧИіКмГЄЕФЖЈвхЃЌВЛЙ§УшЪіЕФНЯЮЊМђЕЅЃЌШнвзРэНтЁЃ
ЮЊСЫМђБуЦ№МћЃЌЮвУЧдкPythonжааТДДНЈСЫвЛИіЭъећЕФЁЂЗжВНЕФжИФЯЃЌФуНЋДгжабЇЯАЕНШчКЮНјааЪ§ОнВщевКЭЧхРэЕФвЛаЉЗНЗЈЃК
ШБЪЇЕФЪ§ОнЃЛ
ВЛЙцдђЕФЪ§ОнЃЈвьГЃжЕЃЉЃЛ
ВЛБивЊЕФЪ§ОнЁЊЁЊжиИДЪ§ОнЕШЃЛ
ВЛвЛжТЕФЪ§ОнЁЊЁЊзжФИДѓаЁаДЁЂЕижЗЕШЁЃ
дкБОЮФжаЃЌЮвУЧНЋЪЙгУKaggleЬсЙЉЕФЖэТоЫЙЗПЕиВњЪ§ОнМЏЃЈ
https://www.kaggle.com/c/sberbank-russian-housing-market/overview/descriptionЃЉЃЌФПБъЪЧвЊдЄВтвЛЯТЖэТоЫЙНќЦкЕФЗПМлВЈЖЏЁЃЮвУЧВЛЛсШЅЧхРэећИіЪ§ОнМЏЃЌвђЮЊБОЮФжЛЪЧЛсгУЕНЦфжаЕФвЛВПЗжЪОР§ЁЃ
дкЖдЪ§ОнМЏПЊЪМНјааЧхРэЙЄзїжЎЧАЃЌШУЮвУЧЯШМђЕЅЕиПДвЛЯТРяУцЕФЪ§ОнЁЃ
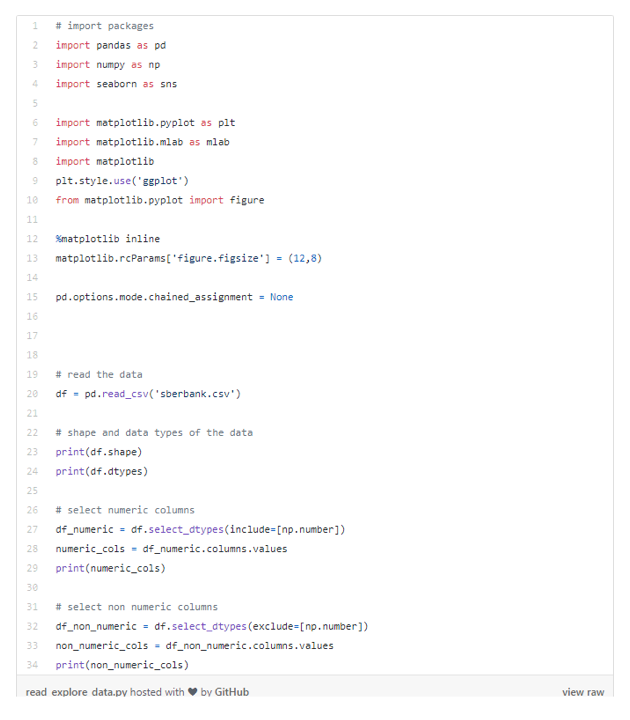
ДгЩЯЪіЕФНсЙћжаЃЌЮвУЧСЫНтЕНетИіЪ§ОнМЏзмЙВга30471ааКЭ292СаЃЌЛЙШЗЖЈСЫЬиеїЪЧЪ§жЕБфСПЛЙЪЧЗжРрБфСПЃЌетаЉЖдЮвУЧРДЫЕЖМЪЧгагУЕФаХЯЂЁЃ
ЯждкПЩвдВщПДвЛЯТЁАdirtyЁБЪ§ОнРраЭЕФСаБэЃЌШЛКѓж№ИіНјаааоИДЁЃ
ШУЮвУЧТэЩЯПЊЪМЁЃ
ШБЪЇЕФЪ§Он
ДІРэШБЪЇЕФЪ§ОнЪЧЪ§ОнЧхРэжазюМЌЪжЕЋвВЪЧзюГЃМћЕФвЛжжЧщПіЁЃЫфШЛаэЖрФЃаЭПЩвдЪЪгІИїжжИїбљЕФЧщПіЃЌЕЋДѓЖрЪ§ФЃаЭЖМВЛНгЪмЪ§ОнЕФШБЪЇЁЃ
ШчКЮЗЂЯжШБЪЇЕФЪ§ОнЃП
ЮвУЧНЋЮЊФуНщЩмШ§жжММЪѕЃЌПЩвдНјвЛВНСЫНтдкЪ§ОнМЏжаЕФШБЪЇЪ§ОнЁЃ
1ЁЂШБЪЇЪ§ОнЕФШШЭМ
ЕБЬиеїЪ§СПНЯЩйЕФЪБКђЃЌЮвУЧПЩвдЭЈЙ§ШШЭМРДНјааШБЪЇЪ§ОнЕФПЩЪгЛЏЙЄзїЁЃ
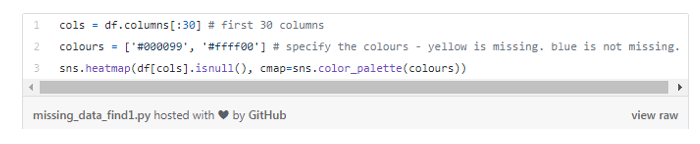
ЯТЭМЯдЪОСЫЧА30ИіЬиеїЕФШБЪЇЪ§ОнбљБОЁЃКсжсБэЪОЬиеїЕФУћГЦЃЛзнжсЯдЪОЙлВтЕФЪ§СПвдМАааЪ§ЃЛЛЦЩЋБэЪОШБЪЇЕФЪ§ОнЃЌЖјЦфЫќЕФВПЗждђгУРЖЩЋРДБэЪОЁЃ
Р§ШчЃЌЮвУЧПДЕНЬиеїlife_sqдкаэЖраажаЪЧгаШБЪЇжЕЕФЁЃЖјЬиеїfloorдкЕк7000ааИННќМИКѕОЭУЛгаЪВУДШБЪЇжЕЁЃ
ШБЪЇЪ§ОнШШЭМ
2ЁЂШБЪЇЪ§ОнЕФАйЗжБШСаБэ
ЕБдкЪ§ОнМЏжагазуЙЛЖрЕФЬиеїЪБЃЌЮвУЧПЩвдЮЊУПИіЬиеїСаГіШБЪЇЪ§ОнЕФАйЗжБШЁЃ
етНЋдкЯТУцаЮГЩвЛИіСаБэЃЌгУРДЯдЪОУПИіЬиеїЕФШБЪЇжЕЕФАйЗжБШЁЃ
ОпЬхРДЫЕЃЌЮвУЧПДЕНЬиеїlife_sqШБЪЇСЫ21%ЕФЪ§ОнЃЌЬиеїfloorдђжЛШБЪЇСЫ1%ЁЃетИіСаБэЪЧвЛИіНЯЮЊгагУЕФЛузмЃЌИљОнЫќОЭПЩвдВЙГфШШЭМПЩЪгЛЏСЫЁЃ

