| БрМЭЦМі: |
| БОЮФРДздгкЮЂаХЙЋжкКХЃКPythonЪ§ОнПЦбЇЃЌЮФеТжївЊНВНтСЫдѕУДЩОГ§DataFrameЕФСаЃЌИФБфDataFrameЕФЫїв§ЃЌЪ§ОнЧхЯДЕУДгМђЕЅЕУзжЖЮЕНЧхЯДећИіЪ§ОнМЏЕШЕШЁЃ |
|
Ъ§ОнПЦбЇМвЛЈСЫДѓСПЕФЪБМфЧхЯДЪ§ОнМЏЃЌВЂНЋетаЉЪ§ОнзЊЛЛЮЊЫћУЧПЩвдДІРэЕФИёЪНЁЃЪТЪЕЩЯЃЌКмЖрЪ§ОнПЦбЇМвЩљГЦПЊЪМЛёШЁКЭЧхЯДЪ§ОнЕФЙЄзїСПвЊеМећИіЙЄзїЕФ80%ЁЃ
вђДЫЃЌШчЙћФуе§ЧЩвВдкетИіСьгђжаЃЌЛђепМЦЛЎНјШыетИіСьгђЃЌФЧУДДІРэетаЉдгТвВЛЙцдђЪ§ОнЪЧЗЧГЃживЊЕФЃЌетаЉдгТвЪ§ОнАќРЈвЛаЉШБЪЇжЕЃЌВЛСЌајИёЪНЃЌДэЮѓМЧТМЃЌЛђепЪЧУЛгавтвхЕФвьГЃжЕЁЃ
дкетИіНЬГЬжаЃЌЮвУЧНЋРћгУPythonЕФPandasКЭNumpyАќРДНјааЪ§ОнЧхЯДЁЃ
жївЊФкШнШчЯТЃК
ЩОГ§ DataFrame жаЕФВЛБивЊ columns
ИФБф DataFrame ЕФ index
ЪЙгУ .str() ЗНЗЈРДЧхЯД columns
ЪЙгУ DataFrame.applymap() КЏЪ§АДдЊЫиЕФЧхЯДећИіЪ§ОнМЏ
жиУќУћ columns ЮЊвЛзщИќвзЪЖБ№ЕФБъЧЉ
ТЫГ§ CSVЮФМўжаВЛБивЊЕФ rows
ЯТУцЪЧвЊгУЕНЕФЪ§ОнМЏЃК
BL-Flickr-Images-Book.csv - вЛЗнРДздгЂЙњЭМЪщЙнАќКЌЙигкЪщМЎаХЯЂЕФCSVЮФЕЕ
university_towns.txt - вЛЗнАќКЌУРЙњИїДѓжоДѓбЇГЧУћГЦЕФtextЮФЕЕ
olympics.csv - вЛЗнзмНсСЫИїЙњМвВЮМгЯФМОгыЖЌМОАТСжЦЅПЫдЫЖЏЛсЧщПіЕФCSVЮФЕЕ
ФуПЩвдДгReal Python ЕФ GitHub repository ЯТдиЪ§ОнМЏРДНјааЯТУцЕФР§згЁЃ
зЂвтЃКНЈвщЪЙгУJupter NotebooksРДбЇЯАЯТУцЕФжЊЪЖЁЃ
бЇЯАжЎЧАМйЩшФувбОгаСЫЖдPandasКЭNumpyПтЕФЛљБОШЯЪЖЃЌАќРЈPandasЕФЙЄзїЛљДЁSeriesКЭDataFrameЖдЯѓЃЌгІгУЕНетаЉЖдЯѓЩЯЕФГЃгУЗНЗЈЃЌвдМАЪьЯЄСЫNumPyЕФNaNжЕЁЃ
ШУЮвУЧЕМШыетаЉФЃПщПЊЪМЮвУЧЕФбЇЯАЁЃ
>>> import
pandas as pd
>>> import numpy as np |
ЩОГ§DataFrameЕФСа
ОГЃЕФЃЌФуЛсЗЂЯжЪ§ОнМЏжаВЛЪЧЫљгаЕФзжЖЮРраЭЖМЪЧгагУЕФЁЃР§ШчЃЌФуПЩФмгавЛИіЙигкбЇЩњаХЯЂЕФЪ§ОнМЏЃЌАќКЌаеУћЃЌЗжЪ§ЃЌБъзМЃЌИИФИаеУћЃЌзЁжЗЕШОпЬхаХЯЂЃЌЕЋЪЧФужЛЯыЗжЮібЇЩњЕФЗжЪ§ЁЃ
