| БрМЭЦМі: |
ЮФеТНщЩмСЫШчКЮЪЙгУPythonЕкШ§ЗНПтPyAudioНјааТѓПЫЗчТМвєШЛКѓздЖЏВЅЗХвбОКЯГЩЕФгявєЪЕЯжгявєНЛЛЅЛиД№ЁЃ
БОЮФРДздгкcnblogs ЃЌгЩЛ№СњЙћШэМўLucaБрМЃЌЭЦМіЁЃ |
|
Python КмЧПДѓЦфдвђОЭЪЧвђЮЊЫќХгДѓЕФШ§ЗНПт , зЪдДЪЧЗЧГЃЕФЗсИЛ
, ЕБШЛвВВЛЛсШБЩйЙигквєЦЕЕФПт
ЙигквєЦЕ, PyAudio етИіПт, ПЩвдЪЕЯжПЊЦєТѓПЫЗчТМвє, ПЩвдВЅЗХвєЦЕЮФМўЕШЕШ,ДЫПЬЮвУЧВЛШЅСЫНтЦфЫћЕФЙІФм,жЛСЫНтвЛЯТЫќШчКЮЪЕЯжТМвєЕФ
ЪзЯШвЊЯШ pip вЛИі PyAudio
pip install pyaudio
вЛ.PyAudio ЪЕЯжТѓПЫЗчТМвє
ШЛКѓНЈСЂвЛИіpyЮФМў,ИДжЦШчЯТДњТы
import pyaudio
import wave
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 2
RATE = 16000
RECORD_SECONDS = 2
WAVE_OUTPUT_FILENAME = "Oldboy.wav"
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("ПЊЪМТМвє,ЧыЫЕЛА......")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("ТМвєНсЪј,ЧыБезь!")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close() |
ГЂЪдвЛЯТ,дкФПТМжаГіЯжСЫвЛИі Oldboy.wav ЮФМў , Ь§вЛЬ§,ЛЙЪЧКмЧхЮњЕФТя
НгЯТРД,ЮвУЧНЋетЖЮТМвєДњТы,аДдквЛИіКЏЪ§РяУц,ШчЙћвЊТМвєЕФЛАОЭЕїгУ
НЈСЂвЛИіЮФМў pyrec.py ВЂНЋТМвєДњТыКЭКЏЪ§аДдкФк
# pyrec.py ЮФМўФкШн
import pyaudio
import wave
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 2
RATE = 16000
RECORD_SECONDS = 2
def rec(file_name):
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("ПЊЪМТМвє,ЧыЫЕЛА......")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("ТМвєНсЪј,ЧыБезь!")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(file_name, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close() |
rec КЏЪ§ОЭЪЧЮвУЧЕїгУЕФТМвєКЏЪ§,ВЂЧвИјЫћвЛИіЮФМўУћ,ЫћОЭЛсздЖЏНЋЩљвєаДШыЕНЮФМўжаСЫ
Жў.ЪЕЯжвєЦЕИёЪНздЖЏзЊЛЛ ВЂ ЕїгУгявєЪЖБ№
ТМвєЕФЮЪЬтНтОіСЫ,ИЯПьКЭАйЖШгявєЪЖБ№НгдквЛЦ№ЪЙгУвЛЯТ:
ВЛЙмФуЕФТМвєгаЖрУДЖрУДЧхЮњ,ФуЗЂЯжАйЖШИјФуЗЕЛиЕФгРдЖЪЧ:
| {'err_msg':
'speech quality error.', 'err_no': 3301, 'sn':