ШБЪЇЪ§ОнЕФАйЗжБШСаБэЁЊЁЊЧА30ИіЬиеї
3ЁЂШБЪЇЪ§ОнЕФжБЗНЭМ
ЕБЮвУЧгазуЙЛЖрЬиеїЕФЪБКђЃЌШБЪЇЪ§ОнЕФжБЗНЭМвВЪЧвЛжжММЪѕЁЃ
ЮЊСЫСЫНтИќЖрЙигкЙлВтЪ§ОнЕФШБЪЇжЕбљБОЕФаХЯЂЃЌЮвУЧПЩвдЪЙгУжБЗНЭМРДЖдЫќНјааПЩЪгЛЏВйзїЁЃ
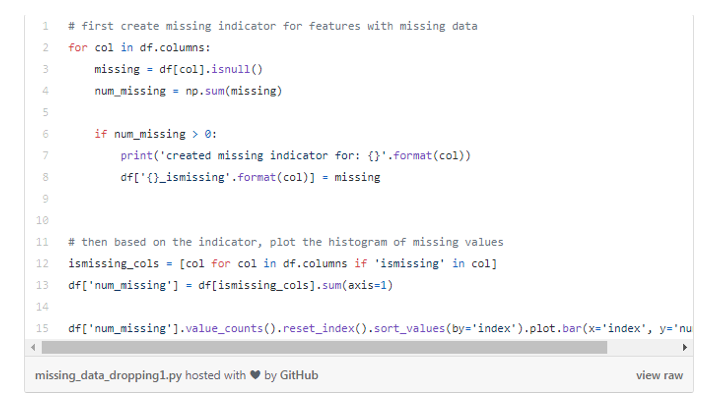
етИіжБЗНЭМгажњгкЪЖБ№30471ИіЙлВтЪ§ОнжаЕФШБЪЇжЕЧщПіЁЃ
Р§ШчЃЌга6000ЖрИіУЛгаШБЪЇжЕЕФЙлВтЪ§ОнЃЌЖјНЋНќ4000ИіЙлВтЪ§ОнжаНігавЛИіШБЪЇжЕЁЃ