етИіЧщПіЯТЃЌзЁжЗЛђепИИФИаеУћаХЯЂЖдФуРДЫЕОЭВЛЪЧКмживЊЁЃетаЉУЛгагУЕФаХЯЂЛсеМгУВЛБивЊЕФПеМфЃЌВЂЛсЪЙдЫааЪБМфМѕТ§ЁЃ
PandasЬсЙЉСЫвЛИіЗЧГЃБуНнЕФЗНЗЈdrop()КЏЪ§РДвЦГ§вЛИіDataFrameжаВЛЯывЊЕФааЛђСаЁЃШУЮвУЧПДвЛИіМђЕЅЕФР§згШчКЮДгDataFrameжавЦГ§СаЁЃ
ЪзЯШЃЌЮвУЧв§ШыBL-Flickr-Images-Book.csvЮФМўЃЌВЂДДНЈвЛИіДЫЮФМўЕФDataFrameЁЃдкЯТУцетИіР§згжаЃЌЮвУЧЩшжУСЫвЛИіpd.read_csvЕФЯрЖдТЗОЖЃЌвтЮЖзХЫљгаЕФЪ§ОнМЏЖМдкDatasetsЮФМўМаЯТЕФЕБЧАЙЄзїФПТМжаЃК

ЮвУЧЪЙгУСЫhead()ЗНЗЈЕУЕНСЫЧАЮхИіаааХЯЂЃЌетаЉСаЬсЙЉСЫЖдЭМЪщЙнгаАяжњЕФИЈжњаХЯЂЃЌЕЋЪЧВЂВЛФмКмКУЕФУшЪіетаЉЪщМЎЃКEdition
Statement, Corporate Author, Corporate Contributors,
Former owner, Engraver, Issuance type and ShelfmarksЁЃ
вђДЫЃЌЮвУЧПЩвдгУЯТУцЕФЗНЗЈвЦГ§етаЉСаЃК
>>> to_drop
= ['Edition Statement',
... 'Corporate Author',
... 'Corporate Contributors',
... 'Former owner',
... 'Engraver',
... 'Contributors',
... 'Issuance type',
... 'Shelfmarks']
>>> df.drop(to_drop, inplace=True,
axis=1) |
дкЩЯУцЃЌЮвУЧЖЈвхСЫвЛИіАќКЌЮвУЧВЛвЊЕФСаЕФУћГЦСаБэЁЃНгзХЃЌЮвУЧдкЖдЯѓЩЯЕїгУdrop()КЏЪ§ЃЌЦфжаinplaceВЮЪ§ЪЧTrueЃЌaxisВЮЪ§ЪЧ1ЁЃетИцЫпСЫPandasЮвУЧЯывЊжБНгдкЮвУЧЕФЖдЯѓЩЯЗЂЩњИФБфЃЌВЂЧвЫќгІИУПЩвдбАевЖдЯѓжаБЛвЦГ§СаЕФаХЯЂЁЃ
ЮвУЧдйДЮПДвЛЯТDataFrameЃЌЮвУЧЛсПДЕНВЛвЊЯыЕФаХЯЂвбОБЛвЦГ§СЫЁЃ

ЭЌбљЕФЃЌЮвУЧвВПЩвдЭЈЙ§ИјcolumnsВЮЪ§ИГжЕжБНгвЦГ§СаЃЌЖјОЭВЛгУЗжБ№ЖЈвхto_dropСаБэКЭaxisСЫЁЃ
| >>> df.drop(columns=to_drop,
inplace=True) |
етжжгяЗЈИќжБЙлИќПЩЖСЁЃЮвУЧетРяНЋвЊзіЪВУДОЭКмУїЯдСЫЁЃ
ИФБфDataFrameЕФЫїв§
PandasЫїв§indexРЉеЙСЫNumpyЪ§зщЕФЙІФмЃЌвддЪаэИќЖрЖрбљЛЏЕФЧаЗжКЭБъМЧЁЃдкКмЖрЧщПіЯТЃЌЪЙгУЮЈвЛЕФжЕзїЮЊЫїв§жЕЪЖБ№Ъ§ОнзжЖЮЪЧЗЧГЃгаАяжњЕФЁЃ
