| БрМЭЦМі: |
| БОЮФРДздгкcsdn,БОЮФжївЊНВНтШчКЮРћгУЪ§ОнШБЪЇЁЂМьВтКЭЙ§ТЫвьГЃжЕЁЂвЦГ§жиИДЪ§ОнЖдPython
PandasНјааЪ§ОндЄДІРэ,ЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ |
|
Ъ§ОнШБЪЇ
Ъ§ОнШБЪЇдкДѓВПЗжЪ§ОнЗжЮігІгУжаЖМКмГЃМћЃЌPandasЪЙгУИЁЕужЕNaNБэЪОИЁЕуКЭЗЧИЁЕуЪ§зщжаЕФШБЪЇЪ§ОнЃЌЫћжЛЪЧвЛИіБугкБЛМьВтГіРДЕФЪ§ОнЖјвбЁЃ
from pandas import
Series,DataFrame
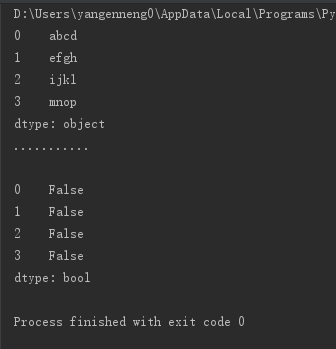
string_data=Series(['abcd','efgh','ijkl','mnop'])
print(string_data)
print("...........\n")
print(string_data.isnull())
|
PythonФкжУЕФNoneжЕвВЛсБЛЕБзїNAДІРэ
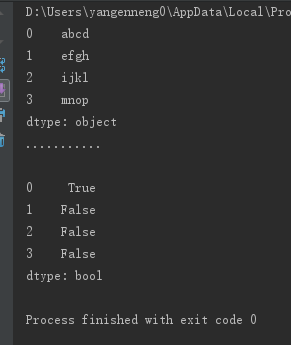
from pandas import
Series,DataFrame
string_data=Series(['abcd','efgh','ijkl','mnop'])
print(string_data)
print("...........\n")
string_data[0]=None
print(string_data.isnull())
|
ДІРэNAЕФЗНЗЈгаЫФжжЃКdropna,fillna,isnull,notnull
is(not)nullЃЌетвЛЖдЗНЗЈЖдЖдЯѓзіГідЊЫиМЖЕФгІгУЃЌШЛКѓЗЕЛивЛИіВМЖћаЭЪ§зщЃЌвЛАуПЩгУгкВМЖћаЭЫїв§ЁЃ
dropnaЃЌЖдгквЛИіSeriesЃЌdropnaЗЕЛивЛИіНіКЌЗЧПеЪ§ОнКЭЫїв§жЕЕФSeriesЁЃ
ЮЪЬтдкгкDataFrameЕФДІРэЗНЪНЃЌвђЮЊвЛЕЉdropЕФЛАЃЌжСЩйвЊЖЊЕєвЛааЃЈСаЃЉЁЃетРяНтОіЗНЗЈгыЧАУцРрЫЦЃЌЛЙЪЧЭЈЙ§вЛИіЖюЭтЕФВЮЪ§ЃКdropna(axis=0,how=ЁЏanyЁЏ,thresh=None)ЃЌhowВЮЪ§ПЩбЁЕФжЕЮЊanyЛђепall.allНідкЧаЦЌдЊЫиШЋЮЊNAЪБВХХзЦњИУаа(Са)ЁЃthreshЮЊећЪ§РраЭЃЌeg:thresh=3,ФЧУДвЛааЕБжажСЩйгаШ§ИіNAжЕЪБВХНЋЦфБЃСєЁЃ
fillna,fillna(value=None,method=None,axis=0)жаЕФvalueГ§СЫЛљБОРраЭЭтЃЌЛЙПЩвдЪЙгУзжЕфЃЌетбљПЩвдЪЕЯжЖдВЛЭЌСаЬюГфВЛЭЌЕФжЕЁЃ
Й§ТЫЪ§ОнЃК
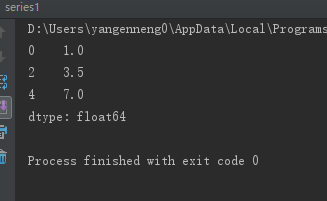
ЖдгквЛИіSeriesЃЌdropnaЗЕЛивЛИіНіКЌЗЧПеЪ§ОнКЭЫїв§жЕЕФSeriesЃК
from pandas import
Series,DataFrame
from numpy import nan as NA
data=Series([1,NA,3.5,NA,7])
print(data.dropna()) |
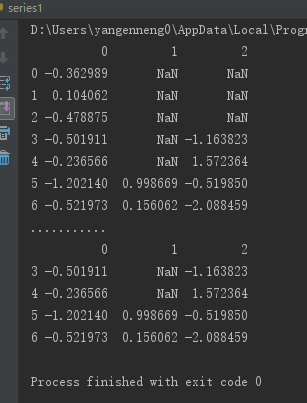
СэвЛИіЙ§ТЫDataFrameааЕФЮЪЬтЩцМАЮЪЬтађСаЪ§ОнЁЃМйЩшжЛЯыСєвЛВПЗжЙлВьЪ§ОнЃЌПЩвдгУthreshВЮЪ§ЪЕЯжДЫФПЕФЃК
from pandas import
Series,DataFrame, np
from numpy import nan as NA
data=DataFrame(np.random.randn(7,3))
data.ix[:4,1]=NA
data.ix[:2,2]=NA
print(data)
print("...........")