ШБЪЇЪ§ОнжБЗНЭМ
ЮвУЧгІИУдѕУДзіЃП
ЖдгкДІРэШБЪЇЕФЪ§ОнЃЌУЛгаШЮКЮвЛжТЕФНтОіАьЗЈЁЃЮвУЧБиаыдкбаОПСЫЬиЖЈЕФЬиеїКЭЪ§ОнМЏжЎКѓЃЌРДОіЖЈДІРэЫќУЧЕФзюМбЗНЪНЁЃ
дкЯТЮФжаЃЌЗжБ№НщЩмСЫЫФжжДІРэШБЪЇЪ§ОнЕФГЃМћЗНЗЈЁЃЕЋЪЧЃЌШчЙћгіЕНИќИДдгЕФЧщПіЃЌЮвУЧОЭашвЊРћгУвЛаЉЯрЖдИќМгИДдгЕФЗНЗЈЃЌБШШчШБЪЇЪ§ОнНЈФЃЕШЁЃ
1ЁЂЗХЦњЙлВь
дкЭГМЦбЇжаЃЌетжжЗНЗЈБЛГЦЮЊСаБэЩОГ§ММЪѕЁЃдкетИіЗНАИжаЃЌжЛвЊАќКЌСЫвЛИіШБЪЇжЕЃЌЮвУЧОЭвЊЩОГ§ећЬѕЕФЙлВтЪ§ОнЁЃ
жЛгаЕБЮвУЧШЗЖЈЫљШБЪЇЕФЪ§ОнУЛгаЬсЙЉгагУаХЯЂЕФЪБКђЃЌЮвУЧВХФмжДааДЫВйзїЁЃЗёдђЃЌЮвУЧгІИУПМТЧЪЙгУЦфЫќЕФАьЗЈЁЃ
ЕБШЛЃЌвВПЩвдЪЙгУЦфЫќБъзМРДЩОГ§ЙлВьЪ§ОнЁЃ
Р§ШчЃЌДгШБЪЇЪ§ОнЕФжБЗНЭМжаЃЌЮвУЧПЩвдПДЕНзмЙВШБЪЇСЫжСЩй35ИівдЩЯЕФЬиеїЙлВтЪ§ОнЁЃЮвУЧПЩвдДДНЈвЛИіаТЕФЪ§ОнМЏdf_less_missing_rowsЃЌШЛКѓЩОГ§Опга35ИівдЩЯШБЪЇЬиеїЕФЙлВтЪ§ОнЁЃ

2ЁЂЩОГ§Ьиеї
гыЗНАИвЛБШНЯРрЫЦЃЌЮвУЧжЛгадкШЗЖЈЕБЧАЬиеїУЛгаЬсЙЉШЮКЮгагУаХЯЂЕФЪБКђВХФмжДааетИіВйзїЁЃ
Р§ШчЃЌДгШБЪЇЪ§ОнАйЗжБШЕФСаБэжаЃЌЮвУЧзЂвтЕНhospital_beds_raionЕФШБЪЇжЕАйЗжБШИпДя47%ЁЃФЧУДЃЌЮвУЧОЭПЩвдЩОГ§ећИіЬиеїЪ§ОнСЫЁЃ
3ЁЂЬюВЙШБЪЇЪ§Он
ЕБЬиеїЪЧвЛИіЪ§жЕБфСПЕФЪБКђЃЌПЩвдНјааШБЪЇЪ§ОнЕФЬюВЙЁЃЮвУЧЛсНЋШБЪЇЕФжЕЬцЛЛЮЊЯрЭЌЬиеїЪ§ОнжавбгаЪ§жЕЕФЦНОљжЕЛђЪЧжажЕЁЃ
ЕБЬиеїЪЧвЛИіЗжРрБфСПЕФЪБКђЃЌЮвУЧПЩвдЭЈЙ§ФЃЪНЃЈзюЦЕЗБГіЯжЕФжЕЃЉРДЬюВЙШБЪЇЕФЪ§ОнЁЃ
вдlife_sqЮЊР§ЃЌЮвУЧПЩвдгУЫќЕФжажЕРДЬцЛЛетИіЬиеїЕФШБЪЇжЕЁЃ

ДЫЭтЃЌЮвУЧЛЙПЩвдЭЌЪБЖдЫљгаЕФЪ§зжЬиеїЪЙгУЯрЭЌЕФЬюВЙЪ§ОнЕФЗНЪНЁЃ
БШНЯавдЫЕФЪЧЃЌЮвУЧЕФЪ§ОнМЏжаВЂУЛгаШБЪЇЗжРрЬиеїЕФжЕЁЃШЛЖјЃЌЮвУЧПЩвдЖдЫљгаЕФЗжРрЬиеїНјаавЛДЮадЕФФЃЪНЬюВЙВйзїЁЃ
4ЁЂЬцЛЛШБЪЇЕФЪ§Он
ЖдгкЗжРрЬиеїЃЌЮвУЧПЩвдЬэМгвЛИіРрЫЦгкЁА_MISSING_ЁБетбљЕФжЕЃЌетЪЧвЛжжаТРраЭЕФжЕЁЃЖдгкЪ§жЕЬиеїЃЌЮвУЧПЩвдЪЙгУ-999етбљЕФЬиЪтжЕРДЬцЛЛЫќЁЃ
етбљЃЌЮвУЧШдШЛПЩвдБЃСєШБЪЇжЕзїЮЊгагУЕФаХЯЂЁЃ
ВЛЙцдђЕФЪ§ОнЃЈвьГЃжЕЃЉ
вьГЃжЕЪЧгыЦфЫќЕФЙлВтжЕНиШЛВЛЭЌЕФЪ§ОнЃЌЫќУЧПЩФмЪЧеце§ЕФвьГЃжЕЛђепЪЧДэЮѓжЕЁЃ
ШчКЮЗЂЯжВЛЙцдђЕФЪ§ОнЃП
ИљОнЬиеїЪЧЪ§жЕЕФЛЙЪЧЗжРрЕФЃЌЮвУЧПЩвдЪЙгУВЛЭЌЕФММЪѕРДбаОПЦфЗжВМЬиЕугУвдМьВтЫќЕФвьГЃжЕЁЃ
1ЁЂжБЗНЭМКЭЗНПђЭМ
ЕБЬиеїЪЧЪ§жЕЕФЪБКђЃЌЮвУЧПЩвдЪЙгУжБЗНЭМЛђепЪЧЗНПђЭМРДМьВтЫќЕФвьГЃжЕЁЃ
ЯТУцЪЧЬиеїlife_sqЕФжБЗНЭМЁЃ

