| БрМЭЦМі: |
| БОЮФРДздгкcsdn,ЮФеТжївЊЭЈЙ§АИР§НщЩмСЫЪ§ОнЧхЯДЗНЗЈЃЌНщЩмНЯЮЊЯъЯИЃЌЯЃЭћЖдДѓМвгаАяжњЁЃ |
|
ЪзЯШдиШыИїжжАќЃК
import pandas
as pd
import numpy as np
from collections import Counter
from sklearn import preprocessing
from matplotlib import pyplot as plt
%matplotlib inline
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei'] #
жаЮФзжЬхЩшжУ-КкЬх
plt.rcParams['axes.unicode_minus'] = False # НтОіБЃДцЭМЯёЪЧИККХ'-'ЯдЪОЮЊЗНПщЕФЮЪЬт
sns.set(font='SimHei') # НтОіSeabornжаЮФЯдЪОЮЪЬт
|
ЖСШыЪ§ОнЃКетРяЪ§ОнЪЧБрдьЕФ
data=pd.read_excel('dummy.xlsx')
|
БОАИР§ЕФецЪЕЪ§ОнЪЧетбљЕФЃК
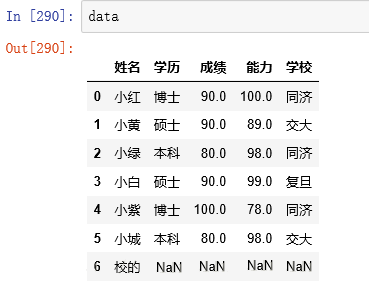
ЖдЪ§ОнНјааЖрЗНЮЛЕФВщПДЃК
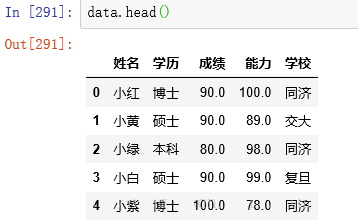
ЪЕМЪЧщПіжаПЩФмЛсгаКмЖрааЃЌвЛАугУhead()ПДЪ§ОнЛљБОЧщПі
data.head()
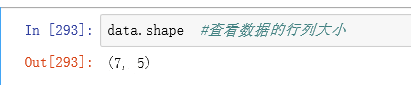
#ВщПДГЄЩЖбљ
data.shape #ВщПДЪ§ОнЕФааСаДѓаЁ
data.describe()
|
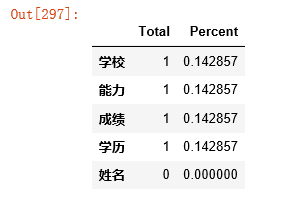
#СаМЖБ№ЕФХаЖЯ,ЕЋЗВФГвЛСагаnullжЕЛђПеЕФЃЌдђЮЊец
data.isnull().any()
#НЋСажаЮЊПеЛђепnullЕФИіЪ§ЭГМЦГіРДЃЌВЂНЋШБЪЇжЕзюЖрЕФХХЧА
total = data.isnull().sum().sort_values (ascending=False)
print(total)#ЪфГіАйЗжБШЃК
percent =(data.isnull().sum( )/data.isnull( ).count()).sort_values(ascending=False)
missing_data = pd.concat([total, percent], axis=1,
keys=['Total', 'Percent'])