print(data.dropna(thresh=2)) |
ВЛЯыТЫГ§ШБЪЇЕФЪ§ОнЃЌЖјЪЧЭЈЙ§ЦфЫћЗНЪНЬюВЙЁАПеЖДЁБЃЌfillnaЪЧзюжївЊЕФКЏЪ§ЁЃ
ЭЈЙ§вЛИіГЃЪ§ЕїгУfillnaОЭЛсНЋШБЪЇжЕЬцЛЛЮЊФЧИіГЃЪ§жЕЃК
from pandas import
Series,DataFrame, np
from numpy import nan as NA
data=DataFrame(np.random.randn(7,3))
data.ix[:4,1]=NA
data.ix[:2,2]=NA
print(data)
print("...........")
print(data.fillna(0))
|
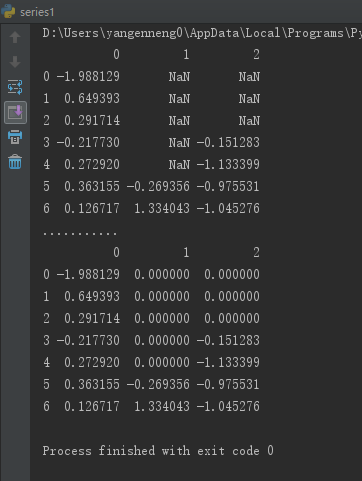
ШєЪЧЭЈЙ§вЛИізжЕфЕїгУfillnaЃЌОЭПЩвдЪЕЯжЖдВЛЭЌСаЬюГфВЛЭЌЕФжЕЁЃ
from pandas import
Series,DataFrame, np
from numpy import nan as NA
data=DataFrame(np.random.randn(7,3))
data.ix[:4,1]=NA
data.ix[:2,2]=NA
print(data)
print("...........")
print(data.fillna({1:111,2:222}))
|
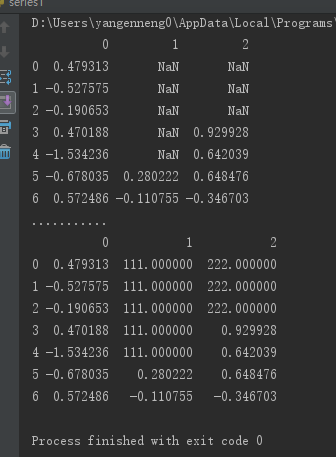
ПЩвдРћгУfillnaЪЕЯжаэЖрБ№ЕФЙІФмЃЌБШШчПЩвдДЋШыSeriesЕФЦНОљжЕЛђжаЮЛЪ§ЃК
from pandas import
Series,DataFrame, np
from numpy import nan as NA
data=Series([1.0,NA,3.5,NA,7])
print(data)
print("...........\n")
print(data.fillna(data.mean()))
|
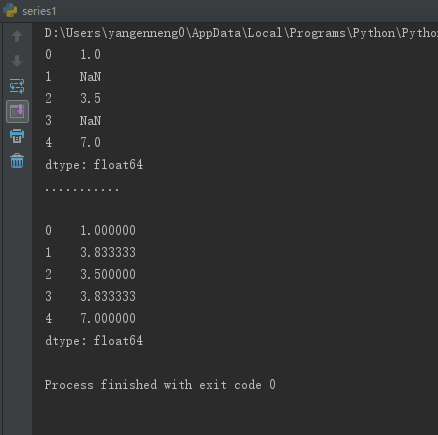
МьВтКЭЙ§ТЫвьГЃжЕ
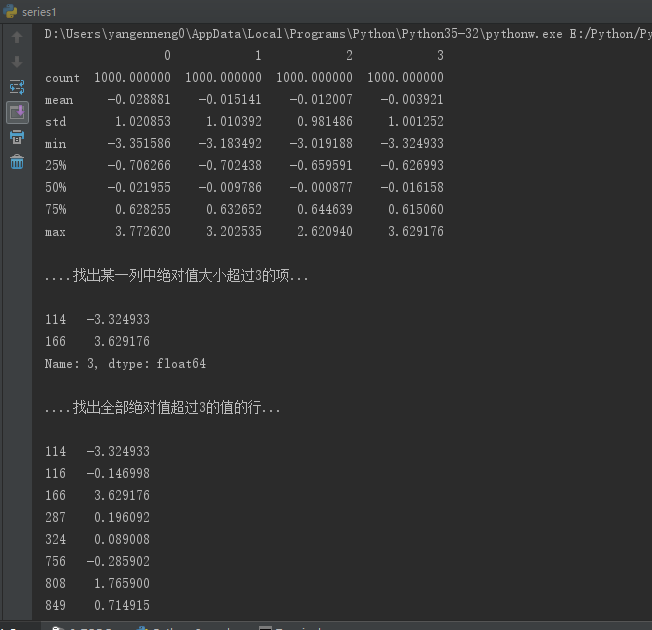
вьГЃжЕ(outlier)ЕФЙ§ТЫЛђБфЛЛдЫЫудкКмДѓГЬЖШЩЯОЭЪЧЪ§зщдЫЫуЁЃШчЯТвЛИі(1000,4)ЕФБъзМе§ЬЌЗжВМЪ§зщЃК
from pandas import
Series,DataFrame, np
from numpy import nan as NA
data=DataFrame(np.random.randn(1000,4))
print(data.describe())
print("\n....евГіФГвЛСажаОјЖджЕДѓаЁГЌЙ§3ЕФЯю...\n")
col=data[3]
print(col[np.abs(col) > 3] )
print("\n....евГіШЋВПОјЖджЕГЌЙ§3ЕФжЕЕФаа...\n")
print(col[(np.abs(data) > 3).any(1)] )
|
вЦГ§жиИДЪ§Он