гЩгкПЩФмДцдквьГЃжЕЃЌвђДЫЃЌЪ§ОнзМШЗадЕФВюБ№ПДЦ№РДЪЧвьГЃЯджјЕФЁЃ
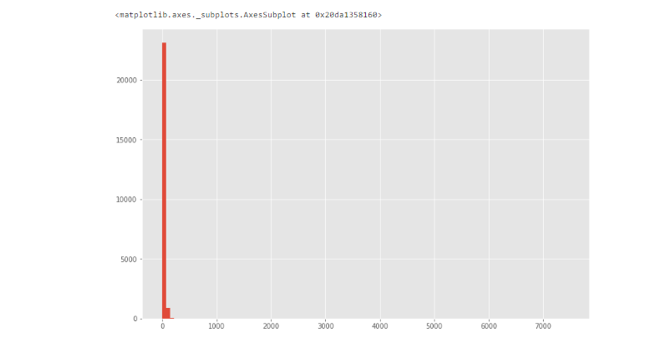
жБЗНЭМ
ЮЊСЫИќЩюШыЕибаОПетИіЬиеїЃЌЯТУцЮвУЧРДЛвЛИіЗНПђЭМЁЃ

дкетИіЭМжаЃЌЮвУЧПЩвдПДЕНвЛИіГЌЙ§7000ЕФвьГЃжЕЁЃ
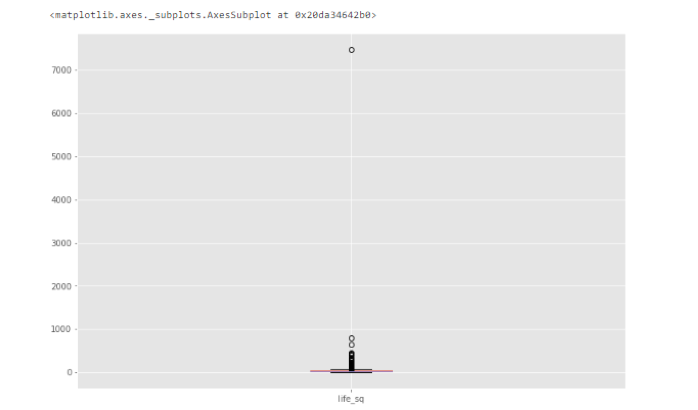
ЗНПђЭМ
2ЁЂУшЪіадЭГМЦЪ§Он
ДЫЭтЃЌЖдгкЪ§жЕЬиеїЃЌвьГЃжЕПЩФмЙ§гкУїЯдЃЌвджТЗНПђЭМЮоЗЈЖдЦфНјааПЩЪгЛЏЁЃЯрЗДЕиЃЌЮвУЧПЩвдПДПДЫќУЧЕФУшЪіадЭГМЦЪ§ОнЁЃ
Р§ШчЃЌЖдгкЬиеїlife_sqЃЌЮвУЧПЩвдПДЕНзюДѓжЕЪЧ7478ЃЌЖј75%ЕФЫФЗжЮЛЪ§жЛга43ЁЃКмУїЯдЃЌ7478жЕЪЧвЛИівьГЃжЕЁЃ

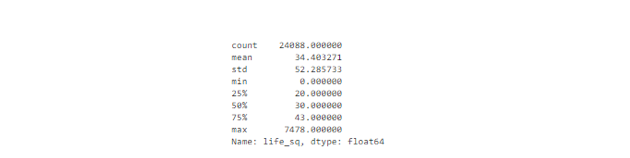
3ЁЂЬѕаЮЭМ
ЖдгкЗжРрЬиеїЃЌЮвУЧПЩвдЪЙгУЬѕаЮЭМРДСЫНтЬиеїЕФРрБ№вдМАЗжВМЕФЧщПіЁЃ
Р§ШчЃЌЬиеїecologyОпгаКЯРэЕФЗжВМЃЌЕЋЪЧЃЌШчЙћгавЛИіРрБ№жЛгавЛИіНазіЁАotherЁБЕФжЕЃЌФЧУДетПЯЖЈОЭЪЧвЛИівьГЃжЕЁЃ