'6397933501529645284'} # вєжЪВЛЧхЮњ |
ЦфЪЕВЛЪЧУЛЬ§Чх,ЖјЪЧАйЖШжЇГжЕФвєЦЕИёЪНPCMИуЕФЙэ
Ыљвд,ЮвУЧвЊНЋТМжЦЕФwavвєЦЕЮФМўзЊЛЛЮЊpcmЮФМў
аДвЛИіЮФМў wav2pcm.py етИіЮФМўРяУцЕФКЏЪ§ЪЧзЈУХЮЊЮвУЧзЊЛЛwavЮФМўЕФ
ЪЙгУ os ФЃПщжаЕФ os.system()ЗНЗЈ етИіЗНЗЈЪЧжДааЯЕЭГУќСюгУЕФ,
дкwindowsЯЕЭГжаЕФУќСюОЭЪЧ cmd РяУцаДЕФЖЋЮї,dir , cd етРрЕФУќСю
# wav2pcm.py
ЮФМўФкШн
import os
def wav_to_pcm(wav_file):
# МйЩш wav_file = "вєЦЕЮФМў.wav"
# wav_file.split(".") ЕУЕН["вєЦЕЮФМў","wav"]
ФУГіЕквЛИіНсЙћ"вєЦЕЮФМў" гы ".pcm" ЦДНг
ЕШЕННсЙћ "вєЦЕЮФМў.pcm"
pcm_file = "%s.pcm" %(wav_file.split(".")[0])
# ОЭЪЧДЫЧАЮвУЧдкcmdДАПкжаЪфШыУќСю,етРяУцОЭЪЧдкШУPythonАяЮвУЧдкcmdжажДааУќСю
os.system("ffmpeg -y -i %s -acodec pcm_s16le
-f s16le -ac 1 -ar 16000 %s"%(wav_file,pcm_file))
return pcm_file |
етбљЮвУЧОЭгаСЫАбwavзЊЮЊpcmЕФКЏЪ§СЫ , дйжиаТЙЙНЈвЛДЮдлУЧЕФДњТы
етДЮЕФЗЕЛиНсЙћЛЙЭІШУШЫТњвтЕФТя
| {'corpus_no':
'6569869134617218414', 'err_msg': 'success.',
'err_no': 0, 'result': ['xxxНЬг§'], 'sn': '8116162981529666859'} |
ФУЕНгявєЪЖБ№ЕФзжЗћДЎСЫ,НгЯТРДгУетЖЮзжЗћДЎ гявєКЯГЩ, бЇЯАдлУЧЫЕГіРДЕФЛА
Ш§.гявєКЯГЩ гы FFmpeg ВЅЗХmp3 ЮФМў
ФУЕНзжЗћДЎСЫ,жБНгЕїгУsynthesisЗНЗЈШЅКЯГЩАЩ

етЖЮДњТыЯЮНгЩЯвЛЖЮДњТы,ГЩЙІЛёЕУСЫ synth.mp3 вєЦЕЮФМў,ВЂЧвШЗЖЈСЫЪЕдкбЇЯАЮвУЧЫЕЕФЛА
НгЯТРДОЭЪЧШУЮвУЧЕФГЬађздЖЏНЋ synth.mp3 вєЦЕЮФМўВЅЗХСЫ ЦфЪЕPyAudio гаВЅЗХЕФЙІФм,ЕЋЪЧВйзїгаЕуИДдг
ЫљвдЮвУЧЛЙЪЧбЁдёгУМђЕЅЕФЗНЪННтОіИДдгЕФЮЪЬт,ОЭЪЧетУДМђЕЅДжБЉ,ЪЧЗёЛЙМЧЕУFFmpeg Фи?
FFmpeg етИіЯЕЭГЙЄОпжа,гавЛИі ffplay ЕФЙЄОпгУРДДђПЊВЂВЅЗХвєЦЕЮФМўЕФ,ЪЙгУЗНЗЈДѓИХЪЧ:
ffplay вєЦЕЮФМў.mp3
НЈСЂвЛИіplaymp3.pyЮФМў, аДвЛИі play_mp3 ЕФКЏЪ§гУРДВЅЗХвбОКЯГЩЕФгявє
# playmp3.py
ЮФМўФкШн
import os
def play_mp3(file_name):
os.system("ffplay %s"%(file_name)) |
ЛиЕНжїЮФМў,ЕїгУplaymp3.pyЮФМўжаЕФ play_mp3 КЏЪ§

жДааДњТы,ЕБФуПДЕН : ПЊЪМТМвє,ЧыЫЕЛА......