Р§ШчЃЌШдШЛЪЙгУЩЯвЛНкЕФЪ§ОнМЏЃЌПЩвдЯыЯѓЕБвЛИіЭМЪщЙмРэдБбАеввЛИіМЧТМЃЌЫћУЧвВаэЛсЪфШывЛИіЮЈвЛБъЪЖРДЖЈЮЛвЛБОЪщЁЃ
>>>
df['Identifier'].is_unique
True |
ШУЮвУЧгУset_indexАбвбОДцдкЕФЫїв§ИФЮЊетИіСаЁЃ

ММЪѕЯИНкЃКВЛЯёдкSQLжаЕФжїМќвЛбљЃЌpandasЕФЫїв§ВЛБЃжЄЮЈвЛадЃЌОЁЙмаэЖрЫїв§КЭКЯВЂВйзїНЋЛсЪЙдЫааЪБМфБфГЄШчЙћЪЧетбљЁЃ
ЮвУЧПЩвдгУвЛИіжБНгЕФЗНЗЈloc[]РДЛёШЁУПвЛЬѕМЧТМЁЃОЁЙмloc[]етИіДЪПЩФмПДЩЯШЅУЛгаФЧУДжБЙлЃЌЕЋЫќдЪаэЮвУЧЪЙгУЛљгкБъЧЉЕФЫїв§ЃЌетИіЫїв§ЪЧааЕФБъЧЉЛђепВЛПМТЧЮЛжУЕФМЧТМЁЃ

ЛЛОфЛАЫЕЃЌ206ЪЧЫїв§ЕФЕквЛИіБъЧЉЁЃШчЙћЯыЭЈЙ§ЮЛжУЛёШЁЫќЃЌЮвУЧПЩвдЪЙгУdf.iloc[0]ЃЌЪЧвЛИіЛљгкЮЛжУЕФЫїв§ЁЃ
жЎЧАЃЌЮвУЧЕФЫїв§ЪЧвЛИіЗЖЮЇЫїв§ЃКДг0ПЊЪМЕФећЪ§ЃЌРрЫЦPythonЕФФкНЈrangeЁЃЭЈЙ§Ијset_indexвЛИіСаУћЃЌЮвУЧОЭАбЫїв§БфГЩСЫIdentifierжаЕФжЕЁЃ
ФувВаэзЂвтЕНСЫЮвУЧЭЈЙ§df = df.set_index(...)ЕФЗЕЛиБфСПжиаТИјЖдЯѓИГСЫжЕЁЃетЪЧвђЮЊЃЌФЌШЯЕФЧщПіЯТЃЌетИіЗНЗЈЗЕЛивЛИіБЛИФБфЖдЯѓЕФПНБДЃЌВЂЧвЫќВЛЛсжБНгЖддЖдЯѓзіШЮКЮИФБфЁЃЮвУЧПЩвдЭЈЙ§ЩшжУВЮЪ§inplaceРДБмУтетИіЮЪЬтЁЃ
| df.set_index('Identifier',
inplace=True) |
ЧхЯДЪ§ОнзжЖЮ
ЕНЯждкЮЊжЙЃЌЮвУЧвЦГ§СЫВЛБивЊЕФСаВЂИФБфСЫЮвУЧЕФЫїв§БфЕУИќгавтвхЁЃетИіВПЗжЃЌЮвУЧНЋЧхЯДЬиЪтЕФСаЃЌВЂЪЙЫќУЧБфГЩЭГвЛЕФИёЪНЃЌетбљПЩвдИќКУЕФРэНтЪ§ОнМЏКЭМгЧПСЌајадЁЃЬиБ№ЕФЃЌЮвУЧНЋЧхЯДDate
of PublicationКЭPlace of PublicationЁЃ
ИљОнЩЯУцЙлВьЃЌЫљгаЕФЪ§ОнРраЭЖМЪЧЯждкЕФobjectdtypeРраЭЃЌВюВЛЖрРрЫЦгкPythonжаЕФstrЁЃ
ЫќАќКЌСЫвЛаЉВЛФмБЛЪЪгУгкЪ§жЕЛђЪЧЗжРрЕФЪ§ОнЁЃетвВе§ГЃЃЌвђЮЊЮвУЧе§дкДІРэетаЉГѕЪМжЕОЭЪЧдгТвЮоеТзжЗћДЎЕФЪ§ОнЁЃ
>>>
df.get_dtype_counts()
object 6 |
вЛИіашвЊБЛИФБфЮЊЪ§жЕЕФЕФзжЖЮЪЧthe date of publicationЫљвдЮвУЧзіШчЯТВйзїЃК
>>>
df.loc[1905:, 'Date of Publication'].head(10)
Identifier
1905 1888
1929 1839, 38-54
2836 [1897?]