ЬѕаЮЭМ
4ЁЂЦфЫќЕФММЪѕ
ЛЙгааэЖрЦфЫќЕФММЪѕвВПЩвдгУРДЗЂЯжвьГЃжЕЃЌР§ШчЩЂЕуЭМЁЂz-scoreКЭОлРрЕШЕШЃЌдкетРяНЋВЛЛсвЛвЛНјааНВНтЁЃ
ЮвУЧгІИУдѕУДзіЃП
ЫфШЛбАеввьГЃжЕВЂВЛЪЧЪВУДФбЪТЃЌЕЋЪЧЮвУЧБиаыШЗЖЈе§ШЗЕФНтОіАьЗЈРДНјааДІРэЁЃЫќИпЖШвРРЕгкЫљЪЙгУЕФЪ§ОнМЏКЭЯюФПЕФФПБъЁЃ
ДІРэвьГЃжЕЕФЗНЗЈгааЉРрЫЦгкШБЪЇЪ§ОнЕФВйзїЁЃЮвУЧвЊУДЗХЦњЁЂвЊУДЕїећЁЂвЊУДБЃСєЫќУЧЁЃЖдгкПЩФмЕФНтОіЗНАИЃЌЮвУЧПЩвдВЮПМБОЮФЕФШБЪЇЪ§ОнВПЗжЁЃ
ВЛБивЊЕФЪ§Он
дкЖдШБЪЇЪ§ОнКЭвьГЃжЕНјааСЫЫљгаЕФХЌСІжЎКѓЃЌШУЮвУЧПДПДЙигкВЛБивЊЕФЪ§ОнЃЌетОЭИќМђЕЅСЫЁЃ
ЪзЯШЃЌЫљгаЪфШыЕНФЃаЭжаЕФЪ§ОнЖМгІИУЮЊЯюФПЕФФПБъЗўЮёЁЃВЛБивЊЕФЪ§ОнОЭЪЧЪ§ОнУЛгаЪЕМЪЕФЪ§жЕЁЃИљОнВЛЭЌЕФЧщПіЃЌЮвУЧжївЊЛЎЗжСЫШ§жжРраЭЕФВЛБивЊЪ§ОнЁЃ
1ЁЂЮоаХЯЂЛђепжиИДжЕ
гаЪБЃЌвЛИіЬиеїУЛгагагУЕФаХЯЂЃЌвђЮЊЬЋЖрЕФааОпгаЯрЭЌЕФжЕЁЃ
ШчКЮЗЂЯжЮоаХЯЂЛђепжиИДжЕЃП
ЮвУЧПЩвдДДНЈвЛИіОпгаЯрЭЌЪ§жЕЕФАйЗжБШНЯИпЕФЬиеїСаБэЁЃ
Р§ШчЃЌЮвУЧдкЯТУцжИЖЈЯдЪО95%вдЩЯЕФОпгаЯрЭЌжЕЕФааЕФЬиеїЁЃ
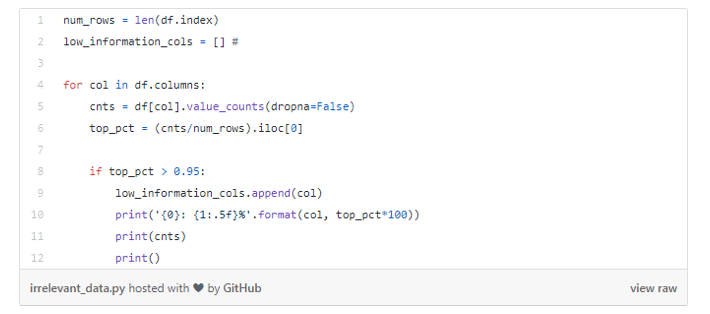
ЮвУЧПЩвдвЛИівЛИіЕибаОПетаЉБфСПЃЌПДПДЫќУЧЪЧЗёОпгагаМлжЕЕФаХЯЂЃЌдкетРяОЭВЛЯдЪОЯИНкСЫЁЃ