ЧыДѓЩљЕФЫЕГі: бЇIT евxxxНЬг§
ШЛКѓФуОЭЛсЬ§ЕН,вЛИіНПЕЮЕЮЩљвєжиИДФуЫЕЕФЛА
ЫФ.МђЕЅЮЪД№
ЪзЯШЮвУЧвЊАбДњТыжиаТЪсРэвЛЯТ:
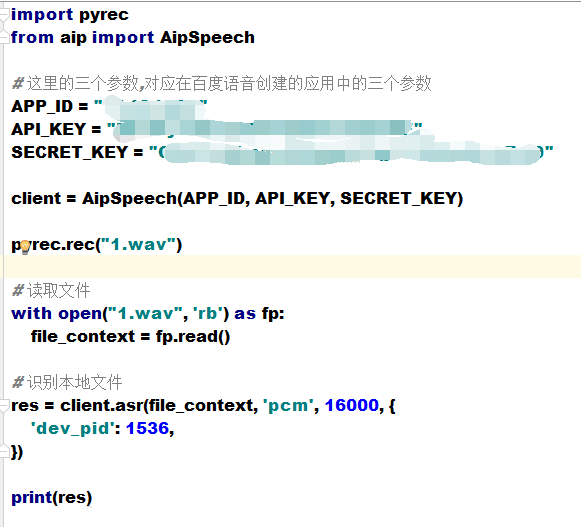
АбгявєКЯГЩ гявєЪЖБ№ВПЗжЕФДњТыЖРСЂГЩКЏЪ§ЗХЕНbaidu_ai.pyЮФМўжа
# baidu_ai.py
ЮФМўФкШн
from aip import AipSpeech
# етРяЕФШ§ИіВЮЪ§,ЖдгІдкАйЖШгявєДДНЈЕФгІгУжаЕФШ§ИіВЮЪ§
APP_ID = "xxxxx"
API_KEY = "xxxxxxx"
SECRET_KEY = "xxxxxxxx"
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
def audio_to_text(pcm_file):
# ЖСШЁЮФМў , жегкЕУЕНСЫPCMЮФМў
with open(pcm_file, 'rb') as fp:
file_context = fp.read()
# ЪЖБ№БОЕиЮФМў
res = client.asr(file_context, 'pcm', 16000,
{
'dev_pid': 1536,
})
# ДгзжЕфРяУцЛёШЁ"result"ЕФvalue СаБэжаЕк1ИідЊЫи,ОЭЪЧЪЖБ№ГіРДЕФзжЗћДЎ"xxxНЬг§"
res_str = res.get("result")[0]
return res_str
def text_to_audio(res_str):
synth_file = "synth.mp3"
synth_context = client.synthesis(res_str, "zh",
1, {
"vol": 5,
"spd": 4,
"pit": 9,
"per": 4
})
with open(synth_file, "wb") as f:
f.write(synth_context)
return synth_file |
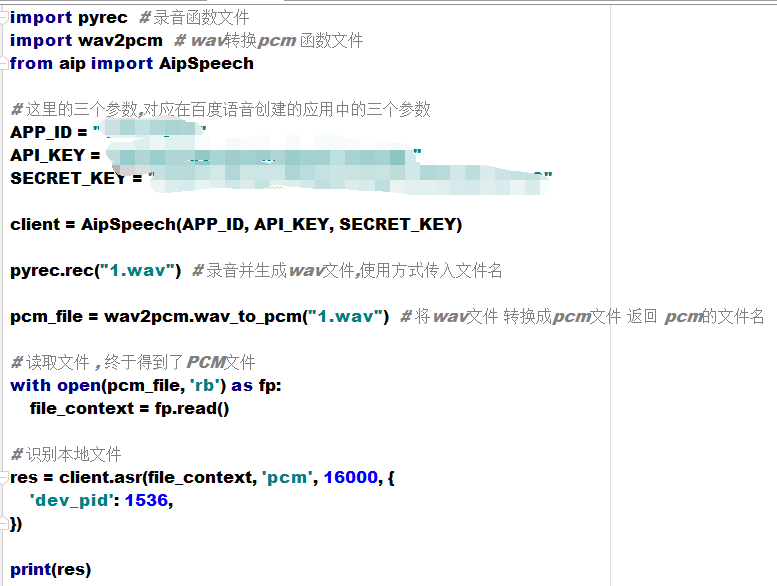
ШЛКѓАбЮвУЧЕФжїЮФМўНјаавЛЯТаоИФ
import pyrec
# ТМвєКЏЪ§ЮФМў
import wav2pcm # wavзЊЛЛpcm КЏЪ§ЮФМў