2854 1865
2956 1860-63
2957 1873
3017 1866
3131 1899
4598 1814
4884 1820
Name: Date of Publication, dtype: object |
вЛБОЪщжЛФмгавЛИіГіАцШеЦкdata of publicationЁЃвђДЫЃЌЮвУЧашвЊзівдЯТЕФвЛаЉЪТЧщЃК
вЦГ§дкЗНРЈКХФкЕФЖюЭтШеЦкЃЌШЮКЮДцдкЕФЃК1879[1878]ЁЃ
НЋШеЦкЗЖЮЇзЊЛЏЮЊЫќУЧЕФЦ№ЪМШеЦкЃЌШЮКЮДцдкЕФЃК1860-63;1839,38-54ЁЃ
ЭъШЋвЦГ§ЮвУЧВЛЙиаФЕФШеЦкЃЌВЂгУNumpyЕФNaNЬцЛЛЃК[1879?]ЁЃ
НЋзжЗћДЎnanзЊЛЏЮЊNumpyЕФNaNжЕЁЃ
ПМТЧетаЉФЃЪНЃЌЮвУЧПЩвдгУвЛИіМђЕЅЕФе§дђБэДяЪНРДЬсШЁГіАцШеЦкЃК
ЩЯУце§дђБэДяЪНЕФвтЫМдкзжЗћДЎПЊЭЗбАевШЮКЮЫФЮЛЪ§зжЃЌЗћКЯЮвУЧЕФЧщПіЁЃ
\dДњБэШЮКЮЪ§зжЃЌ{4}жиИДетИіЙцдђЫФДЮЁЃ^ЗћКХЦЅХфвЛИізжЗћДЎзюПЊЪМЕФВПЗжЃЌдВРЈКХБэЪОвЛИіЗжзщЃЌЬсЪОpandasЮвУЧЯывЊЬсШЁе§дђБэДяЪНЕФВПЗжЁЃ
ШУЮвУЧПДПДдЫааетИіе§дђдкЪ§ОнМЏЩЯжЎКѓЛсЗЂЩњЪВУДЁЃ
>>>
extr = df['Date of Publication'].str.extract(r'^(\d{4})',
expand=False)
>>> extr.head()
Identifier
206 1879
216 1868
218 1869
472 1851
480 1857
Name: Date of Publication, dtype: object |
ЦфЪЕетИіСаШдШЛЪЧвЛИіobjectРраЭЃЌЕЋЪЧЮвУЧПЩвдЪЙгУpd.to_numericЧсЫЩЕФЕУЕНЪ§зжЕФАцБОЃК
>>>
df['Date of Publication'] = pd.to_numeric(extr)
>>> df['Date of Publication'].dtype
dtype('float64') |
етИіНсЙћжаЃЌ10ИіжЕРяДѓдМга1ИіжЕШБЪЇЃЌетШУЮвУЧИЖГіСЫКмаЁЕФДњМлРДЖдЪЃгргааЇЕФжЕзіМЦЫуЁЃ
>>>
df['Date of Publication'].isnull().sum() / len(df)
0.11717147339205986 |
НсКЯstrЗНЗЈгыNumpyЧхЯДСа
ЩЯУцЃЌФуПЩвдЙлВьЕНdf['Date of Publication'].str. ЕФЪЙгУЁЃетИіЪєадЪЧpandasРяЕФвЛжжЬсЩ§зжЗћДЎВйзїЫйЖШЕФЗНЗЈЃЌВЂгаДѓСПЕФPythonзжЗћДЎЛђБрвыЕФе§дђБэДяЪНЩЯЕФаЁВйзїЃЌР§Шч.split(),.replace(),КЭ.capitalize()ЁЃ
ЮЊСЫЧхЯДPlace of PublicationзжЖЮЃЌЮвУЧПЩвдНсКЯpandasЕФstrЗНЗЈКЭnumpyЕФnp.whereКЏЪ§ХфКЯЭъГЩЁЃ
ЫќЕФгяЗЈШчЯТЃК
| >>> np.where(condition,
then, else) |
етРяЃЌconditionПЩвдЪЙвЛИіРрЪ§зщЕФЖдЯѓЃЌвВПЩвдЪЧвЛИіВМЖћБэДяЁЃШчЙћconditionжЕЮЊецЃЌФЧУДthenНЋБЛЪЙгУЃЌЗёдђЪЙгУelseЁЃ
ЫќвВПЩвдзщЭјЪЙгУЃЌдЪаэЮвУЧЛљгкЖрИіЬѕМўНјааМЦЫуЁЃ
>>>
np.where(condition1, x1,
np.where(condition2, x2,