ЮвУЧгІИУдѕУДзіЃП
ЮвУЧашвЊСЫНтжиИДЬиеїБГКѓЕФдвђЃЌЕБЫќУЧецЕФШБЩйгагУаХЯЂЕФЪБКђЃЌОЭПЩвдАбЫќУЧЗХЦњСЫЁЃ
2ЁЂВЛЯрЙиЕФЪ§Он
ЭЌбљЃЌЪ§ОнашвЊЮЊЯюФПЬсЙЉгагУЕФаХЯЂЁЃШчЙћетаЉЬиеїЪ§ОнгыЮвУЧдкЯюФПжавЊНтОіЕФЮЪЬтУЛЪВУДЙиЯЕЃЌФЧУДЫќУЧОЭЪЧВЛЯрЙиЕФЁЃ
ШчКЮЗЂЯжВЛЯрЙиЕФЪ§ОнЃП
ЪзЯШЃЌЮвУЧашвЊфЏРРвЛЯТетаЉЬиеїЃЌвдБужЎКѓФмЪЖБ№ФЧаЉВЛЯрЙиЕФЪ§ОнЁЃ
Р§ШчЃЌвЛИіМЧТМЖрТзЖрЬьЦјЕФЬиеїЪ§ОнВЂВЛФмЮЊдЄВтЖэТоЫЙЗПМлЬсЙЉШЮКЮгагУЕФаХЯЂЁЃ
ЮвУЧгІИУдѕУДзіЃП
ЕБетаЉЬиеїЪ§ОнВЂВЛЗћКЯЯюФПЕФФПБъЪБЃЌЮвУЧОЭПЩвдЗХЦњЫќУЧСЫЁЃ
3ЁЂжиИДЪ§Он
жиИДЪ§ОнЪЧжИДцдкЖрИіЯрЭЌЕФЙлВтжЕЁЃ
жиИДЪ§ОнжївЊАќКЌСНжжРраЭЁЃ
ЃЈ1ЃЉЛљгкЫљгаЬиеїЕФжиИДЪ§Он
ШчКЮЗЂЯжЛљгкЫљгаЬиеїЕФжиИДЪ§ОнЃП
ЕБЙлВьЕНЕФЫљгаЬиеїЪ§ОнЖМЯрЭЌЕФЪБКђЃЌОЭЛсЗЂЩњетжжжиИДЯжЯѓЃЌетЪЧКмШнвзЗЂЯжЕФЁЃ
ЮвУЧЪзЯШвЊШЅГ§Ъ§ОнМЏжаЕФЮЈвЛБъЪЖЗћidЃЌШЛКѓЭЈЙ§ЩОГ§жиИДЪ§ОнРДДДНЈвЛИіУћЮЊdf_deduppedЕФЪ§ОнМЏЁЃЮвУЧЭЈЙ§БШНЯСНИіЪ§ОнМЏЃЈdfКЭdf_dedupedЃЉЃЌевГігаЖрЩйИіжиИДааЁЃ
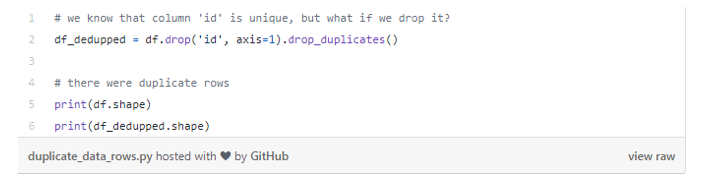
ЕУГіЃЌ10ааЪЧЭъШЋжиИДЕФЙлВьНсЙћЁЃ
ЮвУЧгІИУдѕУДзіЃП
ЮвУЧгІИУЩОГ§етаЉжиИДЪ§ОнЁЃ
ЃЈ2ЃЉЛљгкЙиМќЬиеїЕФжиИДЪ§Он
ШчКЮЗЂЯжЛљгкЙиМќЬиеїЕФжиИДЪ§ОнЃП
гаЪБзюКУИљОнвЛзщЮЈвЛЕФБъЪЖЗћРДЩОГ§ФЧаЉжиИДЕФЪ§ОнЁЃ
Р§ШчЃЌЭЌвЛНЈжўУцЛ§ЁЂЭЌвЛМлИёЁЂЭЌвЛНЈжўФъЗнЕФСНИіЗПВњНЛвзЭЌЪБЗЂЩњЕФПЩФмадМИКѕЮЊСуЁЃ
ЮвУЧПЩвдЩшжУвЛзщЙиМќЬиеїзїЮЊНЛвзЕФЮЈвЛБъЪЖЗћЃЌАќРЈtimestampЁЂ full_sqЁЂlife_sqЁЂfloorЁЂbuild_yearЁЂnum_roomЁЂprice_docЃЌЮвУЧЛсМьВщЪЧЗёгаЛљгкетаЉБъЪЖЗћЕФИББОЃЈжиИДМЧТМЃЉЁЃ

ЛљгкетзщЙиМќЬиеїЃЌЙВга16ИіИББОЃЌвВОЭЪЧжиИДЪ§ОнЁЃ
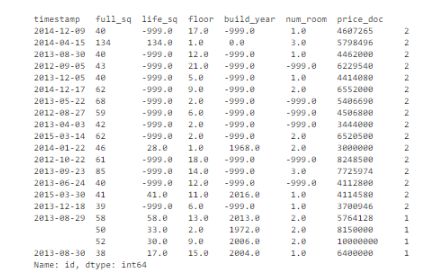
ЮвУЧгІИУдѕУДзіЃП
ЮвУЧПЩвдИљОнЙиМќЬиеїЩОГ§етаЉжиИДЪ§ОнЁЃ

ЮвУЧдкУћЮЊdf_dedupped2ЕФаТЪ§ОнМЏжаЩОГ§СЫ16ИіжиИДЪ§ОнЁЃ

ВЛвЛжТЕФЪ§Он
ШУЪ§ОнМЏзёбЬиЖЈЕФБъзМРДФтКЯФЃаЭвВЪЧжСЙиживЊЕФЁЃЮвУЧашвЊгУВЛЭЌЕФЗНЗЈШЅЬНЫїЪ§ОнЃЌетбљОЭПЩвдевГіВЛвЛжТЕФЪ§ОнСЫЁЃКмЖрЪБКђЃЌетШЁОігкЯИжТЕФЙлВьКЭЗсИЛЕФОбщЃЌВЂУЛгаЙЬЖЈЕФДњТыгУРДдЫааКЭаоИДВЛвЛжТЕФЪ§ОнЁЃ
ЯТУцЮвУЧНЋНщЩмЫФжжВЛвЛжТЕФЪ§ОнРраЭЁЃ
1ЁЂДѓаЁаДВЛвЛжТ
дкЗжРржЕжаДцдкзХДѓаЁаДВЛвЛжТЕФЧщПіЃЌетЪЧвЛИіГЃМћЕФДэЮѓЁЃгЩгкPythonжаЕФЪ§ОнЗжЮіЪЧЧјЗжДѓаЁаДЕФЃЌвђДЫетОЭПЩФмЛсЕМжТЮЪЬтЕФГіЯжЁЃ
ШчКЮЗЂЯжДѓаЁаДВЛвЛжТЃП
ЯШШУЮвУЧРДПДПДЬиеїsub_areaЁЃ