DataFrameЕФduplicatedЗНЗЈЗЕЛивЛИіВМЖћаЭSeriesЃЌБэЪОИїааЪЧЗёЪЧжиИДааЁЃ
from pandas import
Series,DataFrame, np
from numpy import nan as NA
import pandas as pd
import numpy as np
data=pd.DataFrame({'k1':['one']*3+['two']*4, 'k2':[1,1,2,2,3,3,4]})
print(data)
print("........\n")
print(data.duplicated())
|

гыДЫЯрЙиЕФЛЙгавЛИіdrop_duplicatedЗНЗЈЃЌЫќгУгкЗЕЛивЛИівЦГ§СЫжиИДааЕФDataFrameЃК
from pandas import
Series,DataFrame, np
from numpy import nan as NA
import pandas as pd
import numpy as np
data=pd.DataFrame({'k1':['one']*3+['two']*4, 'k2':[1,1,2,2,3,3,4]})
print(data)
print("........\n")
print(data.drop_duplicates())
|
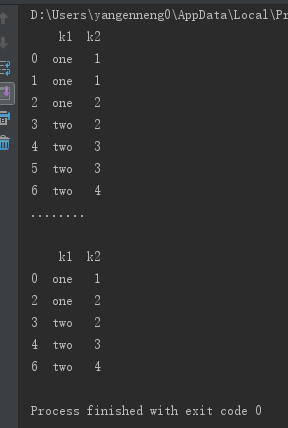
ЩЯУцЕФСНИіЗНЗЈЛсФЌШЯХаЖЯШЋВПСаЃЌвВПЩвджИЖЈВПЗжСаНјаажиИДЯюХаЖЯЃЌМйЩшЛЙгавЛСажЕЃЌЖјжЛЯЃЭћИљОнk1СаЙ§ТЫжиИДЯюЁЃ
from pandas import
Series,DataFrame, np
from numpy import nan as NA
import pandas as pd
import numpy as np
data=pd.DataFrame({'k1':['one']*3+['two']*4, 'k2':[1,1,2,2,3,3,4]})
data['v1']=range(7)
print(data)
print("........\n")
print(data.drop_duplicates(['k1']))
|
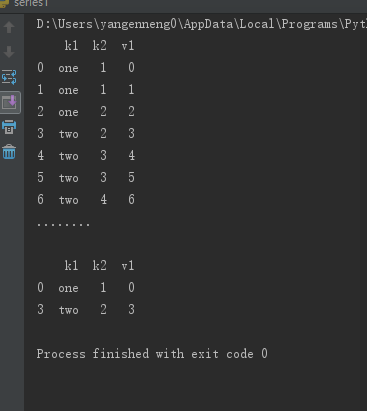
10duplicatesКЭdrop_duplicatesФЌШЯБЃСєЕквЛИіГіЯжЕФжЕзщКЯЁЃДЋШыtake_last=TrueдђБЃСєзюКѓвЛИіЃК
from pandas import
Series,DataFrame, np
from numpy import nan as NA
import pandas as pd
import numpy as np
data=pd.DataFrame({'k1':['one']*3+['two']*4, 'k2':[1,1,2,2,3,3,4]})
data['v1']=range(7)
print(data)
print("........\n")
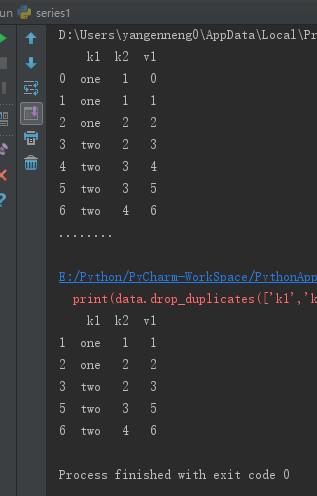
print(data.drop_duplicates(['k1','k2'],take_last=True)) |
|