missing_data.head(20)
|
вВПЩвдДгЪгОѕЩЯжБЙлВщПДШБЪЇжЕЃК
import missingno
missingno.matrix(data)
data=data.dropna(thresh=data.shape [0]*0.5,axis=1)
#жСЩйгавЛАывдЩЯЪЧЗЧПеЕФСаЩИбЁГіРД
|
#ШчЙћФГвЛааШЋВПЖМЪЧnaВХЩОГ§ЃК
data.dropna(axis=0,how='all') |
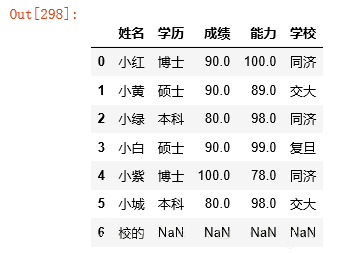
#ФЌШЯЧщПіЯТЪЧжЛБЃСєУЛгаПежЕЕФаа
data=data.dropna(axis=0) |
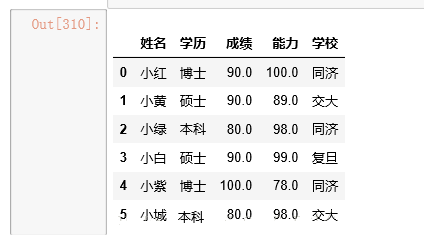
#ЭГМЦжиИДМЧТМЪ§
data.duplicated().sum()
data.drop_duplicates() |
ЖдСЌајаЭЪ§ОнКЭРыЩЂаЭЪ§ОнЗжПЊДІРэЃК
data.columns
#ЕквЛВНЃЌНЋећИіdataЕФСЌајаЭзжЖЮКЭРыЩЂаЭзжЖЮНјааЙщРр
id_col=['аеУћ']
cat_col=['бЇРњ','бЇаЃ'] #етРяЪЧРыЩЂаЭЮоађЃЌШчЙћгаађЃЌЧыВЮПМmapгУЗЈЃЌвЛаЉВЉПЭЩЯгааД
cont_col=['ГЩМЈ','ФмСІ'] #етРяЪЧЪ§жЕаЭ
print (data[cat_col]) #етРяЪЧРыЩЂаЭЕФЪ§ОнВПЗж
print (data[cont_col])#етРяЪЧСЌајадЪ§ОнВПЗж
|
ЖдгкРыЩЂаЭВПЗжЃК
#МЦЫуГіЯжЕФЦЕДЮ
for i in cat_col:
print (pd.Series(data[i]).value_counts())
plt.plot(data[i]) |
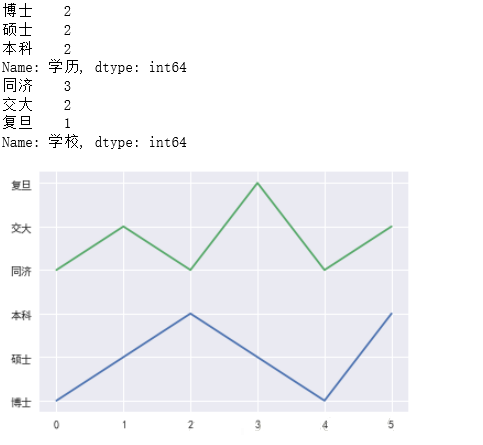
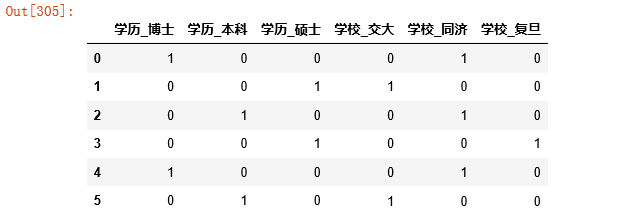
#ЖдгкРыЩЂаЭЪ§ОнЃЌЖдЦфЛёШЁбЦБфСП
dummies=pd.get_dummies(data[cat_col])
dummies |
ЖдгкСЌајаЭВПЗжЃК
#ЖдгкСЌајаЭЪ§ОнЕФДѓИХЭГМЦЃК
data[cont_col].describe()
#ЖдгкСЌајаЭЪ§ОнЃЌПДЦЋЖШЃЌвЛАуДѓгк0.75ЕФЪ§жЕзівЛИіlogзЊЛЏЃЌЪЙжЎОЁСПЗћКЯе§ЬЌЗжВМЃЌвђЮЊКмЖрФЃаЭЕФМйЩшЪ§ОнЪЧЗўДге§ЬЌЗжВМЕФ