ЫќгУРДДцДЂВЛЭЌЕиЧјЕФУћГЦЃЌПДЦ№РДвбОЗЧГЃЕФБъзМЛЏСЫЁЃ

ЕЋЪЧЃЌгаЪБКђдкЭЌвЛИіЬиеїЪ§ОнжаДцдкзХДѓаЁаДВЛвЛжТЕФЧщПіЁЃОйИіР§згЃЌЁАPoselenie SosenskoeЁБКЭЁАpOseleNie
sosenskeoЁБОЭПЩФмжИЕФЪЧЭЌвЛЕиЧјЁЃ
ЮвУЧгІИУдѕУДзіЃП
ЮЊСЫБмУтетжжЧщПіЕФЗЂЩњЃЌЮвУЧвЊУДЫљгаЕФзжФИгУаЁаДЃЌвЊУДШЋВПгУДѓаДЁЃ
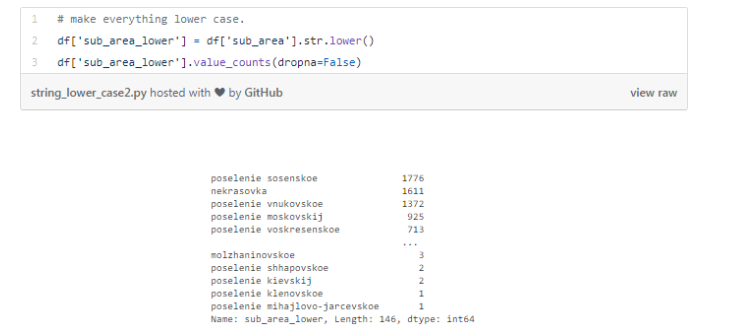
2ЁЂЪ§ОнИёЪНВЛвЛжТ
ЮвУЧашвЊЪЕааЕФСэвЛИіБъзМЛЏЪЧЪ§ОнИёЪНЁЃетРягавЛИіР§згЃЌЪЧНЋЬиеїДгзжЗћДЎЃЈStringЃЉИёЪНзЊЛЛЮЊШеЦкЪБМфЃЈDateTimeЃЉИёЪНЁЃ
ШчКЮЗЂЯжВЛвЛжТЕФЪ§ОнИёЪНЃП
ЬиеїtimestampЪЧвдзжЗћДЎЕФИёЪНРДБэЪОШеЦкЕФЁЃ
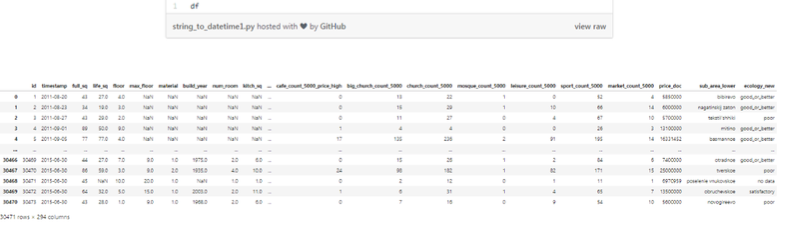
ЮвУЧгІИУдѕУДзіЃП
ЮвУЧПЩвдЪЙгУЯТУцЕФДњТыНјаазЊЛЛЃЌВЂЬсШЁГіШеЦкЛђЪБМфЕФжЕЁЃжЎКѓЃЌЛсИќШнвзАДФъЛђдТНјааЗжзщЕФНЛвзСПЗжЮіЁЃ
3ЁЂЪ§ОнЕФЗжРржЕВЛвЛжТ
ВЛвЛжТЕФЗжРржЕЪЧЮвУЧвЊЬжТлЕФзюКѓвЛжжВЛвЛжТЪ§ОнЕФРраЭЁЃЗжРрЬиеїжЕЕФЪ§СПгаЯоЁЃгаЪБКђгЩгкЪфШыДэЮѓЕШдвђЃЌПЩФмЛсДцдкЦфЫќЕФжЕЁЃ
ШчКЮЗЂЯжВЛвЛжТЕФЗжРржЕЃП
ЮвУЧашвЊзаЯИЙлВьвЛИіЬиеїРДевГіВЛвЛжТЕФжЕЃЌдкетРяЃЌЮвУЧгУвЛИіР§згРДЫЕУївЛЯТЁЃ
гЩгкЮвУЧдкЗПЕиВњЪ§ОнМЏжаВЂВЛДцдкетбљЕФЮЪЬтЃЌвђДЫЃЌЮвУЧдкЯТУцДДНЈСЫвЛИіаТЕФЪ§ОнМЏЁЃР§ШчЃЌЬиеїcityЕФжЕБЛДэЮѓЕиЖЈвхЮЊЁАtorontooЁБКЭЁАtrontoЁБЁЃЕЋЫќУЧСНИіЖМжИЯђСЫе§ШЗЕФжЕЁАtorontoЁБЁЃ
вЛжжМђЕЅЕФШЗШЯЗНЗЈЪЧФЃК§ТпМЃЈЛђЪЧБрММфИєЃЌedit distanceЃЉЁЃЫќКтСПСЫЮвУЧашвЊИќИФвЛИіжЕЕФЦДаДгУРДгыСэвЛИіжЕНјааЦЅХфЕФзжФИВювьЪ§СПЃЈОрРыЃЉЁЃ
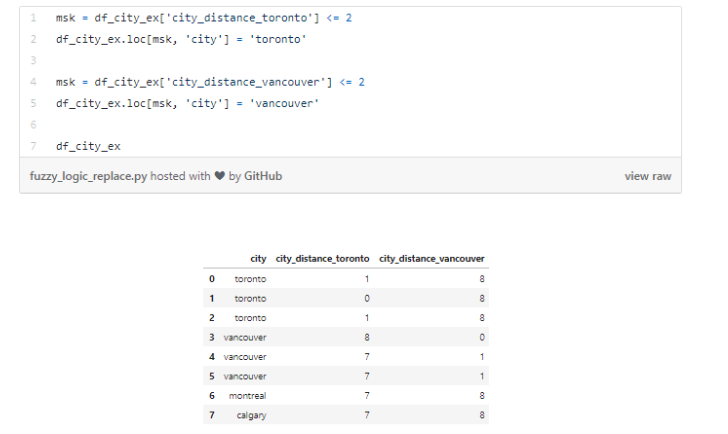
ЮвУЧжЊЕРетаЉРрБ№гІИУжЛгаЁАtorontoЁБЁЂЁАvancouverЁБЁЂЁАmontrealЁБвдМАЁАcalgaryЁБетЫФИіжЕЁЃЮвУЧМЦЫуСЫЫљгаЕФжЕгыЕЅДЪЁАtorontoЁБЃЈКЭЁАvancouverЁБЃЉжЎМфЕФОрРыЁЃПЩвдПДЕНЃЌФЧаЉгаПЩФмЪЧДђзжДэЮѓЕФЕЅДЪгые§ШЗЕФЕЅДЪжЎМфЕФОрРыНЯаЁЃЌвђЮЊЫќУЧжЎМфжЛВюСЫМИИізжФИЖјвбЁЃ