np.where(condition3, x3, ...))) |
ЮвУЧНЋЪЙгУетСНИіЗНГЬРДЧхЯДPlace of PublicationгЩгкетСагазжЗћДЎЖдЯѓЁЃвдЯТЪЧетИіСаЕФФкШнЃК
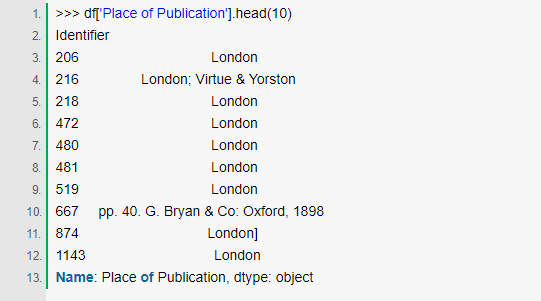
ЮвУЧПДЕНЃЌЖдгквЛаЉааЃЌplace of publicationЛЙБЛвЛаЉЦфЫќУЛгагУЕФаХЯЂЮЇШЦзХЁЃШчЙћЮвУЧПДИќЖрЕФжЕЃЌЮвУЧЗЂЯжетжжЧщПіжагааЉаа
ШУЮвУЧПДПДСНИіЬиЪтЕФЃК
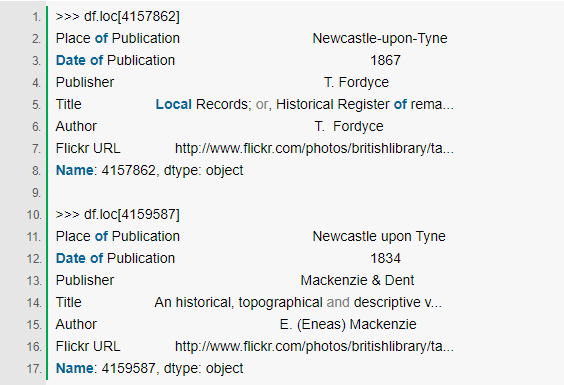
етСНБОЪщдкЭЌвЛИіЕиЗНГіАцЃЌЕЋЪЧвЛИігаСЌзжЗћЃЌСэвЛИіУЛгаЁЃ
ЮЊСЫвЛДЮадЧхЯДетИіСаЃЌЮвУЧЪЙгУstr.contains()РДЛёШЁвЛИіВМЖћжЕЁЃ
ЮвУЧЧхЯДЕФСаШчЯТЃК
>>>
pub = df['Place of Publication']
>>> london = pub.str.contains('London')
>>> london[:5]
Identifier
206 True
216 True
218 True
472 True
480 True
Name: Place of Publication, dtype: bool
>>> oxford = pub.str.contains('Oxford')
|
ЮвУЧНЋЫќгыnp.whereНсКЯЁЃ
df['Place of
Publication'] = np.where(london, 'London',
np.where(oxford, 'Oxford',
pub.str.replace('-', ' ')))
>>> df['Place of Publication'].head()
Identifier
206 London
216 London
218 London
472 London
480 London
Name: Place of Publication, dtype: object |
етРяЃЌnp.whereЗНГЬдквЛИіЧЖЬзЕФНсЙЙжаБЛЕїгУЃЌconditionЪЧвЛИіЭЈЙ§st.contains()ЕУЕНЕФВМЖћЕФSeriesЁЃcontains()ЗНЗЈгыPythonФкНЈЕФinЙиМќзжвЛбљЃЌгУгкЗЂЯжвЛИіИіЬхЪЧЗёЗЂЩњдквЛИіЕќДњЦїжаЁЃ
ЪЙгУЕФЬцДњЮяЪЧвЛИіДњБэЮвУЧЦкЭћЕФГіАцЩчЕижЗзжЗћДЎЁЃЮвУЧвВЪЙгУstr.replace()НЋСЌзжЗћЬцЛЛЮЊПеИёЃЌШЛКѓИјDataFrameжаЕФСажиаТИГжЕЁЃ
ОЁЙмЪ§ОнМЏжаЛЙгаИќЖрЕФВЛИЩОЛЪ§ОнЃЌЕЋЪЧЮвУЧЯждкНіЬжТлетСНСаЁЃ
ШУЮвУЧПДПДЧАЮхааЃЌЯждкПДЦ№РДБШЮвУЧИеПЊЪМЕФЪБКђКУЕуСЫЁЃ
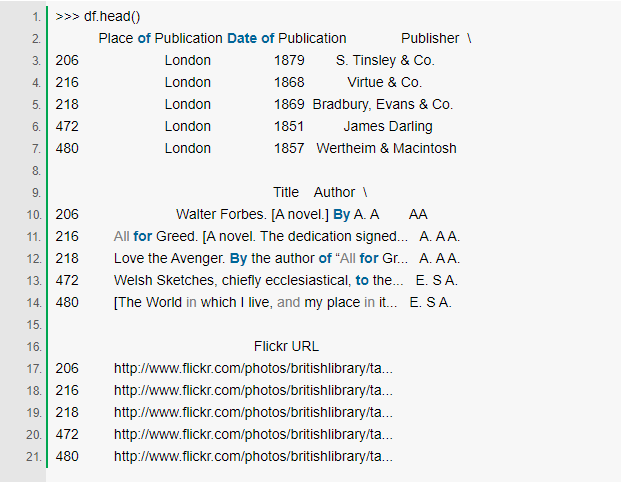
дкетвЛЕуЩЯЃЌPlace of PublicationОЭЪЧвЛИіКмКУЕФашвЊБЛзЊЛЛГЩЗжРрЪ§ОнЕФРраЭЃЌвђЮЊЮвУЧПЩвдгУећЪ§НЋетЯрЕБаЁЕФЮЈвЛГЧЪаМЏБрТыЁЃЃЈЗжРрЪ§ОнЕФЪЙгУФкДцгыЗжРрЕФЪ§СПвдМАЪ§ОнЕФГЄЖШГЩе§БШЃЉ
ЪЙгУapplymapЗНЗЈЧхЯДећИіЪ§ОнМЏ
дквЛЖЈЕФЧщПіЯТЃЌФуНЋПДЕНВЂВЛЪЧНіНігавЛЬѕСаВЛИЩОЛЃЌЖјЪЧИќЖрЕФЁЃ
дквЛаЉЪЕР§жаЃЌЪЙгУвЛИіЖЈжЦЕФКЏЪ§ЕНDataFrameЕФУПвЛИідЊЫиНЋЛсЪЧКмгаАяжњЕФЁЃpandasЕФapplyma()ЗНЗЈгыФкНЈЕФmap()КЏЪ§ЯрЫЦЃЌВЂЧвМђЕЅЕФгІгУЕНвЛИіDataFrameжаЕФЫљгадЊЫиЩЯЁЃ