skewed_feats = data[cont_col].apply( lambda x:
(x.dropna()).skew() )#compute skewness
skewed_feats = skewed_feats[skewed_feats >
0.75]
skewed_feats = skewed_feats.index
data[skewed_feats] = np.log1p(data[skewed_feats])
skewed_feats
|
#ЖдгкСЌајаЭЪ§ОнЃЌЖдЦфНјааБъзМЛЏ
scaled=preprocessing.scale( data[cont_col])
scaled=pd.DataFrame( scaled,columns=cont_col)
scaled
|
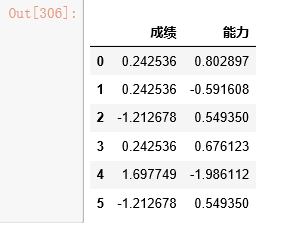
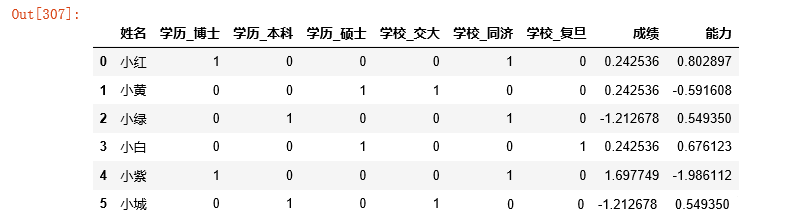
m=dummies.join(scaled)
data_cleaned=data[id_col].join(m)
data_cleaned |
ПДБфСПжЎМфЕФЯрЙиадЃК
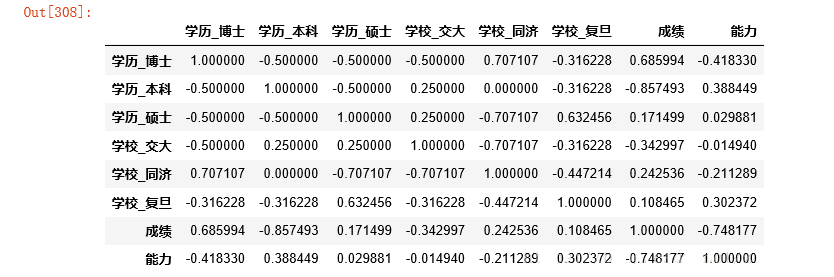
#вдЯТЪЧЯрЙиадЕФШШСІЭМЃЌЗНБуШтблПД
def corr_heat(df):
dfData = abs(df.corr())
plt.subplots(figsize=(9, 9)) # ЩшжУЛУцДѓаЁ
sns.heatmap(dfData, annot=True, vmax=1, square=True,
cmap=" Blues")
# plt.savefig ('./BluesStateRelation.png')
plt.show()
corr_heat(data_cleaned)
|
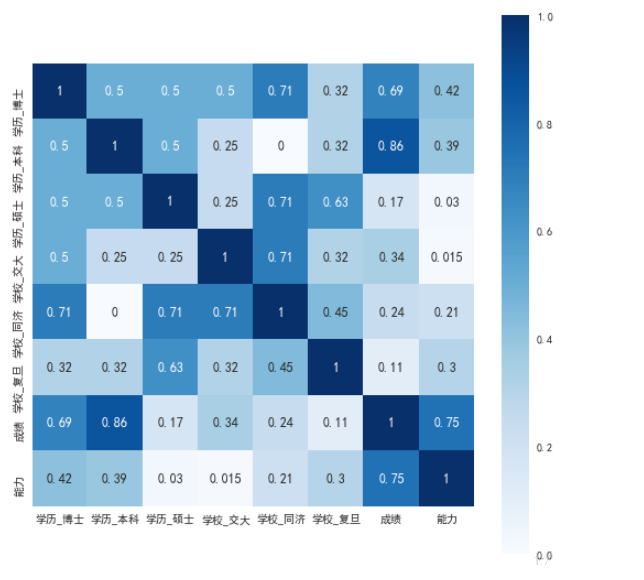
ШчЙћгаОѕЕУЯрЙиадЦЋИпЕФЪгЧщПіЩОМѕФГаЉБфСПЁЃ
#ШЁГігыФГИіБфСПЃЈетРяжИФмСІЃЉЯрЙиадзюДѓЕФЧАЫФИіЃЌзіГіШШЕуЭМБэЪО
k = 4 #number of variables for heatmap
cols = corrmat.nlargest(k, 'ФмСІ' )['ФмСІ'].index
cm = np.corrcoef(data_cleaned[ cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True,
fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values,
xticklabels =cols.values)
plt.show()
|
|