ЮвУЧгІИУдѕУДзіЃП
ЮвУЧПЩвдЩшжУвЛИіБъзМНЋетаЉДэЮѓЕФЦДаДзЊЛЛЮЊе§ШЗЕФжЕЁЃР§ШчЃЌЯТУцЕФДњТыНЋОрРыЁАtorontoЁБ2ИізжФИвдФкЕФЫљгажЕЖМЩшжУЮЊЁАtorontoЁБЁЃ
4ЁЂЕижЗЪ§ОнВЛвЛжТ
ЕижЗЬиеїФПЧАГЩЮЊСЫЮвУЧаэЖрШЫзюЭЗЬлЕФЮЪЬтЁЃвђЮЊШЫУЧОГЃдкВЛзёбБъзМИёЪНЕФЧщПіЯТЃЌОЭНЋЪ§ОнЪфШыЕНЪ§ОнПтжаСЫЁЃ
ШчКЮЗЂЯжВЛвЛжТЕФЕижЗЃП
ЮвУЧПЩвдЭЈЙ§ВщПДЪ§ОнРДевЕНФбвдДІРэЕФЕижЗЁЃМДЪЙгаЪБКђЮвУЧЗЂЯжВЛСЫШЮКЮЮЪЬтЃЌЕЋЮвУЧЛЙПЩвддЫааДњТыЃЌЖдЕижЗЪ§ОнНјааБъзМЛЏДІРэЁЃ
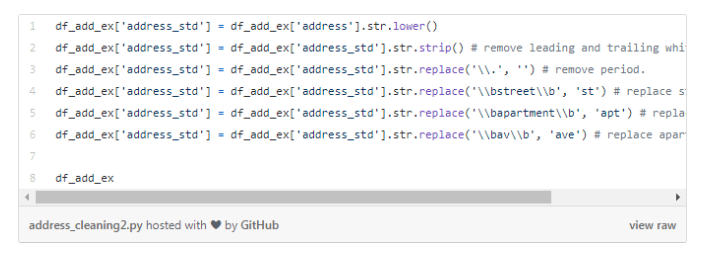
дкЮвУЧЕФЪ§ОнМЏжаУЛгаЪєгквўЫНЕФЕижЗЁЃвђДЫЃЌЮвУЧРћгУЬиеїaddressДДНЈСЫвЛИіаТЕФЪ§ОнМЏdf_add_exЁЃ

е§ШчЮвУЧЫљПДЕНЕФФЧбљЃЌЕижЗЪ§ОнПЩЪЧЗЧГЃВЛЙцЗЖЕФЁЃ
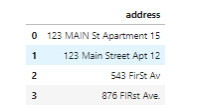
ЮвУЧгІИУдѕУДзіЃП
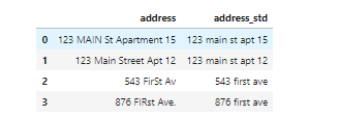
ЮвУЧдЫааЯТУцЕФДњТыЃЌФПЕФЪЧНЋзжФИЭГвЛБфГЩаЁаДЕФЁЂЩОГ§ПеИёЁЂЩОГ§ПеаавдМАНјааЕЅДЪБъзМЛЏЁЃ
ЯждкПДЦ№РДКУЖрСЫЁЃ
ЮвУЧжегкЭъГЩСЫЃЌОЙ§СЫвЛИіКмГЄЕФЙ§ГЬЃЌЧхГ§СЫФЧаЉЫљгазшАФтКЯФЃаЭЕФЁАdirtyЁБЪ§ОнЁЃ |