ШУЮвУЧПДвЛИіР§згЁЃЮвУЧНЋЛљгк"university_towns.txt"ЮФМўДДНЈвЛИіDataFrameЁЃ
$ head Datasets/univerisity_towns.txt
Alabama[edit]
Auburn (Auburn University)[1]
Florence (University of North Alabama)
Jacksonville (Jacksonville State University)[2]
Livingston (University of West Alabama)[2]
Montevallo (University of Montevallo)[2]
Troy (Troy University)[2]
Tuscaloosa (University of Alabama, Stillman College,
Shelton State)[3][4]
Tuskegee (Tuskegee University)[5]
Alaska[edit] |
ЮвУЧПЩвдПДЕНУПИіstateКѓБпЖМгавЛаЉдкФЧИіstateЕФДѓбЇГЧЃКStateA TownA1 TownA2
StateB TownB1 TownB2...ЁЃШчЙћЮвУЧзаЯИЙлВьstateУћзжЕФаДЗЈЃЌЮвУЧЛсЗЂЯжЫќУЧЖМга"[edit]"ЕФздзжЗћДЎЁЃ
ЮвУЧПЩвдРћгУетИіЬиеїДДНЈвЛИіКЌга(state,city)дЊзщЕФСаБэЃЌВЂНЋетИіСаБэЧЖШыЕНDdataFrameжаЃЌ
>>>
university_towns = []
>>> with open('Datasets/university_towns.txt')
as file:
... for line in file:
... if '[edit]' in line:
... # Remember this `state` until the next is
found
... state = line
... else:
... # Otherwise, we have a city; keep `state`
as last-seen
... university_towns.append((state, line))
>>> university_towns[:5]
[('Alabama[edit]\n', 'Auburn (Auburn University)[1]\n'),
('Alabama[edit]\n', 'Florence (University of North
Alabama)\n'),
('Alabama[edit]\n', 'Jacksonville (Jacksonville
State University)[2]\n'),
('Alabama[edit]\n', 'Livingston (University of
West Alabama)[2]\n'),
('Alabama[edit]\n', 'Montevallo (University of
Montevallo)[2]\n')] |
ЮвУЧПЩвддкDataFrameжаАќзАетИіСаБэЃЌВЂЩшСаУћЮЊ"State"КЭ"RegionName"ЁЃpandasНЋЛсЪЙгУСаБэжаЕФУПИідЊЫиЃЌШЛКѓЩшжУStateЕНзѓБпЕФСаЃЌRegionNameЕНгвБпЕФСаЁЃ
зюжеЕФDataFrameЪЧетбљЕФЃК
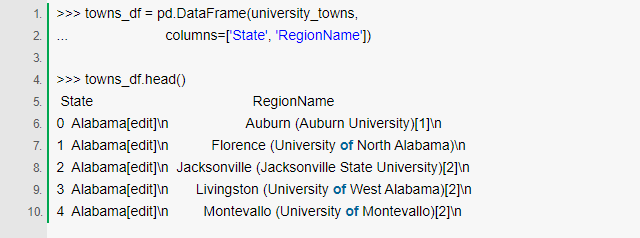
ЮвУЧПЩвдЯёЩЯУцЪЙгУfor loopРДНјааЧхЯДЃЌЕЋЪЧpandasЬсЙЉСЫИќМђЕЅЕФАьЗЈЁЃЮвУЧжЛашвЊstate
nameКЭtown nameЃЌШЛКѓОЭПЩвдвЦГ§ЫљвдЦфЫћЕФСЫЁЃетРяЮвУЧПЩвддйДЮЪЙгУpandasЕФ.str()ЗНЗЈЃЌЭЌЪБЮвУЧвВПЩвдЪЙгУapplymap()НЋвЛИіpython