import baidu_ai # гявєКЯГЩКЏЪ§,гявєЪЖБ№КЏЪ§ ЮФМў
import playmp3 # ВЅЗХmp3 КЏЪ§ ЮФМў
pyrec.rec("1.wav") # ТМвєВЂЩњГЩwavЮФМў,ЪЙгУЗНЪНДЋШыЮФМўУћ
pcm_file = wav2pcm.wav_to_pcm("1.wav")
# НЋwavЮФМў зЊЛЛГЩpcmЮФМў ЗЕЛи pcmЕФЮФМўУћ
res_str = baidu_ai.audio_to_text(pcm_file)
# НЋзЊЛЛКѓЕФpcmвєЦЕЮФМўЪЖБ№ГЩ ЮФзж res_str
synth_file = baidu_ai.text_to_audio(res_str)
# НЋres_str зжЗћДЎ КЯГЩгявє ЗЕЛиЮФМўУћ synth_file
playmp3.play_mp3(synth_file) # ВЅЗХ synth_file |
ШЛКѓОЭЪЧДѓеЙКъЭМЕФЪБКђСЫ,еЙПЊФуУЧЕФЯыЯѓСІ:
res_str ЪЧзжЗћДЎ,ШчЙћзжЗћДЎЕШгк"ФуНаЪВУДУћзж"ЕФЪБКђ,ЮвУЧОЭвЊИјЫћвЛИіЛиД№:ЮвЕФУћзжНаxxxНЬг§
аТНЈвЛИіFAQ.pyЕФЮФМўШЛКѓНЈСЂвЛИіКЏЪ§faq:
# FAQ.py ЮФМўФкШн
def faq(Q):
if Q == "ФуНаЪВУДУћзж": # ЮЪЬт
return "ЮвЕФУћзжЪЧxxxНЬг§" # Д№АИ
return "ЮвВЛжЊЕРФудкЫЕЪВУД" #ЮЪЬтУЛгаД№АИЪБЗЕ |
дкжїЮФМўжаЕМШыетИіКЏЪ§,ВЂНЋгявєЪЖБ№КѓЕФзжЗћДЎДЋШыКЏЪ§жа

ЯждкРДГЂЪдвЛЯТ:"ФуНаЪВУДУћзж","ФуНёФъМИЫъСЫ"
ГЩЙІСЫ,ЯждкФуПЩвдЖд FAQ.py етИіЮФМўНјааИќЖрЕФЮЪЬтЦЅХфСЫ
ЛЙЪЧФЧОфЛА,Б№ЭцЖљЛЕСЫ
ЫМПМЬт:
1.ШчКЮЪЕЯжвЛжБЮЪД№ВЛгУЮЪвЛДЮЭЃвЛДЮ?
2.ЮЪЬтФЧУДЖр,ЪЧВЛЪЧвЊаДетУДЖрЮЪЬтФи?
3.ШчЙћЮвЮЪФуЪЧЫ,ЪЧВЛЪЧвЊжиИДвВвЛДЮ ЮвЕФУћзжНаXXX ЕФД№АИФи? |