callableгГЩфЕНDataFrameжаЕФУПИідЊЫиЩЯЁЃ
ЮвУЧвЛжБдкЪЙгУ"дЊЫи"етИіЩугкЃЌЕЋЪЧЮвУЧЕНЕзЪЧЪВУДвтЫМФиЃППДПДЯТУцетИі"toy"ЕФDataFrameЃК

дкетИіР§згжаЃЌУПИіЕЅдЊ (ЁЎMockЁЏ, ЁЎDatasetЁЏ, ЁЎPythonЁЏ,
ЁЎPandasЁЏ, etc.) ЖМЪЧвЛИідЊЫиЁЃвђДЫЃЌapplymap()НЋЗжБ№гІгУвЛИіКЏЪ§ЕНетаЉдЊЫиЩЯЁЃШУЮвУЧЖЈвхетИіКЏЪ§ЁЃ

pandasЕФapplymap()жЛгУвЛИіВЮЪ§ЃЌОЭЪЧвЊгІгУЕНУПИідЊЫиЩЯЕФКЏЪ§ЃЈcallableЃЉЁЃ
| >>>
towns_df = towns_df.applymap(get_citystate) |
ЪзЯШЃЌЮвУЧЖЈвхвЛИіКЏЪ§ЃЌЫќНЋДгDataFrameжаЛёШЁУПвЛИідЊЫизїЮЊздМКЕФВЮЪ§ЁЃдкетИіКЏЪ§жаЃЌМьбщдЊЫижаЪЧЗёгавЛИі(Лђеп[ЁЃ
ЛљгкЩЯУцЕФМьВщЃЌКЏЪ§ЗЕЛиЯргІЕФжЕЁЃзюКѓЃЌapplymap()КЏЪ§БЛгУдкЮвУЧЕФЖдЯѓЩЯЁЃЯждкDataFrameОЭПДЦ№РДИќИЩОВСЫЁЃ

applymap()ЗНЗЈДгDataFrameжаЬсШЁУПИідЊЫиЃЌДЋЕнЕНКЏЪ§жаЃЌШЛКѓИВИЧдРДЕФжЕЁЃОЭЪЧетУДМђЕЅЃЁ
ММЪѕЯИНкЃКЫфШЛ.applymapЪЧвЛИіЗНБуКЭСщЛюЕФЗНЗЈЃЌЕЋЪЧЖдгкДѓЕФЪ§ОнМЏЫќНЋЛсЛЈЗбКмГЄЪБМфдЫааЃЌвђЮЊЫќашвЊНЋpython
callableгІгУЕНУПИідЊЫиЩЯЁЃвЛаЉЧщПіжаЃЌЪЙгУCythonЛђепNumPYЕФЯђСПЛЏЕФВйзїЛсИќИпаЇЁЃ
жиУќУћСаКЭвЦГ§аа
ОГЃЕФЃЌФуДІРэЕФЪ§ОнМЏЛсгаШУФуВЛЬЋШнвзРэНтЕФСаУћЃЌЛђепдкЭЗМИааЛђзюКѓМИаагавЛаЉВЛживЊЕФаХЯЂЃЌР§ШчЪѕгяЖЈвхЃЌЛђЪЧИНзЂЁЃ
етжжЧщПіЯТЃЌЮвУЧЯыжиаТУќУћСаКЭвЦГ§вЛЖЈЕФаавдШУЮвУЧжЛСєЯТе§ШЗКЭгавтвхЕФаХЯЂЁЃ
ЮЊСЫжЄУїЮвУЧШчКЮДІРэЫќЃЌЮвУЧЯШПДвЛЯТ"olympics.csv"Ъ§ОнМЏЕФЭЗ5ааЃК
$ head -n 5
Datasets/olympics.csv
0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15
,? Summer,01 !,02 !,03 !,Total,? Winter,01 !,02
!,03 !,Total,? Games,01 !,02 !,03 !,Combined total
Afghanistan (AFG),13,0,0,2,2,0,0,0,0,0,13,0,0,2,2
Algeria (ALG),12,5,2,8,15,3,0,0,0,0,15,5,2,8,15
Argentina (ARG),23,18,24,28,70,18,0,0,0,0,41,18,24,28,70
|
ЯждкЮвУЧНЋЫќЖСШыpandasЕФDataFrameЁЃ

етЕФШЗгаЕуТвЃЁСаУћЪЧвдећЪ§ЕФзжЗћДЎаЮЪНЫїв§ЕФЃЌвд0ПЊЪМЁЃБОгІИУЪЧСаУћЕФааШДДІдкolympics_df.iloc[0]ЁЃЗЂЩњетИіЪЧвђЮЊCSVЮФМўвд0,
1, 2, Ё, 15Ц№ЪМЕФЁЃ
ЭЌбљЃЌШчЙћЮвУЧШЅЪ§ОнМЏЕФдДЮФМўЙлВьЃЌЩЯУцЕФNaNецЕФгІИУЪЧЯё"Country"етбљЕФЃЌ?
SummerгІИУДњБэ"Summer Games", Жј01 !гІИУЪЧ"Gold"жЎРрЕФЁЃ
вђДЫЃЌЮвУЧашвЊзіСНМўЪТЃК
вЦГ§ЕквЛааВЂЩшжУheaderЮЊЕквЛаа
жиаТУќУћСа
ЕБЮвУЧЖСCSVЮФМўЕФЪБКђЃЌПЩвдЭЈЙ§ДЋЕнвЛаЉВЮЪ§ЕНread_csvКЏЪ§РДвЦГ§ааКЭЩшжУСаУћГЦЁЃ
етИіКЏЪ§гаКмЖрПЩбЁшёЪїЃЌЕЋЪЧетРяЮвУЧжЛашвЊheader
РДвЦГ§Ек0ааЃК
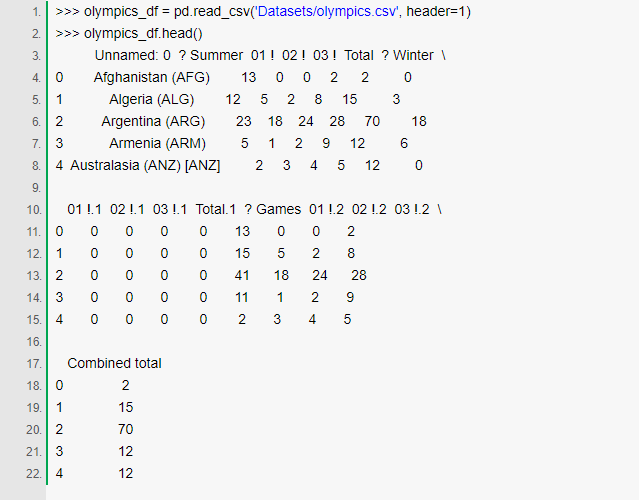
ЮвУЧЯждкгаСЫЩшжУЮЊheaderЕФе§ШЗааЃЌВЂЧвЫљгаУЛгУЕФааЖМБЛвЦГ§СЫЁЃМЧТМвЛЯТpandasЪЧШчКЮНЋАќКЌЙњМвЕФСаУћNaNИФБфЮЊUnnamed:0ЕФЁЃ
ЮЊСЫжиУќУћСаЃЌЮвУЧНЋЪЙгУDataFrameЕФrename()ЗНЗЈЃЌдЪаэФувдвЛИігГЩфЃЈетРяЪЧвЛИізжЕфЃЉжиаТБъМЧвЛИіжсЁЃ
ШУЮвУЧПЊЪМЖЈвхвЛИізжЕфРДНЋЯждкЕФСаУћГЦЃЈМќЃЉгГЩфЕНИќЖрЕФПЩгУСаУћГЦЃЈзжЕфЕФжЕЃЉЁЃ

ЮвУЧдкЖдЯѓЩЯЕїгУrename()КЏЪ§ЃК
| >>>
olympics_df.rename (columns=new_names, inplace=True)
|
ЩшжУinplaceЮЊTrueПЩвдШУЮвУЧЕФИФБфжБНгЗДгГдкЖдЯѓЩЯЁЃШУЮвУЧПДПДЪЧЗёе§ШЗЃК
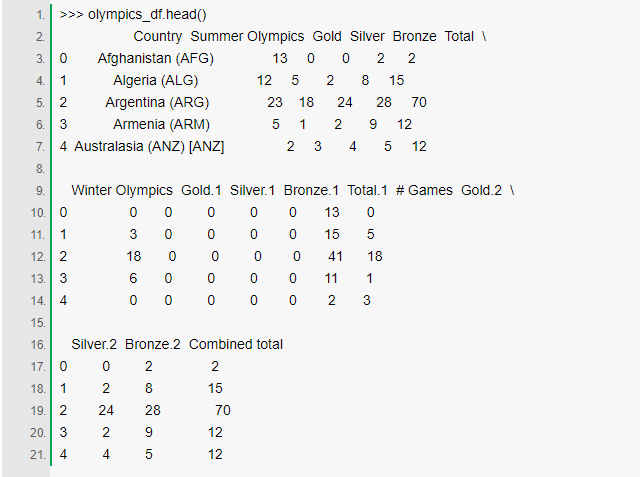
PythonЪ§ОнЧхЯДЃКЛиЙЫ
етИіНЬГЬжаЃЌФубЇЛсСЫДгЪ§ОнМЏжаШчКЮЪЙгУdrop()КЏЪ§ШЅГ§ВЛБивЊЕФаХЯЂЃЌвВбЇЛсСЫШчКЮЮЊЪ§ОнМЏЩшжУЫїв§ЃЌвдШУitemsПЩвдБЛШнвзЕФевЕНЁЃ
ИќЖрЕФЃЌФубЇЛсСЫШчКЮЪЙгУ.str()ЧхЯДЖдЯѓзжЖЮЃЌвдМАШчКЮЪЙгУapplymapЖдећИіЪ§ОнМЏЧхЯДЁЃзюКѓЃЌЮвУЧЬНЫїСЫШчКЮвЦГ§CSVЮФМўЕФааЃЌВЂЧвЪЙгУrename()ЗНЗЈжиУќУћСаЁЃ
еЦЮеЪ§ОнЧхЯДЗЧГЃживЊЃЌвђЮЊЫќЪЧЪ§ОнПЦбЇЕФвЛИіДѓЕФВПЗжЁЃФуЯждкгІИУгаСЫвЛИіШчКЮЪЙгУpandasКЭnumpyНјааЪ§ОнЧхЯДЕФЛљБОРэНтСЫЁЃ
|









